
Поначалу история звучит довольно просто: СХД хорошо работает три года на расширенной гарантии, относительно нормально живёт четвёртый, а на пятый покупается новая вместо устаревшей. Вендоры выжимают из вас деньги повышением стоимости поддержки и всякими платными фичами вроде поддержки VDI. Можно поломать эту схему? Наверное, да.
Компания вышла на рынок с интригующим предложением: железяка всегда работает, всегда делает это быстро, стоимость поддержки каждый год одна и та же, все фичи доступны сразу. Ну то есть просто взяли коробку и время от времени меняют в ней комплектующие так, что они устаревают примерно со скоростью замены. Раз в три года обновляются контроллеры, есть возможность замены старых дисков на более современные, т. е. занимаемое СХД в стойке место может не только расти, но и уменьшаться, при этом объём и производительность увеличиваются.
Собственно, первое, что вы видите в стойке — это ручки с названием модели, за которые можно и нужно дёргать контроллеры из массива.

Делается это без выключения, наживую, и запас производительности такой, чтобы банковские системы не тормозили во время замены. Чтобы так получилось, понадобилось написать собственную файловую систему (точнее, аналог RAID), собрать внутри кластер и сделать ещё пару улучшений, заодно выкидывая оверхед, доставшийся от жёстких дисков.
Давайте посмотрим, что получилось и как получилось. Начнём с архитектуры.
Для начала — процедура работы с массивом не предусматривает кнопок питания. Совсем. Не понадобится. Для выключения достаточно просто выдернуть кабели из PDU.

Архитектура Pure Storage
Компания начинала с того, что разработала с нуля очень хорошую архитектуру, заточенную под флеш (c 2017 года — NVMe), и эффективные алгоритмы дедупликации и компрессии данных. Расчёт был такой: на рынке тогда были массивы из жёстких дисков, гибридные решения и SSD all-flash. Флешовые были дорогие, а дисковые — медленные. Соответственно, они ворвались в конкурентное окружение с флешовыми массивами по цене владения дисковых.

Сделали вот что:
- Написали собственную ОС для дисков. Главная особенность — быстрое сжатие данных перед записью, а потом постпроцессинг с мощным дедупом, который позволяет утрамбовать их ещё плотнее и точнее.
- Взяли только флешовые диски (сейчас это вообще строго NVMе) и мощное железо для вычислений.
Первые внедрения были под VDI-среды, поскольку данные там очень хорошо сжимаются. Алгоритмы дедупликации и сжатия давали выигрыш в шесть–девять раз по используемому месту, то есть при всех преимуществах all-flash скидывали цены примерно на порядок. Плюс подкупала экономическая модель: фиксированная стоимость на поддержку и возможность не менять железку. Тогда я увидел первые замены двух стоек на трёх или шестиюнитовые исполнения, но всё ещё не верил, что эта железяка будет использоваться где-то за пределами VDI.
И тут LinkedIn начал хранить на этих железках. Подключился AT&T. Топ банков и телекомов в США тоже закупил в прод.
Оказалось, алгоритмы сжатия достаточно хорошо подходят для сред разработки и тестирования. После замены SSD на NVME внезапно началась конкуренция в обычных транзакционных базах данных в банковском сегменте. Потому что массив получался быстрым и надёжным из-за своей архитектуры «в любой момент можем потерять два любых флеш-модуля». Потом вышел флеш-массив на более дешёвых чипах (QLC) со временем отклика 2–4 мс, а не 1 мс как в топовых моделях, и я начал наблюдать вынос тех же VNX и Compellent. Стало понятно, что железка вполне себе конкурентоспособная.
Естественно, стоимость ТБ будет по-прежнему высокой там, где есть несжимаемые данные: это шифрование, хранение архивов, видеопотоки (видеонаблюдение) и библиотеки изображений, но иногда и такие внедрения случаются, когда клиенту требуется большая производительность. Знаю случай, когда сжали видео (казалось бы, сжатые данные) дополнительно на 10 %.
Но даже для обычных баз данных оказалось вполне рабочей по цене за гигабайт.
И вот тут-то начала подкупать модель «вечнозелёной» СХД.
Постоянный апгрейд
За пять лет в железке из старого остаётся только шасси и блоки питания, по сути. Можно переезжать рывками с переносами, а можно менять комплектующие как в кластере. Собственно, это и есть кластер, только собранный в одной трёхюнитовой (или шестиюнитовой) коробке. Железо делали с нуля для себя. Сначала давайте посмотрим на архитектуру, а потом перейдём к тому, почему удобно менять её по кускам.

