Я являюсь .NET разработчиком стартапа, фото-сервиса
http://gfranq.com/ и в данной статье решил описать как была реализована функциональность выборки и отображения фотографий на определенном участке карты, как и обещал в
предыдущей статье.
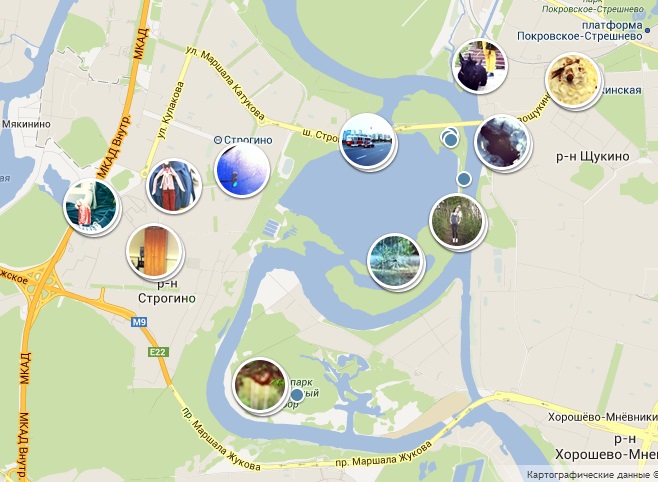
Так как сейчас фотографий на нашем сервисе очень много и посылать запросы к БД при каждом изменении окна просмотра слишком ресурсозатратно, логично было разбить карту на участки, в которых хранилась бы информация об уже извлеченных данных. Эти участки по вполне понятным причинам имеют прямоугольную форму (хотя вариант с гексагональной сеткой тоже рассматривался).
Итак, в данной статье будут затронуты следующие проблемы:
- Хранение и выборка фотографий из БД и помещение их в серверный кэш (SQL, C#).
- Загрузка необходимых фотографий на стороне клиента и помещение их в клиентский кэш (JavaScript).
- Перерасчет фотографий, которые нужно скрыть или отобразить при каждом изменении окна просмотра (JavaScript).
Серверная часть
Были придуманы следующие способы выборки и хранения геоинформации в БД:
- Встроенных географические типы SQL Server.
- Обычная выборка с ограничениями.
- Использование дополнительной таблицы.
Далее эти способы будут рассмотрены подробно.
Встроенные геотипы
Как известно, в SQL Server 2008 появилась поддержка типов geography и geometry, которые позволяют задавать географическую (на сфере) и геометрическую (на плоскости) информацию, такие как точки, линии, многоугольники
и т.д. И для того, чтобы получить все фотографии, заключенные прямоугольником с координатами (lngMin latMin) и (latMax lngMax), можно воспользоваться следующим запросом:
DECLARE @h geography;
DECLARE @p geography;
SET @rect =
geography::STGeomFromText('POLYGON((lngMin latMin, lngMax latMin, lngMax latMax, lngMin latMax, lngMin latMin))', 4326);
SELECT TOP @cound id, image75Path, geoTag.Lat as Lat, geoTag.Long as Lng, popularity, width, height
FROM Photo WITH (INDEX(IX_Photo_geoTag))
WHERE @rect.STContains(geoTag) = 1
ORDER BY popularity DESC
Обратите внимание, что полигон обходится против часовой стрелке и используется пространственный индекс IX_Photo_geoTag, построенный по координатам (кстати, пространственные индексы также работают по принципу
B-деревьев ).
Однако оказалось, что в Microsoft SQL Server 2008 пространственные индексы не работают в случае, если колонка с геотипами может принимать NULL значения, а также составной индекс не может содержать в себе колонку с типом geography, и этот вопрос был затронут на stackoverflow. Из-за этого производительность таких запросов (без индексов) становится очень низкой.
В качестве решения такой проблемы можно предложить следующее:
Несмотря на широкие возможности географических типов (а они позволяют производить не только такую простую выборку, указанную в примере выше, но и использовать расстояния, различные многоугольники), они не были использованы у нас в проекте.
Обычная выборка
Выборку фотографий из области, ограниченной координатами (lngMin latMin) и (latMax lngMax), несложно реализовать с помощью следующего запроса:
SELECT TOP @Count id, url, ...
