
Дмитрий Иванов — Software Analysis TeamLead в Huawei, в прошлом техлид JetBrains Rider и разработчик ядра ReSharper: структур данных, кэшей, многопоточности, регулярный спикер конференции DotNext.
Под катом — видеозапись и текстовая расшифровка доклада Дмитрия с конференции DotNext 2019 Piter.
Далее повествование от лица спикера.
В многопоточном или асинхронном коде часто что-то ломается. Причиной может быть как deadlock, так и race. Как правило, race падает один раз из тысячи, зачастую не локально, а только на билд-сервере, и нужно несколько дней, чтобы его поймать. Уверен, для многих это знакомая ситуация.
Кроме того, просматривая асинхронный код даже опытных разработчиков, я ловлю себя на мысли, что некоторые вещи можно записать в три раза короче и правильнее.
Это наводит на мысль, что проблема не в людях, а в инструменте. Люди просто используют инструмент и хотят, чтобы он решал их задачу. Сам инструмент обладает очень большим количеством возможностей (иногда даже лишних), настроек, неявным контекстом, что приводит к тому, что его очень легко использовать неправильно. Давайте попробуем разобраться, как правильно использовать async/await и работать с классом Task в .NET.
План
- Проблемы подходов, которые решаются с помощью async/await.
- Примеры спорного дизайна.
- Задача из реальной жизни, которую мы решим «асинхронно».
Async/await и решаемые проблемы
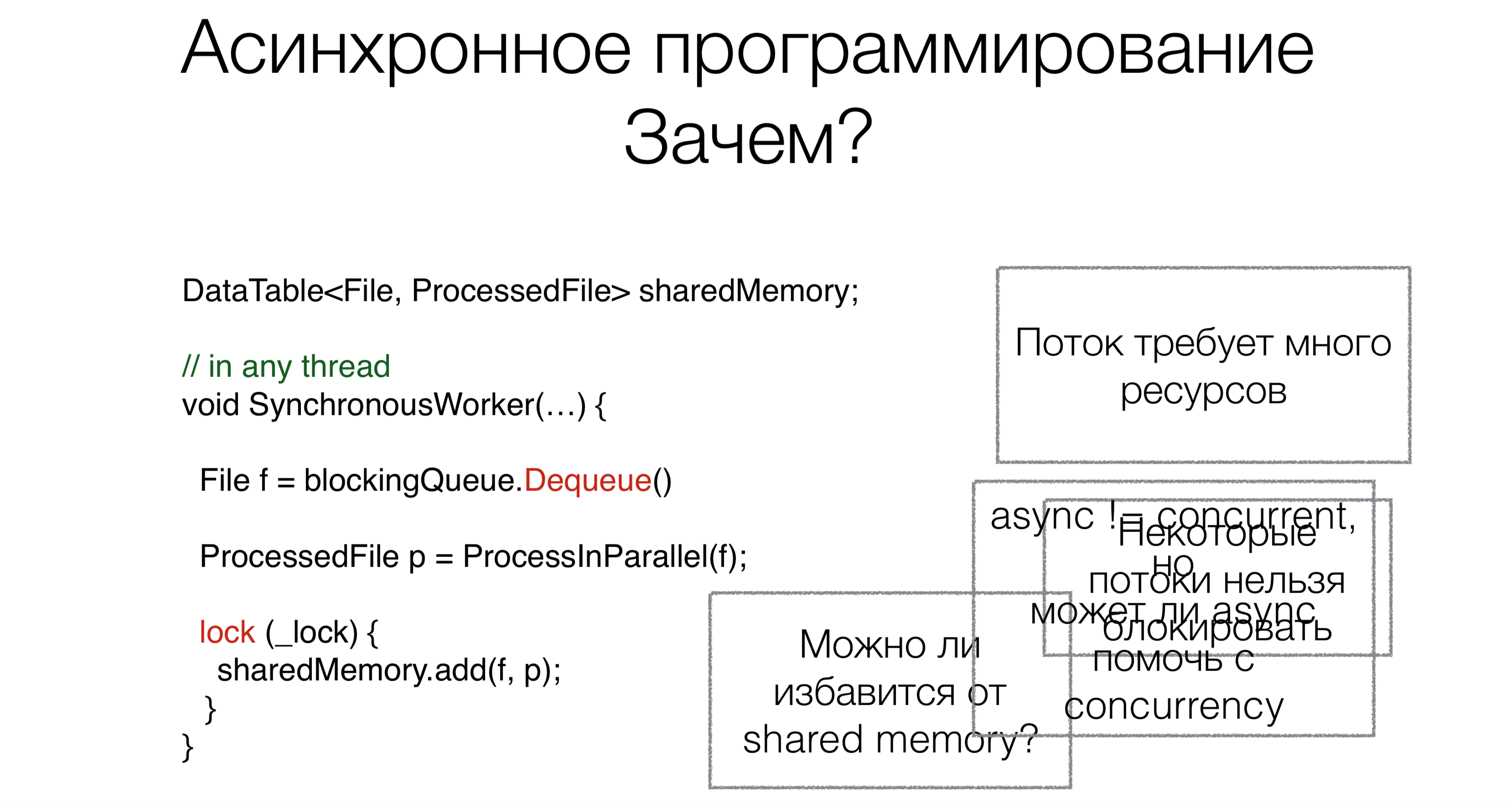
Зачем вообще нужны async/await? Допустим, у нас есть код, работающий с общей разделяемой памятью.
В начале работы мы считываем запрос, в данном случае — файл из блокирующей очереди (например, из интернета или с диска), c помощью блокирующего запроса Dequeue (блокирующие запросы будут помечены красным на картинках с примерами).
Этот подход требует много потоков, а каждый поток требует ресурсов, создает нагрузку на scheduler. Но это не основная проблема. Предположим, люди смогли бы переписать операционные системы так, чтобы эти системы поддерживали и сто тысяч, и миллион потоков. Но основная проблема в том, что некоторые потоки просто нельзя занимать. Например, у вас есть поток пользовательского интерфейса. Нормальных адекватных UI-фреймворков, где доступ к данным был бы не только с одного потока, пока нет. UI-поток нельзя блокировать. И чтобы его не блокировать нам потребуется асинхронный код.
Теперь поговорим про вторую задачу. После того, как мы прочитали файл, его нужно как-то обработать. Будем делать это параллельно.
Многие из вас слышали, что параллельность — это не то же самое, что асинхронность. В таком случае возникает вопрос: может ли асинхронность помочь записать параллельный код компактнее, красивее и быстрее?
Последняя задача — это работа с общей памятью. Нужно ли нам тащить этот механизм с lock-ами, синхронизацией в асинхронный код или этого можно как-то избежать? Может ли async/await в этом помочь?
Путь к async/await
Посмотрим на эволюцию асинхронного программирования вообще в мире и в .NET.
Callback
Void Foo(params, Action callback) {…}
Void OurMethod() {
…//synchronous code
Foo(params,() =>{
…//asynchronous code;continuation
});
}
Асинхронное программирование начиналось с callback-ов. То есть сначала нужно вызвать какую-то часть кода синхронно, а вторую часть — асинхронно. Например, вы читаете из файла, и, когда данные готовы, они будут каким-то образом вам доставлены. Эта асинхронная часть передается в виде callback.
More callbacks
void Foo(params, Action callback) {...}
void Bar(Action callback) {...}
void Baz(Action callback) {...}
void OurMethod() {
... //synchronous code
Foo(params, () => {
... //continuation 1
Bar(() => {
//continuation 2
Baz(() => {
//continuation 3
});
});
});
}
Таким образом, с одного callback-а можно зарегистрировать другой callback, с которого можно зарегистрировать третий callback, и в конце концов это все превращается в Callback Hell.

