[unable to retrieve full-text content]
суббота, 28 ноября 2020 г.
Почему дилетанты ведут себя увереннее, чем профи, и что с этим делать
Как проверить себя на эффект Даннинга-Крюгера, и преодолеть его?
Профессионал не готов к публичности
Сергей (имя изменено) позвонил мне поздно вечером и, запинаясь, сбивчиво стал объяснять, почему завтра утром он не сможет сняться в сюжете для телевидения. Ему крайне неудобно и передо мной, и перед телевизионщиками, но он не готов к съемкам, и вообще, не готов к публичности.
Мы несколько месяцев работали над созданием его личного бренда. Создали концепцию и стратегию продвижения Сергея. Подготовили и провели серию успешных переговоров с собственниками и руководством с предложениями по оптимизации работы его направления. Изменили его имидж, убрали из него неформальные нотки, мешавшие образу эксперта. Тренировали навыки публичного выступления. Сергей открыл блог, писал туда регулярно, участвовал в различных тематических чатах и группах.
И вот теперь венец нашей работы – интервью для федеральной новостной программы. Мне стоило больших трудов уговорить знакомого редактора взять интервью именно у Сергея, который работал руководителем департамента в крупной финансовой структуре. И программа как раз делала сюжет о новых финансовых трендах в связи с пандемией.
Почему Сергей хотел отказаться?
Я предложил прямо сейчас, ночью, провести сессию по скайпу и разобраться в его ограничивающих убеждениях. По окончанию сессии мы решили, что утро вечера мудренее. В 8 утра Сергей был должен принять окончательное решение и сообщить мне…
Работая с запросами людей на создание личного бренда можно выявить следующую закономерность. Большинство претендентов на личный брендинг – дилетанты, уверовавшие в свою особенность, востребованность и профессионализм. А вот настоящие, серьезные профессионалы как-то не рвутся к собственному брендированию.
Почему так происходит?
Это наглядная иллюстрация эффекта Даннинга-Крюгера. Если кратко: невежда уверен в том, что он – суперпрофи, а высококлассный профессионал считает, что недостаточно хорош, чтобы заявлять о себе, как о суперэксперте. Чем меньше человек разбирается в вопросе, тем меньше объективности в оценке своей компетентности. Но! Чем лучше разбираешься, тем меньше уверенности в себе, как в специалисте.
Создание личного бренда подразумевает публичность и претензию на то, что ты лучший, особенный, значимый для других. А значит, нужна убежденность, что это соответствует действительности. И если дилетант с легкостью бьет себя в грудь, доказывая, что он лучший, то профессионал тщательно взвесит свои достижения, и будет сравнивать себя с признанными мастерами в своей сфере.
Вот и получается, что активно продвигаются, пиарят себя далеко не самые достойные. У целевой аудитории создается ложное представление о компетенциях как бы «крутых» специалистов. И нередко именно по таким выскочкам оценивают уровень качества всего профессионального цеха.
На фоне эффекта Даннинга-Крюгера у профи может проявиться и синдром самозванца. Именно это случилось с Сергеем. Накануне важного для себя события, он пришел к выводу, что его достижения – случайность, счастливое стечение обстоятельств. Он незаслуженно занимает ведущую позицию в компании. И некоторые его коллеги более достойны и компетентны. А значит, дальнейшее его продвижение будет неправильным и нечестным.
Поведение дилетанта
В свое время по просьбе собственника небольшой компании я разбирал ситуацию, когда молодого менеджера по продажам Виталия назначили руководителем. И за месяц из славного, своего парня он превратился в директивного начальника. Решил, что заслужил повышение харизмой, своими выдающимися организаторскими и аналитическими способностями. Начал учить работать более опытных и успешных бывших коллег. На возражения и замечания реагировал истериками. Видел в этом подвох и зависть. В итоге – конфликт и увольнение несостоявшегося руководителя.
Почему так произошло? Его назначение было случайным. Пробным, неким авансом. Эта должность предлагалась более достойным, но те отказывались по разным причинам, о чем Виталию деликатно не сообщили, щадя его самолюбие.
Уверенность – результат либо невежества, либо колоссальной работы над собой. Как писал Бертран Рассел: «Одно из неприятнейших свойств нашего времени заключается в том, что те личности, которые испытывают уверенность, являются глупцами, а те личности, которые обладают каким-либо минимальным пониманием и воображением, постоянно испытывают сомнения и являются нерешительными людьми».
«Молодец среди овец» не готов себя воспринимать в сравнении с молодцом реально. Но считает, что он круче молодца. Успокаивает себя. Неосознанно уходит от ситуаций конкуренции.
Завышенная самооценка – следствие быстрого, легкого или случайного успеха, удачного результата при минимуме усилий.
Переход от дилетанта к профессионалу
Согласно графику метакогнитивного искажения эффекта Даннинга-Крюгера есть «пик» дилетанта/невежества – это зона комфорта. За ним располагается «пропасть» отчаяния, страданий. Из пропасти несколько выходов:
-
назад – «это не мое!»;
-
остаться там и страдать – депрессия и даже суицид;
-
двигаться вперед – «я хочу, я смогу, когда научусь!».
В последнем случае можно выйти на «плато» просветления и, набравшись новых знаний, навыков, компетенций, двинуться к «вершине» профессионализма.
Так вот Виталия судьба вознесла на «пик» дилетанта. Застрявшие на этом «пике» рассуждают так: «Я – крут! Если у меня появилась проблема, то это: случайность, невезение, происки, зависть конкурентов». У дилетантов проблемы с самокритикой. На критику реагируют обидой и защитными установками типа: «Если ты такой умный, почему такой бедный». Стараются найти крайнего, перевести стрелки. Успех других объясняют везением, связями, коррупцией, постелью, умением льстить «кому надо».
Дилетанту свойственна аназогнозия, когда подсознание блокирует информацию о недостатках, проблемах. И легче поверить, что оппоненты неправы или лгут, чем признать, что он дурак, невежда, сравнивая себя не с лучшими, а со случайными/худшими.
Дилетант или профан?
Кстати, есть отличия дилетанта от профана. Профан, как правило, признает свою некомпетентность. А вот дилетант до последнего будет доказывать окружающим, да и себе, что он не профан, а профи.
Дилетант-начальник избавляется и опасается подчиненных, которые умнее, профессиональнее, чем он.
Как проверить свои установки и самоощущение
Какое состояние вам ближе?
Вы достигли успеха, вам радостно, и вы хотите поделиться этим с миром: «Жизнь прекрасна! Давайте радоваться вместе!». Или так: «Я много работаю над собой, повышаю уровень знаний, навыков, стараюсь узнать что-то новое. Меня ждет еще много удивительных и полезных открытий!».
Если у вас и окружения установка: «Я – ОК, Ты – ОК», все нормально. Но если: «Я не ОК , Ты – ОК», то вместо радости будет раздражение, злость, обида на мир, и объяснение чужого успеха случайностью или аморальностью.
Коллективные дилетанты, они же – диванные критики, удобно располагаются на своем «пике» невежества, и скептически обесценивают все, что попадает в их поле зрения. Они не готовы радоваться успеху и достижениям других, это их печалит, раздражает, злит. Поэтому не дразните гусей! Не рассыпайте бисер перед свиньями!
Иногда уместно приуменьшение трансляции своей значимости агрессивно-дремучему большинству дилетантов для экономии собственных сил и сохранения идентичности.
Если вы чувствуете, что застряли на «пике» невежества, то постарайтесь принять эту ситуацию или обратитесь за внешней помощью, чтобы вам помогли это сделать. Да, можем накачать значимость человека, но он все равно останется дилетантом пока. Перед ним встанет выбор остаться здесь (с неминуемым падением в пропасть отчаяния), или ступить на тернистый путь развития. Из точки невежества в точку компетентности, сомневаясь, проверяя. Меняем установки: «Я прав/крут, остальные идиоты, завистники, враги!» – «Я пока неправ/не крут, но я хочу и стану лучше! Остальные – учителя, полезные критики!».
Если же человек уже находится в точке отчаяния и депрессии, то задача становится легче, потому что часть пути уже пройдена. Ищем новые горизонты и – в путь!
Вернемся к Сергею. Состоялось ли его интервью? Накануне мы преодолели фазу реактивного отрицания, неприятия своих достижений, своего уровня компетенции. И утром, несмотря на то, что провел бессонную ночь, он был на удивление бодр и энергичен. Интервью понравилось телевизионщикам. И они хотят обращаться к нему регулярно.
Психолог, коуч Александр Кичаев
[Перевод] Реставрация легендарной 37-летней IBM Model F

