
Одно из первых наставлений, которое молодой падаван получает вместе с доступом к git-репозиториям, звучит так: «никогда не ешь жёлтый снег делай git push -f». Поскольку это одна из сотен максим, которые нужно усвоить начинающему инженеру-разработчику ПО, никто не тратит время на уточнение, почему именно так нельзя делать. Это как младенцы и огонь: «спички детям не игрушки» и баста. Но мы растём и развиваемся как люди и как профессионалы, и однажды вопрос «а почему, собственно?» встаёт в полный рост. Эта статья написана по мотивам нашего внутреннего митапа, на тему: «Когда можно и нужно переписывать историю коммитов».

Я слышал, что умение ответить на этот вопрос на собеседовании в некоторых компаниях является критерием прохождения собеседования на сеньорские позиции. Но чтобы лучше понять ответ на него, нужно разобраться, почему вообще плохо переписывание истории?
Для этого, в свою очередь, нам понадобится быстрый экскурс в физическую структуру git-репозитория. Если вы точно уверены, что знаете об устройстве репо всё, то можете пропустить эту часть, но даже я в процессе выяснения узнал для себя довольно много нового, а кое-что старое оказалось не вполне релевантным.
На самом низком уровне git-репо представляет собой набор объектов и указателей на них. Каждый объект имеет свой уникальный 40-значный хэш (20 байт в 16-ричной системе), который вычисляется на основе содержимого объекта.
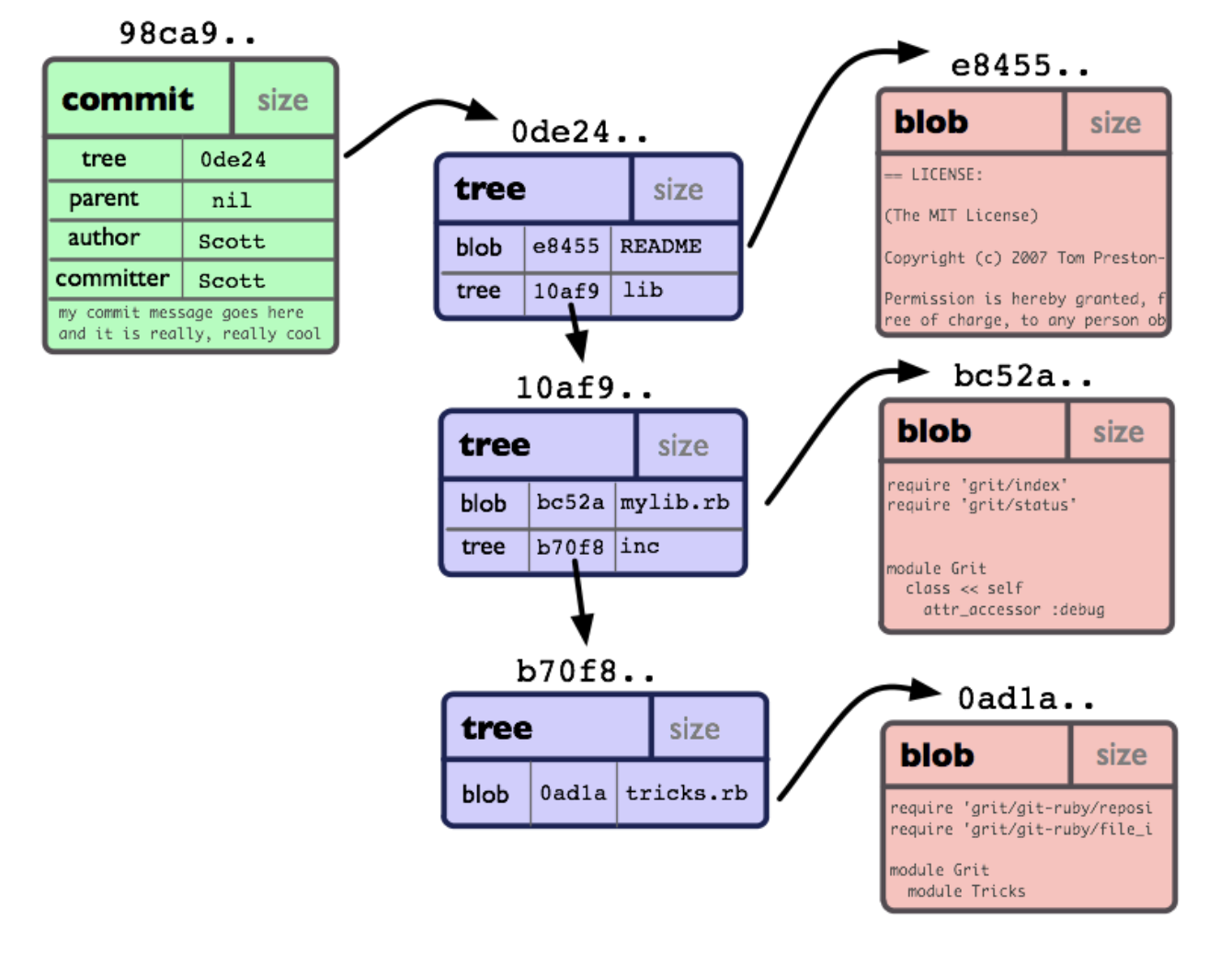
Иллюстрация взята из The Git Community Book
Основные типы объектов — это blob (просто содержимое файла), tree (набор указателей на blobs и другие trees) и commit. Объект типа commit представляет собой только указатель на tree, на предыдущий коммит и служебную информацию: дата/время, автор и комментарий.
