Когда разработчики работали над китом, то не стали писать все с нуля, а использовали наработки из старых проектов. Он словно слеплен из несовместимых частей кода, которые не тестировались, а все проектирование сводилось к выбору фреймворка и к срочному «велосипедированию» уже в продакшне. В итоге получился проект красивый внешне, но с кусками дремучего легаси и костылей под капотом.

Для создания проектов, которые помогают бизнесу зарабатывать, а не похожих на морское животное, которое не может дышать под водой, есть DDD. Это подход, который фокусируется не на инструментах или коде, а на изучении предметной области, отдельных бизнес-процессов и на том, как код или инструменты работают для бизнес-логики.
Что такое DDD и какие инструменты в нем есть, мы расскажем в статье на основе доклада Артема Малышева. Подход DDD в Python, инструменты, подводные камни, контрактное программирование и проектирование продукта вокруг решаемой проблемы, а не используемого фреймворка — все это под катом.
Артем Малышев (proofit404) — независимый разработчик, пишет на Python 5 лет, активно помогал с Django Channels 1.0. Позже сфокусировался на архитектурных подходах: изучил, какого инструментария не хватает архитекторам на Python, и начал проект dry-python. Сооснователь компании Drylabs.
Сложность
Что такое программирование?
Программирование — это постоянная борьба со сложностью, которую создают сами разработчики, когда пытаются решить проблемы.Сложность делится на два типа: привнесенная и естественная. Привнесенная тянется вместе с языками программирования, фреймворками, ОС, моделью асинхронности. Это техническая сложность, которая не относится к бизнесу. Естественная сложность скрыта в продукте и упрощает жизнь пользователям — за это люди и платят деньги.
Хорошие инженеры должны уменьшать привнесенную сложность и увеличивать естественную, чтобы повышать полезность продукта.Но мы, программисты, сложные люди и обожаем добавлять в проекты техническую сложность. Например, мы не заморачивались над стандартами кодирования, не применяли линтеры, практики модульного дизайна и получили в проектах море кода в стиле
if c==1.
Как работать с таким кодом? Прочитать много файлов, понять переменные, условия и то, когда и как это все будет работать. Этот код тяжело держать в голове — абсолютно техническая привнесенная сложность.
Еще один пример привнесенной сложности — мой любимый «callback hell».
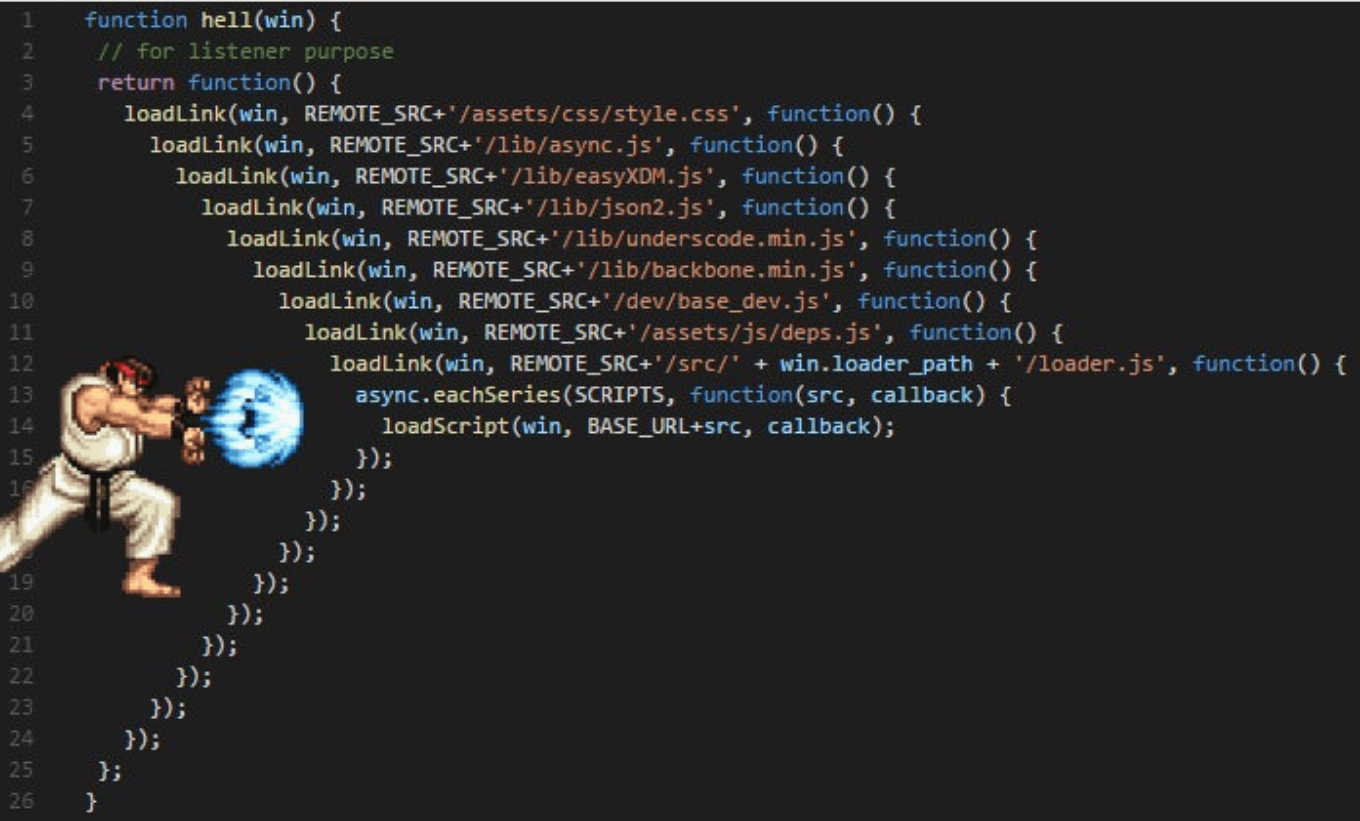
Когда мы пишем в рамках событийно-ориентированной архитектуры (EDA) и выбираем не самый хороший современный фреймворк, то получаем код, в котором непонятно, что и когда происходит. Читать такой код тяжело — это опять привнесенная сложность.
Программисты не только обожают технические сложности, но еще и спорят, какая из них лучше:
- AsyncIO или Gevent;
- PostgreSQL или MongoDB;
- Python или Go;
- Emacs или Vim;
- табы или пробелы;
Правильный ответ хорошего программиста на все эти вопросы: «Без разницы!» Хорошие разработчики не спорят из-за сферических коней в вакууме, а решают проблемы бизнеса и работают над полезностью продукта. Некоторые из них уже давно создали набор практик, которые уменьшают привнесенную сложность и помогают больше думать о бизнесе.
Один из них — Эрик Эванс. В 2004 году он написал книгу «Domain Driven Design» («Предметно-ориентированное проектирование»). Она «выстрелила» и дала импульс больше думать о бизнесе, а технические детали отодвинуть на второй план.

Что такое DDD?
