Стандартные решения проблемы: докинуть серверов, все переписать с 0, оптимизировать уже написанное.
Давайте попробуем пойти путем оптимизации и разобраться, как можно найти и улучшить слабые места приложения. А быть может ускориться не трогая ни строчки кода :)
Всех заинтересованных добро пожаловать под кат!
Для начала определимся с методикой тестирования производительности.
Нас будет интересовать количество обслуженных запросов за 1 секунду: rps.
Запускать будем приложение в режиме 1 воркера (1 процесса), замеряя производительность старого кода и кода с оптимизациями — абсолютная производительность не важна, важна сравнительная производительность.
В типичном приложении с множествами разных роутов логично сначала найти самые загруженные запросы, на обработку которых тратится большая часть времени. Утилы вида request-log-analizer или множество подобных позволят извлечь эту информацию из логов.
С другой стороны, можно взять реальный список запросов и пулять их все (например с помощью yandex-tank-а) — получим достоверный профиль нагрузки.
Но делая множество итераций оптимизации кода, куда удобнее использовать более простой и быстрый инструмент и один конкретный тип запросов (а после оптимизации одного запроса изучать следующий, и т.д.). Мой выбор — wrk. Тем более что в моем случае количество роутов не велико — проверить все по одному не сложно.
Сразу надо оговорится, что в плане блокирующих запросов, ожидания БД и т.п. приложение уже оптимизировано, все упирается в cpu: при тестах воркер потребляет 100% cpu.
На продашен серверах используется node.js версии 6 — с неё и начнем:
Requests/sec: 1210
Пробуем на 8й ноде:
Requests/sec: 2308
10я нода:
Requests/sec: 2590
Разница очевидна. Ключевую роль тут играет обновление версии v8 — множество плохо оптимизирующегося v8 кода осталось в прошлом. И чтобы не бороться с ветряными мельницами исчезнувшими в node.js v8 — лучше сразу обновиться, а потом уже заниматься оптимизацией кода.
Переходим собственно к поиску узких мест: на мой взгляд, лучший инструмент для этого — flamegraph. И с появлением проекта 0x получить flamegraph стало очень просто — запускам 0x вместо node: 0x -o ваш_скрип.js, делаем тест, останавливаем скрипт, смотрим результат в браузере.
Примерно так выглядит flamegraph тестируемого кода до оптимизаций:
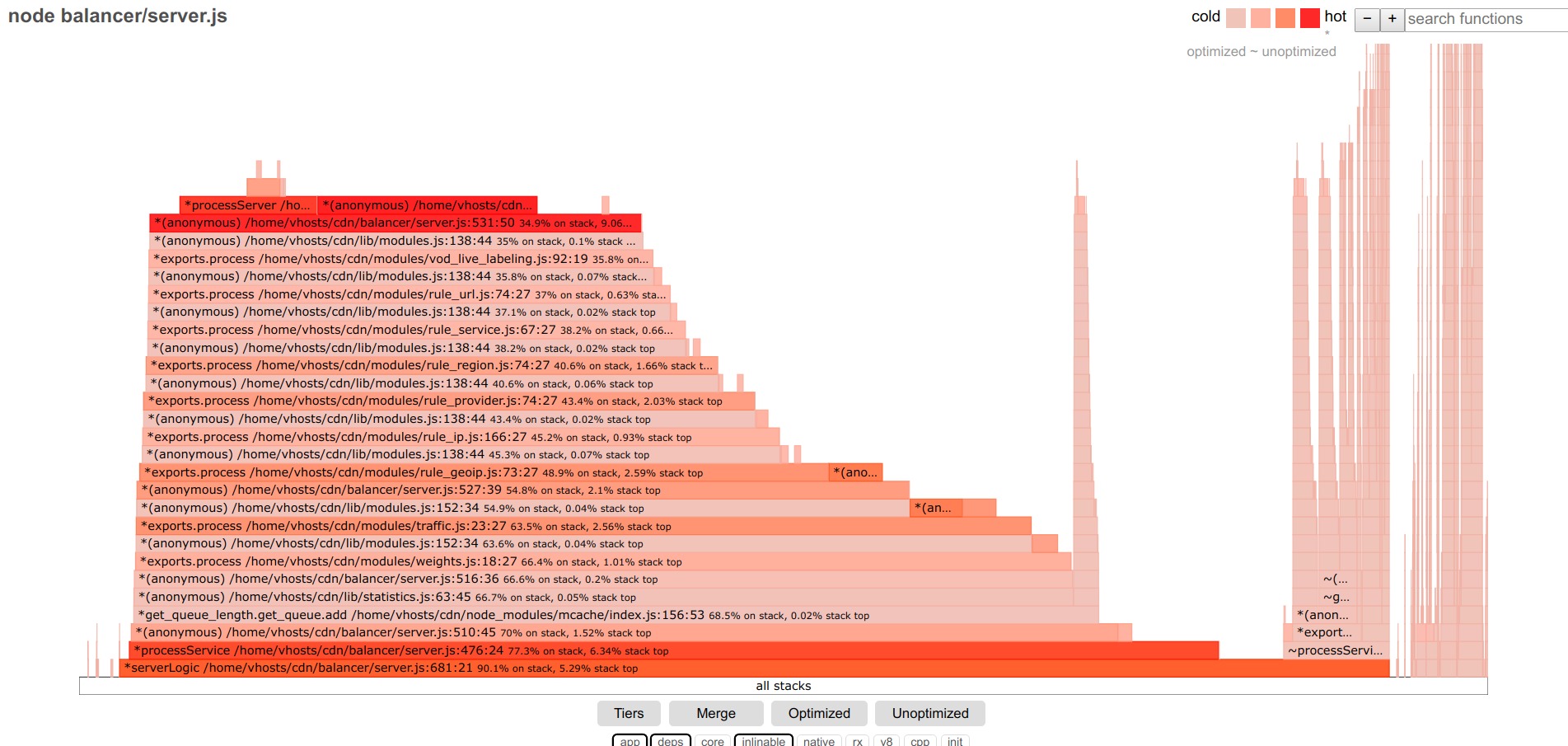
Внизу фильтры, оставляем app, deps — только код приложения и сторонних модулей.
Чем шире полоска — тем больше времени потрачено на выполнения этой функции (включая вложенные вызовы).
Разбираться будем с центральной, самой большой частью.
В первую очередь подсвечиваем неоптимизированные функции. У меня в приложении таких нашлось немного.
Далее, верхние функции — типичные кандидаты на оптимизацию. Остальные же функции выстроились горкой с относительно равномерными ступеньками — каждая функция вкладывает небольшую долю задержек, явного лидера нет.
