И снова привет, Хабр! Сделав перевод статьи об управлении ЖК-модулем с драйвером, но без собственного видео-ОЗУ, я решил перевести ещё одну публикацию на ту же тему. Здесь модуль уже попроще, монохромный, но «оживить» его не менее интересно.
Дисплей, с которым собирается работать автор, взят из старой ленточной библиотеки. Контроллер не сохранился, но поиск чего-либо связанного с «263645-001» показал, что там был ПЛИС. Считается, что непосредственно управлять такими ЖК-модулями от Arduino и т.п. невозможно, нужно промежуточное звено — контроллер серии SEDxxxxx, который не «дружит» с макетными платами, а входов имеет больше, чем сам модуль. Но это не так. Вот целых четыре аналогичных проекта:
На ATmega8515
На нём же
На PIC
На ESP32
А некоторые вообще управляют от восьмиразрядных AVR VGA-мониторами…
В общем, у автора всё получилось, ПО под лицензией MIT — здесь.
Чтобы убедиться, что всё работает, надо сначала попробовать вывести однобитное растровое изображение из флеш-памяти микроконтроллера. Для получения отрицательного напряжения взяты три «Кроны», на вывод V0 подано напряжение с делителя, в качестве которого применён подстроечный резистор. И вот на экране — Ленна:

Автор до сих пор не может понять, как умудрился перевернуть картинку (посомтрите, с какой стороны шлейф). В любом случае, на странице проекта на GitHub есть и этот пример.
Но от видео-ПЗУ толку мало, а 9600 байт для видео-ОЗУ в Arduino нет. На помощь приходит текстовый режим, при котором ПЗУ знакогенератора и видео-ОЗУ вместе взятые имеют меньший объём, чем видео-ОЗУ при графическом режиме. На эту тему сторонники РК и «Специалиста» могут ломать копья бесконечно.
Короткий пример на языке ассемблера AVR:
...
lpm r24, Z
;---------- (CL2 rising edge)
out %[data_port], r24
ld r30, X+
swap r24; (CL2 rising edge)
out %[data_port], r24
lpm r24, Z
;---------- (CL2 rising edge)
out %[data_port], r24
...

Для модуля F-51543NFU-LW-ADN / PWB51543C-2-V0 автор применил:
Arduino на AVR с тактовой частотой в 16 МГц (проверено на Uno, Leonardo и клоне, аналогичном ProMicro).
Источник отрицательного напряжения. У автора это — нестабилизированный DC-DC преобразователь A0524S-1W с развязкой входа и выхода. Подойдут также преобразователи на MC34063 (эту микросхему найти очень просто — достаточно разобрать самую дешёвую USB-зарядку для прикуривателя) или MAX749. Стабилизация не требуется, диапазон допустимых напряжений по этому входу у применённого здесь модуля достаточно широк. Номинал — минус 24 В, максимум — минус 30 относительно общего провода и 35 между Vdd и Vee. Потребляемый ток составит 6 мА.
Два N-канальных МОП-транзистора с управлением логическими уровнями. Автор применил IRL530n, запас, конечно, большой, зато точно не перегорят. Один транзистор управляет подсветкой, другой — источником отрицательного напряжения.
Подстроечный резистор на 250 кОм для подачи напряжения на вход V0. Выставить, чтобы на подвижном контакте было -16.8 В при температуре в +25 °C. Это из даташита, а так, конечно, такая точность не нужна.
Несколько 10-килоомных резисторов для подтягивания вниз.
Макетка и перемычки.
Что бы теперь такого сделать? QR-часы? Спросим котэ:

Котэ предлагает реализовать симуляцию какого-нибудь распространённого ЖКИ с контроллером. Чтобы к этому Arduino можно было подключить другое, «думающее», что работает с дисплеем на HD44780, только большим.
Берём пример с EGA и VGA — там при работе в текстовом режиме сделано именно так. Только здесь знаков поместилось всего 64, но хоть так всё в ОЗУ влезло, в отличие от графического режима. Правда, основной цикл событий замедлило, зато можно попробовать тайловую графику:

В Arduino на AVR столько ОЗУ нет, и точка. Даже в Mega. 320x240 даже при одном бите на пиксель — это уже 9600 байт. Всего для четырёх полутонов потребуется вдвое больше. С внешним ОЗУ, например, 23LC512 в режиме SQI можно попробовать реализовать что-то похожее на DMA, но проще и выгоднее переделать всё на ESP32, где и статического ОЗУ больше, и DMA легче делается.
