Действуем по старой схеме: я для вас отсматриваю подряд 10 докладов, делаю краткое описание содержимого, чтобы неинтересное можно было выбросить. Кроме того, с сайтов собираю ссылки на слайды и описания. Полученное сортирую и выдаю в порядке увеличения рейтинга — то есть в самом низу будет самый крутой доклад. Оценки — это не лайки на YouTube, а собственная оценочная система, она круче лайков.
Предыдущие части: JBreak 2017, JPoint 2017 (обе конференции были про Java).
На этот раз объектом изысканий будет Heisenbug 2017 Moscow — известная конференция для тестировщиков (а также программистов и менеджеров команд, как написано на главной странице сайта).
В посте присутствует зашкаливающее количество картинок и ссылок на YouTube. Осторожно, трафик!
Disclaimer: Все описания являются моим личным мнением. Всё написанное является плодом моего больного воображения, а не искажёнными цитатами докладчиков (это предостережение написано для того, чтобы докладчики меня не побили). Если кого-то случайно обидел — пишите в личку, разберёмся. Но в целом, давайте думать так: если бы BadComedian каждый раз спрашивал у Фонда Кино, что ему стоит говорить или не говорить — снял бы он хоть один ролик?

Спикер: Алексей Виноградов, Андрей Солнцев; оценка: 4,31 ± 0,14. Ссылка на презентацию.
Puzzlers — это доклад-викторина, в которой все зрители становятся непосредственными участниками шоу. Ведущие придумывают полдюжины интересных задачек, почти все из которых взяты из реальной проектной практики. К каждой задачке демонстрируется список вариантов и даются убедительные аргументы в пользу каждого.
Тема этого паззлера — фреймворк для UI-тестирования Selenide. Вопросы доступны для новичков с поверхностными знаниями фреймворка, но об некоторые из них сломают зубы даже профессионалы.
Кстати, Андрей Солнцев — это создатель Selenide, а Алексей Виноградов — это тот самый Виноградов из Radio QA, что само по себе доставляет.

Спойлерить ответы на паззлеры я здесь не буду, но приведу парочку задач.
Самый первый паззлер довольно простой (если видел ответ):

А вот здесь уже не всё так очевидно:

С удовольствием дослушал всё до конца. Забавно, что если на конференциях по программированию паззлеры зачастую бесполезны (но знание магии доставляет программистам неимоверное наслаждение), то вот этот доклад имеет прямую практическую ценность. Сразу видно, что авторы не просто нагуглили топ-10 самых странных вопросов со StackOverflow, а просто взяли задачи из своей практики.
Спикер: Simon Stewart; оценка: 4,33 ± 0,13. Ссылка на презентацию.
Саймон Стюарт — это, мягко говоря, известная личность. Именно он изначально создал WebDriver и продолжает тащить на себе Selenium.
Начинается доклад с каких-то довольно базовых вещей о локаторах, длинных XPath и слипах. Саймон рассказывает, как писать тест и приложение таким образом, чтобы избежать типичных проблем.

Но сразу после этого (где-то на 24 минуте) рассказ конденсируется вокруг основной темы доклада — масштабирования.
Он рассказывает, почему static и ThreadLocals — это плохо, а также почему код должен быть немутабельным и stateless. Причем эти объяснения идут не от стандартного подхода к программированию высокопроизводительного кода (в котором, если сильно постараться, можно и доказать пользу статиков), а именно от тестов.
Всё это подкрепляется живыми демонстрациями на его макбуке.
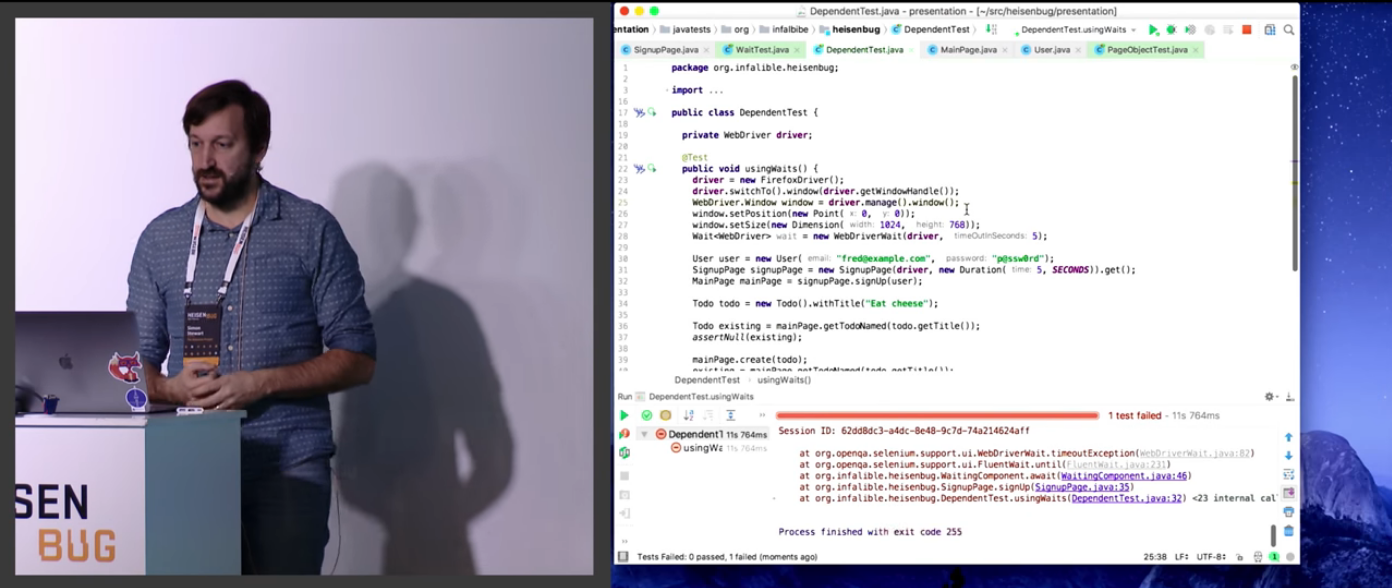
Автор подходит к вопросу системно, рассматривает запуск тестов из независимых местоположений. Вообще, мне кажется, что такой вопрос отлично подойдёт для собеседования, чтобы сразу определить, человек только хэлловорлды писал или работал :-)

На примере типичного веб-приложения рассматриваются ситуации, когда тесты могут падать, но совершенно не по тем причинам, которые мы собирались поймать.
По ходу дела Саймон совершенно не гнушается опускаться в детали применимости архитектуры Selenium. Неудивительно, он же её и разрабатывал.

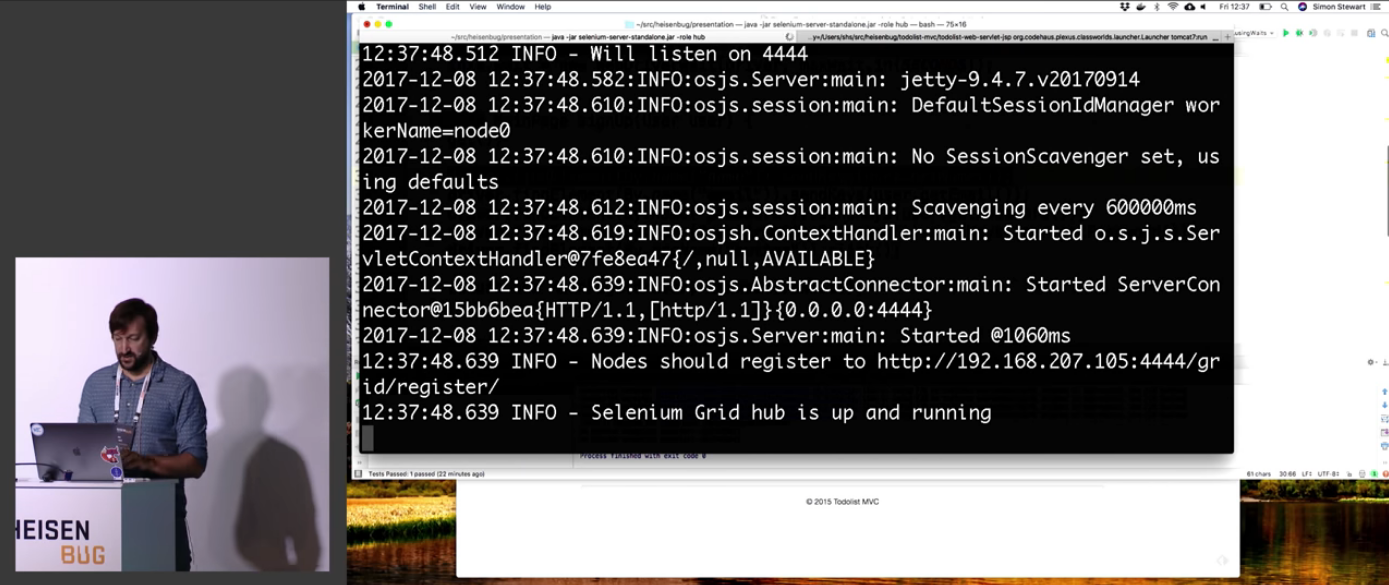
Так он подводит нас к использованию Selenium Grid и показывает это на реальных демках.
Ну и Докер, конечно. Первое правило Докера: всегда говори о Докере!

И заканчивается всё облачными провайдерами.
Под конец доклада идёт обсуждение стандартных ошибок, которые можно при этом наделать.

В прошлом я внедрял DevOps, и описанные в докладе «фуллстековые» проблемы показались мне очень близкими и знакомыми. Для себя я забрал отсюда официальную позицию Саймона (по сути — позицию команды Selenium) по ряду основополагающих вопросов масштабирования тестирования, и это в будущем позволит корректней обращаться с их инструментами.
Спикер: Никита Макаров; оценка: 4,34 ± 0,07. Ссылка на презентацию.
Никита Макаров — руководитель группы автотестирования в Одноклассниках. А ещё он — член Программного комитета Heisenbug. Время от времени мы общаемся в интернете, и посмотреть его доклад было особенно интересно.
Во-первых, доклад начинается с того, что Никита уже выложил презентацию и дал QR-код на неё. Сказать, что это офигенно — это ничего не сказать. Имхо, так нужно делать вообще каждому докладчику. Хотя нам, просматривающим запись конференции на YouTube, это уже не столь важно.
Если коротко, то в отрасли тестирования очень много говорится про «черный ящик», но изредка и вскользь упоминается «белый». Связано это в том числе и с тем, что тестирование «белого ящика» всегда считалась прерогативой программистов.
Этот доклад отвечает на несколько животрепещущих вопросов:
- Как не давать программистам писать неправильный код?
- Как внедрять падения в код так, чтобы не было мучительно больно?
- Зачем вам может понадобиться парсинг исходного кода и что вы можете с этого получить?
- Социальный анализ кода и покрытие — почему и зачем ?

