
Мы в okmeter.io в какой-то момент поняли, что нам тоже нужен k8s в production, хотя у нас нет даже CI/CD, но есть задача делить общий пул серверов между приложениями и достаточно легко добавлять мощности в кластер. При этом был ряд обстоятельств, которые усложняли внедрение k8s:
- мы очень заботимся об отказоустойчивости (мы не притаскиваем новые технологии в prod, пока не разберемся в них на достаточном уровне);
- у нас есть сервисы со временем ответа меньше 10ms;
- у нас очень мало человеческих ресурсов на эту задачу (узнать 10 новых терминов ОК, 50 — уже нет).
Примечание: Доклад 2018 года и некоторые вещи, issue или что еще могло поменяться.

Меня зовут Николай. Я работаю в Okmeter.io. Мы делаем сервис мониторинга. Я имею немаленький опыт администрирования, даже руководил эксплуатацией. Сейчас моя работа полуадминская, менеджерская и связана с разработками. И это все относится к администрированию.

Зачем я сюда пришел и что я хочу рассказать?
Мне кажется, что мой опыт ценен тем, что мне в данный момент по долгу службы приходится совмещать много ролей одновременно, поэтому бизнес хочет, админ хочет делать и разработчики тоже хотят – это все происходит внутри головы.
Я буду рассказывать про наш опыт внедрения Kubernetes.

Мы будем говорить про нашу серверную часть.
У нас есть Okmeter.io. Он состоит из двух частей:
- Это агент, который ставится на сервера наших клиентов, который собирает метрики, auto discovery.
- И это серверная часть, облачная.
Серверная часть состоит:
- Из нескольких сервисов, их не так много, т. е. они не настолько микро, как должны быть по всем тенденциям. Они написаны на Python или на Go.
- И у нас есть какое-то количество баз данных, систем хранений. Есть Kafka, Cassandra, Elasticsearch, PostgreSQL.
- Все это работает на железе. Мы не используем виртуалки ни свои, ни чужие, потому что нам очень важно latency. Производительность и цена тоже важны.
- И в плане DevOps мы некультурные граждане, у нас нет CI/CD, pipeline. И кто накосячил, тот и отвечает.
- Есть нагрузка. Эта нагрузка большая не потому, что пользователи часто смотрят графики (такой нагрузки не так много), а потому что агенты шлют очень много метрик. И их надо писать, и с ними надо работать. На read работают не только люди, но и триггеры. Они их постоянно читают. Соответственно, нагрузка есть как на запись, так и на чтение.
- И мы растем достаточно активно как в клиентах, так и хостах, и в метриках, которые с них снимаются, поэтому масштабирование для нас – это не то, что будет через 2 года, когда все станет классно, а то, что происходит ежедневно и сейчас.
- И требования по отказоустойчивости.

Начну издалека, зачем все это надо.
Первая версия нашего сервиса была написана на Google App Engine. У нас не было никаких серверов. Но стало быстро понятно, что оно не работает под нагрузкой. И мы решили мигрировать.
Сначала мигрировали в облако, в виртуалку, а потом мигрировали на железо. Увидели, как latency упало на порядок. И на железе мы остались.
Соответственно, у нас было сколько-то серверов. И на всех было всё. На каждом была Cassandra, Elasticsearch, куски Go и Python.

Не хотелось софтово выделять больше памяти, поэтому мы взяли железки с большим количеством памяти и отнесли туда Elasticsearch.
Соответственно, Elasticsearch всю машину целиком догрузить не могли, мы ее догрузили сервисами, которые прожорливые по CPU. В нашем случае на Python.

Дальше у нас начали появляться другие сервисы. У нас стали появляться не только сервисы, когда бэкенд есть на Go и он stateless, и он мало весит, и ему нужно процессора и памяти чуть-чуть, но у нас есть и сервисы, которым нужно много памяти, которые по CPU сильно прожорливые и их нужно где-то размещать.
Соответственно, появился третий тип машин. Где машины были недогружены, на них подселяли сервисы, которые требовали ресурсов тех или иных.

С какими проблемами мы столкнулись?
- Все это было на Ansible и, в принципе, не было никаких проблем, кроме того, что маппинг server -> roles стал неоднозначным и достаточно сложным. Этим было сложно управлять.
- И деплоиться бесшовно, чтобы не единого разрыва не было. Это на Ansible написать сложно, потому что вам нужно вырубать машину на балансере, чтобы вообще было идеально. Я не говорю, что нельзя, я говорю, что это сложно.
- И все, кто пользуется Ansible, знают, что в нем не жило бы ничего, если бы там не было тегов. Самая частая операция – это запустить playbooks с тегом. Соответственно, в этом есть потенциальная проблема для бизнеса, что целиком playbooks не тестируются на production. Они не запускаются никогда, потому что они работают настолько долго, что можно состариться буквально. Человек, изменяя маленький кусочек конфига не будет прогонять всю эту штуку.

Как был устроен процесс, когда нам нужно пристроить еще один сервис, instance, приложение?
- Мы смотрим на inventory. Примерно в голове считаем, что этот сервис столько-то того и столько-то сего потребляет.
- Смотрим факт в мониторинге. И вычисляем, куда бы это пристроить, чтобы меньше всего болело. Иногда приходим к выводу, что нам нужна новая машина. И пристраиваем.

Соответственно, управление ресурсами настолько стало болеть, что мы задумались о том, что пора шагнуть в пропасть.
- И по концепции, по маркетинговой документации Kubernetes стало понятно, что там все это есть. И есть ровно в тех абстракциях, в которых мы хотим.
- Мы хотим, чтобы сервис мог забронировать себе место на машине, т. е. мог сказать, что мне нужно минимум два ядра, два гигабайта, дай мне их, пожалуйста, и никому больше не давай, если я взял.
- И есть лимиты, т. е. Request + Limit – то, что нужно.

Мы не готовы влезать со всеми потрохами в кишки Kubernetes. И мы не готовы жертвовать управляемостью контроля. Т. е. если сейчас у нас есть сервисы и они падают, то мы знаем, что с этим делать. Мы знаем, как задеплоить новую машину, мы знаем, как добавить instances. И мы знаем, что если наше приложение убило OOM killer, то мы знаем, где это посмотреть. Мы не хотим дополнительную абстракцию, за которой мы не будем понимать, что происходит.
У нас отказоустойчивость, как у системы мониторинга, на первом месте, потому что наш мониторинг в трех слоях исполнен. У нас три слоя мониторинга мониторинга.
Когда вы говорите, что у вас есть health checks и ваши сервисы всегда будут работать, то я всегда читаю между строк и вижу кучу неправдоподобной информации. Соответственно, я выписал страхи, которые у меня возникли.

Ansible был простой и понятный. Чем мне понравился Ansible? Тем, что пока вы его не запустили, ничего не происходит. Когда вы его запустили, он как будто руками сделал всю работу за вас и это круто. Ansible, на мой взгляд, получил свою популярность ровно поэтому.
Kubernetes, на первый взгляд, сложный. Он постоянно чем-то управляет. И для человека, который хотел только управлять ресурсами, это кажется over kill.

