
Классическими средствами защиты от brute-force являются утилиты типа fail2ban, работающие по принципу: много запросов — один источник. Это не всегда может помочь заблокировать нарушителя, а также может привести к ложным (false-positive блокировкам). В этой статье я напишу про плюсы и минусы классических средств защиты и о возможностях интеллектуальной блокировки атак.
Brute-force
«Brute-force» атака базируется на одноимённом математическом методе («brute force»), в котором правильное решение — конечное число или символьная комбинация находится посредством перебора различных вариантов. Фактически каждое значение из заданного множества потенциальных ответов (решений) проверяется на правильность.
«Brute-force» атака или атака «перебором по словарю», это такой тип атаки на веб-приложение, при котором атакующий перебором значений учетных записей, паролей, сессионных данных и т.д. пытается получить доступ к веб-приложению либо данным.
Основные минусы классических средств защиты
Я ни в коей мере не хочу преуменьшить значение fail2ban, но на мой взгляд такие решения обладают рядом существенных недостатков.
1. Один источник атаки — множество запросов. Такая политика даст предотвратить «атаку в лоб», но в то же время пропустит распределенный brute-force со множества IP-адресов (например с использованием proxy-листов). Также такая политика может заблокировать излишне «ретивого» поискового бота и т.д.
2. Не учитывается контекст запроса: обычные системы защиты не учитывают направление запроса — множественные запросы GET-запросы /somefile, POST-запросы к форме авторизации, либо парсинг каталога товаров — блокировка произойдет при превышении выставленного лимита запросов за промежуток времени из одного источника, что с больше долей вероятности приведет к false-positive блокировкам.
Интеллектуальное выявление атак
Для того, чтобы минимизировать количество ложных срабатываний и выявления реальных brute-force атак были реализованы два механизма: первый позволяет выявлять input-поля веб-приложения для выявления точных зон, подверженных brute-force атакам (это позволяет более точно настроить защиту веб-приложения). Второй модуль выявляет схожесть запросов, отправленных к веб-приложению.
Например brute-force атака с помощью burp suite со словарем 10k_most_common.txt (10.000 наиболее популярных паролей) покажет 88% схожести запросов и будет заблокирована:
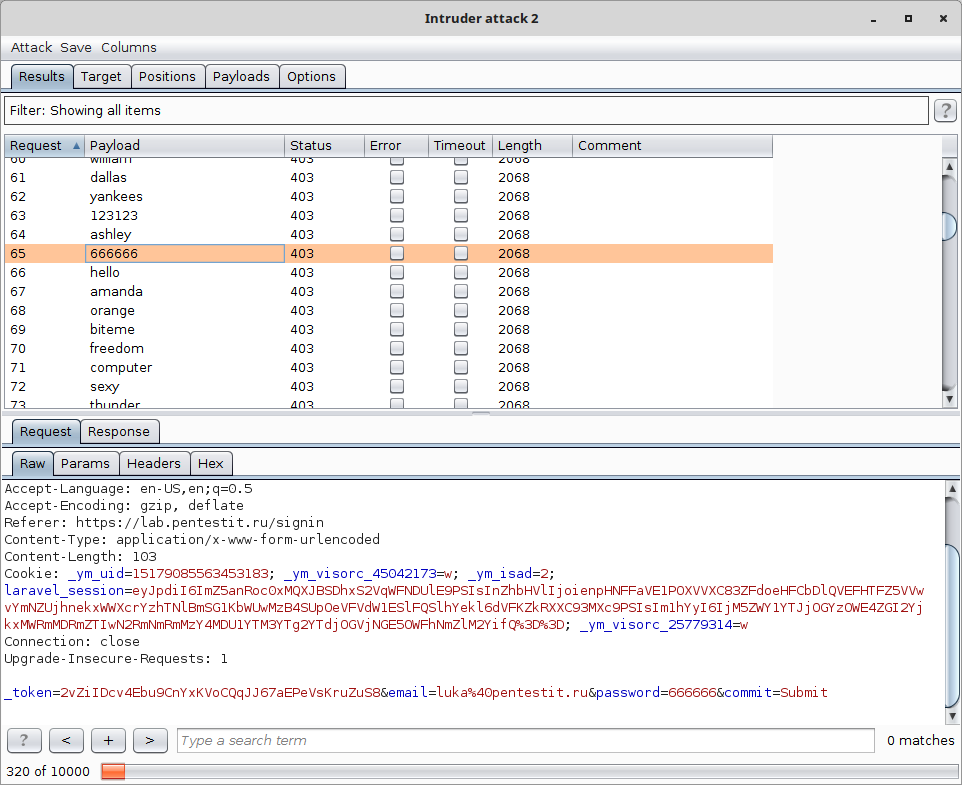
Подход к выявлению атак перебора пароля базируется на расчете взаимного расстояния между запросами, поступающими к веб-приложению (через Nemesida WAF), а также производится учет источников и зон. В качестве метрики для расчета меры близости было выбрано расстояние Левенштейна. Настраивается интервал наблюдения, минимально необходимое количество запросов и пороговое значение меры близости этих запросов.

Расстояние Левенштейна (также редакционное расстояние или дистанция редактирования) между двумя строками в теории информации и компьютерной лингвистике — это минимальное количество операций вставки одного символа, удаления одного символа и замены одного символа на другой, необходимых для превращения одной строки в другую.
Консолидация классических принципов блокировок с использованием принципов интеллектуального выявления атак даст возможность защитить веб-приложение от атак с использованием автоматизированных систем (как наиболее эффективных в brute-force атаках). Защиту от «ручного» перебора паролей, который подвержен большой доле энтропии такими средствами обеспечить нельзя, в данном случае необходимо настраивать веб-приложение, учитывая количество неверно введенных паролей за разумную единицу времени.
Комментариев нет:
Отправить комментарий