Вы когда-нибудь задумывались как устроен ID видео на YouTube?
Возможно, вы уже знаете/нашли ответ, но, как показали обсуждения на Stack Overflow, многие понимают эту технологию неправильно. Если вам интересно изучить что-то новое, добро пожаловать под кат.
Структура ID
Для начала, вспомним что из себя представляет ID видео на YouTube.
ID имеет длину 11 знаков (раньше был длинною 9 знаков).
Состоит из:
- Латинских букв верхнего регистра
[A-Z]— 26 знаков; - Латинских букв нижнего регистра
[a-z]— 26 знаков; - Цифр
[0-9]— 10 знаков; - Тире и нижнее подчеркивание
[-_]— 2 знака.
Итого 64 знака.
Возможно, вы уже заметили сходство с известным многим Base64 (RFC 2045 раздел 6.8) и это неспроста. Только в стандарте Base64 используются в качестве дополнительных символов плюс и слеш [+/], а не тире и нижнее подчеркивание. Плюс и слеш зарезервированы для использования в URL, и чтобы не было проблем с использование ID в URL, YouTube заменили их более безопасными. Но вы можете использовать свои символы, об этом чуть позже.
Зачем это нужно
Как это ни странно, но большинство пользователей и разработчиков ошибочно полагают, что такие ID нужны для защиты от грабберов, которые перебором ID могут скачать весь контент сайта.
Поэтому многие всерьез рассматривают такие ID как систему защиты и придумывают сложные алгоритмы хеширования своих инкрементных числовых идентификаторов, пишут библиотеки и продвигают их.
Тем не менее, хочу вас удивить, это не хешированное число, а просто строка. И даже не инкрементная строка, а случайно генерируемое значение по аналогии с UUID, только заметно компактней.
Это может быть сложно понять тем, кто всегда работал с инкрементными идентификаторами и полагался в этом на БД. У генерируемого идентификатора есть своё назначение, свои преимущества и недостатки перед инкрементным идентификатором.
Генерируемый идентификатор в распределенных системах
Впервые мы сталкиваемся с генерируемым идентификатором в распределенных системах.
Проблема инкрементных идентификаторов в том, что их создаёт БД. Для сохранения консистентности данных нам необходима одна master БД, которая будет генерировать их. Это повышает нагрузку на нее и затрудняет шардинг.
Некоторые решают эту проблему созданием отдельной БД или сервиса, который занимается исключительно генерацией ID. Но все усложняется, когда нам необходимо разнести сервера географически, подключить регионы.
Решение — вести локальный ID и, при периодической синхронизации с главным сервером, получать от него сквозной ID для всей системы. То есть на региональных серверах у нас будет 2 ID — локальный и сквозной.
Для решения подобных проблем и были придуманы генерируемые идентификаторы такие как UUID. За счёт большого количества комбинаций, мы добиваемся очень маленькой вероятности конфликта идентификаторов. Поэтому, мы можем доверить генерацию глобального ID конкретным инстансам приложения.
DDD и идентификаторы
Понятие Domain-driven design (DDD) хорошо описано в книгах Эрика Эванса и Вон Вернона. Общая идея DDD сводится к акцентированию внимания на нашей предметной области, стремление к проектированию систем максимально приближенных к реальному миру. Здесь же я хочу рассказать о роли идентификаторов в DDD.
В понятиях DDD подхода нельзя создавать сущности без идентификатора. Инициализируя новый инстанс сущности, идентификатор в ней уже должен быть. То есть, идентификатор создаваемой сущности должен передаваться ей в конструкторе или передаваться ей сервис доменного уровня для получения идентификатора или это должен быть естественный идентификатор формируемый самой сущностью.
Необходимость наличия идентификатора может возникнуть если мы захотим бросить доменное событие при создании сущности. Если в событии не будет идентификатора, то у слушателей могут возникнуть проблемы с идентификацией сущности.
В тоже время, в БД используется инкрементный ключ на вставку. Пока мы не запишем данные в БД, мы не сможем получить идентификатор для сущности. Нестыковка получается. Мы не можем создать сущность потому, что у нас нет ID, и мы не можем получить ID из БД потому, что для этого нужно записать сущность в БД.
Есть разные способы решения этой проблемы. Один из них — это случайно генерируемый идентификатор, о котором мы сейчас и говорим.
Недостатки
У генерируемых идентификаторов есть и недостатки. Куда же без них.
Очевидными недостатками являются время генерации идентификатора и вероятность коллизии/конфликта идентификаторов. О вероятности конфликта мы и поговорим в следующем разделе.
Вероятность коллизии ID
Давайте вспомним курс комбинаторики и прикинем количество комбинаций. Нам потребуется формула Размещение с повторениями.
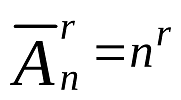
UUID
Для UUID количество комбинаций известно, но мы всё же рассчитаем их для сравнения.
