
В предыдущем главе было много косяков с переводом. Спасибо всем за указания недочетов, текст был полностью переделан. Надеюсь эта глава получилась более «вменяемой» с моей стороны, старался как мог.
В этой главе будут рассмотрены основные строительные материалы Rust программ: переменные и их типы. Мы обсудим такие вопросы, как переменные с базовыми типами, явное указание типа и область видимости переменных. Так же, мы обсудим один из краеугольных камней в стратегии безопасности Rust — неизменяемость.
Комментарии
В идеале программа должны быть самодокументируемой, используя описательные имена переменных и легкий для чтения код, но всегда есть случаи, в которых необходимо указать комментарии с описанием работы программы или алгоритма. Rust имеет следующие правила по написанию комментариев:
- Строчные комментарии (//): Абсолютно все, что идет после //, является комментарием и не будет компилироваться
- Блок или многострочные комментарии (/* */): Все, что находится между начальным /* и конечным */ символами не будет компилироваться
Однако, в Rust желательно использовать только однострочные комментарии, даже для нескольких строк:
fn main() {
// здесь происходит выполнение приложения.
// Тут мы указываем отобразить сообщение с приветствием:
println!("Добро пожаловать в игру!");
}
Используйте блочные комментарии только нужно закомментировать кода.
Rust также имеет комментарии документации (///), их полезно использовать в больших проектах, где требуется официальная документация для разработчиков. Эти комментарии устанавливаются перед элементом на отдельной строке и поддерживают язык разметки Markdown:
/// Начало выполнения игры
fn main() {
}
За сборку комментариев в документацию отвечает инструмент
rustdoc.
Глобальные константы
Часто приложению требуется несколько неизменяемых значений (констант). Они не меняются во время работы программы. Предположим, мы хотим написать игру, под названием «
Атака монстров», в которой будет параметр уровня здоровья, имя игры и максимальный уровень здоровья (
100) – это константы. Мы хотим иметь возможность обращаться к этим константам из любого участка кода, для этого мы определяем их в начале файла, иными словами, указываем в глобальной области видимости. Константы объявляются ключевым словом
static:
static MAX_HEALTH: i32 = 100;
static GAME_NAME: &'static str = "Атака Монстров";
fn main() {
}
Имена констант необходимо указывать верхнем регистре, а для разделения слов использовать символ подчеркивания. Также нужно указать константам тип.
MAX_HEALTH является 32-битным целым числом (
i32), а
GAME_NAME – строкой (
str). По такому же принципу объявляется тип у переменной, разница лишь в том, что в переменной его можно иногда не указывать.
Не забивайте пока голову насчет &’static. Поскольку Rust является низкоуровневым языком, многие вещи в нем требуют уточнения. Символ & служит ссылкой на что-то (в ней содержится адрес на значение в памяти), в нашем случае он содержит ссылку на строку. Однако, если мы напишем только &str и скомпилируем, то мы получим ошибку:
static GAME_NAME: &str = "Атака Монстров";
2:22 error: missing lifetime specifier [E0106]
2:22 означает, что у нас ошибка во 2 строке и 22 символе. Также мы должны добавить спецификатор времени жизни
‘static к аннотации типа, в результате мы имеем
&’static str. В Rust время жизни объекта очень важный момент, поскольку от него зависит на сколько долго объект задержится в памяти. Когда время жизни подходит к концу, компилятор Rust избавляется от объекта и освобождает память, которую объект занимал. Время жизни у
‘static самое долгое, такой объект остается жить в программе на протяжение всей ее работы и доступен во всех местах кода.
Но не смотря на то, что мы добавили и спецификатор и ссылку, компилятор все равно выдает нам предупреждение:
static item is never used: `MAX_HEALTH`, #[warn(dead_code)]
Аналогичное предупреждение будет и у
GAME_NAME. Эти предупреждения не препятствуют компиляции и программа соберется. Тем не менее, компилятор прав, на протяжение всего кода к этим объектам никто не обращался. Если у вас будет настоящий проект, то воспользуйтесь объектами или удалите их.