Мне захотелось поделиться своим опытом возвращения механической клавиатуре IBM Model F XT 1983 года ее былого шика. Я от и до расскажу вам весь процесс, включая описание шагов, ошибок и дополнительного оборудования, которое мне потребовалось для подключения этого раритета к современному ПК. Данная статья посвящается моему отцу, который познакомил меня с миром компьютеров.
Приобретение
Несколько месяцев назад отец спросил, не интересует ли меня его старый ПК IBM model 5150, на что я без промедлений уверенно ответил «Да!». Первым делом я решил восстановить эту самую механическую клавиатуру. Если рассмотреть ситуацию с сентиментальной позиции преемничества, то получалось, что отец передает инструменты своего дела для продолжения семейной линии компьютерного хобби, от чего я не мог отказаться.

Предыстория Model F
Если вы незнакомы с этой серией клавиатур, то modelfkeyboards.com приводит неплохое общее описание:
В производстве клавиатур IBM Model F использовались не только наилучшие переключатели, но и серьезный объем материалов, которые включали в себя около 2кг стали и других металлов, что предполагало сохранение идеальной работоспособности в течение не одного поколения. Проблема же в том, что больше их в таком виде не выпускают. IBM Model F была снята с производства в 80-х. Если вам удастся найти такую клавиатуру, то она, скорее всего, будет грязной, сломанной и потребует долгих часов кропотливого труда для возвращения работоспособного состояния.
Этот клавиатурный танк весит почти три килограмма, звучит так, и, судя по этому обзору, в 1982 году продавался в розницу за $300-400 (на современные деньги это примерно $800-1000),
На восстановление у меня действительно ушло несколько часов и, к счастью, обошлось без паяльника и замены электрических/механических компонентов, потому что все и так было в прекрасной форме…истинное свидетельство долговечного дизайна! А еще круче то, что данную статью я набираю именно на этой восстановленной клавиатуре Model F.
Переходник с XT на USB
Прежде чем приступить к процессу, я нашел сайт ClickyKeyboards, специализирующийся на реставрации и коллекционировании клавиатур Model M — последователей Model F. На этом сайте есть раздел, посвященный переходникам и конвертерам, которые могут потребоваться для адаптирования старых клавиатур с 5-контактным DIN-разъемом к современным USB-портам. Среди прочих на ClickyKeyboards упоминается компания Hagstrom Electronics, которая продает энкодеры и конвертеры протоколов. Особо не разглядывая другие товары, я поспешил купить KE18-XTAT-PS/2, который «преобразует XT клавиатуру в клавиатуру PS/2». Стоило это устройство $55. Я очень обрадовался, найдя переходник на PS/2, потому что далее мне не представляло трудностей найти конвертер из PS/2 в USB.
