Однажды я отправился на поиск учебных руководств по аутентификации в Node.js/Express.js, но, к сожалению, не смог найти ни одного, которое меня бы полностью устроило. Некоторые были неполными, некоторые содержали ошибки в сфере безопасности, вполне способные навредить неопытным разработчикам.
Сразу скажу, что я всё ещё нахожусь в поиске надёжного, всеобъемлющего решения для аутентификации в Node/Express, которое способно составить конкуренцию Devise для Rails. Однако, удручающая ситуация в сфере руководств подвигла меня на подготовку этого материала. Тут я разберу некоторые наиболее распространённые ошибки в области аутентификации и расскажу о том, как их избежать.

Выше я говорил о «неопытных разработчиках». Кто они? Например — это тысячи фронтенд-программистов, брошенных в водоворот серверного JS, которые пытаются набраться практического опыта из руководств, либо просто копипастят всё, что попадётся под руку и устанавливают всё подряд с помощью npm install. Почему бы им не вложить время в серьёзное изучение вопроса? Дело в том, что они копипастят не от хорошей жизни, им приходится из кожи вон лезть, чтобы уложиться в сроки, установленные аутсорс-менеджерами, или кем-то вроде креативных директоров рекламных агентств.
На самом деле, пока я искал подходящее руководство по аутентификации, я проникся ощущением, что каждый Node-программист, у которого есть блог, опубликовал собственный тьюториал, посвящённый тому, как «делать это правильно», или, точнее, о том, «как это делается».
Ещё одна неоднозначная вещь в разработке для Node.js заключается в отсутствии некоего всеобъемлющего, надёжного решения для аутентификации. Этот вопрос, в основном, рассматривается в качестве чего-то вроде упражнения для программиста. Стандартом де-факто для Express.js является Passport, однако, это решение предлагает лишь набор стратегий аутентификации. Если вам нужно надёжное решение для Node, вроде Platformatec Devise для Ruby on Rails, вам, вероятно, придётся обратиться к Auth0 — стартапу, который предлагает аутентификацию как сервис.
Passport, в отличие от полномасштабного Devise, представляет собой промежуточный программный слой, который, сам по себе, не охватывает все части процесса аутентификации. Используя Passport, Node-разработчику придётся создать собственное API для механизма токенов и для сброса пароля. Ему придётся подготовить маршруты и конечные точки аутентификации пользователей. На нём же лежит и создание интерфейсов с использованием, например, некоего популярного языка шаблонов. Именно поэтому существует множество учебных руководств, которые направлены на помощь в установке Passport для Express.js-приложений. Практически все они содержат те или иные ошибки. Ни одно из них не позволяет создать полномасштабное решение, необходимое для работающего веб-приложения.
Хотелось бы отметить, что я не собираюсь нападать на конкретных создателей этих руководств, скорее я использую их ошибки для того, чтобы продемонстрировать проблемы с безопасностью, связанные с развёртыванием ваших собственных систем аутентификации. Если вы — автор подобного руководства — дайте мне знать, если после чтения этого материала внесёте в своё руководство правки. Сделаем экосистему Node/Express безопаснее и доступнее для новых разработчиков.
Ошибка первая: хранилище учётных данных
Начнём с хранилища учётных данных. Запись и чтение учётных данных — это вполне обычные задачи в сфере управления аутентификацией, и традиционный способ решения этих задач заключается в использовании собственной базы данных. Passport является промежуточным программным обеспечением, которое просто сообщает нашему приложению: «этот пользователь прошёл проверку», или: «этот пользователь проверку не прошёл», требуя модуля
passport-local для работы с хранилищем паролей в локальной базе данных. Этот модуль написан тем же разработчиком, что и сам Passport.js.
Прежде чем мы спустимся в эту кроличью нору учебных руководств, вспомним об отличной шпаргалке по хранению паролей, подготовленной OWASP, которая сводится к тому, что нужно хранить высокоэнтропийные пароли с уникальной «солью» и c применением односторонних адаптивных функций хэширования. Тут можно вспомнить и bcrypt-мем с codahale.com, даже несмотря на то, что по данному вопросу имеются некоторые разногласия.
