«Нода» — сервер RabbitMQ.
«Кластер» — совокупность, в нашем случае трех, нод RabbitMQ работающих как единое целое.
«Контур» — совокупность кластеров RabbitMQ, правила работы с которыми определяются на стоящем перед ними балансировщике.
«Балансировщик», «хап» — Haproxy – балансировщик, выполняющий функции переключения нагрузки на кластеры в рамках контура. Для каждого контура используется пара серверов Haproxy, работающих параллельно.
«Подсистема» — публикатор и/или потребитель сообщений, передаваемых через кролика
«СИСТЕМА» — совокупность Подсистем, являющая собой единое программно-аппаратное решение, используемое в Компании, характеризующееся распределённостью по всей территории России, но обладающее несколькими центрами, куда стекается вся информация и где происходят основные расчёты и вычисления.
СИСТЕМА – географически распределённая система – от Хабаровска и Владивостока до Санкт-Петербурга и Краснодара. Архитектурно это несколько центральных Контуров, разделенных по особенностям подсистем, к ним подключённым.
Какая задача возлагается на транспорт в реалиях телекома?
В двух словах: на каждое действие абонента следует реакция Подсистем, которые в свою очередь информирует другие Подсистемы о событиях и последующих изменениях. Сообщения порождаются любыми действиями с СИСТЕМОЙ, не только со стороны абонентов, но и со стороны сотрудников Компании, и со стороны Подсистем (очень большое количество задач выполняется в автоматическом режиме).
Особенности транспорта в телекоме: большой, нет не так, БОЛЬШОЙ поток разнообразных данных, передаваемых через асинхронный транспорт.
Некоторые Подсистемы живут на отдельных Кластерах в силу тяжеловесности потоков сообщений – ни на кого другого на кластере просто не остаётся ресурсов, например, при потоке сообщений 5-6 тыс. сообщений / секунду, объём передаваемых данных может доходить до 170-190 Мегабайт / секунду. При таком профиле нагрузки попытка приземлить на этот кластер ещё кого ни будь, приведёт к печальным последствиям: поскольку ресурсов для обработки всех данных одновременно не хватает, кролик начнёт загонять входящие соединения во flow – начнётся простой публикаторов, со всеми последствиями для всех Подсистем и СИСТЕМЫ в целом.
Основные требования к транспорту:
- Доступность транспорта должны быть 99,99%. На практике это выливается в требование обеспечения работы 24/7 и способность автоматически реагировать на любые аварийные ситуации.
- Обеспечение сохранности данных: % потерянных сообщений на транспорте должен стремиться к 0.
Например, на сам факт совершения вызова, через асинхронный транспорт пролетает несколько разных сообщений. какие-то сообщения предназначены для подсистем, живущих в этом же Контуре, а какие-то предназначены для передачи в центральные узлы. Одно и то же сообщение может быть востребовано несколькими подсистемами, поэтому на этапе публикации сообщения в кролика происходит его копирование и направление к разным потребителям. А в некоторых случаях копирование сообщений вынужденно реализовывается на промежуточном Контуре – когда информацию надо доставить от Контура в Хабаровске, до контура в Краснодаре. Передача выполняется через один из центральных Контуров, где делаются копии сообщений, для центральных получателей.
Кроме событий, вызванных действиями абонента, через транспорт ходят сообщения служебные, которыми обмениваются Подсистемы. Таким образом получается несколько тысяч разных маршрутов передачи сообщений, некоторые пересекаются, некоторые существуют изолированно. Достаточно назвать количество вовлечённых в маршруты очередей на разных Контурах, чтобы понять примерный масштаб транспортной карты: На центральных контурах 600, 200, 260, 15…и на удалённых Контурах по 80-100…
При такой вовлечённости транспорта требования о 100% доступности всех транспортных узлов уже не кажутся чрезмерными. К реализации этих требований мы и переходим.