В самом начале Никита задаётся вопросом, почему так мало информации про белый ящик? Рассказывает о соответствующем историческом контексте и своих изысканиях на эту тему.

После этого мы переходим к конкретике. Забавно, что Никита использует тот же самый скриншот стека вызовов, что и я на моём прошлом выступлении про DevOps:
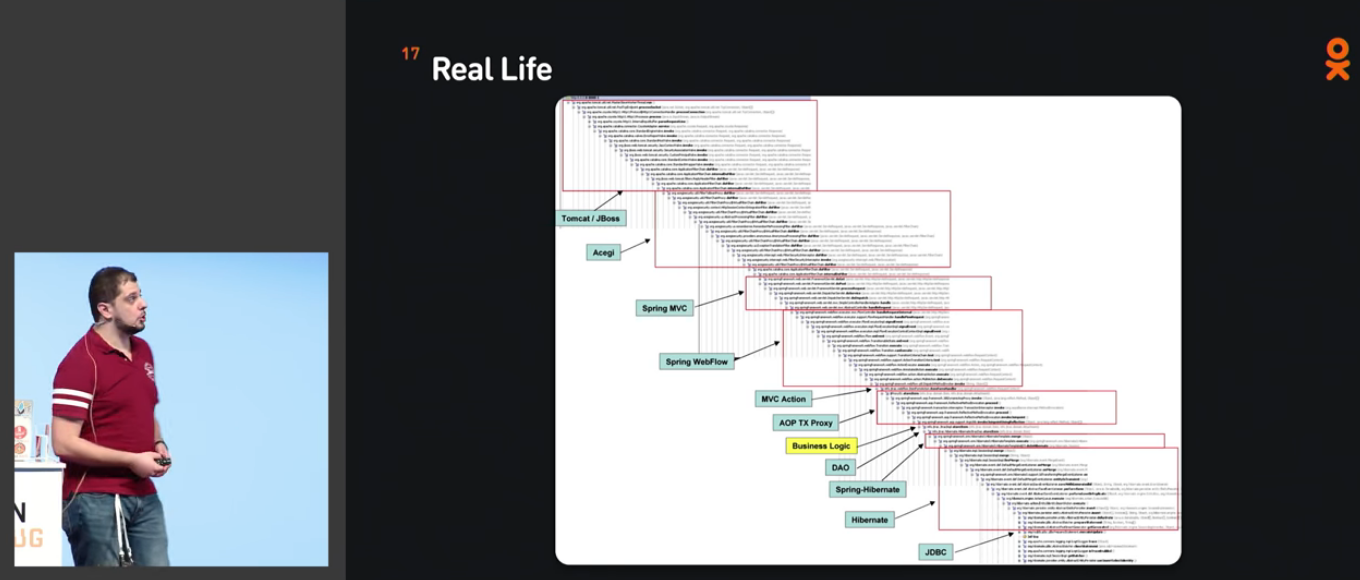
Если попытаться зайти на эту цепочку вызовов с точки зрения чёрного ящика, можно очень много чего не протестировать. Это знает каждый Java-программист, и (я хочу надеяться) каждый Java-тестировщик, но это та штука, о которой обычно задумываться совершенно не хочется.
Это была мотивационная часть. Дальше идёт практика. Никита заранее предупреждает, что готовых решений не будет, и начинает рассказывать принципы.

Разбираемые вопросы иллюстрируются на конкретных примерах в Java-коде:
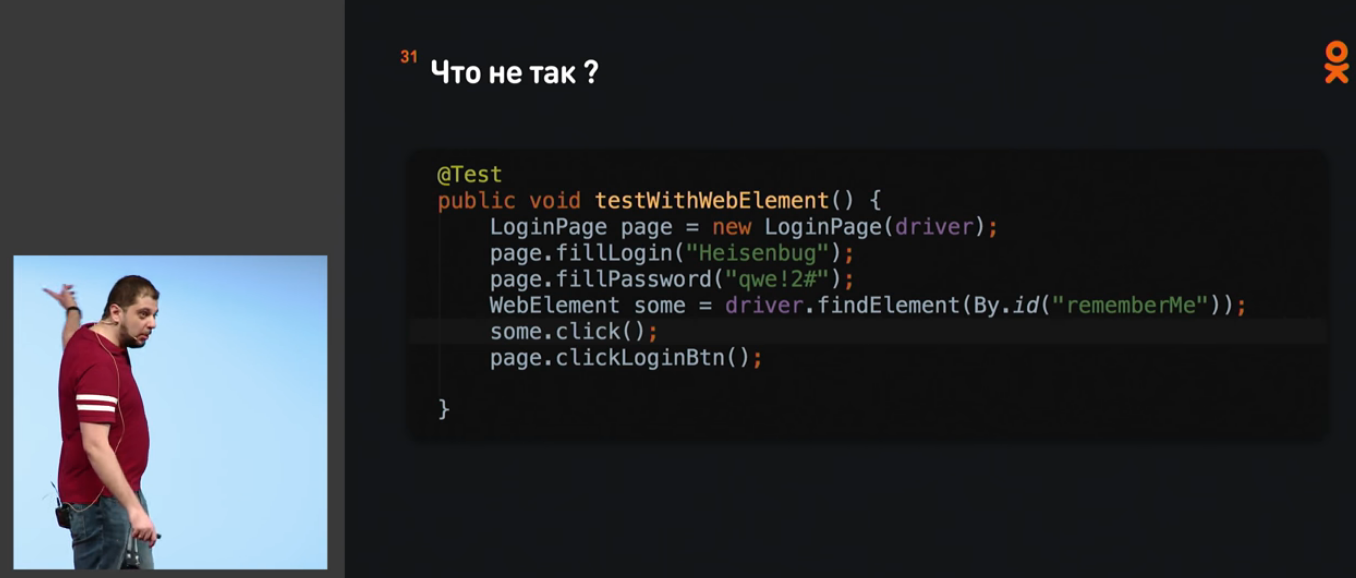
В какой-то момент он даже открыл Идею и начал всё это показывать:

В докладе рассматривается очень много разных видов тестирования и инстурментов для них:

И всё это иллюстрируется живыми демонстрациями на ноутбуке докладчика. Это бессмысленно пересказывать, потому что концентрация информации действительно высока.
По сути, доклад делится на некие «уровни погружения» в тему. Он начинается с самого простого и заканчивается наиболее кошмарным. Например, там будет даже про парсинг исходников и Abstract Syntax Tree.
В самом конце Никита резюмирует, что белый ящик — это стратегия, а как мы его будем реализовывать — это наше дело, и это зависит от конкретного проекта. Надо думать головой.
И что мне особенно понравилось, доклад заканчивается на жизнеутверждающей ноте: нужно читать код! (Как заставить это делать тестировщиков, я пока не понял, впрочем).

Спикер: Роман Поборчий; оценка: 4,36 ± 0,13. Ссылка на презентацию.
С Романом мы познакомились во время подготовки к конференциям JBreak и JPoint. Роман помог сделать мои слайды (и доклады вообще) не такими отстойными, как это получилось бы у меня в одиночку. Там же выяснилось, что Роман обладает просто невероятной глубиной знаний по темам типа A/B-тестирования, и я с нетерпением ждал, когда он тоже сделает доклад. Итак, вот он.
Роман рассказывает об области, смежной с тестированием. После того, как вы проверили, что функциональность реализована нормально, она выкатывается в эксперимент, чтобы узнать, нравится ли новая версия пользователям.
Замечали, что обычно люди, ответственные за эксперименты, в итоге говорят, что данных недостаточно для решения? Часто это действительно так, но нередко всё дело в поломках системы экспериментов и учёта пользовательской статистики.
В докладе рассматриваются типичные поломки, которые там встречаются, в результате чего появляется возможность, вернувшись на рабочее место, немножко побыть data scientist'ами и найти ошибки у себя. Какие-то из них там наверняка есть.
Вообще, я очень плохо разбираюсь в математике, и тем более — в матстате, и я боялся, что из доклада Романа мне не удастся вынести вообще ничего. Просто потому, что не хватит IQ. Но нет, каким-то непостижимым образом содержание доклада оказалось вполне понимаемым и применимым на практике.
Начинается доклад с рассказа про один из тестов Microsoft во времена, когда трава была зеленее:
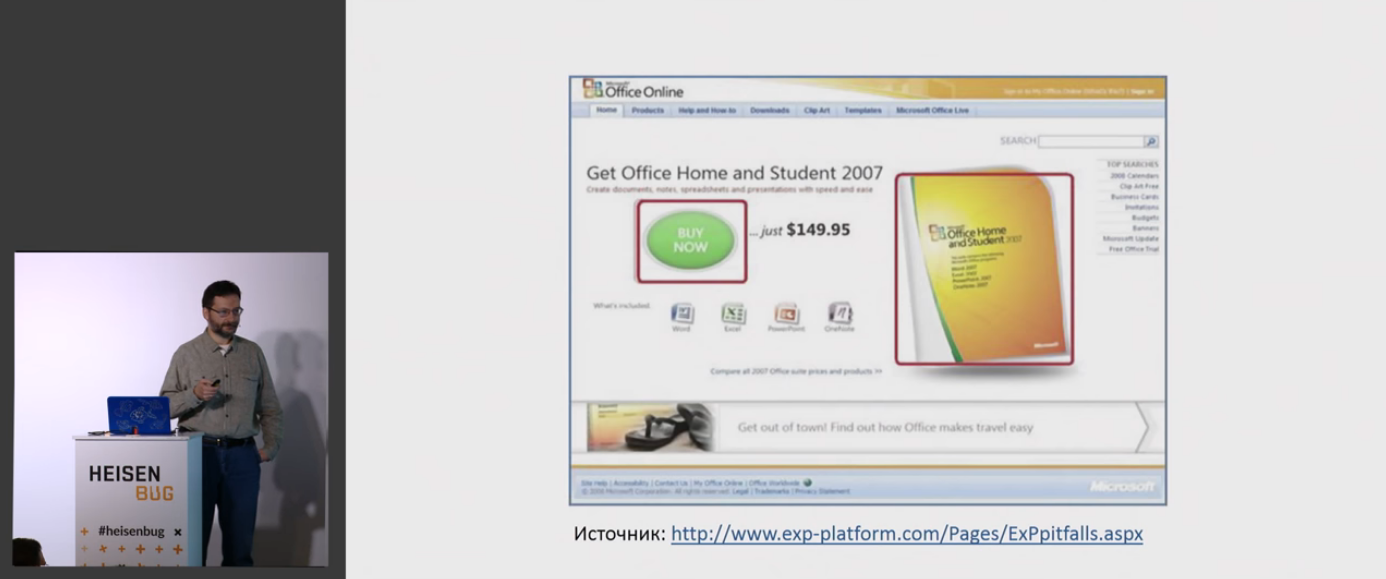
Самая главная ошибка в том, что если вообще не иметь тестов, то можно что-нибудь такое выкатить на прод, что заставит потом очень сильно пожалеть.

