Когда читаешь восторженные комменты о будущем победном шествии StarLink по планете, о том как там почти по мановению ока и взмаху руки Илона Маска появятся межспутниковые каналы, или для SpaceX пересмотрят национальные законы по получению прав на частоты, или как технологическая сложность абонентского терминала StarLink вместе с его ценой рухнет до уровня велосипеда с китайской фабрики, остается только вздохнуть… А ведь это еще не все ограничения и барьеры, которые окружают инженеров StarLink и значительно усложняют их работу.
Сегодня затронем тему — EPFD или Equivalent Power Flux Density (эквивалентная плотность потока мощности). Это еще один параметр, суровая необходимость соблюдать который уже принесла проблемы и ограничения для инженеров StarLink и похоже еще принесет… Вот документ МСЭ описывающий, что это и как считать.
Передатчик на борту спутника посылает сигнал в сторону Земли, и чем сильнее этот сигнал, тем меньше нам нужна площадь антенны внизу, или при том же размере антенны мы можем иметь большее соотношение сигнал/шум и передать больше бит в одном Герце.
Для того, чтобы сигналы от разных источников на одной частоте не мешали друг другу МСЭ ввело лимиты, которые должны соблюдать все владельцы радиоэлектронных средств (в данном случае операторы спутников).
Все развитие ИСЗ на геостационаре шло по пути того, как бы постараться приблизиться к этому лимиту, так как даже мощность 100 Вт передатчика на геостационарном спутнике на расстоянии 36000 км при минимальном угле диаграммы направленности антенны позволял к этому лимиту только немного подойти, а минимальный диаметр зоны освещения на Земле, который удавалось создать, примерно равен 36000 км х 0,01 = 360 км. И весь сигнал «размазывается» по этой площади.
А теперь посмотрим на StarLink: высота всего 550 км (то есть в 65 раз меньше), и диаметр зоны при 1 градусе будет всего около 6 км. Используя тот же передатчик на спутнике, StarLink могли бы иметь в десятки раз более мощный сигнал (по сути разница — это 65², то есть почти в 40000 раз)
Но тут все упирается в нормы по EPFD, которые SpaceX обязан соблюдать, и все на чем он может сэкономить — это на мощности передатчика (габариты, цена и энергопотребление), но это все копейки по сравнению с потерянными возможностями вместо модуляции 8PSK которая имеется сейчас и соответствующих ей 3 бита/Герц, можно было бы использовать 64QAM и получить 6 бит/Гц для полосы в 240 МГц. Это была бы скорость 1,4 Гигабита! Просто фантастика для абонента…
Если Вы посмотрите на Заявку SpaceX в FCC (Federal Communication Comission), то чуть ли не половина ее технической части — это расчеты и диаграммы, доказывающие FCC, что StarLink не выходит за пределы лимита EPFD (красная линия), принятыми FCC для США. Вот пример такого рисунка:
Если бы не эти жесткие лимиты, то StarLink мог бы уменьшить размер терминала или дать абоненту существенно большие скорости и иметь значительно больше абонентов в одной соте.
При этом уход StarLink с первоначальных 1100 км (на которое FCC и дал разрешение в 2018 году) на 550 км только усугубил проблему, сигнал спутника стал на Земле еще мощнее, и вокруг этого сейчас ведется настоящая рубка в FCC (противники SpaceX пытаются доказать, что SpaceX нарушает лимит мощности по EPFD).
Сейчас появился интересный документ, в котором говорится о том, что в своих расчетах SpaceX якобы исходит из того, что участок на Земле получает сигнал только от одного спутника, в то время как на самом деле, имея группировку в 4000+ спутников (при том, что каждый ИСЗ имеет зону видимости на Земле диаметром в 1900 км), на один участок Земли будут светить 2 и более ИСЗ. И тогда приемники спутникового телевидения компании DISH могут столкнуться с проблемами.
И в принципе бизнес логика это и предусматривает – если у Вас рядом есть полупустая зона и зона с многими абонентами, почему на загруженную зону не направить второй и третий луч с других ИСЗ? Или абонент имеет препятствие на линии на основной ИСЗ для этой зоны, почему его не переключить на другой ИСЗ?
Чем это кончится не известно, дебаты в FCC продолжаются. На кону вопрос о переводе всех 4408 ИСЗ StarLink с высоты 1100 км на 550 км, на что уже все ориентировано в SpaceX. Возможно FCC одобрит его, но выдвинет новые ограничения для StarLink.
А между тем на орбиту отправилось уже 1147 ИСЗ из разрешенных FCC 1584 для фазы 1, (если же считать в плоскостях то сделаны запуски в 57 из 72), а конца обсуждению заявки SpaceX от 17 апреля 2020 года о снижении высоты для всех ИСЗ не видно. Напомню, что первую заявку SpaceX ФСС рассматривал более 2 лет (а в 2016-2018 годах к SpaceX и его планам относились не так серьезно и с не таким противодействием от практически всех спутниковых операторов).
Так что в реализации планов Илона Маска на расширение и увеличение скорости для абонентов в этом и следующем году могут быть задержки.
5 марта 2021 года руководитель группы разработчиков Chrome рассказал, что в тестовых сборках Canary браузера, например, в версии 91.0.4437.0, появился упрощенный режим тестирования некоторых экспериментальных функций. Опцию можно вызвать путем нажатия на иконку в виде колбы Эрленмейера на панели инструментов браузера.
Сейчас опция Experiments позволяет активировать три новых функции — Reading list (список для чтения), Tab Scrolling (прокрутка вкладок) и Tab Search (поиск по вкладкам). Также с помощью Experiments можно быстро отсылать сообщения для обратной связи с разработчиками Chrome. Таким образом компания планирует собирать больше отзывов от пользователей о будущих обновлениях и новых функциях. Иконка Experiments в скором времени появится в сборках Dev и Beta браузера.
Если после установки ранней тестовой сборке Canary версии Chrome 91 иконка в виде колбы не появилась, то нужно ее активировать в меню настройки браузера через флаг «chrome://flags/#chrome-labs».
Некоторые пользователи заметили, что опция Experiments уже доступна в Chrome 89 Beta.
4 марта 2021 года Google сообщила, что новые версии браузера, начиная с Chrome 94 и далее, будут выходить каждые 4 недели, вместо существующего 6 недельного графика. Переход на месячный цикл обновлений должен помочь пользователям оперативно получать новые функции и патчи безопасности.
2 марта 2021 года вышел Chrome 89. Эта и последующие версии браузера не будут запускаться на ПК со старыми x86 процессорами, которые не поддерживают набор команд SSE3.
Исследователи из Австралийского национального университета (ANU) заявили, что внутреннее ядро Земли является двухслойным. Они подсчитали, что «самое внутреннее» ядро с температурами, превышающими 5000 градусов по Цельсию, составляет 1% от общего объема нашей планеты.
Геофизик Австралийского национального университета Джоанн Стивенсон говорит, что особые свойства этого внутреннего слоя могут указывать на неизвестное науке событие в истории Земли.
Команда задействовала в своей работе алгоритм, который позволил сопоставить тысячи моделей внутреннего ядра с данными десятилетних наблюдений о том, как долго сейсмические волны проходят через Землю.
Модели анизотропии внутреннего ядра демонстрируют, как различия в его составе изменяют свойства сейсмических волн. Согласно одним, материал внутреннего ядра направляет сейсмические волны параллельно экватору. Другие модели утверждают, что сочетание материалов позволяет создавать более быстрые волны, параллельные оси вращения Земли.
Это исследование обнаружило изменение направления волн на 54 градуса, причем те, что двигались быстрее, проходили параллельно оси.
«Мы нашли доказательства, которые могут указывать на изменение структуры железа, что предполагает, возможно, два отдельных периода похолодания в истории Земли», — отметила Стивенсон.
Эта работа может объяснять, почему некоторые экспериментальные данные не соответствуют нынешним моделям строения Земли.
Ученые выделяют четыре основных слоя Земли: кору, мантию, внешнее ядро и внутреннее ядро. Однако в последние годы они уже выдвигали предположение о наличии «самого внутреннего слоя». До проведения нынешнего исследования никаких подтверждений этой теории не существовало.
Ранее Европейское космическое агентство обнаруживало в недрах Земли струйное течение шириной до 420 километров на глубине около 3000 километров. Этот поток циркулирует со скоростью в 40-45 км в год.
Министр просвещения России Сергей Кравцов. Источник фото: Пресс-служба Совета Федерации РФ/РИА Новости.
По информации «РБК», 5 марта 2021 года министр просвещения РФ Сергей Кравцов рассказал, что до конца года все школы страны будут подключены к сети Интернет, в том числе в них будет развернута сеть Wi-Fi. Городские образовательные учреждения получат доступ со скоростью не менее 100 Мбит/с, сельские и поселковые не менее 50 Мбит/с, причем в отдаленных школах будет спутниковое подключение.
Учащиеся смогут использовать школьную беспроводную сеть Wi-Fi для обучения и в своих интересах. Им будет ограничен доступ к «негативному» контенту через эту сеть. Они смогут заходить только на верифицированные ресурсы.
Кравцов уточнил, что эти ограничения необходимы, чтобы защитить детей от негативной информации, которая используется в недобросовестных целях. Министр не пояснил, что именно подразумевается под «негативной информацией».
Кравцов также сообщил, что российский сервис для дистанционного обучения школьников под названием «Сферум» успешно проходит тестирование в 15 регионах страны. К образовательной платформе уже сейчас могут подключиться все желающие.
В начале февраля Роспотребнадзор объявил о новых санитарных правилах, согласно которым детям школьного возраста запрещено использовать личные мобильные телефоны в образовательных целях,
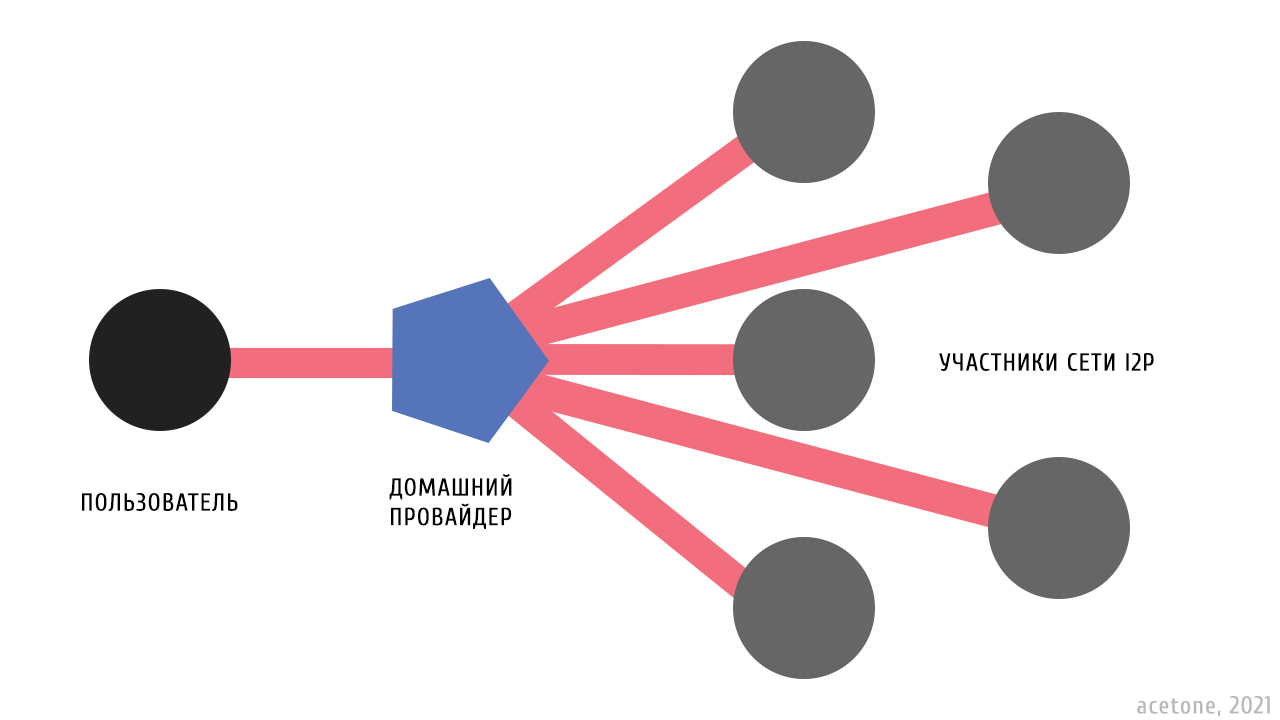
I2P (Invisible Internet Protocol) – свободный инструмент организации анонимных коммуникаций через интернет. Является одноранговой сетью, в которой каждый пользователь по умолчанию является потенциальным звеном в анонимной цепочке других участников сети. Трафик I2P зашифрован и не поддается анализу. Понятие «сторожевого» узла в I2P, которое присутствует в сети Tor, нет: не существует никакого постоянного узла, через который осуществляется выход в сеть. Взаимодействие пользователя с I2P на стороне домашнего провайдера идентифицируется, как хаотичное подключение к случайным хостам. Количество подключений клиента с белым IP в среднем варьируется у отметки в четыре тысячи. Помимо полезной нагрузки, сюда входят обмен служебной информацией с другими роутерами сети и транзитный трафик.
