В концепции умного города привычная инфраструктура ЖКХ и жизнедеятельности оснащается современными сенсорами, контроллерами и видеокамерами, подключается к широкополосным сетям и интегрируется с платформой для сбора и обработки данных. Все эти данные анализируются и позволяют добиться нового уровня эффективности и оптимизации работы городских служб и локального бизнеса, будь то расходование ресурсов или управление пассажиропотоками.
В теории все выглядит просто, но на деле тем, кто развивает идеологию умного города, приходится сталкиваться с массой барьеров, как типичных для крупных IT-проектов, так и индивидуальных, например, для ЖКХ. И это серьезно усложняет процесс.

Некоторое время назад мы представили свое видение умного города — концепцию Smart/Safe City. Под катом — детальный взгляд на нее с позиции бизнеса и технических специалистов.
Идеи и компоненты
Концепция умного города (Smart/Safe City) включает в себя компоненты из самых разных областей жизнедеятельности, потребителями которой являются как бизнес и госорганизации, так и сами жители городов. И прежде чем говорить о деталях идеи, пройдемся по ее основным составляющим.
Умный транспорт
В крупных городах мы привыкли пользоваться интеллектуальными сервисами анализа пробок и планирования маршрутов. В основе таких сервисов — сбор и обработка данных о перемещениях транспортных средств в рамках дорожной сети. Но понятие умного транспорта намного шире. Оснащение транспортных средств датчиками местоположения и скорости, а также камерами видеонаблюдения позволяет решать самые разные задачи, начиная с обеспечения безопасности и заканчивая управлением логистикой: датчики позволяют понимать, где автомобиль находится, чем занимается и как может спланировать свой дальнейший маршрут.

Что может дать бизнесу и городскому хозяйству умный транспорт:
- управление движением городского транспорта;
- работы служебных автопарков и таксопарков.
Хороший пример реализации концепции — одно из наших решений для китайского рынка. В партнерстве с несколькими производителями автомобили прямо на конвейере оснащаются необходимым оборудованием, чтобы после выпуска встроиться в систему управления транспортом, в частности, в городе Chisinau.
Развитие идей умного транспорта приведет к появлению полноценного автопилота для частных автомобилей и, соответственно, к отходу профессии водителя в прошлое. Однако на пути к этому предстоит решить очень много технологических и юридических вопросов, поэтому случится ли это в ближайшее десятилетие (и, тем более, в России) — не ясно.
Безопасность и полиция

Один из наиболее востребованных и проработанных сценариев умного города на сегодняшний день — это безопасность (в контексте защиты от преступности).
Улицы городов по всему миру оснащаются камерами видеонаблюдения, подключенными к единой системе сбора и обработки информации, что позволяет снизить объем преступлений. Хорошо иллюстрирует перспективность этой концепции пример Кении, где по мере развертывания современных сетей связи и реализации проекта «Безопасный город» уровень преступности в среднем по стране за один только 2015 год упал на 46%.
Однако видеонаблюдение — лишь вершина айсберга. Умная полиция — это попытка преобразовать привычную службу в более эффективный инструмент обеспечения правопорядка в условиях роста плотности населения. Тут есть огромный пласт технологий, которых обычный пользователь просто не замечает. Помимо самой системы видеонаблюдения, сюда могут входить:
- новые инструменты связи, позволяющие оперативно получать информацию о происшествиях;
- современные системы экстренного оповещения сотрудников и населения;
- техника (роботы-саперы, беспилотники и т.п.), позволяющая заменить людей при решении опасных задач или усовершенствовать поисковые и иные мероприятия;
- инструменты сбора данных, которые могут быть использованы в качестве доказательной базы (аудиозапись и т.п.);
- системы анализа всевозможных данных, позволяющие выявить нетипичное поведение людей или сбои функционирования инфраструктуры на ранней стадии.
Конечно, переход к умной полиции — это еще и социальные преобразования, позволяющие сообществу участвовать в поддержании порядка.