Callback: exceptions
void Foo(params, Action onSuccess, Action onFailure) {...}
void OurMethod() {
... //synchronous code
Foo(params, () => {
... //asynchronous code on success
},
() => {
... //asynchronous code on failure
});
}Как работать с исключениями? Например, ReSharper при отдельном реагировании на исключения и на хорошее исполнение демонстрирует не самые красивые куски кода — есть отдельные коллбэки на исключительную ситуацию и на успешное продолжение. В результате получается как раз такой callback hell, но только не линейный, а древовидный, что может запутывает окончательно.

В .NET первый callback-подход называется Asynchronous Programming Model (APM). Метод будет называться AsyncCallback, что по сути то же самое, что Action, но у подхода есть некоторые особенности. Прежде всего, методы надо начинать со слова «Begin» (чтение из файла — BeginRead), что возвращает некоторый AsyncResult. Сам AsyncResult — это handler, который знает, что операция завершилась и который имеет механизм WaitHandle. На WaitHandle можно повиснуть, ожидая асинхронного завершения операции. С другой стороны, можно вызвать EndOperation, то есть сделать EndRead и повиснуть синхронно (что очень похоже на свойство Task.Result).
Такой подход имеет ряд проблем. Во-первых, он не предохраняет нас от callback hell. Во-вторых, остается совершенно неясно, что делать с исключениями. В-третьих, непонятно, на каком треде вызовется этот callback — мы никак не контролируем вызов. В-четвертых, возникает вопрос, каким образом комбинировать куски кода с callback-ами?

Вторая модель называется Event-Based Asynchronous Pattern. Это реактивный вариант подхода с callback-ами. Идея метода в том, что мы передаем в метод OperationNameAsync некоторый объект, у которого есть event Completed и подписываемся на этот event. Как вы заметили, BeginOperationName меняется на OperationNameAsync. Путаница может возникнуть, когда вы заходите в класс Socket, где перемешаны два паттерна: ConnectAsync и BeginConnect.
Обратите внимание, что для отмены надо вызывать OperationNameAsyncCancel. Поскольку в .NET такое больше нигде не встречается, обычно все передают CancellationToken-ы. Таким образом, если вы случайно в библиотеке встретили метод, который заканчивается на Async, надо понимать, что он не обязательно возвращает Task, а может возвращать подобную конструкцию.

Рассмотрим модель, которая в Java известна как Futures, в JavaScript — как Promises, а в .NET — как Task Asynchronous Patterns, другими словами — «таски». Этот метод предполагает, что у вас есть некоторый объект вычисления, и у этого объекта можно посмотреть статус (запущен или закончен). В .NET существует так называемый RаnToCompletion, удобное разделение двух статусов: старт таски и завершенность таски. Распространенная ошибка возникает, когда у таски вызывают метод IsCompleted, который возвращает не successful continuation, а RаnToCompletion, Canceled и Faulted. Таким образом, результат нажатия на «Cancel» в UI-приложении должен отличаться от возврата исключений (эксепшенов). В .NET проведено различие: если эксепшн — это ваша ошибка, которую требуется залогировать, то Cancel — принудительная операция.
В .NET было также введено понятие TaskScheduler — это некая абстракция поверх потоков, которая сообщает, где запускать таску. В данном случае поддержка отмены была спроектирована на уровне дизайна. Практически все операции в библиотеке в .NET имеют CancellationToken, который можно передать. Это работает не для всех языков: например, в Kotlin можно отменить таску, а в .NET — нельзя. Выходом может служить разделение ответственности между тем, кто отменяет таску, и самой таской. Когда вы получаете таску, вы не можете отменить ее иначе, кроме как явно — вы должны передать ей CancellationToken.
Специальный объект TaskCompletionSourсe позволяет вам легко адаптировать старые API, которые связаны с Event-Based Asynchronous Pattern или Asynchronous Programming Model. Есть документ, который надо обязательно прочитать, если вы программируете на тасках. В нем описываются все соглашения по поводу тасок. Например, любой метод, возвращая таску, должен вернуть ее в запущенном состоянии, это значит, что она не может быть Created, при этом все такие операции должны оканчиваться на Async.
Combining continuations
Task ourMethod() {
return Task.RunSynchronously(() =>{
... //synchronous code
})
.ContinueWith(_ =>{
Foo(); //continuation 1
})
.ContinueWith(_ =>{
Bar(); //continuation 2
})
.ContinueWith(_ =>{
Baz(); //continuation 3
})
}
Что касается комбинирования, то принимая во внимание callback hell, оно может предстать в более линейном виде, несмотря на наличие кусков повторяющегося кода с минимальными изменениями. Кажется, что код улучшается таким образом, но и здесь есть подводные камни.
Start & continue tasks
Task.Factory.StartNew(Action,
TaskCreationOptions,
TaskScheduler,
CancellationToken
)
Task.ContinueWith(Action<Task>,
TaskContinuationOptions,
TaskScheduler,
CancellationToken
)Обратимся к трем параметрам при стандартном запуске таски: первый — это опции старта таски, второй — это scheduler, на котором таска запускается, и третий — CancellationToken.