FROM Photo
WHERE latitude > @latMin AND longitude > @lngMin AND latitude < @latMax AND longitude < @lngMax
ORDER BY popularity DESC
Стоит отметить, что для полей
latitude и
longitude в данном случае можно создавать любые индексы (в отличие от первого варианта), поскольку они являются обычными типами float. Однако в данной выборке присутствует 4 сравнения.
Использование дополнительной таблицы с кэшами
Наиболее оптимальное решение проблемы выборки фотографий из определенных областей заключается в создании дополнительной таблицы
Zooms, которая хранила бы в себе строки, содержащие в себе хеши областей для каждого зума, как это отображено на рисунке ниже.
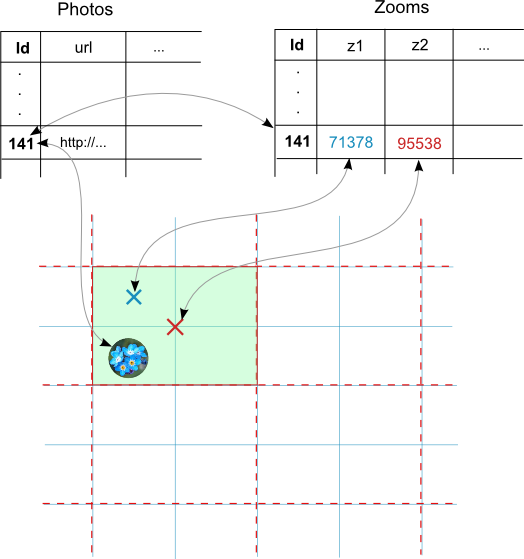
SQL запрос при этом приобретает следующий вид (zn — текущий уровень зума):
DECLARE @hash float;
SET @hash = (@latMin + 90) + (@lngMin + 180) * 180 + (@latMax + 90) * 64800 + (@lngMax + 180) * 11664000;
SELECT TOP @Count id, url, ...
FROM Photo WHERE id = (SELECT id FROM Zooms WHERE zn = @hash)
Недостатком такого подхода является то, что дополнительная таблица занимает дополнительное место в памяти.
Несмотря на достоинство последнего метода, на сервере был реализован второй вариант с обычной выборкой, так как и он показал вполне неплохую производительность.
Сохранение фотографий в кэш на сервер при многопоточном доступе
После того, как информация была извлечена из БД тем или иным образом, фотографии помещаются в серверный кэш следующим образом с использованием синхронизирующего объекта (для поддержки многопоточности):
private static object SyncObject = new object();
...
List<Photo> photos = (List<Photo>)CachedAreas[hash];
if (photos == null)
{
// Использование блокировки для не того, чтобы не случилось ситуации извлечения и вставки в кэш более 1 раза.
lock (SyncObject)
{
photos = (List<Photo>)CachedAreas[hash];
if (photos == null)
{
photos = PhotoList.GetAllFromRect(latMin, lngMin, latMax, lngMax, count);
// Добавление информации о фотографиях в кэш с временем хранения 2 минуты с высоким приоритетом хранения.
CachedAreas.Add(hash, photos, null, DateTime.Now.AddSeconds(120), Cache.NoSlidingExpiration, CacheItemPriority.High, null);
}
}
}
// Дальнейшее использование CachedAreas[hash]
В данном разделе была описана серверная функциональность для выборки фотографий из БД и их сохранения в кэш. В следующем разделе будет описано то, что происходит на стороне клиента.
Клиентская часть
Для визуализации карты и фотографий на ней использовалось Googla Maps API. Для начала карту у пользователя нужно переместить в определенное подходящее место.
Инициализация карты
Существуют два способа определения области навигации при инициализации карты. Первый заключается определении текущей позиции с помощью HTML5, а второй — в использовании заранее определенных координат для всех регионов.
Определение местоположения с помощью HTML5
function detectRegion() {
if (navigator.geolocation) {
navigator.geolocation.getCurrentPosition(success);
} else {
map.setZoom(defaultZoom);
map.setCenter(defaultPoint);
}
}
function success(position) {
...
map.setZoom(defaultZoom);
map.setCenter(new google.maps.LatLng(position.coords.latitude, position.coords.longitude));
}
Недостатком такого подхода является то, что не все браузеры поддерживают данную функцию HTML5, к тому же пользователь может не разрешать доступ к геоинформации на своем устройстве.
