В первой части доклада мы в общих чертах рассказали, как измеряем качество документации и эффективность ее разработки. Теперь погрузимся в детали подсчета метрик.
Рассказывает Юрий Никулин, руководитель службы разработки технической документации.
Для начала давайте определим, что такое производительность. В классическом понимании, это время на производство единицы продукции или количество продукции, произведенное в единицу времени.
Например, это количество произведенных телефонов за месяц или количество времени на производство тысячи телефонов. Возникает вопрос, как измерять интеллектуальный труд, которым занимается наш отдел.
Если применять классический подход к оценке производительности, мы можем посчитать, сколько документов, страниц или слов написано в день, неделю и месяц. Это поможет оценить потенциальное время на производство документации в будущем, но не ответит на вопрос о производительности. Ведь мы точно не заинтересованы в том, чтобы оценивать эффективность писателей по количеству написанных ими слов. Поэтому мы решили, что начинать надо с требований к метрикам, которые планировали считать.
Мы выделили несколько критериев для отбора метрик:
- Прозрачность. Подход к расчету метрик и трактовка результатов должны быть понятны не только нам, но и заказчикам.
- Доступность данных. В том числе данных за какой-нибудь прошлый период, чтобы выдвигать гипотезы и пробовать подтвердить их историческими данными.
- Возможность автоматизировать подсчет. Мы точно не хотим считать метрики руками.
В итоге мы поняли, что идеальный объект для подсчета метрик производительности — это задача в Трекере. Она отвечает всем требованиям, которые мы предъявляли к метрикам.
Источником данных для нас стал Яндекс.Трекер. Он достаточно гибкий и легко настраивается под наши задачи. Там уже есть все необходимые данные, потому что мы ежедневно пользуемся этим инструментом. А еще у Трекера есть API, значит, можно использовать эту информацию и автоматизировать процессы.
Так у нас появился план, как действовать дальше.
Настраиваем очереди и задачи
Начать нужно с выбора очередей, иерархии задач, их типов и статусов.
Об этом подробно рассказывала Катя Куненко в докладе «Инструменты для подготовки пользовательской документации». Мы же коротко расскажем об организации очередей и задач, которую используем сами.
Очереди
У нас есть три очереди, которые по сути отражают нашу целевую аудиторию.

Иерархия задач
У наших задач двухуровневая структура:
- на верхнем уровне задачи соответствуют опубликованным документам,
- на нижнем уровне задачи соответствуют работам по документу.
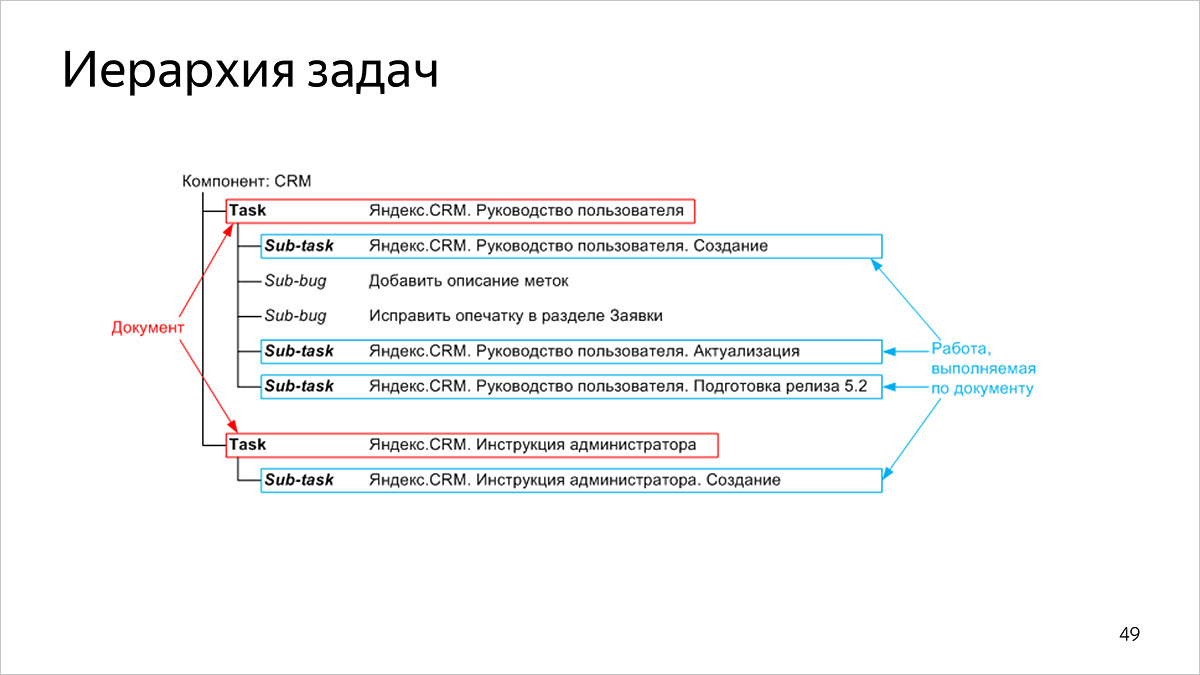
Типы и статусы задач
Типы и статусы задач не только позволяют классифицировать виды работ и их текущее состояние, но и считать наши метрики с разрезами.