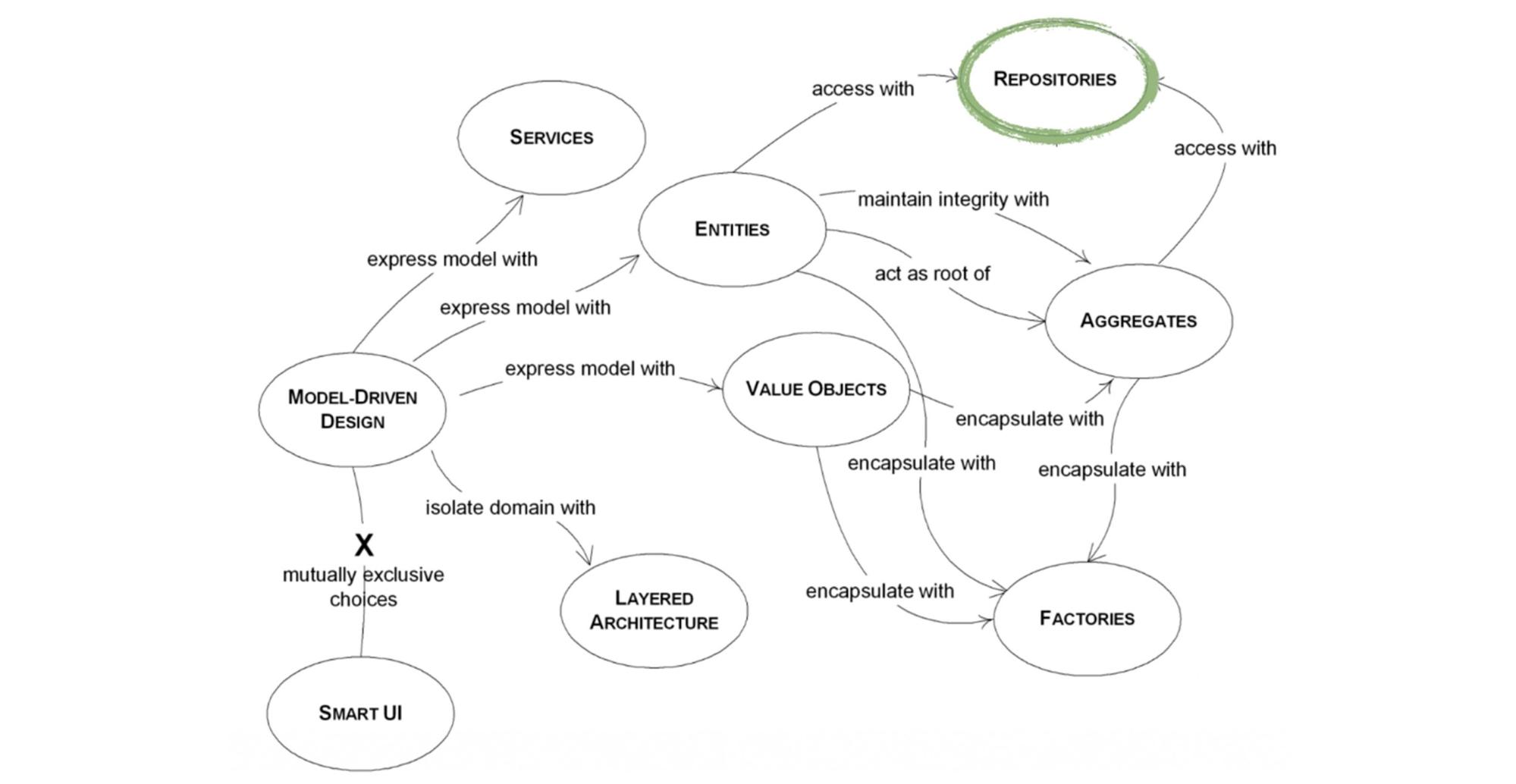
Сначала решение проблемы, а потом инструменты. Прежде всего Эванс вкладывал в понятие DDD, что это не технология, а философия. В философии сначала нужно думать, как решить проблему, а уже потом, с помощью каких инструментов.
Работайте над моделями вместе с экспертами в предметной области и разработчиками ПО. Мы должны общаться с людьми из бизнеса: искать общий язык, строить модель мира, в рамках которой наш продукт будет работать и решать проблемы.
Пишите ПО, которое явно выражает модели. Самое важное отличие DDD от простой коллаборации в команде это то, что мы должны писать ПО в том же стиле, в котором говорим с экспертами предметной области. Вся терминология, подходы к обсуждению и принятию решений должны быть сохранены в исходном коде, чтобы даже не технический человек мог понять, что там происходит.
Говорите с бизнесом на одном языке. DDD — это философия о том, как с экспертами из бизнеса говорить на одном языке в рамках определенной области и к этой области применять терминологию. У нас появляется общий язык или диалект в рамках связанного контекста, который мы считаем истиной. Мы создаем границы вокруг архитектурных решений.
DDD не о технологиях.
Сначала техническая часть, потом — DDD. Скульптор, который высекает статую из камня не читает мануал о том, как держать молоток и долото — он уже знает, как ими работать. Чтобы привнести DDD в ваш проект, освойте техническую часть: выучите до конца Django, прочитайте туториал и перестаньте спорить, что брать — PostgreSQL или MongoDB.
Большинство шаблонов и паттернов проектирования — это технический шум. Большая часть паттернов, которые мы знаем и используем — технические. Они говорят, как переиспользовать код, как структурировать, но не говорят, как применять его для пользователей, бизнеса и моделировать внешний мир. Поэтому фабрики или абстрактные классы слабо привязаны к DDD.
Первая «синяя» книга вышла почти 20 лет назад. Люди пытались писать в этом стиле, ходили по граблям, и поняли, что философия хорошая, но на практике непонятная. Поэтому появилась вторая книга — «красная», именно о том, как программистам мыслить и писать в DDD.

«Красная» и «синяя» книги — это столпы, на которых стоит все DDD.
Примечание. Красная и синяя книги — это уникальный источник информации о DDD, но они тяжелые. Книги непросто читать: в оригинале из-за сложного языка и терминов, а на русском из-за плохого перевода. Поэтому, начните изучение DDD с «зелёной» книги. Это упрощенный вариант первых двух с примерами попроще и общими описаниями. Но лучше так, чем если красная и синяя книга отобьют у вас желание изучать и применять DDD. Лучше читать в оригинале.
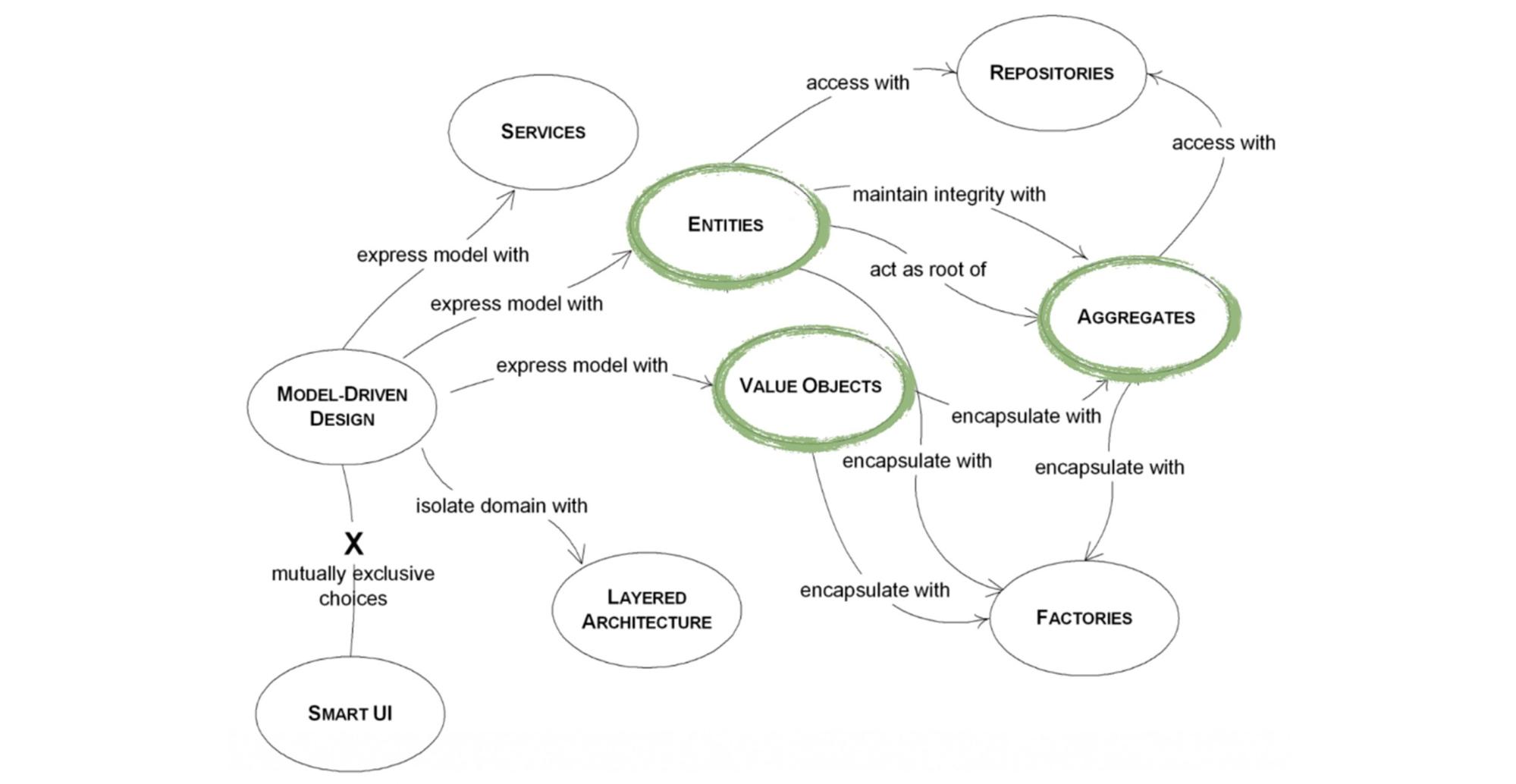
В красной книге проскакивает идея, как лучше всего DDD привносить в проект, как структурировать работу вокруг этого подхода. Появляется новая терминология — «Model-Driven Design», в котором на первое место ставится наша модель внешнего мира.