Определение местоположения с помощью информации с сервера
Инициализация карты производится в следующем участке исходного кода, в котором
bounds — координаты региона (насленного пункта, области или страны), возращенные сервером. Определение приблизительного уровня зума определяется по алгоритму, приведенному в функции
getZoomFromBounds (позаимствовано из
stackoverflow).
var northEast = bounds.getNorthEast();
var southWest = bounds.getSouthWest();
var myOptions = {
zoom: getZoomFromBounds(northEast, southWest),
center: new google.maps.LatLng((northEast.lat() + southWest.lat()) / 2, (northEast.lng() + southWest.lng()) / 2),
mapTypeId: google.maps.MapTypeId.ROADMAP,
minZoom: 3,
maxZoom: 19
}
map = new google.maps.Map(document.getElementById("map_canvas"), myOptions);
function getZoomFromBounds(ne, sw) {
var GLOBE_WIDTH = 256; // a constant in Google's map projection
var west = sw.lng();
var east = ne.lng();
var angle = east - west;
if (angle < 0) {
angle += 360;
}
return Math.round(Math.log($('#map_canvas').width() * 360 / angle / GLOBE_WIDTH) / Math.LN2);
}
Для агрегации всех координат границ для каждого региона использовался google geocoding api. (Хотя использование такой информации в оффлайне не является правомерным, кроме того там есть ограничение на 2500 запросов в день). Для каждого города, области и страны из нашей базы данных формировался запрос следующего типа, который возвращал искомые границы viewport и bounds (Они кстати различны только для больших областей, которые не могут полностью поместиться в окно просмотра). При этом если возвращался ответ с ошибкой, то использовались другие запросы, в котором комбинировалось написание на родном для этого региона языке или английском, убиралась часть {Населенный пункт} и т. д.
http://maps.googleapis.com/maps/api/geocode/xml?address={Страна},{Область/Штат},{Населенный пункт}&sensor=false
Например для такого запроса:
http://maps.googleapis.com/maps/api/geocode/xml?address=Россия, Ивановская%20область, Иваново&sensor=falseБудет возвращаться следующее (фрагмент)
...
<location>
<lat>56.9951313</lat>
<lng>40.9796047</lng>
</location>
<location_type>APPROXIMATE</location_type>
<viewport>
<southwest>
<lat>56.9420231</lat>
<lng>40.8765941</lng>
</southwest>
<northeast>
<lat>57.0703221</lat>
<lng>41.0876169</lng>
</northeast>
</viewport>
<bounds>
<southwest>
<lat>56.9420231</lat>
<lng>40.8765941</lng>
</southwest>
<northeast>
<lat>57.0703221</lat>
<lng>41.0876169</lng>
</northeast>
</bounds>
...
Расчет прямоугольных областей с фотографиями, перекрывающихся текущим окном просмотра
Расчет размера кэширующих областей
Итак, как уже было отмечено ранее, все фотографии и на клиенте и на сервере кэшируются по прямоугольным областям, точкой отсчета которых является произвольная точка (в нашем случае точка с координатами (0, 0)), а размер вычисляется в зависимости от текущего уровня приближения (зума) следующим образом:
// Первоначальное окошко, при котором вычислялось initMapSizeLat и initMapSizeLng
var initDefaultDimX = 1000, var initDefaultDimY = 800;
// Текущее окно просмотра по умолчанию, которое зависит на размер областей.
var currentDefaultDimX = 1080, var currentDefaultDimY = 500;
var initMapSizeLat = 0.0003019; var initMapSizeLng = 0.00067055;
// Коэффициент уменьшения(увеличения) размера.
var initRatio = 0.75;
// Для вычисления этого размера наименьшей кэширующей области карта была приближена до максимального уровня зума
// Т.е. initMapSizeLat и initMapSizeLng были вычислены эмпирически.
var initZoomSize = new google.maps.Size(
initMapSizeLat / initDefaultDimX * currentDefaultDimX * initRatio,
initMapSizeLng / initDefaultDimY * currentDefaultDimY * initRatio);
// Все последующие размеры областей можно вычислить, основываясь только на наименьшей (путем умножения каждого размера на 2, потому что при увеличении уровня зума на 1, линейные размеры увеличиваются в 2 раза, а квадратичные - в 4).
function initZoomSizes() {
zoomSizes = [];
var coef = 1;
for (var i = 21; i >= 0; i--) {
zoomSizes[i] = new google.maps.Size(initZoomSize.width * coef, initZoomSize.height * coef);
coef *= 2;
}
}
Таким образом, на каждом уровне зума, размер прямоугольной области по площади составляет 0.75^2=0.5625 от текущего окна просмотра, если его ширина = 1080px и высота = 500px.