Если начать себя успокаивать и посмотреть на это с другой стороны, что здесь страшного? Я выделил две вещи:
- Первое — раньше вы знали, где и что будет запущено, теперь маппинг становится динамическим.
- Второе – Ansible по вашему запросу начинал приводить систему в то состояние, в которое вы хотите, а Kubernetes делает это постоянно.

И как привести поведение Kubernetes к тому, что было в Ansible? Вы запускаете Kubernetes apply, он все делает, вы гасите все управляторы, т. е. ваши запущенные докер-контейнеры, снапшоты, состояние систем. Мы подумали, что – это прикольно и ничем не отличается оттого, что было.
А потом вы начинаете думать, зачем я буду это выключать? И в каких случая он без вас будет что-то там делать? Это те случаи, когда нода умерла или вы ее вывели из эксплуатации руками. А также, когда у вас умер непоправимо pod. И в этих ситуациях вы, скорее всего, руками запускали Ansible. По сути, если разобраться, то коренным образом ничего не меняется.

Почему нас пугал динамический маппинг? Потому он притаскивает service discovery. У нас его не было, все было статично. И в конфигах nginx, и в других балансерах были прописаны upstream’ы. Т. е. у нас его не было. И это само по себе изменение. Я хотел распределять ресурсами, а сейчас мне говорят, что у меня будут service discovery. И это странно. На этом этапе я все еще готов идти в сторону Kubernetes.
Сложно эксплуатировать, потому что это отдельная абстракция. Есть некая штука, которая знает, где и что работает. И у нее по каким-то протоколам надо спрашивать, где и что живет. Это либо DNS, либо ETCD. Но по большому счету это дополнительный слой, который нужно поддерживать, а он может сломаться и т. д.

Мы говорим, что хорошо, у нас сервисы, мы даже знаем, сколько их будет. И чтобы не думать и не контролировать работает или не работает, то нам нужно хорошенько запариться над readiness/ liveness-пробами. И надо сделать так, чтобы то, что отдает curl, ваши мнимые проверки на жизнеспособность были закодированы, и Kubernetes именно их использовал.
Как у нас раньше было? Идет список айпишников, pull из десяти бэкендов. Один выключили, трафик пошел на соседей, его обратно включили и все хорошо. Сейчас у вас появляется новый pod, новый IP, новый балансер. И весь pull сменился. И чтобы это переживать в нормальной ситуации без единого разрыва, нужно хорошо запариться над балансировщиками. Это задача, которую вам придется решать, если вы не хотите отказов.
И когда у вас есть кривой случай, когда балансировщик уже начал отдавать запрос клиенту, то в этот момент вы pod останавливаете. И балансер, как бы классно он не был настроен, он сделать ничего не может. Поэтому graceful shutdown должен у вас быть. И вы над этим паритесь. Мы над этим уже парились, поэтому не так страшно было.
Контроль и управляемость. Вам нужны логи, вам RequestID, вам нужен tracing, потому что у вас сервисы друг к другу ходят, все на не понятно каких айпишниках, которые нигде не фиксируются. И задним числом понять, что это был за pod и где он работал – это сложно, надо соломки подстелить.

Третий самый жесткий страх – это сеть. Внедряем Kubernetes, чтобы распределять ресурсы, а мне говорят, что вместо твоей классной L2 сети, у тебя теперь будет нечто такое, о чем ты вообще не имеешь представления.

И когда ты лезешь в доку, и говоришь, как будет организована моя сеть? Тебе говорят, что есть 20 плагинов, бери любой. Что такое любой? И начинается. Один работает по bgp. Я знаю, что такое bgp. Но какой еще bgp в сети из 10 компьютеров?
А потом дока Kubernetes говорят, что будет service discovery и мы тебе iptables настроим, т. е. у нас есть daemon, который следит за всеми изменениями и настроит тебе iptables. И я сразу стал представлять, как я буду это дебажить. И мне стало грустно, и на полушаге был оттого, чтобы развернуться и сказать, что нет, я слишком стар для этого.

В итоге начинается самоуспокоение. Давайте откинем из 20 плагинов все, кто предлагает инкапсулировать наш трафик. И если с iptables еще могу смириться, то с инкапсуляциями не хочу работать.
И я знал, что есть такая штука, когда вы можете на аппаратной виртуализации построить плоскую сесть. У вас будет у хоста IP и у pod’а будет IP из этой же сети. Это очень круто, это делается на современном железе влет. Это называется SR-IOV. Это виртуализация, когда у вас один сетевой адаптер умеет распочковаться на 128 виртуальных функций. И там стоит мини switch в адаптере. И он позволяет сделать плоскую сеть. Я подумал, что это то, что надо.
Я протестировал, это работает. У вас реально плоская сеть. Это все работает, но у нас в одном дата-центре, в котором мы размещаемся, это было, а во втором нет. Поэтому начали искать что-то более молодежное. Остановились на flannel host-gw. Это когда у вас на каждой ноде выделяется своя 24-ая сеть и статические маршруты. Понятно, что статические маршруты не из воздуха берутся, а там дискаверятся как-то. Но я решил, что надо остановить свой поток паранойи и смириться с этим.

Когда я увидел iptables kube-proxy, то я стал искать вариант, как выключить iptables при работе Kubernetes. В Google написано, что нельзя. Ерунда полная. Нашлись headless services и это стало спасением.

Что нужно физически сделать?
- Подготовить приложения, чтобы их можно было запаковать в сущность K8s и задеплоить.
- Отработать процесс, как мы будем инициировать раскатку, у нас нет CI/CD.
- Протестировать отказы. Т. е. что будет, когда этот процесс на этом сервисе умрет? Это нужно протестировать, чтобы иметь контроль и не потерять его.
- Протестировать и развернуть кластер для production именно с отказоустойчивостью.

Расскажу, как это было у нас:
- Все наши приложения нужно было подготовить к тому, что они будет работать в K8s. В docker мы их уже завернули, потому что это удобно, особенно в Python. В Go – не особо важно. Оно как и процессом запускалось без пакетирования, так и в docker было завернуть не проблемой. Поэтому для единообразия решили все завернуть.
- Конфиги в нашем деплое с docker монтировались с хоста. Ansible клал на хост конфиг и говорил docker: «Ты либо его стартуй, либо рестартанись, если конфиг изменился».
- И нам не нужно не только деплоить, но еще и реконфигурировать. Это достаточно частой была процедура.

Я читаю документацию. Хорошо, я кладу конфиги куда-то в etcd, называю это ConfigMap, а потом монтирую в контейнер. И думаю, что это классно. А потом мне говорят, что нельзя сделать reconfig. Ты поменял конфиг, а приложению никто об этом не скажет.
И только Helm сможет нам помочь. Но я подумал, что к этому я не готов.

Но выясняется, что дело не в Helm. Для того чтобы обеспечить атомарность update/ rollback каждого pod’а, нужен immutable ConfigMap, потому что на него ссылается ваше приложение. И если вы поменяли, и вдруг знание о том, что оно поменялось, распространилось, то это значит, что у вас произошел не rolling update, а одномоментный, атомарный. И это проблема, потому что это не контролируется. Вы не знаете хороший ли это конфиг или плохой. В тесте он был хорошим, а в production другие условия, и он может быть плохим. И вам нужен идемпотентный ConfigMap, и нужно раскатывать новую версию с новой версией ConfigMag.