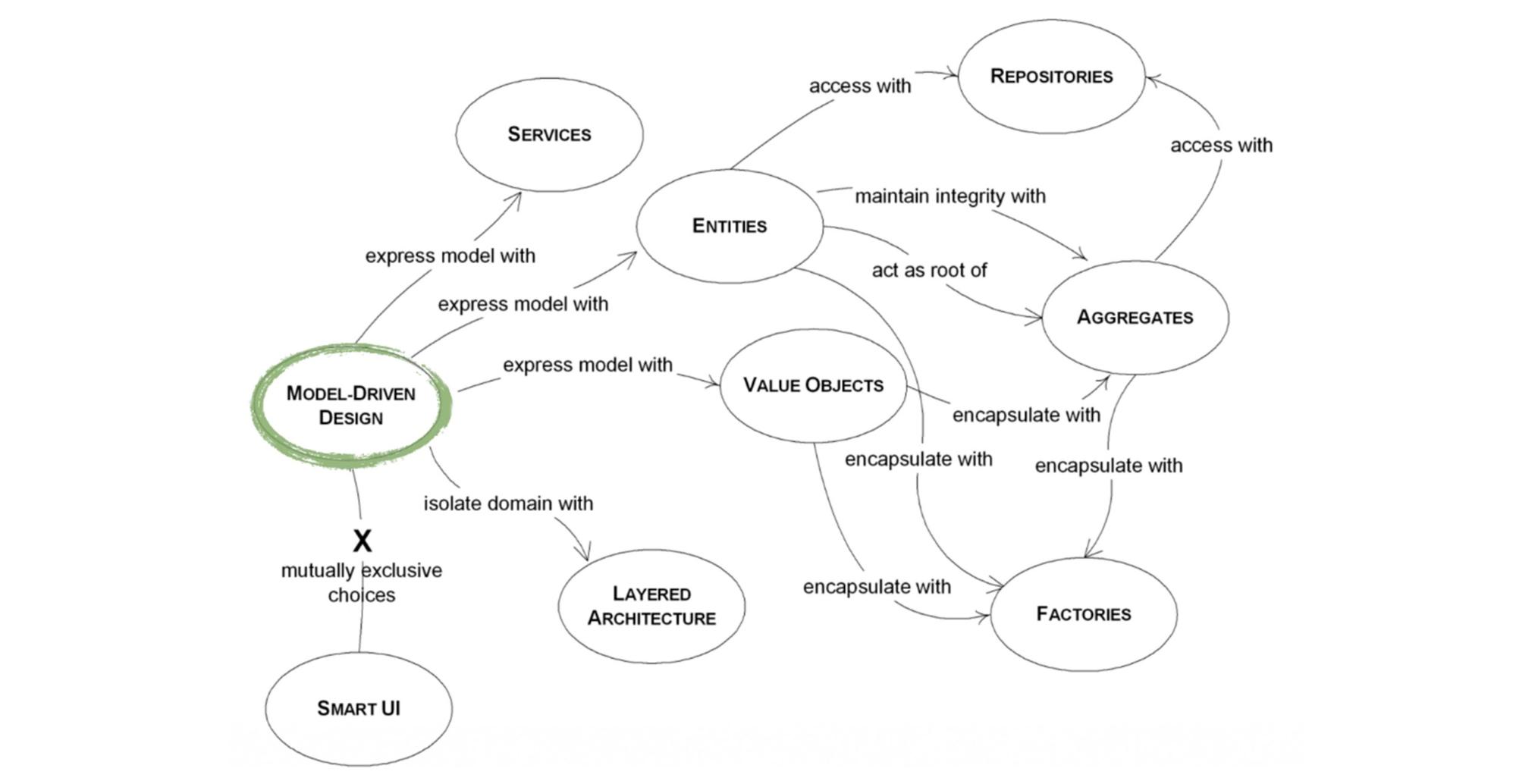
Единственное место, где выбираются технологии — «Smart UI». Это прослойка между внешним миром, пользователем и нами (отсылка к Роберту Мартину и его чистой архитектуре со слоями). Как видим, все идет к модели.
Что такое модель? Это фантомная боль любого архитектора. Все думают, что это UML, но это не так.
Модель — это набор классов, методов и ссылок между ними, которые отражают бизнес-сценарии в программе.Модель отражает реальный объект со всеми необходимыми свойствами и функциями. Это высокоуровневый инструментарий, по которому принимаются решения с точки зрения бизнес-кейсов. Методы и классы же, это низкоуровневый инструментарий для архитектурных решений.
Dry-python
Чтобы заполнить нишу моделей, я начал проект dry-python, который вырос в набор библиотек высокоуровневых архитектурных решений для построения Model Driven Design. Каждая из библиотек пытается закрыть один круг в архитектуре и не мешает другим. Библиотеки можно использовать отдельно, а можно вместе, если войти во вкус.