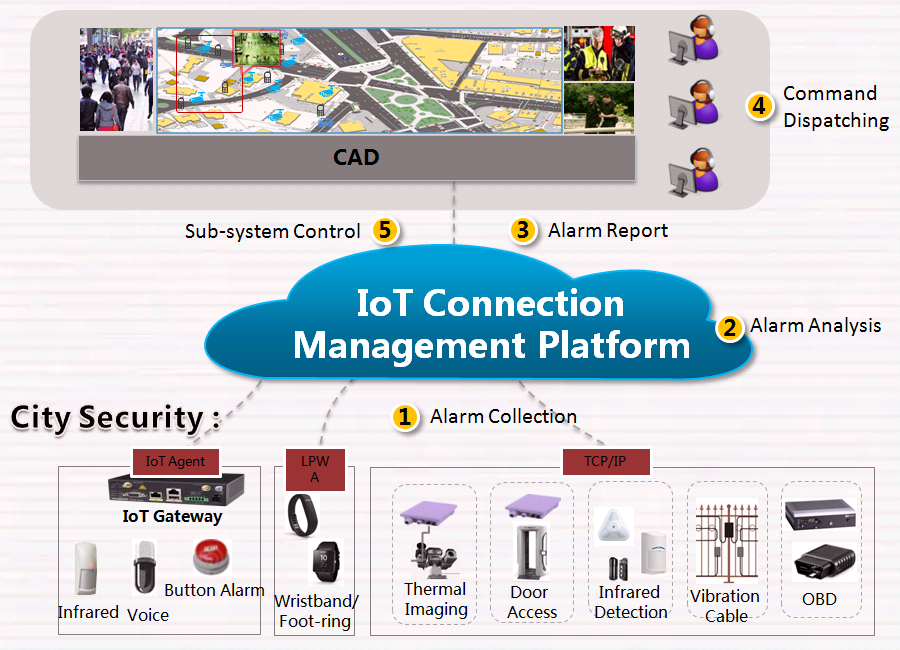
В перспективе концепция умной полиции подразумевает создание ситуационных центров, куда стекается вся информация, собираемая инфраструктурой умного города, особенно из критичных точек. Видя всю ситуацию в комплексе, экстренные службы могут оперативнее принимать решения.

В отдаленной перспективе проекты «безопасный город» должны свести на нет уличную преступность, ведь совершенно бессмысленно воровать сумочки, если благодаря анализу записей камер виденаблюдения в зоне происшествия и отслеживанию маршрута преступника через камеры соседних улиц через 10 минут после кражи злоумышленник будет арестован.
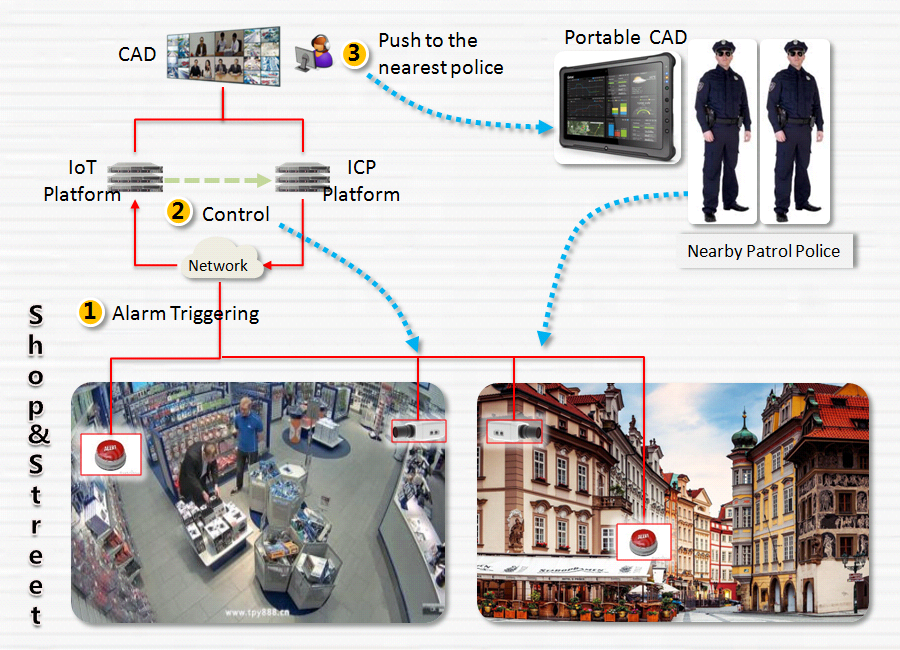
Умное потребление ресурсов
Очевидно, что точный учет потребляемых ресурсов позволяет управлять нагрузкой или осуществлять экономию.
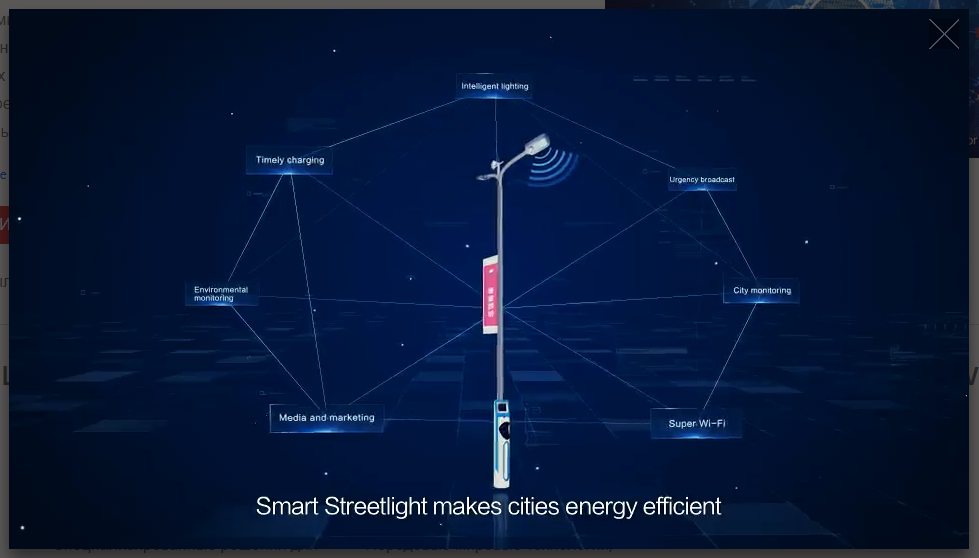
Хотя счетчики расхода различных ресурсов внедряются давно, в этой сфере, если можно так выразиться, пока не пройден даже «уровень 0» — то есть внедрение интеллектуальных систем находится на начальной стадии. Необходимо не только внедрить датчики во всех сферах ЖКХ, но и собрать данные в единую платформу для централизованного управления. В масштабах нашей страны это задача на годы и миллиардные бюджеты.