Сейчас, насколько я понимаю, единственный способ сделать правильно – это переменные окружения.
Переменные окружения – это то, что написано в спецификации прямо в спеке. Это приложение запускается с таким-то снапшотом конфига. И тот pod, который порожден, он действительно immutable. И мы решили, что это нормально. И тем более, что можно не брать Helm.

Мы сделали простейшие изменения. Go-сервис читал файл, разбирал YAML и получал структуру конфига кастомную. Мы не стали описывать, что есть такая-то переменная окружения, есть такая-то. Мы в одну переменную запихнули YAML, и никому больно от этого не стало. Изменения – это одна строчка в коде.

Python в случае с Django делается примерно также. Settings.py – это интерпретируемый кусок кода. Вы там читаете переменную и все остальные settings оттуда набиваете. Это заняло полдня на все сервисы.

Но конфиги надо шаблонизировать, потому что, как минимум, у нас в K8s не было планов сейчас втаскивать stateful наши сервисы. Им нужно объяснить, что вот твои: Cassandra, Kafka. А у нас есть два дата-центра, в которых это один набор, это другой набор.
Понятно, что шаблонизировать надо, но был Ansible. Ansible мы выкинуть не можем, потому что банально кто-но на железке K8s ставить должен. Поэтому почему бы им не шаблонизировать спеки?

И деплой в Kubernetes – это запуск Ansible playbook. И здесь нет изменений в процессе. И это классно. И как раньше мы запускали playbook, и все деплоилось, так и сейчас, только под капотом там сейчас встал K8s.
И в production стало чуть-чуть по-другому управляться.
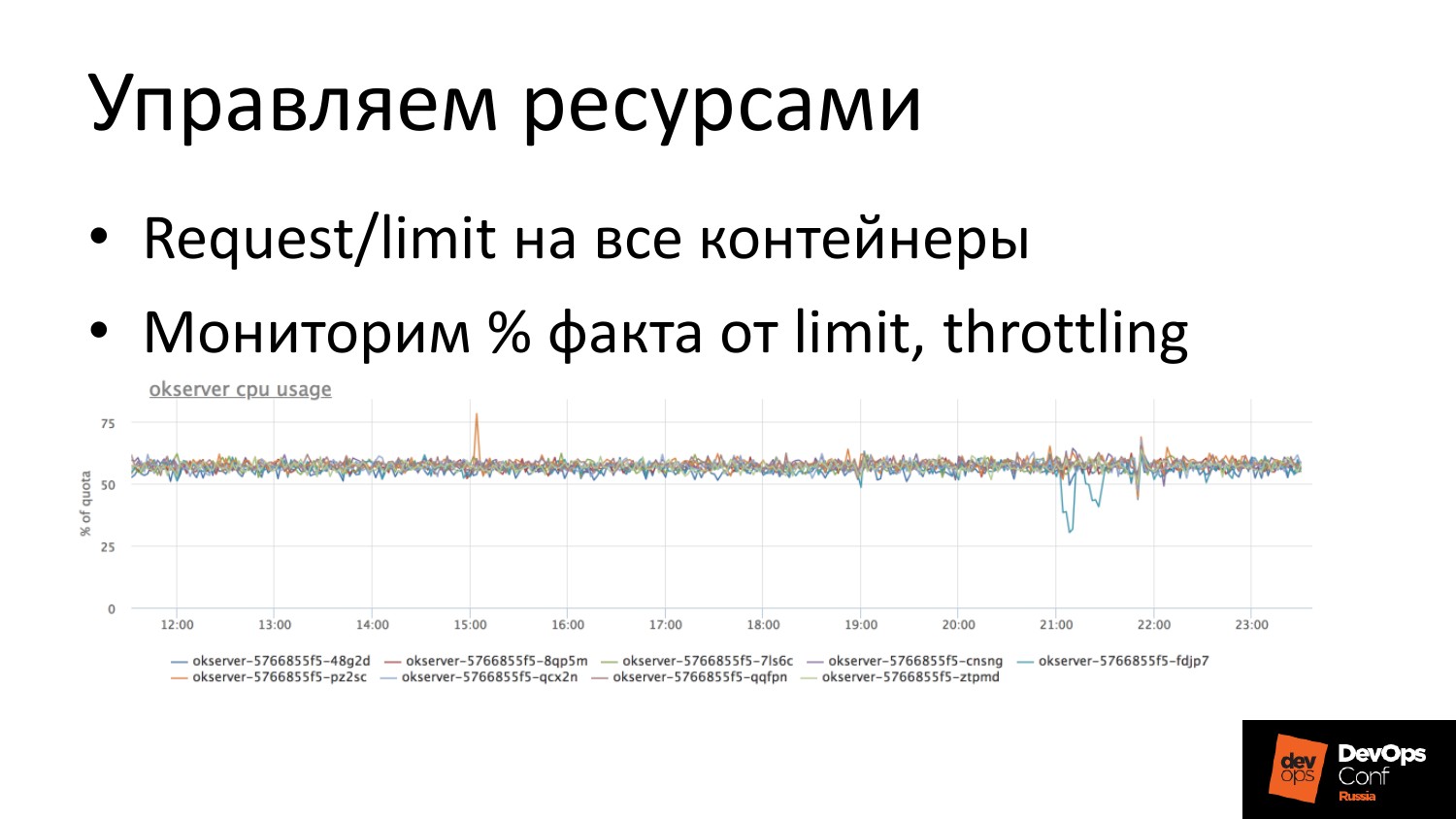
Управление ресурсами мы используем на полную катушку. Мы используем request/ limit.
В облаке надо мониторить, мы мониторим сами себя и всех своих клиентов, естественно. Мы смотрим использование CPU как процент от лимита. И это классно. Мы видим, что эти pod’ы подбираются. И мониторим, что кто-то там начал троттлиться, если говорить про CPU.
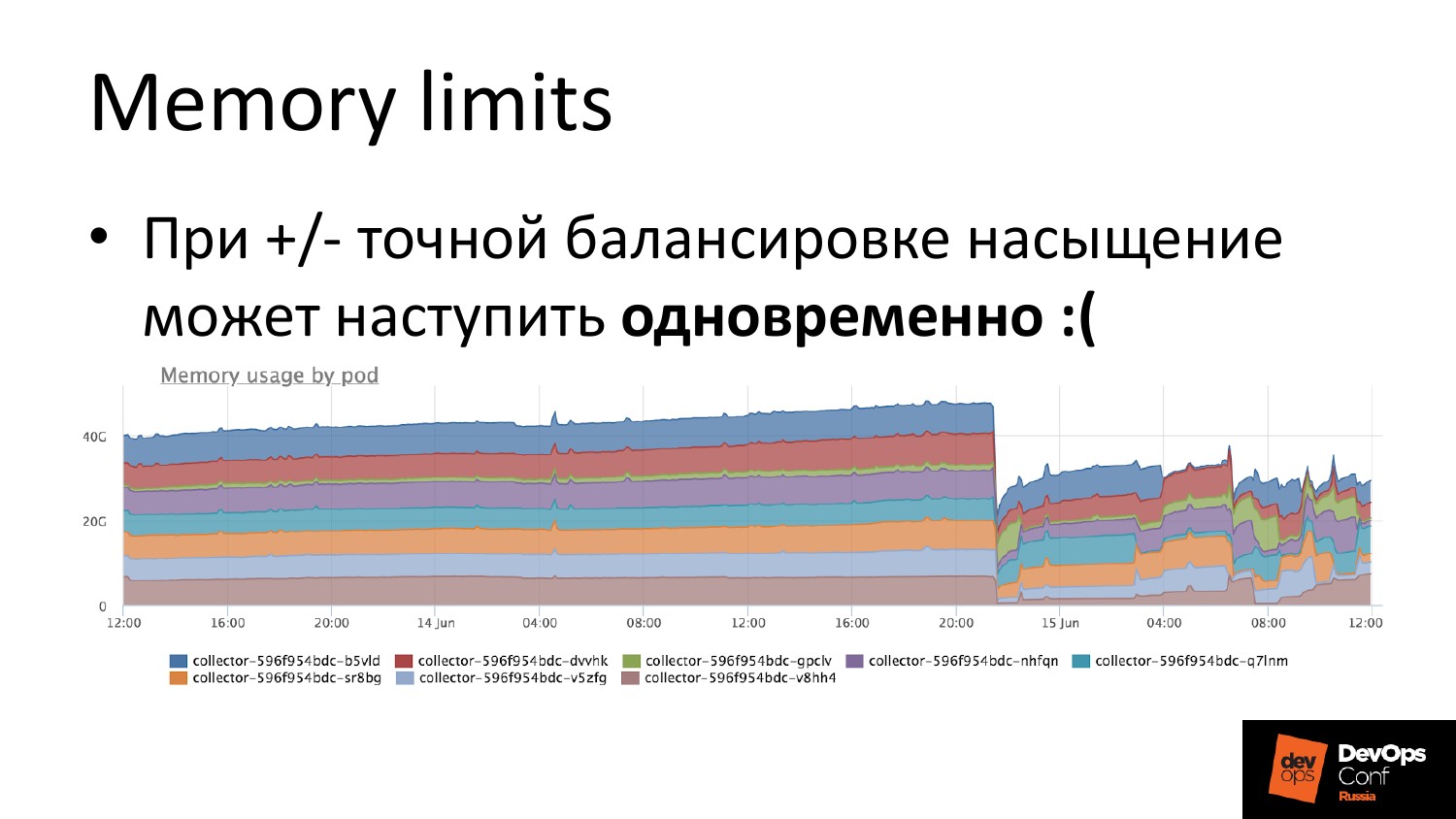
Если говорить про память, то с памятью все просто. Вы ее залимитили, но надо понимать, что если у вас балансировка более-менее нормальная, то OOM Killer придет ко всем сразу. И это проблема, потому что сервис может стартовать не за 100 миллисекунд, а за несколько секунд.