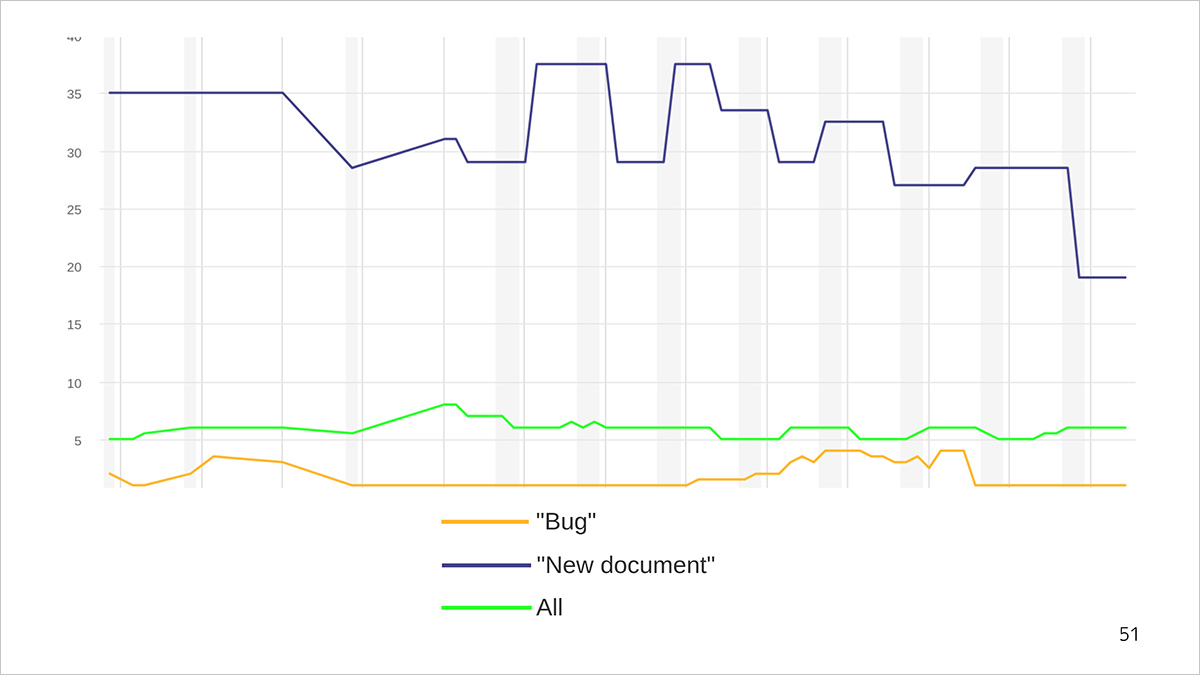
График времени выполнения задач. Синяя линия — среднее время производства документа, оранжевая — время исправления бага, зеленая — среднее время выполнения задач всех типов.
Расскажем на примере графика. Например, баг исправляют в течение 1−5 дней, а на написание нового документа уходит 30−40. При этом новые документы мы пишем реже, чем дополняем старые или исправляем ошибки. Поэтому среднее время выполнения задачи любого типа (зеленая линия) слишком большое для багов и слишком маленькое для новых документов. С его помощью мы получаем только усредненное представление о скорости решения задач.
Поскольку мы считаем метрики, чтобы оптимизировать процессы, нам нужно смотреть на более точечные срезы: например, как долго мы решаем задачу «баг» или «новый документ». А среднее по всем типам можно смотреть для отслеживания общего тренда.
Мы используем такой набор типов задач.
Статусов больше, чем типов, потому что этого требует workflow.
