.map() и .filter() принимают всего один аргумент-коллбэк и позволяют решать простые задачи. Но возникает такое ощущение, что метод .reduce() у многих вызывает определённые затруднения. Понять его немного сложнее.
Я уже писал о том, почему я думаю, что .reduce() создаёт множество проблем. Отчасти это происходит из-за того, что многие руководства демонстрируют использование .reduce() только при обработке чисел. Поэтому я и писал о том, как много задач, не подразумевающих выполнение арифметических операций, можно решать с помощью .reduce(). Но что если вам совершенно необходимо работать именно с числами?
Типичный случай использования .reduce() выглядит как вычисление среднего арифметического значения элементов массива. На первый взгляд кажется, что ничего особенного в этой задаче нет. Но она не так уж и проста. Дело в том, что прежде чем посчитать среднее, нужно найти следующие показатели:
- Общая сумма значений элементов массива.
- Длина массива.
Выяснить всё это довольно просто. А вычисление средних значений для числовых массивов — тоже операция не из сложных. Вот элементарный пример:
function average(nums) {
return nums.reduce((a, b) => (a + b)) / nums.length;
}
Как видите, особых непонятностей тут не наблюдается. Но задача становится тяжелее в том случае, если работать приходится с более сложными структурами данных. Что если у нас имеется массив объектов? Что если некоторые объекты из этого массива нужно отфильтровать? Как быть, если из объектов нужно извлечь некие числовые значения? При таком раскладе вычисление среднего значения для элементов массива — это уже задача немного более сложная.
Для того чтобы с этим разобраться мы решим учебную задачу (она основана на этом задании с FreeCodeCamp). Решим мы её пятью разными способами. У каждого из них есть собственные преимущества и недостатки. Разбор этих пяти подходов к решению данной задачи покажет то, каким гибким может быть JavaScript. И я надеюсь, что анализ решений даст вам пищу для размышлений о том, как использовать .reduce() в реальных проектах.
Обзор задачи
Предположим, что у нас есть массив объектов, описывающих сленговые выражения викторианской эпохи. Нужно отфильтровать те выражения, которые не встречаются в Google Books (свойство
found соответствующих объектов равно false), и найти среднюю оценку популярности выражений. Вот как могут выглядеть подобные данные (они взяты отсюда):
const victorianSlang = [
term: 'doing the bear',
found: true,
popularity: 108,
},
term: 'katterzem',
found: false,
popularity: null,
},
term: 'bone shaker',
found: true,
popularity: 609,
},
term: 'smothering a parrot',
found: false,
popularity: null,
},
term: 'damfino',
found: true,
popularity: 232,
},
term: 'rain napper',
found: false,
popularity: null,
},
term: 'donkey’s breakfast',
found: true,
popularity: 787,
},
term: 'rational costume',
found: true,
popularity: 513,
},
term: 'mind the grease',
found: true,
popularity: 154,
},
];
Рассмотрим 5 способов нахождения среднего значения оценки популярности выражений из этого массива.
1. Решение задачи без использования .reduce() (императивный цикл)
В нашем первом подходе к решению задачи метод
.reduce() использоваться не будет. Если вы раньше не сталкивались с методами для итерирования массивов, тогда, надеюсь, разбор этого примера немного прояснит для вас ситуацию.
let popularitySum = 0;
let itemsFound = 0;
const len = victorianSlang.length;
let item = null;
for (let i = 0; i < len; i++) {
item = victorianSlang[i];
if (item.found) {
popularitySum = item.popularity + popularitySum;
itemsFound = itemsFound + 1;
}
const averagePopularity = popularitySum / itemsFound;
console.log("Average popularity:", averagePopularity);
Если вы знакомы с JavaScript, то вы без особого труда поймёте этот пример. Собственно говоря, здесь происходит следующее:
- Мы инициализируем переменные
popularitySumиitemsFound. Первая переменная,popularitySum, хранит общую оценку популярности выражений. А вторая переменная,itemsFound, (вот уж неожиданность) хранит количество найденных выражений. - Затем мы инициализируем константу
lenи переменнуюitem, которые пригодятся нам при обходе массива. - В цикле
forсчётчикiинкрементируется до тех пор, пока его значение не достигнет значения индекса последнего элемента массива. - Внутри цикла мы берём элемент массива, который хотим исследовать. К элементу обращаемся с помощью конструкции
victorianSlang[i]. - Затем мы выясняем, встречается ли данное выражение в коллекции книг.