Я, в поиске того, что мне нужно, повторяя путь нового пользователя Express.js и Passport, сначала заглянул в примеры к самому passport-local. Там оказался шаблон приложения Express 4.0., который я мог скопировать и расширить под свои нужды. Однако, после простого копирования этого кода, я получал не так уж и много полезностей. Например, здесь не оказалось подсистемы поддержки базы данных. Пример подразумевал простое использование некоторого набора аккаунтов.
На первый взгляд всё вроде бы нормально. Перед нами — обычное интранет-приложение. Разработчик, который воспользуется им, загружен донельзя, у него нет времени что-то серьёзно улучшать. Неважно, что пароли в примере не хэшируются. Они хранятся в виде обычного текста прямо рядом с кодом логики валидации. А хранилище учётных данных здесь даже не рассматривается. Чудная получится система аутентификации.
Поищем ещё одно учебное руководство по passport-local. Например, мне попался этот материал от RisingStack, который входит в серию руководств «Node Hero». Однако, и эта публикация мне совершенно не помогла. Она тоже давала пример приложения на GitHub, но имела те же проблемы, что и официальное руководство. Тут, однако, надо отметить, что 8-го августа стало известно о том, что RisingStack теперь использует bcrypt в своём демонстрационном приложении.
Далее, вот ещё один результат из Google, выданный по запросу express js passport-local tutorial. Руководство написано в 2015-м. Оно использует Mongoose ODM и читает учётные данные из базы данных. Тут есть всё, включая интеграционные тесты, и, конечно, ещё один шаблон, который можно использовать. Однако, Mongoose ODM хранит пароли, используя тип данных String, как и в предыдущих руководствах, в виде обычного текста, только на этот раз в экземпляре MongoDB. А всем известно, что экземпляры MongoDB обычно очень хорошо защищены.
Вы можете обвинить меня в пристрастном выборе учебных руководств, и вы будете правы, если пристрастный выбор означает щелчок по ссылке с первой страницы выдачи Google.
Возьмём теперь материал с самого верха страницы результатов поиска — руководство по passport-local от TutsPlus. Это руководство лучше, тут используют bcrypt с коэффициентом трудоёмкости 10 для хэширования паролей и замедляют синхронные проверки хэша, используя process.nextTick.
Самый верхний результат в Google, это руководство от scotch.io, в котором так же используется bcrypt с меньшим коэффициентом трудоёмкости, равным 8. И 8, и 10 — это мало, но 8 — это очень мало. Большинство современных bcrypt-библиотек используют 12. Коэффициент трудоёмкости 8 был хорош для административных учётных записей восемнадцать лет назад, сразу после выпуска первой спецификации bcrypt.
Если даже не говорить о хранении секретных данных, ни одно из этих руководств не показывало реализацию механизма сброса паролей. Эта важнейшая часть системы аутентификации, в которой немало подводных камней, была оставлена в качестве упражнения для разработчика.
Ошибка вторая: система сброса паролей
Схожая проблема в области безопасности — сброс пароля. Ни одно из руководств, находящихся в верхней части поисковой выдачи, совершенно ничего не говорит о том, как делать это с использованием Passport. Чтобы это узнать, придётся искать что-то другое.
В деле сброса пароля есть тысячи способов всё испортить. Вот наиболее распространённые ошибки в решении этой задачи, которые мне довелось видеть:
- Предсказуемые токены. Токены, основанные на текущем времени — хороший пример. Токены, построенные на базе плохого генератора псевдослучайных чисел, хотя и выглядят лучше, проблему не решают.
- Неудачное хранилище данных. Хранение незашифрованных токенов сброса пароля в базе данных означает, что если она будет взломана, эти токены равносильны паролям, хранящимся в виде обычного текста. Создание длинных токенов с помощью криптографически стойкого генератора псевдослучайных чисел позволяет предотвратить удалённые атаки на токены сброса пароля методом грубой силы, но не защищает от локальных атак. Токены для сброса пароля следует воспринимать как учётные данные и обращаться с ними соответственно.