Зачастую люди не понимают, что там может быть сложного — разбил по юзерам, показал каждому своё, посчитал результат — и готово!
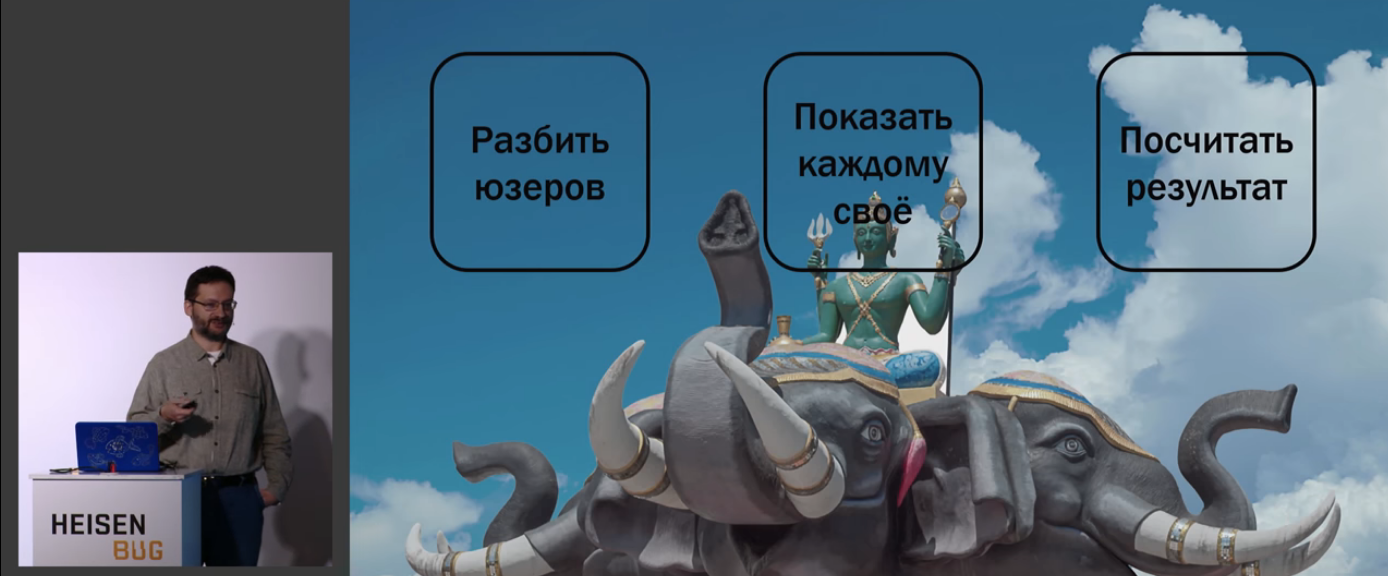
Собственно, весь доклад Романа про то, что сложного там может быть более чем дофига.
Например, человек от своих собственных привычек зависит больше, чем от каких-то мелких изменений на нашем сервисе.
Поэтому картинка разделения получается не такая:
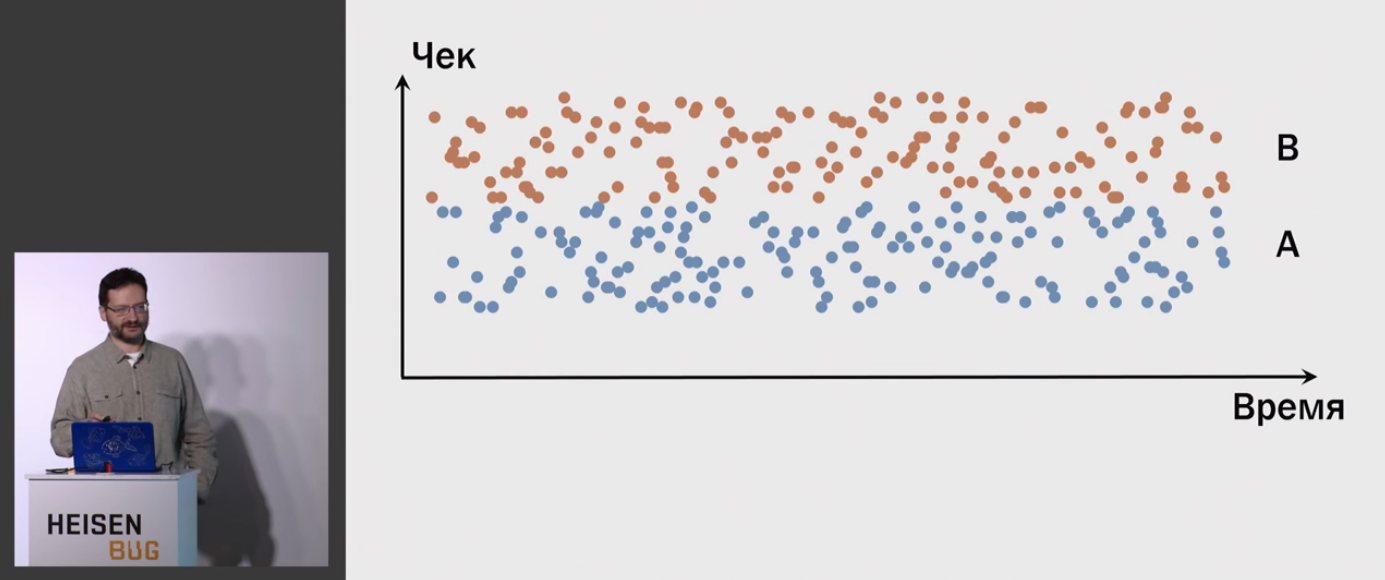
А вот какая-то такая:

Дело в том, что к нам на эксперименты пришло совсем немного людей, а результаты исследования нужно будет применить на всех людей вообще. И это классическая задача статистики.
Центральная линия доклада — это несколько основных ошибок:
- Вообще не проводить экспериментов
- Перебирать параметры руками пользователей
- Провести слишком много плохих экспериментов
- Не сохранять логи экспериментов с возможностью перерасчёта
- Не учитывать, что измеряемый показатель сам собой меняется во времени (это называется сезонность)
Итоги примерно такие (и они следуют из заявленных проблем):

Для меня доклад оказался ценен не итогами как таковыми, а стройной системой рассуждений, которая позволяет взять этот материал за основу и дальше самостоятельно думать в этом направлении.
Ну и конечно, математику всё равно нужно подтягивать.

Если попробовать выразить весь доклад в одном слайде, он, наверное, будет выглядеть как-то так:

Спикер: Алексей Лавренюк, Тимур Торубаров; оценка: 4,38 ± 0,14. Ссылка на презентацию.
Следующий доклад ведут два разработчика из Яндекса. Алексей причастен к таким вещам, как Яндекс.Танк, Pandora и Overload. Тимур 4 года отработал в телекоме и последние 4 — в Яндексе.
Это был один из тех немногих докладов, в котором получилось поучаствовать вживую. Пришёл я на него из скрытых мотивов: позлорадствовать про то, как современные приложения сажают батарейку. Благо доклад как раз от людей, которые героически с этим сражаются в масштабах компании.
Грубо говоря, раньше мы умели тестировать только производительность серверных приложений, а теперь весь мир перешёл на мобилки. В том числе, в Яндексе измеряют энергопотребление телефонов. Алексей и Тимур рассказывают, как научились собирать метрику энергопотребления хардверным способом: собрали небольшую схему на базе Arduino, которая измеряет ток, и написали библиотеку для работы с ней. Библиотеку они выложили в open source. Кроме того, в докладе рассказывается, как подготовить телефоны, собрать коробочки для замеров и как использовать библиотеку.
Конечно, всё это интересно в первую очередь тем, у кого в наличии прямые руки. Я за себя не уверен, что смог бы действительно заниматься таким в проде. Для этого нужно недюжинное упорство и талант. Но вот подивиться, как это делают профессионалы — всегда интересно.
Доклад начинается с того, как всё непросто, если тест происходит с настоящими телефонами.

Проделали некие исследования, кому это вообще нужно, и какие характеристики должны быть у собственного решения по энергопотреблению.

Общий план доклада примерно следующий:

То есть вначале рассказывается, почему они не взяли мультиметр, а потом выходит Тимур, показывает, что есть в опенсорсе и как этим пользоваться.
Даётся некая проблематика того, что умеет и не умеет телефон (и что значит метрика 1/20 применительно к iPhone)
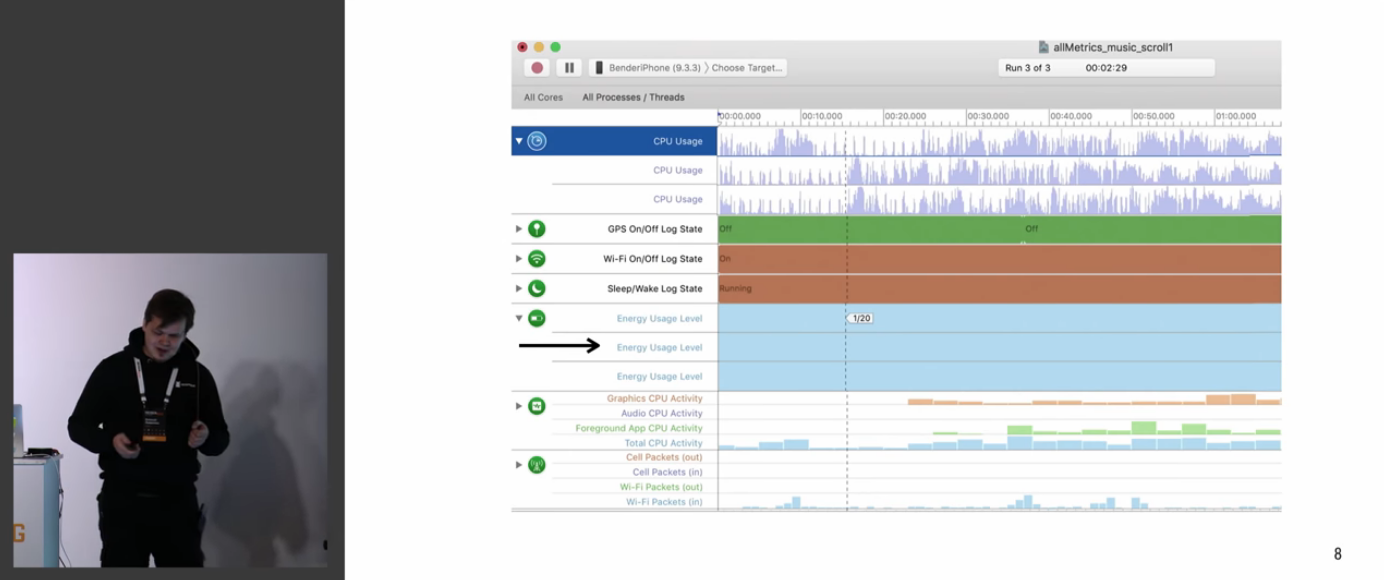

Обсуждается, как они изучали готовые решения.