Где здесь ветки и тэги, которыми мы привыкли оперировать? А они не являются объектами, они являются просто указателями: ветка указывает на последний коммит в ней, тэг — на произвольный коммит в репо. То есть когда мы в IDE или GUI-клиенте видим красиво нарисованные веточки с кружочками-коммитами на них — они строятся на лету, пробегая по цепочкам коммитов от концов веток вниз к «корню». Самый первый коммит в репо не имеет предыдущего, вместо указателя там null.
Важный для понимания момент: один и тот же коммит может фигурировать в нескольких ветках одновременно. Коммиты не копируются при создании новой ветки, она просто начинает «расти» с того места, где был HEAD в момент отдачи команды git checkout -b <branch-name>.
Итак, почему же переписывание истории репозитория вредно?

Во-первых, и это очевидно, при загрузке новой истории в репозитории, с которым работает команда инженеров, другие люди могут просто потерять свои изменения. Команда git push -f удаляет из ветки на сервере все коммиты, которых нет в локальной версии, и записывает новые.
Почему-то мало кто знает, что довольно давно у команды git push существует «безопасный» ключ --force-with-lease, который заставляет команду завершиться с ошибкой, если в удалённом репозитории есть коммиты, добавленные другими пользователями. Я всегда рекомендую использовать его вместо -f/--force.
Вторая причина, по которой команда git push -f считается вредной, заключается в том, что при попытке слияния (merge) ветки с переписанной историей с ветками, где она сохранилась (точнее, сохранились коммиты, удалённые из переписанной истории), мы получим адское число конфликтов (по числу коммитов, собственно). На это есть простой ответ: если аккуратно соблюдать Gitflow или Gitlab Flow, то такие ситуации, скорее всего, даже не возникнут.
И наконец есть неприятная побочка переписывания истории: те коммиты, которые как бы удаляются при этом из ветки, на самом деле, никуда не исчезают и просто остаются навечно висеть в репо. Мелочь, но неприятно. К счастью, эту проблему разработчики git тоже предусмотрели, введя команду сборки мусора git gc --prune. Большинство git-хостингов, как минимум GitHub и GitLab, время от времени,
производят эту операцию в фоне.
Итак, развеяв опасения перед изменением истории репозитория, можно, наконец, перейти к главному вопросу: зачем оно нужно и когда оправдано?
На самом деле, я уверен, что практически каждый из более-менее активных пользователей git хоть раз, да изменял историю, когда вдруг оказывалось, что в последнем коммите что-то пошло не так: вкралась досадная опечатка в код, сделал коммит не от того пользователя (с личного e-mail вместо рабочего или наоборот), забыл добавить новый файл (если вы, как я, любите пользоваться git commit -a). Даже изменение описания коммита приводит к необходимости его перезаписи, ведь хэш считается и от описания тоже!
Но это тривиальный случай. Давайте рассмотрим более интересные.
Допустим, вы сделали большую фичу, которую пилили несколько дней, отсылая ежедневно результаты работы в репозиторий на сервере (4-5 коммитов), и отправили свои изменения на ревью. Двое-трое неутомимых ревьюверов закидали вас крупными и мелкими рекомендациями правок, а то и вовсе нашли косяки (ещё 4-5 коммитов). Затем QA нашли несколько краевых случаев, тоже требующих исправлений (ещё 2-3 коммита). И наконец при интеграции выяснились какие-то несовместимости или попадали автотесты, которые тоже надо пофиксить.