И для этого очередной костыль – это делать несколько deployments одного и того же с чуть-чуть измененным лимитом. И когда вы делается сервис для того, чтобы закетчить это все, вы пишите selector настолько широкий, чтобы он поймал pod обоих deployments. И OOM Killer никуда не денется, он обязательно придет. Но он придет с дельтой во времени. И первый deployment уже отрестартится, и все будет хорошо. Это то, с чем мы столкнулись.

У нас приложение взрывалось по памяти из-за какого-то внешнего запроса. Оно стартовало, приходил запрос – оно падало. Частый рестарт в K8s есть back-off. Это когда следующий рестарт происходит с задержкой. Она ограничена по дефолту пяти минутами.

Мы это все исправили, мы перекрыли вход таких запросов, оно перестало падать, но они были все в состоянии типа …, потому что back-off не истек.
Соответственно, мы руками спровоцировали rollout, чтобы не ждать. Это тоже такая неочевидная штука. Мы достаточно долго понимали, что происходит. Они все висели в ожидании того, когда следующая попытка будет, а мы уже все исправили. Т. е. система была не отзывчива к восстановлению. Соответственно, спровоцировали это все руками.

Проблема, о которой я говорил, с сервисами, с iptables и headless. Что это такое в двух словах? У нас есть selector, который выбирает pod’ы, на которых будем балансировать. У каждого pod’а есть readiness probe, когда он готов отвечать. Из всего этого получается endpoint, куда мы можем слать живые, т. е. endpoint – это список живых pod’ов.
Виртуальный IP сервис. Выделяется IP, по которому из любой точки в кластер вы обращаетесь и попадаете на живой pod.
Реализовано это проксированием этого виртуально IP. Он нигде не поднят, нигде не существует. Но когда вы туда идете, iptables или другой метод проксирования, перехватывает и отправляет его на один из upstream, который он знает.
И каждому сервису выделяется DNS-имя.
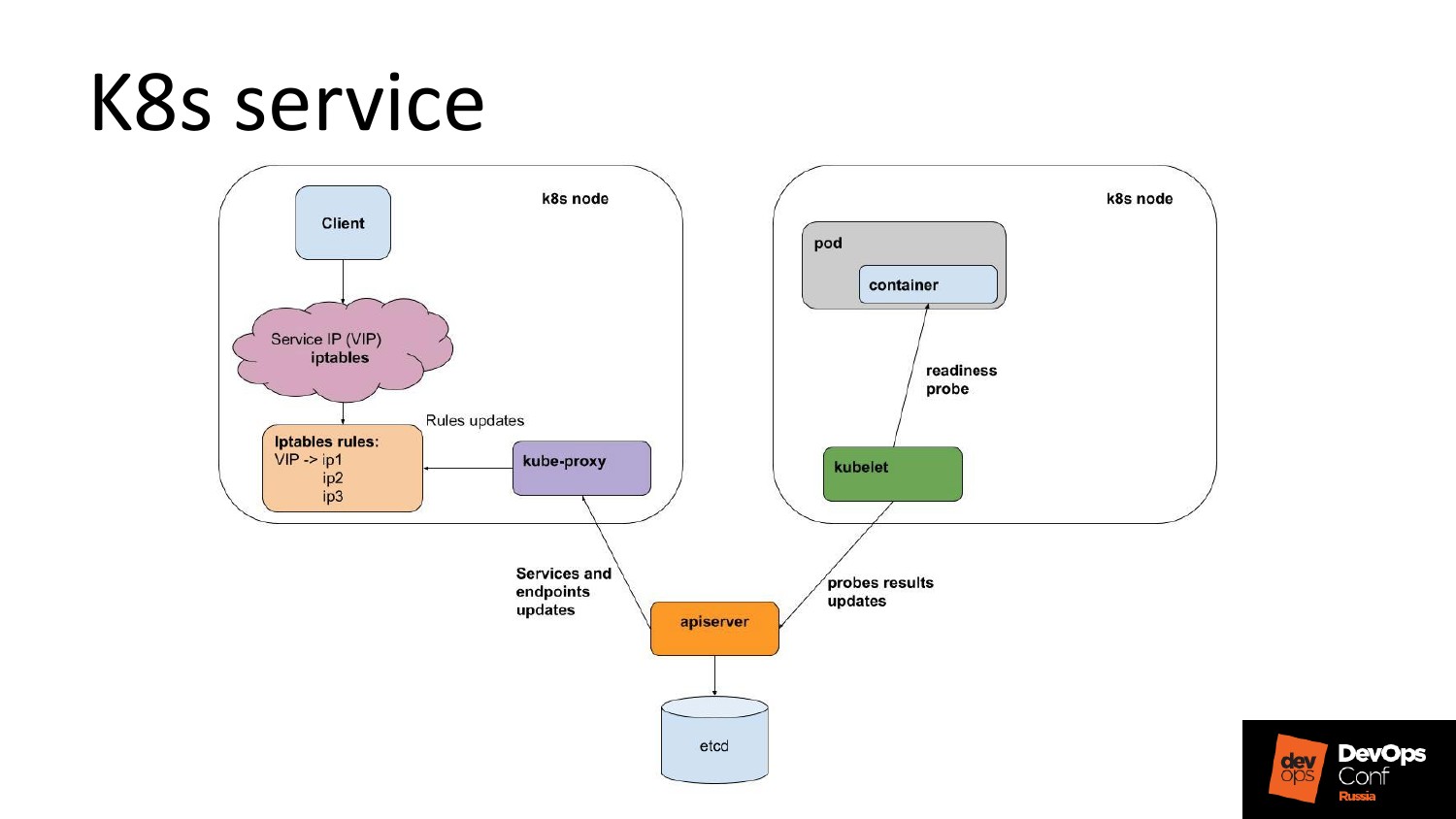
В чем тут история? У вас есть нода, на которой работает pod. Его readiness probe осуществляет kubelet на этой же ноде. Его проверяют локально. И когда его состояние изменяется, информация об этом kubelet’ом доносится в apiserver.
Далее попадает в kube-proxy на каждой ноде. И kube-proxy перестраивает набор правил проксирования. И у вас меняется топология для того, кто клиент.