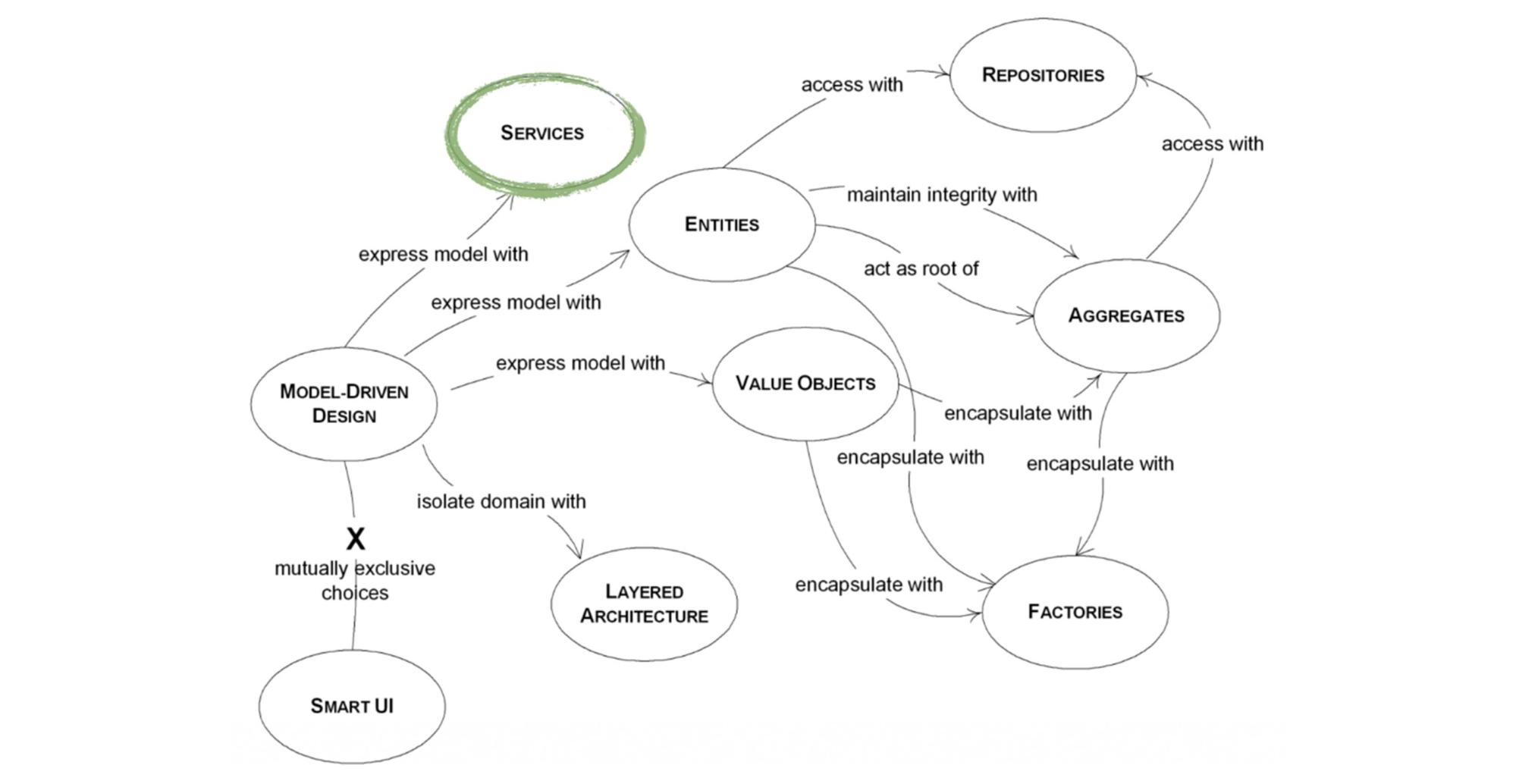
Последовательность повествования соответствует хронологии оптимального добавления DDD в проект — по слоям. Первый слой — сервисы, описание бизнес-сценариев (процессов) в нашей системе. За этот слой отвечает библиотека Stories.
Stories
Бизнес-сценарии делятся на три части:
- спецификация — описание бизнес-процесса;
- состояние, в котором может находиться бизнес-сценарий;
- реализация каждого шага сценария.
Эти части нельзя смешивать. Библиотека Stories разделяет эти части и проводит между ними четкую границу.
Рассмотрим внедрение DDD и Stories на примере. Например, у нас есть проект на Django с мешаниной из Django-сигналов и непонятных «толстых» моделей. Добавим в него пустой пакет services. С помощью библиотеки Stories по частям перепишем эту мешанину в ясный и понятный набор сценариев в нашем проекте.

Спецификация DSL. Библиотека позволяет писать спецификацию и предоставляет для этого DSL. Это способ пошагово описать действия пользователя. Например, чтобы купить subscription, я выполняю несколько шагов: найду заказ, уточню актуальность цены, проверю, может ли позволить себе это пользователь. Это высокоуровневое описание.
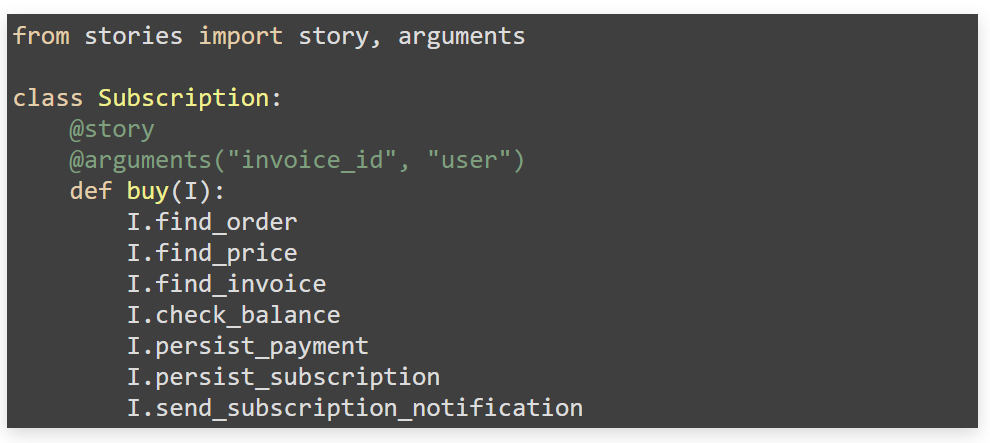
Контракт. Ниже этого класса напишем контракт на состояние бизнес-сценария. Для этого обозначим область переменных, которые возникают в бизнес-процессе, и за каждой переменной закрепим набор валидаторов.
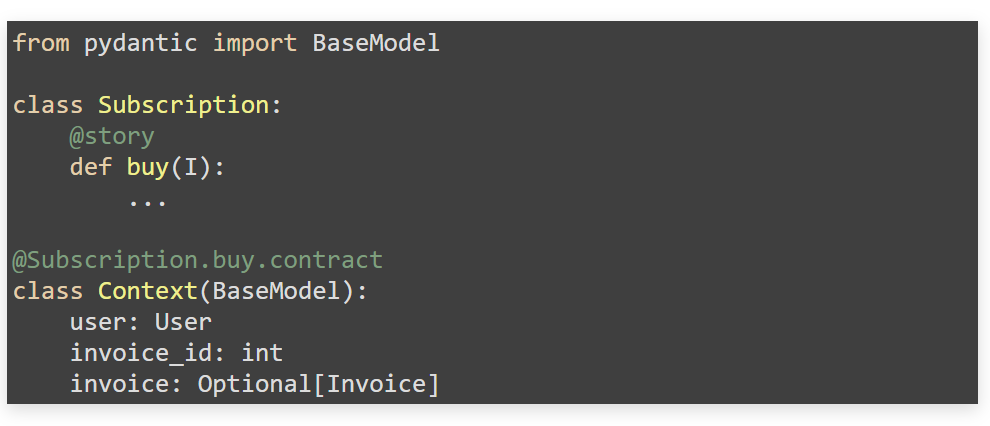
Как только кто-нибудь попробует в рамках бизнес-процесса назначить какую-то переменную в эту область — будет отработан набор валидаторов. Мы будем уверены, что состояние процесса во время выполнения всегда рабочее. Но если нет, оно больно падает и громко об этом кричит.
Этап реализации каждого шага. В том же классе subscription пишем набор методов, имена которых соответствуют бизнес-шагам. Каждый метод на вход получает состояние, с которым он может работать, но не имеет права его модифицировать. Метод может вернуть какой-то маркер и сообщить:
- что успешно отработал, и предложить поместить переменные в область (скоуп) для дальнейшего выполнения;
- что он что-то проверил и понимает, что дальнейшее выполнение не имеет смысла.
