Анатолий Бардуков работал в «Яндексе», улучшая поиск по картинкам. В феврале 2020 года был приглашен в лондонский офис Revolut.
Правда, тогда же начался коронавирус… А потом был выявлен британский штамм...
Мы поговорили с ним о жизни IT-специалиста в Лондоне: о пинг-понге с карантинами и переездами, о местных (некомфортных) оупенспейсах, самом старом в мире метро, проблемах с электросамокатами и лондонском тумане. И о том, кому здесь все-таки стоит жить. Передаю Анатолию слово!
О своей истории с программированием
Я из тех, кто не очень доволен профессией. В разработку пришел в детстве, тогда это была в первую очередь работа над продуктом. Пока учился в школе в Уфе, делал с друзьями сайты, копался в коде игр. Тогда для меня программирование выглядело так: придумал интересную идею, разбил ее на маленькие задачи, и реализуешь, пока не увидишь итог.
Цели научиться программировать у меня не было, только задача сделать продукт, реализовать идею. То, что я научился программировать — побочный результат.
После школы переехал в Москву, поступил в ВШЭ. Если читают студенты: рекомендую воспользоваться академической мобильностью. Я не воспользовался, к сожалению. Со второго курса начал работать, параллельно учился, ходил на хакатоны. Они меня очень привлекали: это как раз цикл от идеи до конечного продукта. Не могу сказать, что много побеждал в хакатонах, но было интересно.
Потом заинтересовался machine learning, и попал в команду «Яндекс.Картинок»: занимался related images, строил связи картинок к картинкам.
В крупной компании оказалось, что от программиста готового продукта не ждут: хотят простой ежедневный кодинг. Приходишь и печатаешь символы, как станочник. По сути, это не креативность, а ремесло — я разочаровался.
Поэтому сейчас пытаюсь найти место, где пригодятся все мои навыки: по бэкенду, по фронтенду и всему, чему я научился. Поэтому в последнее время активно преподаю: в Сириусе в Сочи, в Школе Анализа Данных «Яндекса» в Израиле. Где-то работаю ассистентом, где-то семинаристом, где-то лектором.
Как я попал в Лондон
Через полтора года в «Яндексе» начал искать новую работу: почувствовал, что пора двигаться дальше. Заниматься одним и тем же проектом надоело — его качество повышалось, но очень медленно, и хотелось посмотреть мир, получить новый опыт.
Идея поменять страну не взялась с потолка: у меня много однокурсников, которые куда-то уехали. С десяток людей в Google, кто-то делает свои стартапы, кто-то успешно занимается наукой в Европе. Я тоже начал смотреть, куда можно податься.
До этого пробовал Google. Ездил в Мюнхен, проходил интервью 5 часов — но получил отказ. А после «Яндекса» и хакатонов снова искал новые возможности в компаниях попроще. Пусть не FAANG, но за границей.
Краем уха слышал, что есть банк Revolut, основан выходцем из России, знал об их офисах в Москве и Питере. Не было языкового барьера — это плюс. Так что я просто открыл LinkedIn и написал рекрутеру. Спросил, есть ли вакансии для Python-разработчика в главном офисе, и мне прислали вакансии в Лондон и Берлин.
Вообще-то я хотел в Берлин: и в Россию летать ближе, и город больше нравился. Но офис только открывался, команды питонистов пока не собралось. Поэтому я выбрал Лондон.
Прошел удаленное интервью, сделал тестовое на архитектуру и Python, пообщался с тимлидами и менеджерами. Меня приняли! Наконец смогу посмотреть мир, думал я, поработать за рубежом. Но это был февраль 2020 года… Как раз случился ковид.
С оффером в руках я сидел 8 месяцев. Продолжал работать в «Яндексе», передавал проект следующему поколению и ждал, что когда-то поеду. Лето провел в Москве, солнечное и приятное. В столицу Великобритании отправился только в первых числах декабря.
Работа в Лондоне и карантины
Офис был закрыт. Снимать квартиру дорого, такси и еда тоже выходили в копейку. Я рассчитывал, что скоро выйду в офис, и Лондон на самом деле стали открывать 3–6 декабря. Но тут, если помните, выявили британский штамм, и все закрыли еще более глухо, чем раньше.
Первый месяц аренду оплачивала компания — и этот месяц подходил к концу. Все закрыто, компания перешла на удаленный формат. Поэтому в январе я уехал обратно в Россию. И тут мне «повезло»: 3 января закрылись прямые перелеты из Англии в Россию. Но я смог кое-как добраться через Турцию — потом и способ стал недоступен.
В конце мая, когда сообщение между странами открылось, вернулся обратно в Лондон: 86% людей получили первую дозу вакцины, больше 50% получили вторую. Офис Revolut снова открылся. Хотя людей, как говорят, в нем в 10 раз меньше, чем до пандемии.
Сейчас снимаю жилье, работаю удаленно, изредка хожу в офис. Работаю middle data-engineer в отделе performance marketing, настраиваю процессы интеграции с рекламными платформами. Пока своей работой, скажем так, не недоволен. Переработок много, но когда компания вырастает за два года в несколько раз, понятно, что придется вкладываться.
Плюсы Лондона: почему здесь стоит жить?
Зарплаты! Если не считать Швейцарии, они лучшие в Европе. Даже с учетом местных (диких) налогов, легко получаешь больше, в Москве. Джуны-миддлы до вычета налогов получают £60—90 тысяч в год. На руки в итоге в месяц получается £3—5 тысяч фунтов — это без опционов. Опционы добавляют еще 20–30% заработка, а для сеньоров и лидов — больше. У меня есть опционы Revolut, это очень круто! За последние три года рост в 5 раз, и скоро еще готовится выход на IPO! Полезный сайтик, кстати, чтобы сравнить зарплаты — levels.fyi.
Отличная городская инфраструктура. Двухэтажные автобусы, под них выделены полосы. Весь центр обложен платными въездами и платными парковками, поэтому автобусы спокойно передвигаются, не стоят со всеми в пробках.
Плюс Лондона в сравнении с Берлином: перелет дольше, а по деньгам выходит дешевле. 3000 рублей в один конец с Wizzair было до пандемии.
Неказистое прикольное метро, с историей. Первое метро в мире, очень забавное. Маленькое, тесненькое, со своим особым шармом. Это совершенно другой опыт, чем в Москве: у нас метро помпезное, просторное, с размахом, лепниной. А здесь оно строилось настолько давно, что технологий просто не было. Иногда не работают некоторые ветки или закрываются станции. Вагоны маленькие, круглые, компактные. На входе даже приходится пригибаться. Для интроверта, которому не нравятся большие пространства — уютно.
Разноплановая и интересная архитектура. Здесь рай урбанистов. Широкие тротуары, узенькие дороги для машин. Исторические улицы, памятники архитектуры, низкоэтажная застройка с деревьями, вайбы из Гарри Поттера. Много новой архитектуры, особенно на Oxford Street, где над фасадами креативно издеваются, как могут. Хотя, если выезжаешь из центра — видишь дешевое социальное жилье, напоминающее хрущевки. Мой офис находится в Canary Wharf, тут крутые небоскребы, стеклянные здания по 50–70 этажей. А окружают его кварталы для иммигрантов, спальные районы. Есть все, что только можно придумать.
Разнообразная еда. Много азиатских и арабских блюд, очень популярно поке. Есть ощущение, правда, что вся еда при доставке — фастфудного толка. Ресторанов, предлагающих доставку, немного: к ним нужно идти ногами.
Просто переехать, нет головомойки. Получаешь оффер, показываешь, что знаешь английский, сдаешь тест на туберкулез. Сдаешь документы в посольство, ждешь месяц, и тебе дают визу на три месяца. По приезду меняешь визу на British Residence Permit, ВНЖ на три года, это такая карточка с твоими фото/фамилией/сроком действия. Если увольняешься, у тебя 60 дней, чтобы найти новую работу, чтобы он не аннулировался. Для семьи есть dependent виза. Просто доказываешь, что у тебя достаточно денег, чтобы семью обеспечить, и им можно переезжать. Можно, кстати, даже с гражданской женой.
Минусы Лондона: что нужно знать до переезда
Все дорого! Несмотря на размер моей зарплаты, свободных денег отстается на 10–20 тысяч рублей больше, чем в Москве. Аренда нормальной 1-bedroom квартиры стоит 140–180 тысяч рублей в месяц, если в долгосрок. В Москве такая стоила бы 60 тысяч. Еда тоже дорогая. Продукты в магазинах еще более-менее, всего на 10–15% дороже, чем в Москве. Но все нужно самому готовить, а в ресторанах и фастфудах разница в ценах с Москвой уже в 2 раза.
Такси нереально дорогое, приходится ездить в метро. Добраться из аэропорта до квартиры у меня стоило 5500 рублей (в Москве это было бы 1200 рублей за те же 40 минут). В Москве на зарплату программиста можно спокойно каждый день ездить на такси в комфорте и комфорт-плюсе. В Лондоне это может разорить.
Контракт на жилье заключается сразу на год. И если откажешься от съема — нужно найти себе замену, чтобы под твоим контрактом жил кто-то другой и платил. Иначе деньги сдерут с тебя. Поэтому я сейчас плачу краткосрочную аренду, месячную, на Airbnb. Пусть это и дороже, но можно съехать в любой момент.
Заметил, что в Британии очень любят оупенспейсы. Я к ним не очень хорошо отношусь. В Revolut тоже все сидят в оупенспейсе, даже основатель компании, Николай Сторонский. В плане эргономики у «Яндекса» более продуманные пространства: у каждого был свой квадрат, где можно чувствовать себя как в домике. Здесь такого нет. В лондонском офисе Google то же самое, хотя в Мюнхене у них довольно уютно.
Финансовых компаний в Лондоне сильно больше, чем в IT. Все-таки это в первую очередь финансовая столица Европы. Что накладывает отпечаток: разработчики для компаний здесь не на первом плане. Их не так высоко ценят и не берегут, как в Москве. Те же оупенспейсы, как будто ты швея на фабрике — один из показателей.
Не хотел бы звучать нетолерантно, но здесь много выходцев из Востока, из Африки. Я бы не сказал, что это плюс.
В целом здесь небезопасно. Я тут не так давно, но уже наслышан. У соседа одного из моих коллег пытались отобрать велосипед — он не отдал, его пырнули ножом. Есть карта crime rate Лондона, по районам. В Canary Wharf вроде бы еще спокойно, а соседние районы — показывает в 4–5 раз больше преступлений.
В Москве и Сочи мне понравились электрические самокаты. Когда раннее утро и мало людей — это довольно приятная штука. В Лондоне до недавнего времени ездить на электросамокатах возможности не было. Запрещали даже скейтборды, кататься можно было только на велосипеде, и по выделенным дорожкам. Когда я приехал второй раз, правила упростили, и электросамокатами можно пользоваться. Но бюрократии и ограничений все равно много: они работают только с 6 утра до 8 вечера, без прав кататься нельзя. По тротуарам — вроде бы тоже illegal, катайся по нормальной дороге. Мне на проезжую часть выезжать на самокате, да еще и с левосторонним движением, пока предельно некомфортно.
Погода тут мне нравится меньше. Я очень люблю ярко выраженную сезонность. Снежную зиму, цветущую весну, теплое лето. Может, потому что вырос в Уфе. Так вот, в Лондоне с этим плохо, все размазано. Зимой — от +5ºС, снег за декабрь я видел только один раз. Летом — до +25 ºС, и тоже не особо солнечно. То туман, то облака, то дождь. Туманный Альбион — это не стереотип, а реальность.
Пока что долго задерживаться в Лондоне я не планирую. Думаю, год-полтора мне хватит. Относительно Москвы не вижу больших улучшений. Мне кажется, по уровню жизни в целом Москва не хуже, особенно для программистов. По климату — даже лучше. Разве что если вам очень хочется солнца зимой и вы сталкиваетесь с недостатком витаминов.
Есть ощущение, что я никогда не стану британцем. Я буду «русским в Лондоне». Русскоговорящих здесь полно, войти в иностранную жизнь — очень просто (английский все в школе учили). Но кардинально новых ощущений и крутого опыта вы не получите. Поэтому если нет желания менять менталитет, выходить из зоны комфорта — вам здесь будет хорошо. Я бы рекомендовал.
Но для себя я бы хотел попробовать что-то потеплее, менее туманное. Смотрю на Эмираты, на Бали, на Кремниевую долину. И хочу все-таки делать что-то более предметное, чтобы видеть реальное влияние своей работы на пользователей.
В 2006 году Ктулху в русскоязычном интернет-пространстве был решительно везде.
И началось это, вопреки распространённому мнению, не с электронного голосования по выбору вопросов к пресс-конференции Путина, на котором 17 000 голосов (по тем временам – очень много!) получил вариант «Как вы относитесь к пробуждению Ктулху?».
Уже тот факт, что вопрос про Ктулху набрал почти 17 000 голосов и попал в топ-3 вопросов, указывает на уже существовавшую популярность персонажа у интернет-аудитории. Тогда как и почему осьминогоголовое божество прославилось в рунете?