После получения KE18-XTAT-PS/2 я с нетерпением запустил старинный отцовский системный блок (да, он работал на Windows 2000!) с входом PS/2 на материнской плате, после чего сразу приступил к проверке всех клавиш и убедился, что они по-прежнему работают. Получив подтверждение работоспособности клавиатуры, я был готов переходить к ее реставрации.
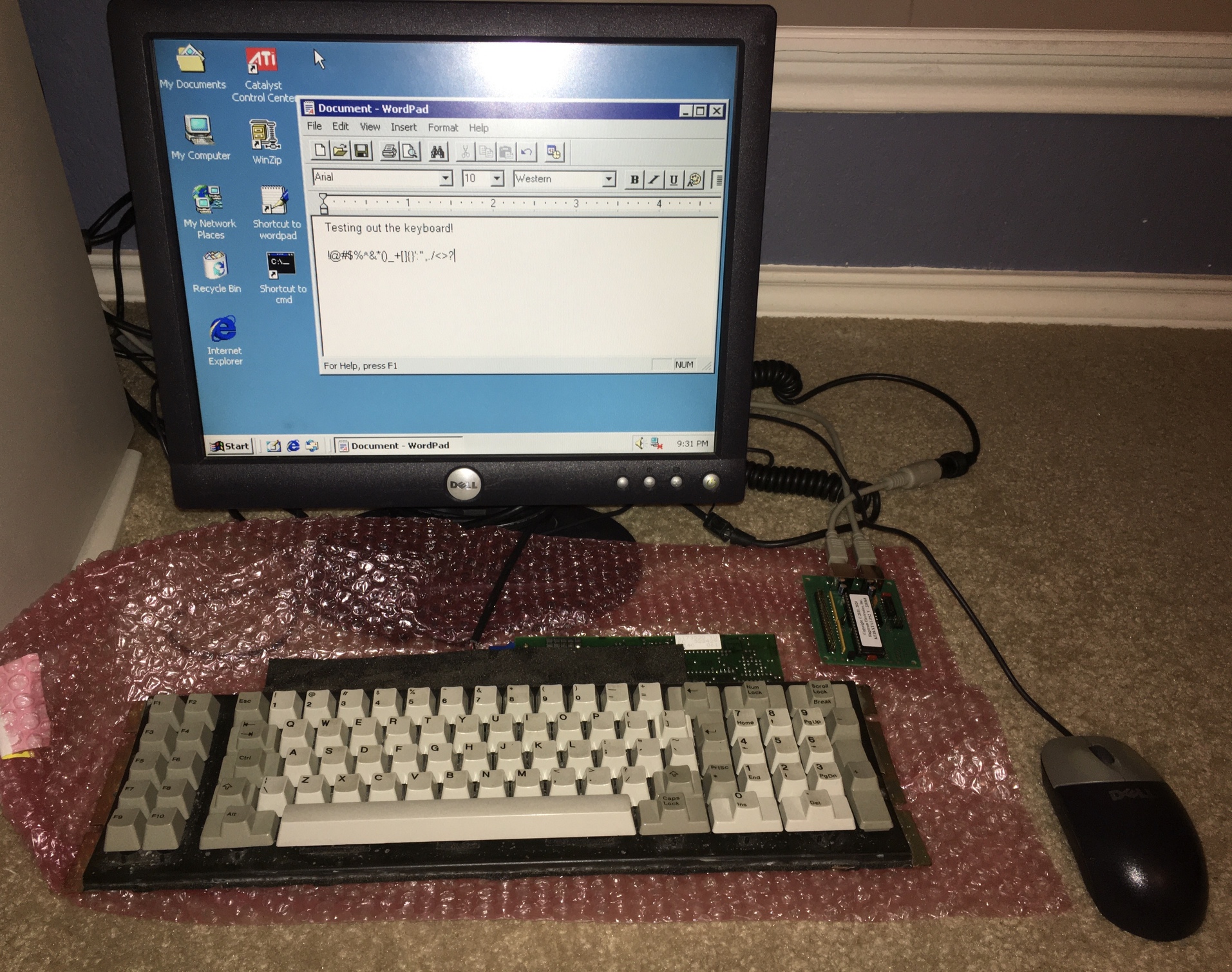
Глубокая чистка

Первым этапом я разобрал металлический корпус, чтобы оценить состояние пластины под клавишами. Там скопились многолетние залежи мусора, следы от кофе и наслоения грязи, которые все предстояло удалить. Удалению также подлежали обнаруженные на пластине следы ржавчины.

Я взял баллон со сжатым воздухом, с помощью которого продул гнезда клавиш и удалил прочий мусор. После этого я попробовал устранить всякие липкие наслоения с помощью ватных палочек и медицинского спирта, но успехом эта затея не увенчалась.
Удаление ржавчины
Для очистки ржавчины я позаимствовал у товарища гравер, на который накрутил насадку с мягкой пластиковой щеточкой, чтобы проделать этот процесс максимально деликатно. Скорее всего, для этой задачи можно было подыскать насадку и получше, но и имеющаяся вполне справилась. При этом мощности и оборотов гравера даже в самом слабом режиме хватало с избытком. В идеале лучше подошел бы инструмент с более низкими оборотами и более миниатюрной насадкой, что позволило бы достать абсолютно все точки ржавчины.

Гравер я использовал под освещением яркой настольной лампы и из-за отражения света не заметил, как он начал стачивать черное покрытие, оголяя серебристое металлическое основание. Тогда я просто решил снять это покрытие везде, где возможно, чтобы придать поверхности более однообразный вид. Серебристый метал виден, когда клавиши и корпус собраны обратно, но смотрится это нормально. К сожалению, с учетом размера вращателя и насадки я не смог зачистить всю поверхность пластины, но так как она все равно в итоге будет закрыта, ее неидеальный вид меня не особо беспокоил.

Goo Gone в помощь

На пластине по-прежнему оставались следы грязи, которые требовалось удалить. Сначала я попробовал соскрести их небольшой отверткой для очков, но вместе с тем соскабливалось черное покрытие, что несколько портило внешний вид. Тогда я решил применить химическое воздействие, в качестве которого использовал Goo Gone, что и следовало сделать изначально. Это средство в сочетании с ватными палочками и некоторыми мышечными усилиями привели-таки к успешному удалению столь упрямой грязи.

Купание клавиш
После приведения пластины в достойную форму, настал черед заняться самими клавишами. Сначала я хорошенько протер их влажными салфетками, с помощью которых удалось удалить большую часть темного налета и пятен. Тем не менее до идеала клавишам было еще далеко, и я где-то вычитал, что в подобном случае им может помочь только многочасовая ванна с большим количеством мыла. Что ж, этот способ сработал! Теперь клавиши выглядят как новые.

