Всем привет. В этой статье я расскажу, почему мы в Авито девять месяцев назад выбрали Kafka, и что она из себя представляет. Поделюсь одним из кейсов использования — брокер сообщений. И напоследок поговорим о том, какие плюсы мы получили от применения подхода Kafka as a Service.

Для начала немного контекста. Некоторое время назад мы начали уходить от монолитной архитектуры, и сейчас в Авито уже несколько сотен различных сервисов. Они имеют свои хранилища, свой стек технологий и отвечают за свою часть бизнес-логики.
Одна из проблем с большим числом сервисов — коммуникации. Сервис А часто хочет узнать информацию, которой располагает сервис Б. В этом случае сервис А обращается к сервису Б через синхронный API. Сервис В хочет знать, что происходит у сервисов Г и Д, а те, в свою очередь, интересуются сервисами А и Б. Когда таких «любопытных» сервисов становится много, связи между ними превращаются в запутанный клубок.
При этом в любой момент сервис А может стать недоступен. И что делать в этом случае сервису Б и всем остальным завязанным на него сервисам? А если для выполнения бизнес-операции необходимо совершить цепочку последовательных синхронных вызовов, вероятность отказа всей операции становится еще выше (и она тем выше, чем длиннее эта цепочка).

Окей, проблемы понятны. Устранить их можно, сделав централизованную систему обмена сообщениями между сервисами. Теперь каждому из сервисов достаточно знать только про эту систему обмена сообщениями. В дополнение сама система должна обладать свойствами отказоустойчивости и горизонтальной масштабируемостью, а также случае аварий копить в себе буфер обращения для последующей их обработки.
Давайте теперь выберем технологию, на которой будет реализована доставка сообщений. Для этого сперва поймем, чего мы от нее ожидаем:
- сообщения между сервисами не должны теряться;
- сообщения могут дублироваться;
- сообщения можно хранить и читать на глубину в несколько дней (персистентный буфер);
- сервисы могут подписаться на интересующие их данные;
- несколько сервисов могут читать одни и те же данные;
- сообщения могут содержать детализированный, объемный payload (event-carried state transfer);
- иногда нужна гарантия порядка сообщений.
Также нам критически важно было выбрать максимально масштабируемую и надежную систему с высокой пропускной способностью (не менее 100k сообщений по несколько килобайт в секунду).
На этом этапе мы распрощались с RabbitMQ (сложно сохранять стабильным на высоких rps), PGQ от SkyTools (недостаточно быстрый и плохо масштабируемый) и NSQ (не персистентный). Все эти технологии у нас в компании используются, но под решаемую задачу они не подошли.
Далее мы начали смотреть на новые для нас технологии — Apache Kafka, Apache Pulsar и NATS Streaming.
Первым отбросили Pulsar. Мы решили, что Kafka и Pulsar — довольно похожие между собой решения. И несмотря на то, что Pulsar проверен крупными компаниями, новее и предлагает более низкую latency (в теории), мы решили из этих двух оставить Kafka, как de facto стандарт для таких задач. Вероятно, мы вернемся к Apache Pulsar в будущем.
И вот остались два кандидата: NATS Streaming и Apache Kafka. Мы довольно подробно изучили оба решения, и оба они подошли под задачу. Но в итоге мы побоялись относительной молодости NATS Streaming (и того, что один из основных разработчиков, Tyler Treat, решил уйти из проекта и начать свой собственный — Liftbridge). При этом Clustering режим NATS Streaming не давал возможности сильного горизонтального масштабирования (вероятно, это уже не проблема после добавления partitioning режима в 2017 году).
Тем не менее, NATS Streaming – крутая технология, написанная на Go и имеющая поддержку Cloud Native Computing Foundation. В отличие от Apache Kafka ей не нужен Zookeeper для работы (возможно скоро можно будет сказать то же самое и о Kafka), так как внутри она реализует RAFT. При этом NATS Streaming проще в администрировании. Мы не исключаем, что в дальнейшем ещё вернемся к этой технологии.