Русскоязычная аудитория познакомилась с творчеством Лавкрафта достаточно поздно. Первые два издания во Владивостоке и Алма-Ате относятся только к 1990 году. Возможно, до этого существовали тексты из сам— и тамиздата – но сведений о них мне найти не удалось.
Массово печатать Лавкрафта на территории уже бывшего СССР начали с 1993 года. С этого времени Лавкрафт понемногу начал завоёвывать сердца и умы русскоязычных гиков и нёрдов, любителей фантастики и фэнтези, первых ролевиков и айтишников эпохи доклассического интернета с фидо.
Учитывая аудиторию первых русскоязычных почитателей Лавкрафта, неудивительно, что его тексты проникли в рунет в первые же годы его сколько-то пристойного и массового распространения. Лавкрафтианский раздел на сайте gothic.ru возник в июле 2001 года. Почти сразу после него, в августе того же года, появился первый отдельный русскоязычный сайт о творчестве HPL: www.lovecraft.ru. Однако никакого особого внимания конкретно к Ктулху тогда не существовало: Лавкрафт интересовал публику именно как автор «тёмного жанра».
В 2000—2001 годах Ктулху в зарождавшемся русскоязычном ЖЖ не упоминался ни разу. В 2002 в ЖЖ появилось 10 записей про Ктулху – и первой из них стала ирония древнего и почти забытого за прошедшие эоны тролля-удаффкомовца Пробежего: по поводу сходства текстов Проханова с Лавкрафтом.
В 2003 году упоминаний насчиталось уже 59, и чуть ли не большая их часть сводилась к повторению шутки о том, что «кхухоль — выхухоль, поклоняющаяся Ктулху». Похоже, этот давно забытый текстовый мем про Ктулху и стал первым в рунете.
Лавкрафтианское сообщество ru-lovecraft возникло в декабре 2003 года. Его первые посты мало отличались от уже упомянутых сайтов. Но в феврале — марте 2004 года в это сообщество и вообще в ЖЖ проникает американский предвыборный мем Cthulhu for President.
В Штатах он зародился ещё в 1996 году, и со слоганом «зачем выбирать меньшее зло?» он с тех пор сопровождает каждую президентскую кампанию. В феврале 2004 года в рунете он наложился на ожидание и обсуждения российских президентских выборов – и «зашёл» аудитории.
С этого начинается популяризация Ктулху в рунете уже не как одного из множества сущностей лавкрафтианской мифологии, а как самостоятельного персонажа и мема. В 2004 году постов с Ктулху было 129, в 2005-м – уже 290. Уже в конце 2004 года к обитателям ru-lovecraft обращаются как к «поклонникам Ктулху». В апреле 2005 ювелир-культист doochdoble заводит сообщество cthulhu-temple, где первым делом выкладывает своё меметичное изделие, «медаль за взятие Р’Льеха» с портретом Ктулху и лозунгом «Ктулху Фхтагн!». По записям этого времени отчётливо заметно, как он превращается в общеизвестного по умолчанию персонажа интернет-фольклора. Про него слагаются стихи и частушки, не говоря уже о гэгах и шутках.
Над седой равниной моря
Гордо реет страшный Ктулху —
Всех сожрёт, не поперхнувшись
И в пучину вновь нырнёт.
А вот в 2006-м записей с упоминаниями обитателя Р’Льеха насчитывалось уже 7554. ЖЖ и прочие русскоязычные интернеты охватила ктулхумания.
Поначалу прирост упоминаний продолжался примерно прежними темпами: 47 постов в январе, 83 в феврале, 87 в марте.
В последний день марта 2006 года в ЖЖ появляется сообщество ru-unspeakable, посвящённое переводу веб-комикса The Unspeakable Vault (of Doom). Его ироничное и, хм, жизнерадостное обыгрывание лавкрафтовских сюжетов с обилием чёрного юмора подхлестнуло популярность Ктулху ещё больше.
Апрель – 118, май — 152, июнь – 199.
Июль – 2433. Да-да, та самая пресс-конференция Путина 6 июля – и разлетевшаяся по рунету информация о том, что вопрос про Ктулху занял третье место. С этого момента Ктулху окончательно становится мемом, и очень скоро его щупальца проникают в самые отдалённые уголки русскоязычного интернета.
Вполне возможно, это осталось бы забытым казусом — но произошла история с пресс-конференцией в то самое время, когда рунет вступил в классическую эпоху мемов. Прославленный «Медвед» взорвал лепру и ЖЖ в феврале 2006 года. Он породил превед-сленг, потеснивший олбанско-падонкаффский йезыг, и создал повальную моду на самые весёлые, безумные и упоротые мемы.
Кстати, самым популярным вопросом Путину в том же голосовании с более чем 28 тысяч голосов стал именно он: «Превед, Владимир Владимирович! Как вы относитесь к медведу?». Ещё одним из топовых вопросов, ушедших в интернет-фольклор, стало «Собирается ли Россия использовать для защиты государственных рубежей огромных боевых человекоподобных роботов?».
(Чёрт, верните мне мой 2006-й!)
Абсолютно топовым временем по числу запросов и упоминаний Ктулху в рунете стала середина 2007 года: масла в огонь подлил всё более популярный башорг и одна из самых известных его цитат про «йа криветко», которую многие незамедлительно проассоциировали с Ктулху. Среди самых популярных его упоминаний оказались фразы «Ктулху зохаваит ффсех» и «Ктулху зохавал мой моск». Мемом стало даже возмущение блогера Транькова «да идите вы уже ***** со своим Ктулху!».
И всё же с 2008 года Ктулху начинает терять популярность вместе с Медведом и прочими классическими мемами рунета. К концу нулевых он становится всего лишь одним из многих культурных явлений русскоязычного интернета. Из памяти он не исчез, лишился привязки к мем-культуре 2006-8 годов, и по сей день остаётся общеизвестным — но и новых всплесков популярности более не получал.
Министерство здравоохранения провинции Буэнос-Айрес в Аргентине сообщает, что, согласно предварительным результатам продолжающегося исследования, комбинации вакцин Sputnik V с Sinopharm и Astrazeneca не выявили серьезных побочных эффектов.
У 41,6% вакцинированных не было никаких неприятных симптомов, связанных с вакцинацией, 8,4% указали на субфебрильную температуру и боль в спине, а 50% — на боль в области укола. 28,1% обследованных составляли женщины и 71,8% — мужчины, средний возраст 49 лет.
Провинция Буэнос-Айрес — одна из выбранных правительством для оценки реакции на использование разных вакцин. Исследования стартовали 7 июля; их цель — увеличение возможностей иммунизации. В министерстве объясняют, что группы волонтеров делятся случайным образом на комбинации вакцин, которые могут быть гетерологичными (из разных лабораторий) или гомологичными (из одной лаборатории).
К исследованию допускаются люди старше 18 лет без диагноза COVID-19, получившие первую дозу любой из вакцин, применяемых в провинции, за период от 7 до 45 дней до включения в исследование. Данных об эффективности комбинации вакцин пока нет.
На сегодня в Аргентине первой дозой привиты 24 919 053 человека, оба компонента получили 6 865 086 человек. В стране используют «Спутник V», а также препараты от AstraZeneca и Sinopharm.
Amazon получила рекордный штраф в размере 746 миллионов евро ($888 млн) за предполагаемые нарушения GDPR при показе поведенческой рекламы. Штраф наложила Люксембургская национальная комиссия по защите прав человека (CNPD) — регулятором, созданный для контроля законности сбора и использования личной информации.
«16 июля 2021 года (CNPD) вынесла решение против Amazon Europe Core, в котором утверждается, что обработка персональных данных Amazon не соответствует Общему регламенту ЕС по защите данных. Решение налагает штраф в размере 746 миллионов евро и соответствующие изменения в практике. Мы считаем решение CNPD необоснованным и намерены активно защищаться в этом вопросе», — указано в документе.
Решение основано на жалобе, которую против европейских подразделений Amazon (Amazon Europe Core SARL, Amazon EU SARL, Amazon Services Europe SARL и Amazon Media EU SARL), а также Amazon Video Limited подала La Quadrature du Net в 2018 году. В жалобе утверждается, что Amazon анализирует поведение пользователей для профилирования рекламы. Создание поведенческих профилей выполняется без согласия пользователя и, таким образом, нарушает GDPR.
Amazon сообщила в комментарии для BleepingComputer, что этот штраф не связан ни с утечкой данных, ни с несанкционированным доступом к данным клиентов, а, скорее, с организацией рекламного процесса. Amazon также заявляет, что, по мнению компании, решение основано на субъективной интерпретации закона о конфиденциальности GDPR.
«Мы категорически не согласны с решением CNPD и намерены подать апелляцию, — говорится в заявлении Amazon для BleepingComputer. — Решение основывается на субъективной и непроверенной интерпретации европейского закона о конфиденциальности, и предлагаемый штраф совершенно несоразмерен даже этой интерпретации».
Это самый крупный штраф, когда-либо наложенный Европейским союзом за нарушение GDPR. До этого решения самый крупный штраф составлял 50 миллионов евро ($56,6 миллиона на тот момент) против Google за неправильное получение согласия при обработке данных пользователя при создании учетной записи Google или демонстрации рекламы.
Модуль «Наука» пристыкован к МКС. Источник фото: Роскосмос.
30 июля 2021 года космонавты Олег Новицкий и Петр Дубров открыли переходные люки и впервые вошли с МКС на борт нового российского модуля «Наука». По их словам, там «визуально все в порядке, пыли нет».
Космонавты получили доступ в зону приборно-герметичный отсек лабораторного модуля «Наука». Они выполнили там контрольный осмотр отсеков, взяли пробы воздуха и установили агрегат фильтра очистки атмосферы.
Во время радиотрансляции переговоров при входе в «Науку» Новицкий рассказал специалисту центра управления полетов, что при открытии люка из модуля «вылетел болт длиной два сантиметра».
На старте в составе модуля полетело в качестве полезной нагрузки 200 кг научного оборудования и 300 кг специальных кронштейнов и креплений. Всего в дальнейшем на транспортных кораблях Роскосмос выведет еще 1,6 тонны научного оборудования для проведения экспериментов на «Науке».
Модуль «Наука» состыковался с МКС 29 июля. Через некоторое время после стыковки МКС развернулась на 45 градусов из-за незапланированного включения двигателей «Науки». Роскосмос пояснил, что это произошло из-за из-за программного сбоя. Сейчас МКС находится в штатной ориентации, все системы МКС и «Науки» работают нормально.
Пользователи решили выяснить, почему при запросе «Turn! Turn! Turn!» в Google на первом месте появляется внутренний калькулятор поисковика, отображающий значение «241217.524881». Видео на YouTube, где The Byrds исполняют одноименную песню Пита Сигера, появляется при этом лишь на второй строчке.
Выяснилось, что это число является численным приближением к Γ(2π+1)² / 2π, где Γ представляет собой гамма-функцию Эйлера.
Пользователи пишут, что Google интерпретирует «Turn» как 2π, а восклицательный знак как x!: = Γ (x + 1), поскольку это относительно распространенный, хотя и не универсальный вариант интерполяции факториальной функции к действительным числам. Однако, по их словам, более ожидаемо было бы, если бы Google интерпретировала «Turn! Turn! Turn!» для представления Γ (2π + 1)³ ≈ 18658774329 вместо приведенного выше выражения.
При этом, если выполняется поиск «Turn! Turn», то получается тот самый результат 7735.248 ≈ Γ (2π + 1) 2π. Но, если искать «Turn! Turn!», то ожидаемого результата Γ (2π + 1)² ≈ 1515614 не выводится, а получается 195,936, что, по-видимому, является численным приближением Γ (2π + 1) / (2π). Более того, Google повторно обрабатывает ввод как «Поверните! (Поверните!)». Пользователи отмечают, что говорит об интерпретации второго восклицательного знака как факториального символа, а первого как a!b: = b / a.
Это объясняет первоначальный результат, если Google интерпретирует «Turn! Turn! Turn!» с первым восклицательным знаком, представляющим обратное деление, но со вторым и третьим как факториалами:
По словам одного из энтузиастов, похоже, что поиск Google использует следующий синтаксис для преобразования между различными единицами измерения или валютами: target_unit! <выражение>. Например, при поиске cm! 1 м + 5 ярдов поисковик выдает 557,2 сантиметра. Интерпретируя поворот как безразмерную величину, равную 2π, поисковый запрос может звучать условно как «рассчитать поворот! И выразить его в единицах». Правда, позднее его поправили.
Синтаксис калькулятора Google и информация о единицах измерения есть тут.
Всем привет! Так уж выдалось, но я являюсь ромхакером в команде Russian Studio Video 7, которая когда-то занималась фанатскими переводами игр на наш великий и могучий. И, в одно время, мы пытались взломать множество игр, либо для того, чтобы перевести самим, либо на заказ, чтобы их перевели другие команды. И так уж получилось, что собралась куча проектов, которые мы начинали взламывать и взламывали до конца, либо забрасывали по причине лени или потери интереса.
О таких проектах я бы и хотел рассказать, запустив, так сказать, новую рубрику “Взломать, чтобы перевести”. И первая игра, попавшая в рубрику, будет культовая Resident Evil 4 на PS3.