- Токены, срок действия которых не истекает. Если срок действия токенов не истекает, у атакующего есть время для того, чтобы воспользоваться временным окном сброса пароля.
- Отсутствие дополнительных проверок. Дополнительные вопросы при сбросе пароля — это стандарт верификации данных де-факто. Конечно, это работает как надо лишь в том случае, если разработчики выбирают хорошие вопросы. У подобных вопросов есть собственные проблемы. Тут стоит сказать и об использовании электронной почты для восстановления пароля, хотя рассуждения об этом могут показаться излишней перестраховкой. Ваш адрес электронной почты — это то, что у вас есть, а не то, что вы знаете. Он объединяет различные факторы аутентификации. Как результат, адрес почты становится ключом к любой учётной записи, которая просто отправляет на него токен сброса пароля.
Если вы со всем этим никогда не сталкивались, взгляните на
шпаргалку по сбросу паролей, подготовленную OWASP. Теперь, обсудив общие вопросы, перейдём к конкретике, посмотрим, что может предложить экосистема Node.
Ненадолго обратимся к npm и посмотрим, сделал ли кто-нибудь библиотеку для сброса паролей. Вот, например, пакет пятилетней давности от в целом замечательного издателя substack. Учитывая скорость развития Node, этот пакет напоминает динозавра, и если бы мне хотелось попридираться к мелочам, то я мог бы сказать, что функция Math.random()предсказуема в V8, поэтому её не следует использовать для создания токенов. Кроме того, этот пакет не использует Passport, поэтому мы идём дальше.
Stack Overflow здесь тоже особенно не помог. Как оказалось, разработчики из компании Stormpath любят писать о своём IaaS-стартапе в любом посте, хоть как-то связанным с этой темой. Их документация тоже всплывает повсюду, они также продвигают свой блог, где есть материалы по сбросу паролей. Однако, чтение всего этого — пустая трата времени. Stormpath — проект нерабочий, 17 августа 2017-го он закрывается.
Ладно, возвращаемся к поиску в Google. На самом деле, такое ощущение, что интересующая нас тема раскрыта в единственном материале. Возьмём первый результат, найденный по запросу express passport password reset. Тут снова встречаем нашего старого друга bcrypt, с даже меньшим коэффициентом трудоёмкости, равным 5, что значительно меньше, чем нужно в современных условиях.
Однако, это руководство выглядит довольно-таки целостным по сравнению с другими, так как оно использует crypto.randomBytes для создания по-настоящему случайных токенов, срок действия которых истекает, если они не были использованы. Однако, пункты 2 и 4 из вышеприведённого списка ошибок при сбросе пароля в этом серьёзном руководстве не учтены. Токены хранятся ненадёжно — вспоминаем первую ошибку руководств по аутентификации, связанную с хранением учётных данных.
Хорошо хотя бы то, что украденные из такой системы токены имеют ограниченный срок действия. Однако, работать с этими токенами очень весело, если у атакующего есть доступ к объектам пользователей в базе данных через BSON-инъекцию, или есть свободный доступ к Mongo из-за неправильной настройки СУБД. Атакующий может просто запустить процесс сброса пароля для каждого пользователя, прочитать незашифрованные токены из базы данных и создать собственные пароли для учётных записей пользователей, вместо того, чтобы заниматься ресурсоёмкой атакой по словарю на хэши bcrypt с использованием мощного компьютера с несколькими видеокартами.
Ошибка третья: токены API
Токены API — это тоже учётные данные. Они так же важны, как пароли и токены сброса паролей. Практически все разработчики знают это и стараются очень надёжно хранить свои ключи AWS, коды доступа к Twitter и другие подобные вещи, однако, к программам, которые они пишут, это часто не относится.
