
Сложный был год: налоги, катастрофы, бандитизм и стремительное исчезновение малых языков. С последним мириться было нельзя...
На территории России проживает большое количество народов, говорящих более чем на 270 языках. Около 150 языков насчитывает менее 1 тысячи носителей, а за последние 20 лет 7 языков уже исчезло.
Этот проект — мои "пять копеек" по поддержке языкового разнообразия. Его цель — помощь исследователям в области машинного перевода, лингвистам, а также энтузиастам, радеющим за свой родной язык. Помогать будем добыванием параллельных корпусов, — своеобразного "топлива", при помощи которого современные модели все успешнее пытаются понять человеческий язык.
Сегодняшние языки — башкирский и чувашский, с популяризаторами которых я в последнее время тесно общался. Сначала я покажу как в принципе извлечь корпус из двух текстов на разных языках. Затем мы столкнемся с тем, что на рассматриваемых языках предобученная модель не тренировалась и попробуем ее дообучить.
Экспериментировать мы будем в среде Colab'а, чтобы любой исследователь при желании смог повторить этот подход для своего языка.
I. Извлекаем параллельный корпус
Для выравнивания двух текстов я написал на python'е библиотеку lingtrain_aligner. Код у нее открыт. Она использует ряд предобученных моделей, можно подключать и свои. Одной из самых удачных мультиязыковых моделей сейчас является LaBSE. Она обучалась на 109 языках. Так как соотношение текстов смещено в сторону популярных языков, то для них качество эмбеддингов (эмбеддингом называют вектор чисел применительно к данным, которые он описывает) будет лучше.
Colab
Попробовать извлечь корпус на нужном языке можно в этом Colab'e. Дальше пройдемся по шагам более подробно.
Установка
Установим библиотеку командой
pip install lingtrain_alignerПосле этого импортируем необходимые модули:
from lingtrain_aligner import splitter, aligner, resolver, metricsНаши тексты (возьмем для примера главу из Гарри Поттера) разобьем на предложения при помощи модуля splitter. Затем создадим файл с данными для выравнивания (sqlite база данных) и загрузим в нее полученные предложения. За это отвечает модуль aligner.
lang_from = "en"
lang_to = "ru"
db_path = "alignment.db"
splitted_from = splitter.split_by_sentences(text1.split('\n'), lang_from)
splitted_to = splitter.split_by_sentences(text2.split('\n'), lang_to)
aligner.fill_db(db_path, lang_from, lang_to, splitted_from, splitted_to)Для учета особенностей грамматики языка (например, особые виды кавычек, отсутствие пробелов и другая лингвистическая экзотика) нужно передать в splitter соответствующие параметры. Выровняем тексты при помощи следующей команды:
aligner.align_db(db_path,
model_name="sentence_transformer_multilingual_labse",
batch_size=200,
window=50,
batch_ids=[],
save_pic=False,
embed_batch_size=5,
normalize_embeddings=True,
show_progress_bar=True,
shift=0)После первичного выравнивания для каждого предложения на английском будет найдено лучшее соответствие на русском. Для поддержки длинных текстов выравнивание идет батчами (отрезками). Между батчами есть нахлест (параметр window). Поток второго текста можно двигать относительно первого (параметр shift). Более подробно о механизме выравнивания можно почитать здесь.
Визуализация
Посмотрим на результат помощи модуля vis_helper:
from lingtrain_aligner import vis_helper
vis_helper.visualize_alignment_by_db(db_path,
output_path="alignment_vis.png",
batch_size=500,
size=(900,900),
lang_name_from=lang_from,
lang_name_to=lang_to,
batch_ids=[],
plt_show=True,
show_info=False)
print("score:", metrics.chain_score(db_path))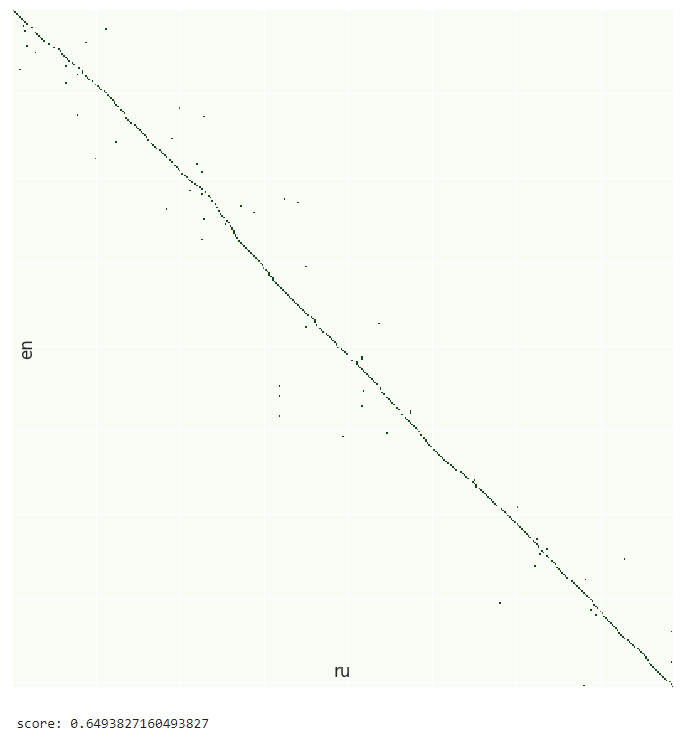
Метрика
Для оценки выравнивания я придумал метрику, логика которой находится в модуле metrics. Она оценивает насколько связанной получилась цепочка выравнивнивания. Цепочка без разрывов должна иметь score = 1, случайный набор точек будет иметь score = 0.
Разрешение конфликтов
Количество предложений в текстах сильно различается. Это связано как со стилем конкретного переводчика, так и с особенностями конкретного языка (например, есть тенденция перевода сложных русских предложений несколькими на китайском). Чтобы это побороть, нам нужно в определенных местах склеить предложения либо первого текста, либо второго. Этим занимается модуль resolver. Он в несколько проходов разрешает найденные конфликты. Самые большие конфликты должны быть разрешены вручную, для этого есть UI, о нем ниже. В нашем же случае качество первичного выравнивания говорит о том, что все должно быть хорошо. Убедимся в этом, поставив все выпавшие строки на место.
steps = 3
for i in range(steps):
conflicts, rest = resolver.get_all_conflicts(db_path,
min_chain_length=2+i,
max_conflicts_len=6*(i+1),
batch_id=-1)
resolver.resolve_all_conflicts(db_path, conflicts, model_name, show_logs=False)
if len(rest) == 0:
breakПосмотрим на визуализацию:

Результат
Картинка красивая, но посмотрим на результат. Из базы можно выгрузить корпуса по отдельности или в формате TMX.
from lingtrain_aligner import saver
output_path="/content"
saver.save_plain_text(db_path, os.path.join(output_path, f"corpora_{lang_from}.txt"), direction="from", batch_ids=[])
saver.save_plain_text(db_path, os.path.join(output_path, f"corpora_{lang_to}.txt"), direction="to", batch_ids=[])
saver.save_tmx(db_path, os.path.join(output_path, f"corpora.tmx"), lang_from, lang_to)Отрывок из corpora.tmx:

Разрешив конфликты, мы из 344 предложений на английском и 372 на русском получили параллельный корпус из 332 строк. Как было сказано ранее, таким же образом можно выравнивать книги полностью.
Так как художественный перевод подчас граничит с искусством, то некоторые пары все равно нуждаются в дополнительной валидации. Все зависит от конкретного перевода. Кроме того, модель может ошибаться на коротких предложениях и предложениях с большим количеством названий и имен.
Иногда переводчик склонен даже "улучшить" оригинал. Например, в одном из переводов "Властелина колец" можно встретить такое описание:
Тень улыбки промелькнула на бледном, без кровинки, лице Боромира.И оригинал:
Boromir smiled.II. Fine-tuning для нового языка
Вернемся к малым языкам. Модель хоть и хорошая и из коробки "понимает" более ста языков, но с новым будет работать неудовлетворительно. Давайте попробуем.
Colab
Проделанные мной эксперименты и код вы можете посмотреть в этом Colab'e.
Башкирский язык
Попробуем выровнять рассказ "Батя Ялалетдин" Мустая Карима на башкирском и русском языках. Проделаем все те же действия, что и в первой части, получим следующее:

Видим, что качество значительно хуже, хотя и довольно неплохое. С чем это связано? С тем, что LaBSE была обучена в том числе и на небольшом корпусе татарского языка. Эти языки являются родственными и иногда можно получить перевод с одного на другой заменой некоторых букв.
Если мы сейчас запустим механизм разрешения конфликтов, то он, конечно же, отработает. Однако будет значительное количество некорректных разрешений. Так как нас это не устраивает, давайте разбираться как можно модель дообучить и улучшить качество корпуса.
Fine-tuning
Сначала вспомним, как Google изначально тренировал свою модель. Задачей, которую модель оптимизировала, был translation ranking task. Из заданного набора переводов нужно было найти самый корректный (картинка из статьи):