Предисловие
Данная рубрика предполагает рассказ о устройстве либо какого-то определённого формата данных, либо о разборе вовсе всей игры для перевода.
В зависимости от игры будет рассказываться взлом либо каких-то определённых форматов данных, которые не были взломаны до сих пор, либо полный разбор игры для перевода.
Надеюсь, эта информация поможет кому-либо в будущем.
О Игре
Если верить игровым критикам, да и самим игрокам, то Resident Evil 4 вышла весьма культовой игрой. Новый сеттинг, интересный сюжет, необычный подход к игре жанра Survival Horror сыграл свою роль. Многие до сих пор считают, что Resident Evil 4 считается одной из лучшей игр серии.
Чего греха таить, когда я был слишком юн, то и я считал, что игра весьма прекрасна. После опыта Resident Evil на Sony Playstation 1, Resident Evil 4 вызывала много эмоций и в плане графики, и в плане геймплея. Она, в каком-то смысле, совершила революцию в жанре Survival Horror.
Но спустя время я вырос, оценил классические Resident Evil на Sony Playstaion 1, оценил Resident Evil 4. И, как ни странно, примкнул к любителям классических резидентов.
Изначально Resident Evil 4 вышла в начале 2005 года на игровую консоль Nintendo Gamecube и позже был портирована на Sony Playstation 2, Nintendo Wii и PC. И, до начала выпуска псевдо-HD ремастеров, версии для GameCube\Wii считались лучшими по графике, ибо данные платформы в разы были мощнее, чем Playstation 2.
К сожалению, версия игры для PC была портирована с урезанной по графике\эффектам версии для PlayStation 2. И переведена она была только для этих платформ. А про GameCube\Wii все забыли. Не в плане игры, а в плане перевода на наш великий и могучий. Возможно, повлияла малая популярность этих консолей на нашем рынке, но есть ещё один фактор, который мешает перевести эту игру для GameCube\Wii на русский язык, о котором будет сказано позже. И к сожалению, данный фактор влияет и на возможность перевода этой игры на PlayStation 3 в псевдо-HD варианте.
Первая проблема перевода
Но всё же, рассказ идёт про версию игры для Playstation 3.
И данная версия игра имеют одну особенность в основных игровых данных, мешающая переводу игры – чек-сумма в основных архивах.
Если изучить игры Capcom на Playstation 3, явно требующие перевода, то мы видим одну и ту же проблему – чек-сумма в игровых архивах. Она встречается не только в Resident Evil 4, но и в так же всеми любимыми среди фанатов Resident Evil: Code Veronica. И самое интересное то, что чек-сумма в игровых архивах встречается только на консоли PlayStaion 3. Именно из-за этого многие проекты Capcom так и не были переведены на русский язык для Playstation 3.
К сожалению, от игры к игре, алгоритм расчёта и размер чек-суммы отличался. Разбор алгоритма расчёта чек-суммы в одной игре, никак не помогал в разборе другой игры от Capcom. Но, повезло тем играм, где контроля чек-суммы не было вовсе.
Вернёмся к основной теме – чек-сумма данных в Resident Evil 4 на Playstation 3.
Игра была построена на базе HD переиздания PC версии, что влекло за собой новый игровой движок и новый формат хранения данных. То, что игра была построена на PC версии сыграло большую роль в разборе алгоритма расчёта чек-суммы, но об этом позже.
Все игровые данные прятались за неким форматом LFS. Он из себя представлял информацию о сжатом файле и о количестве секций, на которые он разделён. Для PC и Xbox360 каждая секция сжималась алгоритмом, который в сообществе ромхакеров называется “xmemdecompress”. Это алгоритм сжатия, который Microsoft внедрила в SDK Xbox360. Данный алгоритм сжатия базируется на алгоритме сжатия LZX.
Но, тут в игру вступает Playstation 3. К большому сожалению, она не использовала данный алгоритм сжатия для секций, она хранила данные в «сыром виде», но, для каждой секции добавились новые 4 байта – чек-сумма. И любой изменённый байт ломал загрузку игры, т.к. файл не проходил проверку.
Именно тут я приступил к разбору алгоритма расчёта чек-суммы. 4 байта намекали на то, что алгоритм расчёта чек-суммы может быть из семейства обычного CRC32. Но, расчёт CRC32 со стандартными значениями полинома, выходного XOR и начального значения выводил результат, не соответствующий тому, что я видел в файле после каждой секции.
Больше не было выбора, как закинуть исполняемый файл в дизассемблер и попробовать найти кусок кода, отвечающий за расчёт чек-суммы. Основная идея лежала в том, чтобы отключить проверку вовсе, а не пытаться разобрать алгоритм расчёта чек-суммы.
Потратив несколько дней на изучение исполняемого файла Playstation 3 в дизассемблере, я так и не смог найти кусок кода, отвечающего за расчёт чек-суммы. Тут повлияло много факторов, как мой малый опыт в разборе кода на таком низком уровне, так и сложность самой архитектуры Cell, используемой в Playstation 3.
В один момент я подумал, что версия игры для PC построена на том же игровом движке, что и на Playstation 3, и, возможно, там мог остаться кусок кода, отвечающий за расчёт чек-суммы.
В PC версии игры в игровых архивах не было чек-суммы секций, как это было в Playstation 3 версии игры, но, надеясь на удачу, я решил изучить исполняемый файл PC версии игры. С помощью нескольких манипуляций я смог найти функцию, отвечающую за чтение основных игровых архивов. Немного попрыгав по функциям внутри, я заметил весьма интересный кусок кода, который был похож на расчёт чего-то. Это и был тот самый алгоритм расчёта чек-суммы.
Как я и говорил ранее, всё было очень похоже на обычный CRC32, но, входные данные для начала расчёта отличались от тех, которые были предположены по умолчанию алгоритмом CRC32.
Всё оказалось весьма просто, полином соответствовал значению по умолчанию – 0x4C11DB7, но значение выходного XOR и начальное значение для расчёт отличались от стандартных параметров.
Если в стандартном алгоритме CRC32 начальное значение и значение выходного XOR соответствует 0xFFFFFFFF, то в текущем алгоритме расчёта чек-суммы эти значения соответствовали 0.
Вроде бы, простые правки в начальных значениях стандартного алгоритма расчёта чек-суммы, но додуматься до этого не возможно.
Вторая проблема перевода
Разобрав, по факту, самую сложную часть, можно было бы разбирать то, что хранится за этим архивом и переводить игру, но не всё так просто.
Ранее я упоминал о том, что версия для GameCube\Wii не переведена до сих пор из-за определённого фактора, а версия для Playstation 3, почему-то, не сжимает секции в основных архивах, как это делается в версии для PC и Xbox360. Вся проблема заключается в специфичном для Gamecube, Wii и Playstation 3 сжатии, которое до сих пор никто не разобрал.
Gamecube версия игры использовала на то время весьма сильное и специфичное сжатие, которое никто не разобрал до сих пор и именно из-за этого игра не переведена на эту прекрасную платформу. Можно понять, почему для GameCube версии использовалось это сжатие. Диски на Gamecube имели размер в 1.4гб (против 4.7 на PS2) и игра еле умещалась на 2 диска. Версия для Wii была аналогична версии для Gamecube, т.к. эти платформы имели идентичную архитектуру и портирование не требовало много человеко-ресурсов. Но, почему Capcom решила использовать внутри LFS для Playstation 3 формат игровых данных с GameCube, используя тоже сжатие? Этот вопрос до сих пор остаётся открытым.
Мои попытки разобрать алгоритм сжатия приводили к краху, но, может, когда-нибудь…
Заключение
В данной статье я хотел рассказать, с какими проблемами часто встречаются ромхакеры, чтобы перевести ту или иную игру и насколько игровые данные могут отличаться между платформами.
Если Вам интересна тематика, то пишите в комментарии, в багаже ещё много подобных историй :)
Так выглядит предыдущее поколение процессора с 256 ядрами
На днях китайская компания Ziguang заявила о создании необычного чипа, в котором не 4, 8 или 16 ядер, а сразу 512. Чип выполнен по 7-нм техпроцессу.
Называется новый процессор H3C Engiant 800. Компания, которая его создала, не является новичком в отрасли. Дело в том, что она — часть холдинга Tsinghua Unigroup. В него же входит Unisoc, разрабатывающая мобильные процессоры, и Yangtze Memory, которая создает чипы памяти.
Количество транзисторов процессора превышает 40 млрд, благодаря чему чип весьма производительный. Кто будет заниматься его производством — пока неясно, поскольку у компании, насколько известно, нет своих фабрик по выпуску чипов.
К сожалению, неизвестно, на какой архитектуре базируется чип. Зато компания сообщила, что это не потребительский процессор, он не будет поставляться производителям потребительской электроники вроде смартфонов или ноутбуков.
Его главная задача — работа в телекоммуникационных системах, где он будет обрабатывать данные в сетях пятого поколения. Кроме того, его смогут использовать и разработчики технологий искусственного интеллекта.
Вполне может быть, что чип отправится на предприятия госсектора, поскольку именно правительственные организации являются основными клиентами H3C Group.
Процессор H3C Engiant 800, согласно объявленным компанией планам, будет доступен уже с 2022 года. Ну а крупнейшие покупатели получат тестовые образцы чипа еще раньше — вероятно, до конца 2021 года.
Что касается предыдущей версии чипа, то это был процессор H3C Engiant 600, в состав которого входят 256 ядер и 18 млрд транзисторов. Сейчас он используется в телекоммуникационном оборудовании, которое поставляется китайским операторам связи.
Новый процесс на 122% производительнее старого. Он открывает линейку чипов ZhiQing, предназначенных для сетевого оборудования.
Не совсем рекордсмен
Весной этого года мы писали о еще более необычном процессоре, размер которого равен размеру кремниевой пластины. Называется он WSE-2: 7-нм, это чип с 850 тысячами ядер и энергопотреблением в 15 кВт Процессор предназначен для дата-центров, задач по обработке вычислений в области машинного обучения и искусственного интеллекта (AI).
У чипа WSE-2 40 ГБ встроенной памяти SRAM. Пропускная способность составляет 20 Пб/с. При этом энергопотребление — 15 кВт.
Чип сам по себе бесполезен, но компания специально для него разработала систему 15U, которая заточена исключительно под характеристики WSE-2. Система второго поколения почти ничем не отличается от системы первого. Блоки первого поколения ранее были отправлены заказчикам. Один из них установлен в Аргоннской национальной лаборатории министерства энергетики США. Она использует первую систему для научных целей — например, изучения черных дыр, а также для работы с медицинскими проблемами вроде анализа причин раковых заболеваний. Другим заказчиком стала Ливерморская национальная лаборатория.
Групповые видеозвонки в Telegram теперь поддерживают до тысячи зрителей. Кроме того, в новой версии мессенджера можно просматривать видеозаписи в ускоренном или замедленном режиме, а качество видеосообщений улучшилось.
«В режиме видеоконференции могут одновременно транслировать видео с камеры или изображение с экрана до 30 участников. С сегодняшнего дня видеоконференции также поддерживают до 1000 зрителей — благодаря чему через Telegram можно смотреть трансляции лекций, концертов и других массовых мероприятий», — сообщает команда мессенджера.
Чтобы запустить конференцию, необходимо выбрать «Голосовой чат» в профиле группы, в которой пользователь является администратором, а затем включить трансляцию видео. Для пользователей iOS кнопка «Аудиочат» доступна прямо из профиля группы.
Качество и разрешение изображения в видеосообщениях улучшилось, а если нажать на полученное видеосообщение, оно развернется на всю ширину чата. Видеосообщения также можно будет перематывать.
Обновился также медиаплеер Telegram: теперь можно замедлить или ускорить видеозапись, выбрав скорость 0.5, 1.5 или 2Х. На Android также поддерживается скорость 0.2x.
В новой версии транслировать экран можно как в групповых видеозвонках, так и в звонках между двумя пользователями. При этом транслируется не только изображение, но и звук с устройства.
Таймер автоматического удаления сообщений в чатах теперь можно установить на 1 месяц — в дополнение к 1 дню и 1 неделе. В медиаредакторе можно добавить рисунок, текст или стикер к фотографии или видеозаписи перед отправкой. Редактор изображений также будет работать и в десктопной версии мессенджера.
iOS-версия Telegram позволяет выбирать уровень приближения от 0,5 до 2х при съемке видеозаписей и фотографий. Среди других нововведений для iOS — возможность пересылки сообщения сразу нескольким адресатам.
Microsoft недавно опубликовали свое исследование в 2-х частях. Уже достаточно известный вредонос продолжает активно совершенствоваться и использовать в качестве таргетов Windows и Linux-системы.
На сегодняшний день является активно разрабатываемым и регулярно обновляемым вредоносом. LemonDuck прежде всего известен своими майнинговыми целями. Спустя некоторые время он эволюционировал в своих действиях: кража паролей, использование множества известных уязвимостей, отключение средств защиты и другие возможности. В конечном итоге, способен использоваться как бэкдор и доставлять дополнительные инструменты, управляемые человеком.
