О статье
Этот пост — небольшая заметка, предназначенная для программистов, которым хочется больше узнать о том, как GPU обрабатывает ветвление. Можно считать её введением в эту тему. Рекомендую для начала просмотреть [1], [2] и [8], чтобы получить представление о том, как в общем виде выглядит модель выполнения GPU, потому что мы будем рассматривать только одну отдельную деталь. Для любопытных читателей в конце поста есть все ссылки. Если найдёте ошибки, то свяжитесь со мной.
Содержание
- О статье
- Содержание
- Словарь
- Чем ядро GPU отличается от ядра ЦП?
- Что такое согласованность/расхождение?
- Примеры обработки маски выполнения
- Выдуманная ISA
- AMD GCN ISA
- AVX512
- Как бороться с расхождением?
- Ссылки
Словарь
- GPU — Graphics processing unit, графический процессор
- Классификация Флинна
- SIMD — Single instruction multiple data, одиночный поток команд, множественный поток данных
- SIMT — Single instruction multiple threads, одиночный поток команд, множественные потоки
- Волна (wave) SIMD — поток, выполняемый в режиме SIMD
- Линия (lane) — отдельный поток данных в модели SIMD
- SMT — Simultaneous multi-threading, одновременная многопоточность (Intel Hyper-threading)[2]
- Множественные потоки пользуются общими вычислительными ресурсами ядра
- IMT — Interleaved multi-threading, чередующаяся многопоточность[2]
- Множественные потоки пользуются общими вычислительными ресурсами ядра, но за такт выполняется только один
- BB — Basic Block, базовый блок — линейная последовательность инструкций с единственным переходом в конце
- ILP — Instruction Level Parallelism, параллелизм на уровне инструкций[3]
- ISA — Instruction Set Architecture, архитектура набора команд/инструкций
В своём посте я буду придерживаться этой придуманной классификации. Она приблизительно напоминает то, как организован современный GPU.
Оборудование:
GPU -+
|- ядро 0 -+
| |- волна 0 +
| | |- линия 0
| | |- линия 1
| | |- ...
| | +- линия Q-1
| |
| |- ...
| +- волна M-1
|
|- ...
+- ядро N-1
* АЛУ - АЛУ SIMD
Программное обеспечение:
группа +
|- поток 0
|- ...
+- поток N-1
Другие названия:
- Ядро может называться CU, SM, EU
- Волна может называться фронтом волны (wavefront), аппаратным потоком (HW thread), warp, контекстом (context)
- Линия может называться программным потоком (SW thread)
Чем ядро GPU отличается от ядра ЦП?
Любое текущее поколение ядер GPU менее мощно, чем центральные процессоры: простые ILP/multi-issue[6] и предвыборка[5], никакого прогнозирования или предсказания переходов/возвратов. Всё это наряду с крошечным кэшами освобождает довольно большую площадь на кристалле, которая заполняется множеством ядер. Механизмы загрузки/хранения памяти способны справляться с шириной канала на порядок величин больше (это не относится к интегрированным/мобильным GPU), чем обычные ЦП, но за это приходится расплачиваться высокими задержками. Для сокрытия задержек GPU использует SMT[2] — пока одна волна простаивает, другие пользуются свободными вычислительными ресурсами ядра. Обычно количество обрабатываемых одним ядром волн зависит от используемых регистров и определяется динамически, выделением фиксированного файла регистров[8]. Планирование выполнения инструкций гибридное — динамически-статическое[6] [11 4.4]. SMT-ядра, выполняемые в режиме SIMD, достигают высоких значений FLOPS (FLoating-point Operations Per Second, флопс, количество операций с плавающей запятой в секунду).
Легенда диаграммы. Чёрный — неактивно, белый — активно, серый — отключено, синий — простаивает, красный — в ожидании

Рисунок 1. История выполнения 4:2
На изображении показана история маски выполнения, где на оси x отложено время, идущее слева направо, а на оси y — идентификатор линии, идущий сверху вниз. Если вам это пока вам непонятно, то вернитесь к рисунку после прочтения следующих разделов.
