В этом посте мы как раз и поговорим о практическом применении ИИ в тяжелой промышленности (да, мы не только приложения делать умеем), а именно о том, как технологии помогли одному производству по переработке руды существенно повысить эффективность работы и перестать гонять человека пару раз в день просеивать куски породы через большое сито.

В 1949 году советский пилот-геологоразведчик Михаил Сургутанов пролетал над одной из территорий Казахстана (урочище Сарбай) и, взглянув на компас, заметил, что стрелка стала игнорировать Север и зажила своей жизнью. Да, как в кино при обнаружении каких-то магнитных аномалий.
Собственно, это она и была, что подтвердили прибывшие на место геологи. А дальше было просто: раз тут есть больше месторождение железной руды, надо её добывать. Результатом стало строительство в 1957 году Соколовско-Сарбайского горно-обогатительного комбината. А чтобы было, кому на нём работать, построили заодно и город, который назвали Рудный.С
На сегодня в городе живут около 115 000 человек, и это крупнейшее производство Казахстана, на нём перерабатывают более 40 млн тонн железной руды в год.
Почему руду надо перемалывать до нужного размера
Сама затея переработки руды в том, чтобы добыть из неё металл. В нашем случае руда железная и получают из неё железо, для чего забрасывают руду в печь и активно плавят. Скормить печке сразу кусок руды размером с холодильник — так себе затея. Руда должна быть измельчённой. Поэтому после первичного дробления породы куски руды прогоняют через специальную мельницу, которая и даёт на выходе фракцию нужного размера.
Именно на этой мельнице у нас и был фокус. Благодаря ребятам из ERG (Евразийская Группа) у нас появилась возможность поучаствовать в этом проекте с софтовой точки зрения и предложить свои решения.
На эффективность работы мельницы влияют такие параметры: гранулометрический состав самой руды, подача воды и непосредственно режим работы (подаваемая мощность, крутящий момент и прочее). Проблема в том, что обычно на производстве такого рода параметры (например, размер входных фрагментов руды) выставляются на глаз. То есть работник пару раз в день берёт большое сито и просеивает через него руду, а потом на основе этого настраивает мельницу.

Например, прописал специалист режим работы с расчётом на один гран. состав (соответственно, одно время) — и мельница именно это время будет работать. Если человек перестраховался с расчетами, то мельница успешно перемелет все, но какое-то время прокрутится вхолостую.
Если же выставил время работы мельницы поменьше — то какие-то куски просто не будут перемолоты до нужного размера, и придется запускать процесс заново. А каждая минута работы мельницы это счета за электричество и воду, не говоря уже о потраченном времени в принципе — придётся и руду заново загружать, и настройки мельницы обновлять. Сутки работы в таком режиме с повторными запусками могут стоить дорого комбинату, а если такая ситуация стала нормой, то годовые финансовые потери будут весьма ощутимыми.
Поэтому определить размеры руды на конвейере — задача важная, и надо сделать это максимально точно.

Как шла работа
Мы сначала набросали несколько вариантов, от рентгеновского анализа и лазеров до 3D-модели и использования ультразвука, но решили все же использовать систему из видеокамер и возможностей компьютерного зрения: качество на уровне, а вот ресурсы проекта экономятся заметно.
Когда делаешь систему, которая должна визуально оценивать какие-то предметы и разделять их на «правильно» и «неправильно», нужно вот это «правильно» скормить алгоритму, чтобы ему было, на что ориентироваться. На основе информации от ERG мы прописали расположение оборудования — куда и что надо поставить, где какие кожухи, как установить видеокамеры и прочее. (А вот с поставкой оборудования все прошло не так оперативно: пилот у нас пришелся на май, поэтому половина контрагентов перешли в режим «Давай уже после майских»).

Ещё штука в том, что лента движется со скоростью 2 метра в секунду, поэтому за каких-то 50 секунд кусочек руды успевает сдать норматив на стометровку.
Настройка камер и сбор фотографий для обучения модели заняли у нас несколько недель, за это время удалось набрать около 2000 подходящих фото, и мы стали в полуавтоматическом режиме размечать картинки. Снимаем всё, кстати, на промышленные фотокамеры Basler с выдержкой более 1/2000с, иначе получить адекватные фото мелких движущихся на большой скорости предметов сложновато. Всего было закуплено три таких камеры, но пока работают две из них.