В мире есть примеры городов, активно внедряющих умное потребление ресурсов. В частности, Барселона внедрила автоматизированное управление уличным освещением с учетом времени суток и погодных условий. Учитывая благоприятные климатические условия (и серьезные проблемы с загрязнениями городского воздуха), здесь активно используется солнечная энергия — для нагрева воды в зданиях, а также питания интерактивных табло остановок общественного транспорта. При участии города разрабатывается модульная open source платформа Sentilo, собирающая и анализирующая информацию со счетчиков потребления основных ресурсов, датчиков погоды, окружающего шума и т.п. (система работает уже более трех лет, ее работу можно оценить на официальном сайте sentilo.io). В 2015 Барселона удостоилась звания «самого умного города на планете».
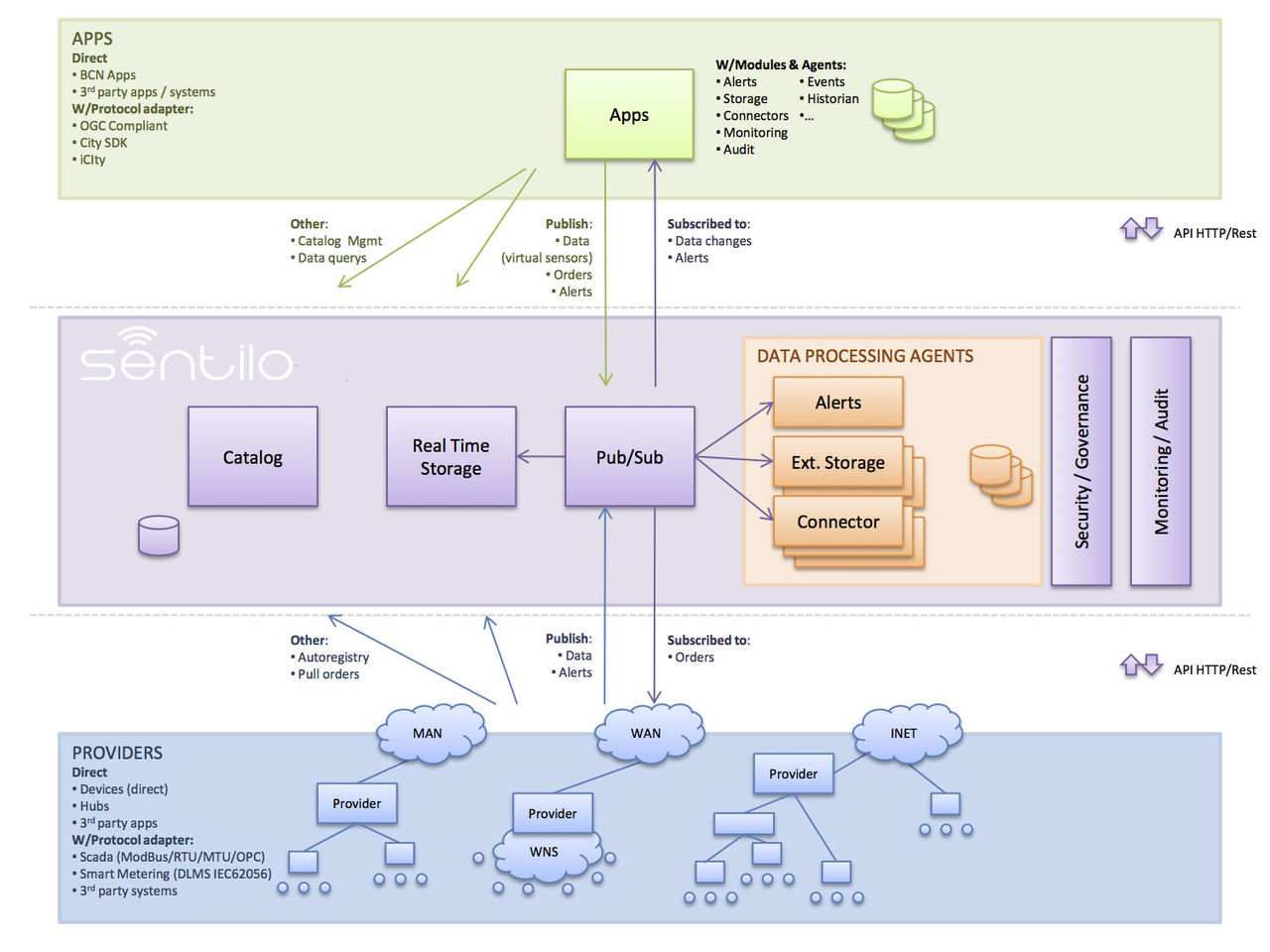

Еще один пример — китайский город Шеньчжень (IT-столица Китая), где на базе нашей системы умного города был оснащен датчиками городской водопровод. В общей сложности в системе расставлено порядка двух миллионов датчиков, собирающих информацию с разных точек и позволяющих в режиме реального времени управлять ситуацией с подачей воды.