Предпосылки
Существенное слабое место сети I2P заключается в необходимости обращения к одному из стартовых узлов через обычный интернет при первом запуске. Пакет с начальным рисунком сети в виде нескольких случайных роутеров и узел, который его отдает, называются ресидом. Стартовые узлы держат энтузиасты, их список имеется в общем доступе и нередко претерпевает изменения в силу обычных человеческих обстоятельств. Бутылочное горлышко заключается в возможности на стороне провайдера идентифицировать большинство обращений к ресиду через мониторинг DNS-запросов, а также в блокировке доменов стартовых узлов, что затруднит первый запуск для неопытного пользователя, т.к. потребует использование прокси или VPN.
Блокировка запроса к ресиду на стороне провайдера
В отличие от обычного интернета, пользователи I2P без выделенного адреса имеют худшее качество использования скрытой сети, чем абоненты с белым IP. Это связано с постоянной необходимостью прямого сообщения с другими роутерами сети. Каждый роутер публикует свой адрес, который включает в себя ключи шифрования, IP-адрес и порт для приема сообщений. Очевидно, что достучаться до узла сети за NAT-сервером – задача не из простых.
Разница между пользователем с выделенным IP и пользователем за NAT-ом
Однако работа роутеров без выделенного адреса возможна: клиенту сети за NAT-ом приходится постоянно поддерживать активное UDP-соединение, резервируя на выходном сервере провайдера порт, обращения на который будут переданы клиенту. Этот сценарий весьма сложен, особенно, когда речь заходит про инициализацию соединения извне. Механика работы клиента за NAT-ом – произведение инженерной мысли, которое заслуживает отдельной статьи.
Кратко об Yggdrasil
Yggdrasil – один из немногих работоспособных протоколов меш-сетей. Основная концепция заключатся в автоматической маршрутизации во внутренней IPv6 подсети (200::/7) и абсолютной масштабируемости. Yggdrasil является полностью одноранговой сетью: не существует каких-либо «мастер-узлов», которым делегируется какая-то глобальная ответственность. Является идеологическим продолжателем проекта CJDNS (Hyperborea).
Абстрактная идея меш-сети во главу угла ставит производительность, приватность и простоту использования: шифрование трафика и низкий порог вхождения новых пользователей. Yggdrasil не является инструментом анонимности, т.к. ближайшие к пользователю узлы видят его реальные сетевые интерфейсы в локальной сети, либо IP-адрес при подключении к публичному пиру через интернет. Меш-сети находят применение в организации псевдолокальных сетей, объединяя удаленные компьютеры в одну IPv6-сеть (по аналогии с Hamachi для игры в Minecraft и прочие мультиплеерные игры). Также служит для организации прочих внутрисетевых ресурсов вроде сайтов и VoIP-телефонии.
Первые попытки интеграции
Небольшое замечание
Описанные ниже нововведения на момент публикации статьи касаются только i2pd – I2P-роутера на C++.
I2P-роутер публикует свои адреса, в том числе IPv6, если он включен в конфиге и имеется фактически. Так как Yggdrasil предоставляет пользователю не локальный прокси, а полноценный сетевой интерфейс (туннель WireGuard), до недавних пор I2P-роутер публиковал адрес IPv6 из подсети Yggdrasil. Так как пользователей с включенным протоколом IPv6 в конфигурации I2P-роутера и установленным Yggdrasil было больше, чем один и даже два, периодически можно было видеть, что клиент I2P (роутер) сообщается с другими Yggdrasil-адресами.
Однако на лицо следующие недостатки:
обращение к ресиду в конечном счете должно осуществляться через обычный интернет;
опубликованный роутером адрес IPv6-Yggdrasil для подавляющего большинства пользователей I2P является неизвестным и недоступным;
успешный запуск I2P-роутера на Yggdrasil-Only устройстве маловероятен в силу возможного отсутствия в ресиде или локальной базе роутера узлов с адресом IPv6-Yggdrasil.
Начало полной совместимости
С версии 2.36.0 i2pd имеет несколько новых конфигурационных параметров, главный из которых meshnets.yggdrasil=true Этот параметр не зависит от конфигурации IPv4 и IPv6. В частности, реальные сетевые интерфейсы могут быть отключены. В таком случае I2P-роутер будет работать в режиме Yggdrasil-Only.
Также организован специальный ресид, доступный из Yggdrasil и отдающий пользователю пакет в первую очередь состоящий из известных роутеров с адресом IPv6-Yggdrasil. При каждом запуске I2P-роутера, работающего в режиме Yggdrasil-Only, проводится проверка наличия в локальной базе доступных узлов на транспортном уровне, т.е. наличие других узлов с IPv6-Yggdrasil. Если по каким-то причинам совместимых роутеров в локальной базе не оказалось, происходит повторное обращение к Yggdrasil-ресиду.
При современном использовании Yggdrasil по большей части через оверлейные подключения к публичным пирам через интернет, работа I2P-роутера в Yggdrasil сравнима со связкой “Tor-over-VPN”: подобный подход полностью скрывает факт использования скрытой сети от домашнего провайдера. В случае с I2P имеется еще одно специфичное преимущество: пользователю не нужно иметь выделенный IP от провайдера для беспроблемных внешних обращений, т.к. IPv6-Yggdrasil является глобально доступным в рамках сегмента сети Yggdrasil (физически соединенной группы участников, в том числе через публичные пиры в интернете).
Целостность сети
Описанное решение не является фактором фрагментации I2P. Построение туннелей скрытой сети – весьма емкий и даже ювелирный процесс, в рамках которого в том числе происходит согласование транспортных возможностей узлов. Формируя «чеснок» - зашифрованное сообщение группе узлов, которые должны образовать туннель, - роутер проверяет их адреса на совместимость. Например, узел с единственным адресом IPv4 не получит инструкцию, согласно которой ему необходимо установить контакт с адресом IPv6, т.к. это заведомо невозможно.
Чтобы Yggdrasil-Only роутеру построить туннель до узла с адресом из обычного интернета, как минимум будет подобран транзитный роутер, имеющий два интерфейса: IPv6-Yggdrasil и, например, обычный IPv4. В свою очередь, другие Yggdrasil-Only роутеры также могут выступать транзитными звеньями туннеля, но только для сообщения с узлами совместимыми по транспорту, т.е. также имеющими сетевой интерфейс Yggdrasil. Чем больше в сети I2P количество роутеров с одновременно включенными IPv4, IPv6 и Yggdrasil интерфейсами, тем связнее сеть.
Подключение к I2P через Yggdrasil
Перспектива
Пример с Yggdrasil является частным шагом в будущее, а не самоцелью. Описанный опыт успешной интеграции скрытой сети в меш-сеть является важным концептуальным шагом, который при надобности позволит интегрировать сеть I2P в другие меш-сети. Перспектива открывается при рассмотрении самоорганизованных сегментов меш-сети, например, в многоквартирных домах без централизованного провайдера. В локальной сети клиент Yggdrasil автоматически находит другие узлы и сообщается с ними, сам выступая при надобности транзитным. При подключении хотя бы одного узла в таком сегменте к другому сегменту сети (например, к глобальному через интернет), сети автоматически объединяются. Такой подход к организации сети стал еще реальнее, т.к. теперь имеет место быть и вторая сторона привычного интернета – скрытая.
Для более детального ознакомления с I2P и Yggdrasil рекомендую видео:
Привет, меня зовут Иван. Сразу отвечу на главный вопрос: почему стал собирать сам, а не взял готовое решение? Во-первых, стоимость готовых решений - Raspberry Pi со всеми датчиками и камерой вышла не больше $30, большая часть еще по курсу 60 рублей за доллар. Во-вторых, почти все части уже были - Raspberry Pi отдал брат, камера осталась еще с лохматых времен, диод тоже был - покупал для Arduino, а датчик движения на Aliexpress стоил не больше 100 рублей.
Повествование в статье будет построено следующим образом:
Определим что нам потребуется;
Поработаем с диодом;
С датчиком движения;
С камерой (фото);
С камерой (видео);
Разберем работу с Telegram-ботом (рассмотрим скелет);
Создадим "Умную камеру";
Посмотрим на работу "Умной камеры";
Определим узкие места и возможные решения.
Итак, поехали
Что нам потребуется
На Raspberry должен быть настроен интернет, установлены:
ffmpeg - для записи видео с камеры;
Python 3.7.
У Python должны быть следующие библиотеки:
RPi.GPIO;
pygame;
telebot.
И понадобятся провода - F2F, что бы все это соединить.
Импортируем библиотеку для работы с нодами Raspberry, определяем нод для диода. В методе настройки библиотеки указываем, что нумерация нодов будет в соответствии с номерами на самой Raspberry, отключаем все предупреждения библиотеки и сообщаем, что на нод диода ток будет выходить, а не считываться. В методе очистки ресурсов отключаем диод и очищаем библиотеку. В главном методе - blink подаем сигнал на нод диода, ждем 1 секунду и выключаем подачу сигнала на нод диода. В методе main вызываем все методы подряд и больше ничего не делаем. Светом диода будем отображать обнаруженение движения датчиком.
Работа с датчиком движения
Перед подключением датчика движения к Raspberry необходимо для начала определить какой провод за что отвечает, потому что на некоторых датчиках земля находится слева, на некоторых - справа и это будет кардинально влиять на работу датчика:
После этого можно подключать датчик и настраивать его физически - скорректировать значение delay и sensitivity для своих нужд, вот пример моей настройки:
Помимо этого, есть еще один параметр настройки у датчика движения, хоть он и не бросается в глаза. На обратной стороне датчика есть "ключ", которым можно настроить дальность работы датчика, для своих нужд я переключил его:
В принципе, работа с датчиком движения сводится к одному методу - методу чтения сигнала с датчика (16 строка).
import RPi.GPIO as GPIO
import time
PIR_PIN = 11
def setup():
GPIO.setmode(GPIO.BOARD)
GPIO.setwarnings(False)
GPIO.setup(PIR_PIN, GPIO.IN)
def destroy():
GPIO.cleanup()
def sensorJob():
while True:
i = GPIO.input(PIR_PIN)
print("PIR value: " + str(i))
time.sleep(0.1)
def main():
setup()
sensorJob()
destroy()
if __name__ == '__main__':
main()
Определяем нод для датчика движения. В методе настройки библиотеки указываем, что по указанном ноду будет читаться сигнал. В главном методе - sensorJob в бесконечном цикле считываем сигнал, выводим значение в консоль и ожидаем небольшой промежуток времени.
