
Представляем настраиваемую и интерактивную структуру дерева решений, написанную на Python. Эта реализация подходит для извлечение знаний из данных, проверки интуитивного представления, улучшения понимание внутренней работы деревьев решений, а также изучение альтернативных причинно-следственных связей в отношении вашей проблемы обучения. Она может использоваться в качестве части более сложных алгоритмов, визуализации и отчётов, для любых исследовательских целей, а также как доступная платформа, чтобы легко проверить ваши идеи алгоритмов дерева решений.
TL;DR
- Репозиторий HDTree
- Дополняющий Notebook внутри
examples. Каталог репозитория здесь (каждая иллюстрация, которую вы видите здесь, будет сгенерирована в блокноте). Вы сможете создавать иллюстрации самостоятельно.
О чём пост?
О еще одной реализация деревьев решений, которую я написал в рамках своей диссертации. Работа разделена на три части следующим образом:
- Я попытаюсь объяснить, почему я решил потратить своё время, чтобы придумать собственную реализацию деревьев решений. Я перечислю некоторые из его функций, но также недостатки текущей реализации.
- Я покажу базовое использование HDTree с помощью фрагментов кода и объяснений некоторых деталей по ходу дела.
- Подсказки о том, как настроить и расширить HDTree вашими идеями.
Мотивация и предыстория
Для диссертации я начал работать с деревьями решений. Моя цель сейчас – реализовать ориентированную на человека ML-модель, где HDTree (Human Decision Tree, если на то пошло) — это дополнительный ингредиент, который применяется как часть реального пользовательского интерфейса для этой модели. Хотя эта история посвящена исключительно HDTree, я мог бы написать продолжение, подробно описав другие компоненты.
Особенности HDTree и сравнение с деревьями решений scikit learn
Естественно, я наткнулся на реализацию деревьев решений
scikit-learn [4]. Реализация sckit-learn имеет множество плюсов:
- Она быстра и оптимизирована;
- Написана на диалекте Cython. Cython компилируется в C-код (который, в свою очередь, компилируется в двоичный код), сохраняя при этом возможность взаимодействия с интерпретатором Python;
- Простая и удобная;
- Многие люди в ML знают, как работать с моделями
scikit-learn. Вам помогут везде благодаря его пользовательской базе; - Она испытана в боевых условиях (её используют многие);
- Она просто работает;
- Она поддерживает множество методов предварительной и последующей обрезки [6] и предоставляет множество функций (например, обрезка с минимальными затратами и весами выборки);
- Поддерживает базовую визуализацию [7].
Тем не менее, у нее, безусловно, есть некоторые недостатки:
- Ее нетривиально изменять, отчасти из-за использования довольно необычного диалекта Cython (см. преимущества выше);
- Нет возможности учитывать знания пользователей о предметной области или изменить процесс обучения;
- Визуализация достаточно минималистичная;
- Нет поддержки категориальных признаков;
- Нет поддержки отсутствующих значений;
- Интерфейс для доступа к узлам и обхода дерева громоздок и не понятен интуитивно;
- Нет поддержки отсутствующих значений;
- Только двоичные разбиения (смотрите ниже);
- Нет многовариантных разбиений (смотрите ниже).
Особенности HDTree
HDTree предлагает решение большинства этих проблем, но при этом жертвует многими преимуществами реализации scikit-learn. Мы вернемся к этим моментам позже, поэтому не беспокойтесь, если вы еще не понимаете весь следующий список:
- Взаимодействует с обучающим поведением;
- Основные компоненты имеют модульную структуру и их довольно легко расширить (реализовать интерфейс);
- Написана на чистом Python (более доступна);
- Имеет богатую визуализацию;
- Поддерживает категориальные данные;
- Поддерживает отсутствующих значений;
- Поддерживает многовариантные разделения;
- Имеет удобный интерфейс навигации по структуре дерева;
- Поддерживает n-арное разбиение (больше 2 дочерних узлов);
- Текстовые представления путей решения;
- Поощряет объясняемость за счет печати удобочитаемого текста.
Минусы:
- Медленная;
- Не проверена в боях;
- Качество ПО посредственно;
- Не так много вариантов обрезки. Хотя реализация поддерживает некоторые основные параметры.
Недостатков не много, но они критичны. Давайте сразу же проясним: не скармливайте этой реализации большие данные. Вы будете ждать вечно. Не используйте её в производственной среде. Она может неожиданно сломаться. Вас предупредили! Некоторые из проблем выше можно решить со временем. Однако скорость обучения, вероятно, останется небольшой (хотя логический вывод допустим). Вам нужно будет придумать лучшее решение, чтобы исправить это. Приглашаю вас внести свой вклад. Тем не менее, какие возможны варианты применения?
- Извлечение знаний из данных;
- Проверка интуитивного представление о данных;
- Понимание внутренней работы деревьев решений;
- Изучение альтернативных причинно-следственных связей в отношении вашей проблемы обучения;
- Использование в качестве части более сложных алгоритмов;
- Создание отчётов и визуализация;
- Использование для любых исследовательских целей;
- В качестве доступной платформы, чтобы легко проверить ваши идеи для алгоритмов дерева решений.
Структура деревьев решений
Хотя в этой работе не будут подробно рассмотрены деревья решений, мы резюмируем их основные строительные блоки. Это обеспечит основу для понимания примеров позже, а также подчеркнет некоторые особенности HDTree. На следующем рисунке показан фактический результат работы HDTree (за исключением маркеров).