Дальше возможен простой алгогритм действий: оптимизировать самые широкие функции, переходя от одной к другой. Но я выбрал другой подход: оптимизировать начиная от точки входа в приложения (обработчик запроса в http.createServer). В конце исследуемой функции вместо вызова следующих функций я завершаю обработку запроса, отвечая ответом-пустышкой, и изучаю производительность именно этой функции. После её оптимизации ответ-пустышка перемещается дальше по стеку вызовов к следующей функции и т.д.
Удобное следствие такого подхода: можно видеть rps в идеальных условиях (при работающей только одной стартовой функцией rps близок к максимальному rps-у hellow world node.js приложения), и при дальнейшем перемещении заглушки-ответа вглубь приложения наблюдать вклад исследуемой функции в падение производительности в rps-ах.
Итак, оставляем только стартовую функцию, получаем:
Requests/sec: 16176
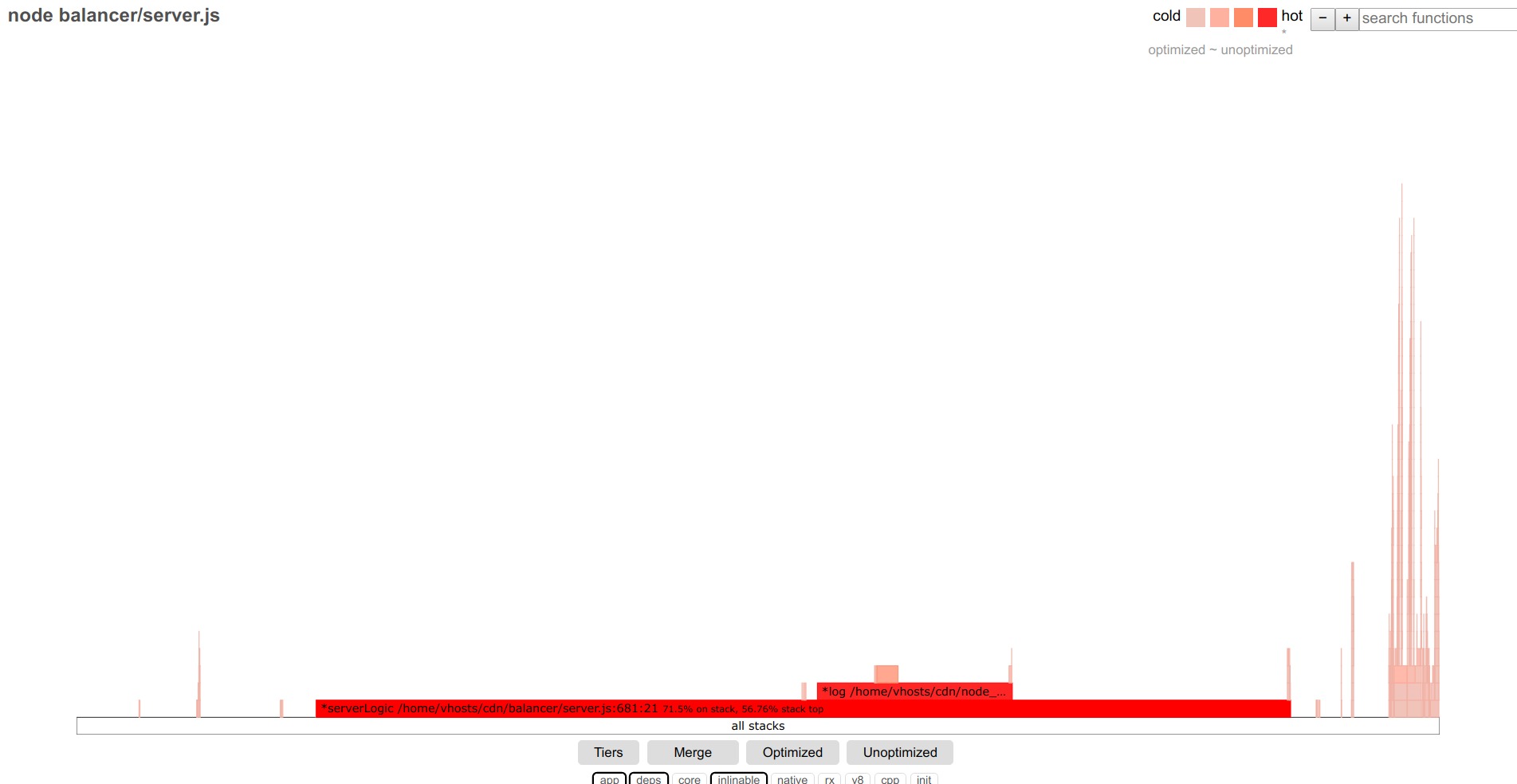
Подключая фильтры core, v8 можно увидеть, что практически вся исследуемая функция состоит из отправки ответа, логгирования и других слабо оптимизируемых вещей — едем дальше.
Переходим к следующей функции:
Requests/sec: 16111
Ничего не изменилось — погружаемся дальше:
Requests/sec: 13330
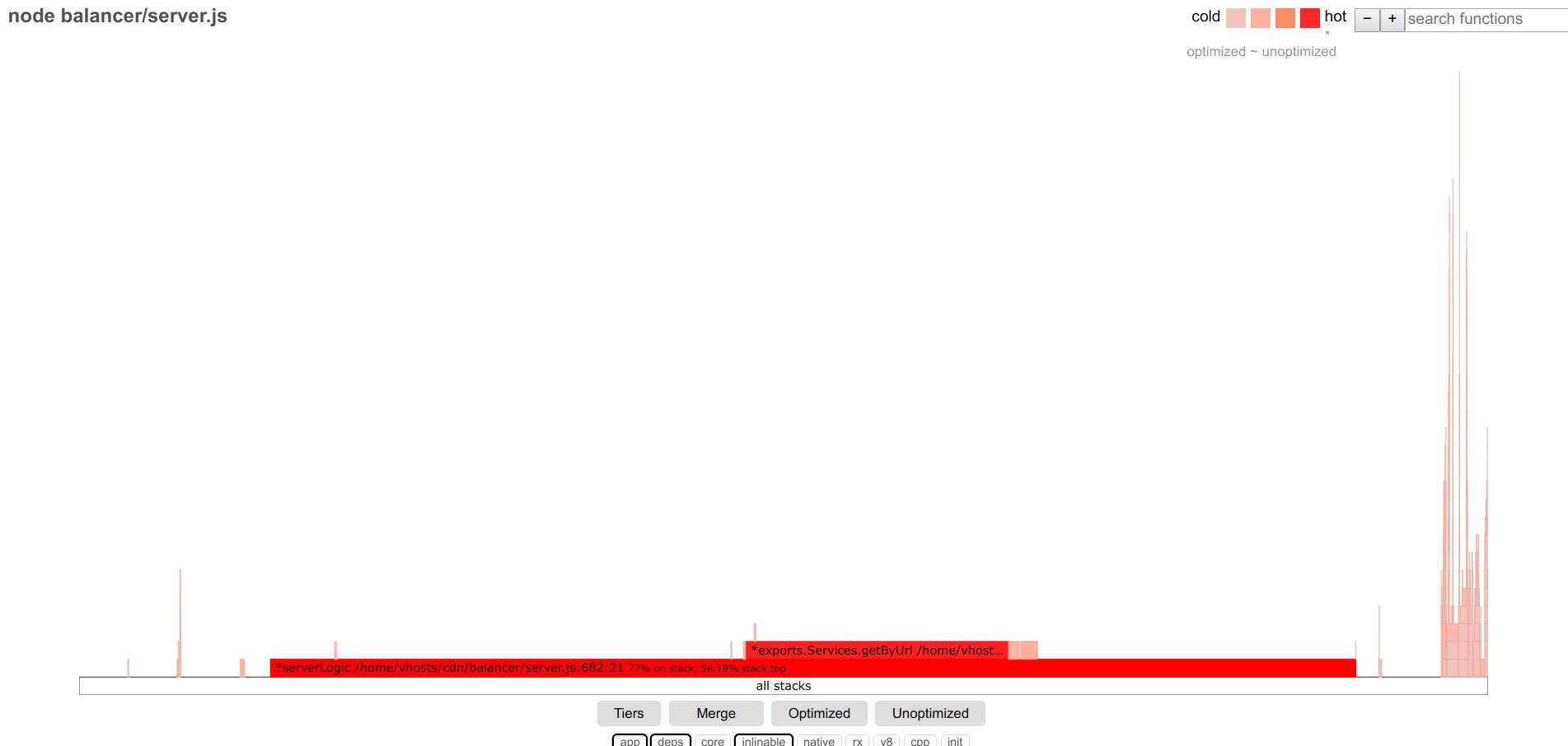