- Если выражение в книгах встречается — мы берём значение его рейтинга популярности и прибавляем к значению переменной
popularitySum. - При этом мы ещё и увеличиваем счётчик найденных выражений —
itemsFound. - И, наконец, мы находим среднее значение, деля
popularitySumнаitemsFound.
Итак, с задачей мы справились. Возможно, решение у нас получилось не особенно красивое, но своё дело оно делает. Использование методов для итерирования массивов позволит сделать его немного чище. Давайте взглянем на то, удастся ли нам, и правда, «почистить» это решение.
2. Простое решение №1: .filter(), .map() и нахождение суммы с помощью .reduce()
Давайте, перед первой попыткой воспользоваться методами массивов для решения задачи, разобьём её на небольшие части. А именно, вот что нам нужно сделать:
- Отобрать объекты, представляющие выражения, которые имеются в коллекции Google Books. Тут можно воспользоваться методом
.filter(). - Извлечь из объектов оценки популярности выражений. Для решения этой подзадачи подойдёт метод
.map(). - Вычислить сумму оценок. Здесь мы можем прибегнуть к помощи нашего старого друга
.reduce(). - И, наконец, найти среднее значение оценок.
Вот как это выглядит в коде:
// Вспомогательные функции
// ----------------------------------------------------------------------------
function isFound(item) {
return item.found;
};
function getPopularity(item) {
return item.popularity;
}
function addScores(runningTotal, popularity) {
return runningTotal + popularity;
}
// Вычисления
// ----------------------------------------------------------------------------
// Отфильтровываем выражения, которые не были найдены в книгах.
const foundSlangTerms = victorianSlang.filter(isFound);
// Извлекаем оценки популярности, получая массив чисел.
const popularityScores = foundSlangTerms.map(getPopularity);
// Находим сумму всех оценок популярности. Обратите внимание на то, что второй параметр
// указывает на то, что reduce нужно использовать начальное значение аккумулятора, равное 0.
const scoresTotal = popularityScores.reduce(addScores, 0);
// Вычисляем и выводим в консоль среднее значение.
const averagePopularity = scoresTotal / popularityScores.length;
console.log("Average popularity:", averagePopularity);
Приглядитесь к функции
addScore, и к той строке, где вызывается .reduce(). Обратите внимание на то, что addScore принимает два параметра. Первый, runningTotal, известен как аккумулятор. Он хранит сумму значений. Его значение изменяется каждый раз, когда мы, перебирая массив, выполняем оператор return. Второй параметр, popularity, представляет собой отдельный элемент массива, который мы обрабатываем. В самом начале перебора массива оператор return в addScore ещё ни разу не выполнялся. Это значит, что значение runningTotal ещё не устанавливалось автоматически. Поэтому, вызывая .reduce(), мы передаём этому методу то значение, которое нужно записать в runningTotal в самом начале. Это — второй параметр, переданный .reduce().
Итак, мы применили для решения задачи методы итерирования массивов. Новая версия решения получилась гораздо чище, чем предыдущая. Другими словами, решение получилось более декларативным. Мы не сообщаем JavaScript о том, как именно нужно выполнить цикл, не следим за индексами элементов массивов. Вместо этого мы объявляем простые вспомогательные функции маленького размера и комбинируем их. Всю тяжёлую работу делают за нас методы массивов .filter(), .map() и .reduce(). Такой подход к решению подобных задач оказывается более выразительным. Эти методы массивов гораздо полнее, чем это может сделать цикл, сообщают нам о намерении, заложенном в код.