Если вы хотите просто подключить такой дисплей к ПК через USB, можно попробовать применить для этого ATmega32u4 — ресурсов хватит даже для градаций яркости (при помощи FRC, о том, что это такое, рассказано в моём предыдущем переводе). Но не у «меги», используемой как преобразователь интерфейсов, а у ПК, который будет сам сканировать ЖКИ на лету со скоростью в 5.4 мегабит в секунду.
Когда модуль ещё стоял в ленточной библиотеке, там и GUI, и градации яркости — всё было.
Обновления будут. А пока…

И это — не фотомонтаж, а результат управления с ПК. А мы перейдём с Hackaday.io на GitHub — там в README.md ещё много интересного.
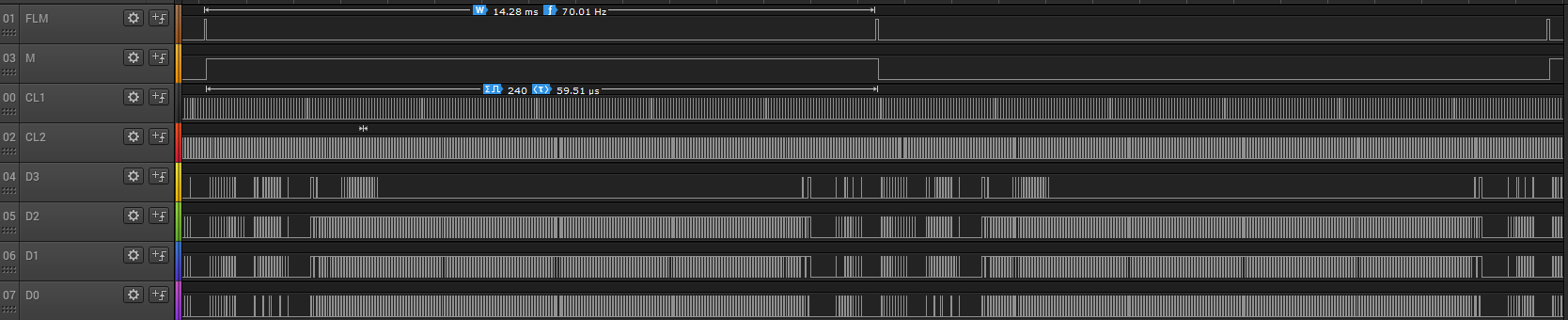
FLM — First Line Marker — маркер первой строки, может также называться FRAME, VSYNC, и т.п.
CL1 — Row latch pulse — импульс записи строки, может также называться. LOAD, HSYNC, и т.п.
CL2 — Pixel shift clock — импульс смены пикселя, может также называться. CP (change pixel), и т.п.
M — чередующийся сигнал, благодаря которому пиксели управляются переменным напряжением, может также называться BIAS (смещение), и т.п.
D0-D3 — четырёхразрядная параллельная шина данных.
Выводы общего провода, питания подсветки (например, VLED±), питания модуля (VEE и V0)
Не пренебрегайте даташитами. Модуль может требовать другое отрицательное напряжение, или оно может оказаться положительным, или преобразователь может быть встроенным. Может отличаться логика, например, при единице на CL1 не будет реакции на CL2. Может быть другая подсветка (CCFL (осторожно, инвертор «кусач») вместо светодиодов), или на плате не указана цоколёвка, тогда без даташита её точно не узнать. Наугад что-либо подключать нельзя.
Передать строку кусками по четыре бита, запись производится по спаду на линии CL2. Передав строку, записать её по спаду на линии CL1 (ага, всё-таки, чуть-чуть ОЗУ в модуле есть — на одну строку). Следующая строка будет выбрана автоматически. Передав весь кадр, вернуться в начало при помощи сигнала FLM. В даташите на LC79401 есть пример. Запись производить с достаточной скоростью, импульсы на CL1 подавать равномерно. Контроллер чуть замешкался — экран некрасиво мигнул.
После каждого кадра менять логический уровень на входе M на противоположный, чтобы пиксели управлялись переменным напряжением. Иначе дисплей портится:
Эту операцию можно не доверять микроконтроллеру, а поставить счётный триггер. Входом на FLM, выходом на M — в общем, понятно.
Пример для вывода изображения из флеш-памяти (см. начало статьи) называется в этом репозитории clglcd_simple
Как уже было сказано, проделать то же самое с ОЗУ в Arduino на AVR невозможно — его не хватит, поэтому…
Согласно даташиту, можно передавать данные по четырёхразрядной шине и «дёргать» CL2 с частотой до 6 МГц. Поэтому можно быстро-быстро передать строку, потом микроконтроллер немного порешает другие задачи, а как таймер ему «скажет» — он «дёрнет» CL1 и повторит цикл.