UUID имеет вид 550e8400-e29b-41d4-a716-446655440000, имеет длину 33 символа за вычетом разделителей (-) и состоит из шестнадцатеричных цифр. Что нам дает 1633 или 2132 комбинаций. Это очень много.
На самом деле комбинаций там меньше, а точнее 2128, так как есть некоторые ограничения (смотри RFC 4122 или пример на PHP).
У UUID много хорошего и многие им успешно пользуются. Лично мне он не нравится тем, что он ну очень длинный, занимает много места в БД и его затруднительно использовать в URL, хотя некоторых это не смущает.
YouTube ID
А теперь сравним UUID и YouTube видео ID и высчитаем количество комбинаций.
Как мы уже выяснили ранее, ID у YouTube видео состоит из 64 знаков и имеет длину 11 знаков, что нам дает 6411 или 266. Эта цифра конечно заметно меньше чем UUID, но я все равно считаю, что она достаточно большая:
73 786 976 294 838 206 464
Чтобы хоть как-то осознать это число, представьте, что для получения всех возможных значений идентификаторов длиной 11 символов и создавая идентификатор каждую наносекунду, вам потребуется 2 339 лет.
А для того, чтобы получить такое же количество комбинаций как у UUID нам потребуется 2128 = 6421 строка длинною 21 символов, то есть почти в 2 раз короче UUID (37 символов). А если мы возьмём идентификатор такой же длинны как у UUID, то мы получим 6437 = 2222 против 2128 у UUID.
Самое главное преимущество такого подхода в том, что мы сами управляем количеством комбинаций путем изменения длинны строки.
Не сложно догадаться, что можно сделать идентификатор еще более компактным взяв большее множество знаков. Например, взяв множество из 128 знаков и тогда, идентификатор длинной 18 знаков даст нам 12818 = 2126 комбинаций, что сравнимо с UUID. Но это экономит нам всего несколько символов, а проблем добавляет целую кучу. Увеличивая количество используемых знаков мы сталкиваемся с проблемой использования зарезервированных знаков или с проблемой расхождения кодировки знаков. Поэтому я рекомендую ограничится 64 знаками и играться только с длиной идентификатора.
Для расчета вероятности коллизии воспользуемся формулой из статьи про UUID на Википедии.

она же

Где
N — количество возможных вариантов.
n — число сгенерированных ключей.
Возьмем идентификатор длинною 11 знаков, как у YouTube, что даст нам N = 6411 = 266 и соответственно мы получим:
p(225) ≈ 7.62*10-6
p(230) ≈ 0.0077
p(236) ≈ 0.9999
Это даёт нам гарантию, что первые несколько миллионов идентификаторов будут уникальными. Не самый плохой результат для столь короткого идентификатора.
Генерация ID
И наконец-то код. Генерируется ID элементарно.
class Base64UID
{
private const CHARS = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ_-';
public static function generate(int $length): string
{
$uid = '';
while ($length-- > 0) {
$uid .= self::CHARS[random_int(0, 63)];
}
return $uid;
}
}
Использование:
$uid = Base64UID::generate(11); // iKtwBpOH2Ew
DDD
А теперь прикинем как это может использоваться в вашей предметной области при использовании DDD подхода. Допустим, мы хотим использовать наш новый ID в сущности Статья. Для начала создадим ValueObject для идентификатора статьи, чтобы однозначно идентифицировать принадлежность идентификатора к статье.
class ArticleId
{
private $id;
public function __construct(string $id)
{
$this->id = $id;
}
public function id(): string
{
return $this->id;
}
public function __toString(): string
{
return $this->id;
}
}
Теперь создадим интерфейс сервиса предметной области для получения ID. Сервис нам нужен для инкапсуляции генерации ID и подмены при необходимости.
interface ArticleIdGenerator
{
public function nextIdentity(): ArticleId
}
Создадим имплементацию конкретного сервиса генератора ID статьи, использующий наш новый генератор случайных идентификаторов.
class Base64ArticleIdGenerator implements ArticleIdGenerator
{
public function nextIdentity(): ArticleId
{
return new ArticleId(Base64UID::generate(11));
}
}
Теперь мы можем создать сущность Статьи с идентификатором.
class Article
{
private $id;
public function __construct(ArticleIdGenerator $generator)
{
$this->id = $generator->nextIdentity();
}
public function id(): ArticleId
{
return $this->id;
}
}
Пример использования:
$generator = new Base64ArticleIdGenerator();
$article = new Article($generator);
echo $article->id(); // iKtwBpOH2Ew
Заключение
Вот таким простым способом мы получили управляемый генерируемый идентификатор с высокой степенью уникальности. Использовать ли генерируемые идентификаторы в своих проектах, решать вам, но их плюсы очевидны.
А вы используете генерируемые идентификаторы? Расскажите в комментариях.
PS: Для тех кому лень писать свое, есть готовая библиотека под PHP 5.3+
PSS: Для расчетов могу порекомендовать этот онлайн калькулятор.
Комментариев нет:
Отправить комментарий