Какие в этом есть проблемы?
- Probes не является никакой гарантией. Если у вас сервис ответил на пробу, не факт, что он живой.
- Это интервал раз в секунду. Между секундой 10 000 rps, посчитайте, сколько запросов проходит.
- Задержка обновления статуса. Kubelet -> apiserver -> kube-proxy-> iptables. И все это, если еще работает.
- Что будет, если kubelet не сможет запостить проб в apiserver? Выкинет ли его kube-proxy его из iptables? Я не стал исследовать это, чтобы себя не расстраивать.
- И если вдруг получилось так, что вы в iptables попали на дохлый pod, то у вас нет шансов. Вы, как клиент, никогда не получите успешный ответ. Нет retries.

Соответственно, headless service – это тоже самое, только без всякой ереси.
У вас есть живые сервисы. И вы их список можете получить либо по etcd, либо через apiserver, либо через DNS.

В нашем случае мы используем envoy, потому что нам нужен L7, чтобы делать retry. Если у нас http, то retry может сделать только тот, кто видит статус запроса. Соответственно, чтобы видеть статус запроса, он должен понимать application level протокол. Если он его понимает, то какой самый классный балансировщик? Envoy.

Мы его не внедряли никуда. Мы просто взяли envoy. Он умеет DNS. У K8s есть DNS, который отдает все endpoints. Все классно, все срастается. Он устраивает нас по фичам, берем.
Мы envoy запускаем не как DeamonSet, а используем, как sidecar container. Почему? Из-за гранулярности изменений.
Если envoy, вы меняете что-то, начинаете деплоить, если вы его измените на машине, то поведение всех pod’ов на этой машине изменится. Это не круто. Нужна более маленькая гранулярность. Мы хотим запустить rolling-update. Что-то упало, например, один pod у нас валяется и ничего страшного.

И гранулярность отказов. Т. е. у envoy нет встроенного nginx -t. Он не может сам прочитать свой конфиг и сказать устраивает он его или нет. Если вы будете это деплоить, он скажет: «Извините, конфиг у тебя не особо». И упадает. Соответственно, все pod’ы на ноде упадут.
И мы решили, что sidecar классно ложится на концепцию и управляемость. Плюс мы не такой гигантский конфиг envoy имеем, а кучу маленьких.

Это примерно выглядит вот так. Это пример конфиг envoy. Мы говорим хосту, что ты будешь resolve имя сервиса, который мы создали, вот тебе 3 DNS. Пока у нас клиент посылает запрос, envoy в этот момент ничего не resolve. И это классно. Т. е. он делает в фоне постоянно, плюс у него свои health check, плюс у него retry.

Все говорят, что нам service mesh нужен. Нам не нужен service mesh, потому что это сложно. Потому что у нас маленькая команда. И нам не будет от этого пользы, мы поимеем еще один сложный слой.
Если вы хотите втащить какой-то компонент к себе, то сходите на GitHub и посмотрите, какое количество кода в нем есть. Меня ужасает количество строчек кода в envoy. Но я к нему теплое чувство испытываю, а к istio я не испытываю никаких чувств, но там тоже много строчек кода. И я не хочу про это все знать.

Мы тоже не используем ingress-контроллеры. У нас есть внешние машины с внешними IP, они не в K8s-кластере. Там нельзя сказать K8s, чтобы он не использовал внешний интерфейс, а мне это не нравится.
На каждой ноде есть DaemonSet с envoy, который как входная точка используется. DaemonSet – это классная точка опоры. Вы знаете IP нод, и если там стоит DaemonSet, то вы можете на IP ноды прописать куда-то сверху. И вам не нужно дискаверить. Вы прописали 3 мастер-ноды или 4, 5, 10 в upstream и все.
Отказы DaemonSet и его rolling обрабатывает внешний балансировщик.

Не ingress controller, потому что я не хочу знать и отдельно ботать, как мне в nginx пропихнуть такой тайм-аут сквозь писание сущности ingress в K8s. В пределе я понимаю, что эта задача решается кастомизацией контроллера. И в пределе у меня будет свой контроллер. И, более того, той envoy, который в DaemonSet, на самом деле ingress controller. Но я не хочу пока это адаптировать. Меня устраивает DaemonSet, я не парюсь. Я не делаю себе отдельную абстракцию в виде ingress.