При генерации знаков для горизонтального разрешения в 320 пикселей всё это удаётся проделывать за 20 мкс (320 пикслей /4 бита = 80 импульсов, CL2 «дёргаем» с частотой в 4 МГц). На остальные задачи остаётся 39.5 мкс. CL1 «дёргаем» каждые 59.5 мкс и получаем частоту кадров в 70 Гц. Ну, там ещё процедурв обработки прерываний будут и прочее, в общем, микроконтроллер будет занят управлением дисплеем 45% времени. «Целых» 45 или «всего» 45? Наверное, второе: перезаписать данные в видео-ОЗУ можно достаточно быстро.
Хотите, чтобы микроконтроллер тратил меньше времени на управление индикатором, и больше на другие задачи? Можно уменьшить частоту кадров до 50 Гц, можно разогнать микроконтроллер до 20 МГц. При любом из этих способов между проуедурами обработки прерываний пройдёт больше тактов.
Таймер сравнения выхода переключает линию CL2 через каждые четыре тактовых импульса со скважностью в 50%. Одновременно данные поступают на выходы порта PORTB, подключённые к четырёхразрядной шине данных модуля таким образом, что смена их происходит в момент нарастания уровня на CL2, а в момент спада они остаются неизменными. Конечно, без ассемблера такое не проделать:
...
lpm r24, Z
;---------- (CL2 rising edge)
out %[data_port], r24
ld r30, X+
swap r24; (CL2 rising edge)
out %[data_port], r24
lpm r24, Z
;---------- (CL2 rising edge)
out %[data_port], r24
...
8 тактов — и переданы четыре полубайта. А что именно передавать — зависит от того, какой символ находится в соответствующей ячейке видео-ОЗУ, какие именно пиксели, соответствующие этому символу, надо передать из ПЗУ знакогенератора, и что хранится в соответствующих ячейках этого ПЗУ.
Самое неудобное здесь — необходимость останавливать таймер ровно через 80 импульсов. Некоторые таймеры, например Timer4 в 32u4, так не могут.
Для получения сигнала, подаваемого на линию CL1, автор применил другой вывод микроконтроллера, предназначенный как для таймера, так и для быстрого ШИМ. Что из этого применено здесь, понятно. Переключается он каждые 952 такта. Или если считать после делителя тактовой частоты на 8 — получается через каждые 119 импульсов. В этот момент запускается процедура обработки прерывания и заставляет микроконтроллер подать на линии управления новые данные, которые потребуются при следующем импульсе на CL1. Ну а уровень на линии M меняется с вдвое меньшей частотой. И ЖКИ не портится. Все сигналы вместе выглядят так:
Знакогенератор состоит из 256 символов — хватит для 866, KOI-8R или 1251. В видео-ОЗУ помещается 40хN символов, где N — количество строк, зависящее от высоты символа. Ширина символа — всегда 8 пикселей, а высота может быть 6, 8, 10, 12, 15, 16. Чем она меньше, тем меньше требуется ПЗУ для знакогенератора и больше видео-ОЗУ. При шрифте 8х8 (40 символов на 30 строк) надо 1200 байт ОЗУ и 2048 байт ПЗУ. При шрифте 8х16 (на этом модуле смотрится лучше всего) ОЗУ надо 600 байт, а ПЗУ — 4096. От переводчика: можно шрифт хранить в виде 8х8, а по вертикали масштабировать вдвое программно, и обойтись 600 байтами ОЗУ и 2048 — ПЗУ. Чтобы хранить в ПЗУ несколько шрифтов, нужно держать адрес начала шрифта не в константе, а в переменной, но выводить текст сразу несколькими шрифтами не получится, если, конечно, не менять этот адрес на лету процедурой обработки прерывания прямо во время передачи пикселей в дисплей.
Шрифт хранится так: сначала верхние строки всех 256 символов, потом на одну строку ниже, и так далее. В папке misc репозитория есть скрипт на Python, который автоматически преобразует TTF-шрифт в файл заголовка clglcd_font.h с массивом PROGMEM в необходимом формате. Классические пиксельные шрифты под CC-BY-SA 4.0 можно взять здесь.
Но на этот раз с подробностями. Знакогенератор в ОЗУ, как указано выше, вмещает всего 64 знака, их можно обозначить номерами от 0 до n либо от 255-n до 255. Хранятся они аналогично: верхние строки всех символов, затем следующие, и так далее. Только выровнено всё это с учётом того, что знаков не 256, а 64. Для знаков размером 8х16 пикселей потребуется 16*64=1024 байта. В репозитории есть пример работы со знакогенератором в ОЗУ.
