Меня зовут Лёша Гусев, я работаю в команде разработки видеоплеера Яндекса. Если вы когда-нибудь смотрели фильмы или трансляции на сервисах Яндекса, то использовали именно наш плеер.
Я сделал небольшую оптимизацию размера бандла — минификацию приватных полей. В докладе на Я.Субботнике я рассказал об использовании Babel-плагинов, трансформеров TypeScript и о том, насколько в итоге уменьшился размер продакшен-сборки проекта.
Конспект и видео будут полезны разработчикам, которые ищут дополнительные способы оптимизации своего кода и хотят узнать, как webpack, Babel и TypeScript могут в этом помочь. В конце будут ссылки на GitHub и npm.
— С точки зрения структуры наш видеоплеер — довольно типичный фронтенд-проект. Мы используем webpack для сборки, Babel для транспиляции кода, скин нашего плеера мы пишем на React, весь код написан на TypeScript.
Мы также активно используем опенсорсные библиотеки, чтобы реализовывать адаптивный видеостриминг. Одна из таких — библиотека shaka-player, которая разрабатывается в Google, и нужна она для того, чтобы поддерживать в вебе адаптивный формат MPEG-DASH.
Мы контрибьютим в эту библиотеку, чинили в ней некоторые баги, делаем патчи, специфичные для нашего проекта.
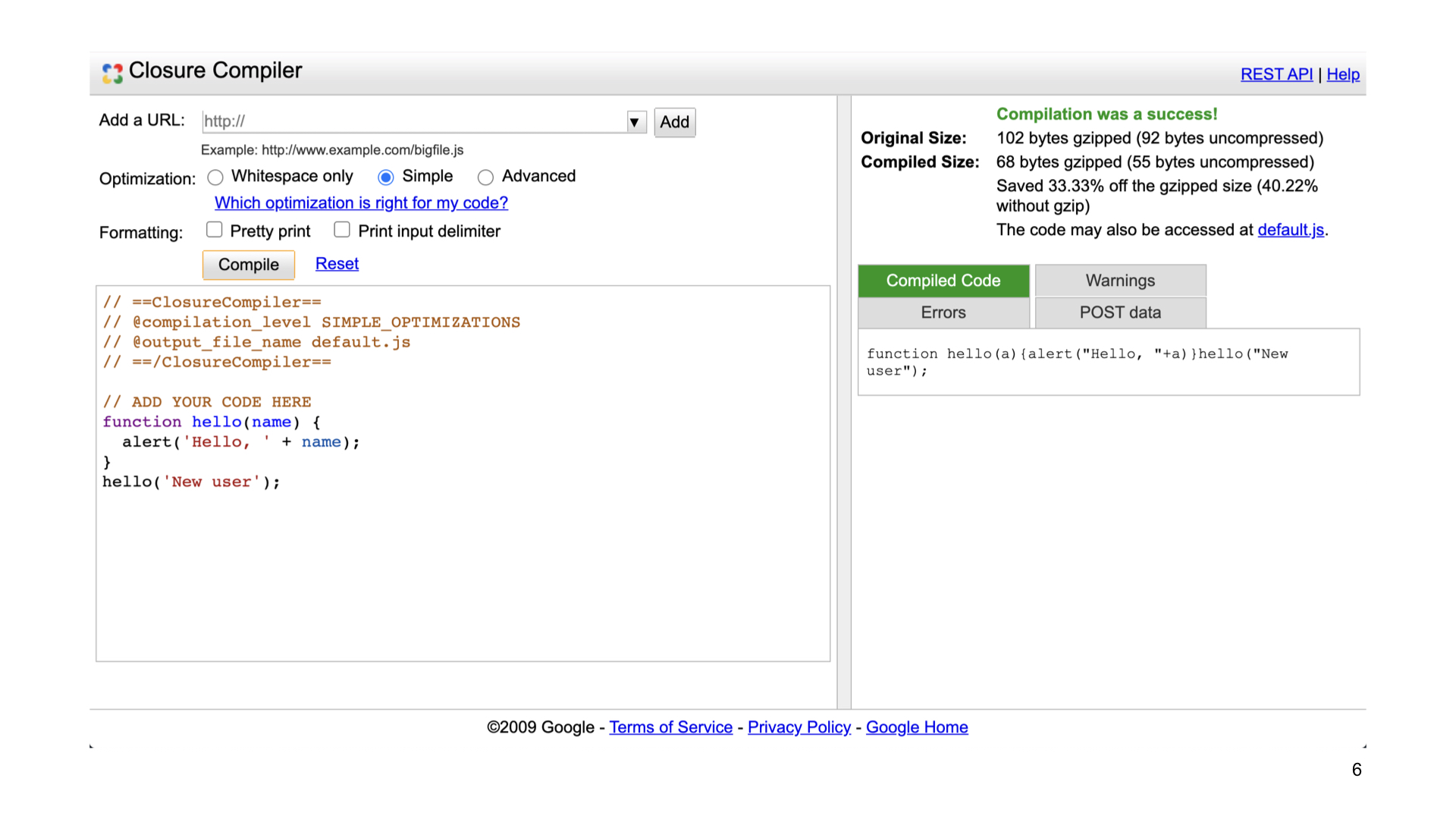
В процессе работы с этой библиотекой я познакомился с инструментом, который называется Google Closure Compiler. Наверняка многие из вас слышали про этот инструмент. Возможно, кто-то пользовался вот такой классной онлайн-страничкой, куда можно вставить кусок JavaScript-кода и минифицировать его с помощью Google Closure Compiler.
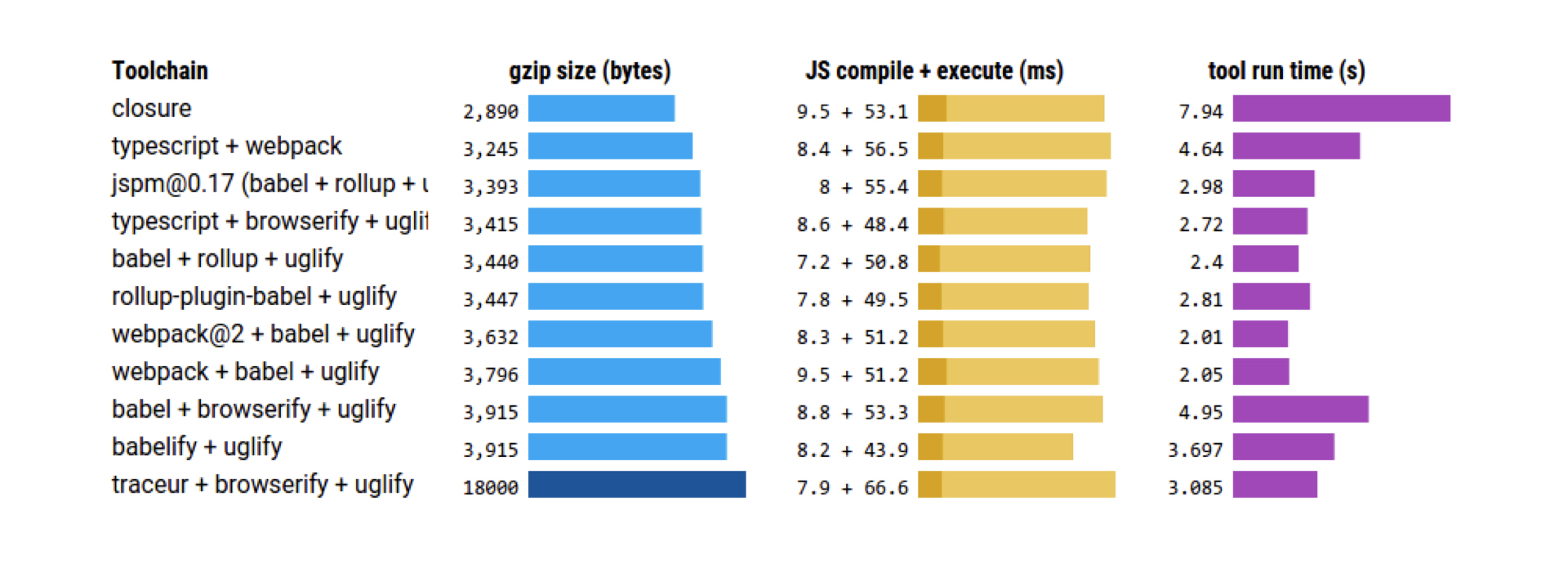
Кто-то, может быть, использовал плагин webpack-closure-compiler. Здесь на слайде сравнение webpack-closure-compiler с другими инструментами минификации webpack, и, как видно, closure-compiler по этому сравнению лидирует.