Как мы решаем поставленные задачи
Кроме непосредственно RabbitMQ, для балансировки нагрузки и обеспечения автоматического реагирования на аварийные ситуации, используется Haproxy.
Несколько слов об программно-аппаратном окружении, в котором существуют наши кролики:
- Все сервера кроликов виртуальные, с параметрами 8-12 CPU, 16 Gb Mem, 200 Gb HDD. Как показал опыт, даже использование жутких не виртуальных серверов на 90 ядер и кучей ОЗУ обеспечивает небольшой прирост производительности при значительно больших затратах. Используемые версии: 3.6.6 (на практике – самая устойчивая из 3.6) с эрлангом 18.3, 3.7.6 с эрлангом 20.1.
- Для Haproxy требования значительно ниже: 2 CPU, 4 Gb Mem, версия haproxy – 1.8 stable. Загруженность по ресурсам, на всех серверах haproxy, не превышает 15% CPU/Mem.
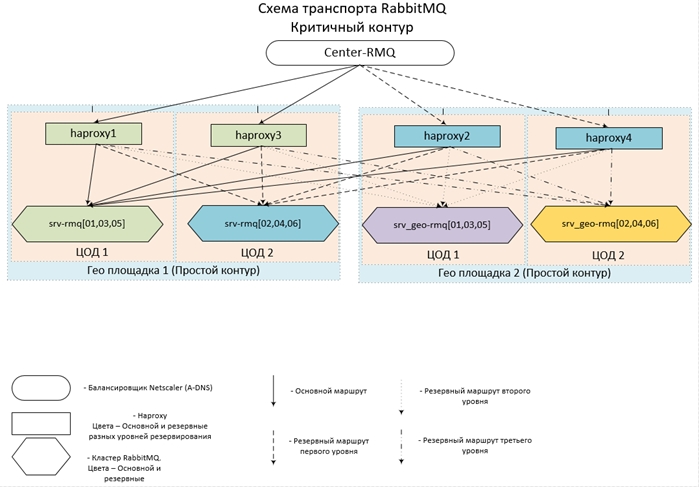
- Располагается весь зоопарк в 14 ЦОДах на 7 площадках по всей стране, объединённых в единую сеть. В каждом из ЦОДов располагается Кластер из трёх Нод и один Хап.
- Для удалённых Контуров используются по 2 ЦОДа, для каждого из центральных Контуров — по 4.
- Центральные Контуры взаимодействуют как между собой, так и с удалёнными Контурами, в свою очередь удалённые Контуры работают только с центральными, прямой связи между собой не имеют.
- Конфигурации Хапов и Кластеров в рамках одного Контура полностью идентичны. Точкой входа для каждого Контура псевдоним на несколько A-DNS записей. Таким образом, чтобы не произошло, будет доступен хотя бы один хап и хотя бы один из Кластеров (хотя бы одна нода в Кластере) в каждом Контуре. Поскольку случай выхода из строя даже 6 серверов в двух ЦОДах одновременно крайне маловероятен, принимается доступность близкая к 100%.
Выглядит задуманное (и реализованное) всё это примерно так:

Теперь немного конфигов.