Если задействовать одновременно оба знакогенератора — 256-символьный в ПЗУ и 64-символьный в ОЗУ, придётся смириться с тем, что не только останется меньше ОЗУ, но и уменьшится скорость передачи данных о строках в модуль — вместо 8 тактов загрузки двух полубайтов потребуется 12, то есть, не 20 мкс, а 30, а вместо 45% времени на управление ЖКИ уйдёт 60.
Как указано выше, в этом случае микроконтроллер работает просто преобразователем интерфейсов. Потребуется ATmega32u4, а что как делать, описано
здесь.
Так вот что это за четырёхпроводной шлейф — от резистивного сенсора, оказывается.
Как указано выше, потребуется отрицательное напряжение, которое в первых опытах можно снять с трёх «Крон», а потом собрать преобразователь, например, на MAX749. Сигналы управления питанием, а также сигнал DISPOFF (это сигнал инверсный, модуль включён при единице) подтянуть резисторами вниз. Во время прошивки и сброса микроконтроллера появление там логических единиц недопустимо.
Отрицательное напряжение подавать после напряжения +5В, а логическую единицу на линию DISPOFF — когда на линиях управления уже присутствуют данные: хотя бы одна единица на шине данных, единица на CL1. Иначе может выйти из строя модуль.
Входы D0-D3 подключить к выходам одного и того же порта микроконтроллера, например, Px4-Px7, при этом, выходы Px0-Px3 использовать в качестве GPIO нельзя. Можно назначить им другие функции, например, использовать их как выходы таймеров, последовательного интерфейса, и т.п. Если вы используете их как входы, будьте осторожны: встроенные подтягивающие резисторы могут переключаться произвольно, если их не отключить (PUD — pull-up disable).
Вход M — на выход таймера сравнения или ШИМ.
Вход CL1 — на другой выход того же таймера.
Вход CL2 — на выход другого таймера сравнения.
FLM — на любой цифровой выход.
DISPOFF — на любой другой цифровой выход.
Остальное зависит от того, как вы запитываете модуль. Автор предпочитает управлять подсветкой и Vee по отдельности.
Поместить в скетч файлы clglcd.h and clglcd.cpp
Сделать резервную копию файла clglcd_config.h и отредактировать его с учётом того, что куда подключено, а также того, какие функции вам нужны: знакогенератор в ОЗУ, и т.п. Внимание, в коде указаны не названия выводов Arduino, а названия выводов микроконтроллера согласно даташиту. Названия выходов теймеров сравнения расшифровываются так: например, 2,B — это OC2B, что на Arduino Uno соответствует PD3. В примерах приведены варианты подключения, которые заработали у автора.
Сгенерировать файл шрифта clglcd_font.h Python-скриптом в папке misc (см. выше).
Посмотреть в примерах, как инициализировать, включить и выключить дисплей. Поместить в массив screen текст, который вы желаете отобразить для проверки.
Скомпилировать и залить скетч. Проверить логическим анализатором, что на дисплей пойдут правильные сигналы, а вольтметром — что все напряжения питания в норме. Только после этого подключать дисплей.
Добавить в скетч код, который будет что-нибудь делать, например, принимать текст по последовательному порту и отображать.
Обновлять дисплей надо постоянно, чем занимаются процедуры обработки прерываний. Если прерывания прекратятся более чем на 30 мкс, дисплей начнёт моргать, а если более чем на 60 мкс при единице на линии FLM — он может выйти из строя. Если надо прекратить прерывания надолго, сначала выключайте дисплей сигналом DISPOFF (повторяю, это сигнал инверсный, модуль включён при единице). Конечно, если он будет выключаться на две секнуды каждый раз, когда надо обработать данные от датчика влажности и температуры, это мало кому понравится, но лучше уж так, чем испортить модуль. Ещё лучше поручить всё остальное отдельному микроконтроллеру. Особенно недопустим обмен информацией тем же самым микроконтроллером с устройствами, работающими по протоколу 1-wire, и адресными светодиодами. Клоны Arduino Pro Micro достаточно недороги, чтобы купить два.
Зато будут прекрасно работать аппаратно реализованные интерфейсы: последовательные порты, шина I
2C, SPI в ведущем режиме. В ведомом — только если ведущее устройство допускает периодическое «отваливание» ведомого на 25-35 мкс. Конечно же, всё ещё зависит от того, сколько «ног» осталось не занято после подключения дисплея.
USB на 32u4 работает отлично, если не опрашивать конечную точку управления слишком часто (медленный код процедуры обработки прерывания). Драйвер CDC и его API оказались достаточно быстрыми.
Далее в файле README.md на GitHub повторён перечень аналогичных проектов, такой же, как на странице проекта на Hackaday.io
Спасибо за внимание!
Let's block ads! (Why?)