После этого я допустил одну оплошность, а именно не дал клавишам достаточно просохнуть изнутри, собрав их обратно слишком рано. В результате на несколько пружин попала влага, вызвав легкий налет ржавчины, который можно заметить на паре фотографий выше. После этого я еще раз искупал клавиши и теперь уже хорошенько продул их сжатым воздухом. После этого я дополнительно просушил их еще в течение двух дней и лишь потом установил обратно.
Апгрейд из XT в USB
После успешного тестирования клавиатуры и практически полного завершения ее реставрации пришло время поиска кабеля-переходника PS/2 – USB. Между делом я снова забрел на сайт Hagstrom Electronics и заметил, что у них в продаже уже есть небольшой блок KE-XTUSB для преобразования XT в USB, который продавался по той же цене, что и прежний. В итоге они любезно позволили мне вернуть ранее купленный KE18-XTAT-PS/2 в обмен на это устройство. Спустя несколько дней конвертер поступил на почту, и я с нетерпением подключил его уже к своему текущему компьютеру.

Итог
Все заработало прекрасно за исключением двух клавиш. Пружинный механизм “s” либо не обнаруживал нажатия клавиши, либо застревал в нажатом положении, выводя бесконечную череду “sssssssssssssssssssssssssss” на экране. Путем нехитрых манипуляций я добился правильного положения колпачка клавиши, и теперь она работает отлично. Второй проблемной клавишей оказался бухгалтерский "+" рядом с блоком дополнительных клавиш. В этом случае я обнаружил выскочившую каким-то образом пружинку, которую решил зафиксировать супер клеем. Тем не менее проблему это не устранило, потому что нажатия этой клавиши не регистрируются. Небольшая потеря, так как "+" можно напечатать и другой клавишей.
В общем и целом, я очень впечатлен внешним видом клавиатуры, и если сравнивать с этим видео, в котором распаковывается новехонькая Model F, то выглядит она почти так же!

Если у вас есть вопросы или комментарии — обращайтесь в Twitter @opsdisk


Удобное логирование на бэкенде. Доклад Яндекса
Что-то всегда идет не по плану. Приходится отвечать на вопросы, «Что сломалось?», «Почему тормозит?» и «Почему мы не увидели этого раньше?». На примере простого приложения Даниил Галиев zefirior из Яндекс.Путешествий показал, как отвечать на эти вопросы и какие инструменты в этом помогут. Настроим логирование, прикрутим трассировку, разложим ошибки, и все это в удобном интерфейсе.— Давайте начинать. Я расскажу об удобном логировании и инфраструктуре вокруг логирования, которую можно развернуть, чтобы вам с вашим приложением и его жизненным циклом было удобно жить.
Начнем. Наш стартап — это «Книжная лавка». Главной фичей этого приложения будет продажа книг, это все, что мы хотим сделать. Дальше немного начинки. Приложение будет написано на Flask. Все сниппеты кода, все инструменты общие и абстрагированы от Python, поэтому их можно будет интегрировать в большинство ваших приложений. Но в нашем докладе это будет Flask.
Теперь давайте про базовое логирование, то, которое мы впилили. Начнем с терминологии.
Переходим к проблемам. Для начала проблема первая: логи разбросаны.
Следующая проблема — тормоза. В микросервисной архитектуре всегда и везде бывают тормоза.
Последняя проблема — ошибки. Да, я лукавлю. Я не помогу вам избавиться от ошибок в приложении, но я расскажу, что с ними можно делать дальше.

Что будем делать? Мы построим небольшое приложение, наш стартап. Потом внедрим в него базовое логирование, это маленькая часть доклада, то, что поставляет Python из коробки. И дальше самая большая часть — мы разберем типичные проблемы, которые встречаются нам во время отладки, выкатки, и инструменты для их решения.
Небольшой дисклеймер: я буду говорить такие слова, как «ручка» и «локаль». Поясню. «Ручка» — возможно, яндексовый сленг, это обозначает ваши API, http или gRPC API или любые другие комбинации букв перед APU. «Локаль» — это когда я разрабатываю на ноутбуке. Вроде бы я рассказал обо всех словах, которые я не контролирую.
Приложение «Книжная лавка»
Начнем. Наш стартап — это «Книжная лавка». Главной фичей этого приложения будет продажа книг, это все, что мы хотим сделать. Дальше немного начинки. Приложение будет написано на Flask. Все сниппеты кода, все инструменты общие и абстрагированы от Python, поэтому их можно будет интегрировать в большинство ваших приложений. Но в нашем докладе это будет Flask.
Действующие лица: я, разработчик, менеджеры и мой любимый коллега Эраст. Любые совпадения случайны.
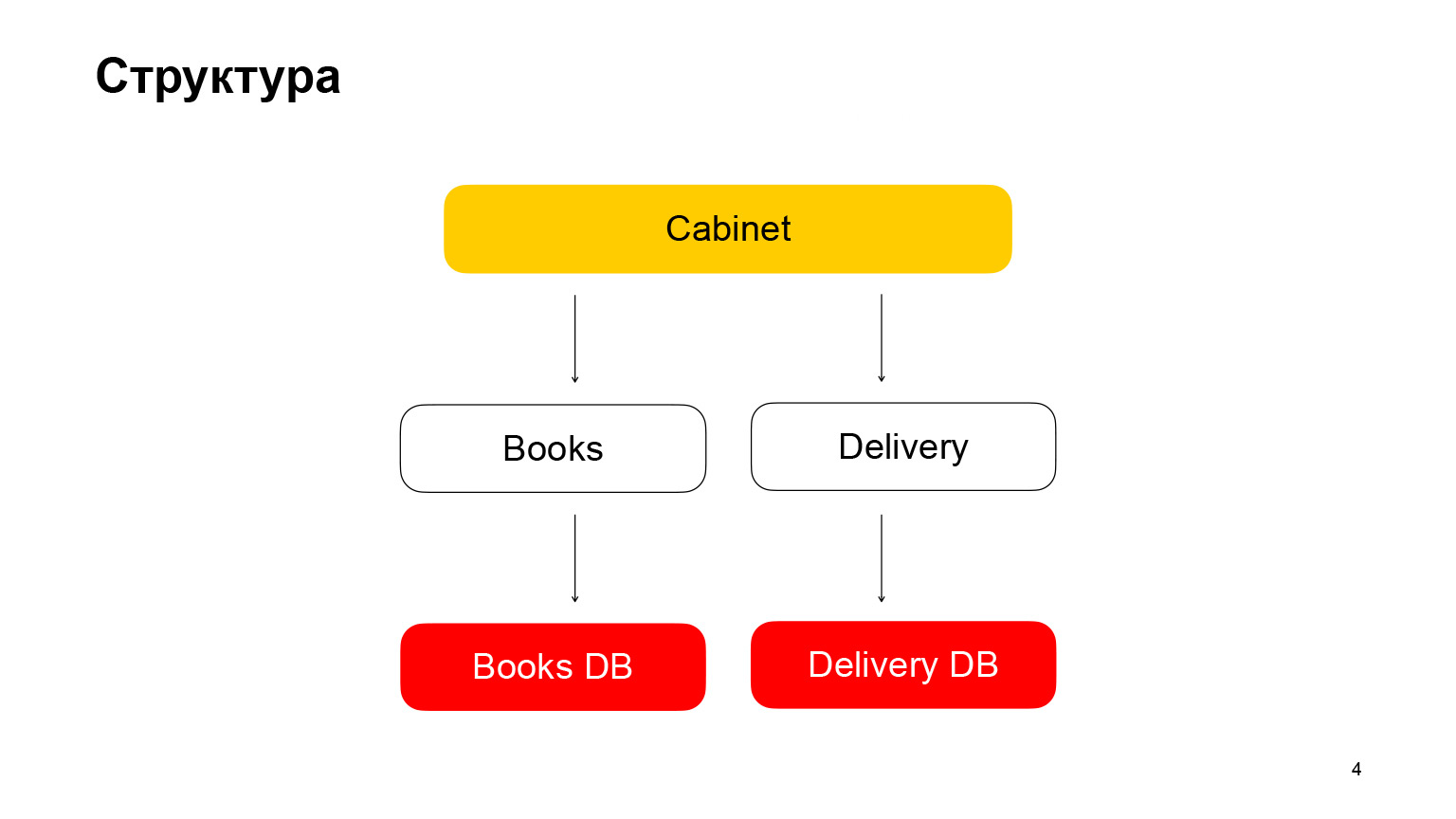
Давайте немного про структуру. Это приложение с микросервисной архитектурой. Первый сервис — Books, хранилище книг с метаданными о книгах. Он использует базу данных PostgreSQL. Второй микросервис — микросервис доставки, хранит метаданные о заказах пользователей. Cabinet — это бэкенд для кабинета. У нас нет фронтенда, в нашем докладе он не нужен. Cabinet агрегирует запросы, данные из сервиса книг и сервиса доставки.