Работать с типами и статусами проще, если они однозначные и их не слишком много. Иначе исполнители могут запутаться.
Как считаем метрики производительности
В прошлой части мы рассказали, что провели исследование и выбрали 20 метрик документирования из 136. Метрик производительности среди них шесть.

В подсчете метрик есть два аспекта.
- Подсчет метрик по срезам. Выше мы рассказали, что это такое и почему нам это важно.
- Подсчет усредненных значений.
Классический подход подсчета усредненных значений — просуммировать все показатели и поделить на их количество. Этот подход не всегда хорошо работает, потому что он учитывает вырожденные случаи. Например, мы знаем, что большинство багов у нас исправляют за день. Но бывают вырожденные случаи — например, потерялся тикет или уволился сотрудник — тогда на исправление уходит больше времени. Предположим, за рассматриваемый период у нас было шесть багов. Пять мы решили за день, а один — за 115. Выходит, среднее исправление бага — 20 дней. Но эта цифра не отражает действительность: мы почти всегда правим ошибки за день, а один длинный тикет ощутимо влияет на этот показатель.
В таких случаях на выручку приходит перцентиль. Это максимальное значение (в нашем случае — метрики), в которое укладывается указанный процент объектов. Например, 80-й перцентиль — это значение, которое не превышает 80% объектов выборки. В нашем случае таким значением было бы значение 1, так как его не превышают 83% объектов.
Здесь появляется третья плоскость — время, за которое мы считаем метрики. Почти все наши метрики считаются за 30 дней.

Метрики с разрезами мы считаем следующим образом:
- сначала все очереди вместе,
- затем делаем срез по очередям,
- потом детализируем: делаем срез по очередям с разрезом по всем типам задач.
Каждый следующий срез метрики уточняет предыдущий. Среднее значение по всем очередям, типам и статусам задач дает обобщенное представление. Затем мы считаем значение для отдельных очередей, чтобы понимать, как обстоят дела с технической, пользовательской или внутренней документацией. На последнем, самом детальном уровне, мы прорабатываем пару «очередь + тип и статус».
Дальше мы расскажем, как считаем метрики производительности.
Количество закрытых задач

Как считаем: по количеству задач, которые закрыты в интервале [31 день назад; вчера].
Количество взятых в работу задач
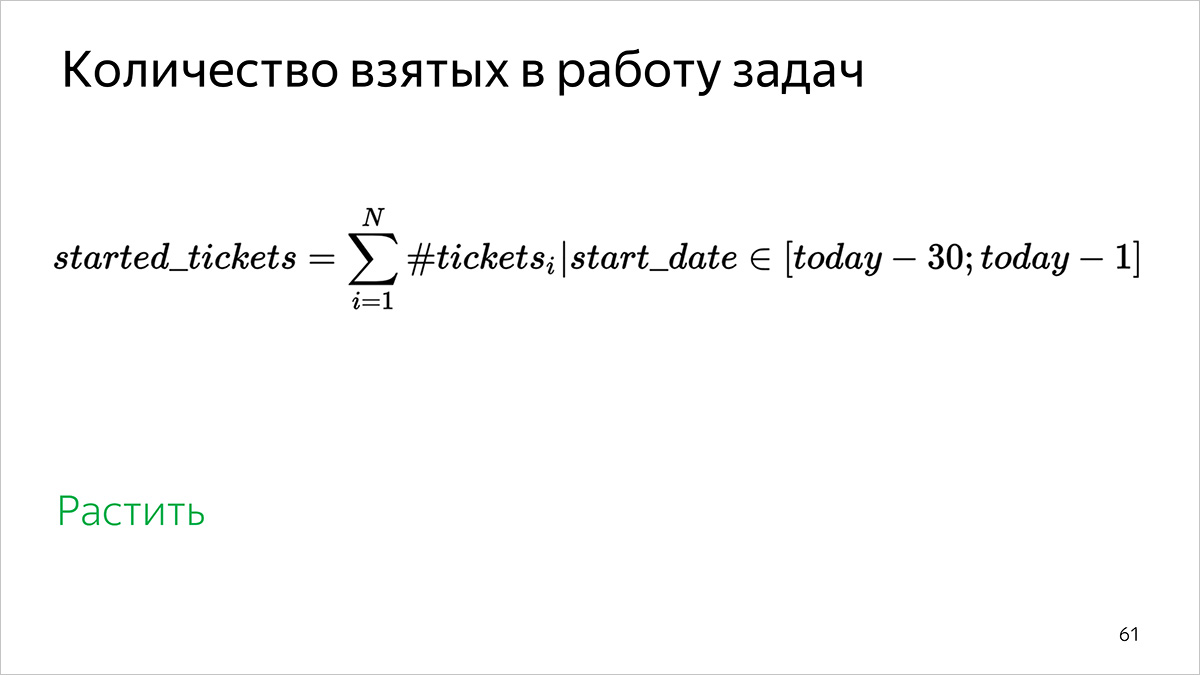
Как считаем: по количеству задач, у которых начало работы находится в интервале [31 день назад; вчера].