Воспользуемся системой JSON Web Tokens (JWT) для создания учётных данных доступа к API. Применение токенов без состояния, которые можно добавлять в чёрные списки и нужно запрашивать, это лучше, чем старый шаблон API key/secret, который использовался в последние годы. Возможно, наш начинающий Node.js-разработчик где-то слышал о JWT, или даже видел пакет passport-jwt и решил реализовать в своём проекте стратегию JWT. В любом случае, JWT — это то место, где кажется, что все попадают в сферу влияния Node.js. (Почтенный Томас Пташек заявит, что JWT — это плохо, но я сомневаюсь, что его кто-нибудь услышит).
Поищем по словам express js jwt в Google и откроем первый материал в поисковой выдаче, руководствоСони Панди об аутентификации пользователей с применением JWT. К несчастью, этот материал нам ничем не поможет, так как в нём не используется Passport, но пока мы на него смотрим, отметим некоторые ошибки в хранении учётных данных:
- Ключи JWT хранятся в виде обычного текста в GitHub-репозитории.
- Для хранения паролей используется симметричный шифр. Это означает, некто может завладеть ключом шифрования и расшифровать все пароли. К тому же, тут наблюдаются неправильные взаимоотношения между ключом шифрования и секретным ключом JWT.
- Здесь, для шифрования данных в хранилище паролей, используется алгоритм AES-256-CTR. AES вообще не стоит использовать, и данный его вариант ничего не меняет. Я не знаю, почему был выбран именно этот алгоритм, но только одно это делает зашифрованные данные уязвимыми.
Да уж… Вернёмся к Google и поищем ещё руководств. Ресурс scotch.io, который, в руководстве по passport-local, проделал замечательную работу, касающуюся хранилища паролей, просто
игнорирует свои же идеи и хранит пароли в новом примере в виде обычного текста.
Однако, я решил дать этому руководству шанс, хотя его нельзя рекомендовать любителям копипастить. Это из-за одной интересной особенности, которая заключается в том, что тут выполняется сериализация объекта пользователя Mongoose в JWT.
Клонируем репозиторий этого руководства, следуя инструкциям развернём и запустим приложение. После нескольких DeprecationWarning от Mongoose можно будет перейти на http://localhost:8080/setup и создать пользователя. Затем, отправив на /api/authenticate учётные данные — «Nick Cerminara» и «password», мы получим токен, Просмотрим его в Postman.

JWT-токен, полученный из программы, описанной в руководстве scotch.io
Обратите внимание на то, что JWT-токен подписан, но не зашифрован. Это означает, что большой фрагмент двоичных данных между двумя точками — это объект в кодировке Base64. По-быстрому его раскодируем и перед нами откроется кое-что интересное.
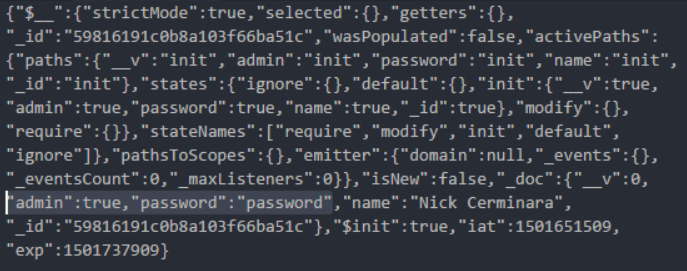
Что может быть лучше пароля в виде обычного текста
Теперь любой, у кого есть токен, даже такой, срок действия которого истёк, имеет пароль пользователя, а заодно и всё остальное, что хранится в модели Mongoose. Учитывая то, что токен передаётся по HTTP, завладеть им можно с помощью обычного сниффера.
Как насчёт ещё одного руководства? Оно рассчитано на новичков и посвящено аутентификации с использованием Express, Passport и JWT. В нём наблюдается та же уязвимость, связанная с раскрытием информации. Следующее руководство, подготовленное стартапом SlatePeak, выполняет такую же сериализацию. На данном этапе я прекратил поиски.
Ошибка четвёртая: ограничение числа попыток аутентификации
Я не нашёл упоминаний об ограничении числа попыток аутентификации или о блокировке аккаунта ни в одном из рассмотренных руководств.