Одной из главных особенностей LemonDuck является зачистка посторонней малвари/майнеров со скомпрометированного устройства, дабы избавиться от своих конкурентов. Также исправляет уязвимости, которые уже использовались для получения доступа к системе.
В своем исследовании Microsoft описывают компанию LemonCat, которая связана с LemonDuck. Эксперты считают, что LemonCat является таргетированной интерпретацией предшественника, имеет другии цели и используется для более опасных операций. Новая версия активна с января 2021 года. Отличительной чертой указано то, что она применялась в атаках на уязвимые серверы Microsoft Exchange, и эти инциденты приводили к установке бэкдора, хищению информации с последующей установкой трояна Ramnit.
Технические подробности
Изначально LemonDuck был обнаружен в Китае в мае 2019 года, но с тех пор его деятельность расширилась. На текущий момент он имеет широкую географию распространения: больше всего наблюдаются в США, России, Китае, Германии, Великобритании, Индии, Корее, Канаде, Франции и Вьетнаме.
В 2021 году LemonDuck начала использовать более диверсифицированную инфраструктуру и функционал классической полезной нагрузки (C2). Это обновление способствовало заметному увеличению количества действий после взлома, которые варьировались в зависимости от ценности скомпрометированных устройств для злоумышленников. Однако, несмотря на все эти обновления, LemonDuck по-прежнему использует C2, функций, структур сценариев и имен переменных гораздо дольше, чем у большинства вредоносов. Вероятно, это связано с использованием сверхнадежных хостинг-провайдеров, таких как Epik Holdings, которые вряд ли когда-нибудь отключат хотя бы часть инфраструктуры LemonDuck даже в случае получения сообщений о вредоносных действиях, что позволяет LemonDuck выживать и продолжать свою активность.
инфраструктура LemonDuck
Первичное проникновение/пробив/попадание в инфраструктуру LemonDuck выполняет двумя основными способами:
При содействии существующих ботов, уже перемещающихся по организации.
Почтовый фишинг.
После проникновения малварь выполняет поиск устройств с такими уязвимостями, как CVE-2017-0144 (EternalBlue), CVE-2017-8464 (LNK RCE), CVE-2019-0708 (BlueKeep), CVE-2020-0796 (SMBGhost), CVE-2021-26855 (ProxyLogon), CVE-2021-26857 (ProxyLogon), CVE-2021-26858 (ProxyLogon) и CVE-2021-27065 (ProxyLogon). Также выполняется поиск слабой аутентификации, либо открытых SMB, Exchange, SQL, Hadoop, REDIS, RDP и т.д.
После попадания на хост с почтовым ящиком Outlook, в рамках своего обычного поведения, LemonDuck пытается запустить сценарий, использующий учетные данные, полученные на устройстве. Сценарий дает указание почтовому ящику отправлять копии фишингового сообщения с предустановленными сообщениями и вложениями всем контактам организации. Это позволяет обходить большинство политик безопасности электронной почты, скоращая количество проверок для отправки писем внутри организации.
«LemonDuck пытается автоматически отключить Microsoft Defender для мониторинга конечных точек и добавляет целые диски - в частности, диск C: \ - в список исключений Microsoft Defender», - группа аналитики угроз Microsoft 365 Defender, рассказывая о тактике вредоноса, которая была недавно раскрыта.
Также сообщается, что часть атак использует широкий спектр opensource-инструментов, включая настраиваемые инструменты для получения учетных данных, перемещения по сети, повышения привилегий и даже удаления следов всех других ботнетов, майнеров и ВПО конкурентов со скомпрометированных устройств.
– Здравствуйте, @*! Спасибо, что согласились поговорить со мной!
– Саша, я к вашим услугам. За миллион долларов в секунду я с вами хоть все десять минут, пока держит канал.
– Времени мало, предлагаю писать кратко, чтобы больше успеть. Хорошо?
– Кнчн
– Ну можно и не так коротко)) Интересует производство Жемчужин сознания. Хочу построить фабрику.
– Это ДОРОГО
– Понимаю, @*, но я получил большое наследство. Как вообще делаются жемчужины сознания?
– Исходный объект подвергается сильным перегрузкам и облучению. В результате несколько сот тонн сжимаются до шарика в 10 грамм.
– Исходный объект - что это?
– Это мозг местных созданий, похожих на китов. Я так их и называю - *киты.
– Ох, блин! Это же не этично — делать товар из живых существ! Мне что, придется их убивать?? Интересно, каким оружием...
– Они уже мертвы. Первая экспедиция занесла инфекцию, которая моментально убила всех *китов.
– А они там... не испортятся, плавая в воде?
– Тут не вода, а жидкий метан. Его температура: -170 градусов по Цельсию. Трупы сохраняются вечно. Собственно *киты — бессмертны. Были.
– Ясненько! Т.е. мне надо просто вылавливать трупы, потом крутить на какой-нибудь центрифуге для перегрузок и облучать. Все? Звучит не сложно.
– Еще нужна медицинская клиника для пересадки жемчужины сознания в мозг человека.
– Так вроде вставил — и все.
– В каждом шарике жемчужины находится от 100 до 500 миллиардов коннекторов. Нужен очень точный робот-хирург. Представляете, высушенный 100 тонный мозг нужно подключить к другому!
– Все понял! Подскажите, @*, где мне раздобыть информацию о там, как строить завод и клинику? Чертежи там какие-нибудь.
– Все чертежи, схемы и ПО я могу предоставить за отдельную плату. Просто сделайте мне перевод на $1 000 000 000 000.
– Ого! Ну ничего, я потяну)) На какой счет?
– Номер счета: @*
– Удобно! Вот бы и у меня был номер счета: Саша)) Инициировал перевод.
[ПРОХОЖДЕНИЕ ТРАНЗАКЦИИ]
– Платеж получен. Я открою вам параллельный канал для загрузки проектной документации.
– Уже не терпится начать! Наконец-то я всем покажу! Они перестанут говорить, что я тупой сынок олигарха!
– Саша, кому вы планируете продавать Жемчужины сознания?
– @*, я никому не буду их продавать! Все жемчужины для меня!
– Вы же... знаете, как они работают? Уверены?
– Уверен! Я наделаю на своей фабрике кучу этих шариков сознания и запихну себе в мозг! А вы что, против???
– Саша, я только за! Мне самой интересно посмотреть, что получится. Вы — безрассудный... я хотела сказать, смелый человек.
– А вы, @*, вставляли себе Жемчужину сознания? Вы же из той самой первой экспедиции? Иначе откуда вы все знаете?
– Все участники первой экспедиции погибли. Я — местная жительница. Инопланетянка по-вашему))
– Ё-мае! Подождите, вы же говорили, что там у вас все погибли от вируса!
– Погибли все *киты. На * жили не только они, но и я.
– Ха, отлично, что вы выжили, ведь теперь мы можем вставить жемчужину сознания и удвоиться! Одна голова хорошо, а две — лучше! Для начала я хочу вставить себе 100 жемчужин, чтобы стать в 100 раз круче!
– Каждая жемчужина удваивает сознание. Сто штук — это два в степени 100. У вас Саша сознаний будет больше, чем атомов во вселенной!
– Э-э-э..., а как они мне в голову-то все влезут?
– «Сознания», которые дают жемчужины — это лишь варианты восприятия действительности. Это нематериальные сущности. Не беспокойтесь!
– Я говорил с одним чуваком, у которого в голове эта штука — так он явно умный. Это для меня главное.
– Что же, вы явно почувствуете разницу, Саша! Время заканчивается, до свидания!
– Чао, @*!
[ПЯТЬ ЛЕТ СПУСТЯ]
– Здравствуйте, Саша! Прошли уже сутки с того момента, как вы вставили себе в голову 100 Жемчужин сознания. Расскажите о ваших ощущениях.
– Привет, @*! Видимо, жемчужины еще не начали работать.
– Почему?
– Да что-то мозги не стали быстрее шевелиться. Мне, наверное, достались бракованные *киты!
– Саша, вам достались самые отборные трупы *китов! Давайте проверим действия жемчужин. Возьмите монетку и подкиньте её. Пока будет лететь, скажите вслух, что выпадет: орёл или решка?
– … ух ты! Подкидывал много раз и каждый раз отгадывал! Я что, ясновидящем стал?
– У вас огромное количество вариантов восприятия действительности, Саша. То, что для других
случайность, для вас теперь — закономерность.
– Чего?
– Совместная работа Жемчужин сознания выделяет в событиях невидимые для других тренды за счет усреднения миллиардов и миллиардов вариантов. Если быть точным, то вариантов: 2 в степени 100, а именно 1 267 650 600 228 229 401 496 703 205 376.
– Погодите, а биржевые курсы или нет... курс Биткоина я тоже смогу предсказывать?!
– Конечно.
– ОФИГЕТЬ! Ну все...
– Только, Саша...
– ТЕПЕРЬ Я ВСЕМ ПОКАЖУ!!!
– … будьте осторожны!
– В смысле осторожен? Я хочу отбить триллион, который вложил в фабрику!
– Дело в том, что чем более сложные вопросы вы перед собой ставите, тем на более долгое время «зависаете». Для простых вопросов, типа анализа финансовых рынков — это миллисекунды. Более сложные вопросы могут погрузить вас в кому, причем, на целые минуты.
– А сложные, это какие?
– Ну, Саша, подумайте, например, как я - единственное оставшееся в живых существо на * - могу отомстить человечеству?
– Мне пофиг, я же теперь могу столько заработать...
– А вы подумайте, Саша! Ведь люди уничтожили все живое на моей планете. Мне же хочется отомстить!
– Да какая мне разница. Хотели бы — отомстили!
– Я не могу придумать, как. Я всего лишь @*! А вот вы — человек, объединивший в себе мозги ста *китов! Как бы я могла отомстить людям, Саша?
– Ну, не знаю. Например...
– … я подожду ответ.
[ТЫСЯЧУ ЛЕТ СПУСТЯ]
НОВОСТЬ ДНЯ: Впавший в кому тысячу лет назад сын олигарха, очнулся!
Добро пожаловать в наше уютное конспирологическое логово. Сегодня мы будем рассматривать тени на фотографиях с Марса, округлять числа и писать отвратительный код.
Автор (справа) и предмет исследования (слева)
В этом выпуске: астрономические наблюдения теней в пустыне, аугментация ушей, заглядывание за левый край видео, гадание по фотографиям и особенности работы GSCMOS матриц семилетней давности.
Маленький вертолет летает на Марсе, но где летает Марс? Насколько он дальше от Солнца чем Земля? Насколько меньше света достается камерам и солнечной батарейке?
У меня нет фотографии солнечной батарейки, чтобы по ней гадать, зато есть фотография тени от солнечной батарейки:
https://ift.tt/37b6nJO
Тень должна быть шириной с саму батарейку (165мм), ведь лучи от солнца параллельны. Можно взять ширину тени на фото и пересчитать пиксели в миллиметры.
2086 пикселей = 165мм. 0.079мм/пиксель.
Зачем нам это, и почему где-то в середине тени, а не по её верхней границе? Потому что перспектива заваливает размеры, а именно на этой линии слева нет особо крупных камней.
Как раз там, где тень переходит в свет.
Солнце, хоть и находится очень далеко, имеет заметный угловой размер на небе и границы теней от него не идеально резкие. Хуже того, ширина полутени (L) очень просто зависит от расстояния до предмета отбрасывающего тень (h), и углового размера Солнца (a)
Вооружившись этим знанием, а так-же тем, что высота Ingenuity составляет 49см, а солнечная батарея находится на самой его макушке, мы можем прикинуть, насколько далеко находится Марс.
Для начала измерим полутень. Песок и камни мешают это сделать вручную, но их можно усреднить. Повернем фотографию так, чтобы граница тени была строго вертикальна, берем кусок без камней, и сохраняем.
Дальше надо преобразовать картинку в Ч/Б, усреднить все строки и построить график яркости от координаты X. 10 строчек на питоне:
import sys
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
im = Image.open(sys.argv[1]).convert('L')
im.resize((im.size[0],1), Image.ANTIALIAS)
plt.plot(np.arange(im.size[0]), np.array(im).mean(axis=0))
plt.show()
Яркость начинает падать примерно на x=43 и перестает на x=80. Ширина полутени получается 37 пикселей, или ~3мм.
Теперь, проведем такой-же эксперимент на Земле. Тень от предмета на расстоянии 49см:
Рядом нарисован один стандартный нарисованный сантиметр
Ширина полутени получилась 4.56мм. Делим одно на другое и узнаем, насколько Марс дальше от Солнца, чем Земля: 4.56/3 = 1.52. А значит света на Марсе в 1.52^2 ≈ 2.3 раза меньше (без учета особенностей атмосфер обоих планет).
Теперь, расстояние от Солнца до Марса: отношение полутени к высоте солнечной батареи 3/490 = 0.00612. Диаметр солнца 1.3927 миллионов километров, значит расстояние 1.3927/0.00612 = 227.5 миллионов километров.
1.2 Ошибки?