| frontend center-rmq_5672 | ||
| bind | *:5672 | |
| mode | tcp | |
| maxconn | 10000 | |
| timeout client | 3h | |
| option | tcpka | |
| option | tcplog | |
| default_backend | center-rmq_5672 | |
| frontend center-rmq_5672_lvl_1 | ||
| bind | localhost:56721 | |
| mode | tcp | |
| maxconn | 10000 | |
| timeout client | 3h | |
| option | tcpka | |
| option | tcplog | |
| default_backend | center-rmq_5672_lvl_1 | |
| backend center-rmq_5672 | ||
| balance | leastconn | |
| mode | tcp | |
| fullconn | 10000 | |
| timeout | server 3h | |
| server | srv-rmq01 10.10.10.10:5672 check inter 5s rise 2 fall 3 on-marked-up shutdown-backup-sessions | |
| server | srv-rmq03 10.10.10.11:5672 check inter 5s rise 2 fall 3 on-marked-up shutdown-backup-sessions | |
| server | srv-rmq05 10.10.10.12:5672 check inter 5s rise 2 fall 3 on-marked-up shutdown-backup-sessions | |
| server | localhost 127.0.0.1:56721 check inter 5s rise 2 fall 3 backup on-marked-down shutdown-sessions | |
| backend center-rmq_5672_lvl_1 | ||
| balance | leastconn | |
| mode | tcp | |
| fullconn | 10000 | |
| timeout | server 3h | |
| server | srv-rmq02 10.10.10.13:5672 check inter 5s rise 2 fall 3 on-marked-up shutdown-backup-sessions | |
| server | srv-rmq04 10.10.10.14:5672 check inter 5s rise 2 fall 3 on-marked-up shutdown-backup-sessions | |
| server | srv-rmq06 10.10.10.5:5672 check inter 5s rise 2 fall 3 on-marked-up shutdown-backup-sessions |
Первая секция фронта описывает точку входа – ведущую на основной Кластер, вторая секция предназначена для балансировки резервного уровня. Если просто описать в секции backend все резервные сервера кроликов (инструкция backup), то срабатывать будет так же – при полной недоступности основного кластера, соединения пойдут на резервный, однако, все соединения пойдут на ПЕРВЫЙ в списке backup сервер. Для обеспечения балансировки нагрузки на все резервные ноды, как раз и вводим ещё один фронт, который делаем доступным только с localhost и именно его назначаем backup сервером.
Приведённый пример описывает балансировку удалённого Контура – который работает в рамках двух ЦОДов: сервера srv-rmq{01,03,05} – живут в ЦОД №1, srv-rmq{02,04,06} – в ЦОД №2. Таким образом для реализации четырёх-цодового решения нам требуется только дописать ещё два локальных фронта и две backend секции соответствующих серверов кроликов.
Поведение балансировщика с такой конфигурацией следующее: Пока жив хотя бы один основной сервер, используем его. Если недоступны основные сервера – работаем с резервом. Если хотя бы один основной сервер становится доступен – все соединения с резервными серверами разрываются и при восстановлении подключения уже попадают на основной Кластер.
Опыт эксплуатации такой конфигурации показывает практически 100% доступность каждого из Контуров. Данное решение требует от Подсистем вполне законного и простого: уметь восстанавливать соединение с кроликом после разрыва связи.
Итак, балансировку нагрузки на произвольное количество Кластеров и автоматическое переключение между ними мы обеспечили, пора переходить непосредственно к кроликам.
Каждый Кластер создан из трёх нод, как показывает практика – наиболее оптимальное количество нод, при котором обеспечивается оптимальный баланс доступность / отказоустойчивость / скорость работы. Поскольку кролик горизонтально не масштабируется (производительность кластера равна производительности самого медленного сервера), создаём все ноды с одинаковыми, оптимальными параметрами по CPU/Mem/Hdd. Располагаем сервера как можно ближе друг к другу – в нашем случае запиливаем виртуальные машины в рамках одной фермы.
Что касается предварительных условий, следование которым со стороны Подсистем обеспечит максимально устойчивую работу и выполнение требования о сохранении поступивших сообщений:
- Работа с кроликом идёт только по протоколу amqp/amqps – через балансировку. Авторизация под локальными учётками — в рамках каждого Кластера (ну и Контура в целом)
- Подсистемы подключаются к кролику в пассивном режиме: Никаких манипуляций с сущностями кролей (создание очередей/эксченджей/биндов) не допускается и ограничивается на уровне прав учётных записей – на конфигурирование прав просто не даём.