По-быстрому покажу код ручек этих сервисов, API Books. Это ручка выгребает данные из базы, сериализует их, превращает в JSON и отдает.

Пойдем дальше. Сервис доставки. Ручка точно такая же. Выгребаем данные из базы, сериализуем их и отправляем.

И последняя ручка — ручка кабинета. В ней немного другой код. Ручка кабинета запрашивает данные из сервиса доставки и из сервиса книг, агрегирует ответы и отдает пользователю его заказы. Всё. Со структурой приложения мы по-быстрому разобрались.
Базовое логирование в приложении
Теперь давайте про базовое логирование, то, которое мы впилили. Начнем с терминологии.

Что нам дает Python? Четыре базовые, главные сущности:
— Logger, входная точка логирования в вашем коде. Вы будете пользоваться каким-то Logger, писать logging.INFO, и все. Ваш код больше ничего не будет знать о том, куда сообщение улетело и что с ним дальше произошло. За это уже отвечает сущность Handler.
— Handler обрабатывает ваше сообщение, решает, куда его отправить: в стандартный вывод, в файл или кому-нибудь на почту.
— Filter — одна из двух вспомогательных сущностей. Удаляет сообщения из лога. Другой стандартный вариант использования — это наполнение данными. Например, в вашей записи нужно добавить атрибут. Для этого тоже может помочь Filter.
— Formatter приводит ваше сообщение к нужному виду.

На этом с терминологией закончили, дальше к логированию прямо на Python, с базовыми классами, мы возвращаться не будем. Но вот пример конфигурации нашего приложения, которая раскатана на всех трех сервисах. Здесь два главных, важных для нас блока: formatters и handlers. Для formatters, есть пример, который вы можете увидеть здесь, шаблон того, как будет выводиться сообщение.
В handlers вы можете увидеть, что logging.StreamHandler использован. То есть мы выгружаем все наши логи в стандартный вывод. Всё, с этим закончили.
Проблема 1. Логи разбросаны
Переходим к проблемам. Для начала проблема первая: логи разбросаны.
Немножечко контекста. Наше приложение мы написали, конфетка уже готова. Мы можем на нем зарабатывать денежку. Мы его выкатываем в продакшен. Конечно, там не один сервер. По нашим скромным подсчетам, нашему сложнейшему приложению нужно порядка трех-четырех машинок, и так для каждого сервиса.
Теперь вопрос. Прибегает к нам менеджер и спрашивает: «Там сломалось, помоги!» Вы бежите. У вас же все логируется, это великолепно. Вы заходите на первую машинку, смотрите — там ничего нет по вашему запросу. Заходите на вторую машинку — ничего. И так далее. Это плохо, это надо как-то решать.

Давайте формализуем результат, который мы хотим увидеть. Я хочу, чтобы логи были в одном месте. Это простое требование. Немного круче то, что я хочу поиск по логам. То есть да, оно лежит в одном месте и я умею грепать, но было бы прикольно, если бы были какие-нибудь tools, крутые фичи помимо простого грепа.
И я не хочу писать. Это Эраст любит писать код. Я не про это, я сразу сделал продукт. То есть хочется меньше дополнительного кода, обойтись одним-двумя файликами, строчками, и всё.