Если теперь нажать, не глядя, кнопку Merge, то в главную ветку (у многих она по старинке называется master) вольются полтора десятка коммитов типа «My feature, day 1», «Day 2», «Fix tests», «Fix review» и т.д. От этого, конечно, помогает режим squash, который сейчас есть и в GitHub, и в GitLab, но с ним надо быть осторожными: во-первых, он может заменить описание коммита на что-то непредсказуемое, а во-вторых — заменить автора фичи на того, кто нажал кнопку Merge (у нас это вообще робот, помогающий релиз-инженеру собрать сегодняшний деплой). Поэтому самым простым будет перед окончательной интеграцией в релиз схлопнуть все коммиты ветки в один при помощи git rebase.
Но бывает также, что к код-ревью вы уже подошли с историей репо, напоминающей салат «Оливье». Такое бывает, если фича пилилась несколько недель, ибо была плохо декомпозирована или, хотя за это в приличных коллективах бьют канделябром, требования изменились в процессе разработки. Вот, например, реальный merge request, который приехал ко мне на ревью две недели назад:
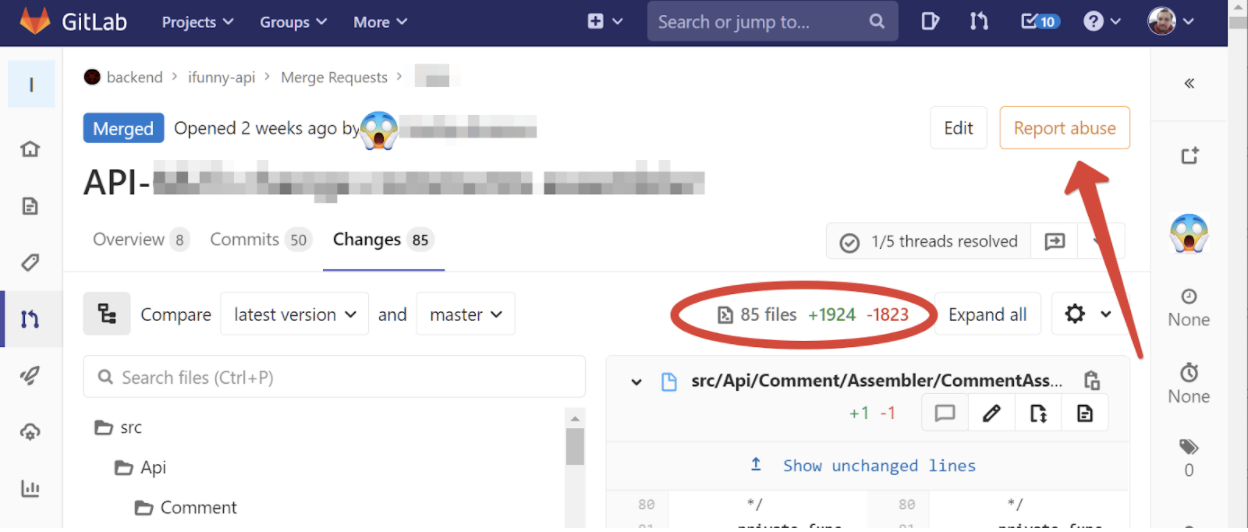
У меня рука машинально потянулась к кнопке «Report abuse», потому что как ещё можно охарактеризовать реквест из 50 коммитов с почти 2000 изменённых строк? И как его, спрашивается, ревьюить?
Честно говоря, у меня ушло два дня просто на то, чтобы заставить себя приступить к этому ревью. И это нормальная реакция для инженера; кто-то в подобной ситуации, просто не глядя, жмёт Approve, понимая, что за разумное время всё равно не сможет сделать работу по обзору этого изменения с достаточным качеством.
Но есть способ облегчить жизнь товарищу. Помимо предварительной работы по лучшей декомпозиции задачи, уже после завершения написания основного кода можно привести историю его написания в более логичный вид, разбив на атомарные коммиты с зелёными тестами в каждом: «создал новый сервис и транспортный уровень для него», «построил модели и написал проверку инвариантов», «добавил валидацию и обработку исключений», «написал тесты».
Каждый из таких коммитов можно ревьюить по отдельности (и GitHub, и GitLab это умеют) и делать это набегами в моменты переключения между своими задачами или в перерывах.
Сделать это всё нам поможет всё тот же git rebase с ключом --interactive. В качестве параметра надо передать ему хэш коммита, начиная с которого нужно будет переписать историю. Если речь о последних 50 коммитах, как в примере на картинке, можно написать git rebase --interactive HEAD~50 (подставьте вместо “50” вашу цифру).