- Все необходимые сущности создаются централизовано, не средствами Подсистем и на всех Кластерах Контура делаются одинаково – для обеспечения автоматического переключения на резервный Кластер и обратно. Иначе можем получить картину: на резерв переключились, а очереди или бинда там нет, и можем получить на выбор либо ошибку подключения, либо пропажу сообщений.
Теперь непосредственно настройки на кроликах:
- У локальных УЗ нет доступа к Web интерфейсу
- Доступ к Web организуется чрез LDAP – интегрируем с AD и получаем логирование кто и куда на вебке ходил. На уровне конфигурации ограничиваем права у учёток AD, мало того, что требуем нахождение в определённой группе, так и права даём только на «посмотреть». Группы monitoring более чем достаточно. А права администратора навешиваем на другую группу в AD, таким образом сильно ограничивается круг влияния на транспорт.
- Для облегчения администрирования и отслеживания:
На всех VHOST сразу вешаем политику 0 уровня с применением на все очереди (pattern: .*):- ha-mode: all – хранить все данные на всех нодах кластера, снижается скорость обработки сообщений, но обеспечивается их сохранность и доступность.
- ha-sync-mode: automatic – поручаем кролю автоматически синхронизировать данные на всех нодах кластера: так же увеличивается сохранность и доступность данных.
- queue-mode: lazy – пожалуй одна из самых полезных опций, появившаяся в кроликах с версии 3.6 – немедленная запись сообщений на HDD. Данная опция кардинально снижает потребление ОЗУ и увеличивает сохранность данных при остановках/падениях нод или кластера в целом.
- Настройки в файле конфигурации (rabbitmq-main/conf/rabbitmq.config):
- Секция rabbit: {vm_memory_high_watermark_paging_ratio, 0.5} – порог выгрузки сообщений на диск 50%. При включённом lazy служит больше как страховка, когда нарисуем политику, например, 1 уровня, в которую забудем включить lazy.
- {vm_memory_high_watermark, 0.95} – ограничиваем кроля 95% всей ОЗУ, поскольку на серверах живёт только кролик, нет смысла вводить более жёсткие ограничения. 5% «широким жестом» так и быть – оставляем ОС, мониторингу и прочим полезным мелочам. Поскольку это значение является верхней границей — ресурсов хватает всем.
- {cluster_partition_handling, pause_minority} – описывает поведение кластера при возникновении Network Partition, для трёх и более нодового кластера рекомендуется именно такой флаг – позволяет кластеру самому восстановиться.
- {disk_free_limit, «500MB»} – тут всё просто, когда останется свободного места на диске 500 MB – публикация сообщений будет остановлена, будет доступно только вычитывание.
- {auth_backends, [rabbit_auth_backend_internal, rabbit_auth_backend_ldap]} — порядок авторизации на кроликах: Сначала проверяется наличие УЗ в локальной базе и если не находится – идём на сервера LDAP.
- Секция rabbitmq_auth_backend_ldap – конфигурация взаимодействия с AD: {servers, [«srv_dc1»,«srv_dc2»]} – список контроллеров домена, на которых и будет проходить аутентификация.
- Параметры, непосредственно описывающие пользователя в AD, порт LDAP и прочее, сугубо индивидуальны и подробно описаны в документации.
- Самое важное для нас – описание прав и ограничений на администрирование и доступ к Web интерфейсу кролей: tag_queries:
[{administrator,{in_group, «cn=rabbitmq-admins,ou=GRP,ou=GRP_MAIN,dc=My_domain,dc=ru»}},
{monitoring,
{in_group, «cn=rabbitmq-web,ou=GRP,ou=GRP_MAIN, dc=My_domain,dc=ru»}
}] – данная конструкция обеспечивает административные привилегии всем пользователям группы rabbitmq-admins и права monitoring (минимально достаточные для доступа на просмотр) для группы rabbitmq-web. - resource_access_query:
{for,
[{permission,configure, {in_group, «cn=rabbitmq-admins,ou=GRP,ou=GRP_MAIN,dc=My_domain,dc=ru»}},
{permission,write, {in_group, «cn=rabbitmq-admins,ou=GRP,ou=GRP_MAIN,dc=My_domain,dc=ru»}},
{permission, read, {constant, true}}
]
} – обеспечиваем права на конфигурирование и запись только группе администраторов, всем остальным, кто успешно авторизуется права доступны только на чтение – вполне может вычитать сообщения через Web интерфейс.