Почему он такой классный? Дело в том, что в closure-compiler есть так называемый advanced-уровень оптимизации. На этой страничке он кроется за переключалкой в radio button.
Что из себя представляют advanced-оптимизации и почему они такие классные? Это некоторый набор оптимизаций, которых нет в других инструментах. Рассмотрим некоторые из них.

Closure-compiler умеет инлайнить функции. Здесь он просто заинлайнил тело функции f и удалил объявление самой функции, так как она больше нигде не используется.

Он умеет удалять неиспользуемый код. Здесь объявлен класс A и класс B. По факту используется только один метод из класса A. Класс B был удален совсем. Из класса A method() был заинлайнен, и мы в итоге получили только console.log.

Closure-compiler умеет инлайнить и вычислять значения переменных на этапе сборки.

Еще он умеет минифицировать поля объектов. Здесь объявлен класс A со свойством prop, и после обработки closure-compiler свойство prop заменилось на короткий идентификатор a, за счет чего код стал меньше весить.
Это не все оптимизации. В статье можно подробно почитать, что еще может closure-compiler. Там довольно много чего крутого.
Когда я про это узнал, мне очень понравилось. Я захотел притащить все эти оптимизации к нам в проект. Что мне особенно понравилось, так это минификация полей объектов, а именно минификация приватных полей для TypeScript.

Если вы никогда не писали на TypeScript, то что такое приватные поля? Это такой синтаксический сахар, который просто удаляется при сборке, при компиляции TS-кода в JavaScript. Но если вы используете приватное поле за пределами класса, вы получите ошибку компиляции.
Почему мне понравилась идея минифицировать приватные поля?

У нас в проекте довольно много React-компонентов, написанных в ООП-стиле с классом. И есть TypeScript-код, в котором используются классы и приватные поля.
Давайте рассмотрим вот такой компонент. В нем есть приватное поле clickCount.

Сейчас при сборке и компиляции кода TypeScript оставляет название этого поля как есть, просто удаляет модификатор private. Было бы клево, если бы clickCount заменился на короткий идентификатор A.
Чтобы достичь этого, давайте попробуем использовать Closure Compiler в advanced-режиме как минификатор.
И тут можно столкнуться с проблемами. Давайте рассмотрим пример. Объявлен объект с полем foobar. Обратимся к этому полю. Здесь все хорошо. Closure Compiler отработает такой код корректно. Поле foobar будет переименовано.

Ссылка со слайда
Но если мы вдруг зачем-то будем обращаться к этому полю через строковой литерал, то после сборки получим no reference, ошибку в коде. Она связанна с тем, что в поле идентификатор foobar Closure Compiler переименует, а строковые литералы оставит как есть.

Ссылка со слайда
Следующий пример. Здесь мы объявляем метод у объекта, который внутри использует ключевое слово this. После сборки с помощью Closure Compiler и удаления мертвого кода, как видно на слайде, идентификатор this станет глобальным. Вы опять же получите ошибку в коде.
Примеры немножко утрированные, надеюсь, такие конструкции у себя в проектах вы не применяете. Тем не менее, есть более сложные случаи, когда advanced-оптимизации могут сломать ваш код. По ссылке вы можете посмотреть документацию Closure Compiler, какие ограничения он привносит на ваш код. Тем более нельзя гарантировать, что ваши внешние npm-зависимости после обработки Closure Compiler будут работать корректно.

Ссылка со слайда
Для нашего проекта это еще критичнее. Как я говорил, мы разрабатываем видеоплеер. Видеоплеер — это встраиваемая библиотека. Если Closure Compiler переименует поле в нашей встраиваемой библиотеке, переименует публичный метод, то внешний код сломается и не сможет взаимодействовать с плеером.
Наверное, как-то нужно сказать Closure Compiler о том, что какие-то поля можно минифицировать, какие-то нельзя, какие-то, очевидно, публичные, какие-то приватные.
Но выходит, что advanced-оптимизации в общем случае не безопасны. Их можно сделать безопасными, если вы используете Closure Compiler на полную мощность.

Я немножко слукавил. Closure Compiler — не просто минификатор, а целый комбайн. Он заменяет собой webpack, Babel и TypeScript. За счет чего и как ему это удается?

Ссылка со слайда
В Closure Compiler есть своя модульная система goog.provide, goog.require.

Ссылка со слайда
Есть своя транспиляция и вставка полифиллов для различных таргетов, для разных версий ECMASCRIPT.

Ссылка со слайда
Еще там есть свои аннотации типов. Только описываются они не как в TypeScript, а в JSDoc. Точно так же там можно пометить, например, модификаторы доступа public, private и подобные.

Если сравнивать микросистему webpack-Babel-TypeScript с Closure Compiler, то, на мой вкус, Closure Compiler проигрывает. У него чуть хуже документация, им умеют пользоваться меньше разработчиков. В целом не самый удобный инструмент.
Но я все-таки хочу оптимизации. Может, можно как-то взять Closure Compiler, взять TypeScript и объединить их?

Такое решение есть. Называется оно tsickle.

Ссылка со слайда
Это проект, который разрабатывается в Angular и занимается тем, что компилирует TypeScript-код в JS-код с аннотациями Closure Compiler.

Ссылка со слайда
Есть даже webpack loader, tsickle-loader называется, который внутри использует tsickle и заменяет собой tsickle loader. То есть он подгружает TypeScript-код в webpack и эмитит JavaScript с аннотациями. После чего можно запустить Closure Compiler как минификатор.