Интересные решения такие:
- Вычислительная мощность всегда в два раза избыточная: это нужно для замены контроллера без деградации производительности. При этом на фронте работают оба контроллера, а на бэкенде для записи на флеш-модули используется один контроллер.
- RAID-массив заложен на уровне ОС контроллеров, он N + 2, то есть можно без остановки вытаскивать два любых диска. Что самое смешное, как вытаскиваешь — можно поменять их местами и воткнуть обратно, и всё продолжит работать. Это я на тестах проверил.
- Поскольку дисков N + 2, всегда можно восстанавливать данные, используя наименее занятые диски. То есть если данные хранятся на пяти дисках, то достаточно трёх из них для полноценного чтения. И RAID, собственно, читает с трёх дисков, потому что восстановить данные, используя процессорную мощность второго контроллера (который стоит в запасе фактически) быстрее, чем прочесть полный набор.
- И можно выбирать для чтения наименее занятые диски! То есть если в нашем примере данные на пяти дисках, то мы будем читать с тех, куда не идёт запись. Система приоритетов тоже на уровне ОС контроллера, и это какая-то чёртова магия.
- Как вы помните, кэша контроллера нет! Есть буфер на запись, установленный отдельно в шасси, он маленький (несколько ГБ), и он задействуется доли секунды во время онлайн-сжатия данных. Защищён он, кстати, большими конденсаторами, которые позволяют успеть записать всё из буфера при отключении питания. Это я тоже несколько раз проверил. Буфер защищён зеркалированием двойным, там четыре модуля в RAID 10.
- Вместо кэша контроллера на чтение — сами NVMe-диски, на запись — модули NVRAM. Дополнительно возможна установка модулей Optane. Архитектура не похожа на мидрейндж — не зеркалирует кэш, нет классического кэша (но есть SCM-память), нет накладных расходов на это.
- Вместо кнопки питания просто гнездо кабеля. Если его вдруг нужно куда-то перевозить, то есть процедура выключения, но можно просто дёрнуть кабель. Страшно, но работает.
- На первичной записи в буфере лёгкая компрессия примерно уровня 3:1, дальше данные пишутся на диск и потом на постпроцессинге прогоняются тяжёлыми алгоритмами и дедупом. Гранулярность блока 512 байт при том, что норма в индустрии 8 КБ. Если блоки повторяются — они плавающие, то есть на повторах границы раздвигаются. Это даёт лучшие коэффициенты сжатия по сравнению с другими вендорами. Старые архитектуры заточены на HDD, новые же позволяют менять время процессоров на более плотную упаковку.
- Приложение может прозрачно переезжать без переключения томов на другие такие же устройства (это для удалённой репликации). Весь софт входит в базовую поставку, апдейты приходят в виде обновлений прошивки.
Но компании оказалось мало собрать свою архитектуру и написать к ней фактически серверную ОС. Они залезли ещё в низкий уровень самих флеш-чипов и выпустили свои. Но при этом совместимые со стандартами. Сверху интерфейс NVMe, внутри чипы своей разработки.

По такому пути ходила Violin, что когда-то дало им космически быстрые массивы. Только они сделали свой собственный стандарт, а здесь используется открытый и общедоступный. Для чего это нужно? Прошивка чипа представляет собой часть прошивки контроллера, и поэтому СХД точно знает, что именно происходит на каждом отдельном кирпичике.

Если в обычной дисковой полке каждый SSD или NVMe-модуль — это маленький чёрный ящик для контроллера, то тут он видит вообще всё. Понадобилось это при решении проблемы большого адресуемого объёма, потому что проблемы flash-массивов всё те же: управление износом, сбор мусора и т. п. Это делается прошивкой контроллеров.