Получаем сконфигурированный (на уровне файла конфигурации и настроек в самом кролике) кластер, который максимально обеспечивает доступность и сохранность данных. Этим мы реализуем требование – обеспечение доступности и сохранности данных…в большинстве случаев.
Есть несколько моментов, которые стоит учитывать при эксплуатации подобных высоко нагруженных систем:
- Все дополнительные свойства очередей (TTL, expire, max-length и прочее) лучше организовывать политиками, а не вешать параметрами при создании очередей. Получается гибко настраиваемая структура, которую можно подгонять на лету под изменяющиеся реалии.
- Использование TTL. Чем длиннее очередь, тем выше будет нагрузка на CPU. Чтобы не допустить «пробивания потолка» лучше длину очереди так же ограничить через max-length.
- Кроме самого кролика на сервере крутится ещё некоторое количество служебных приложений, которым, как ни странно, тоже требуются ресурсы CPU. А прожорливый кролик, по умолчанию, занимает все доступные ядра…Может получиться неприятная ситуация: борьба за ресурсы, которая запросто приведёт к тормозам на кролике. Избежать возникновения такой ситуации можно, например, так: Изменить параметры запуска эрланга – ввести принудительное ограничение на количество используемых ядер. Делаем это следующим образом: находим файл rabbitmq-env, ищем параметр SERVER_ERL_ARGS= и добавляем к нему +sct L0-Xc0-X +S Y:Y. Где X-число ядер-1 (отсчёт начинается с 0), Y – Количество ядер -1 (отсчёт с 1). +sct L0-Xc0-X – меняет привязку к ядрам, +S Y:Y – изменяет число шедулеров, запускаемых эрлангом. Так для системы из 8 ядер добавляемые параметры примут вид: +sct L0-6c0-6 +S 7:7. Этим мы отдаём кролику только 7 ядер и рассчитываем, что ОС запуская другие процессы поступит оптимально и повесит их на не нагруженное ядро.
Нюансы эксплуатации получившегося зоопарка
От чего не может защитить никакая настройка, так это от развалившейся базы mnesia – к сожалению, случающееся с не нулевой вероятностью. К подобному плачевному результату приводят не глобальные сбои (например, полный выход из строя целого ЦОДа – нагрузка просто переключится на другой кластер), а сбои более локальные – в рамках одного сегмента сети.
Причем страшны именно локальные сетевые сбои, т.к. аварийное выключение одной или двух нод не приведёт к летальным последствиям – просто все запросы будут идти на одну ноду, а как мы помним, производительность зависит от производительности только самой ноды. Сетевые же сбои (не берём в расчёт мелкие прерывания связи – они переживаются безболезненно), приводят к ситуации, когда ноды начинают процесс синхронизации между собой и тут сваливается опять разрыв связи и опять на несколько секунд.
Например, многократное моргание сети, причем с периодичностью больше 5 секунд (именно такой таймаут выставлен в настройках Хапов, можно им конечно поиграться, но для проверки эффективности потребуется повторение сбоя, чего никому не хочется).
Одну – две такие итерации кластер ещё выдержать может, но больше – уже шансы минимальны. В такой ситуации может спасти остановка выпавшей ноды, но успеть это сделать вручную практически невозможно. Чаще результатом является не просто выпадение ноды из кластера с сообщением «Network Partition», но и картина, когда данные по части очередей жили как раз этой ноде и не успели синхронизироваться на оставшиеся. Визуально – в данных по очередям стоит NaN.