Поэтому они взялись за дело сами!


Обсуждаются не только чисто аппаратные мелкие вопросы, которые возникали по ходу работы:

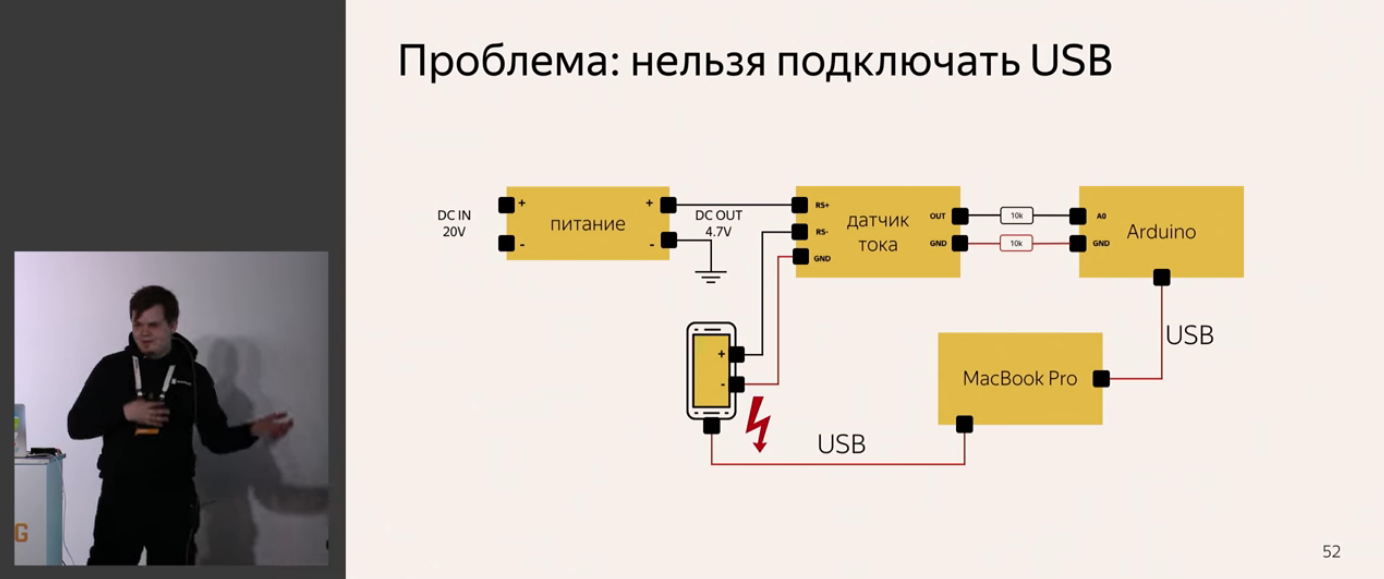
Но и проблемы разработки софта:


Вторая часть доклада посвящена готовому решению — Volta и VoltaBox.


Софт устанавливается с помощью pip install volta. Вот так софт выглядит под капотом:
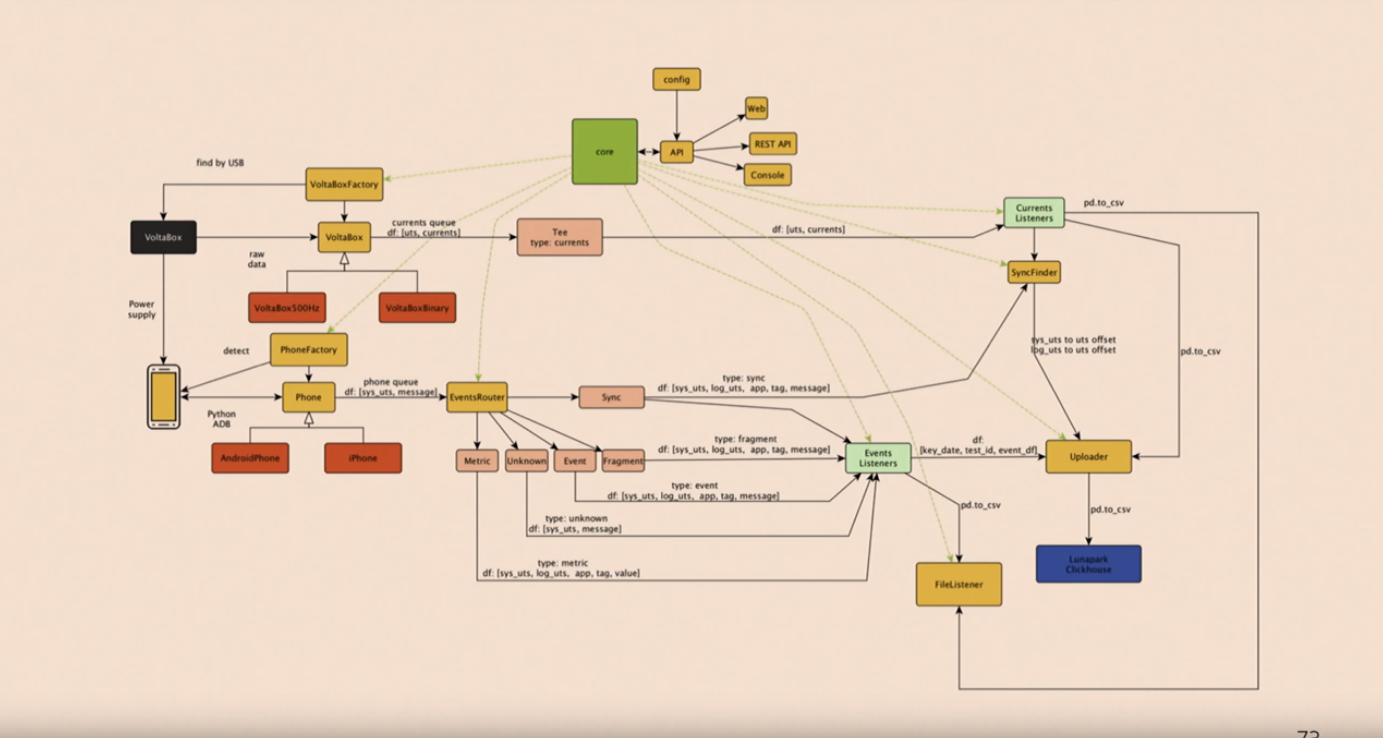
Собственно, диаграммка тут только затем, чтобы показать, что там внутри всё очень хорошо продумано.
Тимур рассказывает, как это всё реально конфигурить и использовать. Всё работает просто на Jupyter Notebook, а дальше — следите за руками!

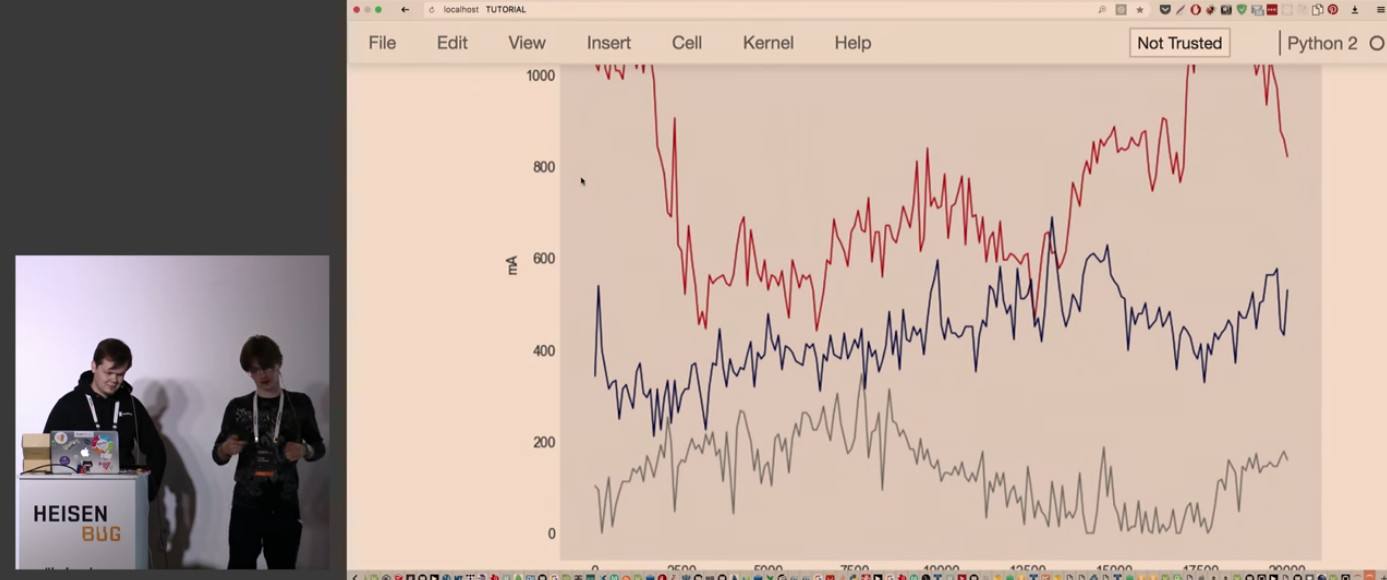
В общем, результаты выглядят как-то так:

Доклад оставляет ощущение того, что измерение энергопотребления — это не какая-то фантастика и отдалённое будущее, а это можно сделать прямо сейчас. И всё это не требует быть доктором физико-математических наук. Конечно, это возможно только потому, что такие люди, как Алексей и Тимур, всё сделали за нас, а нам остаётся только использовать готовенькое.
Спикер: Антонина Хисаметдинова; оценка: 4,40 ± 0,10. Ссылка на презентацию.
Обычный программист (да и тестировщик тоже) любит тестировать только happy path. Всё, что не happy, слишком сильно капает на нервы. Поэтому сценариям с ошибками обычно уделяется очень мало внимания.
Многие просто создают однотипные интерфейсные окна вроде «Ошибка № 392904» или «Упс, что-то пошло не так», не задумываясь, что почувствует пользователь. А ведь он может расстроиться, потерять доверие к продукту. Ну, или догнать на улице и побить.
Доклад показывает ошибки глазами обычных людей. Антонина рассказывает, как научить интерфейс грамотно сообщать об ошибках и сбоях, чтобы не бесить пользователей.
Рассказ начинается с обзора сценариев с ошибками.
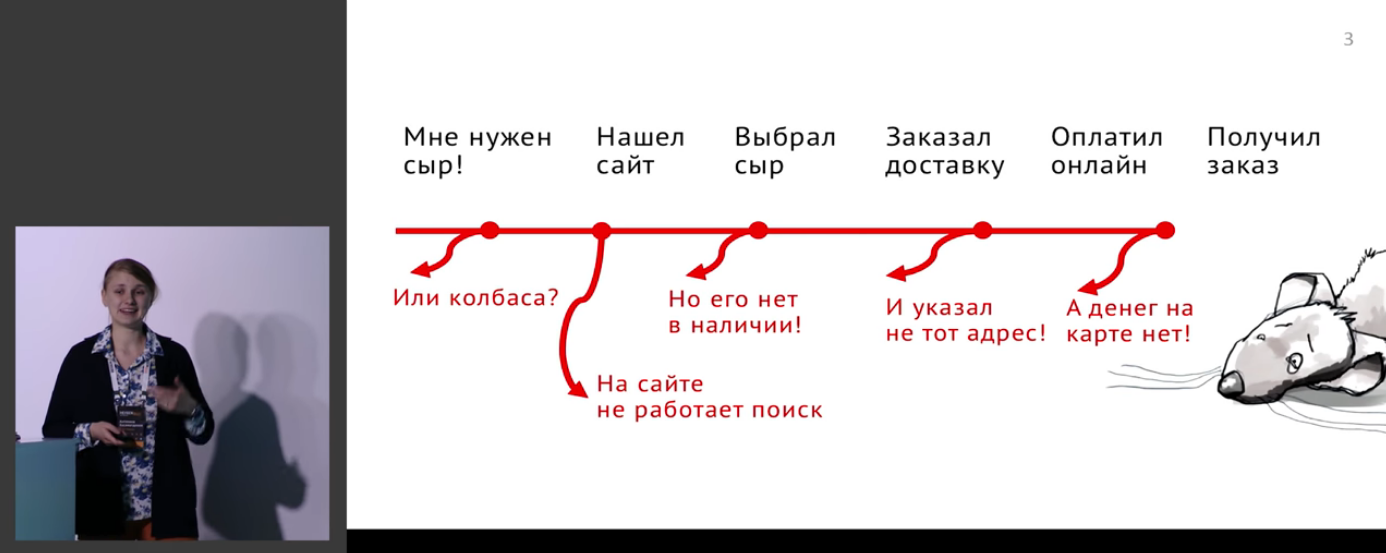
Немного про то, как обосновывать бизнесу обработку таких сценариев:

Всё это выливается в реальные деньги:

То есть хорошее сообщение об ошибке:
- Снижает нагрузку на поддержку
- Помогает пользователю не потеряться в воронке конверсии
- Быстро обучает работе с продуктом
- Помогает сохранить доверие к сервису в трудную минуту
Дальше системно обсуждаются разные типы ошибок, реакции пользователя на них (в т.ч. на примере World of Tanks!) и то, какие нюансы всё это вносит в формирование сообщения об ошибке.


Есть немного о каналах обращения пользователей и способах грамотного информирования пользователей об ошибках:

Даются вполне конкретные советы по улучшению приложений в виде чеклистов.

Всё это иллюстрируется на безумном количестве живых примеров:

Рассматриваются даже такие достаточно необычные применения, как интерфейсы для слабовидящих:

Вообще, доклад просто переполнен сконцентрированной информацией, и передать всё в виде этой выжимки, думаю, невозможно.
Но можно накидать некий центральный план:
- Как сообщать о глобальных сбоях?
- Специфические баги
- Ошибки пользователей
- Проблемы подключенного сервиса
- Внешние проблемы
- Крайне необычное поведение пользователей или сервиса
Ближе к концу поднимается главный вопрос вселенной жизни и вообще:
Там же имеется чёткий чеклист, что теперь со всем этим делать и что почитать по теме:


Слайд про «Что почитать?» — девяносто третий. Девяносто три слайда, Карл!
После просмотра видео у меня появилось ощущение, что это не просто какой-то доклад, а самая настоящая книга, умная и с высокой глубиной проработки. Может быть, когда-нибудь она напишет книгу? Было бы здорово.
Ну и да, абсолютно всё, что там было сказано — очень полезно, чётко и по делу. Один из немногих докладов, которые применимы на 146%.
Спикер: Артем Ерошенко; оценка: 4,45 ± 0,08. Ссылка на презентацию.
Артём известен тем, что является автором Allure и HtmlElements. Давно занимаясь проектами, связанными с автоматизацией веб-тестирования, он сформировал свод правил, которые обеспечивают комфортную работу ему и его команде на протяжении жизни всего проекта от первого теста до нескольких тысяч. Этот свод правил условно разделен на три группы: «Простота разработки», «Доверие к результатам» и «Контроль качества».
В докладе идёт речь об инструментах, которые позволяют Артему с командой создавать и править тесты максимально просто и наглядно. Рассмотрены подходы, которые помогают добиться доверия к результатам прохождения тестов у всей команды, как осуществляется контроль за качеством тестов.
Самым правильным будет представить этот доклад в виде некоего плана.
Дело в том, что в докладе используется более 170 слайдов. Если начать описывать это подробно, то нужен будет отдельный хабрапост — а возможно, и не один.

Всё вместе это будет выглядеть как-то так (сорри, если где-то перепутал с уровнями вложенности, ибо разговор стелется плавно):
- Простота
- Инструменты разработки
- Работа с браузером
- PageElements
- Структура элемента
- Структура страницы
- Как выглядит тест?
- Недостатки HtmlElements
- Боль с Ajax-страницами
- Проверки сбоку
- Отсутствие параметризации
- Отсутствие логирования
- Интерфейсы вместо классов
- Параметризация
- Проверки с перепопытками
- Шаблоны страниц
- Дескрипшн элемента
- Степы практически не нужны
- Подготовка данных
- Конфигурация тестов
- Запуск тестов
- Конфигурация тестов
- Описание конфигурации
- Примитивные типы
- Расширенные типы
- Списки и массивы
- Несколько источников
- Переопределение значений
- Конфигурация WebConfig
- Конфигурация ApiConfig
- Инициализация конфигов
- Использование в тестах
- Инъекция зависимостей
- Граф зависимостей
- Базовый класс — плохо
- Статические поля — плохо
- Что нам реально нужно?
- ПоставщикWebConfig
- ПоставщикWebDriver
- Поставщик MainPage
- Конфигурация модуля
- Поставщик User
- Интеграция с JUnit
- Как выглядит тест?
- Доверие
- Доверие команды к тестам
- Короткие тесты
- Пример на диаграммах
- Как выглядит сервис
- Как выглядит запуск тестов
- Как на самом деле
- Почему так происходит
- Разные точки входа
- Как действовать
- Пример на диаграммах
- Сервер «заглушек»
- Как проверить объявление
- Как проверить фильтры
- Какие есть реализации
- Как устроен сервис
- Сервер «заглушек»
- Режим прокси
- Как устроено тестирование
- Как выглядит код в тесте
- А если в несколько потоков?
- Идентификатор теста
- Заголовок в HTTP-запросе
- Короткие тесты
- Доверие команды к тестам
- Контроль
- Launches types
- Grafana
- Примеры графиков
- Количество тестов
- Статус запуска тестов
- Статусы теста
- Время запуска тестов
- Количество перезапусков
- Перезапуски и статус
- Перезапуски и время
- Проблемы запуска
- Файл 'categories.json'
- Категории проблем
- Как настроить?
- Как это работает?
- Экспорт в InfluxDB
- Формат данных InfluxDB
- Allure Plugin
По сути, это один из самых полных докладов-справочников по теме, и добавить тут особо нечего. Это такой мега-чеклист, по которому надо идти и последовательно прорабатывать.
TOP-3
Спикер: Александр Хозя, Николай Козлов; оценка: 4,57 ± 0,10. Ссылка на презентацию.
Работа с локациями достаточно нетривиальна, и в процессе всплывает очень много моментов, которые сложно предугадать заранее. Докладчики освещают проблемы и нюансы этой темы, раздают полезные советы и рассказывают об используемых инструментах. Информации по теме не так уж и много, так что доклад окажется полезным почти для кого угодно.
Вначале докладчики выкатывают набор понтов на тему, какие они крутые и большие в Badoo. Сам я этим сервисом не пользуюсь, так что циферки повергли меня в легкий шок:

И всё это хранится правильно, в защищённом виде.
Доклад вот о чём:


Вначале даётся некая вводная о том, как работает современная геолокация:
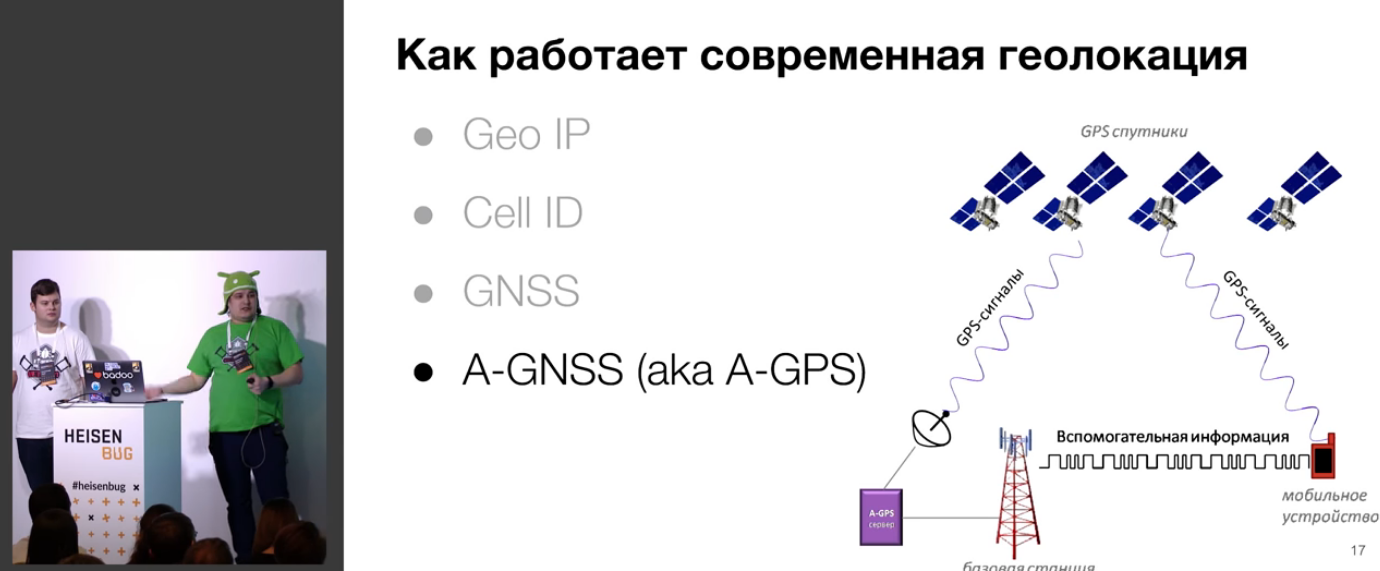
Дальше ставится несколько задач (вроде «обработать тонну геоданных при как можно меньшем энергопотреблении») и показывается куча примеров, где эти самые геоданные используются.
Проблема в том, что между стартом приложения и сбором геоданных с заданной точностью может пройти время.
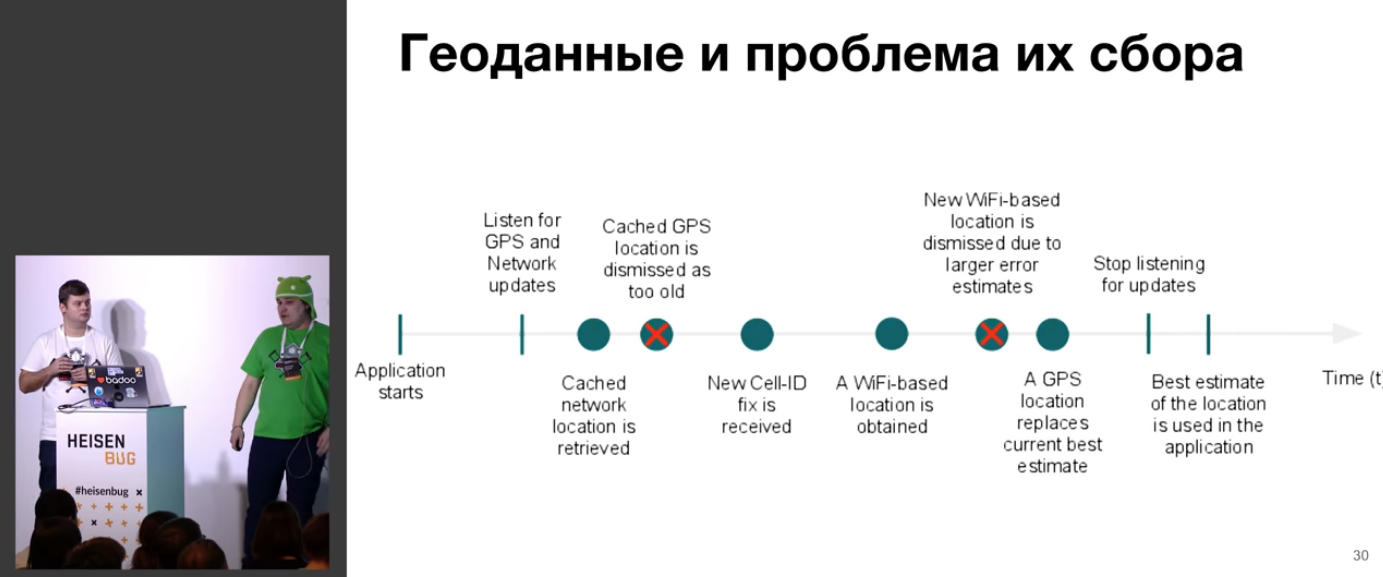
Упоминается о том, что данные получаются не абсолютно точные, и что их нужно уметь тестировать. Для тестирования используется эмулятор андроида и симулятор Xcode, причём там везде есть баги.

Разные интересные утилиты:

Теперь система уже принимает данные (благодаря вышеописанному), и нужно определить, что она вообще хоть как-то работает.
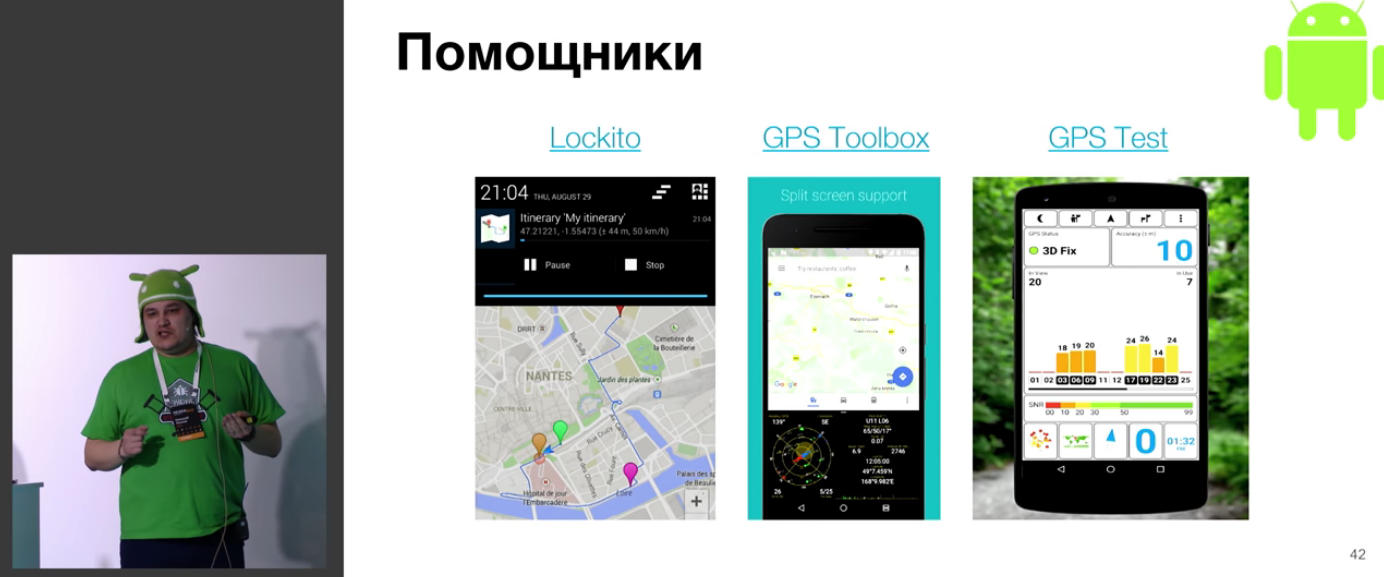
Обсуждается проблема информационного шума, и что иногда даже непонятно, в какую сторону копать:

Естественно, тут приходит очередь логов. Формулируются критерии хороших логов:


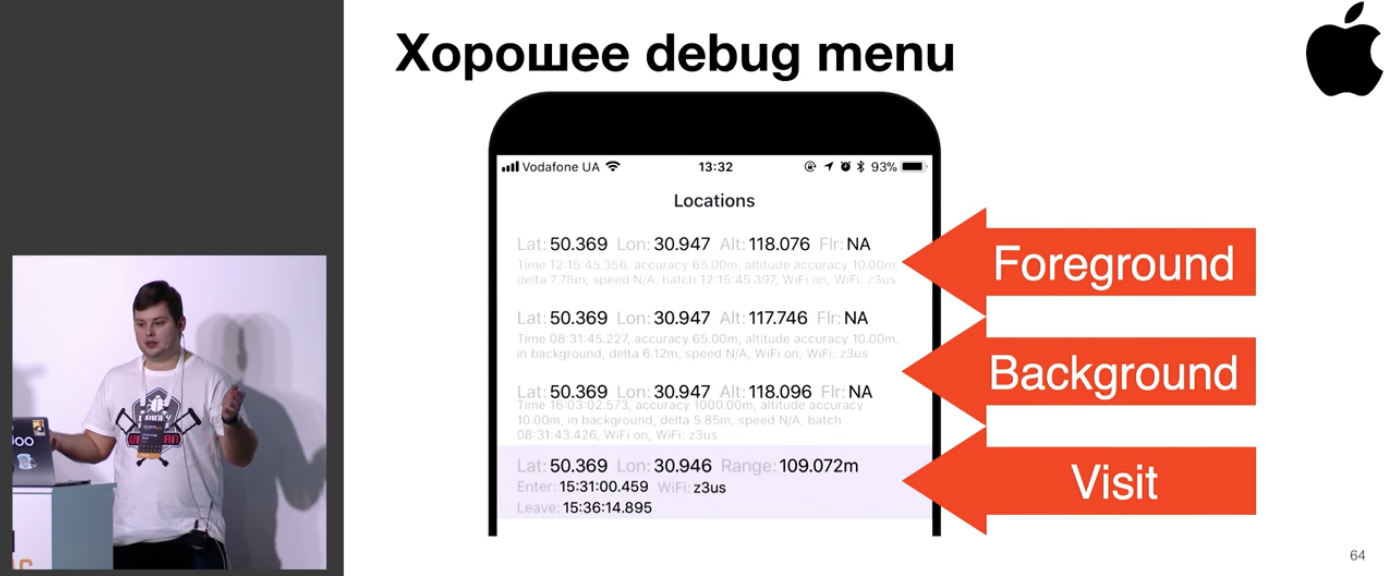
Дальше идёт целый блок рассуждений о том, как сделать хорошее отладочное меню.
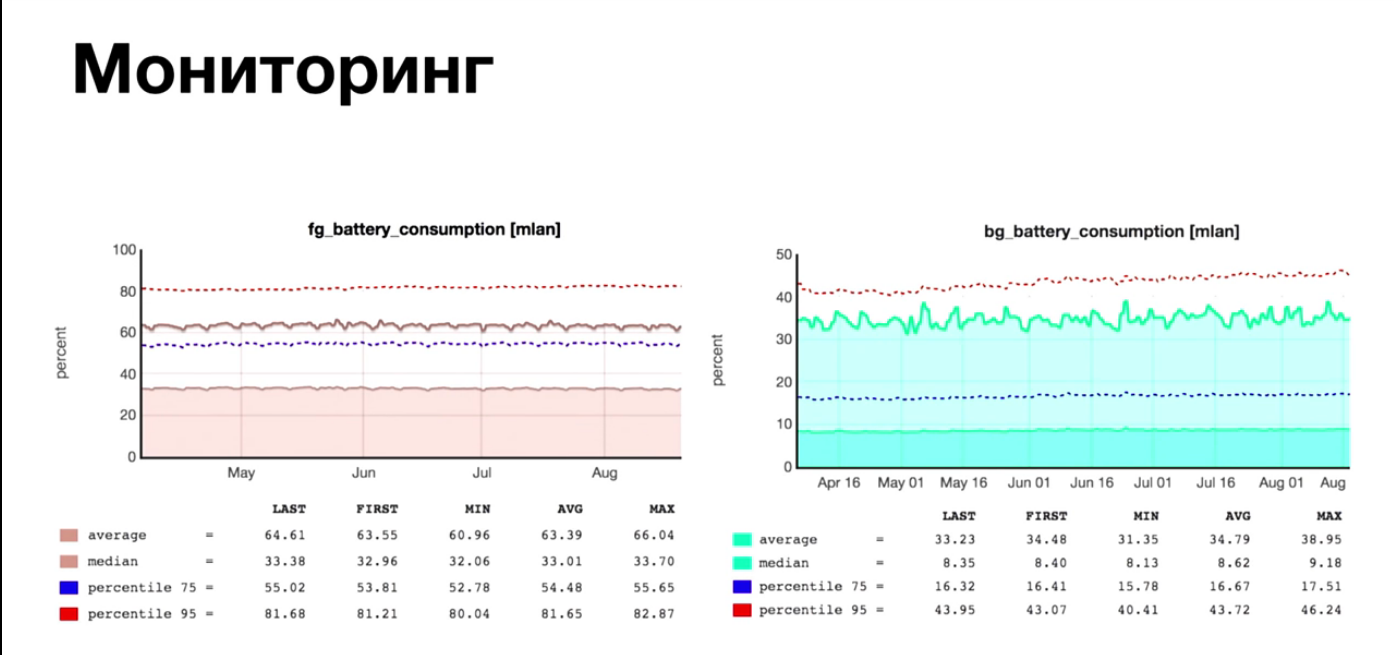
А как же логи потребления электричества? Отличная отсылка к предыдущему докладу Яндекса!