Есть инструкция, которая позволяет вам его сделать. Там есть миллион неточностей.
Kubespray – это такая штука, которую запускаешь, приходишь через 20 минут и там у тебя есть K8s-кластер.
Но у нас есть образовательная задача, нам нужно понять, как это будет работать, чтобы понять, как это упадает. А чтобы понять, как это упадет, нужно развернуть ее целиком.
Свой playbook пишется за день.
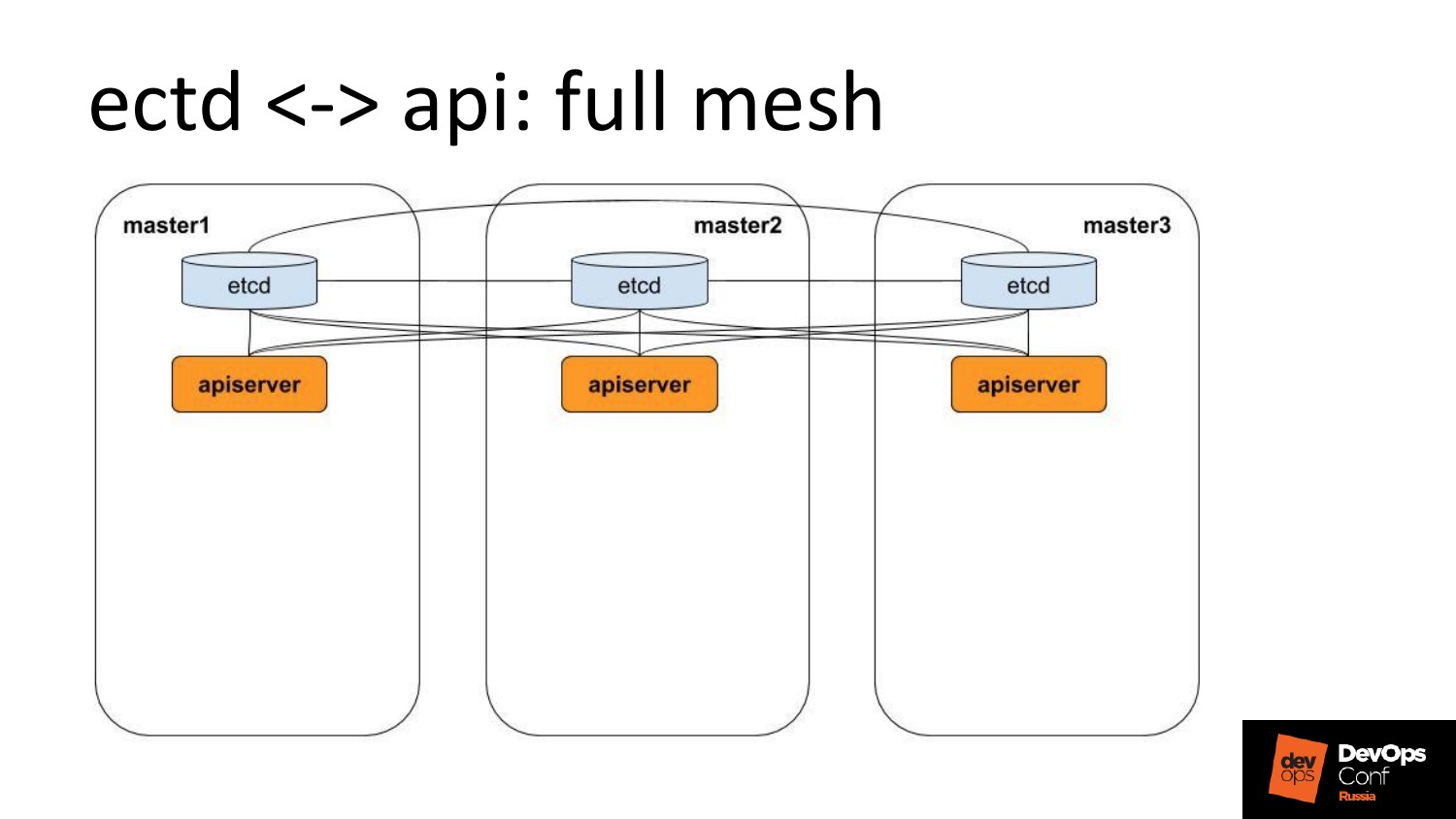
Какие проблемы я там встретил?
Есть etcd c apiserver’ами. Их много. Но у них full mesh.
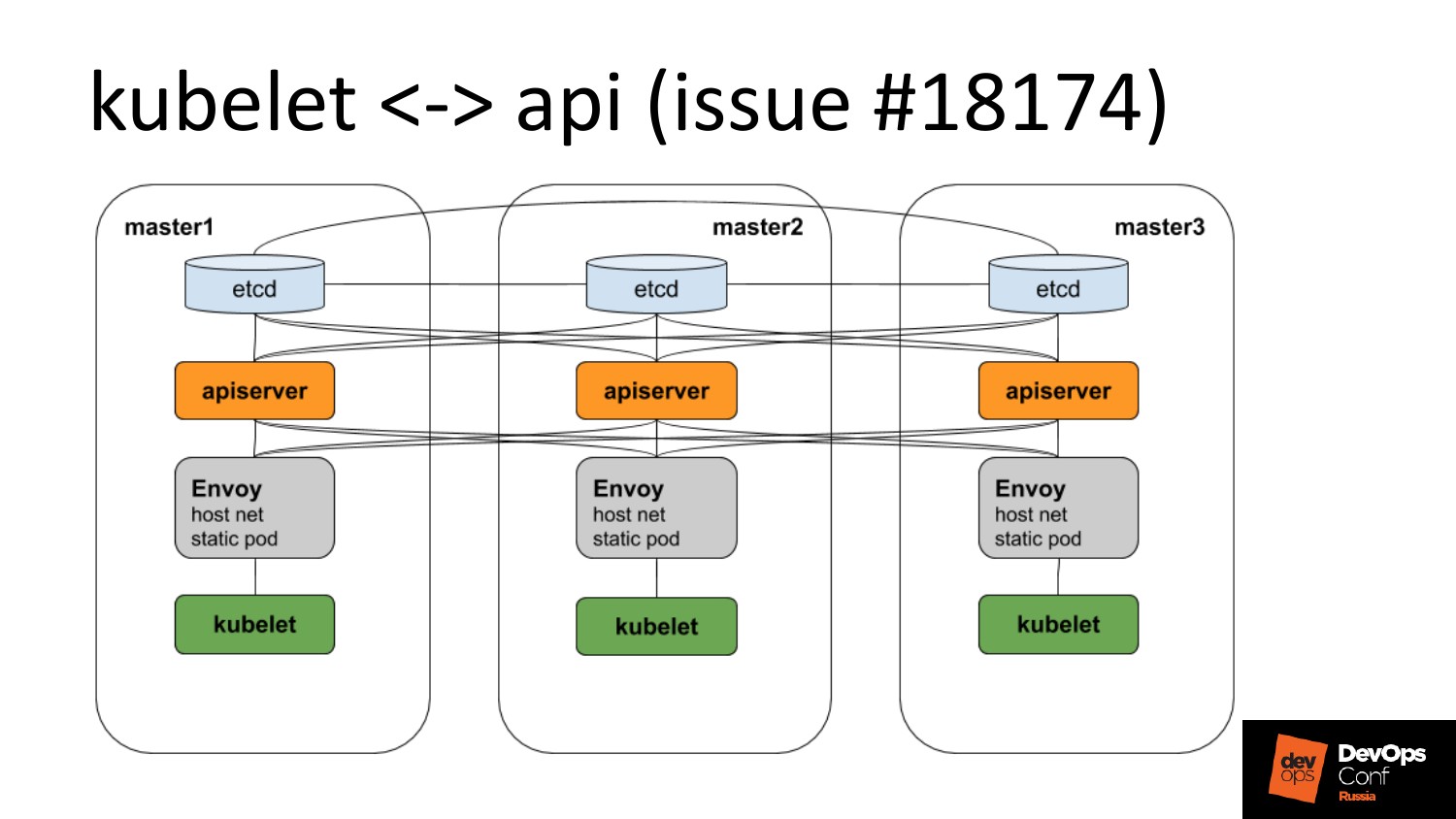
Но есть тикет, что Kubelet не умеет ходить в …, поэтому перед ним нужно поставить балансировщик. Это дичь, это просто мы костыль подставили, т. е. статический pod на каждую ноду, который знает айпишники мастеров и умеет туда разбалансить. Но тикет этот починят, и этот слой уберется.