Вот так выглядит лента глазами фотокамеры
Так вот, камнями, которые надо отправить на перемолку в мельницу, считаются кусочки размером более 16 миллиметров. Всё, что меньше, считается сопутствующим мусором (песок, пыль, прочая мелочь). Если кусочек руды меньше монетки в 1 копейку (она 15,5 мм в диаметре), это мимо, а всё, что больше, должно считаться как полезная нагрузка для мельницы.

Это то, как видит камни алгоритм авторазметки, описанный ниже
Процесс

Различаем границы с помощью алгоритма Робертса с применением размытия Гаусса

Вычитаем найденные границы из исходного нормализованного изображения, повторно размываем алгоритмом Гаусса, кластеризуем изображения на 4 компоненты на основе значений цветов пикселей. Акцентируем внимание на пикселях кластера 2 (салатовый цвет), выделяем компонент связности.


Удаляем компоненты, которые по обеим граням меньше 15 пикселей (отбрасываем камни, размера меньше, чем 16 мм, по предварительным расчетам 16 мм по диагонали это примерно 20 пикселей, берем 15, так как камера смотрит на конвейер под небольшим углом).
Затем алгоритм преобразует эти данные в числовые метрики и вычисляет площадь каждого кусочка руды, что даёт нам средние значения (соотношение площади пикселей нужных камней к площади конвейера), плюс высчитывается плавающее среднее по соседним кадрам.
Но не фото едиными, коллеги из ERG дали нам множество полезных исторических данных за несколько лет, с помощью которых можно было определить процент крупности фрагментов руды (грансостав и долю больших камней в общей массе). Видеонаблюдение позволяет оценить только верхний слой руды на ленте, поэтому все, что под ним, мы прогнозировали.
В общем, мы скормили алгоритму фотографии камней на ленте, размеченные картинки с камнями больше 16 мм, исторические данные от ERG и пошли тестировать. Точность на выходе оказалась порядка 80%, в масштабах завода и конвейерных условиях, это неплохой результат. С помощью всей этой информации алгоритм определяет процент крупности гранул руды. А это и является тем самым параметром, от которого и отталкиваются при настройке мельницы.
Как тренировали нейросеть
Базис у нас реализован на сети Fast-SCNN, основанной на UNet, но не с таким большим количеством параметров для тренировки, плюс есть слои для борьбы с эффектом потери информации на уровнях сильного снижения размерности и ряд других полезных оптимизаций. Одна из главных фич такой сети — возможность адекватно уменьшать размеры выходного изображения в 8 раз по высоте и ширине. Её авторы считают, что использовать в таком деле изображения более 1024 пикселей по стороне нецелесообразно, потому что обе сети получаются примерно одинакового качества, а вот количества параметров для обучения отличается на пару порядков.
Мы провели несколько экспериментов и выделили для себя лучшую модель с точки зрения визуализации, для проверки которой нужна была валидация в терминах точности. Чтобы её провести, мы руками разметили несколько фотографии, дабы проверить, насколько хорошо сетка будет распознавать камни (полученная точность на старте 55,3% в терминах пикселей).
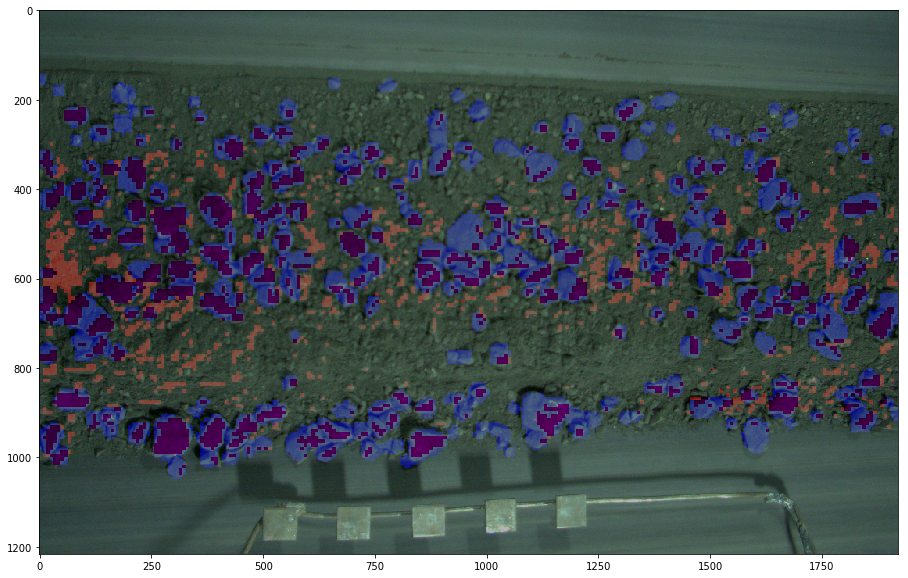
Вот пример визуализации.
- Фиолетовым цветом отмечены правильно распознанные пиксели камней.
- Синим — пиксели камней, которые предиктор распознал как фон.
- А красным — пиксели фона, который предиктор распознал как камни.