Работа с камерой (фото)
С "железом" разобрались и теперь можно переходить к съемке фото и видео. Подключаем камеру к любому USB-порту, по необходимости, настраиваем. Вероятнее всего, операционная система сама подцепит нужные драйвера и дополнительной настройки не потребуется. Если у вас подключена 1 камера она будет называться /dev/video0. Также важно определить разрешение камеры, потому что можно получить фотографии сплошным черным цветом.
Импортируем библиотеку для работы с камерой. Инициализируем библиотеку, инициализируем расширение для работы с камерой, выводим список доступных камер, сохраняем нужную нам камеру в переменную, во втором параметре указываем разрешение камеры. В методе saveCapture определяем название файла, вызываем метод start у камеры, через метод get_image() у камеры получаем объект со снимком, сохраняем его методом pygame.image.save, в завершение останавливаем работу камеры методом stop. Очень важно останавливать работу камеры через библиотеку pygame, потому что библиотека ffmpeg будет пытаться использовать камеру и в случае, если мы ее не освободим будет завершаться ошибкой.
Работа с камерой (видео)
Для съемки видео мы будем отправлять в терминал сообщение следующего вида:
Где будем указывать формат видео - v4l2, количетсво кадров, разрешение съемки, главный аргумент -c copy, если у вас медленная камера, с этим параметром съемка и сохранение файла будет происходить в десятки раз быстрее, но будет отсутствовать preview у видео и в Telegram не будет отображаться количество времени, которое длится видео. Также, нельзя будет просмотреть видео прямо из Telegram, потребуется отдельный плеер.
Каркас Telegram-бота
Перед рассмотрением работы с Telegram-ботом предполагаем, что вы уже получили ключ от BotFather и выполнили настройку бота на стороне Telegram, там нет ничего сложного, поэтому не будем на этом останавливаться. Также, мы будем работать сразу с InlineKeyboard у Telegram-бота, потому что это удобно и не нужно переживать о том, как правильно писать ту или иную команду. Кроме того, в самом начале будем делать проверку на ID пользователя, чтобы никто случайно (или специально) не подглядывал в нашу камеру.
from telebot.types import InlineKeyboardMarkup, InlineKeyboardButton
import telebot
TOKEN = '99999999999:xxxxxxxxxxxxxxxxxx'
ADMIN_USER_ID = 999999999
bot = telebot.TeleBot(TOKEN)
@bot.message_handler(commands=['start'])
def start(message):
telegram_user = message.from_user
if telegram_user.id != ADMIN_USER_ID:
bot.send_message(message.chat.id, text="Hello. My name is James Brown. What do i do for you?")
return
keyboard = [
[
InlineKeyboardButton("Send capture", callback_data='sendCapture'),
InlineKeyboardButton("Send video", callback_data='sendVideo')
],
]
bot.send_message(chat_id=message.chat.id,
text="Supported commands:",
reply_markup=InlineKeyboardMarkup(keyboard))
def sendCapture(chat_id):
bot.send_photo(chat_id, photo=open('<filename>', 'rb'))
def sendVideo(chat_id):
bot.send_video(chat_id, open('<filename>', 'rb'))
@bot.callback_query_handler(func=lambda call: True)
def button(call):
globals()[call.data](call.message.chat.id)
def main():
setup()
bot.polling(none_stop=False, interval=5, timeout=20)
destroy()
if __name__ == '__main__':
main()
Импортируем классы для InlineKeyboard, импортируем библиотеку Telegram-бота. В переменной TOKEN указываем ключ от BotFather. Сохраняем ADMIN ID. С помощью нотаций указываем команду для метода start. В методе start делаем проверку на USER ID и если это не мы, то выводим сообщение и выходим из метода, если же это мы, то отправляем InlineKeyboard с доступными командами. При отправке клавиатуры можно также сразу отправлять и текст. В методах sendCapture и sendVideo показаны примеры команд для отправки фото и видео через Telegram-бота. Далее нам нужно указать метод, который будет обрабатывать нажатия на InlineKeyboard, тоже через нотацию, но теперь нотация немного другая, вызов метода по нажатию на кнопку делаем по имени этого метода. В методе main вызываем bot.pooling, который в бесконечном цикле проверяет наличие входящих сообщений боту. Если у вас быстрая Raspberry и интернет, то можете не указывать параметры у этого метода и оставить их по-умолчанию. У меня стабильность отправки сообщений была низкой из-за чего пришлось добавить interval = 5. В конце статьи расскажу на что это влияет.
"Умная камера"
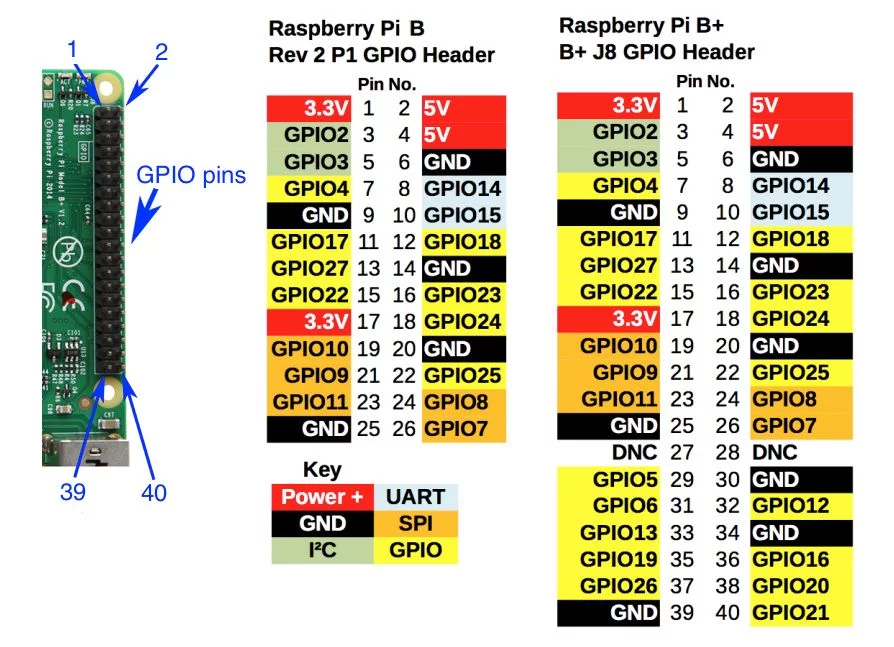
Подключаем диод и датчик движения к нужным GPIO нодам, камеру к USB.
Нумерация нодов
У меня это выглядит вот так:
Теперь соберем все куски логики, описанные ранее и получим "Умную камеру" с управлением через Telegram-бота.
Работу сенсора будем запускать в отдельном потоке, поэтому импортируем необходимую библиотеку. Создаем переменную для хранения расширения видео. Логирование из библиотеки logging не влияет на работу "Умной камеры", поэтому не будем заострять на этом внимание. Создаем переменные для флагов о работе сенсора и необходимости отправки уведомлений. Создаем переменную для хранения последнего chat_id, зачем это - расскажу позже. Переменная для хранения клавиатуры нужна, чтобы можно было повторно отправлять нужную клавиатуру. Дальше идет знакомый нам код по инициализации библиотеки pygame и Telegram-бота. Методы setup и destroy нам уже знакомы, метод логирования можно проигнорировать. В методе start проверяем user_id, если пользователь - мы, то отправляем актуальную клавиатуру. В методе sendCapture определяем filename, создаем изображение с камеры и отправляем по chat_id. Метод get_capture нужен для отправки изображения и клавиатуры с актуальными коммандами. Метод sendVideo отвечает за отправку последнего записанного видео. В методе captureVideo определяем filename и в систему отправляем запрос на запись видео с помощью утилиты ffmpeg. Метод get_video служит для отправки видео с отправкой промежуточных статусов.
Дальше рассмотрим ключевой метод sensorJob: здесь в бесконечном цикле считываем сигнал с датчика движения, выводим его на диод и при наличии сигнала сразу отправляем фото и включаем запись видео. Когда работа цикла завершается - отправляем сообщение об отключении датчика движения и актуальную клавиатуру. Так как метод sensorJob работает из потока - здесь нам и понадобится переменная last_chat_id. В методе start_sensor запоминаем сhat_id, устанавливаем флаг работы датчика движения, запускаем поток с методом sensorJob и отправляем статус и актуальную клавиатуру. В методе stop_sensor чистим last_chat_id, устанавливаем флаг работы датчика движения в ложное состояние, отключаем диод и отправляем актуальную клавиатуру. В методах mute/unmute_notifications переключаем в соответствующее положение флаг и отправляем статус и актуальную клавиатуру. На этом логика "Умной камеры" на текущий момент заканчивается. Теперь посмотрим на "Умную камеру" в действии.
Работа "Умной камеры"
Обратите внимание на время начала записи и получения фото и видео - оно очень большое для реальных кейсов, больше 5 минут. Это связано с параметрами в bot.pooling в методе main, а именно с параметром interval. Если оставить его по-умолчанию, то задержка будет минимальна и, как минимум, фото будет приходить практически моментально, но тогда возможны сбои из-за "Connection timeout" в работе Telegram-клиента и надо как-то обрабатывать это дополнительно.
Узкие места и возможные решения
Необходима быстрая флешка, чтобы успевать сохранять видео;
Желательно запись видео инициировать из Python напрямую, например, через библиотеку pyffmpeg, чтобы уменьшить время на инициализацию библиотеки при каждой записи видео;
Хорошая камера, чтобы можно было рязглядеть нарушителя;
Наличие быстрого интернета для более быстрого получения актуального видео.
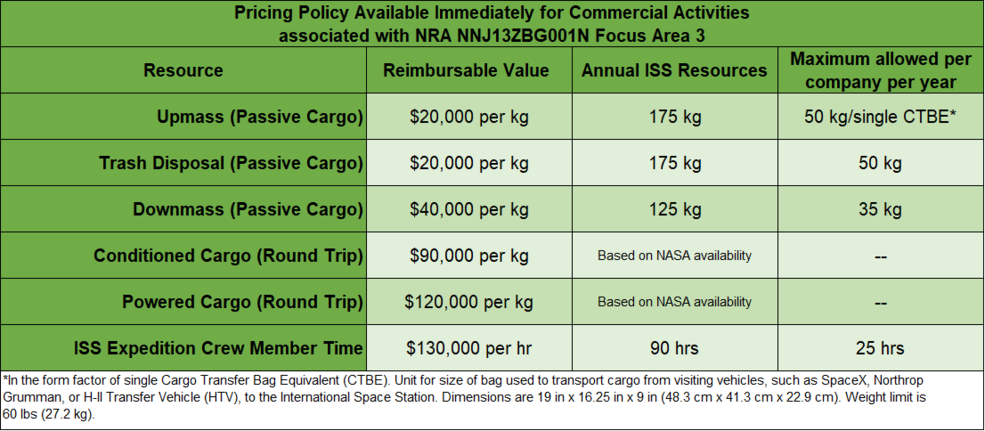
НАСА повысило цены на коммерческую доставку грузов на Международную космическую станцию. Стоимость доставки 1 кг груза выросла почти в семь раз — с $3 тысяч до $20 тысяч. Цена обратной доставки с МКС составит вместо нынешних $6 тысяч за 1 кг $40 тысяч.
Как объяснили в НАСА, после установки прошлых цен в июне 2019 года «наблюдался рост спроса на коммерческую и маркетинговую деятельность как со стороны традиционных аэрокосмических компаний, так и со стороны новых». Прежняя ценовая политика, по словам представителей агентства, «не отражала в полной мере стоимость использования ресурсов НАСА, а была направлена на стимулирование рынка».
Теперь агентство пересмотрит ценовую политику для частных миссий на МКС.