Мы используем CoreDNS. Он поставляется в deployment. Но когда у меня есть deployment, то они вынуждают меня использовать iptables, а я не хочу.
И поэтому чтобы не использовать iptables, мы берем и конвертируем DNS из deployment в DaemonSet. Таким образом, у нас получает три точки опоры, это айпишники наших мастеров. Когда нам нужно гарантированно удачно ходить в DNS мы ходим по этим айпишникам, и кто-то, да ответит.

У нас 3 мастера + N не мастеров. На мастерах работает живая нагрузка, потому что у нас не виртуалки, у нас жирные машины и их лень резать. Я считаю, что это как Ansible. Ему не нужны ресурсы, он там сам управляет.
Так как мы Stateful-сервисы не вешаем, мы их вешаем на эти же машины, но снаружи. Мы их залимитчиваем по ресурсу.
Это пример, когда для Kafka отрезали 4 ядра и 10 гигабайтов. И Kubelet сказали, что у него нет этих ресурсов. Таким образом, никакого overbooked на машине не происходит.
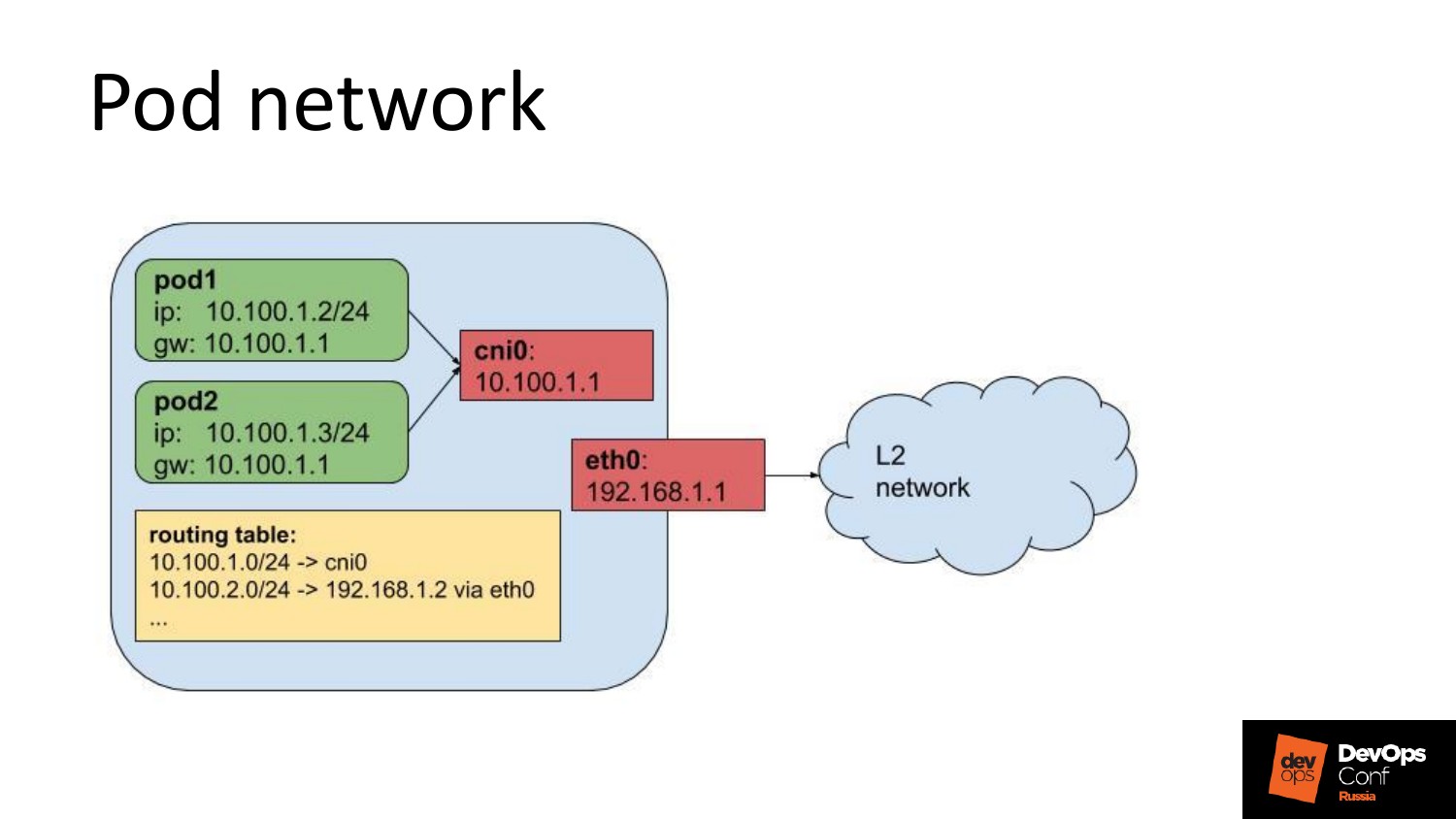
Я нарисовал это, чтобы показать, как flannel работает. У вас pod’ы. На машине выделяется сетка. На этой машине сетка 1/0. У pod’ов выделяются айпишники из этой сети. Статический маршрут до соседей. Т. е. на все эти вторые машины иди через эту. Все просто, паранойю успокаивает.
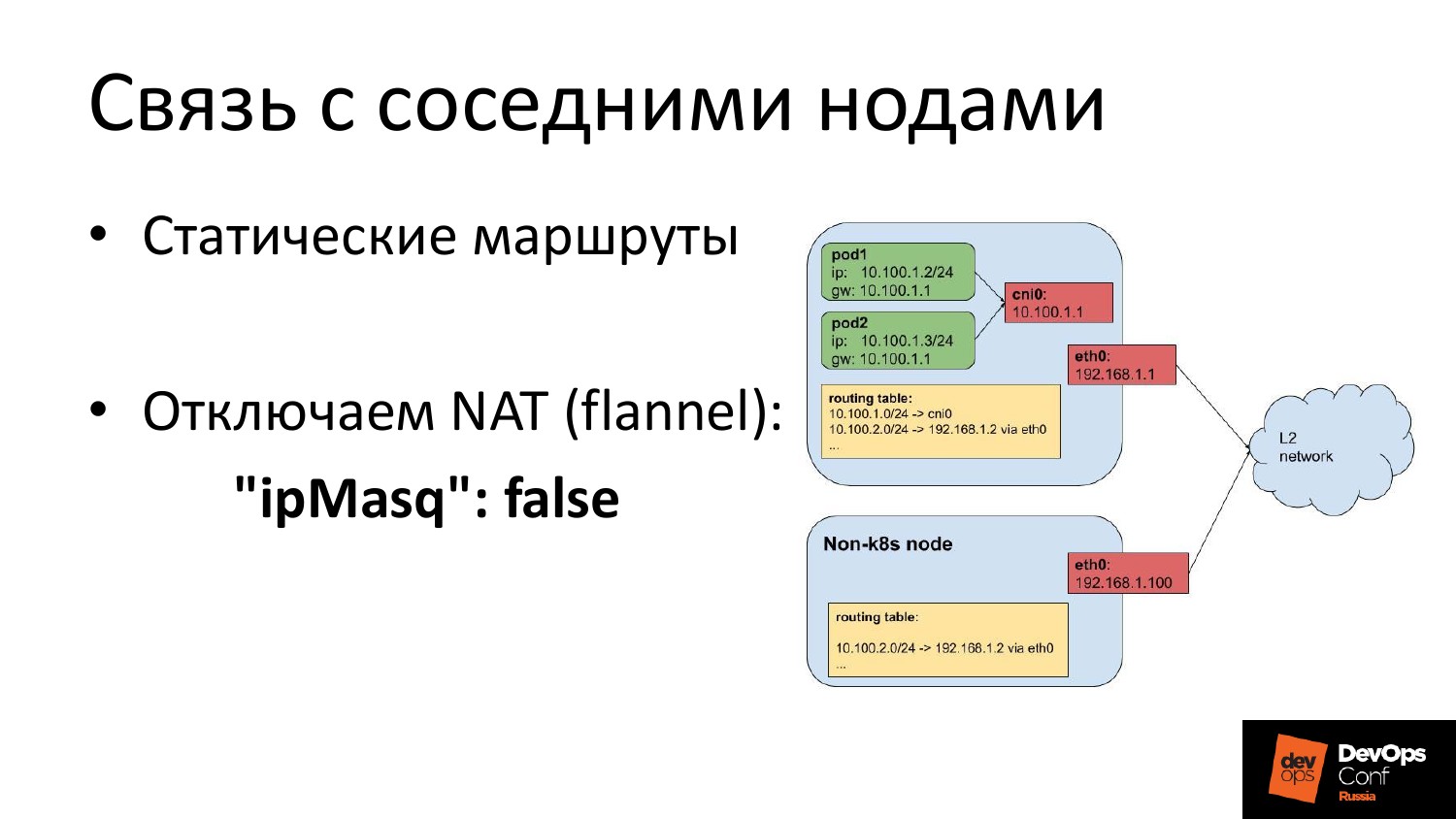
Стальные машины, которые там были, они начинают быть за кластером. И у вас получается, что работает, так называемый, egress, когда вы выходите из машины, из кластера. В flannel надо отключить NAT. Мы на эти машины руками добавили статический маршрут до всех сетей pod’ов всех машин.
И когда мы переключаемся, нам нужно соединить две машины. Мы не хотим там NAT.