Другие сферы
Умные образование и здравоохранение (как и другая сфера — массовые мероприятия и туризм) позволяют не столько сэкономить, сколько повысить качество жизни в городе.
Широкополосные сети дают возможность существенно расширить аудиторию, слушающую тот или иной учебный курс. Для этого образовательные учреждения оснащаются электронными досками и камерами, а также системами удаленного присутствия. На разных уровнях образования это позволяет решить разные задачи — от обеспечения обязательным средним образованием маломобильных граждан до удаленного высшего образования в ведущих университетах страны.
Аналогичные системы в медицине, например, в форме передвижной тележки с диагностическими приборами, компьютером, видеокамерой и т.п., позволяют обслуживать пациентов в больницах на окраинах или в регионах, пользуясь консультациями более квалифицированных специалистов из центра.
Стоит отметить, что разделения отраслей в данном перечне весьма условно. Множество задач решаются на стыке, к примеру, анализа ресурсов и логистики. Хороший пример такого проекта — интеллектуальный сбор мусора в Dubai Silicon Oasis (свободной экономической зоне в Dubai, где активно внедряются технологии умных городов).
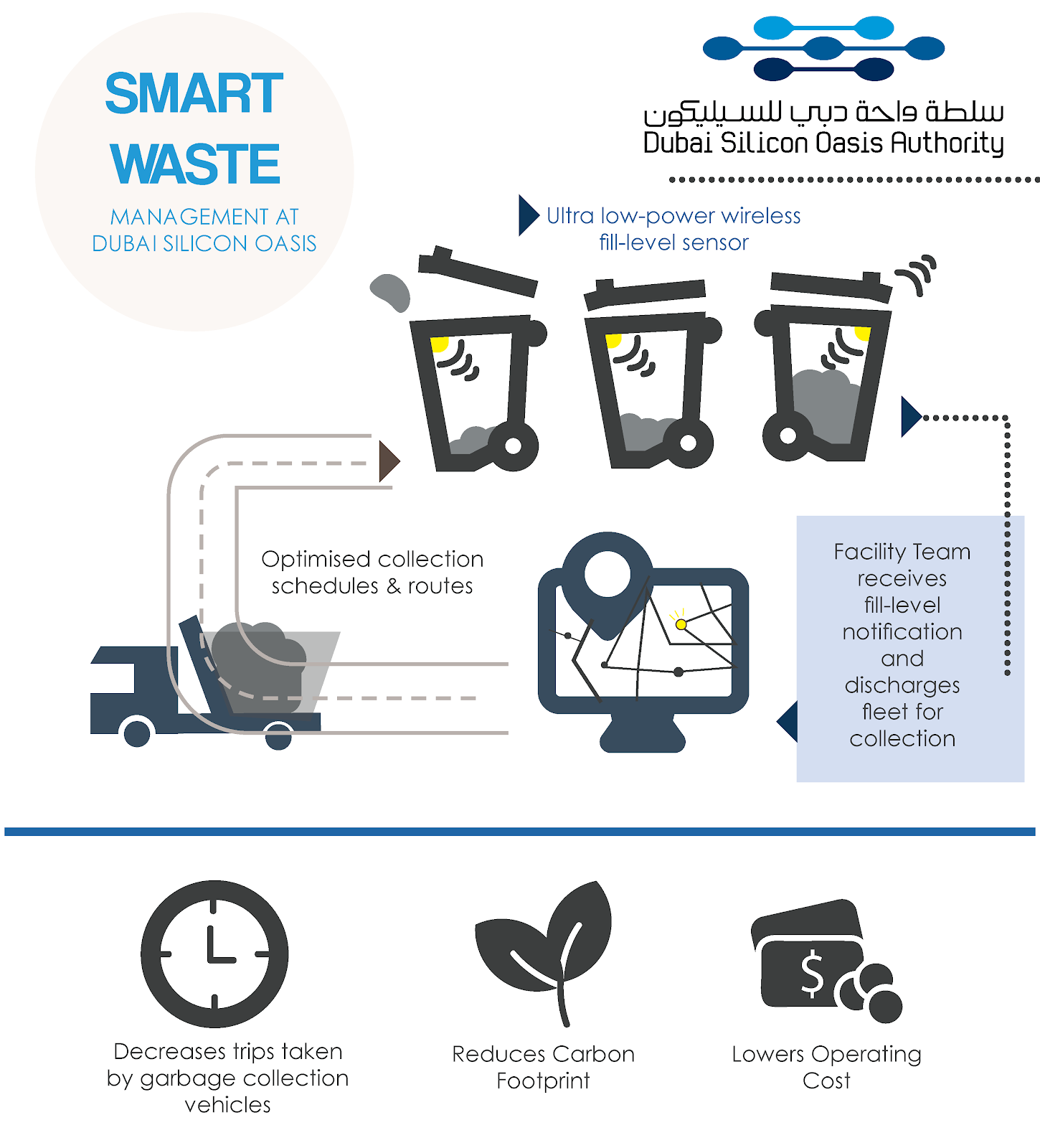
Маршруты автомобилей, вывозящих мусор, планируются не по расписанию, а с учетом показаний датчиков заполненности мусорных контейнеров, поступающих в координационный центр режиме реального времени.
