Но сегодня мы поговорим о строках форматирования функции printf.
Поскольку Юникод был принят в Windows раньше, чем в языке C, это означало, что разработчики Microsoft должны были придумать, как реализовать поддержку этого стандарта в среде выполнения C. В результате появились такие функции, как wcscmp, wcschr и wprintf. Что же касается строк форматирования в printf, то для них ввели следующие спецификаторы:
- %s представляет строку той же ширины, что и строка форматирования;
- %S представляет строку с шириной, обратной ширине строки форматирования;
- %hs представляет обычную строку независимо от ширины строки форматирования;
- %ws и %ls представляют широкую строку независимо от ширины строки форматирования.
Идея состояла в том, чтобы можно было написать такой код:
TCHAR buffer[256];
GetSomeString(buffer, 256);
_tprintf(TEXT("The string is %s.\n"), buffer);
И при компиляции в режиме ANSI получить вот такой результат:
char buffer[256];
GetSomeStringA(buffer, 256);
printf("The string is %s.\n", buffer);
А при компиляции в режиме Юникод — такой [4]:
wchar_t buffer[256];
GetSomeStringW(buffer, 256);
wprintf(L"The string is %s.\n", buffer);
Поскольку спецификатор %s принимает строку той же ширины, что у строки форматирования, такой код будет работать корректно и в формате ANSI, и в формате Юникод. Также это решение очень упрощает преобразование уже написанного кода из формата ANSI в формат Юникод, так как на место спецификатора %s подставляется строка нужной ширины.
Когда поддержка Юникода была официально добавлена в C99, комитет по стандартизации языка C принял другую модель строк форматирования для функции printf:
- %sи %hs представляют обычную строку;
- %ls представляет широкую строку.
Тут-то и начались проблемы. За прошедшие к тому моменту шесть лет для Windows было написано огромное множество программ объёмом в миллиарды строк, и в них использовался старый формат. Как быть компиляторам Visual C и C++?
Было решено остаться на старой, нестандартной модели, чтобы не сломать все существующие в мире программы под Windows.
Если вы хотите, чтобы ваш код работал и в тех средах исполнения, которые придерживаются классических правил для printf, и в тех, которые следуют правилам стандарта C, вам придётся ограничиться спецификаторами %hs для обычных строк и %ls для широких. В этом случае гарантируется постоянство результатов, независимо от того, передаётся строка форматирования в функцию sprintf или wsprintf.
#ifdef UNICODE
#define TSTRINGWIDTH TEXT("l")
#else
#define TSTRINGWIDTH TEXT("h")
#endif
TCHAR buffer[256];
GetSomeString(buffer, 256);
_tprintf(TEXT("The string is %") TSTRINGWIDTH TEXT("s\n"), buffer);
char buffer[256];
GetSomeStringA(buffer, 256);
printf("The string is %hs\n", buffer);
wchar_t buffer[256];
GetSomeStringW(buffer, 256);
wprintf("The string is %ls\n", buffer);
Вынесенное отдельно определение TSTRINGWIDTH позволяет писать, например, вот такой код:
_tprintf(TEXT("The string is %10") TSTRINGWIDTH TEXT("s\n"), buffer);
Поскольку людям нравится табличное представление информации, вот вам таблица.
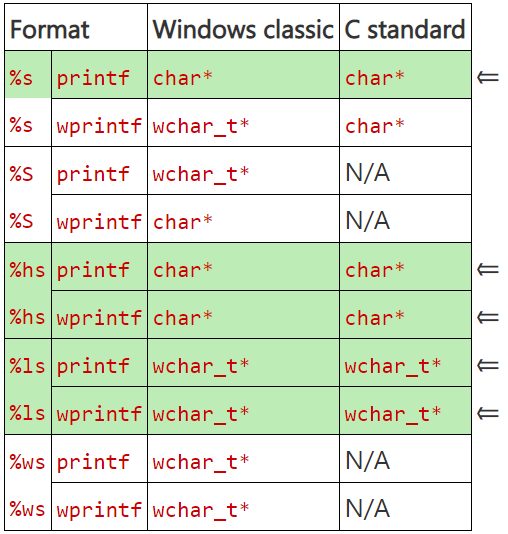
Я выделил строки со спецификаторами, которые в C определены так же, как и в классическом формате, принятом в Windows [5]. Используйте эти спецификаторы, если хотите, чтобы ваш код выдавал одинаковые результаты в обоих форматах.
Примечания
[1] Казалось бы, внедрение Юникода в Windows раньше прочих систем должно было дать Microsoft преимущество первого хода, но — по крайней мере в случае с Юникодом — оно обернулось для них «проклятием первопроходца», потому что остальные решили просто подождать до лучших времён, когда появятся более перспективные решения (такие как кодировка UTF-8), и только после этого внедрять Юникод в свои системы.
[2] Видимо, они полагали, что 65 536 символов должно было хватить на всех.
[3] Позже её заменили на UTF-16. К счастью, UTF-16 имеет обратную совместимость с UCS-2 для тех кодовых знаков, которые могут быть представлены в обеих кодировках.
[4] Формально версия для Юникода должна выглядеть так:
unsigned short buffer[256];
GetSomeStringW(buffer, 256);
wprintf(L"The string is %s.\n", buffer);
Дело в том, что wchar_t тогда ещё не был самостоятельным типом, и пока его не добавили в стандарт, он был всего лишь синонимом unsigned short. О перипетиях судьбы wchar_t можно почитать в отдельной статье.
[5] Классический формат, разработанный Windows, появился первым, так что это скорее стандарту C пришлось подстраиваться под него, а не наоборот.
Примечание переводчика
Я благодарен автору за эту публикацию. Теперь стало понятна, как получилась вся эта путаница с "%s". Дело в то том, что наши пользователи постоянно задавали вопрос, почему PVS-Studio по-разному реагирует на их, как им кажется, «переносимый» код, в зависимости собирают они свой проект под Linux или Windows. Понадобилось сделать в описании диагностики V576 специальный отдельный раздел, посвященный этой теме (см. «Широкие строки»). После этой статьи всё становится ещё более понятно и очевидно. Думаю, эту заметку стоит прочитать всем, кто разрабатывает кроссплатформенные приложения. Читайте и расскажите коллегам.
Комментариев нет:
Отправить комментарий