Это иллюстрация того, как история выполнения ядра GPU может выглядеть в вымышленной конфигурации: четыре волны совместно используют один сэмплер и два АЛУ. Планировщик волн в каждом цикле выпускает по две инструкции от двух волн. Когда волна простаивает при выполнении доступа к памяти или долгой операции АЛУ, планировщик переключается на другую пару волн, благодаря чему АЛУ постоянно заняты почти на 100%.

Рисунок 2. История выполнения 4:1
Пример с такой же нагрузкой, но на этот раз в каждом цикле инструкции выпускает только одна волна. Заметьте, что второе АЛУ «голодает».
Рисунок 3. История выполнения 4:4
На этот раз в каждом цикле выпускаются по четыре инструкции. Заметьте, что к АЛУ теперь слишком много запросов, поэтому две волны почти постоянно ожидают (на самом деле это ошибка алгоритма планирования).
Обновление Подробнее о трудностях планирования выполнения инструкций можно прочитать в [12].
В реальном мире GPU имеют разные конфигурации ядра: у некоторых может быть до 40 волн на ядро и 4 АЛУ, у других фиксированные 7 волн и 2 АЛУ. Всё это зависит от множества факторов и определяется благодаря кропотливому процессу симуляции архитектуры.
Кроме того, у реальных АЛУ SIMD может быть более узкая ширина, чем у обслуживаемых ими волн, и тогда для обработки одной выпущенной инструкции требуется несколько циклов; множитель называется длиной «chime»[3].
Что такое согласованность/расхождение?
Давайте взглянем на следующий фрагмент кода:
Пример 1
uint lane_id = get_lane_id();
if (lane_id & 1) {
// Do smth
}
// Do some more
Здесь мы видим поток инструкций, в котором путь выполнения зависит от идентификатора выполняемой линии. Очевидно, что разные линии имеют разные значения. Что же должно произойти? Существуют разные подходы к решению этой проблемы [4], но в конечном итоге все они делают примерно одно и то же. Один из таких подходов — это маска выполнения, которую я и рассмотрю. Этот подход применялся в GPU Nvidia до Volta и в GPU AMD GCN. Основной смысл маски выполнения заключается в том, что мы храним по биту для каждой линии в волне. Если соответствущий бит выполнения линии имеет значение 0, то для следующей выпущенной инструкции не будут затрагиваться никакие регистры. По сути, линия не должна ощущать влияния всей выполненной инструкции, потому что её бит выполнения равен 0. Это работает следующим образом: волна проходит по графу потока управления в порядке поиска в глубину, сохраняя историю выбранных переходов, пока биты не заданы. Думаю, это лучше показать на примере.
Допустим, у нас есть волны шириной 8. Вот как выглядит маска выполнения для фрагмента кода:
Пример 1. История маски выполнения
// execution mask
uint lane_id = get_lane_id(); // 11111111
if (lane_id & 1) { // 11111111
// Do smth // 01010101
}
// Do some more // 11111111
Теперь рассмотрим более сложные примеры:
Пример 2
uint lane_id = get_lane_id();
for (uint i = lane_id; i < 16; i++) {
// Do smth
}
Пример 3
uint lane_id = get_lane_id();
if (lane_id < 16) {
// Do smth
} else {
// Do smth else
}
Можно заметить, что история необходима. При использовании подхода с маской выполнения оборудование обычно применяет какой-нибудь вид стека. Наивный подход заключается в хранении стека кортежей (exec_mask, address) и добавлении инструкций схождения, которые извлекают маску из стека и изменяют указатель инструкции для волны. В этом случае волна будет иметь достаточно информации для обхода всей CFG для каждой линии.
С точки зрения производительности только для обработки инструкции потока управления требуется пара циклов из-за всего этого хранения данных. И не забывайте, что стек имеет ограниченную глубину.