И вот это уже однозначный сигнал – переключиться на резервный Кластер. Переключение обеспечит хап, требуется только остановить кроликов на основном кластере – дело нескольких минут. В результате получаем восстановление работоспособности транспорта и можем спокойно приступить к анализу аварии и её устранению.
Для того, чтобы вывести из-под нагрузки повреждённый кластер, с целью не допустить дальнейшей деградации, самое простое: заставить кролика работать на портах отличных от 5672. Поскольку Хапы у нас следят за кроликами именно по штатному порту, смещение его, например, на 5673 в настройках кролика позволит полностью безболезненно запускать кластер и попытаться восстановить его работоспособность и сообщения, оставшиеся на нём.
Делаем в несколько шагов:
- Останавливаем все ноды сбойного кластера – хап переключит нагрузку на резервный Кластер
- Добавляем RABBITMQ_NODE_PORT=5673 в файл rabbitmq-env – при запуске кролика настройки эти настройки подтянутся, при этом Web интерфейс по-прежнему будет работать на 15672.
- Указываем новый порт на всех нодах безвременно почившего кластера и запускаем их.
При запуске произойдёт перестройка индексов и в подавляющем большинстве случаев все данные восстанавливаются в полном объёме. К сожалению, случаются сбои в результате которых приходится физически удалять все сообщения с диска, оставляя только конфигурацию – в папке с базой удаляются директории msg_store_persistent, msg_store_transient, queues (для версии 3.6) или msg_stores (для версии 3.7).
После такой радикальной терапии кластер запускается с сохранением внутренней структуры, но без сообщений.
И самый неприятный вариант (наблюдался один раз): Повреждения базы были таковы, что пришлось полностью удалять всю базу и пересобрать кластер с нуля.
Для удобства управления и обновления кроликов используется не готовая сборка в rpm, а разобранный с помощью cpio и переконфигурированный (изменили пути в скриптах) кролик. Основное отличие: не требует для установки/настройки прав root, не устанавливается в систему (пересобранный кролик отлично запаковывается в tgz) и запускается от любого пользователя. Такой подход позволяет гибко проводить обновление версий (если это не требует полной остановки кластера – в таком случае просто переключаем на резервный кластер и обновляемся, не забывая указать смещённый порт для работы). Возможен даже запуск нескольких экземпляров RabbitMQ на одной машине – для тестов вариант очень удобен – можно развернуть уменьшенную архитектурную копию боевого зоопарка.
В результате шаманства с cpio и путями в скриптах получили вариант сборки: две папки rabbitmq-base (в оригинальной сборке – папка mnesia) и rabbimq-main – сюда поместил все необходимые скрипты и самого кролика и эрланга.
В rabbimq-main/bin – симлинки к скриптам кролика и эрланга и скрипт слежения за кроликом (описание ниже).
В rabbimq-main/init.d – скрипт rabbitmq-server через который происходит старт/стоп/ротирование логов; в lib – сам кролик; в lib64 – erlang (используется урезанная, только для работы кролика, версия эрланга).
Получившуюся сборку крайне просто обновлять при выходе новых версий – добавить содержимое rabbimq-main/lib и rabbimq-main/lib64 из новых версий и заменить симлинки в bin. Если обновление затрагивает и управляющие скрипты – достаточно просто изменить в них пути на наши.
Солидное преимущество такого подхода – полная преемственность версий – все пути, скрипты, команды управления остаются без изменений, что позволяет использовать любые самописные служебные скрипты без допиливания под каждую версию.
Поскольку падения кроликов событие хоть и редкое, но происходящее, требовалось воплотить механизм слежения за их самочувствием — поднятие в случае падения (с сохранением логов причин падения). Падение ноды в 99% случаев сопровождается записью в лог, даже kill и тот оставляет следы, это позволило реализовать с помощью простого скрипта слежение за состоянием кроля.