Проблема в том, что в README tsickle явно написано, что работа над проектом в процессе, и Google внутри его использует, но снаружи большого опыта использования этого проекта нет. И завязываться на отдельный компилятор от TypeScript не очень-то и хочется, потому что тогда вы будете отставать по фичам от TypeScript и не получать какие-то новые возможности.
Собственно, tsickle loader имеет ту же проблему, так как он основан на tsickle. В общем, это решение сейчас не выглядит как хорошее продакшен-решение.
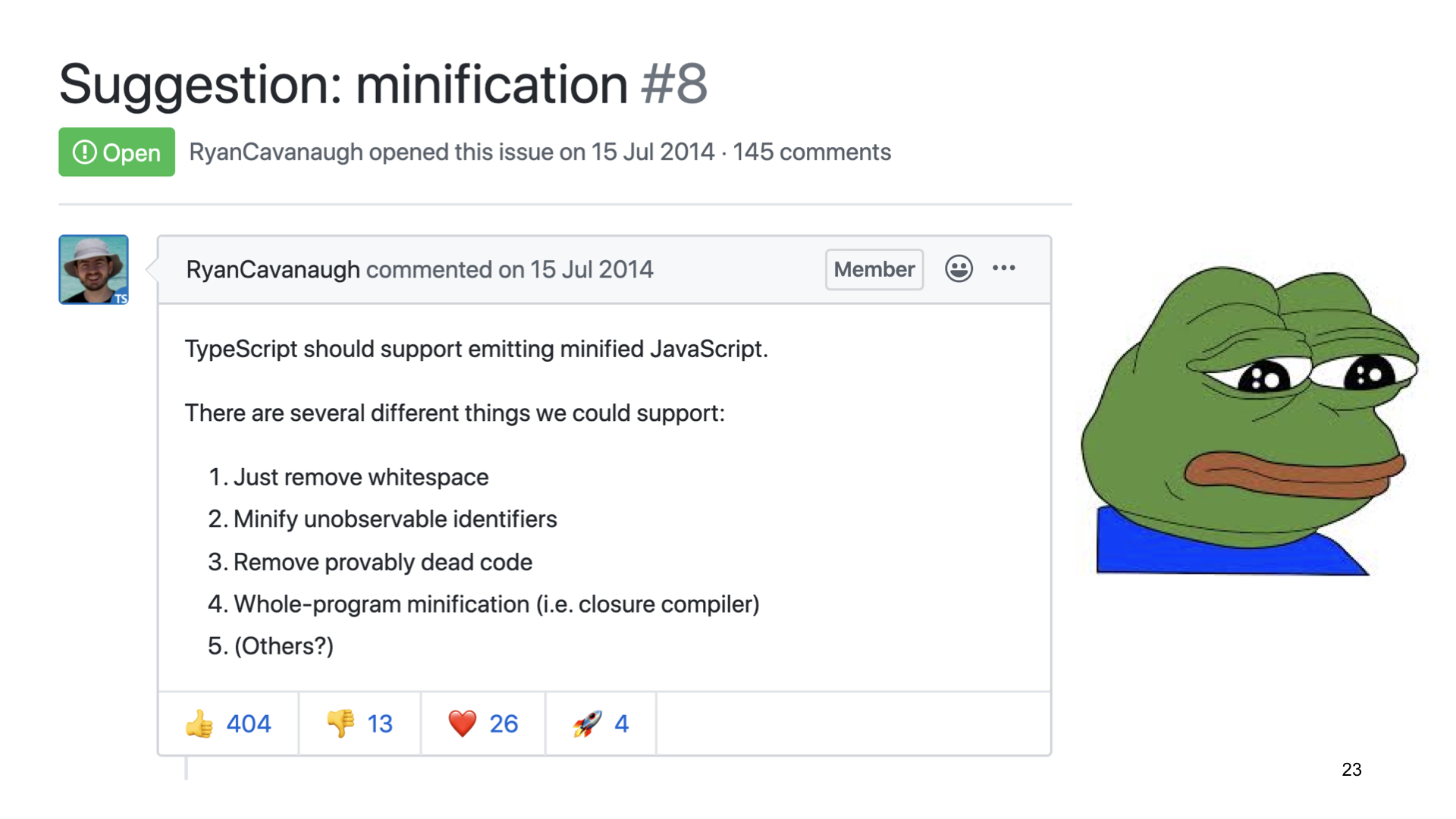
Какие еще есть варианты? В TypeScript есть issue про предложение о минификации. Там идет обсуждение похожей реализации на Closure Compiler: оптимизировать код, используя знания о типах. Проблема в том, что этот issue открыт 15 июля 2014 года, там до сих пор ничего не происходит. Вернее, там происходит 145 комментариев, но результатов пока нет. Судя по всему, команда TypeScript не считает, что компилятор TypeScript должен заниматься минификацией. Это задача других инструментов.
Что делать? Получается, хорошего решения у нас нет. Что делает разработчик, когда его не устраивают существующие решения? Естественно, пишет свой велосипед. Если мы говорим о велосипеде, который как-то модифицирует исходный код, на ум сразу приходит Babel.

Не так давно в Babel появилась поддержка TypeScript. Существует babel/preset-ypescript, который добавляет в Babel возможность парсить TypeScript-код и эмитить JavaScript. Он делает это путем удаления всех TypeScript-модификаторов.

Мы, кстати, не так давно перешли с ts-TS loader на Babel с использованием babel/preset-typescript и этим сильно ускорили сборку. Наконец-то настроили конкатенацию модулей в webpack, сделали еще некоторые оптимизации и настроили разные сборки под ES5- и ES6-браузеры. Про это можно узнать подробнее из доклада моего коллеги.
Окей, давайте попробуем написать babel-plugin, который будет минифицировать приватные поля, раз Babel умеет работать с TypeScript.

Ссылка со слайда
Как Babel работает? На эту тему есть много хороших материалов, статей и докладов. Можно начать, например, с этого материала на Хабре. Я лишь бегло расскажу, как происходит процесс обработки кода через Babel.
Итак, Babel, как и любой транспойлер кода, сначала парсит его и строит абстрактное синтаксическое дерево, abstract syntax tree, AST. Это некоторое дерево, которое описывает код.