Совет
Пройдет какое-то время, прежде чем начинающий разработчик начнет считать Rust компилятор своим другом, а не раздражающей машиной, которая постоянно выплевывает ошибки и предупреждения. К пример, если выйдет подобная ошибка, программа не запустится:
error: aborting due to previous errors
Но помните: исправление ошибок устраняет проблемы с запуском, таким образом, это экономит вам кучу времени, которое может уйти впустую на поиски глюков. Часто в сообщениях об ошибке также указывается и полезная информация о том, как устранить эту проблему. Rust так же предупреждает нас о неиспользуемых объектах в коде, например переменных, функций, импортируемых модулей и прочее. Если у вас определена изменяемая переменная (то есть, переменная которую можно изменять) и на протяжение всего кода она не меняла свое значение, Rust также выдаст предупреждение при компиляции. Компилятор настолько хорошо делает свою работу, что если вам удастся исправить все замечания, скорее всего ваша программа будет работать корректно!
Помимо статических значений мы также можем использовать простые неизменяемые значения. Константы всегда нужно объявлять с указанием типа, например: const PI: f32 = 3.14.
Печать с помощью интерполяции строк
Очевидный способ использования переменных- это выводить их значения:
static MAX_HEALTH: i32 = 100;
static GAME_NAME: &'static str = "Атака Монстров";
fn main() {
const PI: f32 = 3.14;
println!("Игра, в которую вы играете, называется {}.", GAME_NAME);
println!("У вас {} единиц жизней", MAX_HEALTH);
}
После запуска программа выдаст следующее:
Игра, в которую вы играете, называется Атака Монстров.
У вас 100 единиц жизней
Константа
PI имеется в стандартной библиотеке, чтобы ей воспользоваться установите этот оператор в начале кода:
use std::f32::consts;
А работать с ней можно вот так:
println!("{}", consts::PI);
Первый аргумент внутри
println! – это литеральная строка, содержащая плейсхолдер (placeholder)
{}. Значение константы после запятой преобразуется в строку и вставляется заместо
{}. Можно указать несколько плейсхолдеров, пронумеровав их по порядку:
println!("В игре '{0}', у вас будет {1} % очков жизни, да, вы прочли правильно: {1} очков!", GAME_NAME, MAX_HEALTH);
Программа выдаст следующее:
В игре 'Атака Монстров', у вас будет 100 % очков жизни, да, вы прочли правильно: 100 очков!
Плейсхолдер может также содержать один или несколько параметров, передаваемых по имени:
println!("У вас {points} % жизни", points=70);
Программа выдаст:
У вас 70 % жизни
Внутри
{} можно указать тип форматирования:
println!("Значение MAX_HEALTH - {:x}, это шестнадцатеричный формат", MAX_HEALTH); // 64
println!("Значение MAX_HEALTH - {:b}, это бинарный формат", MAX_HEALTH); // 1100100
println!("Значение pi - {:e}, это формат с плавающей запятой", consts::PI); // 3.141593e0
Следующие типы форматирования используются для объектов с определенным типом:
- o для восьмиричного
- x для шестнадцатеричного числа в нижнем регистре
- X для шестнадцатеричного числа в верхнем регистре
- p для указателей
- b для бинарных
- e для экспоненциальной нотации в нижнем регистре
- E для экспоненциальной нотации в верхнем регистре
- ? для отладки
Макрос
format! имеет те же параметры и работает также, как
println!, только он возвращает строку, а не выводит текст.
Для более подробного изучения форматирования можете посетить раздел в официальной документации.
Значения и примитивные типы
У наших констант есть значения. Значение бывает различных типов:
70 – целое число,
3.14 – число с плавающей запятой,
Z и
q – символьный тип (они являются символами) в формате unicode, каждый символ занимает по 4 байта в памяти. “
Godzilla” имеет тип строку
$str (по умолчанию кодировка UTF-8),
true и
false – булевый тип, они являются Булевыми значениями. Целые числа можно написать в различных форматах:
- В шестнадцатеричном формате с 0x (число 70 будет 0x46)
- В восьмеричном формате с 0o (число 70 будет 0o106)
- В бинарном формате с 0b (0b1000110)
Символы подчеркивания можно использовать для читабельности, например
1_000_000. Иногда компилятор будет требовать указать тип числа с суффиксом. Например, после
u или
i указывается число используемых бит памяти:
8,
16,
32, или
64:
- 10usize означает беззнаковое целое число, размер машинного кода usize, которое может быть любым из типов u8, u16,u32 или u64
- 10isize означает знаковое целое число, размер машинного кода isize, которое может быть любым из типов i8, i16, i32, или i64
- 3.14f32 означает 32-битное число с плавающей точкой
- 3.14f64 означает 64-битное число с плавающей точкой
Числовые типы
i32 и
f64 являются значениями по умолчанию, чтобы различить их вам нужно добавить в типе
f64 .0, например так:
let e = 7.0;.