Обновление. Благодаря @craigkolb я прочитал статью [13], в которой замечается, что инструкции fork/join AMD GCN сначала выбирают путь из меньшего количества потоков [114.6], что гарантирует достаточность глубины стека масок, равной log2.
Обновление. Очевидно, что почти всегда можно встроить всё в шейдер/структурировать CFG в шейдере, а потому хранить всю историю масок выполнения в регистрах и планировать обход/схождение CFG статически[15]. Просмотрев LLVM-бэкенд для AMDGPU, я не нашёл никаких свидетельств обработки стеков, постоянно выпускаемых компилятором.
Аппаратная поддержка маски выполнения
Теперь взгляните на эти графы потоков управления из Википедии:

Рисунок 4. Некоторые из видов графов потоков управления
Какое же минимальное множество инструкций управления масками нам необходимо для обработки всех случаев? Вот как это выглядит в моей искусственной ISA с неявным распараллеливанием, явным управлением масками и полностью динамической синхронизацией конфликтов данных:
push_mask BRANCH_END ; Push current mask and reconvergence pointer
pop_mask ; Pop mask and jump to reconvergence instruction
mask_nz r0.x ; Set execution bit, pop mask if all bits are zero
; Branch instruction is more complicated
; Push current mask for reconvergence
; Push mask for (r0.x == 0) for else block, if any lane takes the path
; Set mask with (r0.x != 0), fallback to else in case no bit is 1
br_push r0.x, ELSE, CONVERGE
Давайте взглянем, как может выглядеть случай d).
A:
br_push r0.x, C, D
B:
C:
mask_nz r0.y
jmp B
D:
ret
Я не специалист в анализе потоков управления или проектировании ISA, поэтому я уверен, что существует случай, с которым моя искусственная ISA справиться не сможет, но это не важно, потому что структурированной CFG должно быть достаточно для всех.
Обновление. Подробнее прочитать о поддержке GCN инструкций потоков управления можно здесь: [11] ch.4, а о реализации LLVM — здесь: [15].
Вывод:
- Расхождение — возникающее различие в путях выполнения, выбранных разными линиями одной волны
- Согласованность — отсутствие расхождения.
Примеры обработки маски выполнения
Вымышленная ISA
Я скомпилировал предыдущие фрагменты кода в своей искусственной ISA и запустил их на симуляторе в SIMD32. Посмотрите, как он обрабатывает маску выполнения.
Обновление. Заметьте, что искусственный симулятор всегда выбирает путь true, а это не самый лучший способ.
Пример 1
; uint lane_id = get_lane_id();
mov r0.x, lane_id
; if (lane_id & 1) {
push_mask BRANCH_END
and r0.y, r0.x, u(1)
mask_nz r0.y
LOOP_BEGIN:
; // Do smth
pop_mask ; pop mask and reconverge
BRANCH_END:
; // Do some more
ret

Рисунок 5. История выполнения примера 1
Вы заметили чёрную область? Это время, потраченное впустую. Некоторые линии ждут, пока другие завершать итерацию.
Пример 2
; uint lane_id = get_lane_id();
mov r0.x, lane_id
; for (uint i = lane_id; i < 16; i++) {
push_mask LOOP_END ; Push the current mask and the pointer to reconvergence instruction
LOOP_PROLOG:
lt.u32 r0.y, r0.x, u(16) ; r0.y <- r0.x < 16
add.u32 r0.x, r0.x, u(1) ; r0.x <- r0.x + 1
mask_nz r0.y ; exec bit <- r0.y != 0 - when all bits are zero next mask is popped
LOOP_BEGIN:
; // Do smth
jmp LOOP_PROLOG
LOOP_END:
; // }
ret
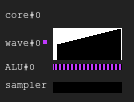
Рисунок 6. История выполнения примера 2
Пример 3
mov r0.x, lane_id
lt.u32 r0.y, r0.x, u(16)
; if (lane_id < 16) {
; Push (current mask, CONVERGE) and (else mask, ELSE)
; Also set current execution bit to r0.y != 0
br_push r0.y, ELSE, CONVERGE
THEN:
; // Do smth
pop_mask
; } else {
ELSE:
; // Do smth else
pop_mask
; }
CONVERGE:
ret

Рисунок 7. История выполнения примера 3
AMD GCN ISA
Обновление. GCN тоже использует явную обработку масок, подробнее об этом можно прочитать здесь: [11 4.x]. Я решил стоит показать несколько примеров с их ISA, благодаря shader-playground это сделать легко. Возможно, когда-нибудь я найду симулятор и удастся получить диаграммы.
