Забавно наблюдать за тем, как компьютерные технологии, которые, в момент их появления, кажутся необычными, в итоге либо уходят в небытие, либо становятся привычными и распространёнными. Например, в своё время, если на компьютере имелось больше одного пользователя, это иначе как «хай-теком» и назвать было нельзя. Были ещё и разработки, которые не завоевали широкой популярности, вроде векторных дисплеев, или памяти, адресуемой содержимым. А вот использование в компьютерах накопителей данных, особенно — жёстких дисков — стало весьма распространённой практикой. Но было время, когда накопители данных были экзотическими устройствами, пользоваться которыми было далеко не так просто, как в наши дни.

Меня, если говорить о накопителях данных, удивляет то, что понятие «файловая система», в том виде, в котором мы его знаем, за годы его существования изменилось не слишком сильно. Конечно, если сравнить то, что есть сейчас, с тем, что было, скажем, в 1960-е годы, то можно сказать, что в наши дни файловые системы дают нам гораздо более широкий функционал, чем прежде. В наши дни всё гораздо лучше в плане скорости, способов кодирования, шифрования, сжатия данных и так далее. Однако фундаментальная природа того, как мы храним файлы, и того, как с ними работаем в компьютерных программах, практически не изменилась. А всё должно быть не так. Нам известны более эффективные способы организации данных, но по каким-то причинам большинство из нас не пользуется этими возможностями в своих программах. Оказывается, правда, что пользоваться ими достаточно просто, и я собираюсь это продемонстрировать на экспериментальном приложении, которое вполне может стать отправной точкой разработки базы данных электронных компонентов для моей лаборатории.
Основой для базы данных, подобной той, о которой я хочу рассказать, может быть файл, где в роли разделителя данных применяются запятые (CSV-файл). Тут можно воспользоваться и чем-то вроде формата JSON. Но я собираюсь задействовать полномасштабную базу данных SQLite для того чтобы избежать необходимости в «тяжёлом» сервере баз данных и сложностей, сопряжённых с его поддержкой. Можно ли, используя мой подход, сделать что-то, что способно заменить базу данных, на которой основана какая-нибудь система резервирования авиабилетов? Нет. А подойдёт ли он для решения большинства задач, которые всем нам так или иначе приходится решать? Готов поспорить, что подойдёт.
Абстракция
Если подумать о файловых системах, то окажется, что это — не более чем абстракция над физическим устройством для хранения данных. Обычно мы не знаем или попросту не беспокоимся о том, где именно хранится нечто вроде файла
hello.c. Нас даже не интересует то, сжат ли этот файл, то, зашифрован ли он. Он, возможно, был загружен по сети, а, может, его части хаотично разбросаны по всему жёсткому диску. Обычно нас это не волнует. А что если абстрагировать саму файловую систему?
Это, в общем-то, идея, лежащая в основе баз данных. Если имеется, например, список электронных компонентов, я могу сохранить его в CSV-файле и прочитать этот файл с помощью программы для работы с электронными таблицами. Или могу использовать полноценную базу данных. Проблема баз данных заключается в том, что для работы с ними обычно требуется некое серверное ПО, вроде MySQL, SQL Server или Oracle. Можно абстрагировать интерфейс базы данных, но это — весьма тяжеловесное решение, если сравнить его с простой операцией открытия файла и с обычной работой с этим файлом.
Правда, существует, например, популярная библиотека, называемая SQLite, которая даёт весьма надёжный механизм работы с базой данных, размещённой в единственном файле. При этом для работы с такой базой данных не нужен специальный сервер, её не нужно как-то по-особенному поддерживать. В работе с подобной БД, конечно, есть и ограничения. Правда, при её применении во многих простых программах можно пользоваться полезными возможностями баз данных, но при этом не тратить системные и финансовые ресурсы на поддержку инфраструктуры, обеспечивающей работу обычной СУБД.
Правильный инструмент для правильной работы
У SQLite, конечно, есть ограничения. Но если, например, некто занимается созданием собственного файлового формата для хранения неких данных, ему, возможно, стоит рассмотреть возможность перехода на SQLite и обработки этих данных средствами СУБД. В соответствии с данными, приведёнными на
сайте SQLite, такой ход вполне может привести к экономии дискового пространства и к увеличению скорости доступа к данным. И ещё — после того, как программист освоится с этой технологией, окажется, что она упрощает работу с данными. И небольшое приложение, основанное на SQLite, если решено будет перевести его на что-то более серьёзное, лучше поддастся такому переходу.