Если компилятор сообщает вам, что он не может определить тип переменной, то необходимо указать его явно.
Приоритеты операторов в Rust похожи на те, что используются в других Си-подобных языках. Однако, Rust не имеет операторов инкремента (++) и декремента (—). Для сравнения двух значений на равенство используется ==, а для проверки их различия- !=.
Существует даже пустое значение () нулевого размера, так называемый тип unit. Он используется для указания на возвращаемое значение, когда выражение или функция ничего не возвращают (нет значения), как и в случае с функцией, которая только печатает текст в консоли. Значение () не эквивалентно значению null в других языках, скобки () означают, что значения нет, тогда как null является значением.
Документация по Rust
Для более глубокого изучения информации по теме, рассказываемой в этой главе, можете воспользоваться официальной документацией по
стандартной библиотеке. Слева располагается список всех контейнеров. Однако, самой полезной функцией там является поле поиска. Введите в нем несколько букв или слово и вы получите ряд ссылок на полезные материалы.
Привязка значения к переменной
Хранение всех значений в константах не самый лучший вариант, так как нам может понадобится изменить какое-нибудь из этих значений. В Rust мы можем привязать значение к переменной с помощью привязки
let:
fn main() {
let energy = 5; // значение 5 привязывается к переменной energy
}
В отличие от таких языков, как Python или Go, нам необходимо указать в конце точку с запятой, чтобы закончить объявление. В противно случае компилятор выдаст ошибку:
error: expected one of `.`, `;`, or an operator, found `}`
Привязку мы тоже создаем пока без ее применения, поэтому не обращайте внимание на предупреждение:
values.rs:2:6: 2:7 warning: unused variable: `energy`, #[warn(unused_variables)] on by default
Совет
Чтобы отключить предупреждения о неиспользуемый переменных используйте префикс нижнего подчеркивания перед именем переменной:
let _energy = 5;
Обратите внимание на то, что в предыдущем примере мы не указывали тип. Rust предположит, что тип переменной
energy будет целое число. Если тип переменной неочевиден, компилятор попробует найти в коде места, где эта переменная использовалась. Однако, можно указывать тип значение и таким способом:
let energy = 5u16;
Это немного поможет компилятору с указанием типа у
energy, в нашей случае мы указали 2-битное беззнаковое целое число.
Мы можем воспользоваться переменной energy, используя его в выражение. Например, присвоить другой переменной или просто распечатать его:
let copy_energy = energy;
println!("Количество энергии: {}", energy););
Вот несколько других объявлений:
let level_title = "Уровень 1";
let dead = false;
let magic_number = 3.14f32;
let empty = (); // значение модульного типа ()
Значение переменной
magic_number также можно записать в формате
3.14_f32. Нижнее подчеркивание отделяет цифры от типа для лучшей читабельности.
Если новой переменной указать существующее уже имя, то она заменит старую переменную. Например, если мы добавим:
let energy = "Очень много";
То старой переменной уже нельзя будет воспользоваться, а ее память будет освобождена.
Изменяемые и неизменяемые переменные
Предположим, что мы используем аптечку и наша энергия поднимается до значения
25. При этом, если мы напишем:
energy = 25;
То мы получим ошибку:
error: re-assignment of immutable variable `energy`
Что здесь не так? Rust использует программную мудрость: много ошибок происходит от случайного или неправильного изменения переменных, так что не позволяйте коду менять значение, если вы осознанно это не указали.
Обратите внимание
Переменные в Rust по умолчанию неизменяемые, тоже самое происходит и в функциональных языках. В чисто функциональных языках изменчивость даже не допускается.
Если вам нужна переменная, которая будет изменяться во время выполнения кода, вам надо объявить ее вместе с mut:
let mut fuel = 34;
fuel = 60;
Объявить простую переменную тоже не получится:
let n;
Подобное приведет к ошибке:
error: unable to infer enough type information about `_`; type annotations required.