TaskScheduler сообщает, где запускается таска и является объектом, который можно самостоятельно переопределить. Например, можно переопределить метод Queue. Если вы делаете TaskScheduler для thread pool, метод Queue берет тред из thread pool и посылает туда вашу таску.
Если же вы берете scheduler поверх главного треда, он все кладет в одну очередь, и таски исполняются последовательно на главном треде. Однако проблема в том, что в .NET можно выполнить таску, не передав TaskScheduler. Возникает вопрос: как тогда .NET вычисляет, какую таску ему передали? Когда таска запускается через StartNew внутри Action, ThreadStatic.Current выставляется в тот TaskScheduler, который мы ей передали.
Этот дизайн кажется довольно спорным из-за неявного контекста. Бывали случаи, когда TaskScheduler содержал асинхронный код, который наследовал где-то очень глубоко TaskScheduler.Current и накладывался на другой scheduler, что приводило к deadlock-ам. В этом случае можно воспользоваться опцией TaskCreationOption.HideScheduler. Это тревожный звоночек, который говорит о том, что у нас есть некоторая опция, которая отменяет ThreadStatic настройку.
С континуациями все то же самое. Возникает вопрос: откуда берется TaskScheduler для континуаций? Прежде всего, он берется в том методе, в котором вы запустили Continuation. Там же TaskScheduler берется из ThreadStatic. Важно, что для async/await континуации работают совсем иначе.

Обратимся к параметрам TaskCreationOptions и TaskContinuationOptions. Основная их проблема в том, что их много. Некоторые из этих параметров отменяют друг друга, некоторые — взаимоисключающие. Все эти параметры можно использовать во всех возможных сочетаниях, поэтому сложно держать в голове все то, что может произойти с таской. Некоторые из этих параметров работают совершенно непонятно.

Например, параметры ExecuteSynchronously и RunContinuationsAsynchronously представляют две возможные опции применения, но будет ли запущена континуация синхронно или асинхронно, зависит от очень многих вещей, о которых вы не узнаете.

Другой пример: мы запустили таску, запустили континуацию и одновременно дали два параметра TaskContinuations.ExecuteSynchronously, после чего запустили континуацию асинхронно. Будет ли она исполнена в том же стеке, где завершится предыдущая таска, или перенесется на thread pool? В данном случае будет третий вариант: зависит.

TaskCompletionSource
Рассмотрим
TaskCompletionSource. Когда вы создаете таску, вы устанавливаете ее результат через SetResult, чтобы адаптировать предыдущие асинхронные паттерны к тасковому миру. У TaskCompletionSource можно запросить tcs.Task, и эта таска перейдет в состояние finish, когда вы вызовете tcs.SetResult. Однако если вы запустите это на thread pool, вы получите deadlock. Спрашивается, почему, если мы ничего не написали даже синхронно?

Создаем TaskCompletionSource, стартуем новую таску, и у нас появляется второй поток, который стартует что-то в этой таске. Он переходит и падает в ожидание на сто миллисекунд. Затем наш основной поток — зеленый — переходит на await и все. Он отпускает стек, стек повисает, ждет, что его позовут в континуации на task.Wait, когда tcs выставится.
В синем треде доходим до tcs, и дальше самое интересное. Исходя из внутренних соображений .NET, TaskCompletionSource считает, что континуацию этого tcs можно выполнить синхронно, то есть прямо в том же стеке, то этому task.Wait выполняется синхронно в том же стеке. Это очень странно, при том, что мы нигде даже не писали ExecuteSynchronously. Вероятно, здесь проблема в смешении синхронного и асинхронного кода.

Другая проблема с TaskCompletionSource состоит в том, что когда мы вызываем SetResult под lock-ом, нельзя вызвать произвольный код, поскольку под lock-ом можно делать только какие-то маленькие гранулярные активности. Запускать под ним какие-то action-ы, неизвестно откуда пришедшие — нельзя. Как решить данную проблему?
var tcs = new TaskCompletionSource<int>(
TaskContinuationsOptions.RunContinuationsAsynchronously
) ;
lock(mylock)
{
tcs.SetResult(O);
});Использовать TaskCompletionSource стоит только для адаптации не Task-кода и в библиотеках. Почти все остальное можно решить через await. При этом всегда настоятельно рекомендуется прописывать параметр «TaskCompletionSource.RunContinuationsAsynchronously». Вам почти всегда нужно запускать континуацию асинхронно. В данном случае у вас возникает tcs.SetResult, под которым ничего запущено не будет.

Почему континуация должна выполнится синхронно? Потому что RunContinuationsAsynchronously относится к следующему ContinueWith, а не к нашему. Чтобы он относился к нашему, нужно написать следующее:

Данный пример показывает, насколько параметры не интуитивны, как они пересекаются друг с другом, как они вносят когнитивную сложность — писать так сложно.
Parent-child hierarchy
Task.Factory.StartNew(() =>
{
//... some parent activity
Task.Factory.StartNew(() => {
//... some child activity
})
})
.ContinueWith(...) // don’t wait for childСуществуют и другие варианты использования параметров. Например, возникает Parent-child иерархия, когда вы запускаете одну таску, а под ней запускаете другую. В этом случае, если вы напишете ContinueWith, то ContinueWith не будет дожидаться таски, запущенной внутри.
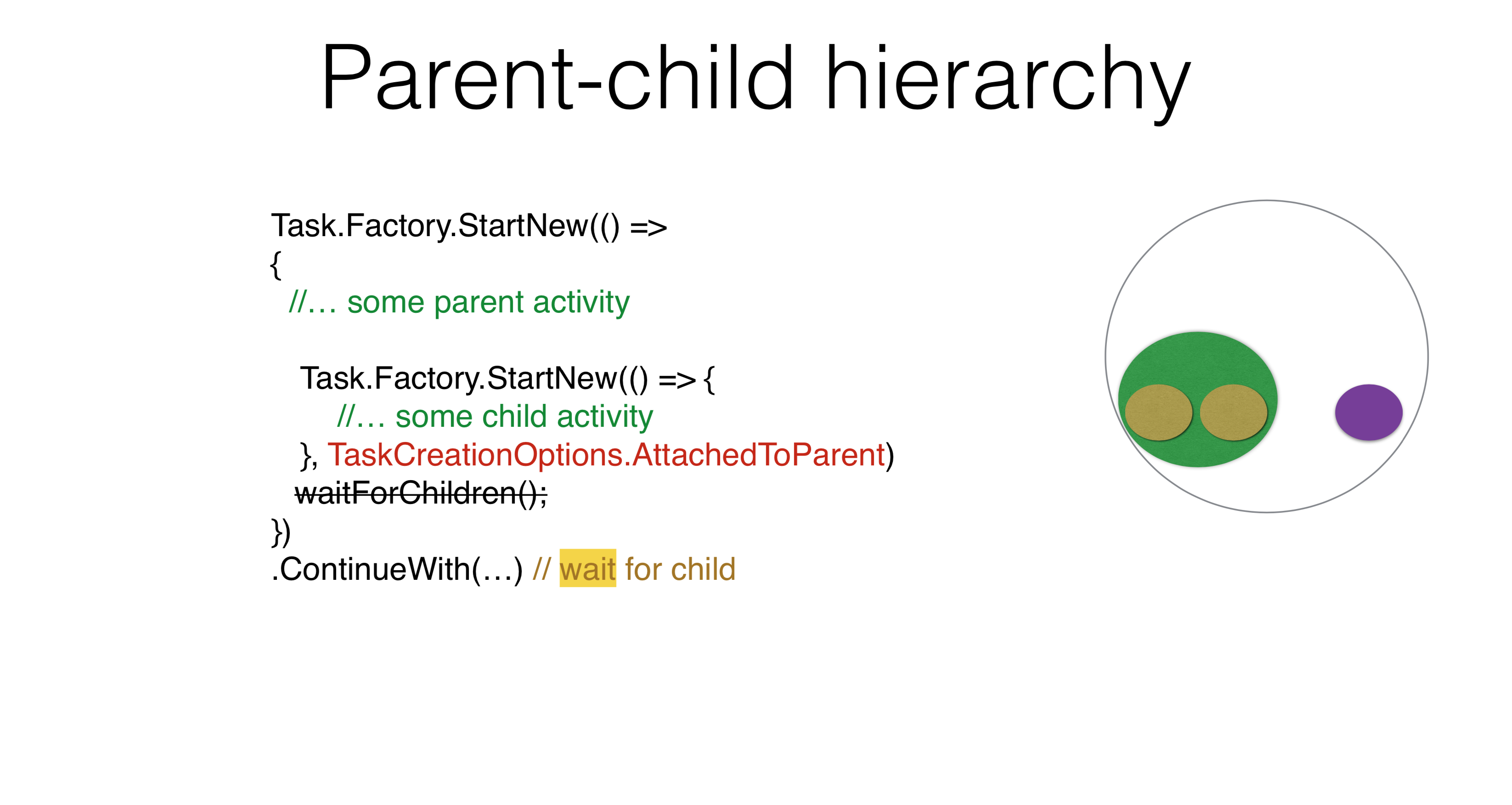
Если вы напишете TaskCreationOptions.AttachedToParent, то ContinueWith будет дожидаться. Это свойство вы можете использовать в своих продуктах. Я думаю, каждый может придумать пример, в котором есть иерархия задач, причем задача ждет подзадачи, а подзадачи — своих подзадач. Не надо нигде писать WaitForChildren, это ожидание происходит асинхронно. То есть заканчивается тело parent-таски, и после этого parent-таска не считается завершенной, не запускает свои континуации, пока child-таски не сработают.
Task.Factory.StartNew(() =>
{
//... some parent activity
Foo();
})
.ContinueWith(...) // still wait for child
void Foo() {
Task.Factory.StartNew(() => {
//... parent task to attach is in ThreadStatic
}, TaskCreationOptions.AttachedToParent);
}Может возникнуть проблема, при которой таска переносится куда-то в ThreadStatic, тогда все, что вы запустили с AttachedToParent, добавится к этой parent-таске, что является тревожным звоночком.
Task.Factory.StartNew(() =>
{
//... some parent activity
Foo();
}, TaskCreationOptions.DenyChildAttach)
.ContinueWith(...) // don’t wait for child
void Foo() {
Task.Factory.StartNew(() => {
//... some child activity
}, TaskCreationOptions.AttachedToParent);
}С другой стороны, существует опция, которая отменяет предыдущую опцию, DenyChildAttach. Такое применение возникает довольно часто.
Task.Run(() =>
{
//... some parent activity
Foo();
})
.ContinueWith(...) //don’t wait for child
void Foo() {
Task.Factory.StartNew(() => {
//... some child activity
}, TaskCreationOptions.AttachedToParent);
}Стоит помнить, что Task.Run — это стандартный способ запуска, который по умолчанию подразумевает DenyChildAttach.
Неявный контекст, который вы кладете в ThreadStatic, добавляет вам сложности. Вы не понимаете, как работает задача, потому что вам нужно знать контекст. Другая проблема, которая может возникнуть, связана с нерабочим состоянием async/await. Все потому, что в async/await-ах у вас не таски, а action-ы. Continuation-ы — это не честные таски, а action-ы. Когда вы пишете async/await-код, вам не нужно использовать AttachedToParent, потому что вы явно подвязываете те таски, которые надо подождать, через await-ы, и это правильный подход.

У вас есть шесть опций, как можно запустить континуацию. Вы запустили таску, запустили ContinueWith. Вопрос: какой статус будет у этой континуации? Тут пять вариантов ответа:
- общая континуация будет успешно выполнена, произойдет RunToCompletion;
- таска будет с ошибкой;
- произойдет отмена;
- таска вообще не дойдет до завершения, будет в каком-то подвешенном состоянии;
- вариант — «зависит».