Для версий 3.6 и 3.7 скрипт немного отличается в силу отличий записей в логах.
#!/usr/bin/python<br>
import subprocess<br>
import os<br>
import datetime<br>
import zipfile<br>
<br>
def LastRow(fileName,MAX_ROW=200):<br>
    with open(fileName,'rb') as f:<br>
        f.seek(-min(os.path.getsize(fileName),MAX_ROW),2)<br>
        return (f.read().splitlines())[-1]<br>
<br>
if os.path.isfile('/data/logs/rabbitmq/startup_log'):<br>
    if b'FAILED' in LastRow('/data/logs/rabbitmq/startup_log'):<br>
        proc = subprocess.Popen("ps x|grep rabbitmq-server|grep -v 'grep'", shell=True, stdout=subprocess.PIPE)<br>
        out = proc.stdout.readlines()<br>
        if str(out) == '[]':<br>
            cur_dt=datetime.datetime.now()<br>
            try:<br>
                os.stat('/data/logs/rabbitmq/after_crush')<br>
            except:<br>
                os.mkdir('/data/logs/rabbitmq/after_crush')<br>
            z=zipfile.ZipFile('/data/logs/rabbitmq/after_crush/repair_log'+'-'+str(cur_dt.day).zfill(2)+str(cur_dt.month).zfill(2)+str(cur_dt.year)+'_'+str(cur_dt.hour).zfill(2)+'-'+str(cur_dt.minute).zfill(2)+'-'+str(cur_dt.second).zfill(2)+'.zip','a')<br>
            z.write('/data/logs/rabbitmq/startup_err','startup_err')<br>
            proc = subprocess.Popen("~/rabbitmq-main/init.d/rabbitmq-server start", shell=True, stdout=subprocess.PIPE)<br>
            out = proc.stdout.readlines()<br>
            z.writestr('res_restart.log',str(out))<br>
            z.close()<br>
            my_file = open("/data/logs/rabbitmq/run.time", "a")<br>
            my_file.write(str(cur_dt)+"\n")<br>
            my_file.close()<br>
if (os.path.isfile('/data/logs/rabbitmq/startup_log')) and (os.path.isfile('/data/logs/rabbitmq/startup_err')):<br>
    if ((b' OK ' in LastRow('/data/logs/rabbitmq/startup_log')) or (b'FAILED' in LastRow('/data/logs/rabbitmq/startup_log'))) and not (b'Gracefully halting Erlang VM' in LastRow('/data/logs/rabbitmq/startup_err')):<br>
Заводим в crontab учётной записи под которой будет работать кролик (по умолчанию rabbitmq) выполнение этого скрипта (имя скрипта: check_and_run) каждую минуту (для начала просим админа выдать учётке права на использование crontab, ну а если права root есть – делаем сами):
*/1 * * * * ~/rabbitmq-main/bin/check_and_run
Второй момент использования пересобранного кроля — ротирование логов.
Поскольку мы не завязываемся на logrotate системы – используем функционал, предоставленный разработчиком: скрипт rabbitmq-server из init.d (для версии 3.6)
Внеся небольшие изменения в rotate_logs_rabbitmq()
Добавляем:
    find ${RABBITMQ_LOG_BASE}/http_api/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {}<br>
    find ${RABBITMQ_LOG_BASE}/*.log.*.back -maxdepth 0 -type f | xargs -i gzip {}<br>
    find ${RABBITMQ_LOG_BASE}/*.gz -type f -mtime +30 -delete<br>
    find ${RABBITMQ_LOG_BASE}/http_api/*.gz -type f -mtime +30 -delete<br>
Результат запуска скрипта rabbitmq-server с ключом rotate-logs: логи сжимаются gzip-ом, и хранятся только за последние 30 дней. http_api – путь куда кролик складывает логи http – настраивается в файле конфигурации: {rabbitmq_management, [{rates_mode, detailed},{http_log_dir, path_to_logs/http_api"}]}
Заодно обращаю внимание на {rates_mode, detailed} – опция несколько увеличивает нагрузку, зато позволяет увидеть на WEB интерфейсе (и соответственно получить через API) информацию о том, кто публикует сообщения в эксченджи. Информация крайне нужная, т.к. все подключения идут через балансировщик – мы увидим только IP самих балансировщиков. А если озадачить все Подсистемы, работающие с кроликом, чтобы они заполняли параметры «Client properties» в свойствах своих подключений к кроликам, то можно будет на уровне коннектов детально получать информацию кто именно, куда и с какой интенсивностью публикует сообщения.