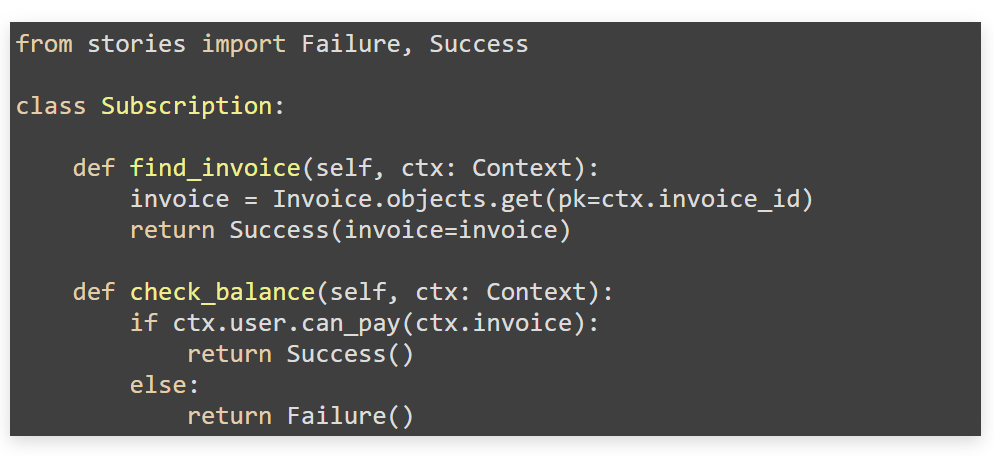
Есть маркеры сложнее: они могут подтверждать, что состояние рабочее, предлагать удалить или изменить какие-то части бизнес процесса. Также можно писать и в классах.
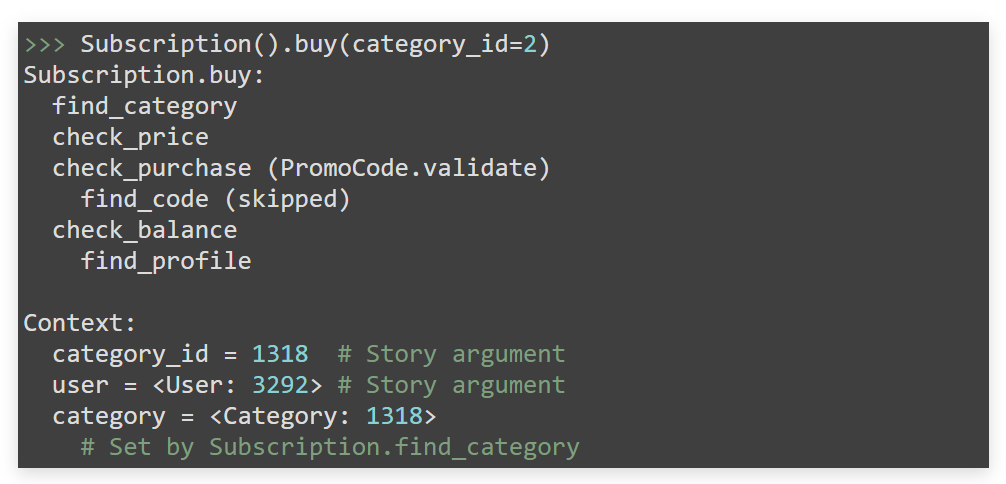
Запускаем Story. Как запустить Story на выполнение? Это бизнес-объект, который работает как метод: передаем на вход данные, он их валидирует, интерпретирует шаги. Выполняющаяся Story помнит историю исполнения, записывает состояние, которое происходило в ней в бизнес-процессе, и рассказывает нам, кто влиял на это состояние.
Панель инструментов отладки. Если пишем на Django и используем панель отладки, можем посмотреть, какие бизнес-сценарии отрабатывались в каждом запросе и их состояния.
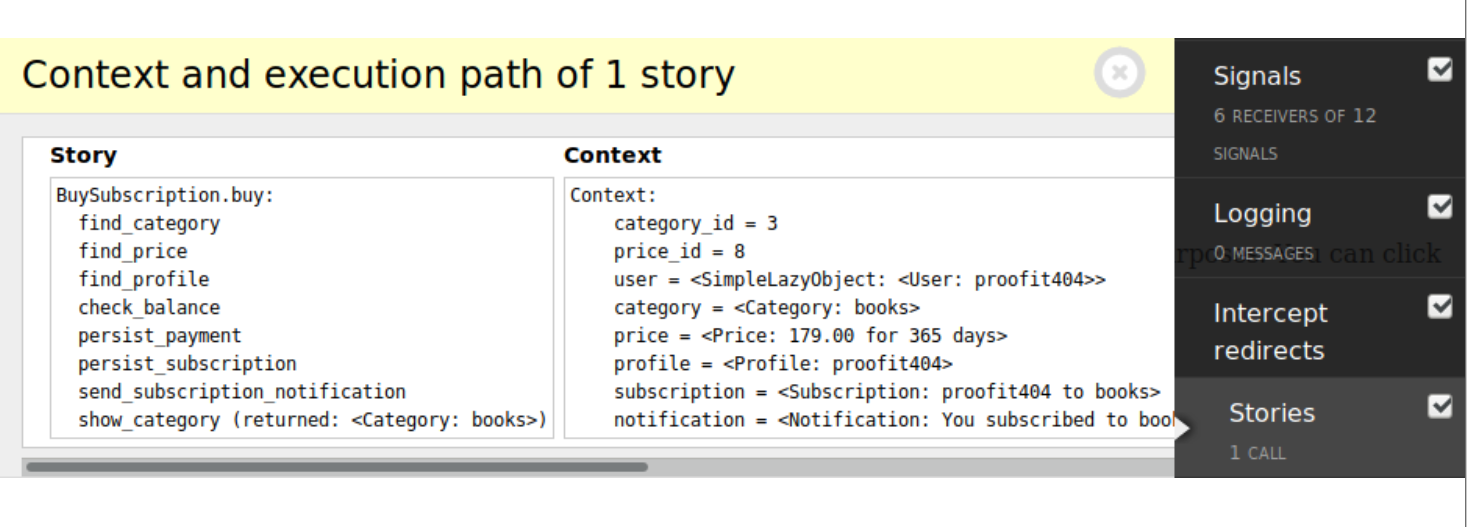
Py.test. Если пишем в py.test, то для упавшего теста можем посмотреть, какие бизнес-сценарии выполнялись на каждой строке и что пошло не так. Это удобно — вместо ковыряния в коде, прочитаем спецификацию и поймем, что произошло.