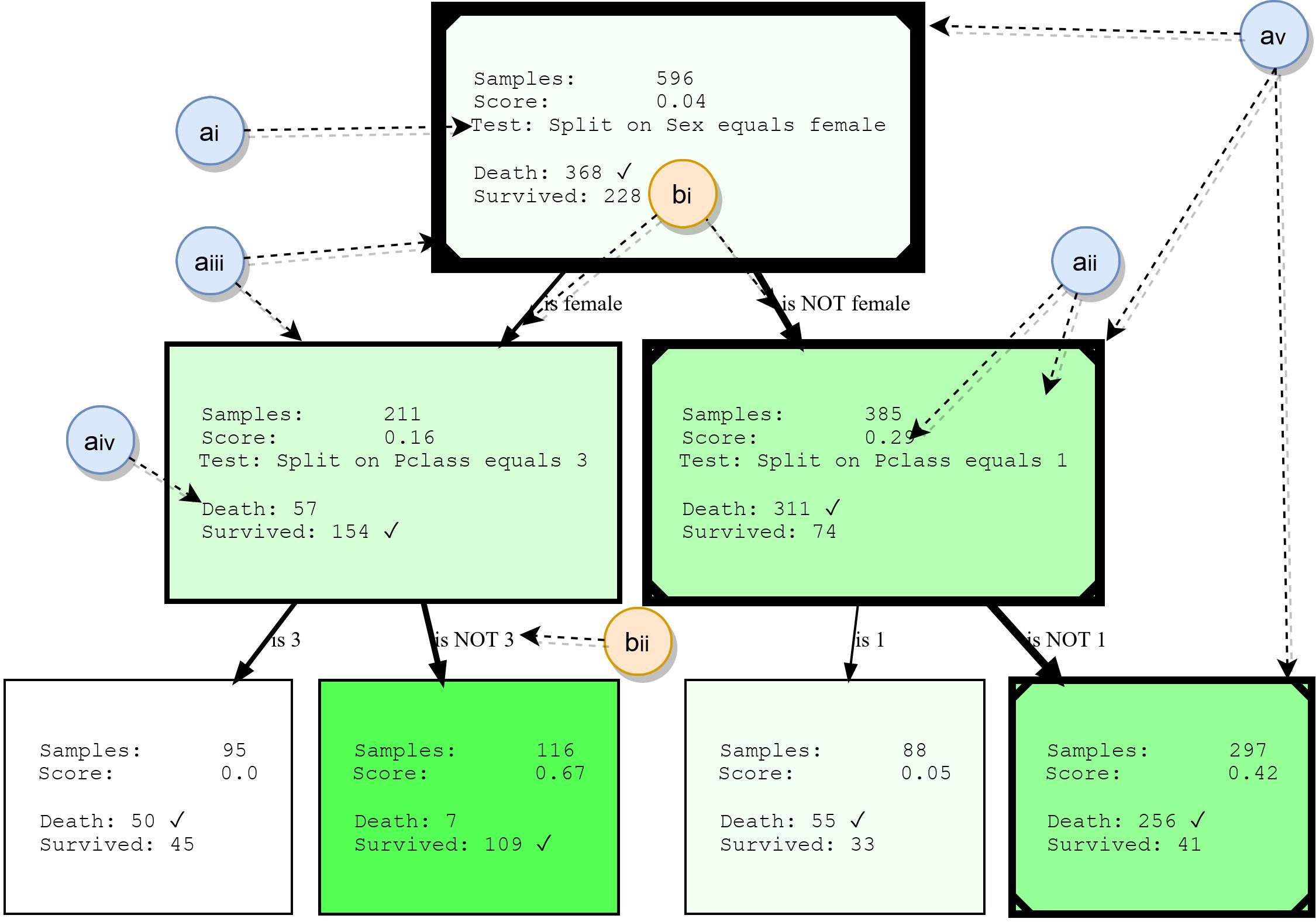
Узлы
- ai: текстовое описание правила проверки и разделения, которое использовалось на этом узле для разделения данных на его дочерние элементы. Отображает соответствующий атрибуты и словесное описание операции. Эти тесты *легко настраиваются* и могут включать любую логику разделения данных. Разработка собственных пользовательских правил поддерживается за счет реализации интерфейса. Подробнее об этом в разделе 3.
- aii: оценка узла измеряет его чистоту, то есть то, насколько хорошо данные, проходящие через узел, разделены. Чем выше оценка, тем лучше. Записи также представлены цветом фона узлов. Чем больше зеленоватого оттенка, тем выше оценка (белый цвет означает нечистые, т.е. равномерно распределенные классы). Эти оценки направляют построение дерева и являются модульным и заменяемым компонентом HDTree.
- aiii: рамка узлов указывает на то, сколько точек данных проходит через этот узел. Чем толще граница, тем больше данных проходит через узел.
- aiv: список целей прогнозирования и меток, которые имеют точки данных, проходящие через этот узел. Самый распространенный класс отмечен .
- av: опционально визуализация может отмечать путь, по которому следуют отдельные точки данных (иллюстрируя решение, которое принимается, когда точка данных проходит дерево). Это отмечено линией в углу дерева решений.
Ребра
- bi: стрелка соединяет каждый возможный результат разделения (ai) с его дочерними узлами. Чем больше данных относительно родителя «перетекает» по краю, тем толще они отображаются.
- bii: каждое ребро имеет удобочитаемое текстовое представление соответствующего результата разбиения.
Откуда разные разделения наборов и тесты?