Если вам надо хранить огромные объёмы информации, скажем — терабайты, или если надо, чтобы с данными одновременно могло бы работать много пользователей, особенно — если всем им надо писать данные в базу, то вам, возможно, это не подойдёт. На сайте SQLite имеется хорошая страница, на которой говорится об удачных и неудачных вариантах использования этой системы.
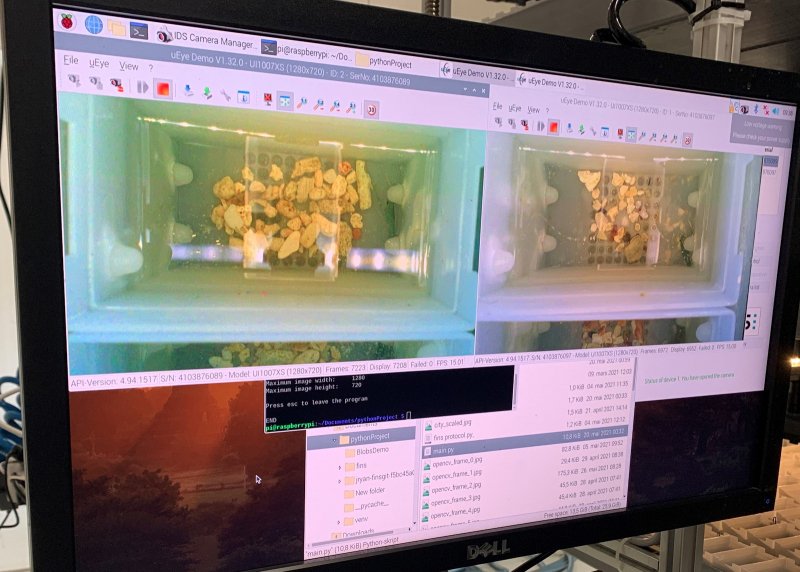
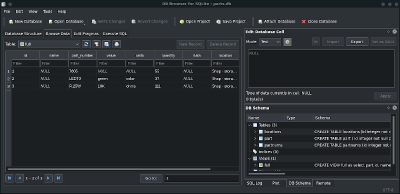
На стороне пользователей SQLite — возможность применения инструментов командной строки или их вариантов с графическим интерфейсом, вроде того, браузерного, который показан на следующем рисунке. Все эти инструменты позволяют работать с SQLite-базами данных без необходимости писать какой-то код.
В результате, например, можно решать задачи, вроде ввода данных в БД или исследования этих данных, и при этом совершенно не нуждаться в написании SQL-кода. Если же говорить о применении для похожих задач некоего собственного файлового формата, то, вероятно, решать эти задачи придётся вручную, или надо будет работать с данными, используя универсальные инструменты, которым ничего не известно об особенностях обрабатываемых с их помощью данных.
О моей задаче
Мне не хотелось бы тут рассказывать обо всём, что связано с разработкой приложения, я не собираюсь делать из этой статьи учебный курс по SQL — языку структурированных запросов, используемому в большинстве СУБД, включая SQLite. Мне, вместо всего этого, хочется показать то, как легко приступить к работе над простым приложением, применяющим возможности базы данных для хранения сведений об электронных компонентах, используя язык C. При этом написание кода на C будет представлять собой самую простую из наших задач. У нас есть две основных задачи, с которыми разобраться уже гораздо сложнее. Это — задача структурирования базы данных, то есть — проектирование схемы БД, и задача первоначального ввода данных в систему. Даже если БД планируется заполнять данными в процессе работы с программой, неплохо будет, если в самом начале в ней уже что-то будет, чтобы соответствующая программа с самого начала была бы работоспособной.
Основы работы с базами данных
В современных реляционных базах данных обычно имеется как минимум одна таблица. Их может быть и несколько. В каждой таблице имеются строки, в которых хранятся данные. Строки состоят из столбцов, которым назначены типы данных. Например, в таблице может присутствовать текстовый столбец, предназначенный для серийного номера электронного компонента. Ещё один столбец, предназначенный для хранения вещественных чисел, содержит сведения о напряжении в испытательной точке. А ещё один, хранящий данные логического типа, содержит значение, указывающее на то, пройдено испытание или нет.
Строки каждой таблицы имеют уникальные идентификаторы (ID). Если программист не предусмотрел механизм формирования этого ID, СУБД обычно может сама его сформировать. В частности, речь идёт об автоматическом инкрементировании подобных идентификаторов и об обеспечении того, что каждой строке таблицы будет назначен уникальный идентификатор.