В этом году станцию должны посетить инвесторы из США и Канады Ларри Коннор и Марк Пати, а также бизнесмен из Израиля Эйтан Стиббе. Частный экипаж направится на МКС на корабле Crew Dragon от SpaceX. Длительность миссии составит восемь дней. Каждый турист заплатит по $55 млн.
Ранее НАСА объявило, что планирует получить место для своего астронавта при следующем запуске «Союза» на МКС в апреле. Агентство хочет обеспечить присутствие США на станции в случае, если возникнут задержки в графике запуска коммерческой миссии. Миссия Crew-2 запланирована на 20 апреля.
Первая коммерческая миссия НАСА и SpaceX Crew-1 к МКС была запущена 16 ноября.
Разбираем внутреннее устройство старого промышленного калькулятора Rockwell 920 и на аппаратно-программном уровне пытаемся отследить неисправность, из-за которой он не работает. Процесс оказывается не столь простым, как можно было предположить, и на пути возникает ряд «странностей».
Rockwell 920/3
У меня есть калькулятор Rockwell 920/3.
Родом этот внушительный зверь, где-то года так из 1975. Он программируемый, а его полностью расширенная версия может иметь 996 программных шагов. Помимо этого, он оснащен устройством чтения/записи магнитных карт и шестнадцатизначным дисплеем. Этот калькулятор может сохранять на картах как данные, так и программы. Конкретно первый оказавшийся у меня экземпляр использовался для ведения платежных ведомостей в крупной английской каталожной компании.
Достался он мне с нерабочим кардридером, что было досадно, ведь у меня как раз имелось несколько подходящих карт с программами, которые я давно уже хотел извлечь. Решилась эта проблема просто. Увидев в продаже другой такой же калькулятор, я с радостью его купил и просто переставил кардридер. В результате все прекрасно заработало, и я даже снял небольшое видео:
Программы я напечатал и как-нибудь займусь их транскрибированием. Позже в продаже появился третий аналогичный калькулятор, который я также без сомнений приобрел. В результате это оказалась модель 920/2, а не 920/3, что означало меньший объем памяти. Внутренне эти машины оснащены одинаковой материнской платой, снаряженной скромным ОЗУ. Вот одна из этих плат с моими подключениями для отладки:
Исходя из его архитектуры, этот калькулятор можно поистине назвать одноплатным компьютером. Здесь есть процессор, ОЗУ и ПЗУ вместе с интерфейсом ввода/вывода общего назначения (GPIO). В качестве процессора установлен Rockwell PPS-4, четырехбитный чип, использовавшийся для небольшого числа устройств в 70-х годах, в частности калькуляторов и машин для игры в pinball. Работает он от нестандартного, по крайней мере на сегодня, источника питания -17В. Логика здесь отрицательная, следовательно ноль – это -17В, а единица – это 0В. В результате подключить такое устройство к логическому анализатору, да даже к осциллографу, оказалось проблематичным. Обычно логический анализатор позволяет отлаживать напряжения от нуля до +5В, где земля — это логический нуль, а +5В — логическая единица (прим. переводчика). Частота процессора тоже далека от современных показателей и составляет всего 200 кГц. Второй и третий экземпляр были в нерабочем состоянии, так что я взялся за их починку. И поскольку было бы кстати понять, что именно делает код, я решил инструментировать сигналы шины и проследить его выполнение, а также, если повезет, создать дамп ПЗУ.
Я мог бы выпаять эти ПЗУ (все из которых находятся в нестандартном 42-контактном корпусе QIP с шахматным порядком выводов), но тогда мне бы понадобилось устройство для их дампа, работающее также от -17В. Позже я, может, и соберу такое, если мне не удастся сделать дамп всего ПЗУ с помощью перехвата шины на работающем калькуляторе. Думаю, что если прогнать его по всем функциям при подключенном сканере, то должно получиться постепенно перехватить содержимое ПЗУ. Как минимум выполняемые его части. Я собрал тестовую схему, чтобы оценить, заработает ли вообще хоть что-то при -17В. Результат на этом видео:
Заработала схема отлично, поэтому я продолжил и собрал плату с достаточным количеством входов для перехвата нужных сигналов и анализа выполнения потока кода. Оказалось, что простой (и дешевый, что будет на руку, если при -17В я вдруг допущу ошибку) микроконтроллер STM32F103C8 имеет достаточно GPIO для обработки адресной шины (на языке PPS-4 это A/B), шины данных (или I/D) и сигналов управления шинами.
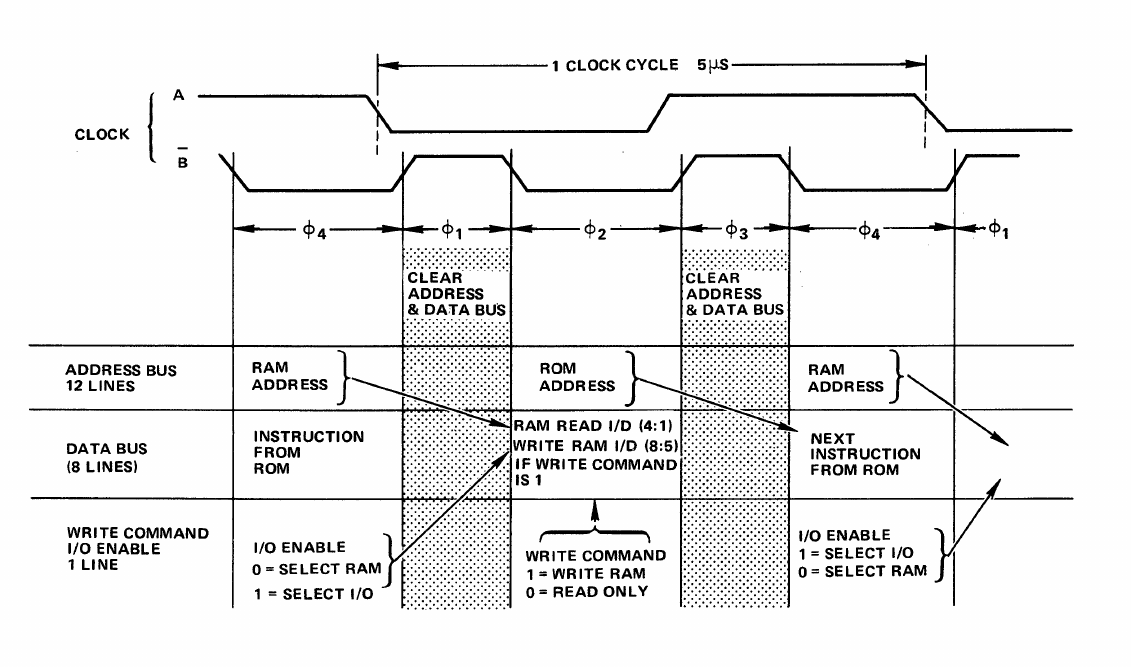
Техническое описание PPS-4 доступно в интернете, и мне удалось найти образец кода в его патенте. Теперь я могу протестировать свой дизассемблер и любой объектный код на работоспособность. При рассмотрении шина процессора может вызвать пугающие ощущения, по крайней мере в сравнении с Z80. Это мультиплексированная, чередующаяся двухфазная штуковина. В ней присутствует четыре фазы тактов (моя терминология). Адреса ПЗУ поступают на адресную шину в фазе 1, в то время как данные ОЗУ или ввода/вывода находятся на шине данных. Затем в фазе 3 адрес ОЗУ или ввода/вывода передается на адресную шину, а ПЗУ на шину данных. Для лучшего понимания стоит взглянуть на схему из технической документации:
Если поразглядывать ее минут 10, то постепенно все становится понятно. Да, у процессора есть два тактовых входа, работающих на двух разных частотах и несколько отличающихся по фазам. Здесь есть специальная микросхема, генерирующая эти тактовые сигналы. На самом деле выпаивание микросхем ПЗУ для считывания является наиболее простой частью всего процесса. После выпаивания нужно сделать их дамп, используя описанную схему шин, и при этом не забывая, что логические уровни сигналов равны 0В и -17В.
Из полезного в данной схеме шин можно выделить пару фаз «освобождения шины». Это позволяет легко управлять фазами при трассировке кода. Можно было подумать, что все просто, но PPS-4 ставит еще одну подножку, инвертируя частоту B и некоторые (только некоторые) данные на шине до их использования. Иногда он инвертирует полубайт, иногда байт. В данном случае уцепиться можно за пустую фазу.
После некоторых простых тестов с микроконтроллером я получил скетч, который фиксирует сигналы шины настолько быстро, насколько это возможно. Я добавил задержку перед запуском в несколько тактов от выхода сигнала сброса в неактивное состояние, чтобы можно было перемещать окно захваченных сигналов шины с целью захвата начального выполнения кода. Надеюсь, что это поможет понять, почему плата не работает.
Обратите внимание на адрес 3 во втором блоке – это адрес ПЗУ. Затем в четвертом блоке данные из ПЗУ помещаются на шину. Содержимое шины данных при представлении адреса ПЗУ — это данные ОЗУ или ввода-вывода из предыдущей инструкции ввода-вывода или чтения.
Перехваченные данные копируются в текстовые файлы по одному для каждого «окна» предварительной задержки. Серия скриптов извлекает информацию ПЗУ. Это скудные данные, поскольку захватываются, очевидно, только адреса ПЗУ, которые выполняются, или к которым обращаются инструкции. Одна из основных последовательностей – это код запуска.
Процессор после сброса начинает с адреса 000, так что у нас есть точка для начала трассировки. Следующая инструкция – это переход (t: transfer) из адреса 000 к адресу 001. Это несколько странно, но похоже на правду. Затем идет переход из 001 к 002. Опять же, странно, но может процессору требуется произвести какие-то настройки в первых циклах инструкций, либо счетчик программы таким образом «завершается», или что-то в том духе? Я нашел в патенте какой-то код PPS-4, который начинается так:
Здесь мы видим такую же инструкцию перехода, что еще раз подтверждает наличие конкретной точки для трассировки. Тем не менее перехода из 001 к 002здесь уже нет. Мне не удалось найти объяснения, откуда они вообще взялись.
Инструкция IOL отправляет команду микросхемам GPIO. Они не отображаются в память или I/O, вместо чего в них заложены номера устройств. IOL ox1E отправляет команду oxE устройству 1. Так происходит настройка сигналов сканирования клавиатуры/дисплея. Я отследил достаточно сигналов на печатной плате, чтобы определить номера устройств для микросхем GPIO. До этого момента я называл микросхему PPS-4 процессором, но это не совсем верно. У этой микросхемы действительно есть порты ввода/вывода. Это не порты GPIO, поскольку являются фиксированными вводами или выводами, поэтому в некотором смысле данная микросхема больше походит на микроконтроллер. Порт вывода в 920-м используется для управления демультиплексором, который контролирует каждую цифру дисплея. Вводы же используются для распознавания матрицы клавиатуры (сигналы сканирования для клавиатуры – это те же сигналы сканирования, которые используются для управления цифрами дисплея).
Набор инструкций
Я знаком с 8-битными процессорами Z80 и 6502, а также с набором инструкций ARM. Мне также доводилось программировать на ассемблере для PIC, Z8, 6301, 8086, 8051, 4-битных микроконтроллеров и т.д. Но при этом некоторые из инструкций PPS-4 меня удивили. Такое ощущение, что они были придуманы до того, как люди сформулировали устойчивые правила. Например, инструкция load immediate:
Четырехбитное содержимое, поле immediate field I(4:1) инструкции, помещается в накопитель (см. примечание ниже)
Хорошо, это 4-битный вариант, и промежуточным значением является полубайт в коде операции. Тогда обратим внимание на правую часть, где идет ссылка на примечание 3.