Наш клиент! Видно что задействованная функция getByUrl занимает значимую часть стартовой функции — что хорошо коррелирует с проседанием rps.
Смотрим внимательно что в ней происходит (включаем core, v8):
много чего происходит… курим код, оптимизируем:
for (var i in this.data) {
if (this[i]._options.regexp_obj.test(url)) return this[i];
}
return null;
превращаем в
let result = null;
for (let i=0; i<this.length && !result; i++) {
if (this[i]._options.regexp_obj.test(url)) result = this[i];
}
И получаем
Requests/sec: 16015

Визуально функция «сдулась» и занимает значительно меньшую долю от стартовой функции.
В детальной информации по функции так же все значительно упростилось:
Идем дальше, к следующей функции
Requests/sec: 13316

В этой функции много array функций и, несмотря на существенное ускорение в последних версиях node.js, они все еще медленней простых циклов: меняем [].map и filter. на обычный for и получаем
Requests/sec: 15067
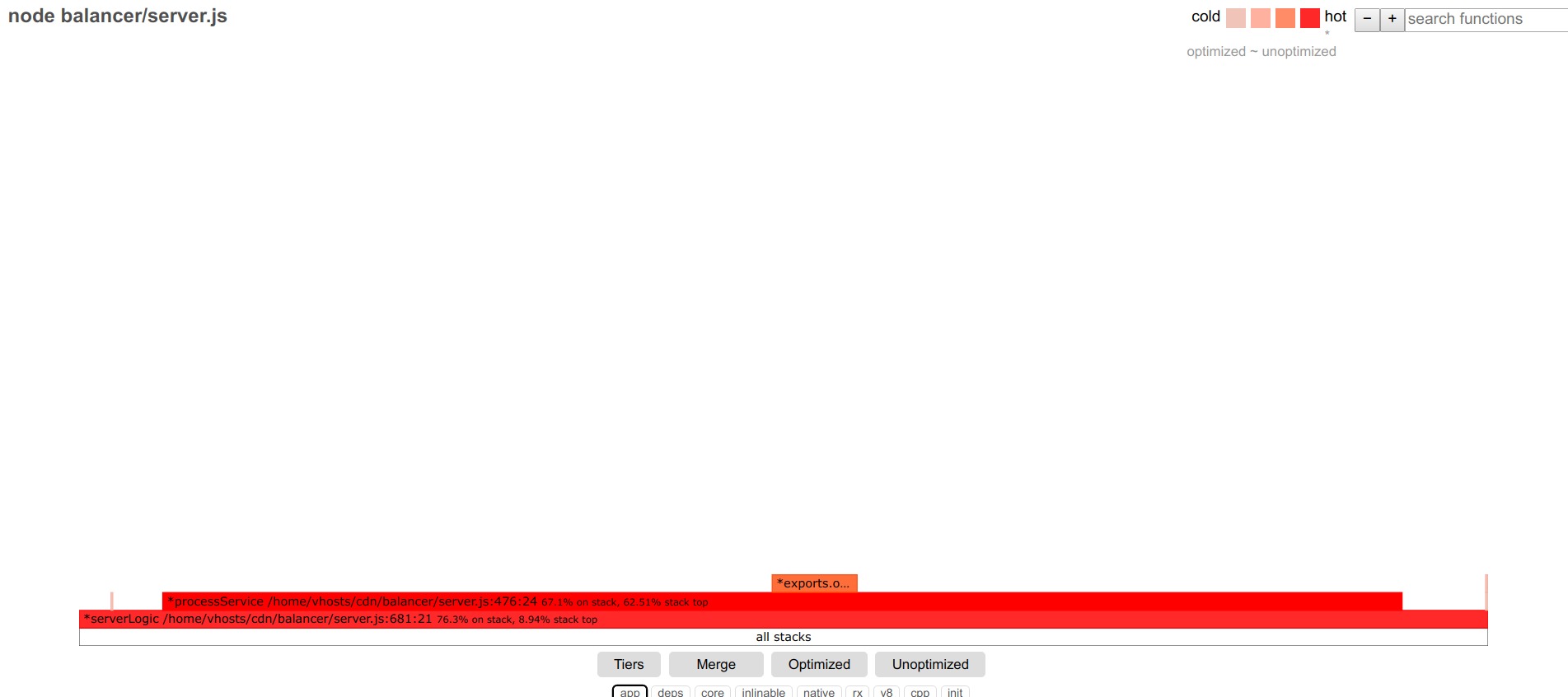
И так раз за разом, для каждой следующей функции.
Еще несколько пригодившихся оптимизаций: для хешей с динамически изменяемым набором ключей new Map() может быть на 40% быстрее обычного {};
Math.round(el*100)/100 в 2 раза быстрее чем toFixed(2).
В flamegraph-е для core и v8 функций можно увидеть как и малопонятные записи, так и вполне говорящие StringPrototypeSplit или v8::internal::Runtime_StringToNumber, и, если это значимая часть выполнения кода, попытаться оптимизировать, например просто переписать код, не выполняющий эти операции.