Компилятору необходимо указать тип этой переменной. Мы передаем информацию по типу когда присваиваем значение:
n = -2;
Но, как говориться в сообщение, мы также можем указать тип следующим образом:
let n: i32;
Кроме этого, мы можем написать сразу все вместе:
let n: i32 = -2;
Для примитивных типов подобное делается с помощью указания суффикса:
let x = 42u8;
let magic_number = 3.14f64;
Попытка использовать неинициализированную переменную приведет к ошибке:
error: use of possibly uninitialized variable
Чтобы избежать неопределенного поведения, локальные переменные нужно инициализировать прежде, чем они будут использованы.
Область действия переменной и затенение
Взглянем еще раз на пример, который рассматривали выше:
fn main() {
let energy = 5; // значение 5 привязывается к переменной energy
}
Здесь переменная располагается в локальной области функции между символами
{}. После символа
} переменная выходит из области видимости и ее выделенная память освобождается.
Мы можем сделать более ограниченную область видимости внутри функции с помощью определения блока кода, который будет содержаться внутри пары фигурных скобок:
fn main() {
let outer = 42;
{ // начало блока кода
let inner = 3.14;
println!("Переменная inner: {}", inner);
let outer = 99; // показать первую переменную outer
println!("Переменная outer: {}", outer);
} // конец блока кода
println!("Переменная outer: {}", outer);
}
Мы получим такой вывод:
Переменная inner: 3.14
Переменная outer: 99
Переменная outer: 42
Переменная, определенная в блоке (
inner), видна только внутри блока. Переменная внутри блока может иметь такое же имя, как и переменная снаружи (
outer), которая заменяется (затеняется) переменной внутри блока до тех пор, пока выполнение внутреннего блока не завершится.
Итак, зачем нам может понадобиться использовать блок кода? В разделе “Выражения” мы увидим, что блок кода может возвращать значение, которое возможно привязать к переменной с let. Блок кода также может быть пустым – {}.
Проверка и преобразование типа
Rust должен знать тип у каждой переменной, в связи с этим он проводит проверку (во время компиляции) на правильное использование переменных. С точки зрения типов, программы безопасны и можно избежать целого ряда ошибок.
По этой же причине из-за статической типизации мы не можем изменять тип переменной в течение всей ее жизни. Например, переменная scope в следующем примере не может поменять тип с числового на строку:
fn main() {
let score: i32 = 100;
score = "ВЫ ПОБЕДИЛИ!"
}
Мы получим ошибку компилятора:
error: mismatched types: expected `i32`, found `&'static str`(expected i32, found &-ptr)
Однако, нам разрешено писать вот так:
let score = "YOU WON!";
Rust позволяет нам переопределять переменные. Каждая привязка
let создает новую переменную
score, скрывая предыдущую, которая освобождает память. На самом деле, это очень полезно, потому как переменные по умолчанию являются неизменными.
Добавление строки с помощью + в Rust не будет работать:
let player1 = "Ваня";
let player2 = "Петя";
let player3 = player1 + player2;
Мы получим ошибку:
error: binary operation `+` cannot be applied to type `&str`.
Вы можете воспользоваться функцией
to_string(), чтобы преобразовать тип значения в
String:
let player3 = player1.to_string() + player2;
Или же воспользуйтесь макросом
format!:
let player3 = format!("{}{}", player1, player2);
В обоих случаях переменная
player3 будет иметь значение “
ВаняПетя“.
Давайте выясним, что произойдет, если присвоить значение переменной одного типа к значению другого типа:
fn main() {
let points = 10i32;
let mut saved_points: u32 = 0;
saved_points = points; // ошибка!