К этому моменту вы уже можете задаться вопросом, чем отличается HDTree от дерева
scikit-learn (или любой другой реализации) и почему мы можем захотеть иметь разные виды разделений? Попробуем прояснить это. Может быть, у вас есть интуитивное понимание понятия пространство признаков. Все данные, с которыми мы работаем, находятся в некотором многомерном пространстве, которое определяется количеством и типом признаков в ваших данных. Задача алгоритма классификации теперь состоит в том, чтобы разделить это пространство на не перекрывающиеся области и присвоить этим областям класс. Давайте визуализируем это. Поскольку нашему мозгу трудно возиться с высокой размерностью, мы будем придерживаться двухмерного примера и очень простой задачи с двумя классами, вот так:

Вы видите очень простой набор данных, состоящий из двух измерений (признаков/атрибутов) и двух классов. Сгенерированные точки данных были нормально распределены в центре. Улица, которая является просто линейной функцией f(x) = y разделяет эти два класса: Class 1 (правая нижняя) и Class 2 (левая верхняя) части. Также был добавлен некоторый случайный шум (синие точки данных в оранжевой области и наоборот), чтобы проиллюстрировать эффекты переобучения в дальнейшем. Задача алгоритма классификации, такого как HDTree (хотя он также может использоваться для задач регрессии), состоит в том, чтобы узнать, к какому классу принадлежит каждая точка данных. Другими словами, задана пара координат (x, y) вроде (6, 2). Цель в том, чтобы узнать, принадлежит ли эта координата оранжевому классу 1 или синему классу 2. Дискриминантная модель попытается разделить пространство объектов (здесь это оси (x, y)) на синюю и оранжевую территории соответственно.
Учитывая эти данные, решение (правила) о том, как данные будут классифицированы, кажется очень простым. Разумный человек сказал бы о таком «подумайте сначала самостоятельно».«Это класс 1, если x > y, иначе класс 2». Идеальное разделение создаст функция
y=x, показанная пунктиром. В самом деле, классификатор максимальной маржи, такой как метод опорных векторов [8], предложил бы подобное решение. Но давайте посмотрим, какие деревья решений решают вопрос иначе:

На изображении показаны области, в которых стандартное дерево решений с увеличивающейся глубиной классифицирует точку данных как класс 1 (оранжевый) или класс 2 (синий).
Дерево решений аппроксимирует линейную функцию с помощью ступенчатой функции.Это связано с типом правила проверки и разделения, которое используют деревья решений. Они все работают по схеме
attribute < threshold, что приведет к к гиперплоскостям, которые параллельны осям. В 2D-пространстве «вырезаются» прямоугольники. В 3D это были бы кубоиды и так далее. Кроме того, дерево решений начинает моделировать шум в данных, когда уже имеется 8 уровней, то есть происходит переобучение. При этом оно никогда не находит хорошего приближения к реальной линейной функции. Чтобы убедиться в этом, я использовал типичное разделение тренировочных и тестовых данных 2 к 1 и вычислил точность деревьев. Она составляет 93,84%, 93,03%, 90,81% для тестового набора и 94,54%, 96,57%, 98,81% для тренировочного набора (упорядочены по глубине деревьев 4, 8, 16). Тогда как точность в тесте уменьшается, точность обучения увеличивается.Повышение эффективности тренировок и снижение результатов тестов — признак переобучения.Полученные деревья решений довольно сложны для такой простой функции. Самое простое из них (глубина 4), визуализированное с помощью scikit learn, уже выглядит так:
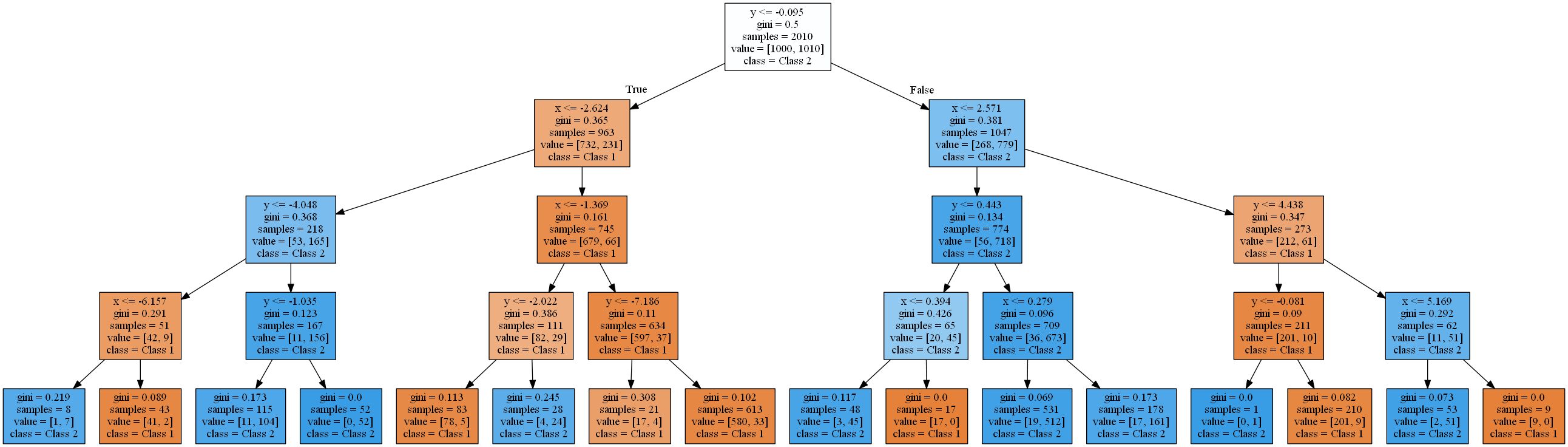
Я избавлю вас от деревьев сложнее. В следующем разделе мы начнем с решения этой проблемы с помощью пакета HDTree. HDTree позволит пользователю применять знания о данных (точно так же, как знание о линейном разделении в примере). Также оно позволит найти альтернативные решения проблемы.