Инструкции ADI, LD, EX, EXD, LDI, LB и LBL содержат в своих immediate field (мгновенных полях) закодированное числовое значение. Это числовое значение должно присутствовать на шине в виде дополнения. Все «мгновенные» поля, которые инвертируются, показываются в квадратных скобках
Например: инструкцияADI 1, которую программист пишет, желая добавить единицу к значению в накопителе, преобразуется в 6E(16)=0110[1110]. В скобках указано двоичное значение в том виде, в каком оно представлено на шине данных.
Если программист использует Rockwell Assembler, ему не нужно вручную определять подходящее инвертированное значение, так как ассемблер делает это сам.
Хорошо, для этих инструкций (не всех инструкций) полубайт, являющийся «мгновенными» данными, инвертируется в ПЗУ и, следовательно, на шине. Мда, несколько странно, но дизассемблер или ассемблер это обработает. Далее мы замечаем, что в четвертом блоке слева есть ссылка на еще одно примечание. На этот раз ссылка ведет сюда:
Будет выполнено только первое вхождение инструкции LB или LBL . Программа будет игнорировать оставшиеся LB или LBL и выполнять следующую действительную инструкцию. Внутри подпрограмм инструкция LB должна использоваться с осторожностью, потому что содержимое SB было изменено.
Так, теперь наблюдается некоторая странность. Если загрузить накопитель с 6, а затем с 4, то в итоге его значение будет 6. Когда я столкнулся с этим впервые, то удивился, но после изучения кода решил, что в этом есть смысл. Если вам нужно ввести программу с различными параметрами, то вы можете сделать следующее:
Enter6 LDI 6
Enter7 LDI 7
Enter 8 LDI 8
* Выполнить действие с A
RTN
Если перейти к Enter6, то накопитель загрузится с 6, последующие загрузки игнорируются, и вы выполняете действия с 6. Если перейти к Enter7, тогда накопитель загружается с 7, и следующая загрузка игнорируется, а вы выполняете нужные действия с 8. Я понимаю, в чем здесь польза.
Вот инструкция:
48 последовательных адресов на странице 3 ПЗУ содержат данные указателей, которые определяют адреса входа подпрограмм. Эти адреса входа ограничены страницами с 4 по 7. Данная инструкция TM будет сохранять адрес следующего слова ПЗУ в регистр SA после загрузки исходного содержимого SA в SB. После этого происходит переход к одному из адресов входа подпрограмм. Эта инструкция занимает в ПЗУ одно слово, но для выполнения требует два цикла.
Она показывает использование таблиц данных в ПЗУ на уровне инструкций.
Что дальше?
Теперь мне нужно отследить выполнение кода вплоть до цикла, в котором оно заканчивается. Может, тогда мне удастся понять, что здесь не так. Мне также нужно нарисовать схему. Плотность заполнения печатных плат невысока, так что это не должно оказаться затруднительным.
Расширение памяти
Небольшое отступление.
Модель 920/2 содержит одну подключаемую плату расширения памяти, а в 920/3 их две:
Удивляет, что на плате ОЗУ в модели 920/2 присутствует четыре микросхемы, а на платах 920/3 их по 6. Еще один сюрприз в том, что эти две платы микросхем отличаются друг от друга. Мне кажется, что у них разные распиновки разъемов, несмотря на то, что объем памяти на них одинаковый. Поэтому вместо того, чтобы задействовать одну печатную плату для обеих конфигураций расширения памяти (часть, заполняющая плату 920/2) я использовал три разные.
От переводчика: Как видно, автор реверс-инжиниринга данного калькулятора делает много интересных открытий. Мы будем и дальше следить за его публикациями, и как только он напишет что-то новое по данной теме, обязательно опубликуем.
Компания Krebsonsecurity сообщила, что за несколько прошедших недель было взломано четыре самых старых и популярных русскоязычных форумов для киберпреступников. В двух случаях взломщики получили доступ к базам данных пользователей с адресами электронных почт и хешированными паролями. Участники форумов переживают, что их личности могут быть идентифицированы путём сопоставления данных через виртуальную версию Rosetta Stone.
Rosetta Stone — программное обеспечение, которое в своей работе использует комбинации из текста, изображений и звука для изучения иностранного языка через интуитивный подход. Похожий метод может быть использован для сопоставления анонимных аккаунтов на нелегальных форумах с аккаунтами этих же людей, но уже вне закрытого комьюнити.
По данным Krebsonsecurity, ссылки на украденную базу данных форума Mazafaka появились 3 и 4 марта. Во вторник появились данные тысяч пользователей с адресами электронной почты и зашифрованными паролями. Форум Mazafaka (Maza, MFclub) существует больше десяти лет и за это время, там были замечены наиболее опытные и известные русские киберпреступники.
Сотрудники Krebsonsecurity обнаружили 35-страничный документ в формате .pdf с приватным ключом шифрования, который предположительно использовали администраторы Maza. В базе данных также есть номера ICQ, где до появления Jabber и Telegram происходило общение пользователей.
По мнению сотрудников компании, именно номера ICQ представляют наибольший интерес среди всех утёкших данных, так как они часто привязаны к другим учётным записям, что позволит быстро сопоставить различные аккаунты с конкретным человеком.
Компания Intel 471, которая занимается цифровой разведкой, считает, что украденная база данных настоящая. Она обнаружила, что в базе было более 3000 строк с информацией о пользователях. Кроме этого, на самом форуме появилась переадресация на страницу с предупреждением об утечке. Представители Intel 471 также сопоставили украденные данные с собственными исследованиями и обнаружили частичную корреляцию, что также подтвердило достоверность опубликованной информации.
Атака на форум Maza произошла через несколько недель после того, как другой крупный русскоязычный ресурс пострадал от действий взломщиков. 20 января администратор сайта Verified сообщил, что регистратор доменов был взломан и домен форума перенаправляет посетителей на сервер, контролируемый хакерами.
В своей заметке администратор форума отметил, что биткоин-кошелёк был взломан, но на нём не было крупной суммы. После этого инцидента он предположил, что данные пользователей теоретически тоже могли пострадать. После этого все данные были сброшены, а пользователям предложили использовать новые. Немного позднее администратор подтвердил, что утечка всё-таки произошла, после чего все пароли были принудительно аннулированы. Форум взломали через регистратора доменов, подменили серверы доменных имён и трафик перенаправили через сниффер.
15 февраля руководство Verified опубликовало письмо от взломщиков, в котором они обвинили администраторов форума в некомпетентности из-за того, что на серверах хранились данные пользователей, среди которых — куки-файлы, рефереры (приглашающие аккаунты), ip-адреса первой регистрации, аналитику входов и т.д.
Другие источники рассказали, что были украдены десятки тысяч личных сообщений между участниками форума, информация о биткоин-депозитах и о выводе средств, а также частные контакты Jabber.
Третьим пострадавшим стал форум Expoit, где по данным Intel 471, администратор 1 марта рассказал о возможной угрозе из-за скомпрометированных данных прокси-сервера, который использовали для защиты от DDoS-атак. Администратор форума заявил, что 27 февраля 2021 года система мониторинга обнаружила признаки несанкционированного доступа к серверу и попытку сброса сетевого трафика.
Вечером, 4 марта, Intel 471 сообщила, что обнаружила проблемы у четвёртого форума по схожей тематике. В феврале руководитель Crdclub, рассказал, что одна из учётных записей администрации была взломана и через неё пользователей вынуждали воспользоваться системой денежных переводов, за которую якобы поручились владельцы ресурса. Crdclub пообещал возместить ущерб обманутым пользователям.
Сотрудники Krebsonsecurity нашли сообщения участников форумов, в которых они высказывали опасения, что подобные действия выглядят как запланированная крупномасштабная операция правительственных органов.
Построение маршрутов..., люди регулярно этим пользуются, особенно для автомобильных маршрутов, в навигаторах.
Решений, для построения маршрута тоже немало, в том числе существует GraphHopper, который умеет строить маршруты, и для автомобилей, и для пешеходов, и даже для пешего туризма, - подойдёт, наверно, в 99% случаев.
Далее речь пойдёт том, что делать в остальных ситуациях, точнее о моём опыте использования GraphHopper, когда существующее решение не подходило. Требовалось учитывать дополнительные ограничения: строить пешеходные маршруты для людей с ограниченными возможностями. Не будет ни каких значимых особенностей реализации именно этой задачи. Обобщённо.
Будет описано, как создать на основе библиотеки GraphHopper свой веб–сервис, который, по координатам начала и окончания пути, вернёт массив координат маршрута.
Пример приложения, со всеми необходимыми для запуска заглушками, можно найти в моём репозитории на GitHub.
GraphHopper - механизм маршрутизации, написанный на Java. Выпущен под лицензией Apache, и может быть встроен в продукты с закрытым исходным кодом.
Статьи подобного толка на хабре встречаются, например, Гуляем по городу с умом, но в ней не приводится деталей реализации, к сожалению, и… ну и всё.
Разработчики GraphHopper ждут наших с вами комментариев, так как они ввели новую функцию, позволяющую даже людям без знания программирования или Java изменять модель построения маршрутов.
Наверно, эта новая функция покроет ещё 0.99% возможных ситуаций, вероятно подойдёт и для Вашей задачи, знания Java не потребуются, и вообще проблем не возникнет. Я расскажу, а своём опыте создания правил построения маршрутов, когда этой функции не было, а до её создания оставалось 2 года.
Понадобятся знания Java.
Считаю, что публикация всё ещё актуальна, ибо:
ничто не может сравниться по гибкости и податливости с возможностью изменения исходного кода
GraphHopper работает на данных OSM, а Вам могут потребоваться правила, не предусмотренные OSM. Например, вы можете строить маршруты по закрытым дорогам, их закрытость очевидна из OSM. Вот только надо учесть цветовую дифференциации штанов. А ездить по зимникам в летнее время года я крайне не рекомендую, здесь может потребоваться проверка даты.
Решение
В статье используется версия библиотеки GraphHopper 0.10.0, актуальная на момент создания приложения.
Исходный код GraphHopper, в том числе этой библиотеки, выложен на github. Так же там есть некоторая документация, например How to create new routing profile aka a new FlagEncoder? которая, как бы намекает, что нам необходимо создавать совой FlagEncoder. Уже существующие FlagEncoder, находятся в пакете com.graphhopper.routing.util, нас особо интересуют FootFlagEncoder, т.к. он занимается построением именно пешеходных маршрутов, и AbstractFlagEncoder, как его родительский класс.
Имеет смысл, либо унаследовать свой FlagEncoder от AbstractFlagEncoder, частично повторив FootFlagEncoder и внеся изменения куда следует, либо сразу от FootFlagEncoder, что избавит от дублирования кода. Мне больше подходит наследование от AbstractFlagEncoder и копирование кода FootFlagEncoder, ибо требуется доступ к полям, которые в FootFlagEncoder приватны.
Магия построения графа путей сосредоточена в методе acceptWay, который принимает поочерёдно объекты дорог - ReaderWay и решает пригодна эта дорога для прохода/проезда или нет. Определение пригодности это уже прерогатива FlagEncoder. Я передаю во FlagEncoder список дорог, по которым ходить нельзя. Необходимо чтобы метод acceptWay, натолкнувшись на эту дорогу сказал своё твёрдое нет – вернув 0.
Список назовём restricted, и хранить он будет id объекта way из OSM.
public class MyFlagEncoder {
…
private List<Long> restricted;
@Override
public long acceptWay(ReaderWay way) {
if (restricted.contains(way.getId()))
return 0;
…
}
…
}
У нас запретительный подход, если объект оказался в списке, то выполнение прерываем, вернув 0.
Предварительная подготовка данных
Написав FlagEncoder, и переделав в нём всё что хотели, можно приступать к построению графа маршрутов.