Впрочем, у докладчиков есть и свои читерские приёмы. Например, в Badoo очень сильная команда мониторинга, и они очень хорошо умеют всё это делать.
Рандомные забавные факты!

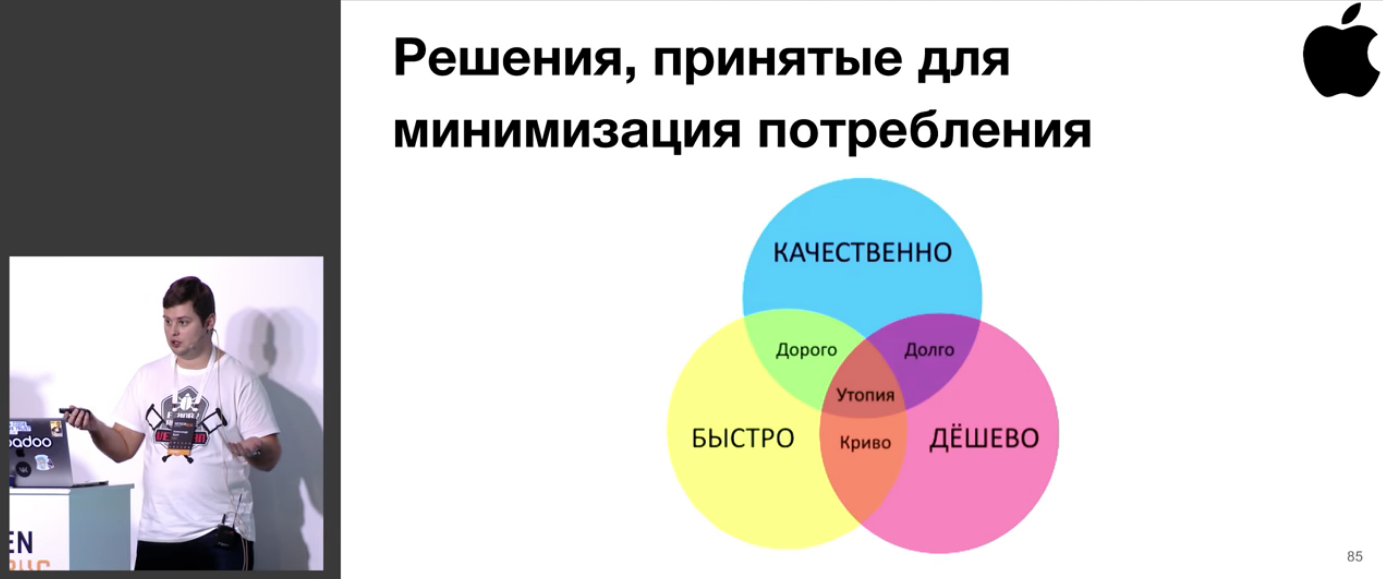
Из чего делается набор выводов по поводу минимизации потребления энергии.
Кроме этого, в докладе есть огромное количество разных интересных вещей, таких как уточнение локации в foreground, реакция на значительные изменения координат, таймауты при работе с сетью, fused location data и многое другое.
Отличный, живой и понятный рассказ о том, как можно и нужно работать с сервисами геолокации, если уж вы решились взяться за это всерьёз!
Спикер: Андрей Солнцев; оценка: 4,57 ± 0,06. Ссылка на презентацию.
Flaky tests — головная боль автотестеров. Ещё вчера тест был зелёный, а сегодня он вдруг покраснел — ни с того ни с сего. Никто ничего не менял. Просто луна не в той фазе. У Андрея есть своя собственная коллекция таких тестов, о которых и пойдёт речь в докладе. Общий смысл доклада — научиться писать тесты так, чтобы они были стабильными и независимыми от кармы разработчика.
Когда-то я был адептом алкокодинга, поэтому очень котирую первый слайд:

Flaky-тест — это тест, который падает только иногда.
И такого непотребства у всех дофига. Чем, наверное, и объясняется популярность доклада и его попадание на второе место рейтинга.

Однако даже 1,5% тестов — это уже очень плохо. Нужно их перезапускать руками и изучать.
План доклада примерно таков:

Доклад изобилует примерами, выглядящими как паззлеры. Поэтому спойлерить я их не буду, а просто приведу пример:

Ну и конечно, для каждого из примеров есть какие-то хорошие лекарства:

Будет пример про nbob (посмотрите сами, что там!), пример на фантомные числа, несоответствие версии Java, «проклятие зелёной кнопки» (нажимаем кнопку, а перехода на следующую страницу нет), зависания Chrome и многое другое.
Для некоторых вещей нужно глубокое понимание вопроса, а для кое-чего хватит обычной житейской мудрости:
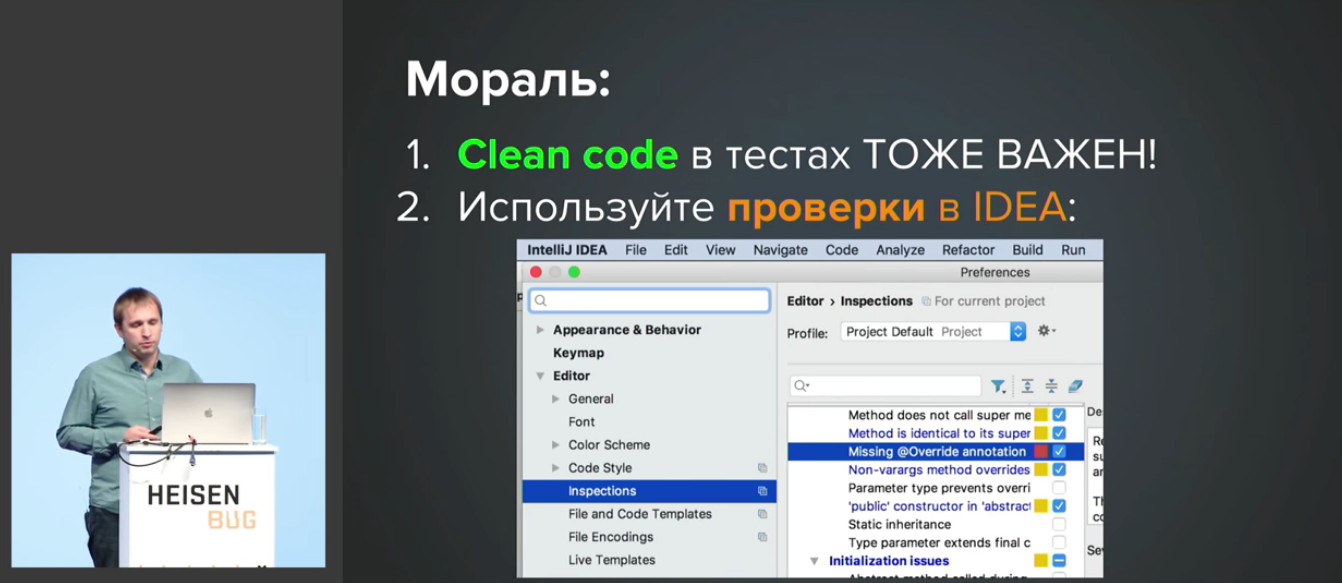

Всё это заканчивается подробным подведением итогов и вот этой жизнеутверждающей мыслью:

Спикер: Александр Шуков; оценка: 4,61 ± 0,11. Ссылка на презентацию.
У меня был некий соблазн для самого лучшего доклада вообще ничего не писать, а сказать: «Это сюрприз, идите смотреть сами». Но это как-то нечестно, верно?
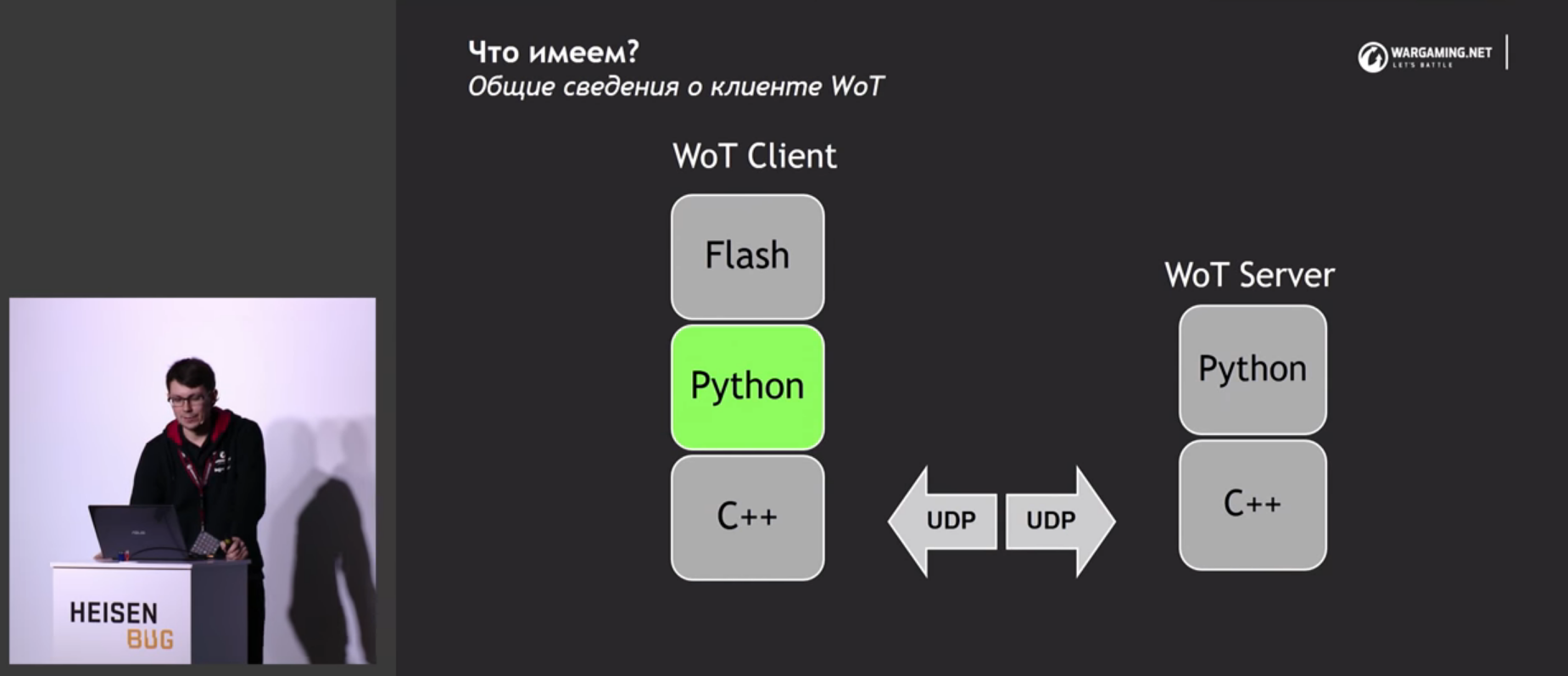
Этот доклад об общих проблемах и подходах автоматизации тестирования в GameDev на примере проекта World of Tanks. Александр расскажет, как, перепробовав всё (от кликеров до инъекций кода в клиент-сервер), они пришли к «bot-net» – тестовому фреймворку для «World of Tanks» со сценариями тестов на Python. Там же рассматривается его устройство и применение.
Доклад больше фокусируется на вопросах построения инфраструктуры и среды для тестов, чем на самих тестах для игр.
Вообще, тесты для игр — очень интересная штука. Во-первых, все мы, наверное, во что-то играем (я в Overwatch, например). Во-вторых, несколько лет назад получилось вписаться в разработку нескольких MMO-игр, и там сразу же стало понятно, насколько это сложное и необычное занятие, в корне отличающееся от разработки банковского софта, например.
По докладу нас будет вести Александр — технический лид автотестеров в World of Tanks.