Учтите, что компилятор умный, поэтому вы можете получить другие результаты. Я попытался обмануть компилятор, чтобы он не оптимизировал мои ветвления, поместив туда циклы следования за указателями, а затем подчистив ассемблерный код; я не специалист по GCN, поэтому несколько важных nop может быть пропущено.
Также заметьте, что в этих фрагментах не используются инструкции S_CBRANCH_I/G_FORK и S_CBRANCH_JOIN, потому что они просты и компилятор их не поддерживает. Поэтому, к сожалению, не удалось рассмотреть стек масок. Если вы знаете, как заставить компилятор выдавать обработку стеков, то сообщите, пожалуйста, мне.
Обновление. Посмотрите этот доклад @SiNGUL4RiTY о реализации векторизованного потока управления в LLVM-бэкенде, используемом AMD.
Пример 1
; uint lane_id = get_lane_id();
; GCN uses 64 wave width, so lane_id = thread_id & 63
; There are scalar s* and vector v* registers
; Executon mask does not affect scalar or branch instructions
v_mov_b32 v1, 0x00000400 ; 1024 - group size
v_mad_u32_u24 v0, s12, v1, v0 ; thread_id calculation
v_and_b32 v1, 63, v0
; if (lane_id & 1) {
v_and_b32 v2, 1, v0
s_mov_b64 s[0:1], exec ; Save the execution mask
v_cmpx_ne_u32 exec, v2, 0 ; Set the execution bit
s_cbranch_execz ELSE ; Jmp if all exec bits are zero
; // Do smth
ELSE:
; }
; // Do some more
s_mov_b64 exec, s[0:1] ; Restore the execution mask
s_endpgm
Пример 2
; uint lane_id = get_lane_id();
v_mov_b32 v1, 0x00000400
v_mad_u32_u24 v0, s8, v1, v0 ; Not sure why s8 this time and not s12
v_and_b32 v1, 63, v0
; LOOP PROLOG
s_mov_b64 s[0:1], exec ; Save the execution mask
v_mov_b32 v2, v1
v_cmp_le_u32 vcc, 16, v1
s_andn2_b64 exec, exec, vcc ; Set the execution bit
s_cbranch_execz LOOP_END ; Jmp if all exec bits are zero
; for (uint i = lane_id; i < 16; i++) {
LOOP_BEGIN:
; // Do smth
v_add_u32 v2, 1, v2
v_cmp_le_u32 vcc, 16, v2
s_andn2_b64 exec, exec, vcc ; Mask out lanes which are beyond loop limit
s_cbranch_execnz LOOP_BEGIN ; Jmp if non zero exec mask
LOOP_END:
; // }
s_mov_b64 exec, s[0:1] ; Restore the execution mask
s_endpgm
Пример 3
; uint lane_id = get_lane_id();
v_mov_b32 v1, 0x00000400
v_mad_u32_u24 v0, s12, v1, v0
v_and_b32 v1, 63, v0
v_and_b32 v2, 1, v0
s_mov_b64 s[0:1], exec ; Save the execution mask
; if (lane_id < 16) {
v_cmpx_lt_u32 exec, v1, 16 ; Set the execution bit
s_cbranch_execz ELSE ; Jmp if all exec bits are zero
; // Do smth
; } else {
ELSE:
s_andn2_b64 exec, s[0:1], exec ; Inverse the mask and & with previous
s_cbranch_execz CONVERGE ; Jmp if all exec bits are zero
; // Do smth else
; }
CONVERGE:
s_mov_b64 exec, s[0:1] ; Restore the execution mask
; // Do some more
s_endpgm
AVX512
Обновление.@tom_forsyth указал мне, что расширение AVX512 тоже имеет явную обработку масок, поэтому вот несколько примеров. Подробнее об этом можно прочитать в [14], 15.x и 15.6.1. Это не совсем GPU, но у него всё равно есть настоящий SIMD16 с 32 битами. Фрагменты кода созданы с помощью ISPC(–target=avx512knl-i32x16) godbolt и сильно переработаны, поэтому могут быть верными не на 100%.