То есть, как видите, пазл складывается так: дешёвое место достигается за счёт обмена на производительность. Высокая производительность означает постоянное избыточное число процессоров и RAID. Избыточное число процессоров означает мощный постпроцессинг сжатия и возможность терять любую часть без потери производительности. RAID сочетается с этой идеей. То есть все эти преимущества чуть ли не бесплатно дают фишку вынимать любую часть «наживую».
Дальше приходит маркетинг и предлагает громкое заявление «нестареющая СХД». Фиксированный ценник поддержки, включено всё ПО, никаких дополнительных бандлов. За счёт отдельного уровня сервиса можно делать замену контроллеров бесплатно раз в три года (Evergreen GOLD-уровень). Есть апгрейды по мере повышения требований: я видел, как XR2 поменяли на XR3. Поработал год, потом пришёл бизнес, сказал, нам нужно новое. У вендора есть вариант сдать старые контроллеры трейд-ином и получить новые раньше времени. Хороший апгрейд. Контроллеры просто меняются по одному.
Апгрейд дисков интереснее. Приходит сервисная полка дополнительная с дисками с завода. На полку мигрируются данные без остановки — все данные с тех носителей, что подлежат замене. Полка работает с основными контроллерами (у неё есть и свои). Фактически это юнит-датапак, временное хранилище. Когда миграция кончается, диски помечаются как ОК, инженер их вынимает из шасси. На место старых вставляет новые и запускает обратную миграцию. Это занимает день и больше, но приложения и сервера не замечают. Поскольку эти СХД часто стоят у сервис-провайдеров, есть возможность одновременной замены и апгрейда: в рамках Evergreen GOLD можно старые диски поменять на несколько новых ёмких и быстрых, плюс докупить таких же.
Так, хорош заливать, слабое место всегда компрессия!
Это мы привыкли слышать от пользователей дисковых СХД. Там история стандартная — функционал не предусматривался при разработке архитектуры — включили сжатие, приложение остановилось, дальше потратили много времени на то, чтобы всё заново восстановить под ругань руководства. Как уже говорили, в Pure Storage пошли другим