Эти компоненты, начиная с графа Tensorflow, могут быть представлены в виде такой диаграммы:
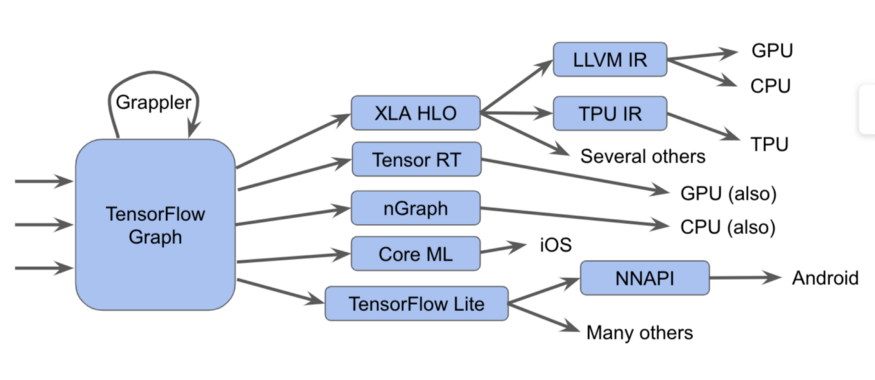
На самом деле всё сложнее
На этой диаграмме мы можем видеть, что графы Tensorflow могут быть запущены несколькими разными способами
В TensorFlow 2.0, графы могут быть неявными, жадное исполнение может запускать операции индивидуально, по группам, или на полном графе. Эти графы или фрагменты графа должны быть оптимизированы и выполнены.
- Посылаем графы исполнителю Tensorflow, который вызывает написанные вручную специализированные ядра
- Преобразуем их в XLA HLO (XLA High-Level Optimizer representation) — высокоуровневое представление оптимизатора XLA, который, в свою очередь, может вызывать компилятор LLVM для CPU или GPU, или продолжать использовать XLA для TPU, или комбинировать их.
- Преобразуем их в TensorRT, nGraph, или другой формат для специализированного набора инструкций, реализованного в железе.
- Преобразуем их в формат TensorFlow Lite, выполняемый в рантайме TensorFlow Lite, или преобразуемый в код для запуска на GPU или DSP через Android Neural Networks API (NNAPI) или подобным образом.
Также существуют более сложные способы, включающие в себя множество проходов оптимизации на каждом слое, как, например, в фреймворке Grappler, который оптимизирует операции в TensorFlow.
Несмотря на то, что эти различные реализации компиляторов и промежуточных представлений улучшают производительность, их разнообразие представляет проблему для конечных пользователей, такие, как сбивающие с толку сообщения об ошибках при сопряжении этих подсистем. Также создатели новых программных и аппаратных стеков должны подстраивать проходы оптимизации и преобразования для каждого нового случая.
И в силу всего этого, мы рады анонсировать MLIR, Многоуровненвое Промежуточное Представление (Multi-Level Intermediate Representation). Это формат промежуточного представления и библиотеки компиляции, предназначенные для использования между представлением модели и низкоуровневым компилятором, генерирующим аппаратно-зависимый код. Представляя MLIR, мы хотим дать дорогу новым исследованиям в разработке оптимизирующих компиляторов и реализациям компиляторов, построенных на компонентах промышленного качества.
Мы ожидаем, что MLIR будет интересен многим группам, включая:
- исследователям компиляторов, а также практикам, желающим оптимизировать производительность и потребление памяти моделей машинного обучения;
- производителям аппаратного обеспечения, ищущим способ объединить с Tensorflow своё железо, такое, как TPU, мобильные нейропроцессоры в смартфонах, и другие кастомные ASIC-и;
- людям, которые хотят дать языкам программирования преимущества, предоставляемые оптимизирущими компиляторами и аппаратными ускорителями;
Что такое MLIR?
MLIR, по сути, гибкая инфраструктура для современных оптимизирующих компиляторов. Это значит, что она состоит из спецификации промежуточного представления (IR) и набора инструментов для преобразования этого представления. Когда мы говорим о компиляторах, переход от более высокоуровневого представления к более низкоуровневому называется «спуском» (lowering), и мы будем использовать этот термин в дальнейшем.
MLIR построен под влиянием LLVM и беззастенчиво заимствует многие хорошие идеи из него. Он имеет гибкую систему типов, и предназначен для представления, анализа и преобразования графов, объединяя множество уровней абстракции в одном уровне компиляции. Эти абстракции включают в себя операции Tensorflow, вложенные регионы полиэдральных циклов, инструкции LLVM, а также операции и типы с фиксированной точкой.
Диалекты MLIR
Для того, чтобы разделить различные программные и аппаратные таргеты, MLIR имеет «диалекты», включающие в себя:
- TensorFlow IR, включающий в себя всё то, что возможно сделать в графах TensorFlow
- XLA HLO IR, разработанный для того, чтобы получить все преимущества, предоставляемые компилятором XLA, на выходе которого мы можем получит код для TPU, и не только.
- Экспериментальный аффинный диалект, предназначенный специально для полиэдральных представлений и оптимизаций
- LLVM IR, 1:1 совпадающий с собственным представлением LLVM, позволяющий MLIR генерировать код для GPU и CPU с помощью LLVM.
- TensorFlow Lite, предназначенный для генерации кода для мобильных платформ
Каждый диалект содержит набор определённых операций, с использованием инвариантов, таких, как: «это бинарный оператор, и его вход и выход имеют один и тот же тип».
Расширения MLIR
MLIR не имеет фиксированного и встроенного списка глобальных intrinsic-операций. Диалекты могут определять полностью кастомные типы, и таким образом MLIR может моделировать такие вещи, как систему типов LLVM IR (имеющую агрегаты первого класса), абстракции доменных языков, такие, как квантизованные типы, важные для оптимизированных под ML ускорителей, и, в будущем, даже систему типов Swift или Clang.
Если вы хотите присоединить к этой системе новый низкоуровневый компилятор, вы можете создать новый диалект и спуск с диалекта графа TensorFlow на ваш диалект. Это упрощает путь для разработчиков аппаратного обеспечения и разработчиков компилятора. Вы можете нацелить диалект на различные уровни одной и той же модели, высокоуровневые оптимизаторы будут отвечать за специфические части IR.
Для исследователей компиляторов и разработчиков фреймворков, MLIR позволяет вам создать преобразования на каждом уровне, вы можете определять свои собственные операции и абстракции в IR, позволяя вам лучше моделировать ваши прикладные задачи. Таким образом, MLIR — это нечто большее, чем чистая инфраструктура компилятора, которой является LLVM.
Хотя MLIR работает как компилятор для ML, он также позволяет использовать технологии машинного обучения! Это очень важно для инженеров, разрабатывающих численные библиотеки, и не могут обеспечить поддержку всего многообразия ML-моделей и аппаратного обеспечения. Гибкость MLIR облегчает исследования стратегий спуска кода при переходе между уровнями абстракции.
Что дальше
Мы открыли GitHub-репозиторий и приглашаем всех заинтересованных (изучите наше руководство!). Мы будем выпускать нечто большее, чем этот набор инструментов — спецификации диалектов TensorFlow и TF Lite, в ближайшие месяцы. Мы можем рассказать вам больше, для того, чтобы узнать подробности, см. презентацию Криса Латтнера и наш README на Github.
Если вы хотите быть в курсе всех вещей, относящихся к MLIR, присоединяйтесь к нашему новому списку рассылки, который в ближайшее время будет сфокусирован на анонсах будущих релизов нашего проекта. Оставайтесь с нами!
Комментариев нет:
Отправить комментарий