}
Опять не получилось. Мы получили ошибку:
error: mismatched types: expected `u32`, found `i32` (expected u32, found i32)
Для максимальной проверки типа Rust не позволяет автоматическое (или неявное) преобразование одного типа в другой, как это сделано в C++. Например, когда значение
f32 преобразовано в значение
ani32, числа после десятичной запятой теряются, если делать это автоматически, то могут произойти ошибки. Однако, мы можем сделать явное преобразование (кастинг) с помощью ключевого слова
as:
saved_points = points as u32;
Когда
points содержит отрицательное значение, знак будет утерян после преобразования. Точно так же большое значение, как
float, преобразуется в целое число, десятичная часть отсекается:
let f2 = 3.14;
saved_points = f2 as u32; // будет обрезано до значения 3
Кроме того, значение должно быть конвертируемым в новый тип, так как строку нельзя будет преобразовать в целое число:
let mag = "Gandalf";
saved_points = mag as u32; // error: non-scalar cast:`&str`as`u32`
Сглаживание
Иногда может быть полезно дать новое, более описательное или короткое имя существующему типу. Это можно сделать с помощью
type:
type MagicPower = u16;
fn main() {
let run: MagicPower= 7800;
}
Имя в
type начинается с заглавной буквы, как и каждое слово, которое является частью имени. Что произойдет, если мы поменяем значение с
7800 на
78000? Компилятор выдаст нам следующее предупреждение:
warning: literal out of range for its type.
Выражения
Rust – выражение-ориентированный язык, это значит, что большинство фрагментов кода являются выражениями, то есть, они вычисляют значение и возвращают значение (в этом смысле, что значения тоже являются выражениями). Однако, выражения сами по себе не образуют осмысленный код, они должны использоваться совместно с операторами.
Привязки let являются операторами объявления. Они не являются выражениями:
let a = 2; // a привязывается к 2
let b = 5; // b привязывается к 5
let n = a + b; // n привязывается к 7
a + b; является оператором выражения, он возвращает пусто значение
(). Если нам надо вернуть результат сложения, то нужно убрать точку с запятой. Rust’у необходимо знать когда операторы заканчивают свое действие, по это причине, практически все строки в Rust заканчиваются точкой с запятой.
Как вы думаете, что здесь присваивается?
m = 42;
Это не привязка, поскольку отсутствует
let. Это – выражение, возвращающее пустое значение
(). Составная привязка, как здесь:
let p = q = 3;
в Rust вообще запрещена. Это вернет ошибку:
error: unresolved name q
Однако, вы можете воспользоваться привязкой let:
let mut n = 0;
let mut m = 1;
let t = m; m = n; n = t;
println!("{} {} {}", n, m, t); // будет напечатано 1 0 1
Блок кода также является выражением, который будет возвращать значение своего последнего выражения, если мы опустим точку с запятой. Например, в следующем фрагменте кода,
n1 получает значение
7, но
n2 получает не значение, потому что возвращаемое значение во втором блоке было подавлено:
let n1 = {
let a = 2;
let b = 5;
a + b // <-- нет точки с запятой!
};
println!("n1: {}", n1); // выведет - "n1: 7"
let n2 = {
let a = 2;
let b = 5;
a + b;
};
println!("n2: {:?}", n2); // выведет - "n2: ()"
Здесь переменные
a и
b объявлены в блоке кода и живы пока живет сам блок, так как переменные локальны для блока. Обратите внимание на то, что необходима точка с запятой после закрывающей фигурной скобки блока
} ;. Для печати пустого значения
(), нам нужно указать
{:?}, как спецификатор формата.
Стек и куча
Поскольку выделение памяти является очень важной темой в Rust, нам надо иметь четкую картину всего происходящего. Память программы разделяется на стек и кучу. На
stackoverflow более детально описали эти понятия. Примитивные значения, такие как цифры, символы, значения true/false, хранятся в стеке, в то время, как значения более сложных объектов, которые могут расти, размещаются в куче памяти. В стеке содержатся адреса памяти на объекты, которые располагаются в куче:
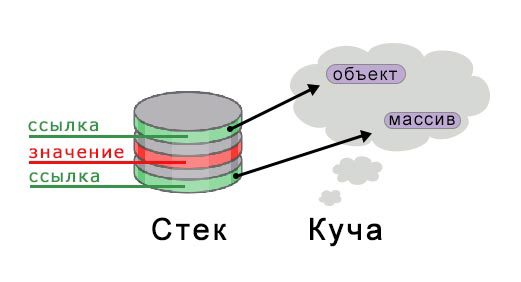
В то время, как стек имеет ограниченный размер, размер кучи может расти до необходимых ему размеров.
Давайте выполним следующий пример и попытаемся визуализировать память программы:
let health = 32;
let mut game = "Космические захватчики";
Значения хранятся в памяти и имеют адреса. Переменная
health содержит целое число со значением
32, которое хранится в стеке с адресом
0x23fba4, в то время, как переменная
game содержит строку, которая хранится в куче, начиная свое положение с адреса
0x23fb90. Это были адреса на момент запуска программы, когда вы запустите программу они будут другими.