GraphHopperStorage graph = hopper.getGraphHopperStorage();
LocationIndex index = new LocationIndexTree(graph, new RAMDirectory());
index.prepareIndex();
Для построения маршрута нам потребуются объекты трёх классов: GraphHopperStorage, FlagEncoder, LocationIndex.
Используем их следующим образом, результатом будет List<Double[]>:
QueryResult fromQR = index.findClosest(fromLon, fromLat, EdgeFilter.ALL_EDGES);
QueryResult toQR = index.findClosest(toLon, toLat, EdgeFilter.ALL_EDGES);
QueryGraph queryGraph = new QueryGraph(graph);
// Получить координаты пути
queryGraph.lookup(fromQR, toQR);
Dijkstra dij = new Dijkstra(queryGraph, new FastestWeighting(encoder), TraversalMode.NODE_BASED);
Path path = dij.calcPath(fromQR.getClosestNode(), toQR.getClosestNode());
PointList pl = path.calcPoints();
return pl.toGeoJson();
Заключение
Реализация получилась примитивной т.к. основана на проверке (в методе acceptWay) попадания объекта в заранее составленный (или полученный всеми правдами и неправдами) список:
if (restricted.contains(way.getId()))
return 0;
Гораздо правильнее было сделать что-то подобное коду, основанному на проверке значений тегов из OSM, как здесь:
if (way.hasTag("foot", intendedValues)) {
return acceptBit;
}
Если у Вас есть возможность, для своей задачи, использовать второй вариант, основанный на проверке тегов – лучше предпочесть его. Это ни как не помешает подмешать туда и дополнительную логику, не вписывающуюся в этот подход.
Сегодня в твиттере NASA появилось сообщение о начале движения марсохода «Настойчивость» по Красной Планете. Ровер проехал несколько метров для проверки ходовой части. Все закончилось хорошо, системы работают как им и положено. Кроме того, марсоход сфотографировал собственные следы. Общее время заезда — 33 минуты, за это время марсоход преодолел 6,5 метра.
Насколько можно понять, с ровером все хорошо. Но, если помните, марсоход опустился на поверхность при помощи «Небесного крана». Система, которая обеспечила мягкую посадку при помощи тросов, в определенный момент отделилась от ровера, и улетела, использовав оставшиеся запасы топлива. Но куда именно она отправилась и насколько далеко смогла удалиться? Давайте подсчитаем сами.
НАСА уже выкладывало фотографию упавшей на поверхность Марса платформы. Агентству известно точное ее местоположение. Но ведь круто же — подсчитать, на какое расстояние удалилась платформа, имея в своем распоряжении изначальные данные о посадке и видео, отправленное ровером.
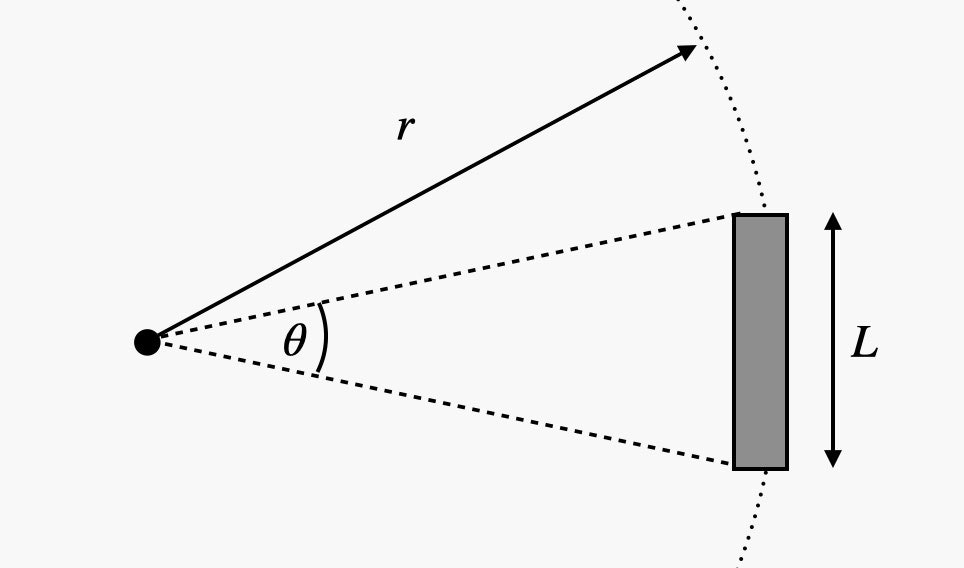
Для расчетов будем использовать угловой размер посадочной платформы.
На Хабре вряд ли имеет смысл рассказывать о том, что такое угловой размер, поэтому сразу приступим к расчетам.
Вычисление углового размера производится очень просто, вот формула.
Зачем нам угловой размер? Ну, если мы его знаем, плюс нам известен реальный размер, то мы можем с легкостью определить расстояние до объекта — это будет r. Идеальный вариант вычислений — использовать просто ровный колышек, с ним проводить вычисления легче всего. Но поскольку у нас не колышек, а платформа, то будет чуть сложнее. Но все же проблем в ходе вычислений не должно возникнуть.
Первое, что мне сделать — определить поле зрения камеры марсохода, направленной вверх.Точных характеристик нет, поэтому прикинем приблизительно. Вот платформа с марсоходом, подвешенным на тросе перед приземлением.
Согласно НАСА, длина троса составляет 6,4 метра — так что мы знаем показатель ® на этой фотографии. Кроме того, мы можем определить и длину посадочной ступени. Если взять ее ширину, это 2,69 метра, то реальный угловой размер, видимый с ровера, составляет 0,42 радиана. Давайте воспользуемся этой цифрой чтобы установить ширину всего кадра видео с угловым полем зрения (FOV) 0,627 радиана (это будет 35,9 градуса).
Все это крайне важно для дальнейших расчетов. С этими данными можно измерить угловой размер посадочной платформы и рассчитать расстояние до марсохода. Для того, чтобы сделать это, можно воспользоваться специальным инструментов, Tracker Video Analysis. Он дает возможность анализировать размеры объектов на видео. Строим вот такой график.
Можно было бы подумать, что график будет параболическим, что показывало бы постоянное ускорение платформы. Но, похоже, ничего такого не было — если платформа и ускорялась, то минимально. Вычисляем скорость — и получаем около 8,2 м/с.
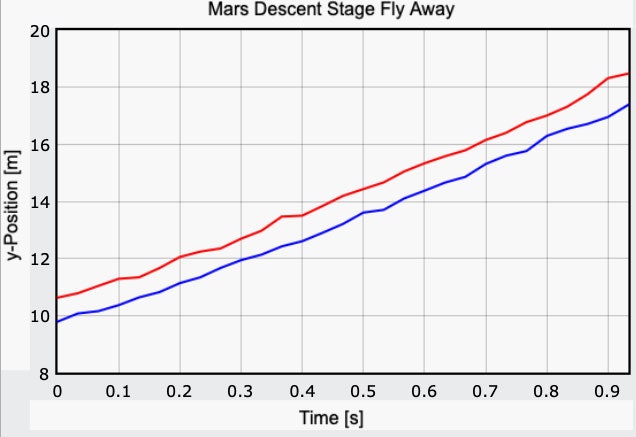
Стоп! Ведь у нас есть еще кое-что. Дело в том, что посадочная платформа уходит под углом, о чем уже не раз говорилось. И в этом есть смысл — если бы платформа просто взлетела наверх, то после использования всего горючего вся эта конструкция рухнула бы потом вниз — прямо на марсоход. Видео дает возможность определить угол наклона. Здесь помогает вот такой график и формула.
Используя известно расстояние до двигателей, а также видимое расстояние, получаем угол наклона в 52 градуса от вертикали. Будем надеяться, что все верно, поскольку этот показатель нужен для дальнейших расчетов.
Движение платформы
Теперь мы готовы к решению важной физической задачи. Звучит она следующим образом.
Посадочный модуль на Марсе выполняет маневр отлета, чтобы уйти на безопасное расстояние от марсохода Perseverance. Модуль запускает движки для достижения скорости в 8,2 м / с при угле пуска 52 градуса от вертикали. Если у Марса гравитационное поле 3,7 Н / кг, как далеко от марсохода он упадет? Вы можете предположить, что сопротивление воздуха незначительно.
Формулировка задачи есть. Теперь нужен ответ. Ключевой момент здесь в том, что движение в горизонтальном направлении (назовем его х-направление) выполняется с постоянной скоростью. Что касается скорости спуска (у-направление), то здесь у нас есть ускорение — g (где g = 3.7 Н/кг), вызванное силой тяжести. Поскольку она постоянна и действует лишь по вертикали, мы можем разделить задачу на две — собственно, движение в горизонтальной плоскости и движение в вертикальной. Эти два элемента одной задачи независимы, их связывает лишь время.
Давайте начнем с движения по вертикали.
Для выполнения нужных вычислений используем косинус. Нам поможет вот такое уравнение для движения с постоянным ускорением.
Начальное и конечное положение равны нулю (это поверхность). Вот выражение, помогающее определить время.
Если мы используем y0 с расстоянием в 6,4 м (что реалистично), придется использовать квадратное уравнение. Это не так уж и сложно. Но мы можем использовать время и при горизонтальном движении спускаемого аппарата. Вот уравнение движения по горизонтали.
Скорость зависит от синуса угла. Теперь можно просто оставить х0 равным нулю и заменить время приведенным выше выражением. В итоге мы получаем вот что.
Подставляя наши значения, получаем, что расстояние, на которое удалилась платформа — 17,6 метров. Но нет, это вовсе не так. Мы знаем это благодаря фотографиям, опубликованным НАСА. Согласно снимкам, платформа опустилась где-то на расстоянии около километра от ровера. Меняем условие задачи.
Для того, чтобы не представлять опасность для ровера, платформа должна улететь на расстояние около 1 км. Скорость спуска — 8,2 м/с с углом наклона около 52 градусов. На какую высоту поднимется платформа, прежде, чем отключатся двигатели? Используем вот эту формулу.
Теперь используем время для решения очередного уравнения.
Если провести расчеты, получается, что показатель для старта по вертикали — 43 км. Почему так? Дело в том, что платформа ускорилась при запуске движков.