Решение, которое можно использовать, — ElasticSearch. Давайте его попробуем поднять. Какие плюсы ElasticSearch нам даст? Это интерфейс с поиском логов. Сразу из коробки есть интерфейс, это вам не консолька, а единственное место хранения. То есть главное требование мы отработали. Нам не нужно будет ходить по серверам.
В нашем случае это будет довольно простая интеграция, и с недавним релизом у ElasticSearch выпустился новый агент, который отвечает за большинство интеграций. Они там сами впилили интеграции. Очень круто. Я составлял доклад чуть раньше и использовал filebeat, так же просто. Для логов все просто.
Немного об ElasticSearch. Не хочу рекламировать, но там много дополнительных фич. Например, крутая штука — полнотекстовый поиск по логам из коробки. Очень круто звучит. Нам пока достаточно этих плюсов. Прикручиваем.
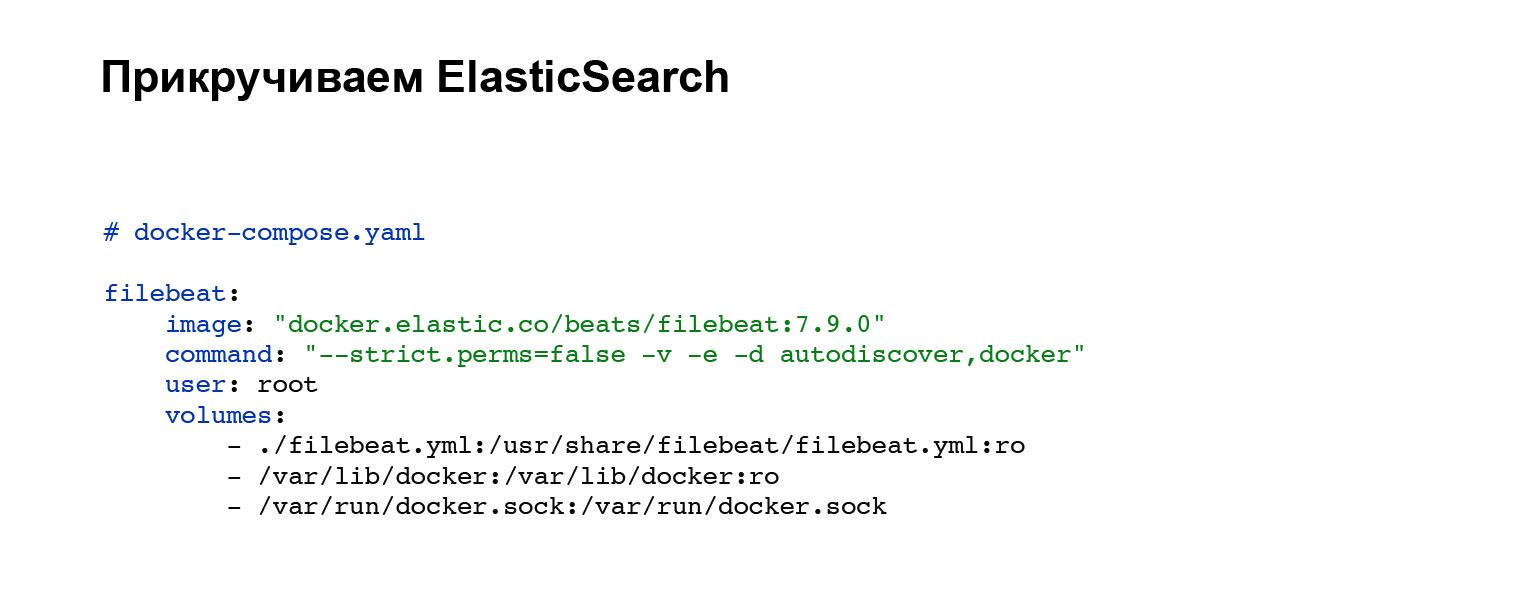
В первую очередь нам нужно будет развернуть агент, который будет отправлять наши логи в Elastic. Вы регистрируете аккаунт в Elastic и дальше добавляете в ваш docker-compose. Если у вас не docker-compose, можете поднимать ручками или в вашей системе. В нашем случае добавляется вот такой блок кода, интеграции в docker-compose. Всё, сервис настроен. И вы можете увидеть в блоке volumes файл конфигурации filebeat.yml.

Вот пример filebeat.yml. Здесь настроен автоматический поиск логов контейнеров docker, которые крутятся рядом. Кастомизован выбор этих логов. По условию можно задавать, вешать на ваши контейнеры лейблы, и в зависимости от этого ваши логи будут отправляться только у определенных контейнеров. С блоком processors:add_docker_metadata все просто. В логи добавляем немножечко больше информации о ваших логах в контексте docker. Необязательно, но прикольно.
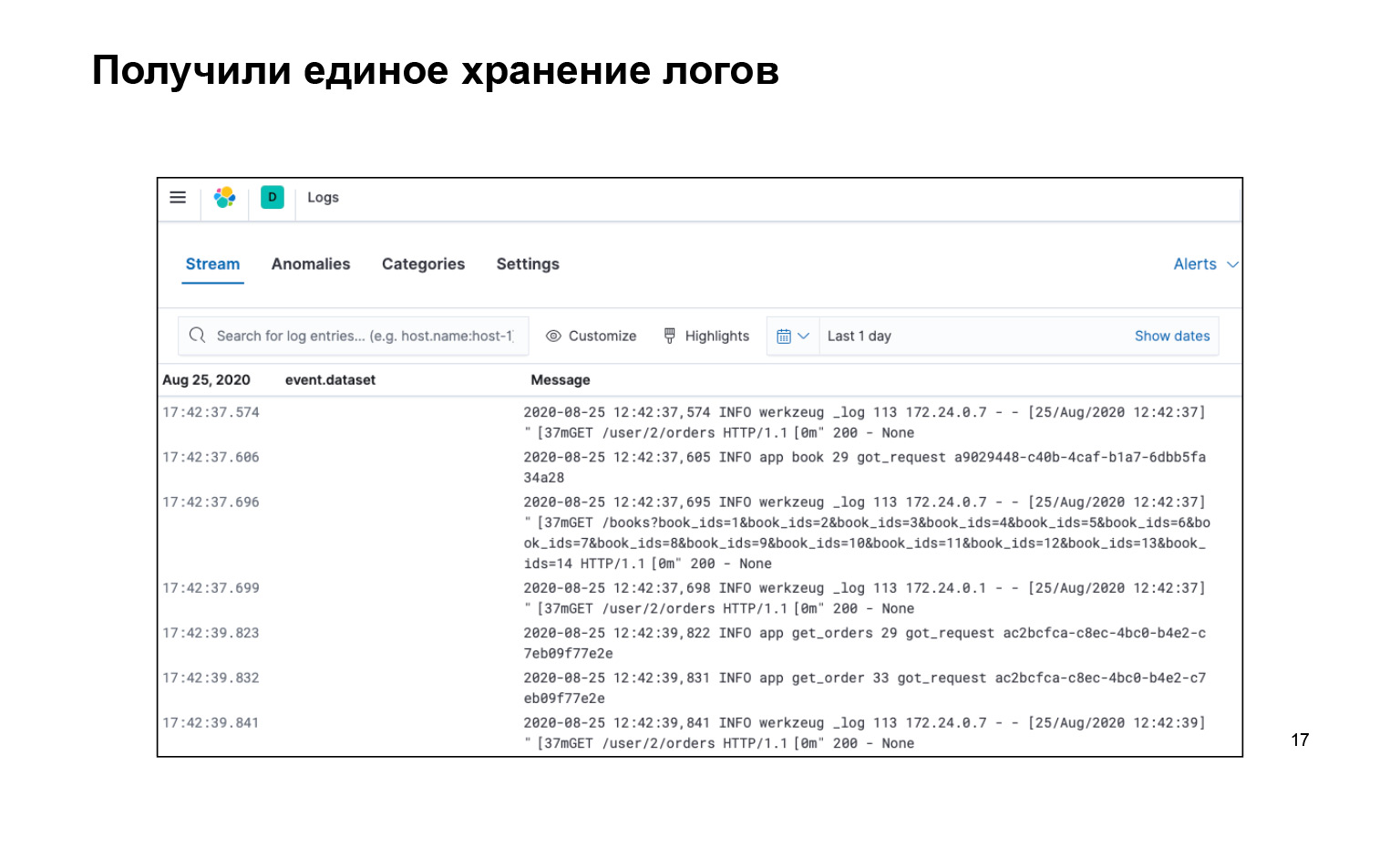
Что мы получили? Это все, что мы написали, весь код, очень круто. При этом мы получили все логи в одном месте и есть интерфейс. Мы можем поискать наши логи, вот плашечка search. Они доставляются. И можно даже в прямом эфире включить так, чтобы стрим летел к нам в логи в интерфейс, и мы это видели.