Давайте попробуем на коротком кусочке кода посмотреть, как строится AST. Наша маленькая программа состоит из двух выражений. Первое выражение — это Variable Declaration, объявление перемены. Из чего оно состоит? Из оператора VAR — на схеме это Variable Declarator. У оператора есть два операнда — идентификатор A, мы создаем переменную A, и Numeric Literal, мы присваиваем им значение «3».
Второе выражение в программе — это Expression Statement, просто выражение. Оно состоит из бинарного выражения, то есть операции, у которой есть два аргумента. Это выражение «+», первый аргумент «a», второй «5», числовой литерал. Примерно так строятся абстрактные статические деревья.
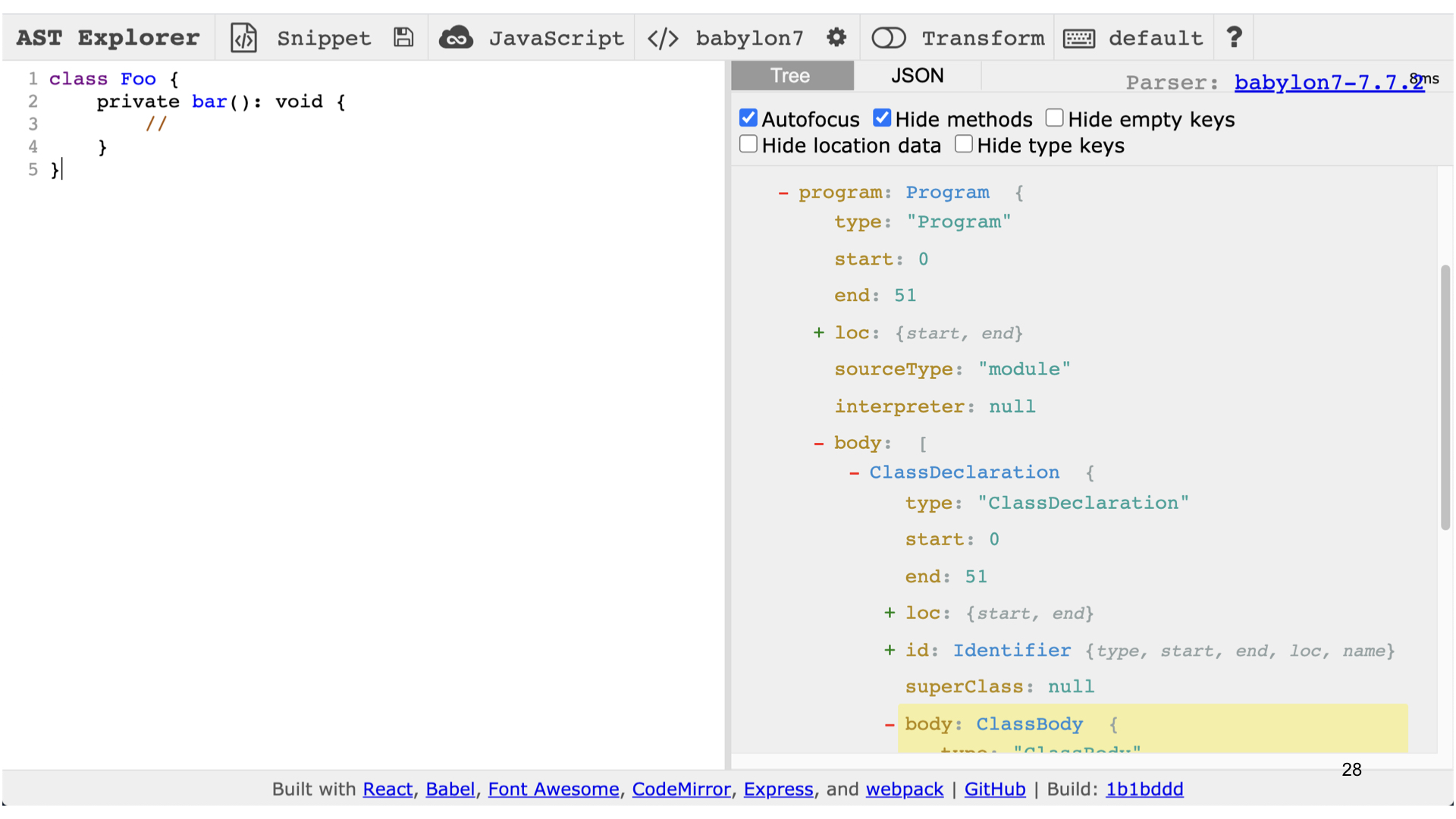
Если вы хотите подробнее в это окунуться или когда-нибудь будете писать свой плагин для Babel, вам очень сильно поможет инструмент AST Explorer. Это онлайн-приложение, куда вы можете просто скопировать ваш код и посмотреть, как строится для него абстрактное синтаксическое дерево.
Здесь есть поддержка Babel и TypeScript. Очень удобный, практически незаменимый инструмент, чтобы заниматься написанием плагинов для Babel.

Ссылка со слайда
Когда мы построили AST, мы его трансформируем. Трансформация — это превращение одного AST в новое, измененное. Как происходит трансформация? Это тот самый процесс, который вы описываете с помощью настроек Babel в файлике .babelrc или где-то еще.
Вы задаете список плагинов, которые вы трансформируете в ваше AST дерево.

Что такое плагин? Это просто функция, которая имплементирует паттерн Visitor. Babel обходит AST в глубину, в том порядке, как указано на схеме на слайде. Babel вызывает функцию вашего плагина, который возвращает объект с некоторыми методами.
В зависимости от того, в каком узле мы сейчас находимся, вызывается соответствующий метод объекта, который вернул плагин. Для идентификатора вызовется Identifier, для строки вызовется StringLiteral и т. д.
Подробно об этом можно узнать из документации Babel и воспользоваться AST Explorer, чтобы понять, какие операции в коде каким узлам в AST- дереве соответствуют.

Ссылка со слайда
Когда мы вызвали метод на узле, узел можно модифицировать, чтобы трансформировать AST-дерево. После этого мы получаем новое AST. Тогда Babel запускает генерацию и эмитит из AST-дерева итоговый код. Примерно так выглядит вся схема работы Babel и, на самом деле, практически любого другого инструмента, который занимается транспиляцией кода.
Давайте напишем плагин, который модифицирует приватные поля. Спойлер: у меня ничего не получилось. Расскажу, почему.
Как будет работать наш плагин? Давайте возьмем какой-нибудь класс, в котором есть приватное поле. Наш плагин Visitor будет заходить во все узлы AST-дерева, соответствующего классу, и в MemberExpression. Это узел, соответствующий операции доступа к полю в объекте.

Ссылка со слайда
Если объект, к которому мы обращаемся, this, то надо проверить, является ли поле приватным.

Ссылка со слайда
Для этого нужно подняться вверх по AST-дереву и найти декларацию этого поля. Тут нам повезло: она имеет модификатор private, значит, можно переименовать это поле.

Ссылка со слайда
Магия! Все работает, классно. Плагин готов.
Так я думал, пока не начал активнее его тестировать.

Ссылка со слайда
Рассмотрим пример. Тут мы добавили в наш класс еще один метод, внутри которого обращаемся к приватному полю не this, а другого инстанса этого класса. Это валидный код, мы обращаемся к приватному полю внутри класса, здесь все ок.
Но мой плагин при обработке этого кода делал вот такое. Почему так происходило? Потому что я сделал так, что мы ищем доступы к объекту this. Если же мы обращаемся к другому объекту, эти узлы AST-дерева мы не рассматриваем.
Окей, можно написать тут костыль, который будет рассматривать все MemberExpression и искать, а в данном случае — пытаться искать, поднимаясь вверх по AST-дереву, декларацию идентификатору foo. Здесь это легко, она описывается в теле функции, в заголовке функции. Можно понять, что у нее стоит тип foo, значит, это поле тоже нужно переименовать.
Звучит как какой-то костыль, будто нам не хватает информации о знании типа.