Доклад будет примерно вот об этом:

Интересная мысль о том, что MMO двигают прогресс. У меня к ММО, как к будущему индустрии, сложилось скорее скептическое отношение, но… послушаем, что говорит гуру :)

Одна из важнейших проблем — монолитность в играх.

Например, моя первая большая игра была на PHP, и она вначале действительно была монолитной, но в этом был некий дополнительный толк — разрабатывать монолит гораздо проще.
И следующее из этого отсутствие стандартизации.
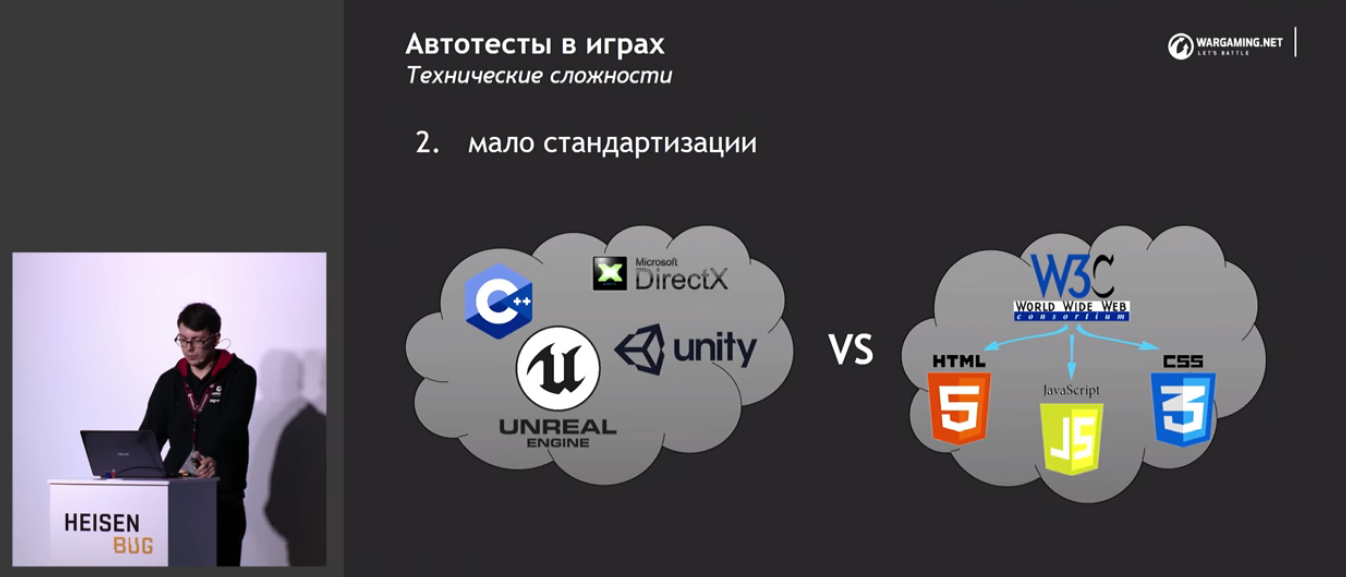
А вот этой проблемы у нас не было, так как наши игры активно использовали веб-интерфейс. Очень соболезную докладчику, что ему не получается использовать эти чудесные наработки.

Ну, и раз у них нет возможности их использовать, начинается разговор, конечно, с кликеров. К сожалению, кликеры не отвечают ни одному критерию хороших автотестов.

Для тестирования ассетов предлагается использовать некий игровой отладчик. Но только для ассетов!

Следующая идея (ни разу не новая, но мощная) — инъекции кода. Прямо в бинарнике WoT есть интерпретатор питона, поэтому его можно слегка поломать и заинжектить свой код.

Конечно, модульные тесты у них тоже есть — со всеми плюсами и минусами. Точнее, как и у всех нормальных людей, у них вначале не было вообще никаких автотестов, а потом появились. Они покрывают ядро: формулы, расчёты, форматы данных и т.п., где очень чётко можно сказать, что хорошо и что плохо.

Проблема в том, что при этом не закрывается уровень интеграционных тестов и выше. Поэтому нужно пилить свой велосипед!
Из этого выявляется список довольно специфичных требований (которые, собственно, и хотелось увидеть в докладе про геймдев):

В результате получилось вот что (по мне так, сформулировано очень сухо, но что есть, то есть):

Зато сразу после этого происходит живая демонстрация, где можно посмотреть, какую именно отладочную информацию пишет их система тестирования.

Проверяется езда по прямой, манёвры, стрельба. Всё это делается не руками, это автотесты. Танчик честно ездит по экрану, показывает графики. Но при этом тест занимает довольно приличное количество времени.
Используется это всё довольно простым и прозрачным образом, об этом на пальцах и рассказывает Александр.

Дальше они начали смотреть, а нельзя ли то же самое сделать как-то ещё лучше, например, сэмулировать клиента. Хотя можно ведь взять сам клиент!

В итоге в копилку способов тестирования добавляется ещё один:

Часть описанных проблем можно решить с помощью headless-клиента.

Дальше возникает вопрос, на каком же языке писать сценарии? Можно писать или на XML, или на одном из языков движка игры: C, C++, C#, Python, LUA.
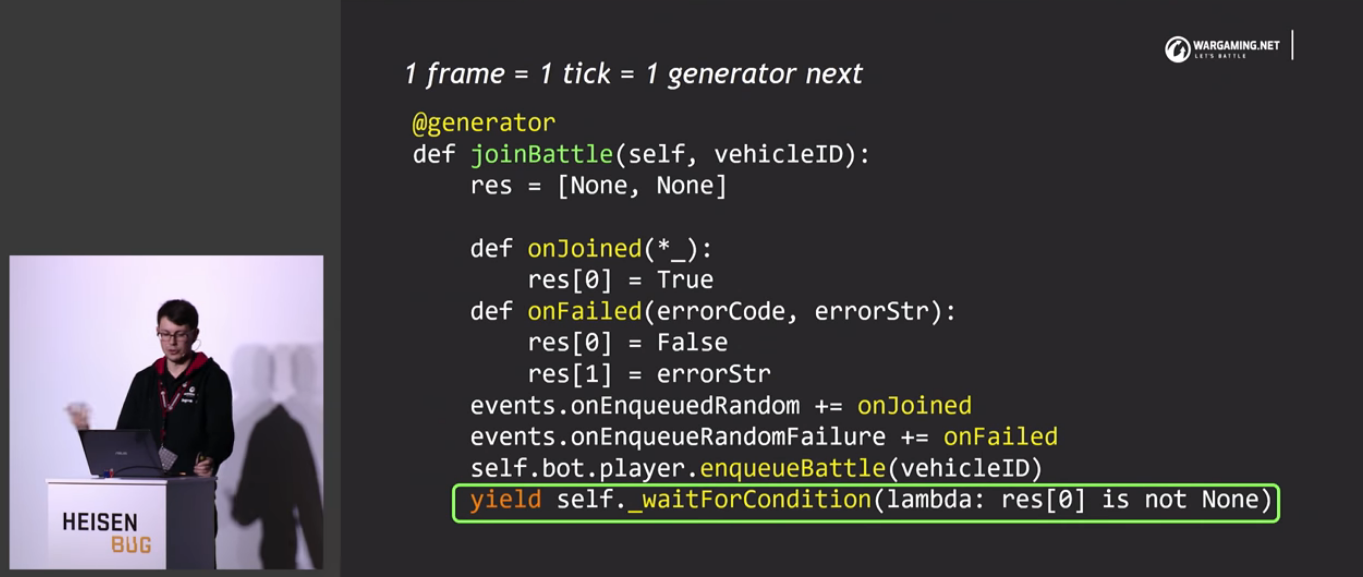
При написании сценариев возник интересный момент. Когда есть тонкий клиент и толстый сервер, всегда нужно ждать ответ от сервера. При этом, если навтыкать в тесты слипы на все ответы сервера, то можно развалить рендерер и т.п. К счастью, решение проблемы есть — кооперативная многозадачность.
Они разделили весь код на две части: синхронный код (очень быстро — либо 1 кадр, либо 100 миллисекунд в случае headless, логике не нужно ждать ответа) и асинхронный код.


Кроме того, для поиска багов (точнее, для выгребания большего количества багов, чем на простых автотестах с ассертами) они пользуются контролем шагов и парсингом логов:

Дальше обсуждается список вещей, которые неплохо бы улучшить в их текущем решении.
И наконец, выводы!



Вот и всё. Думаю, что это действительно заслуженно лучший доклад этой конференции. В нём было хорошо практически всё: и систематизация материала, и анализ, и примеры, и способы улучшения, и вообще, этот доклад нужно обязательно смотреть всем, кто хочет протестировать что-то сложнее «крестиков-ноликов».
Минутка рекламы. Как вы, наверное, знаете, мы делаем конференции. Ближайшая конференция по тестированию — Heisenbug 2018 Piter, которая пройдет 17-18 мая 2018 года. Можно туда прийти, послушать доклады (какие доклады там бывают — вы уже увидели в этой статье), вживую пообщаться с практикующими экспертами в области тестирования и разработчиками разных моднейших технологий. Короче, заходите, мы вас ждём.
Комментариев нет:
Отправить комментарий