В обертке над моделью, которую я использовал (а это очень популярная и удобная библиотека sentence_transformers) есть набор loss'ов, которые примерно это и делают.
Сначала установим зависимости:
pip install transformers sentencepiece sentence_transformersСделаем импорт и проинициализируем модель:
from sentence_transformers import SentenceTransformer, SentencesDataset, losses
from sentence_transformers.readers import InputExample
from sentence_transformers.evaluation import SentenceEvaluator
from torch.utils.data import DataLoader
model = SentenceTransformer('LaBSE')Дообученную модель можно передать как параметр в методы выравнивания, так мы чуть позже и поступим.
Почитав документацию, я нашел несколько подходящих нам функций ошибок. Это MultipleNegativesRankingLoss, ContrastiveLoss и OnlineContrastiveLoss. В два последних необходимо передвать примеры с меткой 0 или 1. 1 — если пара строк является взаимным переводом и надо сблизить соответствующие вектора, 0 — если надо их растащить. MultipleNegativesRankingLoss работает похожим образом, по коду видно, что в этом лоссе для каждого примера из батча корректные переводы будут приближаться, а все остальные — отдаляться. Автор библиотеки порекомендовал использовать именно его, и в ходе экспериментов он действительно оказался эффективнее других.
Для дообучения нужно привести к необходимому виду свой датасет с парами переводов. Разумеется, перед обучением надо обратить внимание на качество датасета и почистить его. Для башкирского языка я пользовался данными, которые мне предоставили энтузиасты в лице Айгиза Кунафина и Искандера Шакирова. Это открытый русско-башкирский датасет.
train_examples = [InputExample(texts=[x['ba'], x['ru']], label=1) for x in train_dataset]
train_dataset = SentencesDataset(train_examples, model)
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=train_batch_size)
train_loss = losses.MultipleNegativesRankingLoss(model=model)После этого можно обучать модель, делается это просто:
num_epochs = 3
warmup_steps = math.ceil(len(train_dataloader) * 0.1 * num_epochs)
model.fit(train_objectives=[(train_dataloader, train_loss)],
evaluator=evaluator,
epochs=num_epochs,
evaluation_steps=1000,
output_path=model_save_path,
save_best_model=True,
use_amp=True,
warmup_steps=warmup_steps)Так же можно в качестве evaluator'а передать свой класс. Он будет вызываться каждые evaluation_steps шагов, считать вашу метрику и рисовать графики. Я добавил класс ChainScoreEvaluator, который выравнивает и оценивает небольшие отрывки текста на рассматриваемых языках.

Так же надо заметить, что Colab хоть и бесплатный, но может выдавать недостаточно мощные для тренировки карточки. Это сказывается на размере батча и скорости обучения. В итоге я оформил подписку за $10 в месяц (примерно 750 рублей).
Улучшение
Дообучив в течение нескольких дней модель в Colab'e, получился следующий результат:

Такого качества уже хватает, чтобы более уверенно поставить на место выпавшие строки.

Чувашский язык
С чувашским языком все было гораздо сложнее, так как исходное качество было в разы хуже. Язык находится дальше от своих тюркских родственников, которые присутствуют в модели.

За датасет спасибо Александру Антонову, популяризатору чувашского языка. Русско-чувашский параллельный корпус можно найти здесь. В результате экспериментов удалось значительно улучшить качество:
Результат после автоматического разрешения конфликтов:

corpora.tmx

Чтобы вы смогли оценить качество этих моделей, я собрал Colab с их использованием. Преимущество Colab'а в том, что он предоставляет свои GPU, поэтому расчеты идут гораздо быстрее. В этом ноутбуке можно выбирать и другие языки, попробуйте.
Валидация
Отдельно скажу про проверку получившегося корпуса. Чтобы улучшить его качество, можно при помощи этой же модели посчитать расстояние между эмбеддингами (напомню, что это всего лишь вектор чисел соответствующий предложению) и отсечь самые далекие по смыслу пары.
Еще лучше привлечь носителей языка. Так поступили башкирские коллеги, написав бота, который дает на оценку пары предложений. Если владеете башкирским, то подключайтесь.
Обе модели можно попробовать здесь.
UI
Для ручного разрешения больших конфликтов и редактирования корпуса я написал UI. Подробнее о нем я рассказывал здесь, а выглядит он так:
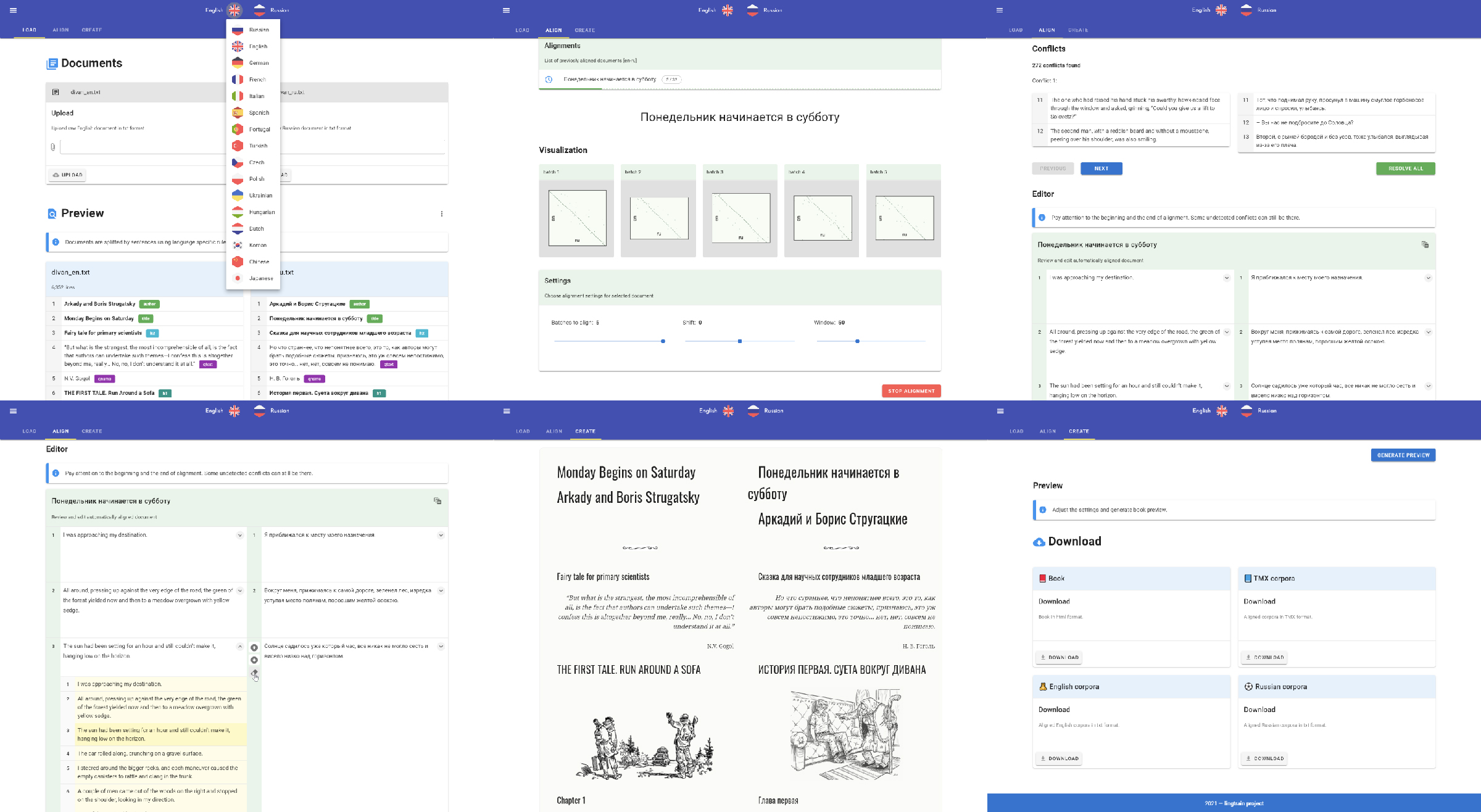
В нем можно не только выравнивать и редактировать корпуса, но и делать из них параллельные книги.
Идеи
Проделанные эксперименты наверняка не являются самыми оптимальными. Качество можно улучшить, если добавить в датасет данные того же стиля, документы на котором необходимо будет выравнивать.
Так же можно использовать тот факт, что родственные языки обладают схожей грамматикой и лексикой с точностью до символов алфавита. Возможно, что при замене, например, кириллических букв на латинские, качество дополнительно возрастет (для того же чувашского). Это тоже предстоит попробовать.
Если у вас какие-то идеи по этому поводу, то буду рад, если поделитесь.
И да, чуть не забыл, — кто угадает, что за языки обозначены на обложке статьи?
Комментариев нет:
Отправить комментарий