- Это все было сделано за месяц. Нам пришлось выкинуть все лишнее и не забивать себе голову.
- Упрощали везде, где можно. Нам приходилось думать немножко, но потом в эксплуатации все компенсируется.
- Какое-то количество граблей с сервисом и т. д. обошли, просто внимательно посмотрев на дизайн, как оно работает. Я призываю всех, если вы что-то втаскиваете, смотрите на дизайн. Когда вы видите в дизайне 3 движущиеся части, то вы понимаете, что одна умрет, все разрушится, то вы начинаете из этого искать обходной путь.
- И я не претендую на то, что это эталонное внедрение Kubernetes, меня оно устраивает с точки зрения того, что я это все контролирую. Я все понимаю, я знаю, как это масштабировать.
Картинка отображает что я думал о Kubernetes месяц назад.

На самом деле Kubernetes сложнее.
Надеюсь, было полезно. Спасибо!
Вопросы:
Николай, спасибо за доклад! Начиналось все с управления ресурсов и follower, потом была борьба с ветряными мельницами, где вы, чтобы получить достаточно простой функционал, боретесь с Kubernetes, а смотрели ли вы какие-то другие средства управления? Или была задача именно Kubernetes запилить напильником?
Помимо здравого смысла, есть чуйка, что Kubernetes будет жить. Это факт уже, мы не можем с ним спорить. У нас помимо этого есть шкурный интерес, нам его мониторить надо было научиться. Мы научились. А не поставив себе, не научишься.
Если разобраться философски, почему так происходит, когда ты хочешь одного, а тебе приносят другое, то оно следует из того, что вы хотите управлять ресурсами, вы не ходите думать, куда впихнуть эту штуку, поэтому эта штука теоретически может уехать на любую из машин. Оп, и вы получили service discovery тут же. И у нас этого просто не было, мы старались перешагивать через ненужное, а с нужным мириться, поэтому что понятно, почему оно появилось.
Привет! У вас была куча Stateful-сервисов и ты говоришь, что вынесли их за кластер. А как вы их мониторите и как обеспечили HA для точки входа? Размещали HAProxy внутри K8s?
В Cassandra отказоустойчивость на уровне клиента. Он понимает, что вот эта нода хорошая, а это плохая. Он знает их все. У него в endpoints не один IP балансера, а несколько.
А Postgres?
Postgres так не может. С Postgres’ом особая история, т. е. есть мастер, есть реплика. Приложение знает, где мастер, где реплики. У нас в Postgres вот столько-то данных. И он используется там, где мы еще не придумали, как этот набор данных натянуть что-то, что отказоустойчиво. По большому счету Postgres падает, у нас все работает.
Николай, добрый день! Спасибо за доклад! Хотел спросить про latency. Вы вначале говорили, что виртуалки не использовали, потому что latency не нравилось. А здесь, как стало?
Выходит пакет. Проходит статический маршрут. И все. А в iptables он не идет, поэтому все хорошо. А если был бы iptables, то было бы все плохо. И так как мы ему проложили дорожку, где его на КПП не остановят, то все хорошо.
Вы говорили про 20 плагинов. Что-то стоящее там есть?
Мы flannel взяли.
А, допустим, если мы хотим Open vSwitch внутри полный сделать?
Я как раз боюсь этих слов. Мы сделали мониторинг K8s запилили, нам нужно было сделать тестовый стенд на виртуалках для того, чтобы демо мониторинга сделать. Там по дефолту Kubespray развернул Calico. Оно работает, но я не понимаю, как оно работает. Мы не гоняли там никакие benchmarks, как оно работает, я не знаю. И как сломается, я не знаю. Я знаю, как flannel сломается, я к этому готов. А как сломаются все остальные 19 плагинов, я не знаю.
Этот вопрос интересен в плане защиты данных, чтобы разделять защищенную сеть, незащищенную.
Мы в этом плане блаженны, у нас ничего такого нет.
Вам очень везет.
Все, спасибо!
Комментариев нет:
Отправить комментарий