Применение пакета HDTree
Этот раздел познакомит вас с основами HDTree. Я постараюсь коснуться некоторых частей его API. Пожалуйста, не стесняйтесь спрашивать в комментариях или свяжитесь со мной, если у вас есть какие-либо вопросы по этому поводу. С радостью отвечу и при необходимости дополню статью. Установка HDTree немного сложнее, чем
pip install hdtree. Извините. Для начала нужен Python 3.5 или новее.
- Создайте пустой каталог и внутри него папку с именем hdtree (
your_folder/hdtree) - Клонируйте репозиторий в каталог hdtree (не в другой подкаталог).
- Установите необходимые зависимости:
numpy,pandas,graphviz,sklearn. - Добавьте
your_folderвPYTHONPATH. Это включит директорию в механизм импорта Python. Вы сможете использовать его как обычный пакет Python.
В качестве альтернативы добавьте
hdtree в папку site-packages вашей установки python. Я могу добавить установочный файл позже. На момент написания код недоступен в репозитории pip. Весь код, который генерируют графику и выходные данные ниже (а также ранее показанные), находятся в репозитории, а непосредственно размещены здесь. Решение линейной проблемы с помощью одноуровневого дерева
Давайте сразу начнем с кода:
from hdtree import HDTreeClassifier, SmallerThanSplit, EntropyMeasure
hdtree_linear = HDTreeClassifier(allowed_splits=[SmallerThanSplit.build()], # Split rule in form a < b
information_measure=EntropyMeasure(), # Use Information Gain for the scores attribute_names=['x', 'y' ]) # give the
attributes some interpretable names # standard sklearn-like interface hdtree_linear.fit(X_street_train,
y_street_train) # create tree graph hdtree_linear.generate_dot_graph() 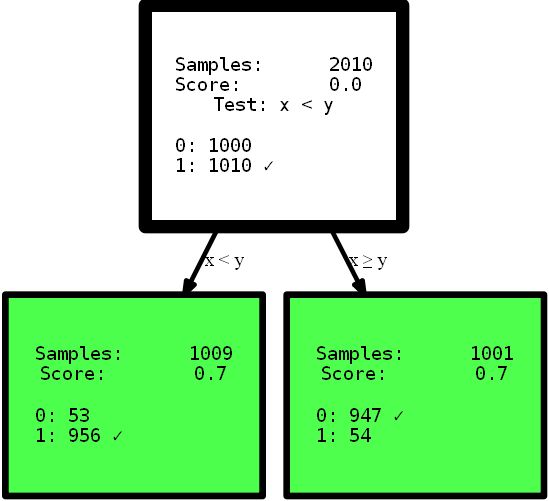
Да, результирующее дерево имеет высоту только в один уровень и предлагает идеальное решение этой проблемы. Это искусственный пример, чтобы показать эффект. Тем не менее, я надеюсь, что он проясняет мысль: иметь интуитивное представление о данных или просто предоставлять дерево решений с различными вариантами разделения пространства признаков, которое может предложить более простое, а иногда даже более точное решение. Представьте, что вам нужно интерпретировать правила из представленных здесь деревьев, чтобы найти полезную информацию. Какую интерпретацию вы сможете понять первой, а какой больше доверяете? Сложная интерпретация, использующая многошаговые функции, или небольшое точное дерево? Думаю, ответ довольно прост. Но давайте немного углубимся в сам код. При инициализации HDTreeClassifier самое важное, что вы должны предоставить, — это allowed_splits. Здесь вы предоставляете список, содержащий возможные правила разделения, которые алгоритм пробует во время обучения для каждого узла, чтобы найти хорошее локальное разделение данных. В этом случае мы предоставили исключительно SmallerThanSplit. Это разделение делает именно то, что вы видите: оно принимает два атрибута (пробует любую комбинацию) и разделяет данные по схеме a_i < a_j. Что (не слишком случайно) соответствует нашим данным настолько хорошо, насколько это возможно.
Этот тип разделения обозначается как многовариантное разделение Оно означает, что разделение использует более одного признака для принятия решения. Это не похоже на одновариантное разделение, которое используются в большинстве других деревьев, таких как scikit-tree (подробнее см. выше), которые принимают во внимание ровно один атрибут. Конечно, у HDTree также есть опции для достижения «нормального разделения», как те, что есть в scikit-деревьях — семейство QuantileSplit. Я покажу больше по ходу статьи. Другая незнакомая вещь, которую вы можете увидеть в коде — гиперпараметр information_measure. Параметр представляет измерение, которое используется для оценки значения одного узла или полного разделения (родительского узла с его дочерними узлами). Выбранный вариант основан на энтропии [10]. Возможно, вы также слышали о коэффициенте Джини, который был бы еще одним допустимым вариантом. Конечно же, вы можете предоставить своё собственное измерение, просто реализовав соответствующий интерфейс. Если хотите, реализуйте gini-Index, который вы можете использовать в дереве, не реализовывая заново ничего другого. Просто скопируйте EntropyMeasure() и адаптируйте для себя. Давайте копнем глубже, в катастрофу Титаника. Я люблю учиться на собственных примерах. Сейчас вы увидите ещё несколько функций HDTree с конкретным примером, а не на сгенерированных данных.