3. Простое решение №2: использование нескольких аккумуляторов
В предыдущей версии решения мы создали целую кучу промежуточных переменных. Например —
foundSlangTerms и popularityScores. В нашем случае такое решение вполне приемлемо. Но что если мы поставим перед собой более сложную цель, касающуюся устройства кода? Хорошо было бы, если мы могли бы использовать в программе шаблон проектирования «текучий интерфейс» (fluent interface). При таком подходе мы смогли бы объединять в цепочку вызовы всех функций и смогли бы обойтись без промежуточных переменных. Однако тут нас поджидает одна проблема. Обратите внимание на то, что нам необходимо получить значение popularityScores.length. Если мы собираемся объединить всё в цепочку, тогда нужен какой-то другой способ нахождения количества элементов в массиве. Количество элементов в массиве играет роль делителя при вычислении среднего значения. Посмотрим — сможем ли мы так изменить подход к решению задачи, чтобы всё можно было бы сделать путём объединения вызовов методов в цепочку. Мы сделаем это, отслеживая при переборе элементов массива два значения, то есть — используя «двойной аккумулятор».
// Вспомогательные функции
// ---------------------------------------------------------------------------------
function isFound(item) {
return item.found;
};
function getPopularity(item) {
return item.popularity;
}
// Для представления нескольких значений, возвращаемых return, мы используем объект.
function addScores({totalPopularity, itemCount}, popularity) {
return {
totalPopularity: totalPopularity + popularity,
itemCount: itemCount + 1,
};
}
// Вычисления
// ---------------------------------------------------------------------------------
const initialInfo = {totalPopularity: 0, itemCount: 0};
const popularityInfo = victorianSlang.filter(isFound)
.map(getPopularity)
.reduce(addScores, initialInfo);
// Вычисляем и выводим в консоль среднее значение.
const {totalPopularity, itemCount} = popularityInfo;
const averagePopularity = totalPopularity / itemCount;
console.log("Average popularity:", averagePopularity);
Здесь мы, для работы с двумя значениями, воспользовались в функции-редьюсере объектом. При каждом проходе по массиву, выполняемом с помощью
addScrores, мы обновляем общее значение рейтинга популярности и количество элементов. Важно обратите внимание на то, что эти два значения представлены в виде одного объекта. При таком подходе мы можем «обмануть» систему и хранить две сущности внутри одного возвращаемого значения.
Функция addScrores получилась немного более сложной, чем функция с таким же именем предыдущего примера. Но теперь оказывается так, что мы можем использовать единственную цепочку вызовов методов для выполнения всех операций с массивом. В результате обработки массива получается объект popularityInfo, который хранит всё, что нужно для нахождения среднего. Это делает цепочку вызовов аккуратной и простой.
Если вы чувствуете в себе желание улучшить этот код, то вы можете с ним поэкспериментировать. Например — можете переделать его так, чтобы избавиться от множества промежуточных переменных. Этот код можно даже попытаться уложить в одну строчку.
4. Композиция функций без использования точечной нотации
Если вы — новичок в функциональном программировании, или если вам кажется, что функциональное программирование — это слишком сложно, вы можете пропустить этот раздел. Его разбор принесёт вам пользу в том случае, если вы уже знакомы с
curry() и compose(). Если вы хотите углубиться в данную тему — взгляните на этот материал о функциональном программировании на JavaScript, и, в частности, на третью часть серии, в которую он входит.
Мы — программисты, которые придерживаются функционального подхода. Это значит, что мы стремимся к тому, чтобы строить сложные функции из других функций — маленьких и простых. До сих пор мы, в ходе рассмотрения разных вариантов решения задачи, уменьшали количество промежуточных переменных. В результате код решения становился всё проще и проще. Но что если довести эту идею до крайности? Что если попытаться избавиться от всех промежуточных переменных? И даже попробовать уйти от некоторых параметров?
Можно создать функцию для вычисления среднего значения с использованием одной лишь функции compose(), без использования переменных. Мы называем это «программированием без использования точеной нотации» или «неявным программированием». Для того чтобы писать подобные программы понадобится множество вспомогательных функций.
Иногда такой код шокирует людей. Это происходит из-за того, что подобный подход сильно отличается от общепринятого. Но я выяснил, что написание кода в стиле неявного программирования является одним из самых быстрых способов вникнуть в сущность функционального программирования. Поэтому я могу вам посоветовать попробовать эту методику в каком-нибудь личном проекте. Но хочу сказать, что, возможно, не стоит писать в стиле неявного программирования тот код, который придётся читать другим людям.