И всё-таки на сегодняшний день нашим победителем стала Apache Kafka. На наших тестах она показала себя достаточно быстрой (более миллиона сообщений в секунду на чтение и на запись при объеме сообщений 1 килобайт), достаточно надежной, хорошо масштабируемой и проверенной опытом в проде крупными компаниями. Кроме этого, Kafka поддерживает как минимум несколько крупных коммерческих компаний (мы, например, пользуемся Confluent версией), а также Kafka имеет развитую экосистему.
Перед тем как начать, сразу порекомендую отличную книгу — «Kafka: The Definitive Guide» (есть и в русском переводе, но термины немного ломают мозг). В ней можно найти информацию, необходимую для базового понимания Kafka и даже немного больше. Сама документация от Apache и блог от Confluent также отлично написаны и легко читаются.
Итак, давайте посмотрим на то, как устроена Kafka с высоты птичьего полета. Базовая топология Kafka состоит из producer, consumer, broker и zookeeper.
Broker

За хранение ваших данных отвечает брокер (broker). Все данные хранятся в бинарном виде, и брокер мало знает про то, что они из себя представляют, и какова их структура.
Каждый логический тип событий обычно находится в своем отдельном топике (topic). Например, событие создания объявления может попадать в топик item.created, а событие его изменения — в item.changed. Топики можно рассматривать как классификаторы событий. На уровне топика можно задать такие конфигурационные параметры, как:
- объем хранимых данных и/или их возраст (retention.bytes, retention.ms);
- фактор избыточности данных (replication factor);
- максимальный размер одного сообщения (max.message.bytes);
- минимальное число согласованных реплик, при котором в топик можно будет записать данные (min.insync.replicas);
- возможность провести failover на не синхронную отстающую реплику с потенциальной потерей данных (unclean.leader.election.enable);
- и еще много других (https://kafka.apache.org/documentation/#topicconfigs).
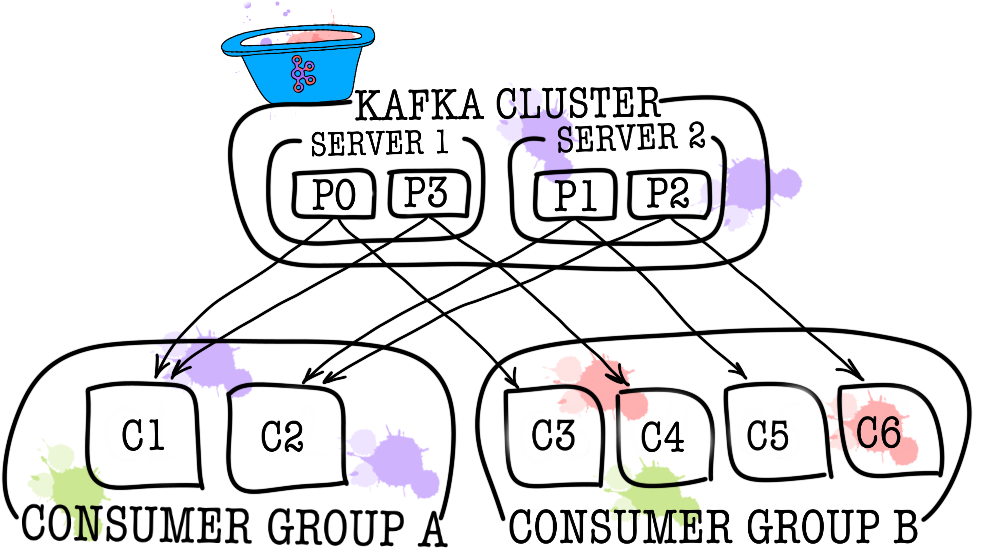
В свою очередь каждый топик разбивается на одну и более партицию (partition). Именно в партиции в итоге попадают события. Если в кластере более одного брокера, то партиции будут распределены по всем брокерам равномерно (насколько это возможно), что позволит масштабировать нагрузку на запись и чтение в один топик сразу на несколько брокеров.