На самом деле расстояние от Марса до Солнца меняется от 249.2 до 206.7 миллионов км в течении года. А в день когда было сделано фото (9 апреля 2021), оно составляло 242.8 (подсмотрено в Stellarium). А соотношение расстояний Марс/Земля было не 1.52, а 1.623. Ошибка в 6.3%, неплохо для разминки.
Ошибка в 1px при измерения полутени от Ingenuity даст погрешность в 1/37 ≈ 3%, а ошибка в 1см в высоте батарейки над тенью (земля под вертолетом не идеально ровная) - погрешность в 2%. Я так-же не исправлял искажения объектива и перспективу, наивно надеясь, что если всё достаточно хорошо центрировать, то ошибки друг-друга скомпенсируют. Дуракам, очевидно, везет.
С количеством света интереснее. У Марса почти нет атмосферы, а вот у Земли есть. И она поглощает заметную часть энергии приходящей от Солнца. Из 1350 Вт/м2, которые получает Земля от Солнца, до поверхности долетает только 1040. А до поверхности Марса ~530 Вт/м2 из 586. Разница в 1.9 раза, а не в 2.3.
2. Вертолеты жужжат
Вертолет, летающий на Марсе, работает на солнечной батарейке, 18650 аккумуляторах, процессоре от смартфона и камерах от Raspberry Pi. Ну разве не потрясающе? Смотрите, как летает:
И на видео даже слышно жужжание винтов! Perseverance, снимающий видео, смотрит на пропеллеры сборку (т.е. находится примерно в плоскости вращения), а значит в спектре звука должна быть очень заметна Blade Passage Frequency. Этот компонент зависит от скорости вращения винта и количества лопастей, а его главная гармоника:
Где n - количество лопастей пропеллера, RPM - обороты в минуту.
Можно собрать пропеллер и проверить как должна выглядеть BPF. Хватаем моторчик от мелкого квадрика и винт от него же. За неимением референсного тахометра, собираем его из спичек и желудей: светодиод воткнутый в микрофонный вход компа и фонарик.
Для таких подозрительных вещей как светодиод на микрофонном входе, хорошо брать не просто FFT но и осциллограмму (в нижней части скриншота)
Тени от лопастей проходят мимо светодиода каждые 2.94ms, перекрывая поток света от фонарика, что вызывает изменение фотоэлектрического тока, и уровня сигнала на микрофонном входе. За каждый оборот мимо датчика проходят обе лопасти, так что период вращения винта получается 6ms. А обороты — 10'000 RPM.
Картинка получается возмутительно большой, но зато разрешение по частоте и времени позволяет всё разглядеть.
BPF на 84Hz
Видно, что пик находится примерно на 84Гц.
Но у ведь Ingenuity не простой винт, а два соосных. Это 2 лопасти или 4?
Не совсем очевидно, но 2. Можно представить себе два пропеллера вращающиеся с одинаковой (иначе вертолет закрутит) скоростью: оба будут шуметь на одной частоте. И как их шум не складывай, ничего кроме громкости меняться не будет.
А можно собрать модель соосного пропеллера из двух обычных и проверить:
Моторы соединены вместе, но повернуты лицом друг к другу, так что винты вращаются в противоположные стороны. RPM (измеренный всё тем-же светодиодом) получился примерно 6000 у каждого.
А спектры шума выглядят вот так:
В плоскости вращения
Пик на ~200Гц как раз соответствует BPF1 для двухлопастного винта на 6000RPM. Обратите внимание что пик двойной — обороты у винтов всё-же немного различаются, и BPF тоже.
А если слушать винты сверху, BPF1 уже не так заметна:
Над винтами (не под потоком воздуха)
В видео гораздо меньше гармоник BPF. Потому, что звук отфильтровали, заглушив всё лишнее. Но если присмотреться, на спектрограмме видны остатки высших гармоник:
BPF1 на ~84Гц, а значит пропеллеры вращаются примерно на 60*(84/2) = 2520RPM.
Фраза «You can also hear the sound change as the helicopter leaves the area and then returns. That’s called the Doppler effect» которая появляется в видео, меня очень расстроила, потому что я никакого Доплера не слышал. Придется прибегнуть к помощи Машины.
2.2 Эффект Доплера
Вытащим звук из видео в WAV и скормим его numpy. Тон BPF самый громкий (спасибо неизвестному звукорежиссеру из JPL), поэтому мы можем просто выбирать самый высокий пик на FFT и, двигаясь по файлу скользящим окном, построить график его частоты по времени.
Важно выбрать достаточно большое окно, чтобы получить хорошее разрешение по частоте. Если мы хотим (а мы хотим!) разрешение в 0.1Гц, окно должно быть 1/0.1 = 10 секунд.
Почему 10?
Представьте что у вас есть запись длительностью 1 сек, в которой только одна частота. Пусть будет 10Гц. Вы можете посчитать сколько периодов помещается в 1 секунду - 10 штук.
Если частота будет 11Гц, вы насчитаете 11 периодов. Но вот если она будет 10.5Гц, вы уже не сможете уверенно сказать количество. У FFT такие-же проблемы.
Разрешение по частоте определяется как Fs/N где Fs это частота дискретизации, а N количество семплов в выборке. Или, если выборка задана в секундах, как 1/T.
Мой слух аугментирован!
Максимальный сдвиг частоты от центра ~1Гц, или 1.2% от 84Гц. Гугл сообщает что человек различает на слух разницу частот в 0.5%. Ну и пусть различает, а мы посмотрим график:
Сразу после взлета вертолет неподвижен. При этом BPF звучит на 84.36Гц, что уточняет обороты до 2531 RPM.
Примерно на 32 секунде BPF начинает увеличиваться. А на видео в это же время вертолет начинает разгон. Задержки между видео и звуком не видно, что при скорости звука в 250м/c дает расстояние до вертолета не более 250 метров.
Скорость звука на Марсе
Сильно зависит от времени суток из-за больших перепадов температуры. Она меняется от 216 (при -95°С) до 270 (+5°С) м/c. Вот тут рассказывают как её измерять, стреляя лазером в камни и слушая задержку. Кстати, тем-же самым микрофоном, через который мы слушаем вертолет. 250 м/c я взял практически по-памяти и это отлично совпало со скоростью при текущей погоде. -27°C дают 247м/c.
Раз мы знаем скорость звука, сдвиг частоты можно пересчитать в скорость. Наблюдатель неподвижен, поэтому:
Где v скорость вертолета (вдоль луча зрения), vs скорость звука, f частота для нулевой скорости (84.36Гц), fo - наблюдаемая частота.
При разрешении по частоте в 0.1Гц, разрешение по скорости выходит ~0.3м/c. Неплохо.
Я отметил некоторые интересные точки и их тайминги. Об этом ниже
Видно, что график симметричный относительно центра, значит вертолет летал примерно одинаково туда и обратно. В центре есть 3 секунды, когда скорость была нулевой: на взлет и посадку нужно больше, значит он просто потупил в дальней точке и полетел домой.
Относительная скорость в начале отрицательная (он приближается!), а на 44 сек резко переходит через 0 и продолжает расти. Вертолет летел по прямой, поэтому путь должен пролегать примерно так
2.3 С какой скоростью он летал?
На 42й секунде видно, как Ingenuity завершает разгон и возвращается в вертикальное положение. Эффект Доплера дает нам лучевую скорость ~1м/c в этот момент. Скорость в проекции можно оценить взяв два кадра из видео с разницей в пару секунд:
347/2 = 173 пикселя за секунду. Высота от дна корпуса до верхушки вертолета ~36 см, а на картинке ~17.5 пикселей: скорость в проекции 173*(0.36/17.5) = 3.56 м/c.
А полная скорость из этих двух компонентов: 3.7 м/c.
2.4 Можем ли мы уточнить расстояние от ровера до вертолета?
Возьмем два фрейма в начале полета: тот на котором Ingenuity еще не начал разгон, и тот на котором он уже почти вылетел из кадра.
Можно измерить размер вертолета на обоих фреймах (лучше всего измерять высоту от дна корпуса до верхушки) и узнать, что он увеличился примерно с 16.5 до 17.5 пикселей, или на 6%.
Между фреймами прошло 10 секунд, в течении которых вертолет разгонялся, и его максимальная скорость вдоль луча зрения составила ~1м/c. При равномерном ускорении это дает (1/2)*10 = 5 метров на которые вертолет приблизился к камере.
За 5 метров угловой размер вертолета вырос на 6%. Что дает нам 5/0.06 = 83 метра дистанции на момент старта.
Но этот метод очень грубый: Если бы размер изменился не на 1 пиксель, а на 2, дистанция получилась бы 43 метра. Да и лучевая скорость у нас с разрешением 0.3м/c.
Попробуем прикинуть расстояние еще одним способом. Можно сделать очень смелое предположение, что вертолет летает какой-нибудь из сторон ланчбокса вперед, и посмотреть как он ориентирован в начале полета.
Разгон начинается в 32 секунды, а в 44 секунды скорость на графике переходит через 0 — в этот момент он летит перпендикулярно лучу зрения. 10 секунд ускорения и 2 секунды полета на 3.7м/с дают 26 метров от начала полета до ближайшей к камере точки. Отсюда,
Правда наверняка где-то между, поэтому возьмем среднее от 83 и 68 — 75 метров.
Кстати, можно представить поле зрения камеры: за время пролета вертолета через весь кадр, направление изменилось на 22.5°. Горизонтальный FOV в 24° дает 55мм объектив кроп-факторе 1.5. То есть буквально как китовый 18-55 на камере с APS-C выкрученный на самый большой зум.
2.5 Места взлета и посадки отличаются
Сравним два кадра:
Картинка увеличена в 10 раз, смещение на 85.5 и 5.5 пикселя. Место посадки было правее и ближе, чем место взлета.
Высота вертолета от дна ланчбокса до верхушки - 36см и 16 пикселей на фото, значит он сместился на 85.5*(36/16) = 186 сантиметров вправо в проекции.
5.5 пикселя вниз, дают 12см в проекции. Предположим, что поверхность ровная и плоская, и что высота мачты с камерой на ровере 2 метра. Тогда, смещение по поверхности вдоль луча зрения 0.12*(75/2) = 4.5 метра.
Что дает:
2.6 Как далеко летал Ingenuity?
Мы знаем, что места взлета и посадки различались, поэтому считаем по-отдельности:
По графику видно, что он начал движение в 32сек, а закончил в 79: 47 секунд полета, из которых 20 на разгон и торможение: 273.6+203.6/2 = 134,7 метра для первой части маршрута.
Обратный путь начался на 82 и закончился на 129 секундах, что тоже дает 47 секунд.
Значит, видимое смещение точки посадки вправо вызвано просто углом траектории относительно луча зрения (а может быть, скорости были разными для двух участков пути):
Действительно, arctan(1.86/4.5) ~ 22.5°. А угол a очень мал, потому что длина пути гораздо больше расстояния между точками.
Суммарная дальность полета получилась 269.4 метра.
2.7 Теперь можно нарисовать план полета
Мы знаем все нужные расстояния и углы:
2.8 Симуляция жужжания
Перед тем как сравнивать всё это безобразие с реальными данными, маленькое отступление. Спектрограмма выглядит страшно, на ней видны порывы ветра, которые почти заглушают гудение мотора. Разрешение в 0.3м/c и окно в 10 секунд не внушают доверия. Можем ли мы вообще говорить о точности в 1 секунду, когда окно такое большое?
Давайте набросаем симулятор жужжащего вертолета. Отсюда можно взять относительные координаты ровера, и точек в которых садился вертолет:
Смотрим координаты на скриншоте и измеряем полоску с масштабом:
hover(hover_time_at_liftoff) # Hovering at p1
set_target(heli_p2)
accelerate(max_speed, accel_time) # Accelerating at p1
free_flight(accel_time) # Flying to p2
decelerate(0, accel_time) # Decelerating at p2
hover(hover_time_at_p2) # Hovering at p2
set_target(heli_p3) # Going home
accelerate(max_speed, accel_time) # Accelerating at p2
free_flight(accel_time) # Flying to p3
decelerate(0, accel_time) # Decelerating at p3
hover(hover_time_at_landing) # Hovering at p3
Чо творится?
Каждая из функций апдейтит положение вертолета и, с шагом dt заполняет массив значениями BPF с учетом скорости.
hover(t) не меняет скорость и завершается через t секунд
set_target(p) меняет вектор направления вертолета, чтобы он двигался к p
accelerate(s, t) увеличивает скорость до s в течение t секунд
free_flight(t) сохраняет текущую скорость и завершается, когда время до цели будет < t
decelerate(t) - как accelerate только с другим знаком и s = 0.
Получилась вот такая красота:
Выглядит точь-в-точь как график, полученный из видео. Амплитуды и тайминги похожи. Чуть ниже будет картинка с наложением одного на другое, а пока можно поиграться с симулятором и посмотреть, что изменится при разных параметрах полета.
Допустим, дальняя точка была расположена на том-же удалении, но так, что вертолет улетает под углом 10° (а не 22.5°) к проекции камеры:
Скорость приближения в начале и конце полета гораздо ниже, а сдвиг частоты всего 0.05Гц. Мы бы даже не заметили этого на графике.