Итак, вернёмся к нашей задаче по построению системы вычисления средних значений. Ради экономии места мы перейдём здесь на использование стрелочных функций. Обычно, как правило, лучше использовать именованные функции. Вот хорошая статья на эту тему. Это позволяет получить более качественные результаты трассировки стека в случае возникновения ошибок.
// Вспомогательные функции
// ----------------------------------------------------------------------------
const filter = p => a => a.filter(p);
const map = f => a => a.map(f);
const prop = k => x => x[k];
const reduce = r => i => a => a.reduce(r, i);
const compose = (...fns) => (arg) => fns.reduceRight((arg, fn) => fn(arg), arg);
// Это - так называемый "blackbird combinator".
// Почитать о нём можно здесь: https://jrsinclair.com/articles/2019/compose-js-functions-multiple-parameters/
const B1 = f => g => h => x => f(g(x))(h(x));
// Вычисления
// ----------------------------------------------------------------------------
// Создадим функцию sum, которая складывает элементы массива.
const sum = reduce((a, i) => a + i)(0);
// Функция для получения длины массива.
const length = a => a.length;
// Функция для деления одного числа на другое.
const div = a => b => a / b;
// Мы используем compose() для сборки нашей функции из маленьких вспомогательных функций.
// При работе с compose() код надо читать снизу вверх.
const calcPopularity = compose(
B1(div)(sum)(length),
map(prop('popularity')),
filter(prop('found')),
);
const averagePopularity = calcPopularity(victorianSlang);
console.log("Average popularity:", averagePopularity);
Если весь этот код кажется вам полной бессмыслицей — не беспокойтесь об этом. Я включил его сюда в виде интеллектуального упражнения, а не для того, чтобы вас расстраивать.
В данном случае основная работа идёт в функции compose(). Если прочесть её содержимое снизу вверх, то окажется, что вычисления начинаются с фильтрации массива по свойству его элементов found. Затем мы извлекаем свойство элементов popularity с помощью map(). После этого мы используем так называемый «blackbird combinator». Эта сущность представлена в виде функции B1, которая используется для выполнения двух проходов вычислений над одним набором входных данных. Для того чтобы лучше в этом разобраться, взгляните на эти примеры:
// Все строки кода, представленные ниже, эквивалентны:
const avg1 = B1(div)(sum)(length);
const avg2 = arr => div(sum(arr))(length(arr));
const avg3 = arr => ( sum(arr) / length(arr) );
const avg4 = arr => arr.reduce((a, x) => a + x, 0) / arr.length;
Опять же, если вы снова ничего не поняли — не беспокойтесь. Это — просто демонстрация того, что на JavaScript можно писать очень разными способами. Из таких вот особенностей и складывается красота этого языка.
5. Решение задачи за один проход с вычислением кумулятивного среднего значения
Все вышеприведённые программные конструкции хорошо справляются с решением нашей задачи (включая императивный цикл). Те из них, в которых используется метод
.reduce(), имеют кое-что общее. Они основаны на разбиении проблемы на небольшие фрагменты. Эти фрагменты потом различными способами компонуются. Анализируя эти решения, вы могли заметить, что в них мы обходим массив три раза. Возникает такое чувство, что это неэффективно. Хорошо было бы, если бы существовал способ обработки массива и выдачи результата за один проход. Такой способ существует, но его применение потребует прибегнуть к математике.
Для того чтобы вычислить среднее значение для элементов массива за один проход, нам понадобится новый метод. Нужно найти способ вычисления среднего с использованием ранее вычисленного среднего и нового значения. Поищем этот способ с помощью алгебры.