На диске данные для каждой партиции хранятся в виде файлов сегментов, по умолчанию равных одному гигабайту (контролируется через log.segment.bytes). Важная особенность — удаление данных из партиций (при срабатывании retention) происходит как раз сегментами (нельзя удалить одно событие из партиции, можно удалить только целый сегмент, причем только неактивный).
Zookeeper
Zookeeper выполняет роль хранилища метаданных и координатора. Именно он способен сказать, живы ли брокеры (посмотреть на это глазами zookeeper можно через zookeeper-shell командой ls /brokers/ids), какой из брокеров является контроллером (get /controller), находятся ли партиции в синхронном состоянии со своими репликами (get /brokers/topics/topic_name/partitions/partition_number/state). Также именно к zookeeper сперва пойдут producer и consumer чтобы узнать, на каком брокере какие топики и партиции хранятся. В случаях, когда для топика задан replication factor больше 1, zookeeper укажет, какие партиции являются лидерами (в них будет производиться запись и из них же будет идти чтение). В случае падения брокера именно в zookeeper будет записана информация о новых лидер-партициях (с версии 1.1.0 асинхронно, и это важно).
В более старых версиях Kafka zookeeper отвечал и за хранение оффсетов, но сейчас они хранятся в специальном топике __consumer_offsets на брокере (хотя вы можете по-прежнему использовать zookeeper для этих целей).
Самым простым способом превратить ваши данные в тыкву является как раз потеря информации с zookeeper. В таком сценарии понять, что и откуда нужно читать, будет очень сложно.
Producer
Producer — это чаще всего сервис, осуществляющий непосредственную запись данных в Apache Kafka. Producer выбирает topic, в котором будут храниться его тематические сообщения, и начинает записывать в него информацию. Например, producer’ом может быть сервис объявлений. В таком случае он будет отправлять в тематические топики такие события, как «объявление создано», «объявление обновлено», «объявление удалено» и т.д. Каждое событие при этом представляет собой пару ключ-значение.
По умолчанию все события распределяются по партициям топика round-robin`ом, если ключ не задан (теряя упорядоченность) и через MurmurHash (ключ), если ключ присутствует (упорядоченность в рамках одной партиции).
Здесь сразу стоит отметить, что Kafka гарантирует порядок событий только в рамках одной партиции. Но на самом деле часто это не является проблемой. Например, можно гарантированно добавлять все изменения одного и того же объявления в одну партицию (тем самым сохраняя порядок этих изменений в рамках объявления). Также можно передавать порядковый номер в одном из полей события.
Consumer
Consumer отвечает за получение данных из Apache Kafka. Если вернуться к примеру выше, consumer’ом может быть сервис модерации. Этот сервис будет подписан на топик сервиса объявлений и при появление нового объявления будет получать его и анализировать на соответствие некоторым заданным политикам.
Apache Kafka запоминает, какие последние события получил consumer (для этого используется служебный топик __consumer__offsets), тем самым гарантируя, что при успешном чтении consumer не получит одно и то же сообщение дважды. Тем не менее, если использовать опцию enable.auto.commit = true и полностью отдать работу по отслеживанию положения consumer’а в топике на откуп Кафке, можно потерять данные. В продакшен коде чаще всего положение консьюмера контролируется вручную (разработчик управляет моментом, когда обязательно должен произойти commit прочитанного события).
В тех случаях, когда одного consumer недостаточно (например, поток новых событий очень большой), можно добавить еще несколько consumer, связав их вместе в consumer group. Consumer group логически представляет из себя точно такой же consumer, но с распределением данных между участниками группы. Это позволяет каждому из участников взять свою долю сообщений, тем самым масштабируя скорость чтения.

Здесь не буду писать много пояснительного текста, просто поделюсь полученными результатами. Тестирование проводилось на 3 физических машинах (12 CPU, 384GB RAM, 15k SAS DISK, 10GBit/s Net), брокеры и zookeeper были развернуты в lxc.
Тестирование производительности
В ходе тестирования были получены следующие результаты.