Количество дней до взятия в работу

Как считаем:
- Для каждой задачи, которая взята в работу в указанный период времени (start date в Трекере в интервале [31 день назад; вчера]), считаем количество полных дней, прошедших между постановкой (поле creation date) и началом выполнения задачи (поле start date).
- Суммируем все значения, полученные на первом шаге.
- Делим полученную сумму на количество задач, для которых мы делали первый пункт.
Для перцентилей пункт 3 опускается, значения сортируются в порядке возрастания и выбирается значение, которое отвечает заданному перцентилю.
Количество дней на выполнение
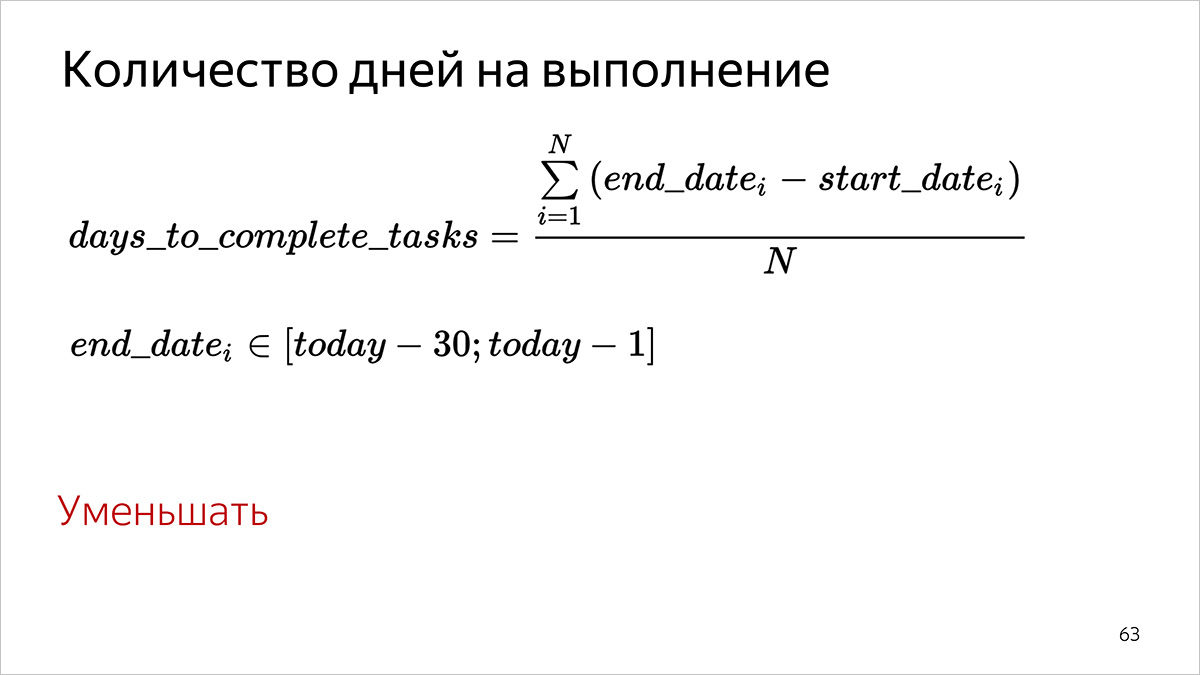
Как считаем.
- Для каждой задачи, которая завершена в указанный период времени (end date в Трекере в интервале [31 день назад; вчера]), считаем количество полных дней, прошедших между началом работы (поле start date) и выполнением задачи (поле end date).
- Суммируем все значения, полученные на первом шаге.
- Делим полученную сумму на количество задач, для которых мы делали первый пункт.
Для перцентилей пункт 3 опускается, значения сортируются в порядке возрастания и выбирается значение, которое отвечает заданному перцентилю.