Пример 1
; Imagine zmm0 contains 16 lane_ids
; AVXZ512 comes with k0-k7 mask registers
; Usage:
; op reg1 {k[7:0]}, reg2, reg3
; k0 can not be used as a predicate operand, only k1-k7
; if (lane_id & 1) {
vpslld zmm0 {k1}, zmm0, 31 ; zmm0[i] = zmm0[i] << 31
kmovw eax, k1 ; Save the execution mask
vptestmd k1 {k1}, zmm0, zmm0 ; k1[i] = zmm0[i] != 0
kortestw k1, k1
je ELSE ; Jmp if all exec bits are zero
; // Do smth
; Now k1 contains the execution mask
; We can use it like this:
; vmovdqa32 zmm1 {k1}, zmm0
ELSE:
; }
kmovw k1, eax ; Restore the execution mask
; // Do some more
ret
Пример 2
; Imagine zmm0 contains 16 lane_ids
kmovw eax, k1 ; Save the execution mask
vpcmpltud k1 {k1}, zmm0, 16 ; k1[i] = zmm0[i] < 16
kortestw k1, k1
je LOOP_END ; Jmp if all exec bits are zero
vpternlogd zmm1 {k1}, zmm1, zmm1, 255 ; zmm1[i] = -1
; for (uint i = lane_id; i < 16; i++) {
LOOP_BEGIN:
; // Do smth
vpsubd zmm0 {k1}, zmm0, zmm1 ; zmm0[i] = zmm0[i] + 1
vpcmpltud k1 {k1}, zmm0, 16 ; masked k1[i] = zmm0[i] < 16
kortestw k1, k1
jne LOOP_BEGIN ; Break if all exec bits are zero
LOOP_END:
; // }
kmovw k1, eax ; Restore the execution mask
; // Do some more
ret
Пример 3
; Imagine zmm0 contains 16 lane_ids
; if (lane_id & 1) {
vpslld zmm0 {k1}, zmm0, 31 ; zmm0[i] = zmm0[i] << 31
kmovw eax, k1 ; Save the execution mask
vptestmd k1 {k1}, zmm0, zmm0 ; k1[i] = zmm0[i] != 0
kortestw k1, k1
je ELSE ; Jmp if all exec bits are zero
THEN:
; // Do smth
; } else {
ELSE:
kmovw ebx, k1
andn ebx, eax, ebx
kmovw k1, ebx ; mask = ~mask & old_mask
kortestw k1, k1
je CONVERGE ; Jmp if all exec bits are zero
; // Do smth else
; }
CONVERGE:
kmovw k1, eax ; Restore the execution mask
; // Do some more
ret
Как бороться с расхождением?
Я попытался создать простую, но полную иллюстрацию того, как возникает неэффективность вследствие комбинирования расходящихся линий.