Пересчет видимых фотографий при изменении размеров окна просмотра с задержкой
Так как перерисовка всех фотографий на карте не очень быстрая операция (как будет показано позже), то решено было ее сделать с определенной задержкой после пользовательского ввода:
google.maps.event.addListener(map, 'bounds_changed', function () {
if (boundsChangedInverval != undefined)
clearInterval(boundsChangedInverval);
var zoom = map.getZoom();
boundsChangedInverval = setTimeout(function () {
boundsChanged();
}, prevZoom === zoom ? moveUpdateDelay : zoomUpdateDelay);
prevZoom = zoom;
});
Расчет координат и хешей всех кэширующих областей, перекрывающихся с окном просмотра
Расчет координат и хешей всех прямоугольников, перекрывающих видимое окно с координатами (
latMin,
lngMin) и размерами, вычисленных по алгоритму, описанным ранее, производится следующим образом:

var s = zoomSizes[zoom];
var beginLat = Math.floor((latMin - initPoint.x) / s.width) * s.width + initPoint.x;
var beginLng = Math.floor((lngMin - initPoint.y) / s.height) * s.height + initPoint.y;
var lat = beginLat;
var lng = beginLng;
if (lngMax <= beginLng)
beginLng = beginLng - 360;
while (lat <= maxlat) {
lng = beginLng;
while (lng <= maxLng) {
// Координаты lat и normalizeLng(lng) являются координатами перекрывающихся прямоугольников.
// Нормализация долготы используется из-за того, что правая граница может быть больше чем 180 или левая меньше чем -180.
loadIfNeeded(lat, normalizeLng(lng));
lng += s.height;
}
lat += s.width;
}
function normalizeLng(lng)
{
var rtn = lng % 360;
if (rtn <= 0)
rtn += 360;
if (rtn > 180)
rtn -= 360;
return rtn;
}
Затем для каждой области вызывается следующая функция, которая посылает запрос к серверу при необходимости. Формула расчета хеша возвращает уникальное значение для каждой области, потому что точка отсчета и размеры фиксированы.
function loadIfNeeded(lat, lng) {
var hash = calculateHash(lat, lng, zoom);
if (!(hash in items)) {
// Сделать запрос к БД и занести данную ячейку в клиентский кэш.
} else {
// Не производить никаких действий.
}
}
function calculateHash(lat, lng, zoom) {
// lat: [-90..90]
// lng: [-180..180]
return (lat + 90) + ((lng + 180) * 180) + (zoom * 64800);
}
Перерисовка отображаемых фотографий (маркеров)
После того, как все фотографии загружены или извлечены из кэша, часть из них нужно перерисовать. При большом скоплении фотографий в одном месте, часть из них желательно нужно скрывать, однако становится непонятно, сколько именно фотографий располагается в данном месте. Для решения этой проблемы было решено сделать поддержку двух типов маркеров: маркеры, отображающие фотографии и маркеры, отображающие, что в данном месте есть фотографии. Также если все маркеры скрывать при изменении границ, а потом заново их отображать, то будет заметно мерцание. Для решения вышеописанных проблем был разработан следующий алгоритм:
- Извлечение всех видимых фотографий из клиентского кэша в массив visMarks. Расчет данных областей с фотографиями был описаны выше.
- Сортировка полученных маркеров по популярности.
- Определение перекрывающихся маркеров с использованием markerSize, smallMarkerSize, minPhotoDistRatio и функции pixelDistance.
- Создание массивов из больших маркеров с количеством maxBigVisPhotosCount и маленьких с количеством maxSmlVisPhotosCount.