Тут я бы и сам спросил: а чего, как грепать-то? Что из себя представляет поиск по логам, что там можно сделать?
Да, из коробки в таком подходе, когда у нас текстовые логи, есть небольшой затык: мы можем по тексту задать запрос, например message:users. Это выведет нам все логи, у которых есть подстрока users. Можно пользоваться звездочками, большинством других юниксовых wild cards. Но кажется, этого недостаточно, хочется сделать сложнее, чтобы можно было нагрепать в Nginx раньше, как мы это умеем.

Давайте немного отступим от ElasticSearch и попытаемся сделать это не с ElasticSearch, а с другим подходом. Рассмотрим структурные логи. Это когда каждая ваша запись лога — это не просто текстовая строчка, а сериализованный объект с атрибутами, которые любая ваша сторонняя система может сериализовать, чтобы получить уже готовый объект.
Какие от этого есть плюсы? Это единый формат данных. Да, у объектов могут быть разные атрибуты, но любая внешняя система может прочитать именно JSON и получить какой-то объект.
Какая-никакая типизация. Это упрощает интеграцию с другими системами: не нужно писать десериализаторы. И как раз десериализаторы — это другой пункт. Вам не нужно писать в приложении прозаичные тексты. Пример: «User пришел с таким-то айдишником, с таким-то заказом». И это все нужно писать каждый раз.
Меня это напрягало. Я хочу написать: «Прилетел запрос». Дальше: «Такой-то, такой-то, такой-то», очень просто, очень по-айтишному.

Давайте дальше. Договоримся: логировать будем в формате JSON, это простой формат. Сразу ElasticSearch поддерживается, filebeat, которым мы сериализуем и попробуем впилить. Это не очень сложно. Для начала вы добавляете из библиотеки pythonjsonlogger в блок formatters JSONFormatter файлика settings, где у нас хранится конфигурация. У вас в системе это может быть другое место. И дальше в атрибуте format вы передаете, какие атрибуты вы хотите добавлять в ваш объект.
Блок ниже — это блок конфигурации, который добавляется в filebeat.yml. Здесь из коробки есть интерфейс у filebeat для парсинга JSON-логов. Очень круто. Это все. Для этогов вам больше ничего писать не придется. И теперь ваши логи похожи на объекты.
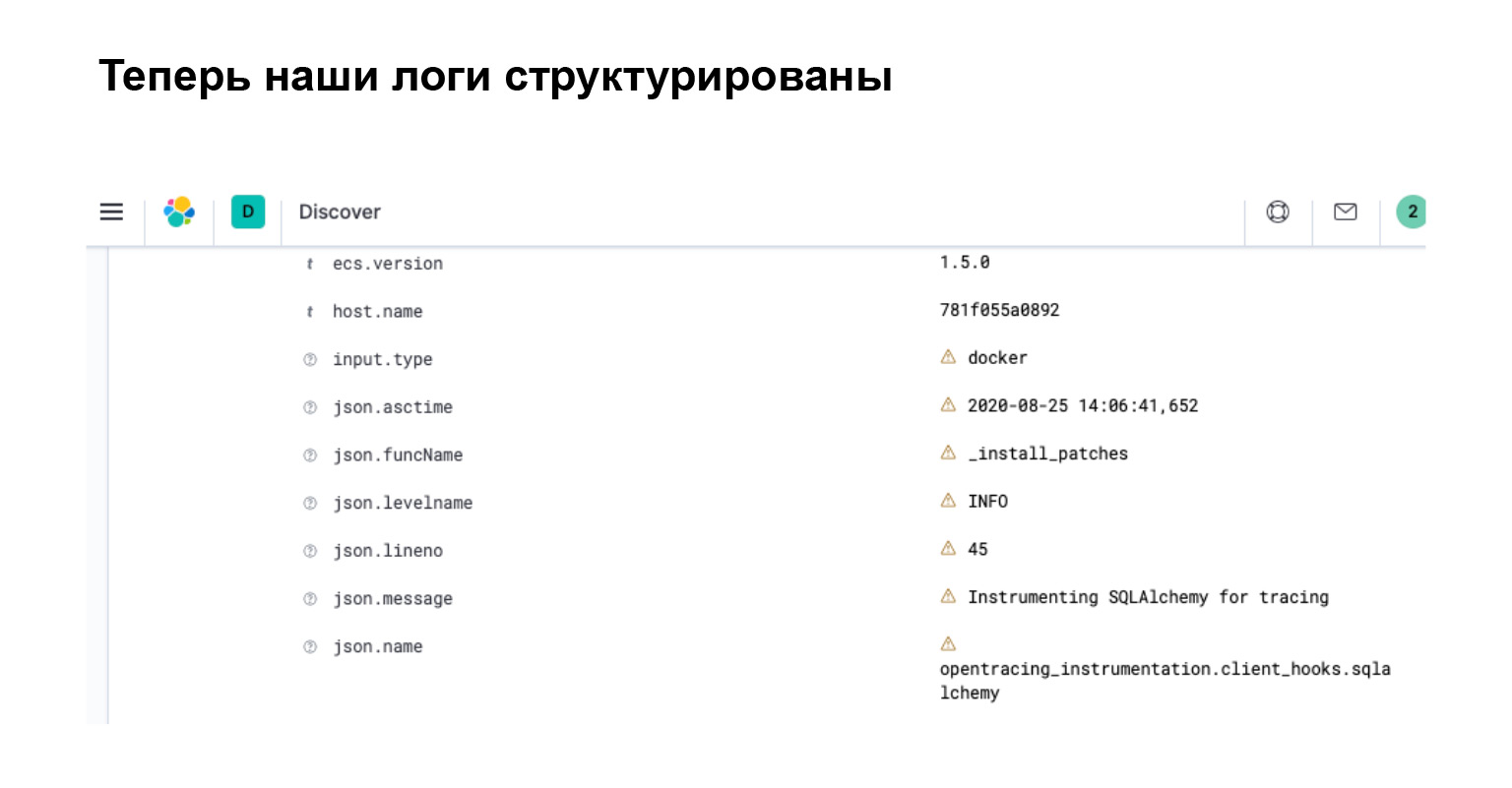
Что мы получили в ElasticSearch? В интерфейсе вы сразу видите, что ваш лог превратился в объект с отдельными атрибутами, по которым вы можете искать, создавать фильтрации и делать сложные запросы.