Количество задач без реакции более 14 дней

Как считаем: по количеству задач, в которых ничего не происходило более 14 дней. Определяется по полю updated в Трекере: значение поля должно быть меньше, чем «вчера−14 дней».
Технический долг

Как считаем: по количеству задач, у которых в Трекере установлен статус «Бэклог».
Техническая реализация подсчета метрик производительности
На верхнем уровне система подсчета метрик состоит из следующих компонентов и информационных связей.
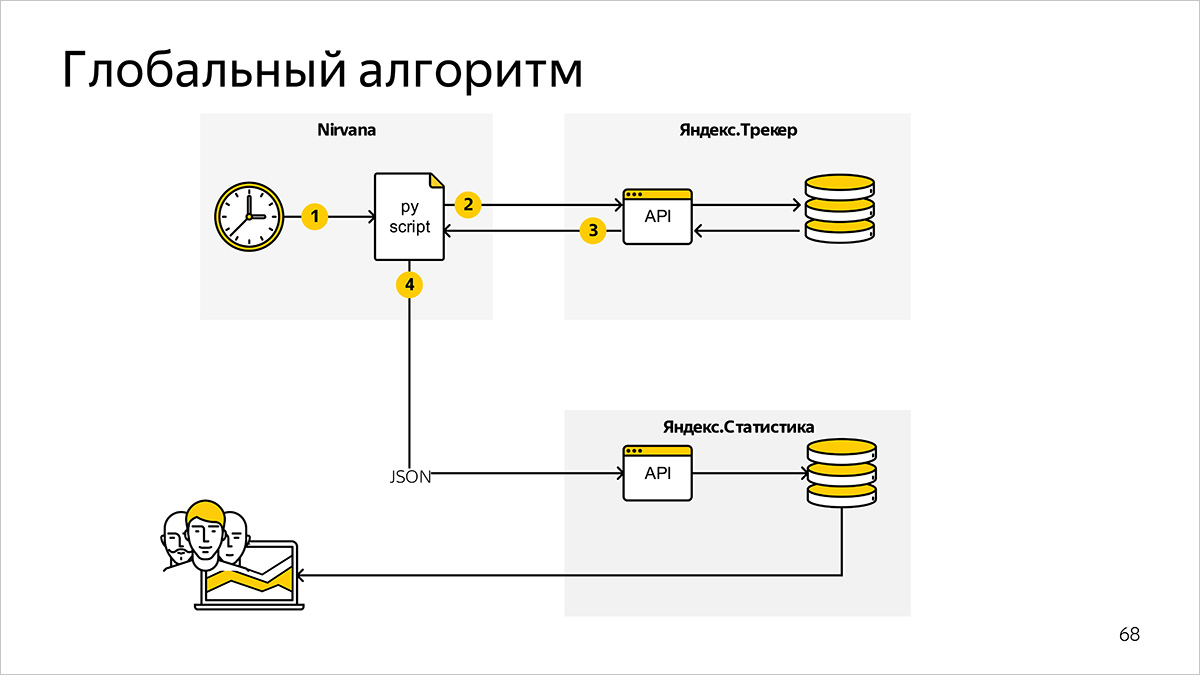
Программа подсчета метрик, запускаемая по расписанию
Мы используем Nirvana — универсальную вычислительную платформу. В ней формально описываем порядок запуска процессов. Вместе с внутренним планировщиком (scheduler) Nirvana заменяет нам набор bash-скриптов и cron.
Программа, написанная на Python, регулярно запускается и запрашивает необходимые для расчета метрик данные.
Система постановки задач
Данные для расчета метрик в нашем случае хранятся в Яндекс.Трекере. В качестве интерфейса к данным мы используем Python API Яндекс.Трекера — это обертка на HTTP API, которая позволяет быстрее и проще получать информацию в подходящих для дальнейшей обработки структурах данных.
Вы можете выбрать удобную для себя систему с подходящим API, например, Jira.
Система подготовки графиков
После подсчета метрик на основе данных из Яндекс.Трекера наша программа генерирует JSON-файлы и передает их во внутренний сервис Яндекс.Статистика для отрисовки графиков.
Вы можете использовать какую-нибудь JS-библиотеку, которая умеет строить графики. Обзор некоторых аналогичных решений есть на Хабре:
15 лучших JavaScript-библиотек
В следующей части мы расскажем, как считаем метрики качества пользовательской документации.
Комментариев нет:
Отправить комментарий