Теперь сложнее. Пусть вертолет, после того как вылетит из кадра, поворачивает немного в сторону, а потом тем-же путем возвращается обратно:
Синие линии — старый путь, зеленые — новый.
Получатся так:
Видно момент, когда из-за смены направления резко меняется относительная скорость. Я сделал поворот моментальным, в реальности переход был-бы более гладким, но с такой-же амплитудой. Не уверен что его было бы видно на нашем графике, но более резкий поворот точно был-бы заметен.
2.9 Ошибки?
1) Реальное значение RPM было 2537 а не 2531. Ошибка около 0.2% или 0.2Гц для BPF. Вполне близко к пределу точности измерений.
3) Скорость полета, по данным в википедии, 3.5м/c, а не 3.7м/c. Ошибка в 6%. Неплохо, учитывая то, как мы её измеряли.
Можно наложить график симуляции на реальные данные и сравнить:
Видно что симуляция (со скоростью 3.7м/с) немного спешит.
Еще стоит заметить, что в симуляции я не учел задержку звука. Но она составляла всего пол секунды в дальней точке:
Rover-Heli dist @ start: 74.2 meters, sound lag 0.30 sec
Rover-Heli dist max: 124.0 meters, sound lag 0.50 sec
4) Расстояние от камеры до Ingenuity на старте, измеренное по карте, получилось 74 метра, а не 75. 1.3% и наглядное подтверждение того, что измерять вещи разными способами и усреднять полученное — полезно. Но вообще, скорее повезло.
6) Дальность полета, по данным из википедии, составляла 268.5 метров в обе стороны. У нас вышло 269.4 метра. Ошибка в 0.3%. На удивление, гораздо меньше ошибки в скорости. Видимо какие-то из предположений (одинаковое время разгона-торможения, равномерное ускорение, одинаковая длина путей) оказались ложными, но ошибки скомпенсировали друг-друга.
5,7) Можно наложить наш план полета на реальную карту:
Я выбрал в качестве опорной точки положение марсохода, а в качестве опорного направления — линию между ним и точкой старта. Совпало хорошо. Чуть-чуть ошиблись в точке посадки, и на пару градусов по направлению. В обоих случаях мы разглядывали 2,5 пикселя, так что ошибки можно понять.
2.10 Всякое
Последняя интересная вещь в видео — посадка вертолета. Коснувшись земли, он немного подпрыгивает и окончательно приземляется на 136 секунде. А на спектрограмме из ffmpeg виден момент когда винт начинает резко сбрасывать обороты:
Разница между приземлением и отключением пропеллера 3 секунды. Ingenuity, коснувшись песка, медленно и осторожно уменьшает угол атаки винтов, постепенно увеличивая нагрузку на грунт. И только когда убедится, что опора надежная — выключает моторы. А в эти 3 секунды он готов взлететь и повторить попытку, если датчики заметят что-то неладное.
А вот видео, где вся движуха собрана на один экран:
Вертолеты на Марсе действительно жужжат, и жужжат занимательно.
Тут вертолет быстро разгоняется до 200 метров в секунду, и пролетает мимо ровера:
Скажем, мы хотим по этой записи найти скорость вертолета, но не знаем даже BPF для нулевой скорости.
Но лучевая скорость становится нулевой в тот момент, когда он пролетает ближайшую точку. И ее можно найти, если принять, что скорости до и после пролета были одинаковыми, но с разным знаком:
Действительно, если взять f1 = 417Гц, а f2 = 45Гц (я взял точки в противоположных концах графика), получается 81.2 Гц. Ошибка в 2.5%, но это не так важно, потому что:
v1 = 250*(81.2/417-1) = -201.3 m/s
v2 = 250*(81.2/45-1) = 201.11 m/s
В тех точках где я измерял частоты, вертолет находился достаточно далеко (порядка 3км), так что я пренебрег поправкой на направление. Но если вам интересно, на 3км угол к лучу зрения получается 5.5°, а cos(5.5°) = 0.995. Погоды не делает.
Ошибка получилась меньше 0.5%. Круто? Попробуем в деле:
Возьмем видео с самым красивым самолетом. 20и-метровый кусок металла с аэродинамикой шлакоблока и радарной сигнатурой маленькой птички, не падающий с неба только благодаря хитрой управляющей электронике. Да, я про F-117:
Можем ли мы измерить его скорость?
Посмотрим на спектрограмму:
Кривая перехода сразу бросается в глаза. Возьмем две частоты и посчитаем:
Частота для нулевой скорости получилась 422Гц.
А скорость вдоль луча зрения в начале видео:
350*(422/898 - 1) = -185.5 м/c
Но летел он не прямо на камеру, а под углом градусов в 15. Так что реальная скорость:
-185.5/cos(15) = -192м/c
Какая была на самом деле? К сожалению видео об этом умалчивает, поэтому возьмем два соседних фрейма, где самолет летит на фоне гор, совместим и измерим:
F-117 в длину 20.1 метр. Но это до края хвостового оперения. А до заднего края корпуса — 17.1 метр. Скорость получается 43*(17.1/110)*30 ≈ 200 м/с. Мы ошиблись на 4%. Наверняка из-за кривой оценки угла, или скорости по фреймам.
2.12 Оффтоп 2: Марсианская аэродинамика
Как известно, у летательного аппарата два врага: сила тяжести и сопротивление атмосферы. Мне было интересно оценить, насколько на вертолет влияет второе (может ему и правда надо летать углом вперед?).
Где Fd сила сопротивления атмосферы, p - плотность, v - скорость вертолета, A - площадь сечения, а k - аэродинамический коэффициент.
Плотность атмосферы на Марсе около 0.02 kg/m3
Скорость 3.5м/c
k считать сложно, скажем, вертолет имеет форму куба (k = 1).
Осталось узнать площадь сечения. Это просто. Открываем 3д модельку и крутим ее до тех пор пока не будет похоже на на вертолет летящий прямо на нас:
Закрашиваем тень, потому что она темнее чем коробка вертолета, и двигаем белый маркер на гистограмме влево, чтобы он стал левее пика светлого фона:
Теперь гистограмма показывает количество пикселей темнее фона. Что, фактически, площадь сечения вертолета с этого ракурса. Правда она в пикселях. Но высота от дна до верхушки тут 100 пикселей, что дает 3.6мм на пиксель. Значит один пиксель это 13мм2, а 8051 пикселей - 104341мм2. Или 0.1м2.
(0.023.5^20.5*0.1)/2 = 0.01225 Ньютона
F = m*a
0.01225 = 1.8*a
a = 0.007м/с2
То-есть, за 27 секунд полета вертолет теряет всего 0.2 м/c скорости.
3. Вертолеты не отбрасывают тени
Вернемся к заглавной картинке (наконец-то!)
https://ift.tt/2WuPJmi
Четыре вещи на ней выглядят подозрительно:
Вертолет явно в воздухе, значит лопасти вращаются на 2500 RPM, а выглядят они очень четкими. Какая же там должна быть выдержка, диафрагма и ISO чтобы получить такую картинку с хорошей экспозицией и не утонуть в шумах и красивом бокэ?
Лопасти кажутся полупрозрачными. Странности добавляет и тень от ноги поверх тени пропеллера, которая прозрачной не выглядит.
Сверху лопасти более темные, чем снизу.
На переднем (более прямом) крае лопасти тень выглядит темнее. Причем на некоторых фото это заметно, а на других — нет:
Что за камера помогает Ingenuity ориентироваться на местности? Это OV7251. 640х480, отсутствие фильтра Байера, глобальный электронный затвор и до 120FPS в максимальном разрешении. Размер матрицы 1/7.5", а размер пикселя 3х3мкм. Эта камера бывает в двух исполнениях — для видимого света (с hotmirror, который отсекает ИК излучение), и для ближнего ИК (с полосовым фильтром на 830нм).
Надо заметить, что мне так и не удалось найти (или понять по фото) какая из двух версий камеры используется на Марсе. Далее я буду предполагать что обычная.
3.1 Гадание по фотографии
Попробуем оценить выдержку. Ищем какое-нибудь прямое место на лопасти и измеряем ширину полутени. Заодно, измеряем и ширину полутени от солнечной батарейки.
Пересечение синих линий — моя скромная попытка найти ось вращения
15 пикселей для винта и 10 пикселей для батарейки. Значит винт смазался вращением на 5 пикселей, что на таком расстоянии от оси вращения дает 1.5°. Но мы не учли искажения оптики: вещи на поверхности, ближе к краю кадра выглядят меньше, чем на самом деле. Пусть будет угол в ~2°, или 1/180 от полной окружности. Полную окружность лопасть проходит за 60000/2500RPM = 24мс, а 1/180 за 133мкс. Это и есть длительность выдержки. Ну или 1/7500, если вы фотограф.
Ошибка на 0.5° при измерении угла, дает примерно 33мкс разницы. К примеру если бы угол был в 1.5°, выдержка получилась бы 100мкс или 1/10000.
Теперь ISO. Хоть светочувствительность по ISO-12232 и не используется в этих камерах, её хорошо знать для сравнения с обычными фотоаппаратами. Когда камеры были большими, а экспонометры отдельными и дорогими, люди пользовались правилом «Sunny 16» чтобы подбирать выдержку. Правило гласит:
On a sunny day set aperture to f/16 and shutter speed to the [reciprocal of the] ISO film speed for a subject in direct sunlight
Сделаем поправку на то, что Марс дальше от Солнца и на него попадает в 2 раза меньше света. Делим 16 на и получаем Mars 11 rule. С диафрагмой f/11 и выдержкой 1/7500 матрице нужна будет чувствительность ISO 7500 чтобы получить нормальную экспозицию. Звучит как высокое и шумное ISO, но подождите.
Размер пикселя слишком мал, чтобы позволить диафрагму f/11: дифракционный предел размажет картинку.
Где d - минимальный размер пятна, N - диафрагма, а λ - длина волны света.
При диафрагме f/11 и λ = 550нм, d получается ~15мкм, целых 5 пикселей (размер пикселя у OV7251 - 3мкм).
Но на кадрах с камеры можно разглядеть отдельные детали в пару пикселей размером, значит d не сильно больше размера пикселя. Пусть будет как-раз 3мкм. Тогда:
N = 2.23
Чтобы дифракция не влияла на картинку, диаметр диафрагмы нужно увеличить в 11/2.23 = 5 раз. Поток света увеличится в = 25 раз, и ISO нужно уменьшить до 7500/25 = ISO 300. Хорошее, низкое ISO. И совсем не шумное.
Но хватит ли, при такой большой диафрагме, глубины резкости, чтобы без автофокуса снимать объекты на расстоянии от 15 сантиметров (когда вертолет приземлился) до десятков метров? Мы можем прикинуть гиперфокальное расстояние. Это расстояние H от камеры до точки фокуса, при котором в поле резкости попадает всё от H/2 до бесконечности:
Где H - гиперфокальное расстояние, f - фокусное расстояние объектива, N - диафрагменное число, а c - диаметр круга нерезкости. Круг нерезкости имеет тот-же смысл что и пятно в дифракционном пределе: мы не хотим чтобы он был больше пикселя.
Не хватает фокусного расстояния объектива. Но мы знаем, что размер матрицы 1/7.5", а угол зрения сильно больше 90° но меньше 180°. Пусть будет середина — 135°. Из справочных табличек (или опыта общения с зеркалками), можно узнать что для full frame матрицы угол в 130° получается при 10мм объективе. Диагональ full frame 1.7", а значит кроп-фактор для 1/7.5" матрицы 12.75. Фокусное расстояние получается 10/12.75 = 0.8мм.
Гиперфокальное расстояние:
H = 0.8^2/(2.23*0.003) = 95.6мм
0.003 - это 3мкм, размер круга нерезкости
Если сфокусировать объектив на 95мм, то резким будет всё от 47мм до бесконечности. Так что глубины резкости хватит с запасом.
Можно поискать модули с этой матрицей чтобы убедиться, что мы не сильно ошиблись. Вот модуль с фокусным расстоянием 1.3мм (и углом зрения в 86°), диафрагмой f/2.2 и фиксированным фокусом от 65mm до бесконечности. В целом сходится.
1/7500", ISO300, диафрагма f/2.2 и объектив с фокусным расстоянием 0.8mm. Странная конфигурация, если вы привыкли к большой фототехнике.
А если бы камера работала в ИК (λ = 850нм), то получилось бы: ISO120, диафрагма f/1.4 и гиперфокальное расстояние в 15 сантиметров.
3.2 Прозрачные лопасти
У этой части проблема с экспериментальными данными: проснувшись однажды утром после беспокойного сна, я обнаружил, что в доме нет ни одной камеры с глобальным электронным затвором, годной для переделки в ИК. Да и негодных нет. В конце мы компенсируем недостаток реальности численным моделированием (отвратительный код на питоне, да).
3.3 Потому, что прозрачные.
Самый очевидный вариант, объясняющий полупрозрачность теней, который приводят в каждом втором обсуждении этих фотографий: лопасти выглядят прозрачными потому-что они прозрачные. Логично.