Ссылка со слайда
Рассмотрим еще один пример. Здесь мы this присваиваем переменную и обращаемся к полю bar из этой переменной. Это тоже валидный код. Но в итоге я получал такое. Здесь тоже нужен костыль, который будет разбирать такие обращения, искать, что this foo — на самом деле this, что у него тип foo. И в этом случае bar нужно точно так же переименовать.
В общем, я понял, что делаю нечто очень странное, мне явно чего-то не хватает. Чего-то — это информации о типах моих идентификаторов. Мои эксперименты вы можете посмотреть в этом репозитории, но, пожалуйста, не пытайтесь использовать их в продакшене.
Я расстроился и уже было похоронил эту идею.
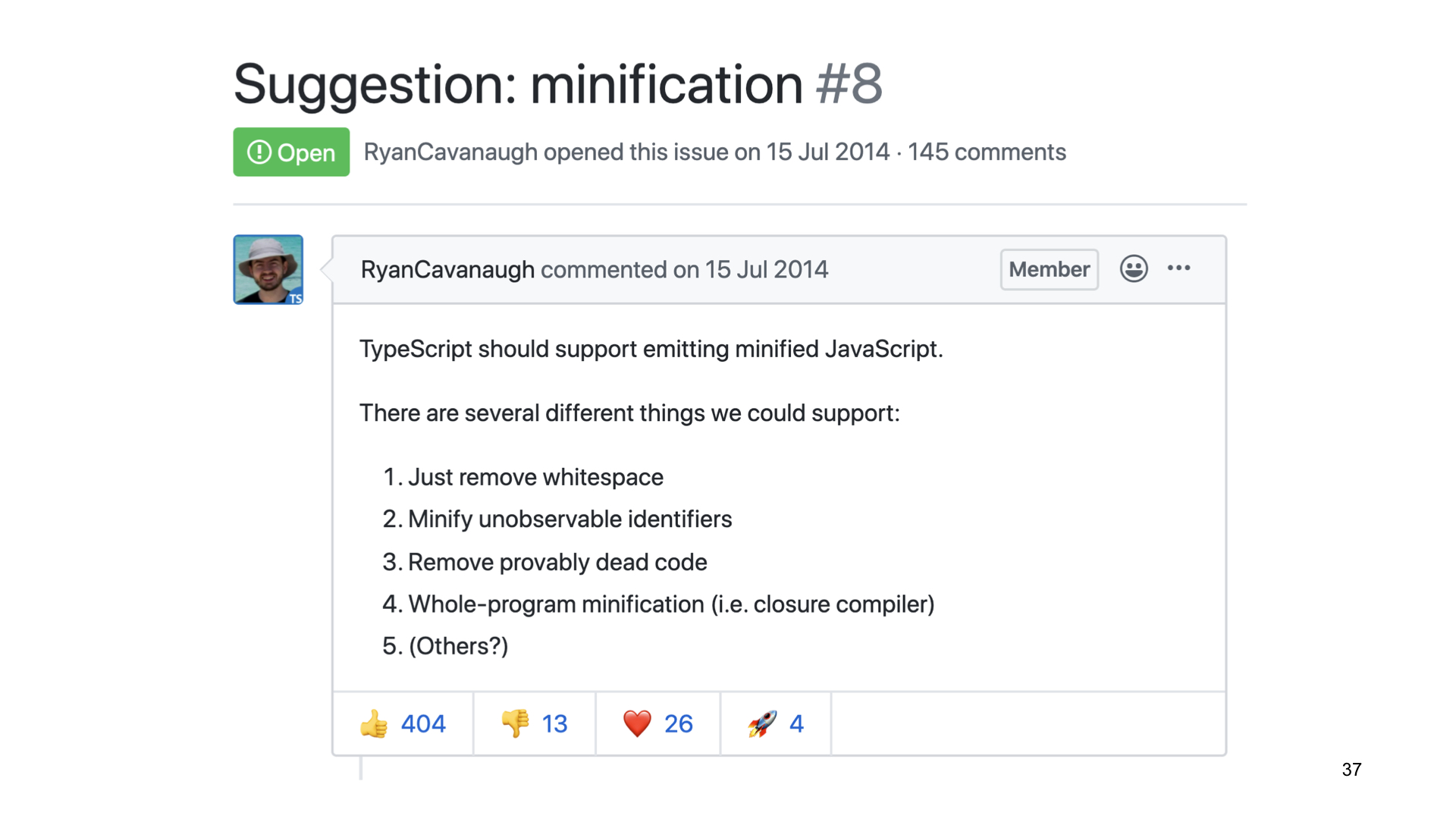
Но потом я вернулся в тот долгий тред про минификацию в TypeScript и увидел там комментарий Евгения Тимохова.
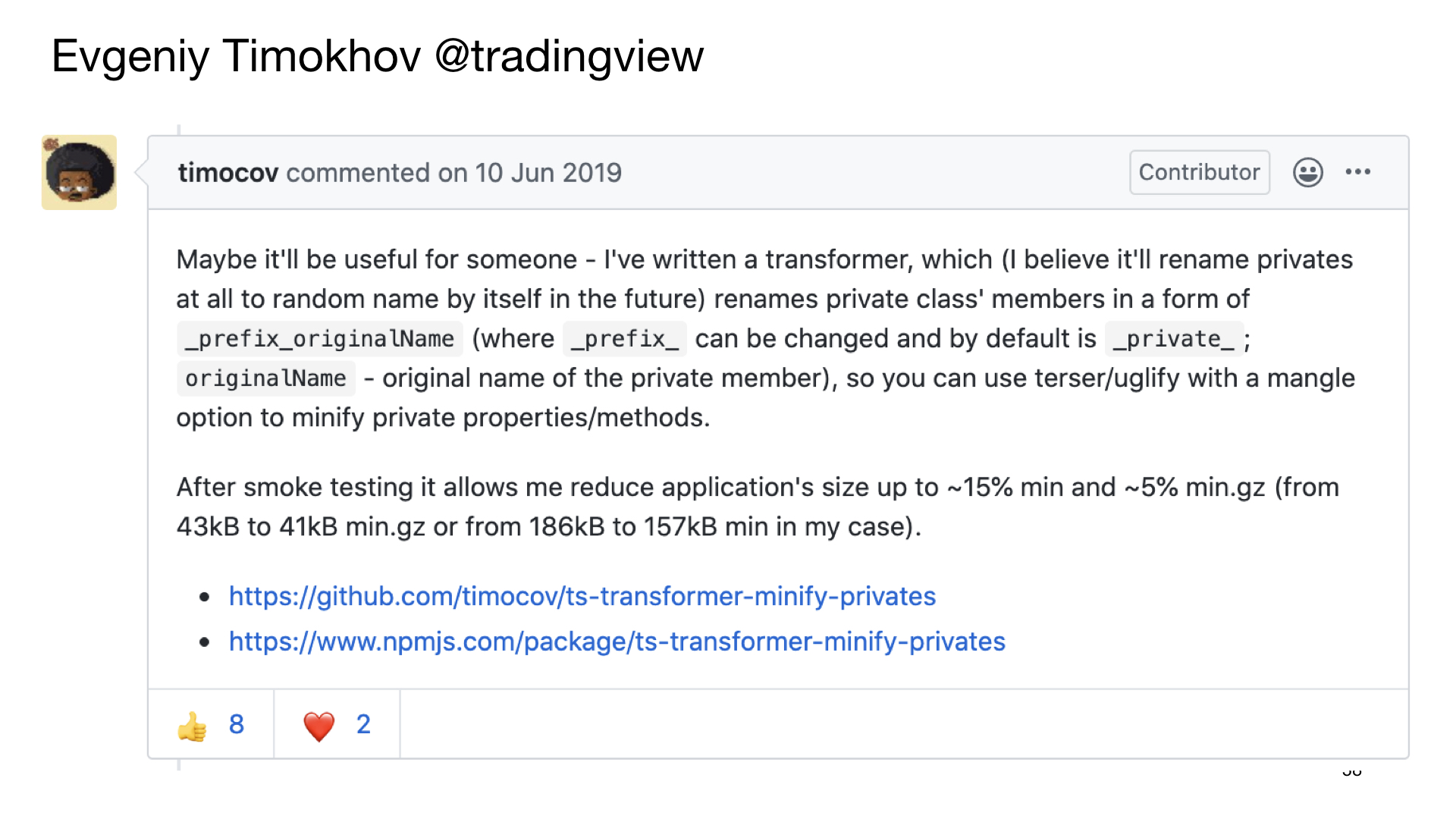
Он писал, что реализовал TypeScript в трансформер, который занимается минификацией приватных полей. И этот трансформер вроде бы даже работает.

У Евгения немножко другой подход. В своем трансформере он не переименовывает поля полностью, как я хотел, а добавляет к ним префикс, нижнее подчеркивание private нижнее подчеркивание.