Сделали выводы, прогнали еще несколько тренировок, доведя точность до 64,1%. Получилось уже вот так.

Как видите, тренировка оказалась полезной. Красные области, обозначающие число ошибок, не были размечены при ручной разметке. Да, там тоже могли бы быть видны камни, но их размер был бы сильно меньше нужного нам. Задумка была еще и в том, чтобы не только снижать число неверно предсказанных областей (красные пиксели), но и увеличивать количество синих. При финальной метрике учитывается тот факт, что пикселей фона сильно больше, поэтому даже небольшое убирание красных областей не повышает точность настолько, насколько улучшенное определение синих.
Но надо было неслабо увеличить объем разметки. Делать все руками, конечно, хорошо, но в пределах определенных масштабов. Поэтому запустили полуавтоматическую разметку с помощью дополнительных инструментов, это когда местами ты сидишь и размечаешь вручную, а местами задействовано автовыделение областей. Вот пример визуализации:

Итого разметили еще 33 фотографии, на 29 провели добавочную тренировку, а потом проверили результаты на четырех изображениях из новой партии и четырех из предыдущей (которые размечали вручную). Получилось вот что: у ручной разметки точность была 64,25%, у полуавтоматической — 62,7%. Вот визуализация.
Пытались пополнять полуавтоматическую разметку и далее, но качество росло незначительно, поэтому стали считать эту модель в рамках пилота финальной.
В деле
Так как лента движется быстро и за минуту успевает перевезти очень много камней, данные о весе руды обновляются раз в секунду. Ясное дело, когда у тебя есть такие данные, оставлять их где-то в мигающих табличках не очень хочется, и мы сделали для сотрудников комбината специальные дашборды с наглядным представлением процесса. Можно отслеживать общие результаты за нужный период, динамику изменений и прочие цифры.

В июле мы закончили обучать алгоритм и налаживать все связанные процессы, а в августе на одном из конвейеров запустили полноценный пилот. ERG после проверки моделей сказали, что их точность достигает 98%.
Сервер для управления камерами на конвейере мы поставили прямо на комбинате: машинное обучение и компьютерное зрение отчасти похожи на Chrome, они с радостью «съедят» все ресурсы, которые у вас будут. Поэтому комбинат, сервер, видеокарты GeForce GTX 1080.
Web-сервис мы сделали на Docker, уложились в 5 образов:
- websocket-service. Для добавления возможности websocket работать с несколькими исполнителями, это посредник между websocket в окне браузера и docker-контейнером db.
- data-service. Сервис общения с камерой, распознавания камней на изображениях, получения метрик в терминах камней, содержит разработанную модель.
- front. Nginx-прокси для доступа к системе.
- db. Образ доступа к накопленной базе данных.
- front-service. Образ web-интерфейса, а также доступа к API.
В итоге получается как раз то правильное воздействие, которое ИИ и технологии машинного обучения и должны оказывать на производственные процессы — повышается общая производительность труда, нивелируется влияние человеческого фактора, извлекается больше железа и, что главное, затраты на производство конечной продукции снижаются.
Директор департамента металлургии рассказал нам, что по итогам 2020 года с помощью модели планируется выпустить около 200 000 тонн готовой продукции дополнительно, при этом себестоимость производства упадет примерно на 5%. Поэтому ребята с комбината и планируют внедрить эту технологию у себя на всех похожих процессах.
Ну и да, про стандартные страшилки в таких постах. Никто не пойдёт увольнять кучу народу после внедрения машинных технологий. Хороший технический специалист остается хорошим специалистом и после этого.
А рабочим, которые время от времени просеивали руду через сито, можно просто найти более полезное занятие на комбинате.
Комментариев нет:
Отправить комментарий