Набор данных
Мы будем работать со знаменитым набором данных машинного обучения для курса молодого бойца: набором данных о катастрофе Титаника. Это довольно простой набор, который не слишком велик, но содержит несколько различных типов данных и пропущенных значений, хотя и не является полностью тривиальным. Кроме того, он понятен человеку, и многие люди уже работали с ним. Данные выглядят так:

Вы можете заметить, что там все виды атрибутов. Числовые, категориальные, целочисленные типы и даже пропущенные значения (посмотрите на столбец Cabin). Задача в том, чтобы спрогнозировать, выжил ли пассажир после катастрофы «Титаника», по доступной информации о пассажире. Описание атрибутов-значений вы найдёте здесь. Изучая ML-учебники и применяя этот набор данных, вы выполняете все виды предварительной обработки, чтобы иметь возможность работать с обычными моделями машинного обучения, например, удаляя отсутствующие значения NaN путём замещения значений [12], отбрасывания строк/столбцов, унитарным кодированием [13] категориальных данных (например, Embarked и Sex или группировки данных, чтобы получить валидный набор данных, который принимает ML-модель. Такая очистка технически не требуется HDTree. Вы можете подавать данные как есть, и модель с радостью примет их. Измените данные только в том случае, когда проектируете реальные объекты. Я упростил всё для начала.
Тренировка первого HDTree на данных Титаника
Просто возьмём данные как есть и скормим их модели. Базовый код похож на код выше, однако в этом примере будет разрешено гораздо больше разделений данных.
hdtree_titanic = HDTreeClassifier(allowed_splits=[FixedValueSplit.build(), # e.g., Embarked = 'C'
SingleCategorySplit.build(), # e.g., Embarked -> ['C', 'Q', 'S']
TwentyQuantileRangeSplit.build(), # e.g., IN Quantile 3-5
TwentyQuantileSplit.build()], # e.g., BELOW Quantile 7
information_measure=EntropyMeasure(),
attribute_names=col_names,
max_levels=3) # restrict to grow to a max of 3 levels
hdtree_titanic.fit(X_titanic_train.values, y_titanic_train.values)
hdtree_titanic.generate_dot_graph()
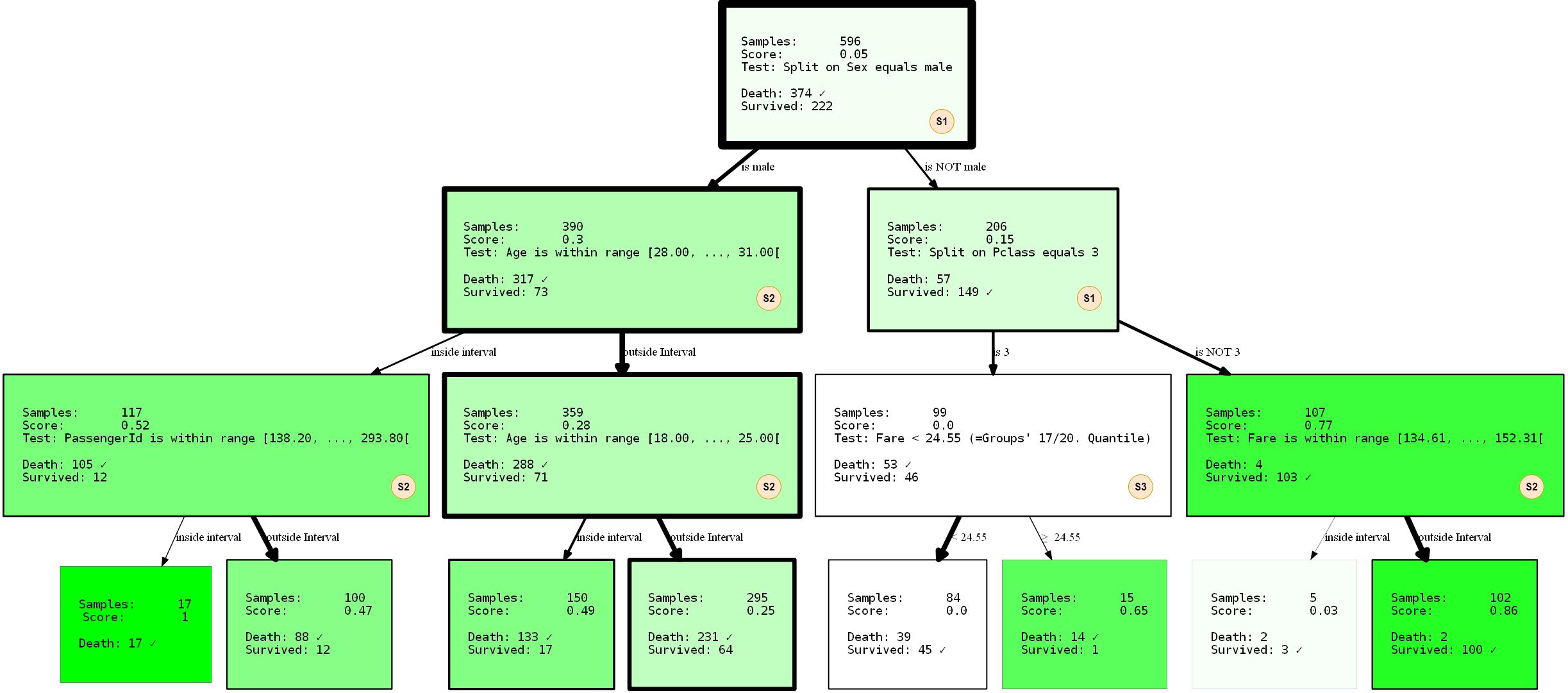
Присмотримся к происходящему. Мы создали дерево решений, имеющее три уровня, которые выбрали для использования 3 из 4 возможных правил разделения SplitRules. Они помечены буквами S1, S2, S3. Я вкратце объясню, что они делают.