Кроме того, есть идеи, собирающие в себе решения сразу из нескольких сфер. К примеру, умные офисные здания, являющиеся частью умного города. Smart building внедряет учет и интеллектуальное управление потреблением основных ресурсов на своем уровне, что в конечном счете влияет и на эффективность «работы» систем всего города.
Проблемы внедрения
С точки зрения бизнеса для развития реальных проектов в рамках концепции умного города существует несколько серьезных барьеров, над устранением которых еще предстоит работать.
Барьер 1: неясная экономика
Отдельные компоненты умного города развиваются в разных городах уже давно. Однако проработанных бизнес-моделей, которые успели доказать свою эффективность именно для бизнеса, пока не так много.
Основной камень преткновения — сроки окупаемости проектов. Бизнесу нужны рыночные стратегии, которые дадут прибыль в ближайшие пять лет (в России с учетом экономической ситуации — в течение трех лет), а умный город — это инвестиции в более отдаленные перспективы. И нестыковка бизнес-кейсов — серьезный тормоз развития умного города; это один из основных факторов, из-за которых smart city развиваются пока не так активно, как могли бы.
Пока подавляющее большинство проектов в мире включает в качестве обязательного компонента бюджетные деньги (а значит, некую национальную задачу), то есть речь идет о стратегическом развитии инфраструктуры.
К примеру, в Чехии построили умное освещение вдоль дорог. Проект был инициирован бизнесом и окупился. Но одной из его основных составляющих была замена ламп освещения. А такие задачи, как правило, выполняются муниципалитетами на собственные средства.
Барьер 2: сложности с тиражированием
Казалось бы, бизнес-модель можно построить на опыте коллег из других городов, благо примеров, вроде упомянутой выше Чехии, множество. Но сложность в том, что они плохо тиражируются. Аналог чешского проекта в России, скорее всего не окупится, поскольку у нас совершенно иные условия по электроснабжению, цены на электричество и масштабы дорожной сети.
Кстати, в России стоимость основных ресурсов относительно других стран мира сравнительно низкая, что выливается в несколько иную экономику проектов сбережения. Отчасти поэтому концепция умного города у нас начинается с другой стороны — с безопасности. Да, Санкт-Петербург и Москва, в определенной степени, уже оснащены камерами видеонаблюдения. Но в других городах-миллионниках и, тем более в регионах, ситуация с ними много хуже.
Поэтому первая задача — повысить уровень безопасности в городах, очевидно, через внедрение систем видеофиксации и видеоаналитики, которые позволяют в автоматическом режиме отсекать большую долю уличных преступлений. В наших реалиях это наиболее понятный кейс: ясно, как этим пользоваться и зачем это нужно, проще обосновать затраты.
В целом для проекта умного города крайне важна местная специфика, ведь в каждом городе мира люди думают по-разному, у них разные потребности и проблемы.
Барьер 3: информационная безопасность
Отдельного упоминания требует вопрос безопасности самой системы умного города. Ведь каждый умный датчик или устройство может стать точкой входа для злоумышленников. ПО датчика может быть модифицировано так, что при наличии «дыр» в системе безопасности он будет выполнять совсем иные задачи. Как пример можно привести взлом камер видеонаблюдения, которые затем используются для осуществления мощных DDoS-атак. Однако пока количество подобных случаев не набрало достаточной «критической массы», чтобы общественность всерьез забеспокоилась на эту тему.
Важно, что в разрезе умного города безопасность систем приобретает совершенно иной смысл. Здесь недостаточно контролировать конечный набор точек — их слишком много. Да, производители уже встраивают в устройства функции, связанные с шифрованием, защитой от несанкционированного доступа и т.п. Но тут нужен принципиально иной подход. И всеобъемлющей концепции, которая объединила бы эти разрозненные компоненты, на текущий момент нет. Все, что сейчас реализуется, — это попытки внедрения существующих методов обеспечения информационной безопасности для решения принципиально новой задачи. И это далеко не самый лучший подход.