Кстати, если вы в процессе работы над задачей подливали к себе ветку master, то сначала надо будет сделать rebase на эту ветку, чтобы merge-коммиты и коммиты из мастера не путались у вас под ногами.
Вооружившись знаниями о внутреннем устройстве git-репозитория, понять принцип действия rebase на master будет несложно. Эта команда берёт все коммиты в нашей ветке и меняет родителя первого из них на последний коммит в ветке master. См. схему:
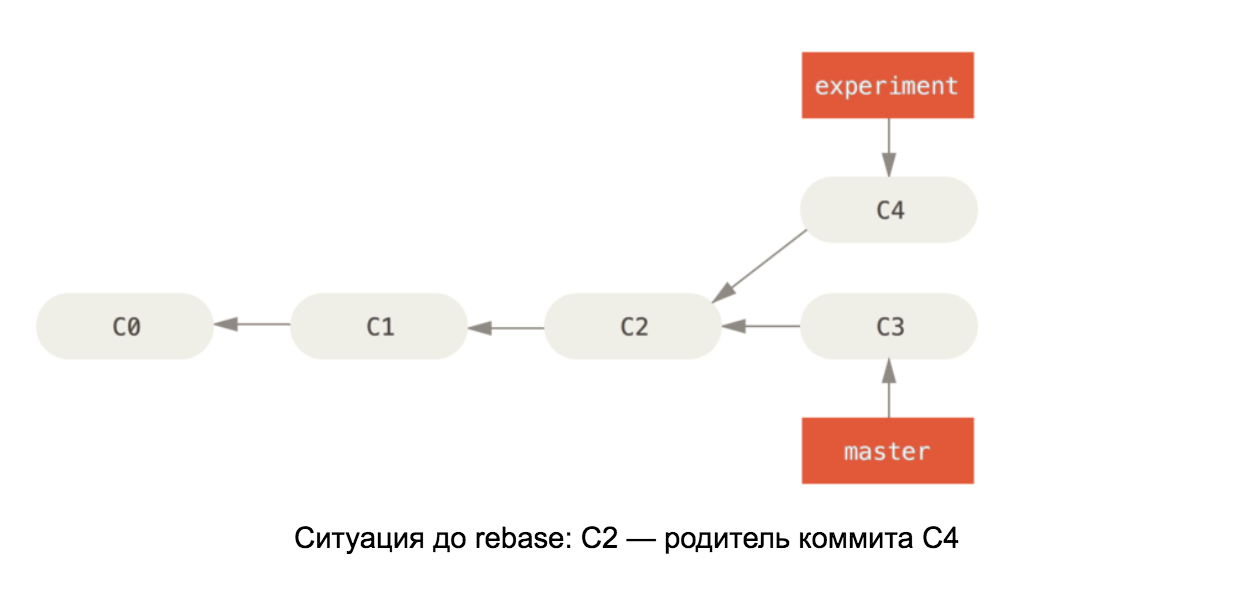
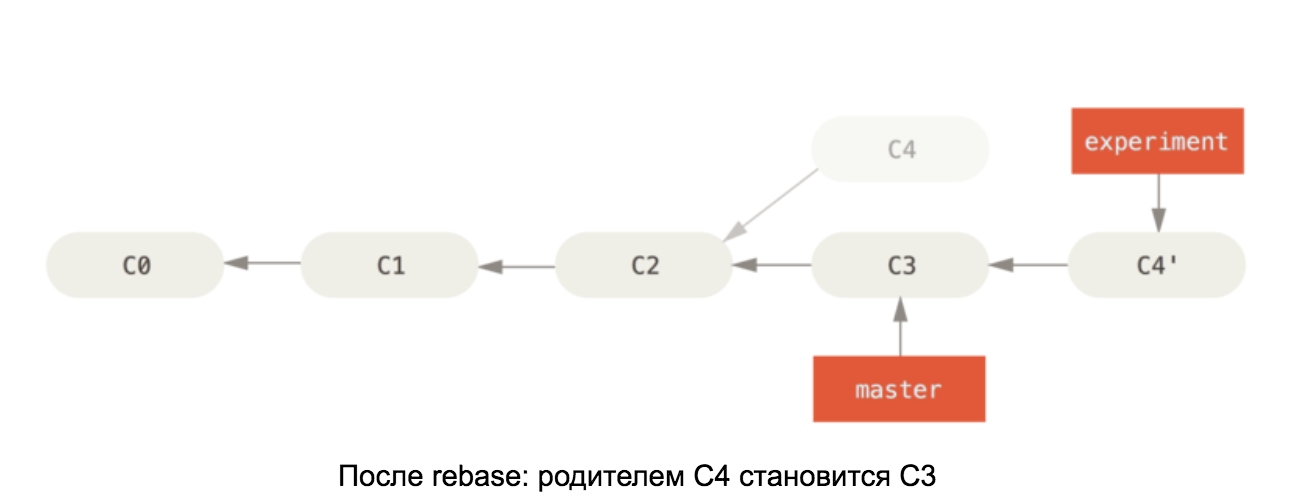
Иллюстрации взяты из книги Pro Git
Если изменения в C4 и C3 конфликтуют, то после разрешения конфликтов коммит C4 изменит своё содержание, поэтому он переименован на второй схеме в C4’.