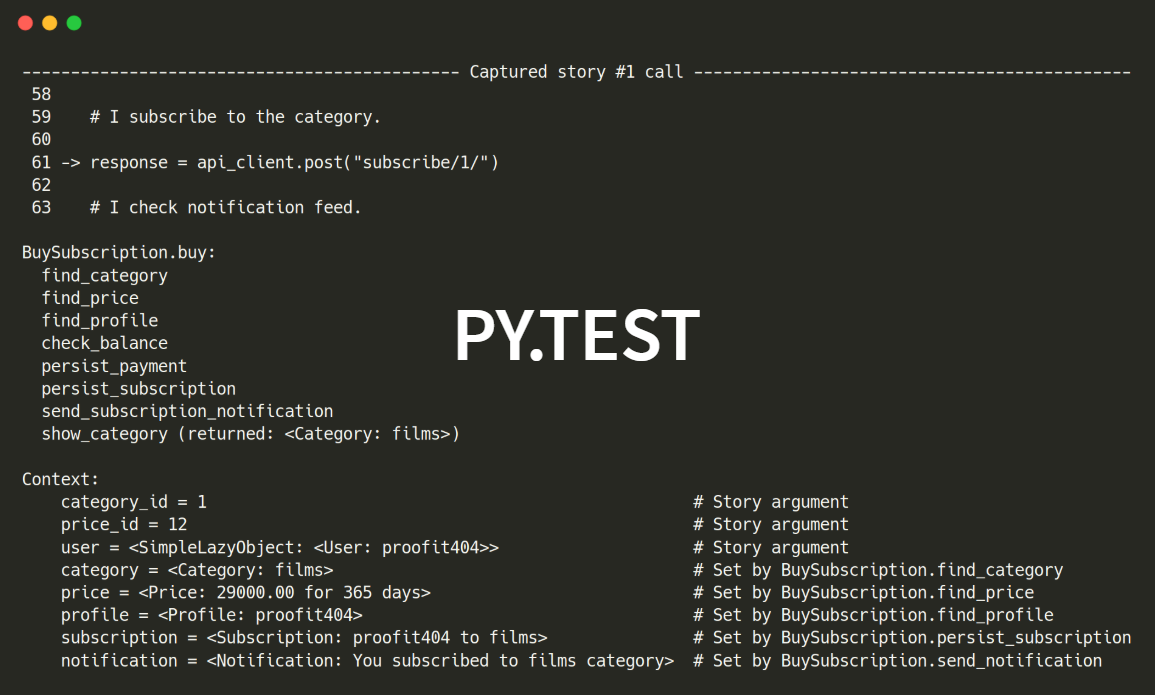
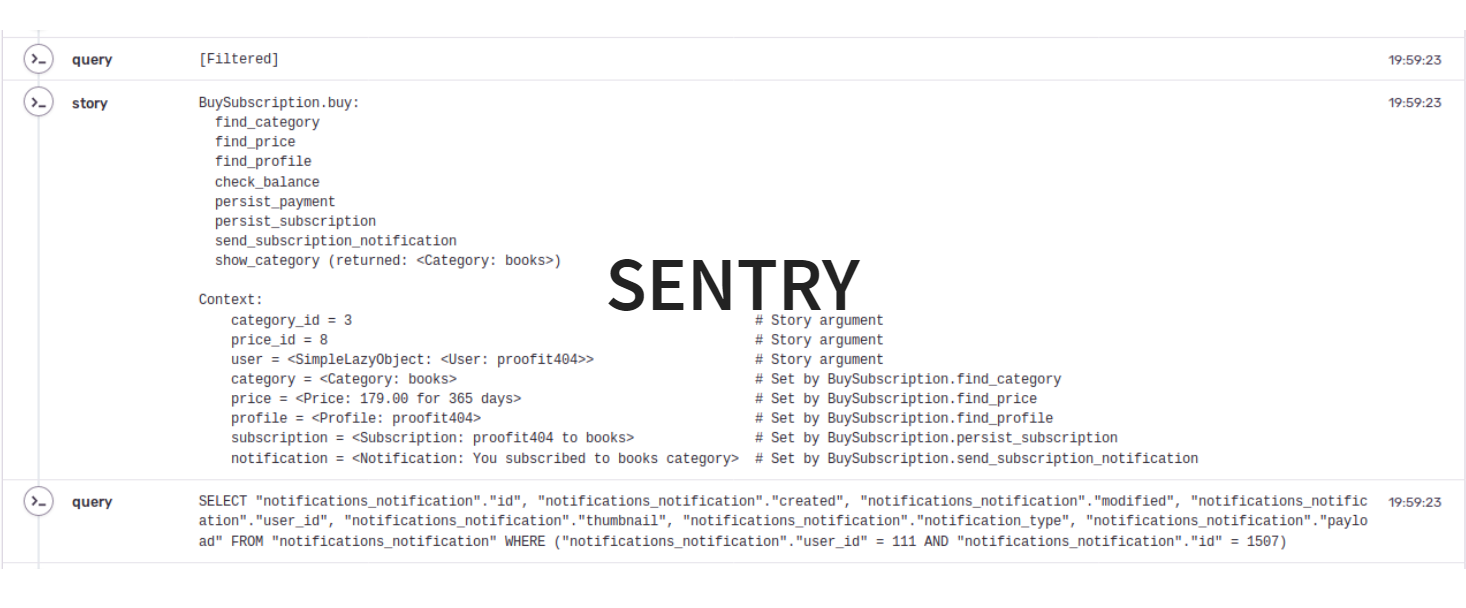
Sentry. Еще лучше, когда получаем ошибку 500. В обычной системе мы смиряемся с ней и начинаем вести расследование. В Sentry же, появится подробный отчет о том, что делал пользователь, чтобы добиться ошибки. Удобно и приятно, когда в 3 часа ночи такую информацию собрали за тебя.
ELK. Сейчас мы активно работают над плагином, который пишет это все в Elasticsearch в стек Kibana и строит грамотные индексы.
Например, у нас есть контракт на состояние бизнес-процесса. Мы знаем, что там есть, например, relation ID отчета. Вместо архаичного исследования того, что там когда-то происходило, мы пишем запрос в Kibana. Он покажет все выполненные Story, которые относятся к определенному пользователю. Дальше мы изучаем состояние внутри наших бизнес-процессов и бизнес-сценариев. Мы не пишем ни одной строки кода логирования, но проект логируется именно на том уровне абстракции, на котором нам интересно смотреть.
Но хочется чего-то более высокоуровневого, например, легких объектов. Такие объекты хранят в себе грамотные структуры данных и методы, которые относятся к принятию бизнес-решений, а не к работе с БД, например. Поэтому мы переходим к следующей части Model-Driven архитектуры — entities, agregates и value objects.
Entities, agregates и value objects
Как все это взаимосвязано? Например, пользователь сделал заказ продукта, и мы выставляем счет. Что здесь корень агрегации, а что — простой объект?
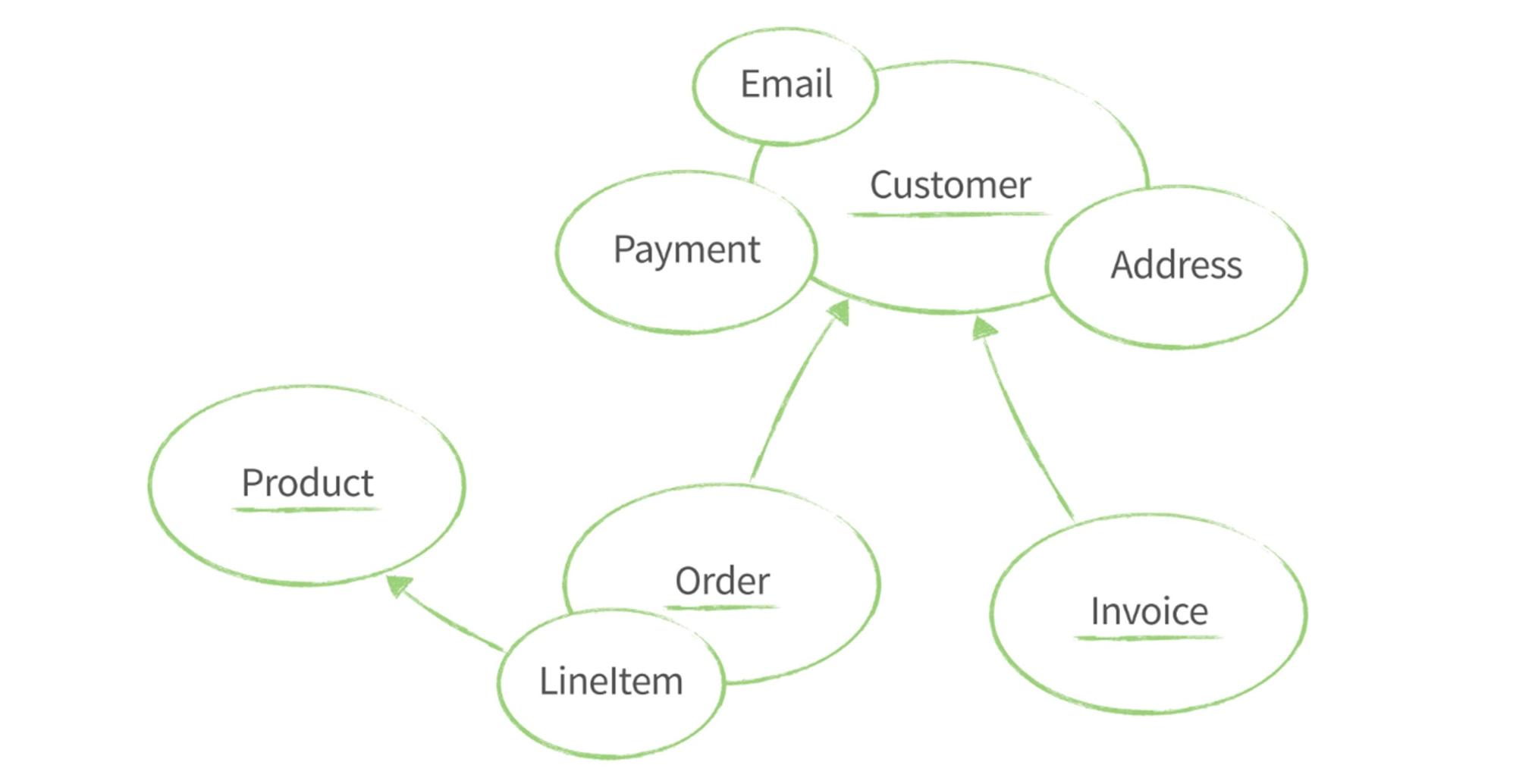
Все, что подчеркнуто, это корень агрегации. Это то, с чем я хочу работать напрямую: важное, ценное, целостное.