Представьте простой фрагмент кода:
uint thread_id = get_thread_id();
uint iter_count = memory[thread_id];
for (uint i = 0; i < iter_count; i++) {
// Do smth
}
Давайте создадим 256 потоков и измерим их длительность выполнения:
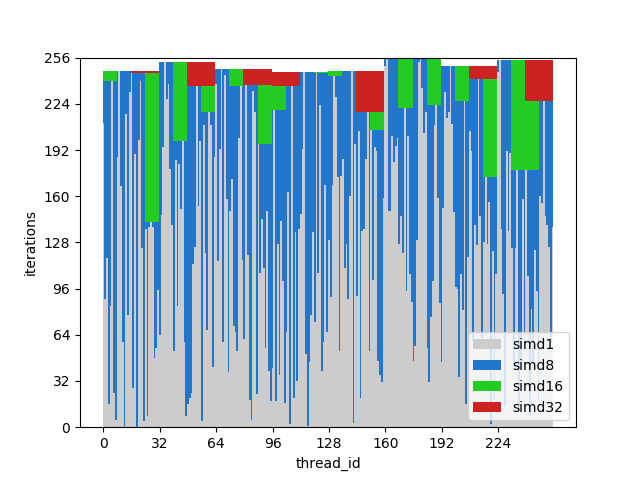
Рисунок 8. Время выполнения расходящихся потоков
Ось x — это идентификатор программного потока, ось y — тактовые циклы; разные столбцы показывают, сколько времени тратится впустую при группировке потоков с разной шириной волн по сравнению с однопоточным выполнением.
Время выполнения волны равно максимальному времени выполнения среди содержащихся в ней линий. Можно увидеть, что производительность сильно падает уже при SIMD8, а дальнейшее расширение просто делает её немного хуже.
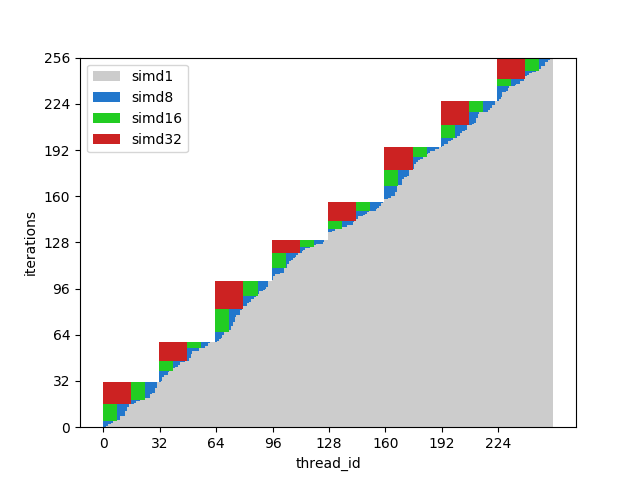
Рисунок 9. Время выполнения согласованных потоков
На этом рисунке показаны те же столбцы, но на этот раз количество итераций отсортировано по идентификаторам потоков, то есть потоки со схожим количеством итераций передаются одной волне.
Для этого примера выполнение потенциально ускоряется примерно вдвое.
Разумеется, пример слишком простой, но я надеюсь, что вы поняли смысл: расхождение при выполнении проистекает из расхождения данных, поэтому CFG должны быть простыми, а данные — согласованными.
Например, если вы пишете трассировщик лучей, вам может дать преимущество группировка лучей с одинаковым направлением и позицией, потому что они скорее всего будут проходить по одинаковым узлам в BVH. Подробнее см. в [10] и других статьях по теме.
Стоит также упомянуть, что существуют техники борьбы с расхождением и на аппаратном уровне например Dynamic Warp Formation[7] и прогнозируемое выполнение для небольших ветвлений.
[1] A trip through the Graphics Pipeline
[2] Kayvon Fatahalian: PARALLEL COMPUTING
[3] Computer Architecture A Quantitative Approach
[4] Stack-less SIMT reconvergence at low cost
[5] Dissecting GPU memory hierarchy through microbenchmarking
[6] Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking
[7] Dynamic Warp Formation and Scheduling for Efficient GPU Control Flow
[8] Maurizio Cerrato: GPU Architectures
[10] Reducing Branch Divergence in GPU Programs
[11] “Vega” Instruction Set Architecture
[12] Joshua Barczak:Simulating Shader Execution for GCN
[13] Tangent Vector: A Digression on Divergence
[14] Intel 64 and IA-32 ArchitecturesSoftware Developer’s Manual
[15] Vectorizing Divergent Control-Flow for SIMD Applications
Комментариев нет:
Отправить комментарий