С выходом новых версий 3.7 произошёл полный отказ от скрипта rabbimq-server в init.d. С целью облегчения эксплуатации (однообразие команд управления независимо от версии кролика) и более плавного перехода между версиями, в пересобранном кролике мы продолжаем использование данного скрипта. Правда опять: немного изменим rotate_logs_rabbitmq(), поскольку в 3.7 поменялся механизм именования логов после ротирования:
    mv ${RABBITMQ_LOG_BASE}/$NODENAME.log.0 ${RABBITMQ_LOG_BASE}/$NODENAME.log.$(date +%Y%m%d-%H%M%S).back<br>
    mv ${RABBITMQ_LOG_BASE}/$(echo $NODENAME)_upgrade.log.0 ${RABBITMQ_LOG_BASE}/$(echo $NODENAME)_upgrade.log.$(date +%Y%m%d-%H%M%S).back<br>
    find ${RABBITMQ_LOG_BASE}/http_api/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {}<br>
    find ${RABBITMQ_LOG_BASE}/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {}<br>
    find ${RABBITMQ_LOG_BASE}/*.gz -type f -mtime +30 -delete<br>
    find ${RABBITMQ_LOG_BASE}/http_api/*.gz -type f -mtime +30 -delete<br>
Теперь осталось только внести в crontab задание по ротированию логов – например каждый день в 23-00:
00 23 * * * ~/rabbitmq-main/init.d/rabbitmq-server rotate-logs
Перейдём к задачам, которые требуется решать в рамках эксплуатации «кроличьей фермы»:
- Манипуляции с сущностями кроликов — создание/удаление сущностей кролика: эксченджей, очередей, биндов, шовелов, пользователей, политик. Причем делать это абсолютно идентично на всех Кластерах Контура.
- После переключения на / с резервного Кластера требуется перенести сообщения, которые на нём остались на текущий Кластер.
- Создание резервных копий конфигураций всех Кластеров всех Контуров
- Полная синхронизация конфигураций Кластеров в рамках Контура
- Производить остановку/запуск кроликов
- Производить анализ текущих потоков данных: все ли сообщения ходят и если ходят, то куда надо или…
- Найти и отловить проходящие сообщения по каким-либо критериям
Эксплуатация нашего зоопарка и решение озвученных задач средствами поставляемого штатного rabbitmq_management плагина возможна, но крайне неудобна, именно поэтому была разработана и реализована оболочка для управления всем многообразием кроликов.






 Операторы связи «Вымпелком», «Мегафон» и Tele2 заявили о повышении стоимости услуг в начале 2019 года, о чем сообщают «Ведомости». Так, «Вымпелком» разослал абонентам сообщения, в которых говорится о повышении тарифов и стоимости подключенных услуг уже с 1 января. Цена будет увеличена на коэффициент 1,016949.
Операторы связи «Вымпелком», «Мегафон» и Tele2 заявили о повышении стоимости услуг в начале 2019 года, о чем сообщают «Ведомости». Так, «Вымпелком» разослал абонентам сообщения, в которых говорится о повышении тарифов и стоимости подключенных услуг уже с 1 января. Цена будет увеличена на коэффициент 1,016949.






{kind=link}