Барьер 4: legacy
Как правило, проекты умного города развиваются в рамках модернизации городских систем, и глубина ее зависит от имеющейся инфраструктуры и текущих потребностей. Иногда такие проекты включают в себя строительство новых сегментов с нуля, однако необходимость поддержки оставшейся устаревшей инфраструктуры почти всегда осложняет ситуацию.
Как и в любом крупном IT-проекте, при построении умного города приходится сталкиваться с инфраструктурой, которая еще не успела выработать свой ресурс (т.е. прямого резона в ее замене нет). И это не только технологические устаревшие городские системы, не предполагающие установку датчиков и автоматики. Свою лепту добавляет внедренная ранее «умная» инфраструктура, которая теперь не интегрируется в комплексные системы или ее интеграция оказывается чересчур затратной.
Концепция Huawei
Построение умного города — это масштабный IT-проект. Как любому IT-проекту, ему нужна общая концепция, включающая описание инфраструктуры на различных уровнях, от конечных устройств (датчиков) до центра системы — платформы сбора и анализа данных, а также пользовательских приложений, обеспечивающих взаимодействие с умным городом.
Если представить весь проект умного города в виде пирамиды, где базовый уровень — это конечные устройства (датчики), а верхний — пользовательские приложения, то мы, как инфраструктурная компания, обеспечиваем функционирование всей середины этой пирамиды. Иными словами, наши решения для умного города включают различные типы сетей, платформу агрегации и обработки данных, различные типы систем хранения.
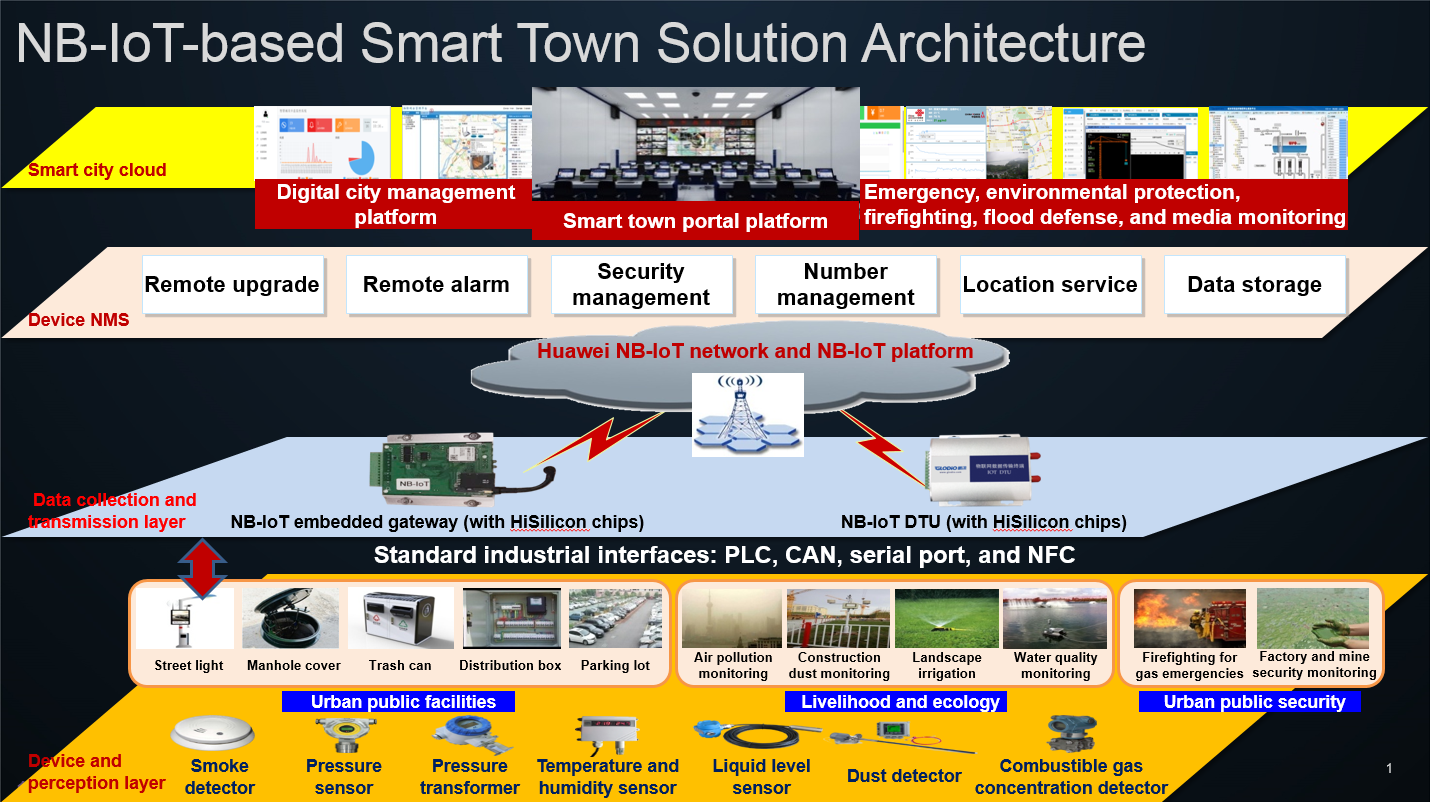
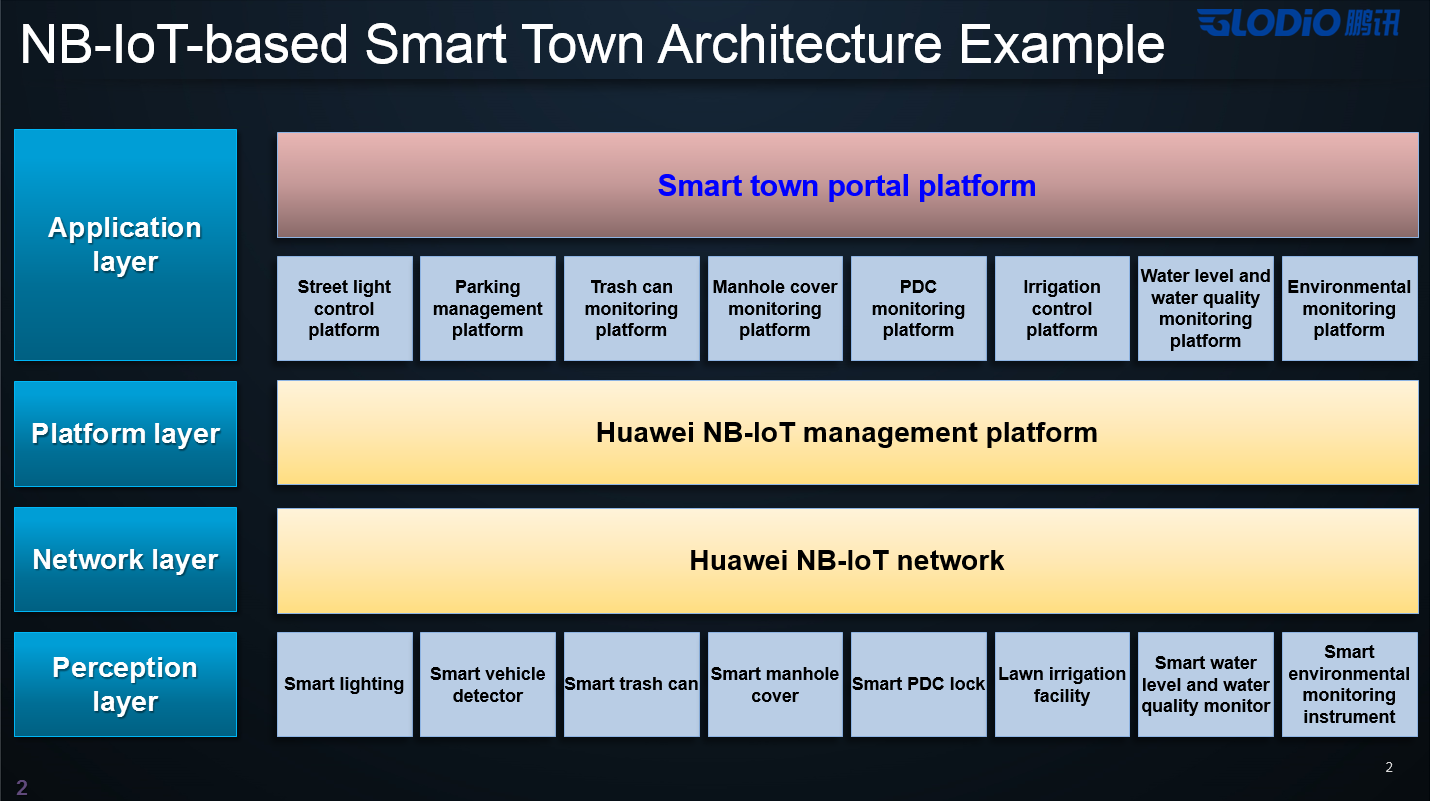
Каждый уровень обладает определенной степенью гибкости, что позволяет снизить один из упомянутых барьеров — например, проблемы с наследованием еще не выработавших свой ресурс систем.
В теории решение, аналогичное умному городу Huawei, можно построить и на базе открытых или сторонних компонентов. Но тут придется уделить дополнительное внимание вопросу трудозатрат (стоимости), а также последующей поддержке решения. Ведь разработанную инфраструктуру необходимо не только развернуть, но и превратить в работающий инструмент. По опыту других отраслей, где внедряются крупные IT-решения, opensource-проекты живут ровно до того момента, пока не придут серьезные промышленные конкуренты.