В данном случае таска будет в состоянии «canceled», хотя нигде здесь слова «canceled» нет. Вот тут мы кидаем эксепшн и ничего не делаем. Проблема в том, что, когда вы читаете чужой код с большим количеством опций — даже если вы знали об этих опциях 10 минут назад — вы все равно забываете, что здесь происходит. Так писать не надо.
Cancellation
Task.Factory.StartNew(() =>
{
throw new OperationCanceledException();
});
FailedТретий параметр при старте таски — канцелляция. Вы пишите OperationCanceledException, то есть специальный экспешн, который переводит таску в состояние «Canceled». В таком случае таска будет в состоянии «Failed», потому что не все OperationCanceledException равны.
Task.Factory.StartNew(() =>
{
throw new OperationCanceledException(cancellationToken);
}, cancellationToken);
CanceledЧтобы таска была в состоянии Canceled, нужно выкинуть OperationCanceledException вместе с ее CancellationToken-ом. В реальности вы никогда явно так не делаете, а делаете подобным образом:
Task.Factory.StartNew(() =>
{
cancellationToken.ThrowIfCancellationRequested();
}, cancellationToken);
CanceledНужно ли различать cancellationToken-ы? Где-то внутри таски вы проверяете, что кто-то вас удалил: кидаете throw cancellation, тогда таска переходит в состояние Canceled. Или кто-то нажал «Cancel» на во время выполнения и отменил задачу. Наша практика в компании JetBrains говорит о том, что различать эти токены не нужно. Если вы получаете OperationCanceledException — специальный вид, который возникает, когда произошла некоторая канцелляция, вы можете его отличить. В этом случае следует просто нормально завершить задачу, не логировать, а когда получаете эксепшн — залогировать.
Deep stack
Task.Factory.StartNew(() =>
{
Foo();
}, cancellationToken);
void Foo() {
Bar() {
...
Baz() {
//how to get cancellation token?
}
}
}Допустим, у вас есть глубокий стек. Данный CancellationToken — единственный явный параметр из тех, которые мы обсуждали. Его нужно везде передавать через абсолютно все иерархии. Что делать, если при наличии глубокой иерархии вам надо где-то на самом нижнем уровне отменить ваше задание, выкинуть эксепшн? Есть такой специальный трюк, который мы используем. Он называется AsyncLocal.
static AsyncLocal<Cancelation> asyncLocalCancellation;
Task.Factory.StartNew(() =>
{
asyncLocalCancellation.Set(cancellationToken)
Foo();
}, cancellationToken); // use AsyncLocal to put cancellation int
void Foo() {
async Bar() {
...
Baz() {
asyncLocalCancellation.Value.CheckForInterrupt();
}
}
}Это то же самое, что и ThreadStatic, только такой специальный ThreadLocal, который переживает походы по async/await-коду. Так как у вас код асинхронный, и у вас есть эта канцелляция, вы кладете ее в AsyncLocal, и где-то на глубоком уровне можете сказать «CheckForInterrupt Throw If Cancellation Requested». Опять же, этот единственный параметр, CancellationToken, которым надо полностью измазать весь код, но, на мой взгляд, для большинства задач вам достаточно просто знать, что произошел OperationCanceledException, и из этого сделать вывод, какое состояние: Canceled или Failed.
Cognitive complexity
Task.Factory.StartNew(Action,
TaskCreationOptions,
TaskScheduler,
CancellationToken
)
JetBrains.Lifetimes
lifetime.Start(TaskScheduler, Action) //puts lifetime in AsyncLocal
lifetime.StartMainRead(Action)
lifetime.StartMainWrite(TaskScheduler, Action)
lifetime.StartBackgroundRead(TaskScheduler, Action)Чем сложнее прочитывается код при запуске таски, тем выше риск ошибки. Посмотрев на код через год, вы забудете, что он делает, потому что там большое количество параметров. Но у нас есть библиотека JetBrains.Lifetimes, которая предлагает современные lifetime-ы, хорошо оптимизированные CancellationToken-ы, с помощью которых был переписан метод Start и решена проблема с повторяющимися кусками кода, как при Task.Factory.StartNew и TaskCreationOptions.
Там небольшое количество scheduler-ов, которые позволяют запланировать задачу на главном треде с read lock. То есть read lock — это не что-то, что вы выберете явно, это специальный scheduler, который планирует ваш код на главном треде с read lock, а также main thread с write lock, background thread — и вот методы становятся совсем простыми по запуску тасок. При этом lifetime-ы автоматически проводят отмены через AsyncLocal, существенно упрощая код.

Посмотрим, как async/await-ы решают эти проблемы, и какие проблемы они вносят.
В данном примере часть кода выполняется синхронно, затем — await и асинхронный код. Во-первых, хорошо, что здесь гораздо меньше повторяющихся кусков кода (boiler-plate). Во-вторых, хорошо, что асинхронный код очень похож на синхронный код, это именно то, для чего нужен async/await. Вы можете писать асинхронно так же, как вы писали синхронно, не занимая при этом потоки.
Что в данном случае развернет компилятор? Синхронный код выполнится синхронно, после чего синхронно выполнится таска InnerAsync, откуда возьмется специальный объект GetAwaiter. В данном случае нас интересует TaskAwaiter. Вы можете написать свой awaiter абсолютно для любого объекта. В результате мы ждем, когда завершится таска InnerAsync, и синхронно выполняем continuationCode. Если таска не завершилась, то continuationCode планируется на Context scheduler. Может быть такое, что, хоть вы и написали await-ы, у вас абсолютно все будет вызываться синхронно.
async Task MyFuncAsync() {
synchronousCode();
await InnerAsync();
await Task.Yield(); //guaranteed !IsCompleted
continuationCode();
}Есть один трюк, Task.Yield — это специальная таска, которая гарантирует, что ее awaiter вам всегда вернет не IsCompleted. Соответственно, continuation не будет вызван синхронно в данном месте. Для UI-потока это может быть важно, потому что вы не занимаете этот поток на большое количество времени.