Таким образом, вы получите ветку, состоящую только из ваших изменений, и растущую из вершины master. Само собой, master должен быть актуальным. Можно просто использовать версию с сервера: git pull --rebase origin/master (как известно, git pull равносилен git fetch && git merge, а ключ --rebase заставит git сделать rebase вместо merge).
Вернёмся наконец к git rebase --interactive. Его делали программисты для программистов, и понимая, какой стресс люди будут испытывать в процессе, постарались максимально сохранить нервы пользователя и избавить его от необходимости чрезмерно напрягаться. Вот что вы увидите на экране:
Это репозиторий популярного пакета Guzzle. Похоже, что rebase ему не помешал бы…
В текстовом редакторе открывается сформированный файл. Внизу вас ожидает подробная справка о том, что тут вообще делать. Далее в режиме простого редактирования вы решаете, что делать с коммитами в вашей ветке. Всё просто, как палка: pick — оставить как есть, reword — поменять описание коммита, squash — слить воедино с предыдущим (процесс работает снизу вверх, то есть предыдущий — это который строчкой ниже), drop — вообще удалить, edit — и это самое интересное — остановиться и замереть. После того, как git встретит команду edit, он встанет в позицию, когда изменения в коммите уже добавлены в режим staged. Вы можете поменять всё, что угодно в этом коммите, добавить поверх него ещё несколько, и после этого скомандовать git rebase --continue, чтобы продолжить процесс rebase.
Да, и кстати, вы можете поменять коммиты местами. Возможно, это создаст конфликты, но в целом процесс rebase редко обходится совсем уж без конфликтов. Как говорится, снявши голову, по волосам не плачут.
Если вы запутались и кажется, что всё пропало, у вас есть кнопка аварийного катапультирования git rebase --abort, которая немедленно вернёт всё как было.
Вы можете повторять rebase несколько раз, затрагивая только части истории, и оставляя остальные нетронутыми при помощи pick, придавая своей истории всё более и более законченный вид, как гончар кувшину. Хорошим тоном, как я уже написал выше, будет сделать так, что тесты в каждом коммите будут зелёными (для этого отлично помогает edit и на следующем проходе — squash).
Ещё одна фигура высшего пилотажа, полезная в случае, если надо несколько изменений в одном и том же файле разложить по разным коммитам — git add --patch. Она бывает полезна и сама по себе, но в сочетании с директивой edit она позволит вам разделить один коммит на несколько, причём сделать это на уровне отдельных строк, чего не позволяет, если я не ошибаюсь, ни один GUI-клиент и ни одна IDE.
Убедившись ещё раз, что всё в порядке, вы наконец можете со спокойной душой сделать то, с чего начался этот туториал: git push --force. Ой, то есть, разумеется, --force-with-lease!

Поначалу вы, скорее всего, будете тратить на этот процесс (включая первоначальный rebase на master) час, а то и два, если фича реально развесистая. Но даже это намного лучше, чем ждать два дня, когда ревьювер заставит себя наконец взяться за ваш реквест, и ещё пару дней, пока он сквозь него продерётся. В будущем же вы, скорее всего, будете укладываться в 30-40 минут. Особенно помогают в этом продукты линейки IntelliJ со встроенным инструментом разрешения конфликтов (full disclosure: компания FunCorp оплачивает эти продукяы своим сотрудникам).
Последнее, от чего хочется предостеречь, — не переписывайте историю ветки в процессе код-ревью. Помните, что добросовестный ревьюер возможно клонирует ваш код к себе локально, чтобы иметь возможность смотреть на него через IDE и запускать тесты.
Спасибо за внимание всем, кто дочитал до конца! Надеюсь, что статья будет полезна не только вам, но и коллегам, которым ваш код попадает на ревью. Если у вас есть клёвые хаки для git — делитесь ими в комментариях!
Комментариев нет:
Отправить комментарий