Ведь OV7251 может работать в диапазоне ближнего ИК, где вещи выглядят неожиданно. Знаменитые примеры:
Тёмное, почти черное, небо. И чем дальше в ИК — тем темнее.
Яркие листья на деревьях, благодаря эффекту Вуда (не от слова "wood", а от слова Robert Wood)
Прозрачность разных пластиков и красителей
Может быть и с лопастями так-же? Лопасти у Ingenuity карбоновые, и это хорошо: у меня есть такие-же. В этот раз не придется даже думать, хватаем пропеллер и смотрим на тень от солнца:
Рядом для сравнения светофильтр, прозрачный в ИК, hotmirror непрозрачный в ИК* но прозрачный в видимом свете и кусок дискеты. А снизу то-же самое, но в видимом диапазоне.
Светлое пятно под hotmirror не от того, что оно пропускает ИК, а от того, что отражает вниз свет который попадает на его нижнюю сторону с яркой бумаги. Смотрите, как оно отражает держалку с круглым фильтром. Потому и "mirror".
Тень от пропеллера совершенно такой-же яркости, как тень от мотора рядом:
3.4 Оффтоп 3: Инфракрасная фотография для бедных
А вот тень от дискеты чуть прозрачнее тени от держалки:
Дискета пропускает очень небольшое количество ИК и красного света. Она сойдет за lowpass-фильтр, если вы хотите попробовать ИК фотографию, а покупать нормальный фильтр не хотите.
Вот пара фоток на дискету:
Откуда берутся цвета на инфракрасных фото? Посмотрите на спектральную чувствительность фильтра Байера:
В серой части (как раз там работает ИК фотография) разные каналы всё еще дают разные значения, а значит есть цветовой контраст. Но чем дальше в ИК, тем меньше их различия. Начиная с 850нм, все каналы практически одинаковы. И действительно, чем дальше граница среза у lowpass фильтра, тем меньше насыщенность картинки:
Конечно, производителей не волнуют характеристики фильтра Байера в ИК, поэтому цвета заметно меняются от камеры к камере.
В общем, карбоновые пропеллеры не относятся к вещам, предательски изменчивым в ИК. Приятно знать.
Ну и чтобы окончательно развеять сомнения, можно посмотреть вот эту фотографию:
https://ift.tt/2V7g7ST
Лопасти тут не вращаются и совершенно не прозрачны. А значит, дело в движении и таймингах.
3.5 Лопасти перемещаются во времени!
Помните эффект, возникающий при фотографировании со вспышкой чего-то шустрого? Рассмотрим фотографию комара:
Крылья получились четкими, но вокруг них смазанный след, потому что длительность вспышки гораздо меньше длительности выдержки. Но след полупрозрачный, потому что вспышка яркая и хорошо подсветила деревья.
Можно повторить то-же самое с пропеллером:
Такой-же эффект, как на фото Ingenuity! Но ведь у камеры вертолета нет вспышки, ему светит солнце. Откуда этот эффект получается у него?
Ответ скрывается в устройстве самой матрицы:
Данные считываются с CMOS матрицы построчно. Контроллер выбирает одну из строк, и АЦП через мультиплексор по-очереди измеряет заряд на пикселях. Затем следующую.
Процесс длится порядка миллисекунд, что сравнимо с длительностью выдержки или даже больше. Поэтому в классических цифровых фотокамерах, по завершении экспозиции матрица прикрывается от света механическим затвором.
А если механического затвора нет, можно экспонировать и считывать строки по-отдельности. Тогда у вас не будет проблемы с тем, что другие строки ждут своей очереди под светом. Но будут другие проблемы: да, мы говорим о rolling shutter. Строки экспонируются в разное время, и объекты в кадре могут успеть переместиться.
Более сложной и дорогой альтернативой rolling shutter является global shutter. Тут вы экспонируете всю матрицу сразу, но по завершении экспозиции перемещаете накопленный пикселем заряд в защищенную от света область, называемую storage node.
Она маленькая, находится вне фокуса микролинзы и прикрыта от света линиями управляющих сигналов, а то и отдельной крышечкой из металлизации. Перемещение зарядов со всех пикселей происходит одновременно, и уже после этого вы неспешно считываете заряды. Как-будто у вас механический затвор.
Вот только он не механический и не 100% эффективный. Крышка на storage node не может быть значительно больше самой storage node, и свет может под неё проникать за счет дифракции на всякой фигне вокруг. А еще электроны, выбитые фотонами, попавшими мимо фотодиода, могут долететь до storage node.
Эта нежелательная засветка при "закрытом" затворе называется Parasitic Light Sensitivity (PLS) и ужасно всех бесит уже много лет.
Пиксели будут засвечиваться, пока идет чтение, причем те которые считываются последними — засветятся больше всех. А если между завершением экспозиции и началом чтения есть пауза, то пиксели будут засвечиваться и в это время, но равномерно.
PLS, в различных статьях, как и другие специфичные вещи, выражается в чем угодно в зависимости от давности статьи и фазы луны на момент написания: Сначала это называли Shutter Efficiency и измеряли в процентах. 99% означает что закрытый затвор пропускает 1% света.
Когда отличать 99.98% от 99.99% стало слишком тяжело, ввели термин PLS ratio. Например 1/10000 означает что закрытый затвор пропускает в 10000 раз меньше света чем открытый. Иногда указывают 1/PLS, чтобы не писать "1/".
Но так-как писать 4-5 нулей довольно утомительно, PLS выражается еще и в децибелах, например -40dB = 1/10000. Или 1/PLS, чтобы не писать у децибелов минус.
Я же пойду еще дальше и буду говорить PLS, имея ввиду 1/PLS.
3.6 Попробуем оценить PLS у нашей камеры
Сколько времени занимает считывание кадра с матрицы? В даташите этого не написано, но можно примерно прикинуть из таймингов камеры:
На странице 31 указан System Clock в 48MHz. А на 20й странице — тайминги MIPI.
Полное время передачи одного фрейма (1) занимает 478848 тактов SysClock, или 10мс (что как раз дает 100 FPS). Но из этого времени только 445056 тактов (9.3мс), занимает передача самого фрейма. Потому что тайминги (2), (3), (5), (7) и (9) — не относятся к передаче полезных данных.
Можно убедиться, поделив 445056 на 928 (период передачи одного пакета) и получив 480 — количество строк сенсора. Значит в каждом пакете одна строка. А то, что из 928 тактов больше половины — пауза между пакетами, говорит о том, что строки действительно оцифровываются по-ходу передачи. Так что ~9.3мс это время чтения сенсора.
Выдержка была ~133мкс, а значит, время чтения в 70 раз больше выдержки.
Можно вернуться к веселым экспериментам. Возьмем две фотографии тени от пропеллера: неподвижного и размазанного вращением.
Скомбинируем их в режиме Addition (по-пиксельное сложение яркости) и сравним с фотографией, где вертолет летит высоко над землей. Лопасти находятся примерно в центре кадра, так что отношение чтение/выдержка будет ~35.
Скажем, что фото с неподвижным винтом это идеальный затвор. А фото с размазанным - эффект от PLS. Тогда, если бы PLS была ровно 35, то простое сложение кадров дало бы такой-же эффект как у вертолета (экспозиция размытого кадра в 35 раз дольше, но сенсор в это время в 35 раз менее чувствительный):
Похоже? Да, но слишком прозрачно.
Покрутим экспозицию для слоя с размазанным пропеллером.
Ну вот, 1.66 ступени вниз и выглядит гораздо лучше. Это эквивалентно уменьшению светочувствительности в 2^1.66 = 3.17 раза. Значит, PLS примерно 35*3.17 ≈ 111.
Такое значение PLS кажется очень плохим по современным меркам. В работах 2018 и 2019 годов приводятся цифры на два порядка лучше для пикселей того-же размера.
-40dB это 1/10000
Даже в пресс-релизе 2019 года, где Omnivision анонсирует новую версию этой камеры - OV7251-1B, заявлена эффективность в 99.96% (PLS = 2500).
Но на всяческих видео и пресс-конференциях команда Ingenuity рассказывала, что работа над вертолетом велась 5-6 лет. В 2014 году вышел Snapdragon 801 который стоит в Ingenuity и моем телефоне, в 2014-же году вышла первая версия OV7251. И графики от 2013 показывают, что в те давние времена, PLS была довольно печальной:
Обратите внимание, что это график для пикселя размером 3.75мкм, а на OV7251 — 3мкм. И PLS очень стремительно ухудшается с уменьшением размера пикселя: примерно в 5 раз на 10% уменьшения размера. Между 3.75 и 3 — 20% разницы, что дает ухудшение в 10 раз и PLS порядка 100. Сходится.
3.7 Откуда на фото градиент яркости?
Потому, что разные строки ждут очереди на считывание разное время. Верхняя строка считывается первой, и PLS на неё не влияет: верхняя часть кадра самая темная. Нижняя строка считывается последней, а до этого засвечивается все 9.3мс. Средняя — в течении 4.65мс.
Попробуем получить PLS еще одним способом (с расстоянием до ровера ведь сработало!). Возьмем все фотографии c навигационной камеры и слепим из них одну:
convert -evaluate-sequence mean ./HELI_NAV/*.png ./heli_nav_mean.png
Получилась вот такая красота:
Видно виньетирование от большой диафрагмы и широкого угла, ногу, пыль на стекле, еще ногу, и тень от вертолета по центру.
Теперь возьмем вертикальную полосу откуда-нибудь из центра кадра и построим график яркости:
В центральной части (где не мешают искажения оптики и тень от вертолета) график более-менее линейный.
За 80 пикселей (360..280) яркость изменилась со 158 до 180. Или на (180-158)/158 ≈ 14%. 80 пикселей это 1/6 от полной высоты картинки, а значит PLS = 70/6/0.14 ≈ 83.
Можно снова взять что-нибудь среднее между 83 и 111: PLS ≈ 100 (или 99% эффективности затвора)
В данном случае эффект от PLS был так заметен только потому, что у нас есть быстро вращающиеся лопасти. Без них эффект выражался бы только в вертикальном градиенте яркости, который легко правится программно (с потерей динамического диапазона, но это не страшно).
3.8 Передний край
С градиентом понятно, но почему передний край на лопасти темнее, чем остальная часть?
В эксперименте со сложением двух фотографий пропеллера, мы упустили важную деталь: там пропеллер вращался быстро и успевал сделать много оборотов за время экспозиции, потому размазывался в аккуратный диск. Но с Ingenuity всё не так: за 9.3мс чтения лопасть проходит 140°. И это за полное время считывания. Для средних строк это будет уже 70°.
А если пропеллер не успевает сделать даже пол-оборота, тень от второй лопасти не дойдет до места, где была первая в момент начала экспозиции. А значит, тень не размажет в ровный круг, и то место откуда начала двигаться лопасть, будет светлее.
А то, что это заметно не на всех кадрах, объясняется вторым винтом: на 3 кадре угол между винтами около 22.5° и сектора, которые проходят лопасти за время засветки, полностью пересекаются, выравнивая яркость. А вот на двух первых кадрах угол >70° и винты не успевают долететь.
Это картинка из будущего, вы еще не знаете что у меня есть отвратительный симулятор PLS, а я знаю.
3.9 Ground truth
Можно ли проверить все эти домыслы, кроме как разглядывая фотографии с Ingenuity?
Я уже говорил, что подходящих камер у меня 0. Да и купить такую сейчас будет сложно — за 6 лет характеристики улучшились на порядки. К счастью, у нас есть ютуб, на котором иногда попадаются хорошие видео. Вот сегодняшнее хорошее видео:
(в комментах можно понаблюдать, как я упорно ничего не понимаю)
Это точно такая-же камера как на Ingenuity, снимающая быстро вращающийся пропеллер. Идеально!
Спасибо Hermann-SW за лучший контент на ютубе
И на видео отлично видно, что лопасти выглядят прозрачными. Гораздо более прозрачными, чем тени от вертолета, но тут и выдержка короче (77 а не 133), и сцена гораздо более контрастная.
3.10 Симуляция неэффективного затвора
Это всё еще не выглядит убедительно. Да, мы знаем что у глобального затвора есть засветка, и примерно представляем её величину для OV7251. Но хочется проверить.
Я набросал контуры винта и коробки с ногами, и нагуглил текстуру песочка.
Trow здесь — время оцифровки одной строки изображения в микросекундах. Оно-же — минимальное время экспозиции. Оно-же — шаг времени для нашей симуляции.
Тут я безуспешно пытаюсь совладать с Pillow, вращаю лопасти на углы a1 и a2, собираю лопасти и коробку вместе, масштабирую и перемещаю, делаю их немного прозрачными (чтобы тень не была совсем черной) и прилепляю на песочек. В конце умножаю всё на gain — коэффициент, который поможет нам в итоге получать нормальную экспозицию.
Как живой!
Теперь, функция, собирающая кадр. Мы можем разделить всё происходящее на три этапа:
Сама экспозиция: кадр с выдержкой длительностью exposure_us, за время которой лопасти успевают немного сдвинуться.
Ожидание перед считыванием. Теперь длительность hold_us, и учитывается PLS - кадр во много раз темнее.