- S1:
FixedValueSplit. Это разделение работает с категориальными данными и выбирает одно из возможных значений. Затем данные разделяются на одну часть, имеющую это значение, и другую часть, для которой значение не установлено. Например, PClass = 1 и Pclass ≠ 1. - S2: (Двадцать)
QuantileRangeSplit. Они работают с числовыми данными. Правила разделят соответствующий диапазон значений оцениваемого атрибута на фиксированное количество квантилей и интервалов, находящихся в пределах последовательных подмножеств. От квантиля 1 до квантиля 5 каждый включает одинаковое количество точек данных. Начальный квантиль и конечный квантиль (размер интервала) ищутся для оптимизации измерения информации (measure_information). Данные делятся на (i) имеющие значение в пределах этого интервала или (ii) — вне его. Доступны разделения различного количества квантилей. - S3: (Двадцать)
QuantileSplit. Подобно разделению диапазона (S2), но разделяет данные по пороговому значению. Это в основном то, что делают обычные деревья решений, за исключением того, что они обычно пробуют все возможные пороги вместо их фиксированного числа.
Возможно, вы заметили, что
SingleCategorySplit не задействован. Я всё равно воспользуюсь шансом пояснить, поскольку бездействие этого разделения всплывет позже:
- S4:
SingleCategorySplitбудет работать аналогичноFixedValueSplit, но создаст дочерний узел для каждого возможного значения, например: для атрибута PClass это будет 3 дочерних узла (каждый для Class 1, Class 2 и Class 3). Обратите внимание, чтоFixedValueSplitидентиченSingleValueSplit, если есть только две возможные категории.
Индивидуальные разделения несколько «умны» по отношению к типам/значениям данных, которые «принимают». До некоторого расширения они знают, при каких обстоятельствах они применяются и не применяются. Дерево также обучалось с разделением тренировочных и тестовых данных 2 к 1. Производительность — 80,37% точности на тренировочных данных и 81,69 на тестовых. Не так уж и плохо.
Ограничение разделений
Предположим, что вы по какой-то причине не слишком довольны найденными решениями. Может быть, вы решите, что самое первое разделение на вершине дерева слишком тривиально (разделение по атрибуту
sex). HDTree решает проблему. Самым простым решением было бы запретить FixedValueSplit (и, если уж на то пошло, эквивалентному SingleCategorySplit) появляться на вершине. Это довольно просто. Измените инициализацию разбиений вот так:
- SNIP -
...allowed_splits=[FixedValueSplit.build_with_restrictions(min_level=1),
SingleCategorySplit.build_with_restrictions(min_level=1),...],
- SNIP -
Я представлю получившееся HDTree целиком, поскольку мы можем наблюдать недостающее разбиение (S4) внутри только что сгенерированного дерева.
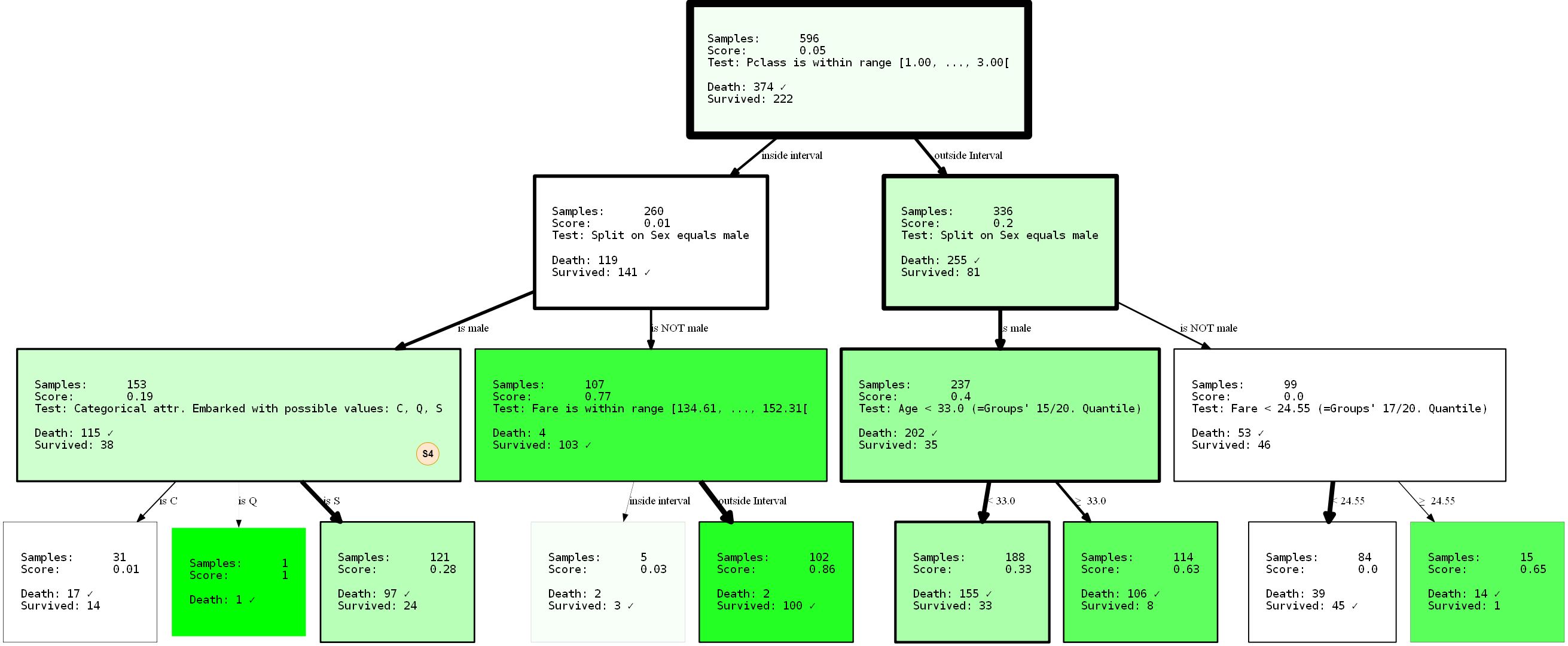
Запрещая разделению по признаку sex появляться в корне благодаря параметру min_level=1 (подсказка: конечно же, вы также можете предоставить max_level), мы полностью реструктурировали дерево. Его производительность сейчас составляет 80,37% и 81,69% (тренировочные/тестовые). Она не менялась вообще, даже если мы взяли предположительно лучшее разделение в корневом узле.