Как выбрать тред для континуации? Философия async/await такая: асинхронный код вы пишете такой же, как синхронный. В случае если это у вас thread pool, вам без разницы — continuationCode выполнится на другом треде. Независимо от того, был ли InnerAsync завершен, когда вы сказали await, или нет, вам надо, чтобы все выполнилось на UI-потоке.
Механизм для task await-ов выглядит следующим образом: берется static, он называется SynchronizationContext и из него создается TaskScheduler. SynchronizationContext — это штука с методом Post, который очень похож на метод Queue. На самом деле TaskScheduler, который был ранее, просто берет SynchronizationContext и через Post выполняет на нем свою таску.
async Task MyFuncAsync() {
synchronousCode();
await InnerAsync().ConfigureAwait(false);
continuationCode();
}Существует способ изменить это поведение при помощи параметра ContinueOnCapturedContext. Самая отвратительная API, которая есть в .NET, называется ConfigureAwait. В данном случае API создает специальный awaiter, отличающийся от TaskAwaiter, который перекладывает континуацию, она выполняется на том же потоке, в том же контексте, в котором завершился метод InnerAsync и где завершилась таска.
async Task MyFuncAsync() {
synchronousCode();
await InnerAsync().ConfigureAwait(continueOnCapturedContext: false);
continuationCode(); //code must be absolutely context-agnostic
}В интернете есть безумное количество советов: если у вас deadlock, пожалуйста, измажьте весь ваш код ConfigureAwait-ом, и все будет хорошо. Это неправильный способ. ConfigureAwait можно использовать в тех случаях, когда требуется немного улучшить перформанс, или в конце метода, в некоторых библиотечных методах.
Deadlocks
async Task MyFuncAsync() { //UI thread
synchronousCode();
await Task.Delay(10).ConfigureAwait(continueOnCapturedContext: false);
continuationCode();
}
myFuncAsync().Wait() //on UI threadЭто классический deadlock. На UI-потоке подождали десять секунд и сделали Wait. Из-за того, что вы сделали Wait, continuationCode никогда не будет запущен, соответственно, Wait никогда не вернется. Все его проходят в самом начале.
async Task OnBluttionClick() { //UI thread
int v = Button.Text.ParseInt();
await Task.Delay(10).ConfigureAwait(continueOnCapturedContext: false);
Button.Text.Set((v+1).ToString());
}
myFuncAsync().Wait() //on UI threadПредставим, что это некая настоящая активность. Мы нажали на кнопочку, взяли Button.ParseInt, сделали await, написали ConfigureAwait Говорим: «Пожалуйста, не замыкай наш UI-поток, выполни континуацию». Проблема в том, что мы хотим, чтобы вторая часть после ConfigureAwait тоже была выполнена на UI-потоке, потому что в этом философия await-ов. То есть у вас асинхронный код выглядит так же, как синхронный код, и выполняется на том же контексте. В данном случае, конечно, будет ошибка. И помимо Button.Text.Set здесь может быть сколько угодно вызовов методов, которые тоже предполагают свой контекст. Как правильно поступить в данной ситуации? Можно сделать так:
async Task MyFuncAsync() { //UI thread
synchronousCode();
await Task.Delay(10).ConfigureAwait(continueOnCapturedContext: false);
continuationCode(); //The same UI context
}
PumpUntil(() => task.IsCompleted);
//VS synchronization contexts always pump on any WaitПри UI-потоке надо запретить делать Wait на тредах, у которых есть общая очередь сообщений. Вместо того, чтобы делать Wait или писать ConfigureAwait, вы можете прокачать данную очередь сообщений, одновременно с этим прокачается и континуация. Если можно не смешивать синхронный и асинхронный код, то не стоит их смешивать. Но иногда этого не избежать.
Например, у вас есть старый код, и вам приходится их смешать, тогда вы прокачиваете UI-поток. Visual Studio прокачивает UI-поток на ожиданиях, она даже SynchronizationContext немножко подменила. Если вы заходите в WaitHandle на любом Wait, то когда повисаете, у вас прокачивается UI-поток. Таким образом, они делают выбор между deadlock-ами и race-ми в пользу race-ов.
PumpUntil — это неидеальная API, то есть, когда вы выполняете рандомную континуацию в произвольном месте, могут быть нюансы. По-другому никак, к сожалению. Смешивайте синхронный и асинхронный коды. Если что, весь Rider так устроен в старых местах, поэтому иногда тоже бывают нюансы.
Change context
async Task MyFuncAsync() {
synchronousCode(); // on initial context
await myTaskScheduler;
continuationCode(); //on scheduler context
}Есть еще интересный способ использования async/await-ов. Вы можете написать Awaiter на scheduler и прыгать по тредам. Я читал посты в Visual Studio, они очень долго писали, что нехорошо в середине метода прыгать туда-сюда, а сейчас сами так делают. В Visual Studio есть API, которая прыгает по тредам через scheduler-ы. Для нормального использования это делать нехорошо.
Structured concurrency
async Task MyFuncAsync() {
synchronousCode(); // on initial context
await Task.Factory.StartNew(() => {...}, myTaskScheduler);
continuationCode(); //on initial context
}Для удобного погружения в новый контекст и возвращения в старый должна выстраиваться некоторая структурная конкуренция, или структурная параллельность. Например, в шестидесятых годах оператор GoTo считался вредным, потому что он нарушал структурность. Так и здесь. Прыгание по тредам нарушает структурность. Удивительно, но хорошим выходом кажется использование async state-машины. То есть там, где у вас нарушается и обычная структурность, вы скачете по GoTo, можете нарушать и тредовую структурность: делать await, мешать его с метками. Это крайне странная и редкая ситуация, когда вам нужно это делать. Все-таки лучше, когда await возвращается в тот же контекст. Таким образом, на тред пуле будет не тот же поток, но тот же контекст, какой был изначально.
Sequential behavior
Почему await — это не то же самое, что и параллельное исполнение? Исполнение await-а — это исполнение последовательное. В данном случае мы стартуем первую таску, ждем ее, стартуем вторую таску — ждем. У нас нет никакой параллельности. Для большинства использований параллельность не нужна. Параллельность сама по себе более сложная, чем последовательность. Последовательный код проще, чем параллельный, это некоторая аксиома. Но иногда вам нужно запустить что-то в параллельном коде, и вы делаете это вот так:
async Task MyAsync() {
var task1 = StartTask1Async();
await task1;
var task2 = StartTask2Async();
await task2;
}Concurrent behavior
async Task MyAsync() {
var task1 = StartTask1Async();
var task2 = StartTask2Async();
await task1;
await task2;
}Здесь таски стартуют в параллель. Понятно, что методы могут вернуть таску сразу в запущенном состоянии, тогда никакой параллельности не будет. Допустим, что обе таски кидают эксепшн. И вы подождали первую таску, после этого на первом же await-е вылетели. То есть как только вы написали await task1, вы вылетели и не обработали exception task2. Интересно, что это абсолютно валидный код. И именно этот код привел .NET к тому, что в версии 4.5 поменялось поведение работы с эксепшнами.
Exception handling
async Task MyAsync() {
var task1 = StartTask1Async();
var task2 = StartTask2Async();
await task1;
await task2;
// if task1 throws exception and task2 throws exception we only throw and
// handle task1’s exception
//4.0 -> 4.5 framework: unhandled exceptions now don’t crush process
//still visible in UnobservedExceptionHandler
}Раньше unhandled эксепшны просто валили процесс, и если вы какой-то эксепшн не поймали в UnobserverExceptionHandler (это тоже некоторый static, который вы можете присоединить к scheduler-у), то это процесс не выполнялся. Сейчас это абсолютно валидный код. Хотя .NET поменял свое поведение, у него сохранилась настройка, чтобы вернуть поведение в обратную сторону.
async Task MyAsync(CancellationToken cancellationToken) {
await SomeTask1 Async(cancellationToken);
await Some Task2Async( cancellation Token);
//you should always pass use async API with cancelationToken if possible
}
try {
await MyAsync( cancellation Token);
} catch (OperationException e) { // do nothing: OCE happened
} catch (Exception e) {
log.Error(e);
}
Посмотрите, как идет обработка эксепшнов. CancellationToken-ы надо передавать, надо «измазывать» CancellationToken-ами весь код. Нормальное поведение async-ов заключается в том, что вы нигде не проверяете Task.Status СancellationToken, вы работаете с асинхронным кодом так же, как с синхронным. То есть в случае канцелляции вы получаете эксепшн, и в данном случае вы ничего не делаете, получив OperationCanceledException.
Различие между статусом Canceled и Faulted в том, что вы получили не OperationCanceledException, а обычный эксепшн. И в этом случае мы можем его залогировать, просто нужно получать эксепшн и на основании этого делать выводы. Если бы вы запускали таску явно, через Task-и, вам бы прилетел AggregateException. А в async-ах они в случае AggregateException всегда кидают самый первый эксепшн, который в нем был (в данном случае — OperationCanceled).
In practice
Синхронный метод
DataTable<File, ProcessedFile> sharedMemory;
// in any thread
void SynchronousWorker(...) {
File f = blockingQueue.Dequeue();
ProcessedFile p = ProcessInParallel(f);
lock (_lock) {
sharedMemory.add(f, p);
}
}Например, в ReSharper работает демон — редактор, который вам подкрашивает файл. Если файл открывается в редакторе, то есть некоторая активность, которая кладет его в блокирующую очередь. Наш процесс worker считывает оттуда, после чего выполняет кучу разных заданий с этим файлом, подкрашивает его, парсит, строит, после чего эти файлы складываются в sharedMemory. С sharedMemory под lock-ом с ней работают уже другие механизмы.
Асинхронный метод
При переписывании кода на асинхронный мы, прежде всего, заменим
void на async Task. Обязательно записать в конце слово «Async». Все асинхронные методы должны заканчиваться на «Async» — это конвенция.
DataTable<File, ProcessedFile> sharedMemory;
// in any thread
async Task WorkerAsync(...) {
File f = blockingQueue.Dequeue();
ProcessedFile p = ProcessInParallel(f);
lock (_lock) {
sharedMemory.add(f, p);
}
}После этого нужно что-то сделать с нашей blockingQueue. Очевидно, что если есть некоторый синхронный примитив, то должен быть некоторый асинхронный примитив.