Без ограничения числа попыток аутентификации, атакующий может выполнить онлайновую атаку по словарю, например, с помощью Burp Intruder, в надежде получить доступ к учётной записи со слабым паролем. Блокировка аккаунта так же помогает в решении этой проблемы благодаря требованию ввода дополнительной информации при следующей попытке входа в систему.
Помните о том, что ограничение числа попыток аутентификации способствует доступности сервиса. Так, использование bcrypt создаёт серьёзную нагрузку на процессор. Без ограничений, функции, в которых вызывают bcrypt, становятся вектором отказа в обслуживании уровня приложения, особенно при использовании высоких значений коэффициента трудоёмкости. В результате обработка множества запросов на регистрацию пользователей или на вход в систему с проверкой пароля создаёт высокую нагрузку на сервер.
Хотя подходящего учебного руководства на эту тему у меня нет, есть множество вспомогательных библиотек для ограничения числа запросов, таких, как express-rate-limit, express-limiter, и express-brute. Не могу говорить об уровне безопасности этих модулей, я их даже не изучал. В целом, я порекомендовал бы использовать в рабочих системах обратный прокси и передавать обработку ограничения числа запросов nginx или любому другому балансировщику нагрузки.
Итоги: аутентификация — задача непростая
Скорее всего авторы учебных руководств будут защищать себя со словами: «Это лишь объяснение основ! Уверены, никто не будет использовать этого в продакшне!». Однако, я не могу не указать на то, что эти слова не соответствуют действительности. Это особенно справедливо, если к учебным руководствам прилагается код. Люди верят словам авторов руководств, у которых гораздо больше опыта, чем у тех, кто руководства читает.
Если вы — начинающий разработчик — не доверяйте учебным руководствам. Копипастинг кода из таких материалов, наверняка, приведёт вас, вашу компанию, и ваших клиентов, к проблемам в сфере Node.js-аутентификации. Если вам действительно нужны надёжные, готовые к использованию в продакшне, всеобъемлющие библиотеки для аутентификации, взгляните на что-то, чем вам удобно будет пользоваться, на что-то, что обладает большей стабильностью и лучше испытано временем. Например — на связку Rails/Devise.
Экосистема Node.js, несмотря на свою доступность, всё ещё таит множество опасностей для JS-разработчиков, которым нужно срочно написать веб-приложение для решения реальных задач. Если ваш опыт ограничивается фронтендом, и ничего кроме JavaScript вы не знаете, лично я уверен в том, что легче взять Ruby и встать на плечи гигантов, вместо того, чтобы быстро научиться тому, как не отстрелить себе ногу, программируя подобные решения с нуля для Node.
Если вы — автор учебного руководства, пожалуйста, обновите его, в особенности это касается шаблонного кода. Этот код попадёт в продакшн.
Если вы — убеждённый Node.js-разработчик, надеюсь, вы нашли в моём рассказе что-нибудь полезное, касающееся того, чего лучше не делать в вашей системе аутентификации, основанной на Passport. Наверняка, если такая система у вас уже есть, что-то в ней сделано неправильно. Я не говорю о том, что мой материал покрывает все возможные ошибки аутентификации. Создание системы аутентификации для Express-приложения — это задача разработчика, который понимает все тонкости конкретного проекта. В результате получиться у него должно что-то качественное и надёжное. Если вы хотите обсудить вопросы защиты веб-приложений на Node.js — отправьте мне сообщение в Twitter.
Автор публикации сообщает, что 7-го августа, с ним связались представители RisingStack. Они сообщили о том, что в их учебных руководствах пароли больше не хранятся в виде обычного текста. Теперь в коде и руководствах они используют bcrypt.
Кроме того, он, вдохновлённый откликами на свой материал, создал этот документ, в котором намеревается собрать всё лучшее из области аутентификации в Node.js.
Уважаемые читатели! Что вы можете сказать об организации системы аутентификации в веб-приложениях, основанных на Node.js?
Комментарии (0)