С чего начать? Создадим в проекте пустой пакет, куда будем складывать наши агрегаты. Агрегаты лучше писать с чем-то декларативным, вроде dataclasses или attrs.

Dataclasses. Если какой-то dataclass укажем агрегатом — напишем на него аннотацию с помощью NewType. В аннотации укажем явный референс, который выразим в системе типов. Если же dataclass — просто структура данных (entity), то сохраним внутри агрегата.
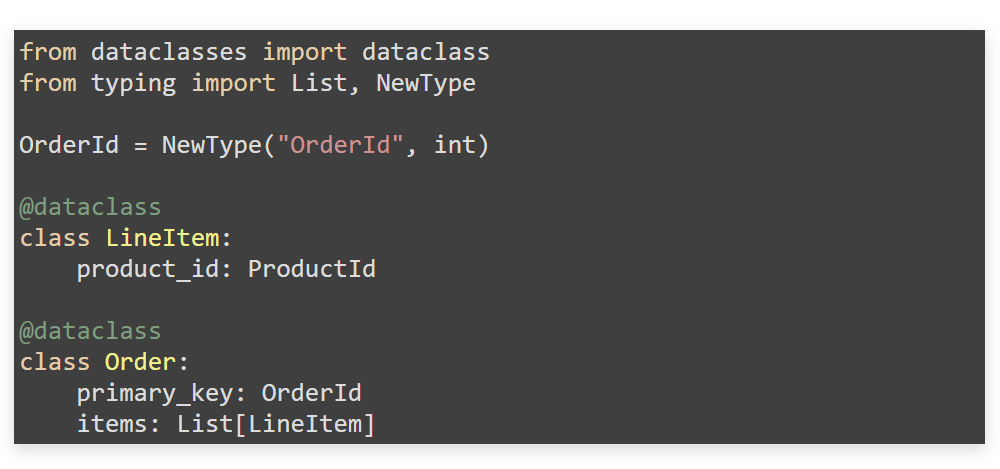
В контексте Stories могут лежать только агрегаты. Доступ к чему-то вложенному в них можно получить только через публичные методы и правила высокого уровня. Это позволяет логично и грамотно выстроить модель, над которой мы трудимся вместе с экспертами из предметной области. Это тот самый единый язык.
Сразу же возникает проблема — репозитории. У меня есть база данных, с которой я работаю через Django, соседний микросервис, в который я отправляю запросы, есть JSON и экземпляр Django-модели. Получать данные и переносить их руками, просто чтобы вызвать или проверить метод красиво? Нет, конечно. В dry-python есть библиотека Mappers, которая позволяет сопоставлять высокоуровневые абстракции и доменные агрегаты с местами, где мы их храним.
Mappers
Добавляем еще один пакет к нашему проекту — репозиторий, в котором будем хранить наши
mappers. Это то, как высокоуровневую бизнес логику будем переносить на реальный мир.
Например, мы можем описать то, как мы сопоставляем какой-нибудь
dataclass с Django-моделью.
Django ORM. Сопоставляем модель заказа с описанием Django ORM — смотрим поля.
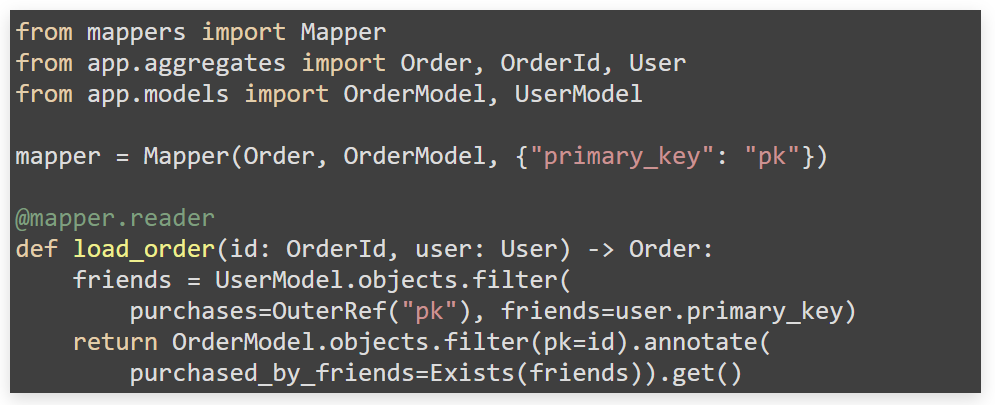
Например, некоторые поля можем переписать через опциональный config. Произойдет следующее: mapper во время декларации будет сравнивать, как написан dataclass и модель. Например, аннотации int (в Order dataclass есть поле cost с аннотацией int) в Django-модели соответствует integer field с опцией nullable="true". Здесь dataclass предложит добавить optional в dataclass, или убрать nullable из field.
Через Mappers можно добавлять функции, которые что-то читают или пишут. Читающие — это функции, которые получают на вход агрегат и возвращают на него референс. Пишущие поступают наоборот — возвращают агрегаты. Под капотом может быть, например, запрос к базе через Django.
Определения Swagger.Те же операции можно проводить и с микросервисами. Можно написать на них часть swagger-схемы и проверить, насколько swagger-схема конкретного сервиса соответствует вашим доменным моделям. Дальше вернувшийся запрос из библиотеки Request будет прозрачно транслирован в dataclass.