Из-за того, что деревья решений строятся в жадной форме, они найдут только локальное _наилучшее разбиение для каждого узла, что не обязательно является _ лучшим _ вариантом вообще. На самом деле нахождение идеального решения проблемы дерева решений — NP-полная задача, это доказано в [15].Так что лучшее, чего мы можем желать, это эвристики. Вернёмся к примеру: обратите внимание, что мы уже получили нетривиальное представление данных? Хотя это тривиально. сказать, что мужчины будут иметь только низкие шансы на выживание, в меньшей степени может иметь место вывод, что, будучи человеком в первом или втором классе
PClass вылет из Шербура (Embarked=C) Может увеличить ваши шансы на выживание. Или что если вы мужчина из PClass 3 и вам меньше 33 лет, ваши шансы тоже увеличиваются? Помните: прежде всего женщина и дети. Хорошее упражнение — сделать эти выводы самостоятельно, интерпретируя визуализацию. Эти выводы были возможны только благодаря ограничению дерева. Кто знает, что еще можно раскрыть, применив другие ограничения? Попробуйте!
Как последний пример такого рода я хочу показать вам, как ограничить разбиение конкретными атрибутами. Это применимо не только для предотвращения обучения дерева на нежелательных корреляциях или принудительных альтернативных решений, но также сужает пространство поиска. Подход может резко сократить время выполнения, особенно при использовании многовариантного разделения. Если вы вернётесь к предыдущему примеру, то можете обнаружить узел, который проверяет наличие атрибута PassengerId. Возможно, мы не хотим его моделировать, поскольку он, по крайней мере, не должен вносить вклад в информацию о выживании. Проверка на идентификатор пассажира может быть признаком переобучения. Давайте изменим ситуацию с помощью параметра blacklist_attribute_indices.
- SNIP -
...allowed_splits=[TwentyQuantileRangeSplit.build_with_restrictions(blacklist_attribute_indices=['PassengerId']),
FixedValueSplit.build_with_restrictions(blacklist_attribute_indices=['Name Length']),
...],
- SNIP -
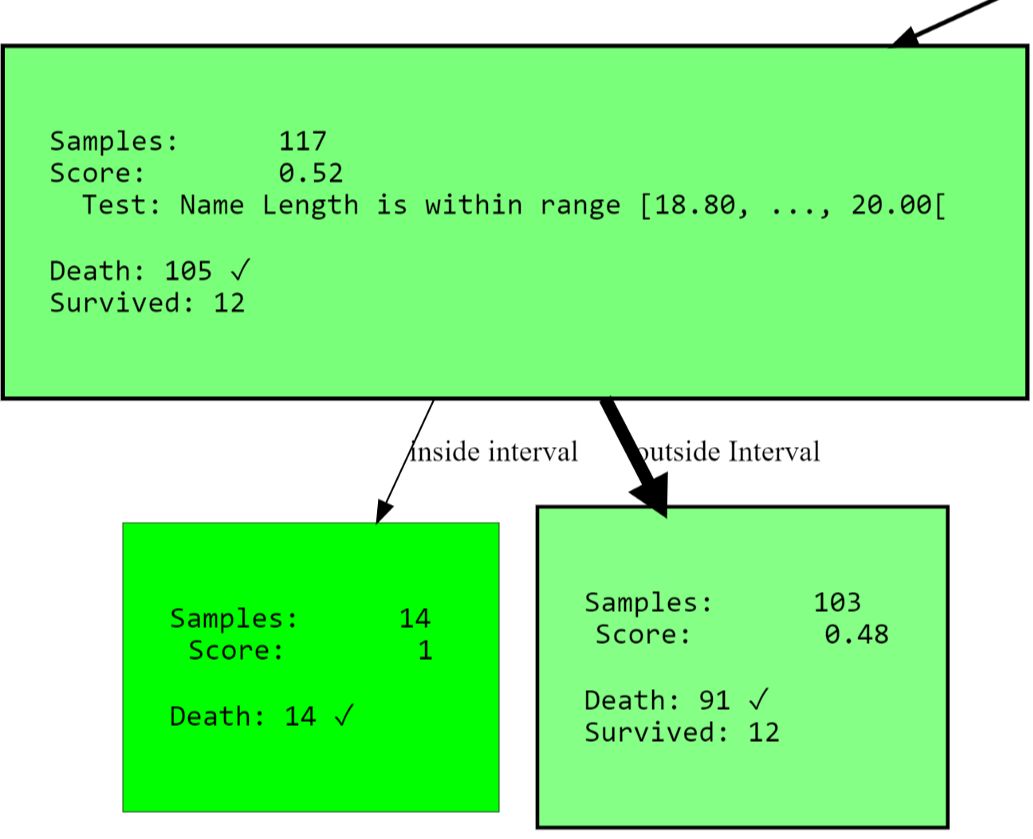
Вы можете спросить, почемуname length вообще появляется. Нужно учитывать, что длинные имена (двойные имена или [благородные] титулы) могут указывать на богатое прошлое, увеличивая ваши шансы на выживание.