Например, замена split на несколько вызовов indexOf и substring может давать двойной выигрыш в производительности.
Отдельная большая и сложная тема — jit оптимизация, а вернее деоптимизированные функции.
При наличии большой доли таких функций надо будет разбираться и с ними.
Тут может помочь вдумчивое изучение вывода node --trace_file_names --trace_opt_verbose --trace-deopt --trace_opt
Например, строчки вида
deoptimizing (DEOPT soft): begin 0x2bcf38b2d079 <JSFunction getTime… Insufficient type feedback for binary operation привели к строчке
return val >= 10? val: '0'+val;
Замена на
return (val >= 10? '': '0')+val;
исправила ситуацию.
Для старого v8 движка есть достаточно много информации по причинам и способах борьбы с деоптимизацией функций:
github.com/P0lip/v8-deoptimize-reasons — список,
www.netguru.co/blog/tracing-patterns-hinder-performance — разбор типовых причин,
www.html5rocks.com/en/tutorials/speed/v8 — про оптимизации для v8, думаю справедливо и для текущего движка v8.
Но многие из проблем уже не актуальны для нового v8.
Так или иначе, после всех оптимизаций удалось получить Requests/sec: 9971, т.е. ускорится примерно в 2 раза за счет перехода на свежую версию node.js, и еще в 4 раза за счет оптимизации кода.
Надеюсь, этот опыт будет полезен кому-нибудь еще.
Комментариев нет:
Отправить комментарий