Этот примитив называется channel: каналы, которые живут в пакете System.Threading.Channels. Вы можете создать каналы и очереди, ограниченные и неограниченные, которые можно подождать асинхронно. Причем можно создать канал с величиной «ноль», то есть он вообще не будет иметь буфера. Такие каналы называются рандеву-каналы и активно пропагандируются в Go и Kotlin. И в принципе, если есть возможность в асинхронном коде использовать каналы, это очень хороший паттерн. То есть мы меняем очередь на канал, где есть методы ReadAsync и WriteAsync.
ProcessInParallel — это куча параллельного кода, который делает процессинг файла и превращает его в ProcessedFile. Могут ли async-и помочь нам написать не асинхронный, а параллельный код компактнее?
Упрощение параллельного кода
Код можно переписать таким образом:
DataTable<File, ProcessedFile> sharedMemory;
// in any thread
async Task WorkerAsync(...) {
File f = await channel.ReadAsync();
ProcessedFile p = await ProcessInParallelAsync(f);
lock (_lock) {
sharedMemory.add(f, p);
}
}
Как выглядят ProcessInParallel? К примеру, у нас есть файл. Сначала мы его разбиваем на лексемы, и у нас параллельно могут идти две задачи: построение поисковых кэшей и построение синтаксического дерева. После этого идет задача «поиск семантических ошибок». Тут важно, что все эти задачи образуют направленный ацикличный граф. То есть какие-то части вы можете запускать в параллельных тредах, какие-то не можете, и явно есть зависимости, какая задача должна подождать другие задачи. У вас получается граф таких задач, вы хотите как-то их раскидать по тредам. Можно ли это написать красиво, без ошибок? У нас в коде эта проблема решалась несколько раз, каждый раз по-разному. Редко случается, когда этот код пишется без ошибок.

