
Каково будущее математики?
- В 1990-х компьютеры стали играть в шахматы лучше людей.
- В 2018 компьютеры стали играть в го лучше людей.
- В 2019 исследователь искусственного интеллекта Christian Szegedy сказал мне, что через 10 лет компьютеры будут доказывать теоремы лучше, чем люди.
Конечно, он может быть не прав. А может быть и прав.
Я верю в следующее: через десять лет компьютеры будут помогать нам доказывать муторные теоремы уровня ранних аспирантов. В каких областях математики? Зависит от того, кого получится привлечь в эту область исследования.
Типичный шаблон работы искусственного интеллекта таков: сначала он очень глупый, а потом он неожиданно умнеет. Естественный вопрос: когда происходит фазовый переход и искусственный интеллект неожиданно становится очень умным? Ответ: этого никто не знает. Ясно лишь то, что чем больше людей будет вовлечено в эту область исследования, тем скорее это произойдет.
Что такое доказательство?
Если спросить студента-отличника, математика-исследователя и компьютер о том, что такое доказательство, каков будет их ответ? Ответы студента-отличника и компьютера совпадут и будут следующим:
Доказательство — это логическая последовательность утверждений, состоящая из аксиом выбранной системы, правил вывода и теорем, которые были доказаны ранее, которые, в конечном итоге, приводят к доказываевому утверждению.Конечно, ответ математика-исследователя не будет таким идеалистичным. Для математика определением доказательства будет то, что другие опытные математики считают доказательством. Или то, что принято к публикации в журналы the Annals of Mathematics или Inventiones.
Однако с этим есть небольшая проблема. Следующие скриншоты взяты с сайта журнала the Annals of Mathematics, одного из самых престижных математических журналов в мире.

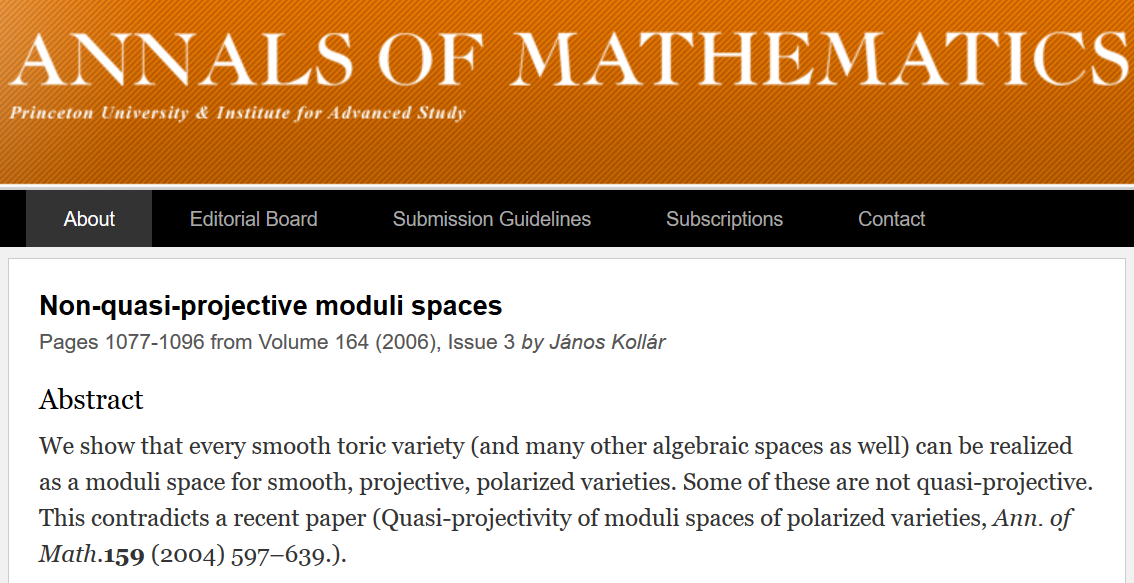
Вторая статья буквально противоречит первой. Авторы открыто пишут об этом в аннотации. Насколько я знаю, the Annals of Mathematics никогда не публиковала опровержений ни одной из этих работ. Какую из работ считают правильной опытные математики? Об этом можно узнать, только если вы работаете в этой области.