Платформа агрегации и анализа данных
Сердцем системы является mediation-платформа агрегации и обработки данных OceanConnect, обеспечивающая работу с миллионами конечных устройств.
В ее задачи входит сбор показаний с большого количества конечных устройств, их анализ и хранение в распределенном хранилище на базе Hadoop.
Платформа может быть развернута в рамках облачного сервиса или на локальной инфраструктуре на разном типе железа. Естественно, у нас есть свое серверное оборудование для подобных систем, но в принципе ее можно развернуть на любом подходящем аппаратном обеспечении.
Сетевая инфраструктура
Инфраструктура Huawei поддерживает целый спектр общепризнанных стандартов связи и протоколов взаимодействия с датчиками. В частности, для большинства современных IT-протоколов в ней предусмотрены коннекторы. В общей сложности интегрировано уже более 170 интерфейсов, а открытый SDK позволяет при необходимости добавлять новые.
Аппаратная составляющая решения подбирается под конкретный проект, у самой Huawei предусмотрен целый класс собственных DCP-решений (развитие Huawei AR с интегрированными стандартами и протоколами IoT), но могут использоваться и сторонние продукты.
Конечные устройства
Для всевозможных датчиков, терминалов и контроллеров мы предлагаем свой чипсет и коммуникационный модуль, а также ОС LiteOS, созданную на базе Linux и ориентированную на IoT. Конечную сборку, производство корпуса и подготовку схемы электропитания, а также разработку ПО на базе официального SDK мы оставляем локальным партнерам.
Конечные приложения
Со стороны приложений у OceanConnect есть открытый API взаимодействия с внешними системами.
Мы изначально не выходим на рынок приложений, придерживаясь мнения, что глобальному производителю бессмысленно соревноваться с местными игроками в понимании той самой местной специфики, которая так важна в популяризации идеи умного города. Локальный бизнес справится лучше и быстрее адаптирует под эти требования свои системы. Поэтому в этой части Huawei стремится сотрудничать с локальными партнерами. Так снимается еще один барьер — учет локальными партнерами.
Взгляд в будущее
Умным городам предрекают большое будущее. Однако когда оно наступит, пока не ясно. Технологически для этого все готово: есть инструменты анализа Big Data, соответствующее серверное оборудование, датчики, способные работать по десять лет без подзарядки аккумулятора, и соответствующие стандарты связи. Но этому рынку очень не хватает технологической стабильности — окончательного выбора доминирующих стандартов и формирования бизнес-моделей, когда станет понятно, как здесь можно работать и зарабатывать.
Подобный процесс мы наблюдали пару десятилетий назад на рынке сотовой связи. Тогда было множество стандартов, помимо GSM, но сейчас они все либо ушли, либо занимают определенные несущественные ниши. На массовом рынке GSM одержал безоговорочную победу. Аналогичный процесс ожидает и сектор интернета вещей. Рано или поздно все придет к одному или нескольким общим стандартам и станет понятна бизнес-модель, по которой будет работать рынок.
Как мы уже писали, чтобы бизнес заинтересовался умным городом, он должен понимать финансовые перспективы. Пока же рынок не устоялся, и многие не хотят быть первыми — поскольку именно первопроходцам обычно достается не только основная прибыль, но и масса нерешенных проблем (и еще не факт, что прибыль в итоге покроет поиск решений). Однако отложить этот проект вовсе не позволяет еще один фактор — прогрессирующий рост урбанизации во всем мире. Города становятся не только центрами экономической и культурной, но и основными источниками ВВП.
Рост городских агломераций и связанные с ним проблемы перенаселения вынуждают заказчиков по всему миру пробовать различные высокотехнологичные решения. И в ответ на этот пока еще невысокий спрос вендоры активно продвигают свои видения концепции умных городов, чем активно заняты и мы.
Let's block ads! (Why?)









 Доклад посвящен проблемам приложения с несколькими разными темами: как их решали раньше, к чему это привело и как удалось всё привести в порядок с помощью автоматической генерации тем.
Доклад посвящен проблемам приложения с несколькими разными темами: как их решали раньше, к чему это привело и как удалось всё привести в порядок с помощью автоматической генерации тем.
 На примерах рабочих сценариев Дмитрий покажет, когда стоит использовать DI, и рассмотрит стандарт JSR-330. Также Дмитрий расскажет о популярных библиотеках для реализации DI и используемых в них подходах, их плюсах, минусах и киллер-фичах.
На примерах рабочих сценариев Дмитрий покажет, когда стоит использовать DI, и рассмотрит стандарт JSR-330. Также Дмитрий расскажет о популярных библиотеках для реализации DI и используемых в них подходах, их плюсах, минусах и киллер-фичах.
 Иван расскажет про модуляризацию Android-приложения Avito: какие цели ставились разработчиками, с какими трудностями столкнулись и каких результатов достигли.
Иван расскажет про модуляризацию Android-приложения Avito: какие цели ставились разработчиками, с какими трудностями столкнулись и каких результатов достигли.