Среднее значение n чисел можно найти, воспользовавшись такой формулой:
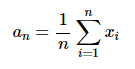
Для того чтобы узнать среднее
n + 1 чисел подойдёт та же формула, но в другой записи:

Эта формула представляет собой то же самое, что вот это:
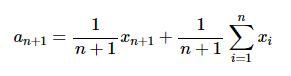
И то же самое, что это:
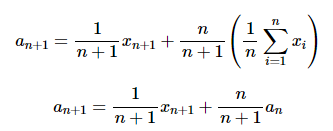
Если немного это преобразовать, то получится следующее:
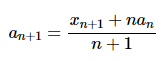
Если вы не видите во всём этом смысла — ничего страшного. Итог всех этих преобразований сводится к тому, что с помощью последней формулы мы можем рассчитывать среднее значение в процессе однократного обхода массива. Для этого нужно знать значение текущего элемента, среднее значение, вычисленное на предыдущем шаге, и число элементов. Кроме того, большинство вычислений можно вынести в функцию-редьюсер:
// Функция для вычисления среднего значения
// ----------------------------------------------------------------------------
function averageScores({avg, n}, slangTermInfo) {
if (!slangTermInfo.found) {
return {avg, n};
return {
avg: (slangTermInfo.popularity + n * avg) / (n + 1),
n: n + 1,
};
}
// Вычисления
// ----------------------------------------------------------------------------
// Вычисляем и выводим в консоль среднее значение.
const initialVals = {avg: 0, n: 0};
const averagePopularity = victorianSlang.reduce(averageScores, initialVals).avg;
console.log("Average popularity:", averagePopularity);
Благодаря использованию этого подхода необходимое значение можно найти, обойдя массив всего один раз. Другие подходы используют один проход для фильтрации массива, ещё один — для извлечения из него нужных данных, и ещё один — для нахождения суммы значений элементов. Здесь же всё укладывается в один проход по массиву.
Обратите внимание на то, что это необязательно делает вычисления более эффективными. При таком подходе приходится выполнять больше вычислений. Мы, при поступлении каждого нового значения, выполняем операции умножения и деления, делая это для поддержания текущего значения среднего в актуальном состоянии. В других вариантах решения этой задачи мы делим одно число на другое лишь один раз — в конце программы. Но такой подход гораздо эффективнее в плане использования памяти. Промежуточные массивы здесь не используются, в результате нам приходится хранить в памяти лишь объект с двумя значениями.
Однако такая вот эффективность использования памяти имеет определённую цену. Теперь в одной функции мы выполняем три действия. Мы в ней фильтруем массив, извлекаем число и пересчитываем результат. Это усложняет функцию. В результате, взглянув на код, уже не так просто его понять.
Что выбрать?
Какой же из рассмотренных выше пяти подходов к решению задачи можно назвать самым лучшим? На самом деле, это зависит от многих факторов. Возможно, вам нужно обработать по-настоящему длинный массив. Или, возможно, вашему коду нужно выполняться на платформе, на которой доступно не особенно много памяти. В подобных случаях имеет смысл воспользоваться тем решением задачи, где обработка массива выполняется за один проход. Но если системные ограничения роли не играют, тогда можно с успехом пользоваться более выразительными подходами к решению задачи. Программисту нужно проанализировать собственную ситуацию и принять решение о том, что лучше всего подходит его приложению, что наиболее целесообразно использовать в его обстоятельствах.
Возможно, у кого-то сейчас возникнет вопрос о том, есть ли способ объединения преимуществ разных подходов к решению подобной задачи. Можно ли разбить задачу на мелкие части, но выполнять все вычисления за один проход по массиву? Сделать это можно. Для этого понадобится применить концепцию трансдьюсеров. Это — отдельная большая тема.
Итоги
Мы рассмотрели пять способов вычисления среднего для элементов массива:
- Без использования
.reduce(). - С использованием методов
.filter()и.map(), а также — метода.reduce()в роли механизма для нахождения суммы чисел. - С использованием аккумулятора, являющегося объектом и хранящего несколько значений.
- С применением методики неявного программирования.
- С вычислением кумулятивного среднего при однократном проходе по массиву.
Что же, всё-таки, стоит выбрать для практического применения? На самом деле — вам решать. Но если вы хотите найти какую-то подсказку — поделюсь своим мнением о том, как можно принять решение о наиболее подходящем способе решения задачи:
- Начните с использования подхода, который вы понимаете лучше всего. Если он позволяет достичь цели — остановитесь на нём.
- Если существует некий подход, который вы не понимаете, но хотите изучить — решите задачу с его помощью.
- И, наконец, если вы столкнулись с проблемой нехватки памяти — попробуйте тот вариант, где массив обходится один раз.
Уважаемые читатели! Как вы чаще всего обрабатываете массивы в JavaScript-проектах?

Комментариев нет:
Отправить комментарий