Считывание кадра. Тут вещи становятся хитрыми. Первая строка проэкспонируется в течение 1 лишнего Trow, а потом прочитается. 480я строка - в течение 480 Trow, причем в это время положение лопастей будет заметно меняться. Так что для кадра в 480 строк нам придется наплодить 480 фреймов для того чтобы брать с них строки для симуляции PLS.
def construct_frame(exposure_us, RPM, PLS, a1, a2, readout_us=h*Trow,
shadow_alpha=0.6, gain=None, hold_us=0, cy=0, cx=0, scale=1):
degrees_per_trow = RPM/60E6*360*Trow
exposure_trows = exposure_us//Trow
hold_trows = hold_us//Trow
kReadout = readout_us/h/Trow
if gain==None:
gain = 1/(exposure_trows + hold_trows/PLS + (h/2)/PLS*kReadout) * gain_correction
sensor = np.zeros((w,h))
if exposure_us != 0:
print("Building Base image")
for i in progressbar(range(exposure_trows)):
sensor += single_exposure(cx, cy, scale, a1, a2, shadow_alpha, gain)
a1 += degrees_per_trow
a2 -= degrees_per_trow
if hold_trows != 0:
print("Building Hold image")
for i in progressbar(range(hold_trows)):
sensor += single_exposure(cx, cy, scale, a1, a2, shadow_alpha, gain) / PLS
a1 += degrees_per_trow
a2 -= degrees_per_trow
if readout_us != 0:
print("Applying PLS frames")
PLS_frames = []
for line in progressbar(range(h)):
PLS_frames.append(single_exposure(cx, cy, scale, a1 ,a2, shadow_alpha, gain) / PLS * kReadout)
for t in range(-1, -line-1, -1):
sensor[line,:] += PLS_frames[t][line,:]
a1 += degrees_per_trow * kReadout
a2 -= degrees_per_trow * kReadout
return Image.fromarray(np.uint8(np.clip(sensor, a_min=0, a_max=255)), 'L')
readout_us и, получаемый из него, kReadout нужны чтобы симулировать разную скорость считывания. А устанавливая exposure_us, readout_us или hold_us в 0 можно отключать соответствующие компоненты кадра.
sensor - массив в котором мы суммируем все экспозиции. Как и в реальности, каждая часть процесса просто насыпает заряд в его ячейки.
gain выбирается так, чтобы в середине кадра (h/2) экспозиция была нормальной.
Чтобы было удобнее перебирать разные параметры, я написал обертку, которой можно задавать варианты для каждого из них. Посмотрим, как размывает лопасти при разной выдержке (без учета PLS):
Выдержка меняется от 19 до 12000 микросекунд
Интересно, что размывает их не просто в диск, а с паттерном из 4х светлых полос, который отмечает места пересечения лопастей при вращении. В любой точке за время экспозиции пролетает 2 лопасти (в разные стороны), но в точках пересечения — они пролетают одновременно, перекрывая свет на в 2 раза меньшее время.
Теперь, посмотрим на эффект от PLS. Если взять PLS=100, то разное время чтения сенсора будет выглядеть вот так:
Время чтения сенсора меняется от 19 до 24000 миллисекунд
Видно, как при увеличении соотношения Чтение/Экспозиция, PLS всё больше влияет на картинку. Если присмотреться, то можно увидеть размазанный след от того, что за время чтения лопасти успели повернуться:
В верхней части они успели повернуться меньше, чем в нижней. Потому что нижние строки засвечивались дольше.
Скажем, что длительность чтения была 9.3мс и посмотрим, что будет если менять PLS:
На низких PLS градиент практически пересвечивает нижнюю часть кадра, а кроме прозрачных винтов заметны и следы от их движения за время чтения. На PLS порядка 100, градиент выравнивается до приличного уровня. Интересно, что даже на PLS 2500 можно разглядеть разницу в тенях между винтом и ногами.
Мы забыли про паузу между экспозицией и чтением. Скажем, что PLS=100, выдержка 133мкс, а чтение 9.3мс. Тогда:
Пауза при неизменной PLS и времени чтения, влияет на общую яркость, при этом уменьшая градиент.
А вот так выглядит отдельно эффект от PLS при разном времени чтения:
Я выбрал несколько кадров с вертолета и попробовал воспроизвести их.
Тут я перепутал фазу винтов, потому что я не очень умныйВиден градиент на краях винтов, которого не было на предыдущем фото
Выглядит похоже. Хотя симуляция кажется несколько темнее (PLS слишком большой?) и с менее заметными градиентами на передней части лопастей (выдержка должна быть по-меньше?). Но в целом это вполне убедительно доказывает, что параметры примерно верные.
4. Постскриптум
Вот так, с помощью спичек, желудей и школьного учебника геометрии, можно изучать космическую технику не вставая с дивана.
Если бы мне 10 лет назад сказали, что на Марсе будет летать вертолет на солнечной батарейке, а марсоход будет снимать его на видео со звуком, я бы не поверил по целому набору причин.
Но вот мы здесь. Ingenuity, который создавался как proof-of-concept и не был обременен излишней консервативностью при выборе оборудования, таскает камеру с самым большим разрешением из всех что были на поверхности Марса и кучу легкой и компактной industrial-grade электроники.
На вертолете нет научного оборудования, кроме камер. Но зато он может моментально слетать за пол-километра и пофоткать со всех сторон очередной очень интересный камень.
Каждый новый полет сложнее предыдущего, но если МиМи не решит сделать бочку, нас ждет еще много материала от маленького марсианского вертолета.


































 и предмет исследования (слева)")








")





")












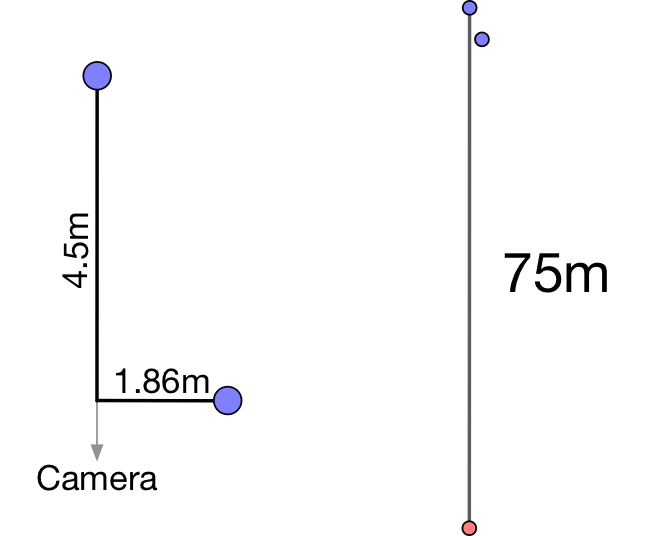









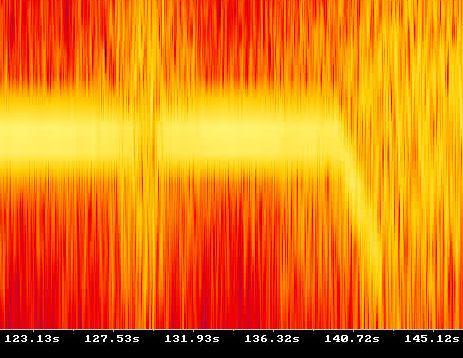













 и получаем Mars 11 rule. С диафрагмой f/11 и выдержкой 1/7500 матрице нужна будет чувствительность ISO 7500 чтобы получить нормальную экспозицию. Звучит как высокое и шумное ISO, но подождите.
и получаем Mars 11 rule. С диафрагмой f/11 и выдержкой 1/7500 матрице нужна будет чувствительность ISO 7500 чтобы получить нормальную экспозицию. Звучит как высокое и шумное ISO, но подождите.

 = 25 раз, и ISO нужно уменьшить до 7500/25 = ISO 300. Хорошее, низкое ISO. И совсем не шумное.
= 25 раз, и ISO нужно уменьшить до 7500/25 = ISO 300. Хорошее, низкое ISO. И совсем не шумное.










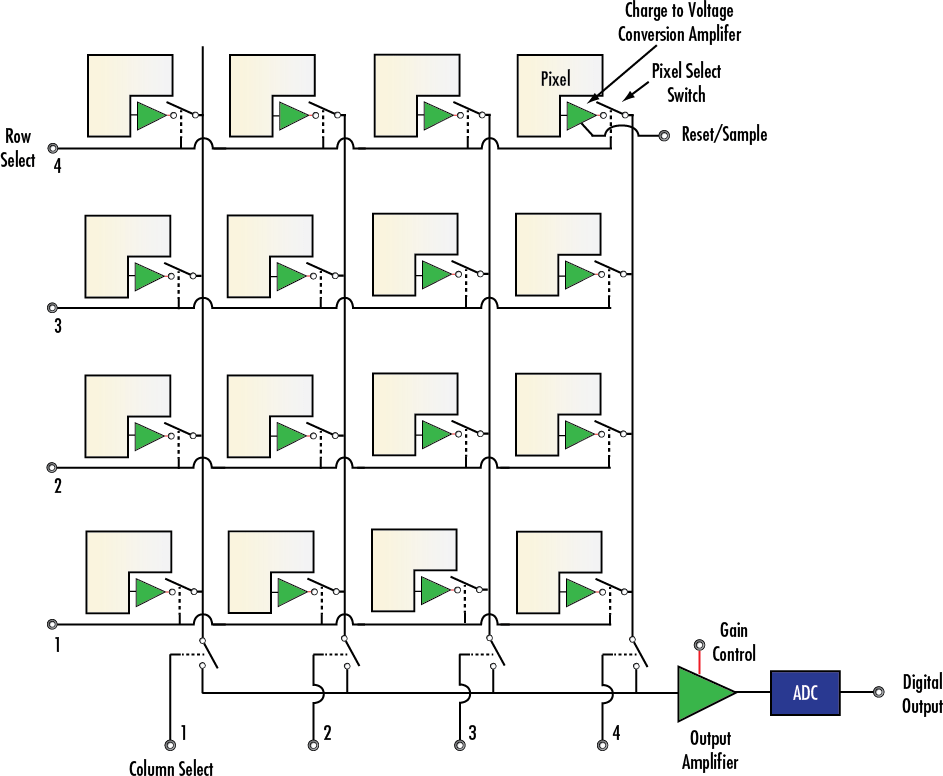
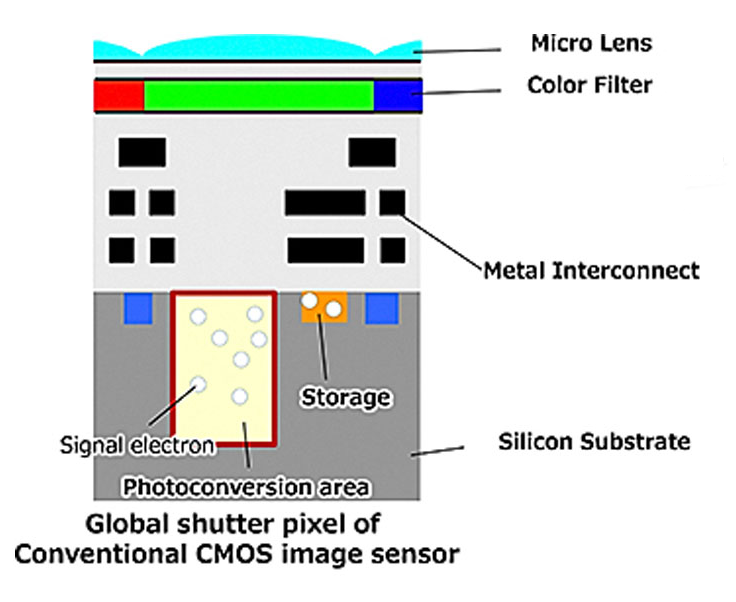








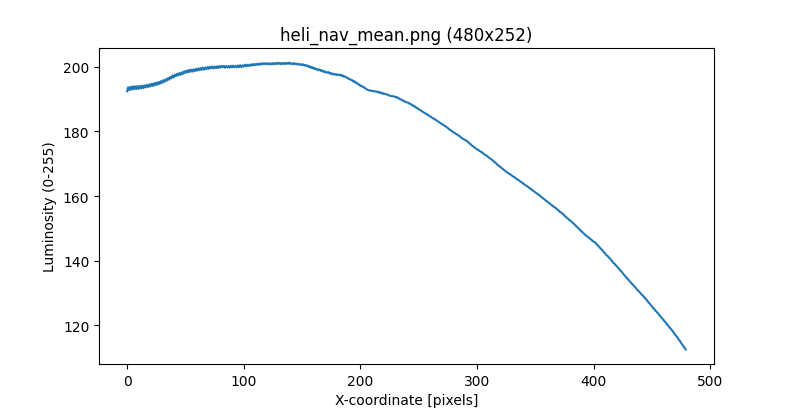












{kind=link}
{kind=link}