Зададим этот граф задач следующим образом: скажем, что у каждой задачи есть другие задачи, от которых она зависит, затем с помощью словаря ExecuteBefore напишем скелет нашего метода.
Скелет решения
Dictionary<Action<ProcessedFile>, Action<ProcessedFile>[]> ExecuteBefore; async Task<ProcessedFile> ProcessInParallelAsync() {
var res = new ProcessedFile();
// lots of work with toposort, locks, etc.
return res;
}Если решать эту задачу в лоб, то вам нужно сделать топологическую сортировку данного графа. Потом взять задачу, которая не имеет зависимых задач, исполнить ее, под lock-ом проанализировать структуру, посмотреть, у каких задач нет зависимых. Выполнить, раскидать их как-то через Task Runner. Запишем это чуть более компактно: топологическая сортировка графа + выполнение на разных тредах таких задач.
Async Lazy
Dictionary<Action<ProcessedFile>, Action<ProcessedFile>[]> ExecuteBefore;
async Task<ProcessedFile> ProcessInParallelAsync() {
var res = new ProcessedFile();
var lazy = new Dictionary<Action<ProcessedFile>, Lazy<Task>>();
foreach ((action, beforeList) in ExecuteBefore)
lazy[action] = new Lazy<Task>(async () =>
{
await Task.WhenAll(beforeList.Select(b => lazy[b].Value))
await Task.Yield();
action(res);
}
await Task.WhenAll(lazy.Values.Select(l => l.Value))
return res;
}Существует паттерн под названием Async Lazy. Мы создаем наш ProcessedFile, на котором должны выполняться разные action-ы. Создадим словарик: каждый из наших stage-й (Action ProcessedFile) оформим в некоторый Task, точнее — в Lazy от Task и побежим по изначальному графу. В переменной action будет сам action, а в beforeList — те action-ы, которые должны выполниться перед нашим. Затем создаем Lazy от action. В Task пишем await. Таким образом, мы ждем все задачи, которые должны быть выполнены до него. В beforeList выбираем тот Lazy, который есть в данном словаре.
Обратите внимание, здесь ничего не будет выполнено синхронно, поэтому этот код не упадет по ItemNotFoundException in Dictionary. Мы выполняем все таски, которые были до нашей, выполняя поиск по action Lazy Task. Потом выполняем наш action. В конце надо просто попросить каждую таску запуститься, а то мало ли что-то не запустилось. В данном случае ничего не запустилось. Это решение. Такой метод пишется за 10 минут, он абсолютно очевиден.
Таким образом, асинхронный код сделал наше решение, изначально он занимал пару экранов со сложным конкурентным кодом. Здесь он абсолютно последователен. Я даже не использую ConcurrentDictionary, я использую обычный Dictionary, потому что мы ничего в него не пишем конкурентно. Идет последовательный понятный код. Мы решаем задачу написания параллельного кода с помощью async-ов красиво, а значит — без багов.
Избавляемся от локов
DataTable<File, ProcessedFile> sharedMemory;
// in any thread
async Task WorkerAsync(...) {
File f = await channel.ReadAsync();
ProcessedFile p = await ProcessInParallelAsync(f);
lock (_lock) {
sharedMemory.add(f, p);
}
}Стоит ли тянуть в async-и вот эти вот lock-и? Сейчас существуют всякие async lock-и, async semaphore-ы, то есть попытка использовать примитивы, которые есть в синхронном и асинхронном коде. Эта концепция представляется неверной, потому что lock-ом вы защищаете что-то от параллельного исполнения. Наша задача состоит в том, чтобы перевести параллельное исполнение в последовательное, потому что это проще. А если проще — меньше ошибок.
Channel<Pair<File, ProcessedFile>> output;
// in any thread
async Task WorkerAsync(...) {
File f = await channel.ReadAsync();
ProcessedFile p = await ProcessInParallelAsync(f);
await output.WriteAsync();
}Мы можем создать некоторый канал и положить туда пару из File и ProcessedFile, а обрабатывать этот канал ReadAsync будет какая-нибудь другая процедура, и делать это она будет последовательно. Сам lock помимо того, что защищает структуру, по сути линеаризует доступ, место, где все потоки из последовательных становятся параллельными. И мы это заменяем явно на канал.

Архитектура выглядит следующим образом: worker-ы, получают файлы из input и отправляют их куда-то в процессор, который тоже все обрабатывает последовательно, никакой параллельности нет. Код выглядит сильно проще. Я понимаю, что далеко не все можно таким образом сделать. Такая архитектура, когда вы можете выстроить data pipe-ы, не всегда работает.

Может быть так, что у вас есть второй канал, который приходит в ваш процессор и из каналов образуется не ацикличный направленный граф, а граф с циклами. Это пример, который Роман Елизаров рассказал на KotlinConf в 2018 году. Он написал пример на Kotlin с этими каналами, причем там были циклы, и этот пример задедлочился. Проблема была в том, что если у вас есть такие циклы в графе, то все становится в асинхронном мире сложнее. Асинхронные дедлоки плохи тем, что решать их сильно сложнее, чем синхронные, когда у вас есть стек потоков, и понятно, что на чем повисло. Поэтому это инструмент, который надо использовать правильно.
Резюме
- Стоит избегать синхронизации в асинхронном коде.
- Последовательный код проще параллельного.
- Асинхронный код может быть простым и использовать минимум параметров и неявного контекста, меняющих его поведение.
Если у вас выработалась привычка писать синхронный код, и пусть асинхронный код очень похож на синхронный, не надо туда тащить примитивы, к которым вы привыкли в синхронном коде вроде async mutex. Используйте каналы, если возможно, и другие примитивы от Message passing.
Последовательный код проще параллельного. Если вы можете записать вашу архитектуру так, чтобы она выглядела последовательно, без запуска параллельного кода и локирования, то пишите архитектуру последовательно.
И последнее, что мы увидели из большого количества примеров с тасками. Когда вы дизайните вашу систему, постарайтесь поменьше полагаться на неявный контекст. Неявный контекст приводит к непониманию того, что происходит в коде, и о неявных проблемах вы сами можете забыть через год. А если над этим кодом будет работать другой человек и что-то в нем переделывать, это может привести к сложностям, о которых вы когда-то знали, а новый программист не знает из-за неявного контекста. В результате для плохого дизайна характерно большое количество параметров, их сочетание и неявный контекст.
Что почитать
Доклад Дмитрия Иванова вошел в топ-10 лучших докладов прошлой питерской конференции. В этом году DotNext 2020 Piter состоится 6-7 апреля на новой площадке — Экспофорум. На сайте конференции можно ознакомиться с программой и приобрести билеты.
Комментариев нет:
Отправить комментарий