путём — дедупликацию с компрессией сделали базовым неотключаемым функционалом. Результат — сейчас Pure Storage cтоит более чем в 15 тысячах инсталляциях. Во время инициализации можно поставить галочку «давать обезличенную статистику», и тогда ваша СХД будет отправлять в систему мониторинга Pure 1. Гарантия для баз данных, например, — 3,5:1. Есть конкретные особенности — тот же VDI от 7:1 и выше. Массивы продаются не по сырому месту, а по полезной ёмкости с гарантией допоставки, то есть если у вас при миграции окажется уровень сжатия ниже гарантируемого, вендор ставит больше физических дисков бесплатно. Вендор говорит, что диски доставляются в примерно 9-10 % случаях, и ошибка редко превышает пару накопителей. В России я такое ещё не видел, коэффициенты совпадали на всех инсталляциях кроме случая, когда «вскрываются» шифрованные данные, про которые заказчик не сказал, что они шифрованные.
Из-за особенностей снапшотов тестовые среды получаются очень эффективными. Есть пример клиента, который делал сайзинг 7:1 в расчёте, а получил 14 с копейками к одному.
Вендор заявляет следующее:
- 3,5:1 базы данных (Oracle, MS SQL).
- 4,2:1 виртуализация серверов (VMware, Hyper-V).
- 7,1:1 VDI (Citrix, VMware).
- 5:1 средний коэффициент по всей инсталлированной базе.
Также из интересного функционала: автоматизация и интеграция с модными молодёжными штуками типа Kubernetes, а также полная поддержка VMware vvol. Здесь всё просто — большая часть западных клиентов Pure Storage — облачные провайдеры типа ServiceNow, кейс по которым, кстати, выложен на сайте. Они привыкли всё максимально автоматизировать.
Итого
Получилась интересная штука, которая сначала выглядит странно, а потом всё радостнее и радостнее. Пять лет в Гартнере:
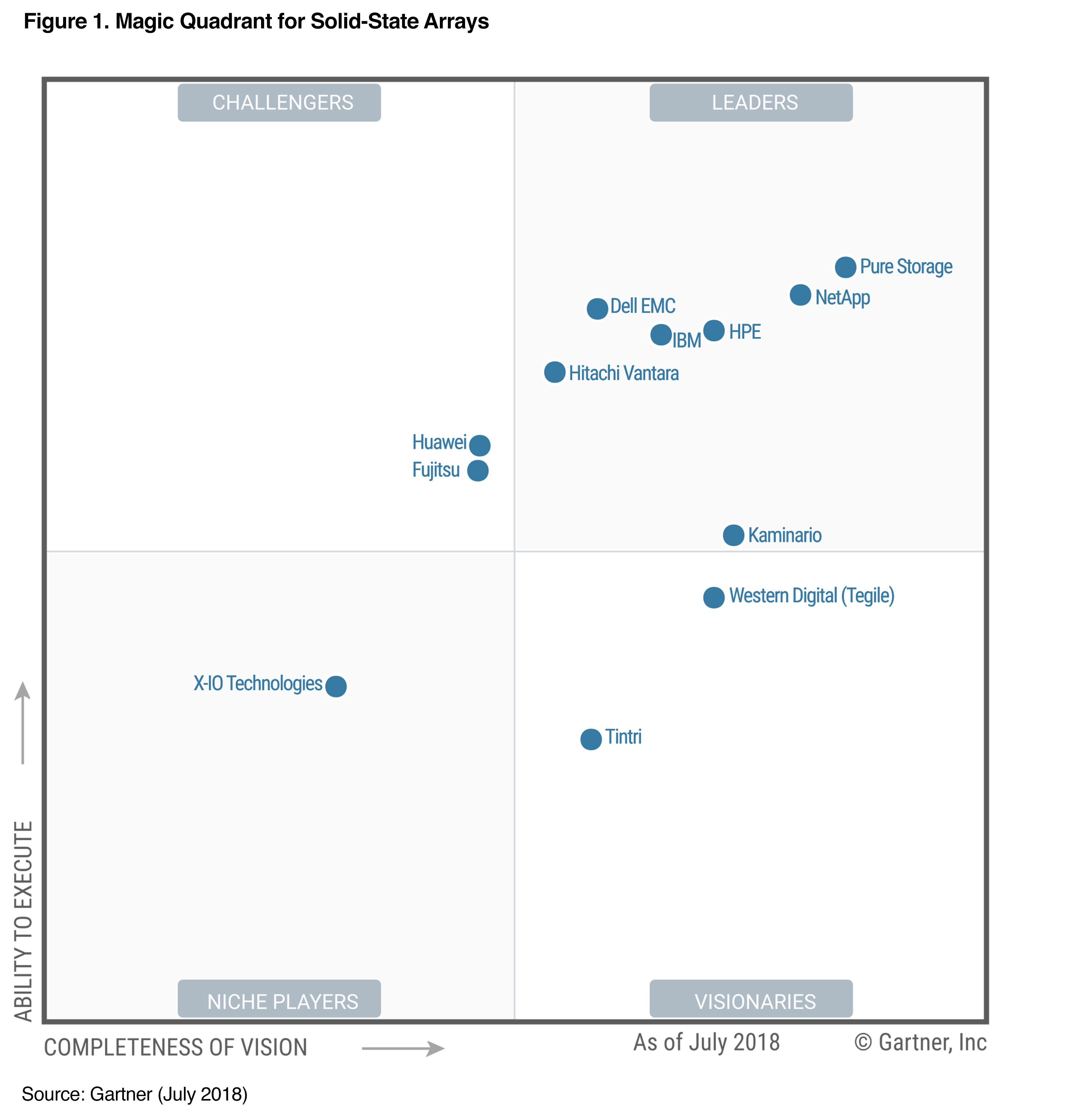
Конечно, экономическая модель Evergreen не такая, что прямо дёшево-дёшево, но от ряда геморроев спасает и при расчёте стоимости владения на несколько лет выглядит вполне конкурентоспособно.
P.S. По ссылке доступен онлайн-митап: «Системы хранения данных по подписке: правда или вымысел».
Комментариев нет:
Отправить комментарий