Переменные, к которым привязаны значения, являются указателями или ссылками на значения. game является ссылкой на “Космические захватчики“. Адрес задается оператором &. Таким образом, &health будет указывать на место расположения значения 32, а &game на место где лежит “Космические захватчики“.
Мы можем распечатать эти адреса при помощи строки, используя формат {:p} для указателей:
println!("Адрес значения health: {:p}", &health); // 0x23fba4
println!("Адрес значения game: {:p}", &game); // 0x23fb90
println!("Значение переменной game: {}", game); // напечатает "Космические захватчики"
Итак, мы имеем следующую ситуацию в памяти (адреса памяти будут отличаться при каждом выполнении):
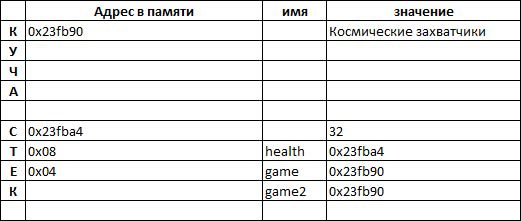
Мы можем создать псевдоним, который будет является другой ссылкой, указывающей на то же место в памяти:
let game2 = &game;
println!("{:p}", game2); // 0x23fb90
Чтобы получить значение объекта, а не его ссылку, добавьте к имени звездочку:
println!("{}", *game2); // напечатает "Космические захватчики"
Эта строка эквивалентна:
println!("game: {}", &game);
Приведенный пример немного упрощен, так как Rust будет еще выделять значения в стеке, который не будет изменяться в размере. Это все делалось с целью показать вам, как работают ссылки на значения.
Мы уже знаем, что привязка let является неизменяемой, так что это значение нельзя изменить:
health = 33; // error: re-assignment of immutable variable `health`.
Если
y объявить как:
let y = &health;
Тогда
*y будет иметь значение
32. Ссылочным переменным можно также дать тип:
let x: &i64;
После привязки
let, переменная
x еще не указывает на значение, и она не содержит адрес памяти. В Rust нет способа создать нулевой указатель, как это делается в других языках. При попытке присвоить переменной
x значение
nil,
null или пустое значение
(), приведет к ошибке. Одна только эта особенность спасает программистов Rust от бесчисленных ошибок. Кроме того, пытаясь использовать
x в выражении, например:
println!("{:?}", x);
Мы получим ошибку:
error: use of possibly uninitialized variable: `x`error
Запрещено размещать изменяемую ссылку на неизменяемый объект, в противном случае неизменяемую переменную можно будет редактировать через изменяемую ссылку:
let tricks = 10;
let reftricks = &mut tricks;
Будет выдана ошибка:
error: cannot borrow immutable local variable `tricks` as mutable
Ссылка на изменяемую перемененную
score может быть неизменяемой или изменяемой соответственно:
let mut score = 0;
let score2 = &score;
// error: cannot assign to immutable borrowed content *score2
// *score2 = 5;
let mut score = 0;
let score3 = &mut score;
*score3 = 5;
Значение в
score можно изменить только с помощью изменяемой ссылки
score3.
По некоторым причинам, которые мы рассмотрим позже, вы можете сделать только одну изменяемую ссылку на изменяемую переменную:
let score4 = &mut score;
Будет выдана ошибка:
error: cannot borrow `score` as mutable more than once at a time
Здесь мы касаемся сердце системы безопасности памяти Rust, где заимствование переменной является одним из его ключевых понятий.
Куча занимает намного больше места в памяти, чем стек, поэтому важно, чтобы ячейки памяти освобождались по окончанию работы. Rust видит когда у переменной должно закончится время жизни (другими словами, выходит за пределы области видимости), во время компиляции он вставляет код в этом месте, который будет освобождать память во время работы программы. В других языках программирования такого поведения нет.
Значения стека можно упаковать, то есть, разместить в куче, для этого используется Box:
let x = Box::new(5i32);
Box является объектом, который ссылается на значения в куче.
This entry passed through the Full-Text RSS service - if this is your content and you're reading it on someone else's site, please read the FAQ at http://ift.tt/jcXqJW.