Вывод: в современной математике мнение по поводу того, является ли что-то доказательством, меняется с течением времени (например, может пройти путь от “является” до “не является”).
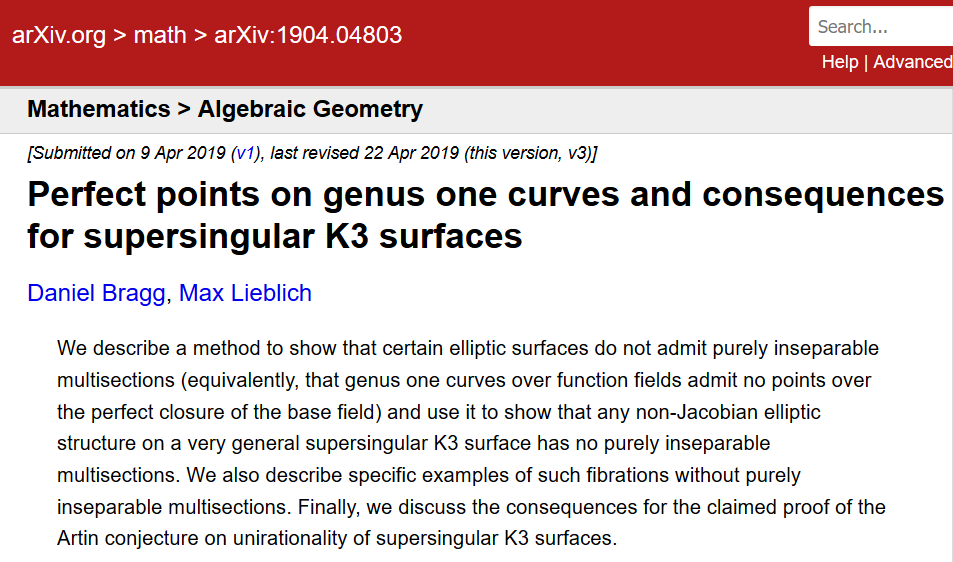
Эта короткая статья 2019 года указывает на то, что другая важная статья 2015 года, опубликованная в Inventiones, в значительной степени опирается на ложную лемму. Этого никто не замечал до 2019 года несмотря на то, что в 2016 году люди устраивали семинары по изучению этой важной работы.
Владимир Воеводский, лауреат Филдсовской премии, внесший вклад в основания математики, пишет, что “если автор, которому люди доверяют, пишет технически сложный аргумент, который трудно проверить, но который похож на другие, правильные, аргументы, то этот аргумент едва ли когда-нибудь будет проверен в деталях вообще.”
Журнал Inventiones так и не опубликовал опровержение работы 2015 года.
Вывод: важная математика, которая была опубликована, иногда оказывается неверной. Более того, в будущем мы наверняка увидим ещё больше опровержений опубликованных доказательств.
Может быть моя работа в области p-адической программы Ленглендса опирается на неверные результаты. Или, более оптимистично, на верные результаты, но у которых нет полного доказательства.
Если наши исследования невоспроизводимы, можем ли мы это называть наукой? Я уверен на 99.9%, что p-адическая программа Ленглендса никогда не будет использована человечеством для того, чтобы сделать что-нибудь полезное. Если моя работа в математике не является полезной и не гарантирована быть верной на 100 процентов, это просто трата времени. Поэтому я решил прекратить исследования и сконцентрироваться на проверке “известной” математики на компьютере.
В 2019 году Balakrishnan, Dogra, Mueller, Tuitman и Vonk нашли все рациональные решения определенного уравнения четвертой степени в двух переменных. В явном виде:
Это вычисление имеет важное приложение в арифметике. Доказательство существенным образом опирается на вычисление в magma (система с закрытым исходным кодом), использующая быстрые нереферируемые алгоритмы. С большим трудом можно было бы перенести все вычисления на систему с открытым исходным кодом, например, sage. Однако никто не планирует этого делать.
Таким образом, часть доказательства остаётся скрытой. И возможно навсегда останется скрытой. Является ли этой наукой?