- Скорость записи сообщений размером 1KB одновременно 9 producer’ами — 1300000 событий в секунду.
- Скорость чтения сообщений размером 1KB одновременно 9 consumer’ами — 1500000 событий в секунду.
Тестирование отказоустойчивости
В ходе тестирования были получены следующие результаты (3 брокера, 3 zookeeper).
- Нештатное завершение одного из брокеров не приводит к остановке или недоступности кластера. Работа продолжается в штатном режиме, но на оставшихся брокеров приходится большая нагрузка.
- Нештатное завершение двух брокеров в случае кластера из трех брокеров и min.isr = 2 приводит к недоступности кластера на запись, но доступности на чтение. В случае, если min.isr = 1, кластер продолжает быть доступен и на чтение и на запись. Тем не менее, данный режим противоречит требованию к высокой сохранности данных.
- Нештатное завершение одного из серверов Zookeeper не приводит к остановке или недоступности кластера. Работа продолжается в штатном режиме.
- Нештатное завершение двух серверов Zookeeper приводит к недоступности кластера до момента восстановления работы хотя бы одного из серверов Zookeeper. Данное утверждение верно для кластера Zookeeper из 3 серверов. В результате после исследований было решено увеличить кластер Zookeeper до 5 серверов для увеличения отказоустойчивости.

Мы убедились, что Kafka — отличная технология, которая позволяет решить поставленную перед нами задачу (реализацию брокера сообщений). Тем не менее, мы решили запретить сервисам напрямую обращаться к Kafka и закрыли ее сверху сервисом data-bus. Зачем мы это сделали? На самом деле есть целых несколько причин.
-
Data-bus забрал на себя все задачи, связанные с интеграцией с Kafka (реализация и настройка consumer’ов и producer’ов, мониторинг, алертинг, логирование, масштабирование и т.д.). Таким образом, интеграция с брокером сообщений происходит максимально просто.
-
Data-bus позволил абстрагироваться от конкретного языка или библиотеки для работы с Kafka.
-
Data-bus позволил другим сервисам абстрагироваться от слоя хранения. Может быть в какой-то момент мы поменяем Kafka на Pulsar и при этом никто ничего не заметит (все сервисы знают только про API data-bus).
-
Data-bus взял на себя валидацию схем событий.
-
С помощью data-bus реализована аутентификация.
-
Под прикрытием data-bus мы можем без даунтайма, незаметно обновлять версии Kafka, централизованно вести конфигурации producer’ов, consumer’ов, брокеров и т.д.
-
Data-bus позволил добавлять необходимые нам фичи, которых нет в Kafka (такие как аудит топиков, контроль за аномалиями в кластере, создание DLQ и т.д.).
-
Data-bus позволяет реализовать failover централизованно для всех сервисов.
На данный момент для начала отправки событий в брокер сообщений достаточно подключить небольшую библиотеку в код своего сервиса. Это всё. У вас появляется возможность писать, читать и масштабироваться одной строчкой кода. Вся реализация скрыта от вас, наружу торчит только несколько ручек типа размера батча. Под капотом сервис data-bus поднимает в Kubernetes нужное количество инстансов producer’ов и consumer’ов и подкладывает им нужную конфигурацию, но все это для вашего сервиса прозрачно.
Конечно, серебряной пули не бывает, и у такого подхода есть свои ограничения.
- Data-bus нужно поддерживать своими силами, в отличие от сторонних библиотек.
- Data-bus увеличивает число взаимодействий между сервисами и брокером сообщений, что приводит к снижению производительности по сравнению с голой Kafka.
- Не всё можно так просто скрыть от сервисов, дублировать функционал KSQL или Kafka Streams в data-bus нам не хочется, поэтому иногда приходится разрешать сервисам ходить напрямую.
В нашем случае плюсы перевесили минусы, и решение прикрыть брокер сообщений отдельным сервисом оправдалось. За год эксплуатации у нас не было никаких серьезных аварий и проблем.
Комментариев нет:
Отправить комментарий