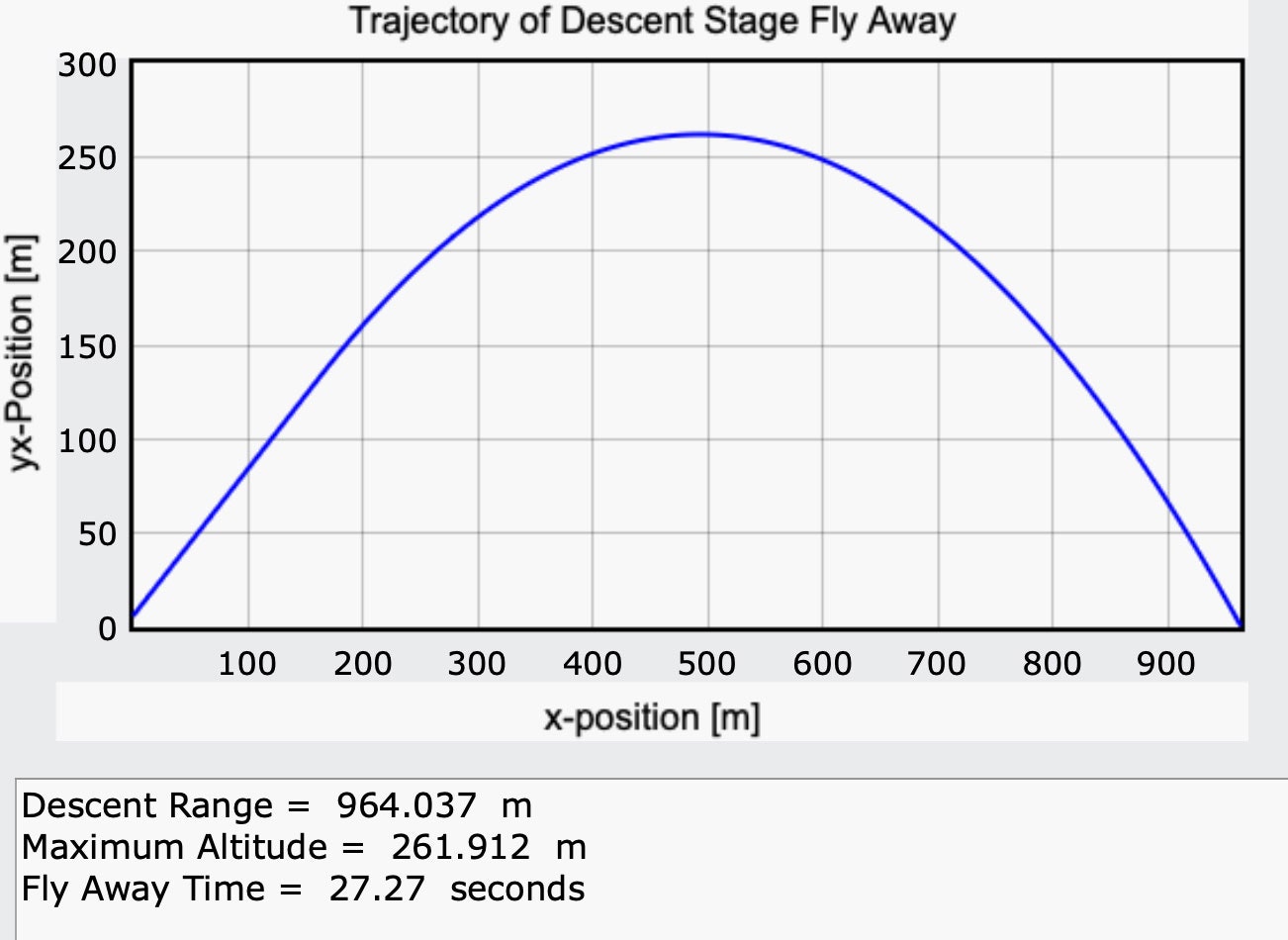
Давайте попробуем провести вычисления на Python. Расчет состоит из двух частей. Во-первых, в течение определенного времени ракета будет лететь с постоянным ускорением в 52 градуса. Нужно подорать лишь время и ускорение, после чего вычислить падение тела на поверхность Марса. Вот код программы, которая производит все вычисления.
GlowScript 3.0 VPython
v0=8.2
g=3.7
theta=52*pi/180
x=1000
y0=.5*g*(x/(v0*sin(theta)))**2-x*cos(theta)/sin(theta)
tgraph=graph(width=550, height=350, xtitle="x-position [m]", ytitle="yx-Position [m]", title="Trajectory of Descent Stage Fly Away")
f1=gcurve(color=color.blue)
#starting position
x=0
y=6.4
#rocket firing time
tf=7
#rocket acceleration
a=6
#initial velocity
vy=v0*cos(theta)
vx=v0*sin(theta)
#time
t=0
dt=0.01
#rockets firing
while t<tf:
vy=vy+a*cos(theta)*dt
vx=vx+a*sin(theta)*dt
y=y+vy*dt
x=x+vx*dt
t=t+dt
f1.plot(x,y)
#to record max height
ymax=0
#projectile motion
while y>=0:
vy=vy-g*dt
y=y+vy*dt
x=x+vx*dt
if vy<0.1:
ymax=y
t=t+dt
f1.plot(x,y)
print("Descent Range = ",x," m")
print("Maximum Altitude = ",ymax," m")
print("Fly Away Time = ",t, " seconds")
Для вычислений берем ускорение платформы в 6 м/с2 и время работы движков в 7 секунд. И получаем уже нормальное значение в 964 метра, что уже очень похоже на правду. Наконец-то.
Полагаю, ни для кого не секрет, что в разработке игр участвует очень много специалистов, а не только программисты. Выпуск игры невозможен без художников, моделлеров, VFX-художников, и, конечно, гейм-дизайнеров. Кстати о последних. Мы их очень любим, но они часто ломают ресурсы. Не то чтобы они хотят это делать, но из-за особенностей работы им нужно делать много мелких правок, и шанс накосячить выше. И ведь множество ошибок — это тривиальные опечатки, недописанная или, наоборот, лишняя удалённая строка. Всё это можно исправить не отходя от кассы. Но как это сделать? Прописать в регламенте, что перед коммитом обязательно запустить %my_folder%/scripts/mega_checker? Мы проверяли — не работает. Человек — существо сложное и забывчивое. А проверять ресурсы хочется.
Но мы нашли выход — теперь нельзя закоммитить в репозиторий без тестов. По крайней мере незаметно и безнаказанно.
Система тестирования
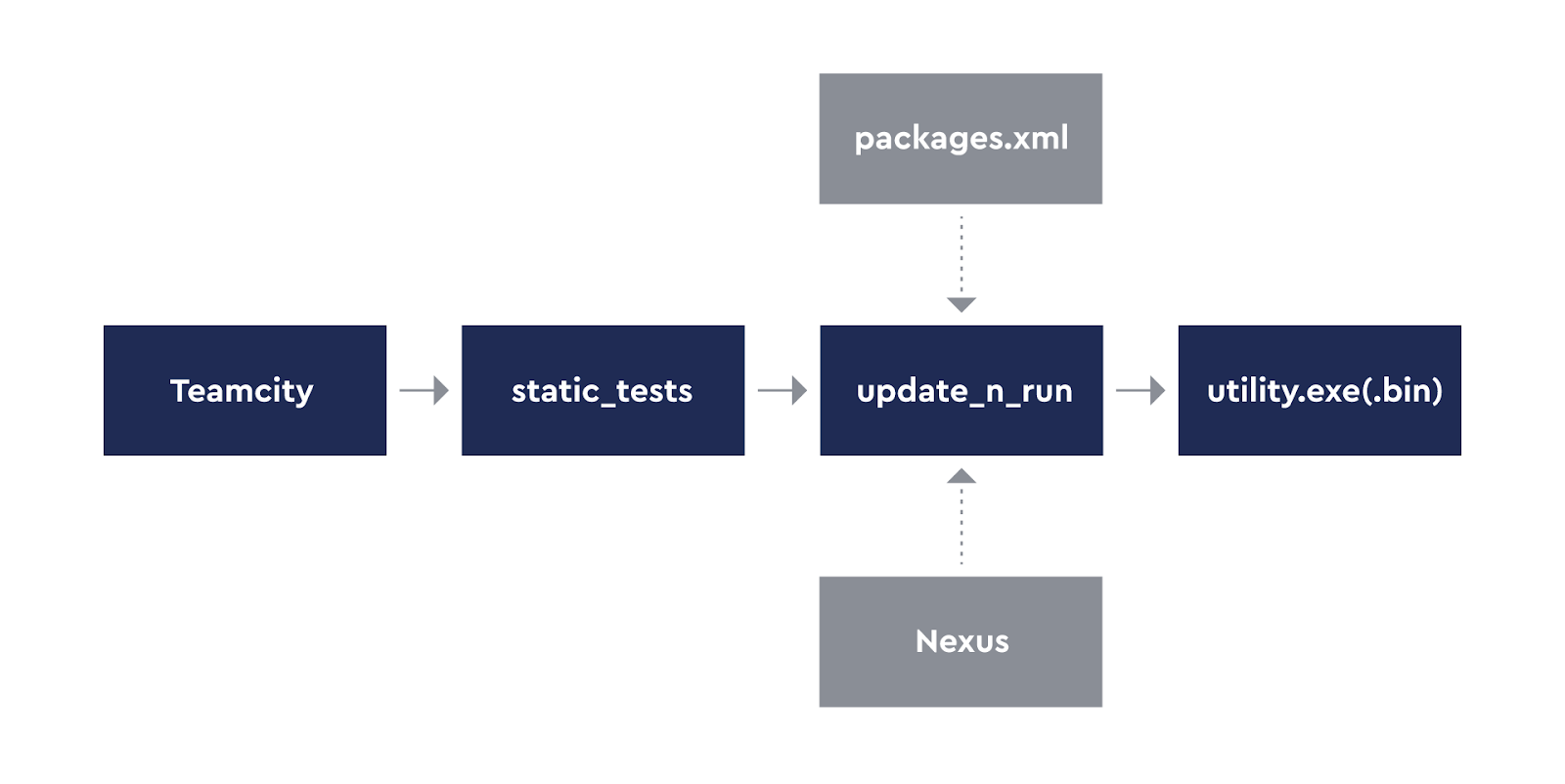
Первое, что нам нужно — это система тестирования. Мы её уже описывали здесь. Напомним, что нужен один и тот же код и для запуска на сервере Ci, и локально, чтобы не было сложности в поддержке. Желательно, чтобы на проекте могли задавать разнообразные параметры для общих тестов, а ещё лучше — расширять собственными. Конечно, конфетка сразу не получилась.
Этап первый — запускать можно, но больно. Что делать с python-кодом ещё понятно, а вот со всевозможными утилитами вроде CppCheck, Bloaty, optipng, нашими внутренними костылями-велосипедами — нет. Для корректного запуска нужны исполняемые файлы для всех платформ, на которых работают наши коллеги (mac, windows и linux). На данном этапе все необходимые бинарные файлы находились в репозитории, а в настройках системы тестов указывался относительный путь к папке с бинарниками.
со стороны проекта нужно хранить в репозитории лишние файлы, так как они нужны на компьютере каждого разработчика. Естественно, репозиторий из-за этого больше.
когда возникает проблема, сложно понять, какая именно версия стоит у проекта, нужная ли структура в папке.
где брать нужные бинарные файлы? Компилировать самому, скачивать в интернете?
Этап второй — наводим порядок в утилитах. А что, если выписать все нужные утилиты и собрать их в одном хранилище? Идея в том, что на сервере находятся уже собранные утилиты для всех нужных платформ, которые ещё и версионируются. У нас уже использовался Nexus Sonatype, поэтому мы пошли в соседний отдел и договорились за файлики. В итоге получилась структура:
Для запуска нужен скрипт, который знает секретный адрес, где лежат бинарники, умеет их скачать, а также запустить в зависимости от платформы с переданными параметрами.
Опуская тонкости реализации
def get_tools_info(project_tools_xml, available_tools_xml):
# Parse available tools at first and feel up dictionary
root = etree.parse(available_tools_xml).getroot()
tools = {}
# Parse xml and find current installed version ...
return tools
def update_tool(tool_info: ToolInfo):
if tool_info.current_version == tool_info.needed_version:
return
if tool_info.needed_version not in tool_info.versions:
raise RuntimeError(f'Tool "{tool_info.tool_id}" has no version "{tool_info.needed_version}"')
if os.path.isdir(tool_info.output_folder):
shutil.rmtree(tool_info.output_folder)
g_server_interface.download(tool_id=tool_info.tool_id, version=tool_info.needed_version,
output_folder=tool_info.output_folder)
def run_tool(tool_info: ToolInfo, tool_args):
system_name = platform.system().lower()
tool_bin = tool_info.exe_infos[system_name].executable
full_path = os.path.join(tool_info.output_folder, tool_bin)
command = [full_path] + tool_args
try:
print(f'Run tool: "{tool_info.tool_id}" with commands: "{" ".join(tool_args)}"')
output = subprocess.check_output(command)
print(output)
except Exception as e:
print(f'Fail with: {e}')
return 1
return 0
def run(project_tools_xml, available_tools_xml, tool_id, tool_args):
tools = get_tools_info(project_tools_xml=project_tools_xml, available_tools_xml=available_tools_xml)
update_tool(tools[tool_id])
return run_tool(tool_info, tool_args)
На сервере мы добавили файл с описанием утилит. Адрес этого файла неизменный, поэтому первым делом идём туда и смотрим, что у нас есть в наличии. Опуская тонкости, это имена пакетов и путь к исполняемому файлу внутри пакета для каждой платформы.