Пробелы в математике
- В 1993 году Эндрю Уайлс объявил о доказательстве Великой теоремы Ферма. В доказательстве был пробел.
- В 1994 году Уайлс и Ричард Тейлор устранили пробел, работа была опубликована и принята в математическом сообществе.
- В 1995 году я указал Тейлору, что их доказательство использует работу Гросса, которая была не завершена. В работе Гросса было предположение, что линейные операторы Гекке, определенные на канонически изоморфных группах когомологий, коммутируют с каноническим изоморфизмом. Тейлор ответил мне, что с этим нет проблем, потому что он знает другой аргумент, который не опирается на работу Гросса.
Что должен делать рецензент, которому пришла на проверку математическая статья? Утверждается, что работа рецензента — это “убедиться в том, что методы, используемые в статье, достаточно сильны для доказательства главного результата работы.”
А что если методы сильны, а авторы — нет? Так возникают ситуации, когда наши доказательства не полны. Так возникают споры о том, доказаны ли наши теоремы на самом деле. Это совсем не то, как мы рассказываем о математике нашим студентам.
Конечно, эксперты знают, какой литературе можно доверять, а какой — нет. Но должен ли я принадлежать к экспертам, чтобы узнать какой литературе я могу доверять?
Большие пробелы в математики
Экспонат A
Классификация простых конечных групп. Эксперты утверждают, что у нас есть законченная классификация простых конечных групп. Я верю экспертам.
- В 1983 году было объявлено о доказательстве классификации экспертами.
- В 1994 году эксперты нашли ошибку (но давайте не будем раздувать из мухи слона?)
- В 2004 году была опубликована 1000+ страничная работа. Эксперт в области Aschbacher утверждает, что ошибка была исправлена и объявляет план о публикации 12 томов полного доказательства.
- В 2005 году только 6 из 12 томов было опубликовано
- В 2010 году только 6 из 12 томов было опубликовано
- В 2017 году только 6 из 12 томов было опубликовано
- В 2018 году были опубликованы 7-й и 8-й тома и заметка о том, что публикация будет доделана к 2023 году.
Из трёх людей, руководящих проектом, один умер. Двум другим уже за семьдесят.
Экспонат B
Потенциальная модулярность абелевых поверхностей. Год назад мой выдающийся аспирант Toby Gee с тремя соавторами опубликовали 285-страничный препринт с результатом о том, что абелевы поверхности над тотально действительными полями являются потенциально модулярными.
Их доказательство цитирует три неопубликованных препринта (один 2018 года, один 2015 года, один 1990-х годов), записки 2007 года из интернета, неопубликованную диссертацию на немецком и работу, чьё главное утверждение было позднее опровергнуто. Более того, на 13 странице мы видим следующий текст:
Мы хотим обратить внимание на то, что мы используем Arthur’s multiplicity formula для дискретного спектра GSp4, которая была объявлена в [Art04]. Доказательство, опирающееся на другие работы автора о симплектической и ортогональной группах, было дано в [GT18], но их доказательство имеет те же предположения, что и результаты в работе [Art13] и [MW16a, MW16b]. В частности, оно зависит от случаев twisted weighted fundamental lemma, которая была объявлена в [CL10], но доказательство которых ещё не было найдено. Более того, мы опираемся на ссылки [A24], [A25], [A26] и [A27] из работы [Art13], который на момент написания статьи ещё не опубликованы.Может ли мы честно утверждать, что это — наука?
Ссылка [CL10] выглядит следующим образом:

Работа, которая нужна моему аспиранту и соавторам так и не опубликована. Скорее всего, утверждение верно. Возможно даже доказуемо.
А это упомянутые ссылки из работы [Art13]:

В прошлом году я спросил Arthur про эти ссылки, и он ответил мне, что ни одна из работ еще не готова. Конечно, Jim Arthur гений. Он выиграл множество престижных наград. Но ему также 75 лет.
Экспонат C
Gaitsgory–Rozenblyum. В последнее время бесконечные категории обрели популярность. Со временем они станут ещё более важными. Работа Филдсовского лауреата Петера Шольце опирается на бесконечные категории.