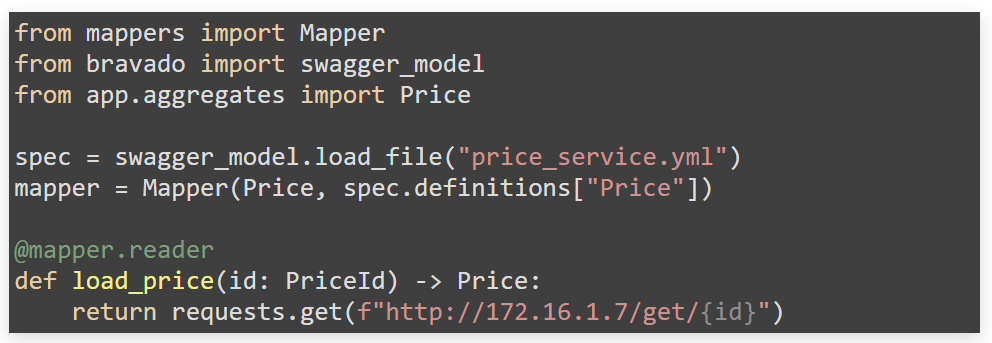
Запросы GraphQL. GraphQL и микросервисы: схема типов интерфейсов GraphQL отлично валидируется против dataclass. Можно транслировать конкретные запросы GraphQL во внутренние структуры данных.
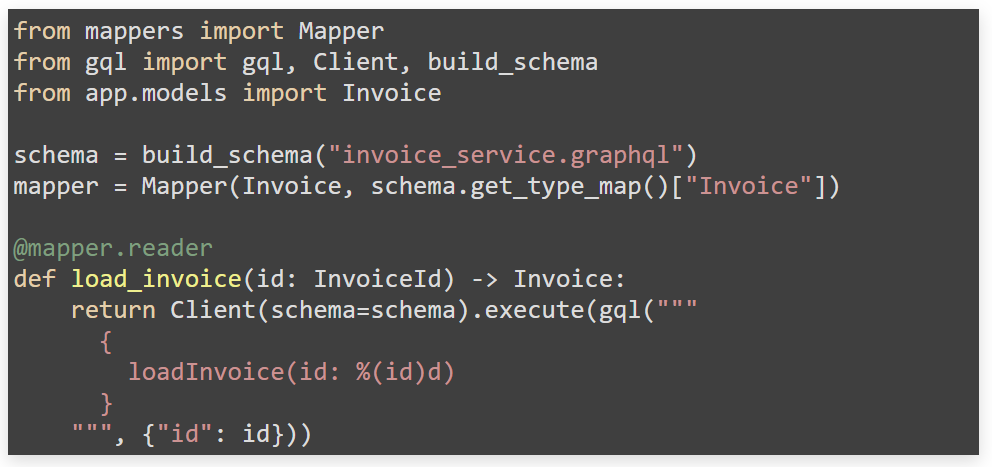
Зачем вообще так заботиться о внутренней высокоуровневой модели данных внутри приложения? Для иллюстрации «зачем» расскажу «занимательную» историю.
В одном нашем проекте веб-сокеты работали через сервис Pusher. Мы не заморачивались, обернули его в интерфейс, чтобы не вызывать напрямую. Этот интерфейс привязывали во всех Stories и были довольны.
Но бизнес-требования изменились. Оказалось, что гарантий, которые предоставляет Pusher к веб сокетам, недостаточно. Например, нужна гарантированная доставка сообщений и история сообщений за последние 2 минуты. Поэтому мы решили переехать на сервис Ably Realtime. В нем же есть интерфейс — напишем адаптер и привяжем его везде, все будет здорово. На самом деле нет.
Абстракции, которые использует Pusher (аргументы функций) попали в каждый бизнес-объект. Пришлось поправить порядка 100 Stories, и исправить формирование канала пользователей, в который мы что-то отправляем.
Вернемся к тестам.
Tests & mocks
Как обычно тестируют такое поведение с внешними сервисами? Что-то мокаем, смотрим, как вызывается сторонняя библиотека, и все — мы уверены, что все хорошо. Но когда библиотека меняется, то форматы аргументов тоже меняются.

Можно сэкономить неделю переписывания тысячи тестов и сотни бизнес-кейсов, если тестировать поведение внутренней модели иначе. Например, чем-то похожим на интеграционное тестирование: пишем в поток пользователя, а уже внутри адаптера, Pusher или Ably транслируем этот поток в название нормального канала, чтобы не писать это все в бизнес-логику.
Dependencies
В такой модельной архитектуре появляется много лишних сущностей. Раньше мы брали какую-нибудь Django-функцию и писали ее: запрос, ответ, минимум телодвижений. Здесь надо инициализировать Mappers, положить в Stories и инициализировать, обработать строку запроса HTTP-запроса, посмотреть, какой ответ отдать. Все это выливается в 30-50 строк boilerplate кода вызова Stories внутри Django-view.
С другой стороны у нас уже написаны интерфейсы и Mappers. Мы можем проверить их совместимость с конкретным бизнес-кейсом, например, с помощью библиотеки Dependencies. Как? Через паттерн Dependency injection все декларативно склеим с минимальным boilerplate.
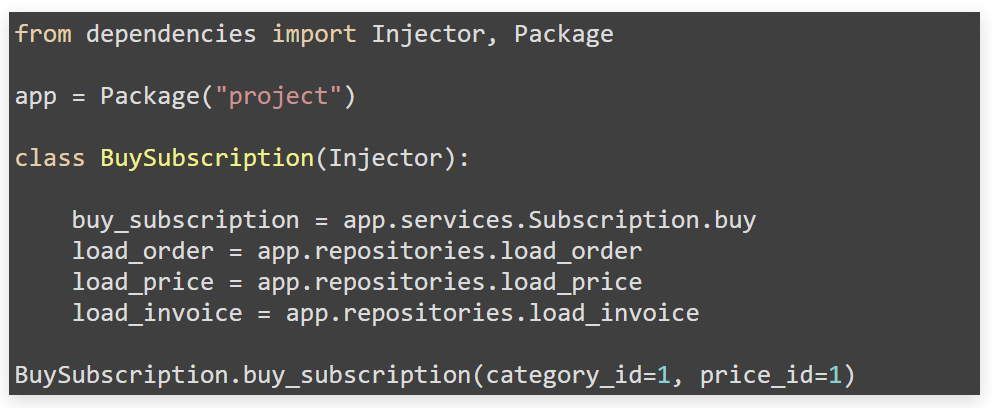
Здесь мы указываем задачу взять в пакете services класс, поместить в него три mappers, проинициализировать объект Stories и отдать нам. С таким подходом количество boilerplate в коде уменьшается колоссально.
Карта рефакторинга
Применяя все, о чем я говорил, мы разработали схему, по которой переписали большой проект с Django сигналов (неявного «callback hell») на Django по DDD.
Первый шаг без DDD. Сначала у нас не было DDD — мы писали MVP. Когда заработали первые деньги, пригласили инвесторов, и убедили перейти на DDD.
Stories без контрактов. Разбили проект на логичные бизнес-кейсы без контрактов данных.
Контракты и агрегаты. Потом один за одним перетащили контракт данных на каждую модель, которые прослеживаются в нашей архитектуре.
Mappers. Написали Mappers, чтобы избавиться от шаблонов работы с хранилищами данных.
Внедрение зависимостей. Избавились от шаблонов склейки.
Если ваш проект перерос MVP и в нем требуется срочно менять архитектуру, чтобы он не скатился в legacy — посмотрите в сторону DDD.
Какие еще есть способы избежать legacy в Python-проектах, или как с ним бороться, если досталось тяжелое наследство, обсудим на Moscow Python Conf++ 27 марта. Кроме того в расписании конференции доклады о самых разных аспектах работы с Python и об альтернативных вариантах решения привычных задач. А за пределами выступлений у нас unconference, общение с коллегами из профессиональных сообществ, и консультации партнеров, например, как раз Drylabs.А если DDD интересует вас вне Python, то рекомендую обратить внимание на TechLead Conf — конференцию про процессы и практики разработки качественных IT-продуктов, на которой будет DDD радар. Конференция состоится 8 июня, Call for Papers открыт до 6 апреля.
Комментариев нет:
Отправить комментарий