Чтобы потом минифицировать такие поля, он предлагает использовать uglifyJS или terser, то есть uglifyJS с поддержкой ES6, и настроить минификацию полей, название которых соответствует регулярным выражениям.
Почему трансформер Евгения работает, а подход, который выбрал я, ни к чему не привел?
Ссылка со слайда
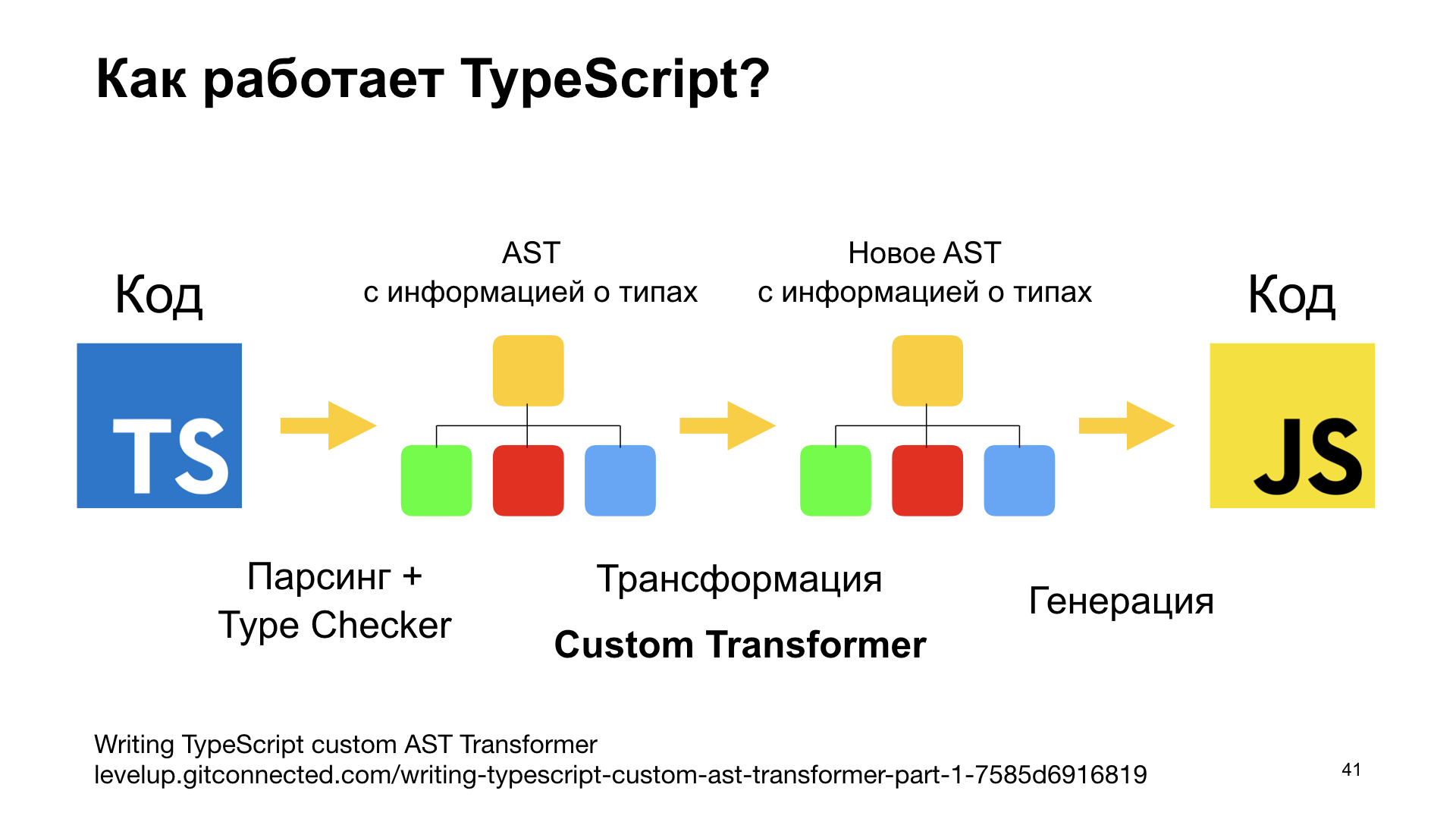
Тут нам потребуется немножко поговорить о том, как работает TypeScript. TypeScript — это ведь тоже транспойлер. Он занимается тем, что берет TypeScript-код и парсит его. Но вместе с парсингом TypeScript еще запускает Type Checker. И при построении AST-дерева TypeScript обогащает его информацией о типах идентификаторов. Это как раз та самая информация, которой мне не хватало в моем Babel-плагине.
Дальше компилятор TypeScript может трансформировать AST-дерево точно так же, как Babel. Построить новое AST-дерево и эмитить из него JavaScript-код.
На этапе трансформации можно подключить кастомный трансформер. Это точно такой же плагин, точно такая же сущность, как плагин Babel, только для TypeScript. Она использует такой же паттерн Visitor и реализует примерно те же идеи.
Как это все использовать? Проблема в том, что в CLI компилятора TypeScript нет возможности подключать кастомные трансформации. Если вы хотите такое делать, вам потребуется пакет ttypescript.

Ссылка со слайда
Это не опечатка, а обертка над компилятором TypeScript, которая позволяет в настройках компилятора в tsconfig указать возможность использовать кастомную трансформацию. Здесь кастомная трансформация будет просто браться из node_modules.

Ссылка со слайда
Такая фича есть и в ts-loader. Там тоже можно задать функцию getCustomTransformers, которая позволит вам применить кастомный трансформер на этапе сборки.