Чтобы было совсем хорошо, и не каждый раз перекачивать с сервера, можно заморочиться, сделав локальный кеш. Тогда переключение версий будет очень дешёвой операцией.
После данных манипуляций процесс работы стал выглядеть предельно прозрачно:
на проекте есть только один файл, где прописаны версии утилит, которые на данный момент актуальны
стало просто распространять обновления, и главное, что понятна текущая версия на проекте. А это правда сильно упрощает поиск проблемы.
На сервере мы это относительно быстро подняли, но наша глобальная цель — запустить тесты у ГД.
А запускать-то как?
Вы когда-нибудь пробовали объяснить, как приготовить круассаны человеку, который никогда не готовил даже яичницы? Вот и нам сложно было объяснять гейм-дизайнерам, как запускать нужные скрипты. Если на сервере один раз настроил — и оно бодро выполняется, то с локальным запуском есть не так много вариантов. Точнее только один: хуки git.
По-простому, хук — это bash-скрипт, который запускается в определённые моменты при работе с git: перед pull или push, во время создания коммита, есть хуки даже на git-сервере.
Из всего разнообразия нас интересуют только три, которые запускаются во время создания коммита:
pre-commit — он выполняется первым и стоит на страже данных. Если код выхода отличный от нуля, то создание коммита прерывается.
prepare-commit-msg — он работает до вызова редактора сообщения коммита, но после создания стандартного сообщения. Нам он нужен, чтобы модифицировать сообщения коммитов слияния или rebase.
commit-msg — в этом хуке можно проверить сообщение к коммиту. Например, что разработчик не забыл добавить ссылку на задачу. Если он вернёт не ноль, то создание коммита прерывается.
Чтобы хук начал действовать, его мало положить в репозиторий, как скрипт, его нужно скопировать в папку .git/hooks. Автоматически это сделать нельзя — эксплойт. Мы не выдумывали хитрых технологий, а сделали два командных файла (для Windows и Mac), которые копируют хуки из одной папки в другую и запускаются двойным кликом. Выполнить их нужно только один раз, и такое уже несложно объяснить человеку без технического образования.
Конечно, не всегда всё идеально. Иногда бывают сбои, которые в основном типичны и делятся на две группы.
Магия у пользователя. Непонятная на первый взгляд ошибка, но стандартная проблема вроде нестандартных символов в путях, отсутствия git-bash на Windows. Для этих случаев мы пишем FAQ.
Недавний случай
Мы перебрали несколько предположений: нет прав на запись в папку, нет доступа на сервер, dns не резолвится. А оказалось, что curl не переваривает символы [ в пути.
Тонкости работы систем. Предусмотреть все возможные варианты и параметры мы не смогли, поэтому периодически вылавливаем разнообразные баги. Мы или подпираем их в скрипте, или добавляем пункт в FAQ. Например, папка .git/hooks не всегда находится в корне репозитория. Чтобы узнать точное расположение, можно использовать команду:
git rev-parse
git rev-parse --git-path hooks
В зависимости от того, в каком типе репозитория запускается команда, она вернёт следующее:
Другой интересный случай — это переключение между ветками во время разработки. Мы не очищали папку .git/hooks, и там могли оставаться старые хуки. Они пытались запуститься и падали. Это довольно сильно расстраивало пользователей, поэтому мы добавили в скрипт очистку .git/hooks перед тем, как начать копирование новых хуков.
Всё сделать идеально с первого раза нельзя, поэтому просто необходима возможность внести правки в репозитории, и чтобы они каким-либо образом автоматически подхватились у всех локально. Это сильно спасает, когда мы находим серьезный просчёт и не бегаем всем в личные сообщения с просьбой опять вызвать наш убер-скрипт. Вся эта работа должна быть максимально скрыта для разработчика — это не его война. Единственная сложность в том, что в момент выполнения хука мы не можем обновить сам файл хука — запись в него заблокирована системой. Одно из решений:
При вызове pre-commit обновить все файлы, кроме него самого. И создать pre-commit-tmp
При вызове commit-msg заменить файл pre-commit на созданный в первом шаге pre-commit-tmp
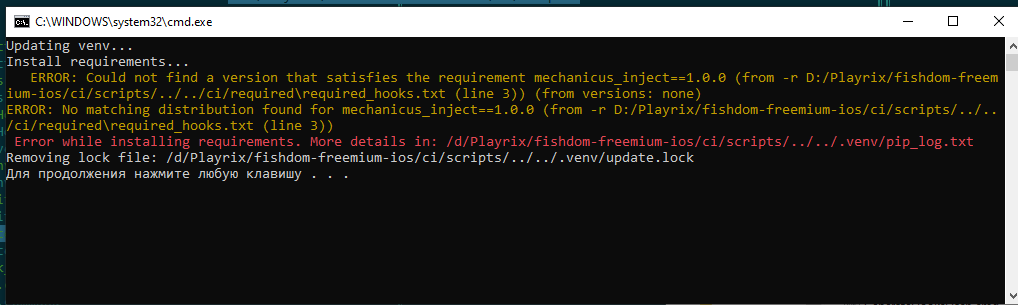
Вот, теперь хорошо: один раз скопировали хуки, и они будут запускаться во время коммита и автоматически обновляться. Мы выдохнули, но пользователи прислали нам скриншот.
<spoiler title=«Причина ошибки:>Причина простая: сначала установили 32-битный питон в глобальном окружении; поняли свою ошибку, удалили и поставили 64-битный; pip install видит, что пакет уже установлен и ничего не делает. Но пакет-то для 32-битной версии — возникает конфликт.
Но всё же, как запускать?
Сначала мы сделали многостраничную инструкцию о том, какие круассаны вкуснее, какой python нужно установить. Но мы помним про гейм-дизайнеров и яичницу? Она всегда была подгоревшей: то python не той битности, то 2.7 вместо 3.7. И всё это множится ещё и на две платформы, где работают пользователи: windows и mac. (Пользователи Linux у нас либо гуру и сами всё настраивали, тихо притопывая под звуки бубна, либо их миновали проблемы.)
Мы решили вопрос радикально — собрали python нужной версии и битности. А на вопрос «как нам его поставить и где хранить» ответили: Nexus! Единственная проблема: у нас ещё нет python, чтобы запустить python-скрипт, который мы сделали для запуска утилит из Nexus.
И тут на помощь приходит bash! Он не такой уж и страшный, а даже хороший, когда к нему привыкнешь. И работает везде: на unix уже всё хорошо, а на Windows он ставится вместе с git-bash (это наше единственное требование к локальной системе). Алгоритм установки очень простой:
Скачать архив собранного python для нужной платформы. Проще всего это сделать через curl — он есть почти везде (даже в Windows).
Разархивировать его, создать виртуальное окружение, ссылающееся на скачанный бинарник. Не повторяйте наших ошибок: не забудьте прибить версию virtualenv.
Когда обращаются с проблемой, то обычно прилагают скриншот консоли, где вывелись ошибки. Для облегчения себе работы мы не только храним вывод последнего запуска pip install, но и добавили красок в жизнь, выводя цветом ошибки из лога прямо в консоль. Да здравствует grep!
Как это выглядит
На первый взгляд может показаться, что нам не нужно виртуальное окружение. Ведь мы и так скачали отдельный бинарник, в отдельную директорию. Даже если есть несколько папок, где развёрнута наша система, то всё равно бинарники разные. Но! У virtualenv есть скрипт activate, который делает так, что можно вызывать python, как будто он в глобальном окружении. Это изолирует выполнение скриптов и упрощает запуск.
Представьте: вам нужно запустить командный файл, из которого запускается python-скрипт, из которого запустится другой python-скрипт. Пример не выдуманный — так выполняются post-build события при сборке приложения. Без virtualenv пришлось бы везде вычислять на лету нужные пути, а с activate везде просто используем python. Точнее vpython — мы добавили свою обёртку, чтобы удобней запускать и из консоли, и из скриптов. В оболочке мы проверяем, находимся ли уже в активированном окружении или нет, запускаемся ли на TeamCity (где своё виртуальное окружение), а заодно подготавливаем окружение.
vpython.cmd
set CUR_DIR=%~dp0
set "REPO_DIR=%CUR_DIR%\."
rem VIRTUAL_ENV is the variable from activate.bat and is set automatically
rem TEAMCITY - if we are running from agent we need no virtualenv activation
if "%VIRTUAL_ENV%"=="" IF "%TEAMCITY%"=="" (
set RETURN=if_state
goto prepare
:if_state
if %ERRORLEVEL% neq 0 (
echo [31m Error while prepare environment. Run ci\PrepareAll.cmd via command line [0m
exit /b 1
)
call "%REPO_DIR%\.venv\Scripts\activate.bat"
rem special variable to check if venv activated from this script
set VENV_FROM_CURRENT=true
)
rem Run simple python and forward args to it
python %*
SET result=%errorlevel%
if "%VENV_FROM_CURRENT%"=="true" (
call "%REPO_DIR%\.venv\Scripts\deactivate.bat"
set CI_VENV_RUN=
set VENV_FROM_CURRENT=
)
:eof
exit /b %result%
:prepare
setlocal
set RUN_FROM_SCRIPT=true
call "%REPO_DIR%\ci\PrepareEnvironment.cmd" > NUL
endlocal
goto %RETURN%
Танакан, или не надо забывать ставить тесты
Проблему забывчивости для запуска тестов мы решили, но даже один скрипт можно упустить из вида. Поэтому сделали таблетку от забывчивости. Она состоит из двух частей.
Когда наша система запустилась, она модифицирует комментарий к коммиту и ставит метку «одобрено». В качестве метки мы решили не мудрствовать и добавлять [+] или [-] в конце комментария к коммиту.
На сервере крутится скрипт, который парсит сообщения, и если он не находит заветный набор символов — создаёт задачу на автора.Это самое простое и элегантное решение. Непечатаемые символы — не очевидно. Чтобы запускать серверные хуки, нужен другой тарифный план на Гитхабе, а покупать премиум для одной фичи никто не будет. Пробежаться по истории коммитов, поискать символ и поставить задачу — очевидно и не так дорого.
Да, можно поставить символ и своими ручками, но вы уверены, что не сломаете сборку на сервере? А если сломаете… да-да, за вами уже едет лысый из Homescapes.
Каков итог
Отследить количество ошибок, которые нашли хуки, довольно сложно — они не попадают на сервер. Есть только субъективное мнение, что зелёных сборок стало гораздо больше. Однако есть и отрицательная сторона — коммит стал занимать довольно много времени. В некоторых случаях доходит до 10 минут, но это отдельная история про оптимизацию.





 Министр просвещения России Сергей Кравцов. Источник фото: Пресс-служба Совета Федерации РФ/РИА Новости.
Министр просвещения России Сергей Кравцов. Источник фото: Пресс-служба Совета Федерации РФ/РИА Новости.























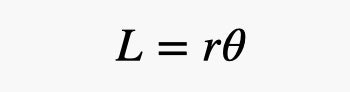




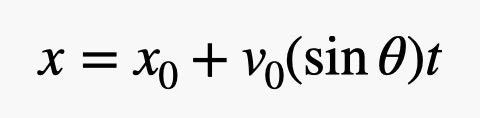
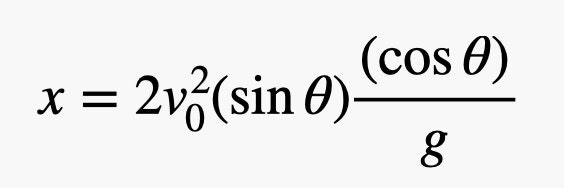








{kind=link}