Если бы возможности СУБД ограничивались тем, о чём я только что рассказал, то у них не было бы особых преимуществ перед обычными CSV-файлами. Но после того, как данные организованы вышеописанным образом, многие задачи можно решать лучше, чем при отсутствии такой структуры. Например, легко попросить систему выполнить сортировку элементов, или, например, выбрать из таблицы строки, содержащие три самых больших значения напряжения.
Надо отметить, что одной из главных сильных сторон баз данных является возможность создавать соединения данных. Предположим, у меня есть список компонентов (Components): печатная плата (PCB), резистор (Resistor), держатель аккумуляторной батареи (Battery Holder) и светодиод (LED). Имеется таблица, в которой для каждого из этих компонентов предусмотрена отдельная строка. Теперь представим, что у меня есть таблица с описанием сборных изделий (Assembly), сделанных из этих компонентов. Тут можно применить простой подход:
Таблица Component
ID Name
===========
1 PCB
2 Resistor
3 LED
4 Battery Holder
Таблица Assembly
ID Name Components
============================
1 Blink1 PCB, Resistor, LED, Battery Holder
2 Blink2 PCB, Resistor, LED, Resistor, LED, Battery Holder
Выглядит это некрасиво, такому подходу свойственно нерациональное использование системных ресурсов. Куда лучше будет использовать три таблицы:
Таблица Component
ID Name
===========
1 PCB
2 Resistor
3 LED
4 Battery Holder
Таблица Assembly
ID Name
=========
1 Blink1
2 Blink2
Таблица Assembly_Parts
ID Component Quan
=======================
1 1 1
1 2 1
1 3 1
1 4 1
2 1 1
2 2 2
2 3 2
2 4 1
Используя операцию соединения данных можно скомпоновать эти таблицы и создать новую таблицу, хранящую сведения о том, сколько и каких компонентов нужно для некоего сборного изделия, не дублируя при этом слишком большого количества данных.
В результате я, в своей базе данных, планирую создать три таблицы. В таблице parts будет храниться список имеющихся у меня компонентов. В таблице partnums — сведения о типах компонентов (например — 7805, 2N2222 или CDP1802). И наконец — в таблице locations будут сведения о том, где именно хранится тот или иной компонент. Мои данные можно структурировать и по-другому. Скажем, может иметься таблица, в которой хранятся сведения о способах монтажа компонента. Например, компоненту 2N2222 может быть назначено значение TO92, или может быть указано, что он предназначен для поверхностного монтажа. Кроме того, я собираюсь создать механизм для просмотра данных, представление (view), в котором все данные будут показаны в развёрнутом виде — как в первом примере. Представление — это нечто такое, что в базе данных не хранится, но, для удобства, выглядит как таблица. А на самом деле это — всего лишь результат выполнения запроса к базе данных, с которым можно что-то делать.
Конечно, работа с БД этим не ограничивается. Существуют, например, внутренние и внешние соединения, имеется множество других деталей и нюансов работы с данными. Но, к нашему счастью, есть много хороших материалов о базах данных. Например — документация по SQLite.
Ровно столько SQL, сколько нужно для дела
Нам, для решения наших задач, понадобится сравнительно немного SQL-инструкций:
create,
insert и
select. Имеется программа,
sqlite3, которая позволяет выполнять команды в применении к базе данных. Этой программе, средствами командной строки, можно передать имя базы данных, а потом можно работать с этой базой данных, что совсем несложно. Для выхода из программы используется команда
.exit.
Вот команды создания таблиц базы данных. Полагаю, устроены они достаточно просто и понятно.
create table part ( id integer not null primary key, name text, partnum integer, value text,
units text, quantity integer, photo blob, data text, location integer, footprint text);
create table partnums (id integer not null primary key, partnum text, desc text);
create table locations (id integer not null primary key, location text, desc text);
create view full as select part.id, name, partnums.partnum as part_number, value, units,
quantity, data, locations.location as location, footprint from part
inner join partnums on part.partnum = partnums.id inner join locations on locations.id=part.location
Я выполнил эти команды с помощью
sqlite3, в командной строке, но их можно было бы выполнить и из программы с графическим интерфейсом. А если бы мне это было нужно, я мог бы сделать так, чтобы они были бы выполнены из моей C-программы. Средства командной строки я использовал и для того, чтобы добавить в базу данных несколько тестовых записей. Например:
insert into locations (location,desc) values ("Shop - storage II","Storage over computer desk in shop");
insert into partnums(partnum,desc) values("R.25W","Quarter Watt Resistor");
insert into part(partnum,quantity,location,value,units) values (2,111,1,"10K","ohms");
Для получения данных из базы используется команда
select:
select * from part;
select partnum, quantity from part where quantity<5;
Если вы хотите глубже разобраться в этих и других командах — существует множество
учебных руководств по SQL.