Когда я решил попробовать этот подход, то столкнулся с проблемой. У нас-то в проекте используется Babel и babel/preset-typescript. Как вы помните из рассказа, мы на него переехали из ts-loader и получили кучу профита, сделали кучу оптимизаций. Откатываться обратно и терять все это мне не хотелось.
Окей, будем делать свой велосипед еще раз. Как выглядит сейчас пайплайн сборки в моем проекте? Мы подгружаем TypeScript-код в Babel loader и эмитим из него JS. Тут мне нужна сущность, которая перед Babel позволит запускать TypeScript-трансформер.
В Babel этого сделать нельзя, потому что он не запускает компилятор TypeScript. Как я говорил, он просто вырезает модификаторы TypeScript из кода.
Ссылка со слайда
Идею такой сущности я подсмотрел в проекте react-docgen-typescript-loader. Это такой loader для webpack, который пригодится, если вы используете Storybook. Storybook — инструмент, который позволяет строить визуальные гайды и документацию к вашим React-компонентам.
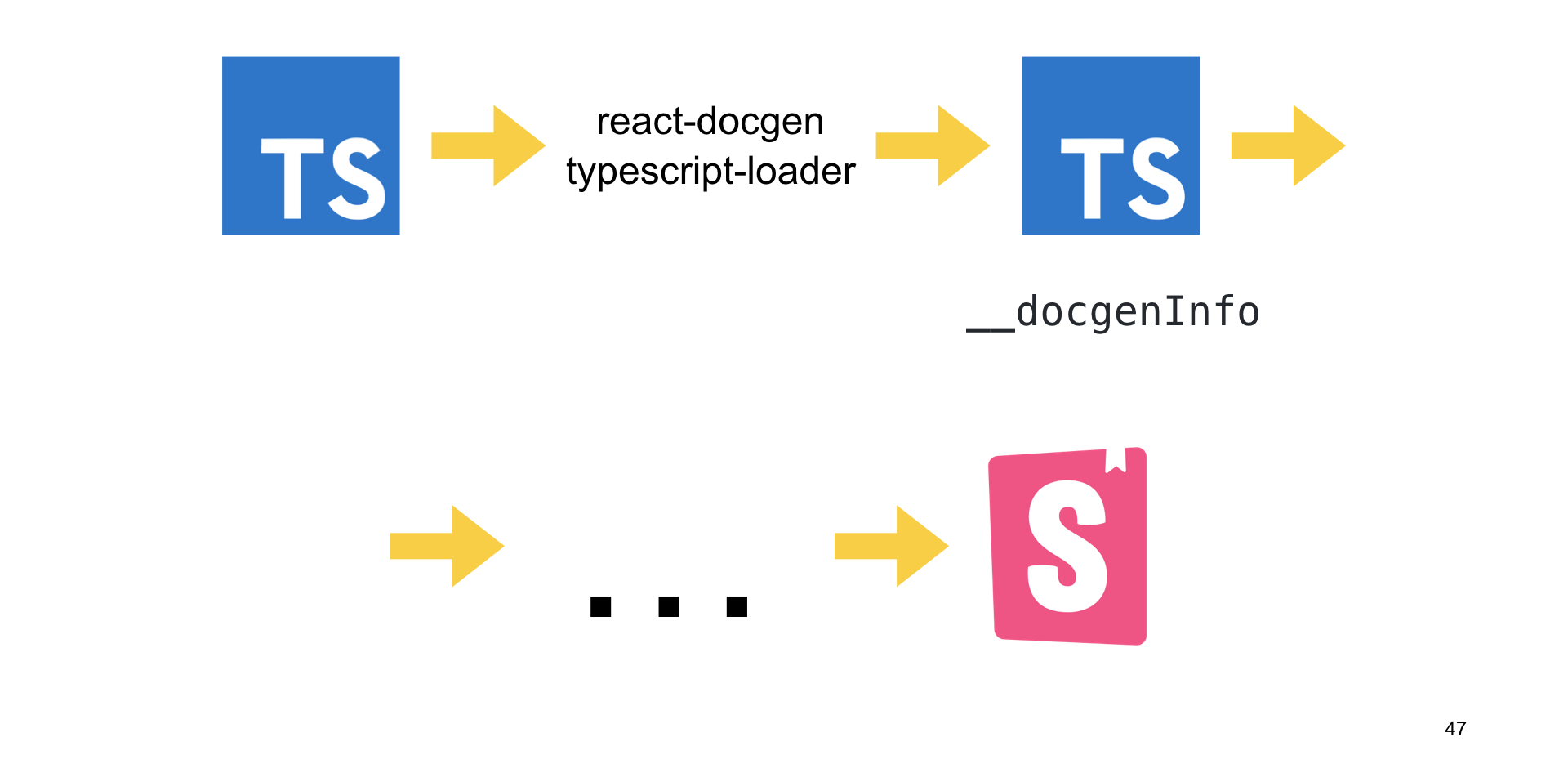
Чем занимается этот loader? Он подгружает TypeScript-код, обрабатывает его и эмитит TypeScript-код с дополнительными полями у React-компонентов. Поля называются docgenInfo, и в них содержится информация для Storybook, чтобы построить документацию к React-компоненту, используя не propTypes, а аннотации TypeScript.
Потом этот код, заэмиченный в react-docgen-typescript-loader, как-то обрабатывается. Например, с помощью TS loader и Babel. В итоге, когда он попадает в Storybook, тот успешно строит документацию по полям docgenInfo.
Мне нужна похожая штука. Мне нужен webpack loader. Как это сделать?

Ссылка со слайда
Webpack loader — это просто функция. Она принимает исходный код файла в виде строки и возвращает исходный код, тоже может его как-то модифицировать.
Здесь на слайде очень глупый loader, который занимается тем, что все ваши файлы превращает в код, содержащий console.log(«Hello World!»).

Ссылка со слайда
Loader может быть и синхронный. Можно получить callback, сделать асинхронную операцию. Вернее, что-то прочитать с диска или сделать что-то подобное и вызвать callback с новым модифицированным source.
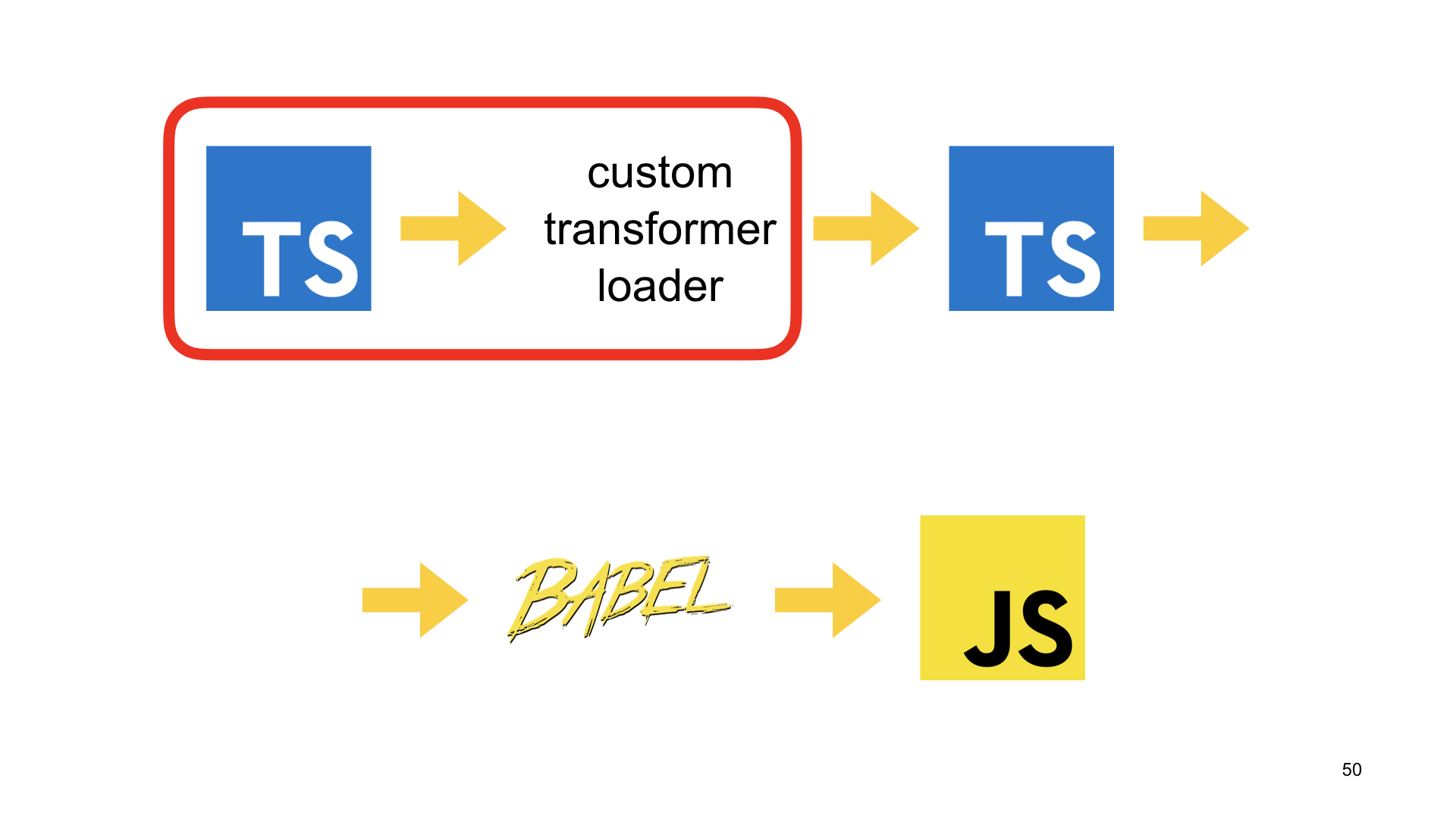
Какой пайплайн должен быть у меня? Мне нужен loader, который подгружает TypeScript, запускает на нем кастомный трансформер. Я хочу применить трансформер, который минифицирует приватные поля и эмитит TypeScript.
Дальше я смогу его обработать с помощью Babel loader, как я делал это сейчас, и эмитить JS. А «нашлепка» из моего кастомного loader будет опциональной. Если что-то пойдет не так, я всегда смогу ее отключить, и максимум, что я здесь потеряю, — минификацию приватных полей. И это не потребует от меня перестройки всего остального пайплайна сборки.
Окей, мы разобрались, как писать loader. Функция, которая обрабатывает source. Теперь нужно понять, как применить на наш файл кастомную TypeScript-трансформацию.