- Определение старых маркеров, которые нужно скрыть и занесение их в smlMarksToHide и bigMarksToHide c помощью refreshMarkerArrays
- Обновление видимости и индекса глубины (zIndex) для новых маркеров, которых нужно отобразить с помощью updateMarkersVis
- Добавление фотографий, которые стали видимыми в текущий момент времени в ленту сверху с помощью addPhotoToRibbon
Алгоритм пересчета видимых маркеров
function redraw() {
isRedrawing = true;
var visMarker;
var visMarks = [];
var visBigMarks2;
var visSmlMarks2;
var bigMarksToHide = [];
var smlMarksToHide = [];
var photo;
var i, j;
var bounds = map.getBounds();
var northEast = bounds.getNorthEast();
var southWest = bounds.getSouthWest();
var latMin = southWest.lat();
var lngMin = southWest.lng();
var latMax = northEast.lat();
var lngMax = northEast.lng();
var ratio = (latMax - latMin) / $("#map_canvas").height();
var zoom = map.getZoom();
visMarks = [];
var k = 0;
var s = zoomSizes[zoom];
var beginLat = Math.floor((latMin - initPoint.x) / s.width) * s.width + initPoint.x;
var beginLng = Math.floor((lngMin - initPoint.y) / s.height) * s.height + initPoint.y;
var lat = beginLat;
var lng = beginLng;
i = 0;
if (lngMax <= beginLng)
beginLng = beginLng - 360;
// Извлечение всех видимых маркеров.
while (lat <= latMax) {
lng = beginLng;
while (lng <= lngMax) {
var hash = calcHash(lat, normLng(lng), zoom);
if (!(hash in curItems)) {
}
else {
var item = curItems[hash];
for (photo in item.photos) {
if (bounds.contains(item.photos[photo].latLng)) {
visMarks[i] = item.photos[photo];
visMarks[i].overlapCount = 0;
i++;
}
}
}
k++;
lng += s.height;
}
lat += s.width;
}
// Сортировка маркеров по популярности.
visMarks.sort(function (a, b) {
if (b.priority !== a.priority) {
return b.priority - a.priority;
} else if (b.popularity !== a.popularity) {
return b.popularity - a.popularity;
} else {
return b.id - a.id;
}
});
// Определение перекрывающихся маркеров и маркеров, превышающих определенное заданное количество.
var curInd;
var contains;
var contains2;
var dist;
visBigMarks2 = [];
visSmlMarks2 = [];
for (i = 0; i < visMarks.length; i++) {
contains = false;
contains2 = false;
visMarker = visMarks[i];
for (j = 0; j < visBigMarks2.length; j++) {
dist = pixelDistance(visMarker.latLng, visBigMarks2[j].latLng, zoom);
if (dist <= markerSize * minPhotoDistRatio) {
contains = true;
if (contains && contains2)
break;
}
if (dist <= (markerSize + smallMarkerSize) / 2) {
contains2 = true;
if (contains && contains2)
break;
}
}
if (!contains) {
if (visBigMarks2.length < maxBigVisPhotosCount) {
smlMarksToHide[smlMarksToHide.length] = visMarker;
visBigMarks2[visBigMarks2.length] = visMarker;
}
} else {
bigMarksToHide[bigMarksToHide.length] = visMarker;
if (!contains2 && visSmlMarks2.length < maxSmlVisPhotosCount) {
visSmlMarks2[visSmlMarks2.length] = visMarker;
} else {
visBigMarks2[j].overlapCount++;
}
}
}
// Занесение маркеров, которые нужно скрыть в smlMarksToHide и bigMarksToHide соответственно.
refreshMarkerArrays(visibleSmallMarkers, visSmlMarks2, smlMarksToHide);
refreshMarkerArrays(visibleBigMarkers, visBigMarks2, bigMarksToHide);
// Сокрытие невидимых и отображение видимых маркеров с изменение zIndex.
var curZInd = maxBigVisPhotosCount + 1;
curZInd = updateMarkersVis(visBigMarks2, bigMarksToHide, true, curZInd);
curZInd = 0;
curZInd = updateMarkersVis(visSmlMarks2, smlMarksToHide, false, curZInd);
visibleBigMarkers = visBigMarks2;
visibleSmallMarkers = visSmlMarks2;
// Добавление видимых фотографий в ленту.