Программирование!
До сих пор мы, готовя основу программы, не нуждались, собственно, в программировании. При этом, исходя из предположения о том, что в нашем распоряжении имеется пакет наподобие
libsqlite3-dev, для того чтобы оснастить C-программу функциями, направленными на работу с базой данных, нам не придётся прилагать особенно больших усилий. В частности, в коде нужно будет подключить
sqlite3.h. Если такого заголовочного файла найти не удаётся — это может означать то, что в системе не установлено то, что нужно для SQLite-разработки. Ещё понадобится связь с
libsqlite3. Если говорить о простом однофайловом проекте, то, чтобы приступить к работе над ним, скорее всего, достаточно будет такого
makefile:
CC=gcc
CFLAGS+=-std=c99 -g
LDFLAGS=-g
LDLIBS+=-lsqlite3
edatabase : main
main : main.c
Сам код очень прост. Сначала нужно открыть файл базы данных (с использованием функции
sqlite3_open). Вместо имени файла можно передать функции
:memory. Тогда в нашем распоряжении окажется база данных, расположенная в памяти, которая будет существовать столько же времени, сколько будет работать программа. Этот вызов возвращает дескриптор базы данных. Далее — нужно подготовить SQL-запрос, который планируется выполнить. Это может быть запрос, подобный тем, которые мы уже выполняли, или — любой другой запрос. В моём случае мне нужно взять все данные из представления
full и вывести их. Поэтому я собираюсь выполнить такой запрос:
select * from full;
И наконец — мы пользуемся функцией
sqlite3_step. До тех пор, пока она возвращает
SQLITE_ROW, мы можем обрабатывать строки, пользуясь функциями вроде
sqlite3_column_text. В конце выполняется финализация и закрытие базы данных. Вот готовый код, из которого удалены механизмы обработки ошибок:
#include <sqlite3.h>
#include <stdio.h>
int main(int argc, char *argv[])
{
sqlite3 *db;
sqlite3_stmt *sql;
int rv;
rv=sqlite3_open("parts.db",&db);
rv=sqlite3_prepare_v2(db, "SELECT * from full", -1, &sql, NULL);
do
{
rv=sqlite3_step(sql);
if (rv==SQLITE_ROW)
{
printf("%s,",sqlite3_column_text(sql,0));
printf("%s\n",sqlite3_column_text(sql,2));
}
} while (rv==SQLITE_ROW);
sqlite3_finalize(sql);
sqlite3_close(db);
return 0;
}
Если хотите —
вот полный код. А в ситуации, когда перебор строк нас не интересует, можно воспользоваться функцией
sqlite3_exec. Даже в документации говорится, что это — лишь обёртка вокруг функций
prepare,
step и
finalize. Поэтому данной функции можно просто передать соответствующие входные данные и всё должно заработать.
Конечно, существует и множество других функций. Например, можно воспользоваться функцией sqlite_column_int, или, для получения других типов, можно применить другие вызовы. Можно прикреплять к SQL-вызовам параметры для установки значений, а не пользоваться строками. Здесь я лишь продемонстрировал то, насколько простым делом может быть создание программы, в которой используется SQLite.
Итоги
Когда вы в следующий раз поймёте, что занимаетесь выдумыванием нового файлового формата — поразмыслите о том, чтобы, вместо этого, воспользоваться SQLite. К вашим услугам будут бесплатные инструменты, а после того, как вы освоите SQL, вы поймёте, что можете сделать очень многое, не написав никакого программного кода, кроме, разве что, кода различных SQL-команд. Можно даже использовать
систему для хранения разных версий базы данных, подобную той, что применяется в Git. И, кстати, некоторые используют в роли базы данных
Git, но мы этого делать не рекомендуем.
Пользуетесь ли вы СУБД в своих программах?

Adblock test (Why?)








 Вместо логического оператора "&&" в коде функции VaultKeyset стоял "&", что приводило к некорректной работе алгоритма входа пользователя в систему.
Вместо логического оператора "&&" в коде функции VaultKeyset стоял "&", что приводило к некорректной работе алгоритма входа пользователя в систему.















")

























{kind=link}
{kind=link}