Дополнительная подсказка: вы всегда можете добавить то жеSplitRuleдважды. Если вы хотите внести в черный список атрибут только для определенных уровней HDTree, просто добавьтеSplitRuleбез ограничения уровня.
Прогнозирование точек данных
Как вы, возможно, уже заметили, для прогнозирования можно использовать общий интерфейс scikit-learn. Это
predict(), predict_proba(), а также score(). Но можно пойти дальше. Есть explain_decision(), которая выведет текстовое представление решения.
print(hdtree_titanic_3.explain_decision(X_titanic_train[42]))
Предполагается, что это последнее изменение в дереве. Код выведет это:
Query:
Query:
{'PassengerId': 273, 'Pclass': 2, 'Sex': 'female', 'Age': 41.0, 'SibSp': 0, 'Parch': 1, 'Fare': 19.5, 'Cabin': nan, 'Embarked': 'S', 'Name Length': 41}
Predicted sample as "Survived" because of:
Explanation 1:
Step 1: Sex doesn't match value male
Step 2: Pclass doesn't match value 3
Step 3: Fare is OUTSIDE range [134.61, ..., 152.31[(19.50 is below range)
Step 4: Leaf. Vote for {'Survived'}
Это работает даже для отсутствующих данных. Давайте установим индекс атрибута 2 (
Sex) на отсутствующий (None):
passenger_42 = X_titanic_train[42].copy()
passenger_42[2] = None
print(hdtree_titanic_3.explain_decision(passenger_42))
Query:
{'PassengerId': 273, 'Pclass': 2, 'Sex': None, 'Age': 41.0, 'SibSp': 0, 'Parch': 1, 'Fare': 19.5, 'Cabin': nan, 'Embarked': 'S', 'Name Length': 41}
Predicted sample as "Death" because of:
Explanation 1:
Step 1: Sex has no value available
Step 2: Age is OUTSIDE range [28.00, ..., 31.00[(41.00 is above range)
Step 3: Age is OUTSIDE range [18.00, ..., 25.00[(41.00 is above range)
Step 4: Leaf. Vote for {'Death'}
---------------------------------
Explanation 2:
Step 1: Sex has no value available
Step 2: Pclass doesn't match value 3
Step 3: Fare is OUTSIDE range [134.61, ..., 152.31[(19.50 is below range)
Step 4: Leaf. Vote for {'Survived'}
---------------------------------
Это напечатает все пути решения (их больше одного, потому что на некоторых узлах решение не может быть принято!). Конечным результатом будет самый распространенный класс среди всех листьев.
… другие полезные вещи
Вы можете продолжить и получить представление дерева в виде текста:
Level 0, ROOT: Node having 596 samples and 2 children with split rule "Split on Sex equals male" (Split Score:
0.251)
-Level 1, Child #1: Node having 390 samples and 2 children with split rule "Age is within range [28.00, ..., 31.00["
(Split Score: 0.342)
--Level 2, Child #1: Node having 117 samples and 2 children with split rule "Name Length is within range [18.80,
..., 20.00[" (Split Score: 0.543)
---Level 3, Child #1: Node having 14 samples and no children with
- SNIP -
Или получить доступ ко всем чистым узлам (с высоким баллом):
[str(node) for node in hdtree_titanic_3.get_clean_nodes(min_score=0.5)]
['Node having 117 samples and 2 children with split rule "Name Length is within range [18.80, ..., 20.00[" (Split
Score: 0.543)',
'Node having 14 samples and no children with split rule "no split rule" (Node Score: 1)',
'Node having 15 samples and no children with split rule "no split rule" (Node Score: 0.647)',
'Node having 107 samples and 2 children with split rule "Fare is within range [134.61, ..., 152.31[" (Split Score:
0.822)',
'Node having 102 samples and no children with split rule "no split rule" (Node Score: 0.861)']
Расширение HDTree
Самое значимое, что вы, возможно, захотите добавить в систему — это ваше собственное
SplitRule. Правило разделения действительно может делать для разделения все, что хочет… Реализуйте SplitRule через реализацию AbstractSplitRule. Это довольно сложно, поскольку вам придется самостоятельно обрабатывать прием данных, оценку производительности и все такое. По этим причинам в пакете есть миксины, которые вы можете добавить в реализацию в зависимости от типа разделения. Миксины делают большую часть трудной части за вас.
Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя онлайн-курсы SkillFactory:
Eще курсы

Комментариев нет:
Отправить комментарий