Джейкоб Лурье написал 1000+ страничную работу об -категориях и включил много деталей в свою работу. Gaitsgory–Rozenblyum хотели получить аналогичные результаты про -категории, но в целях экономии времени опустили многие аргументы. “Опущенные доказательства появятся где-нибудь ещё.”
Я спросил Gaitsgory, как много было пропущено. Он ответил, что около 100 страниц. Я спросил Лурье, что он думает на этот счёт. Он ответил, что “математики сильно различаются по тому, насколько комфортно для них опускать детали.”
Не движется ли математика слишком быстро? Если я “эксперт” — должен ли я верить, что абелевы поверхности над тотально действительными полями потенциально модулярны? Откровенно говоря, я сам уже не знаю.
На конференции в университете Карнеги-Меллона, где я был на прошлой неделе, Markus Rabe рассказал мне, что Google работает над программой, которая будет переводить математические препринты с arxiv.org на язык, возможный для компьютерной проверки. А ещё я недавно видел работу, которая опирается на статью моего ученика, но ничего не упоминает про опущенные 100 страниц в [Art13].
Ошибка напоследок

Это очень интересный пример. Оригинальная работа была опубликована в журнале J. Funct. Anal. в 2013 году. В работе присутствует большая ошибка (неравенство в другую сторону). Ошибка была обнаружена S. Gouezel в 2017 году, когда Gouezel формализовал аргумент, используя компьютерную программу для проверки доказательств (Isabelle).
Новый аргумент представлен Gouezel и автором оригинальной работы. Новая работа не нуждается в рецензировании. Компьютер проверил 100 процентов нового аргумента. Методы оказались достаточно сильными, чтобы доказать теорему. И под “доказательством” я имею в виду классическое, “чистое”, определение доказательства — то, которому мы учим наших студентов. Каждая деталь доказательства доступна читателю. Наука воспроизводима. Это — математика, которую мы преподаем нашим студентам. Это и есть математика.
Вот другие примеры того, что, по-моему, является математикой:
- Типичное доказательство уровня студента или магистра
- Типичное доказательство столетней давности важного результата, который был хорошо задокументирован и исследован десятками тысяч математиков
- Формальные доказательства авторства следующих математиков: Gonthier, Asperti, Avigad, Bertot, Cohen, Garillot, Le Roux, Mahboubi, O’Connor, Ould Biha, Pasca, Rideau, Solovyev, Tassi и доказательство Théry теоремы Feit–Thompson
- Формальное доказательство авторства следующих математиков: Hales, Adams, Bauer, Dat Tat Dang, Harrison, Truong Le Hoang, Kaliszyk, Magron, McLaughlin, Thang Tat Nguyen, Truong Quang Nguyen, Nipkow, Obua, Pleso, Rute, Solovyev, An Hoai Thi Ta, Trung Nam Tran, Diep Thi Trieu, Urban, Ky Khac Vu и доказательство Zumkeller гипотезы Кеплера.
На этом текст презентации заканчивается, потому что Кевин переходит к своей главной части: формальная верификация математических доказательств в системе Lean, разработанной Leo de Moura в Microsoft Research. К сожалению, примеры не вошли в слайды.
Автор — огромный энтузиаст формальной верификации математических доказательств и ведёт очень интересный блог Xena на эту тему, который я очень рекомендую.


 Лекции читают ученые из международной организации «Академия навигации и управления движением». Практику студенты проходят в АО «Концерн «ЦНИИ Электроприбор». Компания закрепляет за каждым магистром своего ментора, который помогает им с рабочими задачами — они связаны с разработкой навигационной аппаратуры и обработкой данных.
Лекции читают ученые из международной организации «Академия навигации и управления движением». Практику студенты проходят в АО «Концерн «ЦНИИ Электроприбор». Компания закрепляет за каждым магистром своего ментора, который помогает им с рабочими задачами — они связаны с разработкой навигационной аппаратуры и обработкой данных.


















 Астронавты Боб Бенкен (Bob Behnken) и Дуг Херли (Doug Hurley) на борту МКС.
Астронавты Боб Бенкен (Bob Behnken) и Дуг Херли (Doug Hurley) на борту МКС.