trPhotosOnMap.innerHTML = '';
for (var marker in visBigMarks2) {
addPhotoToRibbon(visBigMarks2[marker]);
}
isRedrawing = false;
}
function refreshMarkerArrays(oldArr, newArr, toHide) {
for (var j = 0; j < oldArr.length; j++) {
contains = false;
var visMarker = oldArr[j];
for (i = 0; i < newArr.length; i++) {
if (newArr[i].id === visMarker.id) {
contains = true;
break;
}
}
if (!contains) {
toHide[toHide.length] = visMarker;
}
}
}
function updateMarkersVis(showArr, hideArr, big, curZInd) {
var marker;
var bounds = map.getBounds();
for (var i = 0; i < showArr.length; i++) {
var photo = showArr[i];
if (big) {
marker = photo.bigMarker;
$('#divOvlpCount' + photo.id).html(photo.overlapCount);
} else {
marker = photo.smlMarker;
}
marker.setZIndex(++curZInd);
if (marker.getMap() === null) {
marker.setMap(map);
}
}
for (i = 0; i < hideArr.length; i++) {
marker = big ? hideArr[i].bigMarker : hideArr[i].smlMarker;
if (marker.getMap() !== null) {
marker.setMap(null);
marker.setZIndex(0);
if (!bounds.contains(hideArr[i].latLng))
hideArr[i].priority = 0;
}
}
return curZInd;
}
function addPhotoToRibbon(marker) {
var td = createColumn(marker);
if (isLatLngValid(marker.latLng)) {
trPhotosOnMap.appendChild(td);
} else {
trPhotosNotOnMap.appendChild(td);
if (photoViewMode == 'user') {
var img = $("#photo" + marker.id).children()[0];
$('#photo' + marker.id).draggable({
helper: 'clone',
appendTo: $('#map_canvas'),
stop: function (e) {
var mapBoundingRect = document.getElementById("map_canvas").getBoundingClientRect();
var point = new google.maps.Point(e.pageX - mapBoundingRect.left, e.pageY - mapBoundingRect.top);
var latLng = overlay.getProjection().fromContainerPixelToLatLng(point);
marker.latLng = latLng;
marker.priority = ++curPriority;
placeMarker(marker);
},
containment: 'parent',
distance: 5
});
}
}
}
Расстояние между двумя точками на карте в пикселях.
Используется при перерасчете видимых маркеров и вычисляется следующим образом. Данная функция тоже была найдена на просторах stackoverflow.
var Offset = 268435456;
var Radius = 85445659.4471;
function pixelDistance(latLng1, latLng2, zoom) {
var x1 = lonToX(latLng1.lng());
var y1 = latToY(latLng1.lat());
var x2 = lonToX(latLng2.lng());
var y2 = latToY(latLng2.lat());
return Math.sqrt((x1 - x2) * (x1 - x2) + (y1 - y2) * (y1 - y2)) >> (21 - zoom);
}
function lonToX(lng) {
return Math.round(Offset + Radius * lng * Math.PI / 180);
}
function latToY(lat) {
return Math.round(Offset - Radius * Math.log((1 + Math.sin(lat * Math.PI / 180)) / (1 - Math.sin(lat * Math.PI / 180))) / 2);
}
Для стилизации маркеров (чтобы они выглядели как кружки с фотографиями как вконтакте) использовался плагин
richmarker с добавление произвольного стиля элементу div.
Посмотреть как работает разработанная функциональность можно например по данной ссылке: http://gfranq.com/vlada#map
Если данный топик оказался интересным или полезным для вас, то в следующей статья я постараюсь описать еще что-нибудь из работы нашего сервиса, новой функциональности и т.д.
This entry passed through the Full-Text RSS service — if this is your content and you're reading it on someone else's site, please read the FAQ at fivefilters.org/content-only/faq.php#publishers. Five Filters recommends: 'You Say What You Like, Because They Like What You Say' - http://www.medialens.org/index.php/alerts/alert-archive/alerts-2013/731-you-say-what-you-like-because-they-like-what-you-say.html





 . Встречаем
. Встречаем 
 Веб-разработка
Веб-разработка CSS
CSS JavaScripts
JavaScripts Браузеры
Браузеры Новости
Новости Сервисы
Сервисы Сайты с интересным дизайном и функциональностью
Сайты с интересным дизайном и функциональностью Занимательное
Занимательное