Ссылка со слайда
Для этого нам потребуется TypeScript Transformation API — как раз тот самый программный API, который позволяет обработать исходный код на TypeScript, применить к нему трансформацию и заэмитить TypeScript-код. Это то, что нужно моему loader.
Примерно как это работает? Сначала нужно получить TS program, это объект, который содержит коллекцию файлов и настройки компилятора TypeScript. Нам нужно распарсить исходный файл и получить для него AST. Потом мы трансформируем это дерево и подключаем здесь myCustomTransformer, нашу кастомную трансформацию. И получаем в переменной result новое AST. Дальше мы его можем сериализовать обратно в TypeScript-код. Этим занимается компонент printer.
Кажется, ничего не мешает использовать это в webpack loader. Единственная проблема: документация по Transformation API не очень хорошая. И вообще, документация по внутренним сущностям компилятора в TypeScript сильно проигрывает аналогичной документации Babel. Но если вы захотите окунуться в это, начать можно с пул-реквеста в репозитории в TypeScript, где Transformation API сделали публичной.
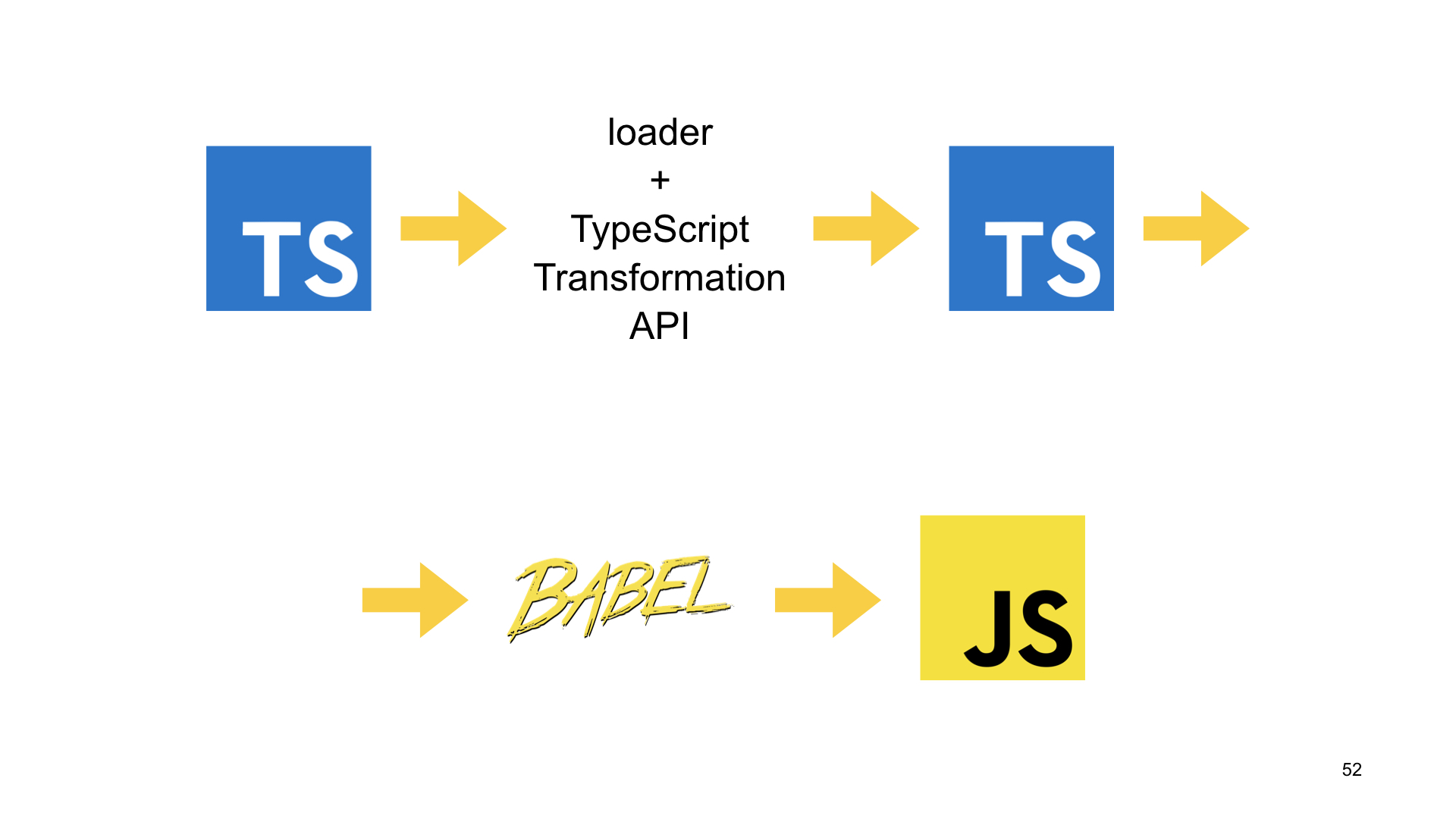
Итак, что в итоге делает мой loader? Подгружает TypeScript-код и с помощью TypeScript Transformation API применяет на него кастомную трансформацию. Эмитит уже модифицированный TypeScript-код обратно. Дальше я скармливаю его Babel, который эмитит JavaScript.
Итоговую реализацию loader я выложил в npm, можно посмотреть исходный код на GitHub и даже подключить и использовать в вашем проекте:
npm install -D ts-transformer-loader
Всю эту прекрасную конструкцию мы даже покатили в продакшен.

Какой профит дала вся эта возня? Сырой непожатый код нашего бандла уменьшился на 31 килобайт, это почти 5%. Результаты в gzip и brotli не такие классные, потому что код и повторяющиеся идентификаторы там и так хорошо сжимаются. Но выигрыш — порядка 2%.
Уменьшение непожатого кода на 5% — не очень крутой выигрыш. Но 2% в минифицированном коде, который вы гоняете по сети, можно даже заметить на мониторингах.
Вот ссылка на мои заметки. Спасибо.
Let's block ads! (Why?)