Давайте подведем итог. Теперь наши логи имеют структуру. По ним несложно грепать и можно писать интеллектуальные запросы. ElasticSearch знает об этой структуре, так как он распарсил все эти атрибуты. А в kibana — это интерфейс для ElasticSearch — можно фильтровать такие логи с помощью специализированного языка запросов, который предоставляет Elastic Stack.
И это проще, чем грепать. Греп имеет довольно сложный и крутой язык. Там очень много можно написать. В kibana можно сделать многие вещи проще. С этим разобрались.
Проблема 2. Тормоза
Следующая проблема — тормоза. В микросервисной архитектуре всегда и везде бывают тормоза.

Тут немного контекста, расскажу вам историю. Ко мне прибегает менеджер, главное действующее лицо нашего проекта, и говорит: «Эй-эй, кабинет тормозит! Даня, спаси, помоги!»
Мы пока ничего не знаем, лезем в Elastic в наши логи. Но давайте я расскажу, что, собственно, произошло.

Эраст добавил фичу. В книгах мы теперь отображаем не айдишник автора, а его имя прямо в интерфейсе. Очень круто. Сделал он это вот таким кодом. Небольшой кусок кода, ничего сложного. Что может пойти не так?
Вы наметанным взглядом можете сказать, что с SQLAlchemy так делать нельзя, с другой ORM тоже. Нужно сделать прекэш или что-нибудь еще, чтобы в цикле не ходить в базу с маленьким подзапросиком. Неприятная проблема. Кажется, что такую ошибку вообще нельзя допустить.
Давайте расскажу. У меня был опыт: мы работали с Django, и у нас в проекте был реализован кастомный прекэш. Много лет все шло хорошо. В какой-то момент мы с Эрастом решили: давай пойдем в ногу со временем, обновим Django. Естественно, Django ничего не знает о нашем кастомном прекэше, и интерфейс поменялся. Прикэш отвалился, молча. На тестировании это не отловили. Та же самая проблема, просто ее сложнее было отловить.
Проблема в чем? Как я помогу вам решить проблему?

Давайте расскажу, что я делал до того, как начал решать именно проблему поиска тормозов.
Первое, что делаю, — иду в ElasticSearch, у нас он уже есть, помогает, не нужно бегать по серверам. Я захожу в логи, ищу логи кабинета. Нахожу долгие запросы. Воспроизвожу на ноутбуке и вижу, что тормозит не кабинет. Тормозит Books.
Бегу в логи Books, нахожу проблемные запросы — собственно, он у нас уже есть. Точно так же воспроизвожу Books на ноутбуке. Очень сложный код — ничего не понимаю. Начинаю дебажить. Тайминги довольно сложно отлавливать. Почему? Внутри SQLAlchemy довольно сложно это определить. Пишу кастомные тайм-логгеры, локализую и исправляю проблему.
Мне было больно. Сложно, неприятно. Я плакал. Хочется, чтобы этот процесс поиска проблемы был быстрее и удобнее.
Формализуем наши проблемы. Сложно по логам искать, что тормозит, потому что наш лог — это лог несвязанных событий. Приходится писать кастомные таймеры, которые показывают нам, сколько выполнялись блоки кода. Причем непонятно, как логировать тайминги внешних систем: например, ORM или библиотек requests. Надо наши таймеры внедрять внутрь либо каким-то Wrapper, но мы не узнаем, от чего оно тормозит внутри. Сложно.

Хорошее решение, которое я нашел, — Jaeger. Это имплементация протокола opentracing, то есть давайте внедрим трассировку.
Что дает Jaeger? Это удобный интерфейс с поиском запросов. Вы можете отфильтровать долгие запросы или сделать это по тегам. Наглядное представление потока запросов, очень красивая картинка, чуть позже покажу.
Тайминги логируются из коробки. С ними ничего не надо делать. Если вам нужно про какой-то кастомный блок проверить, сколько он выполняется, вы можете его обернуть в таймеры, предоставляемые Jaeger. Очень удобно.
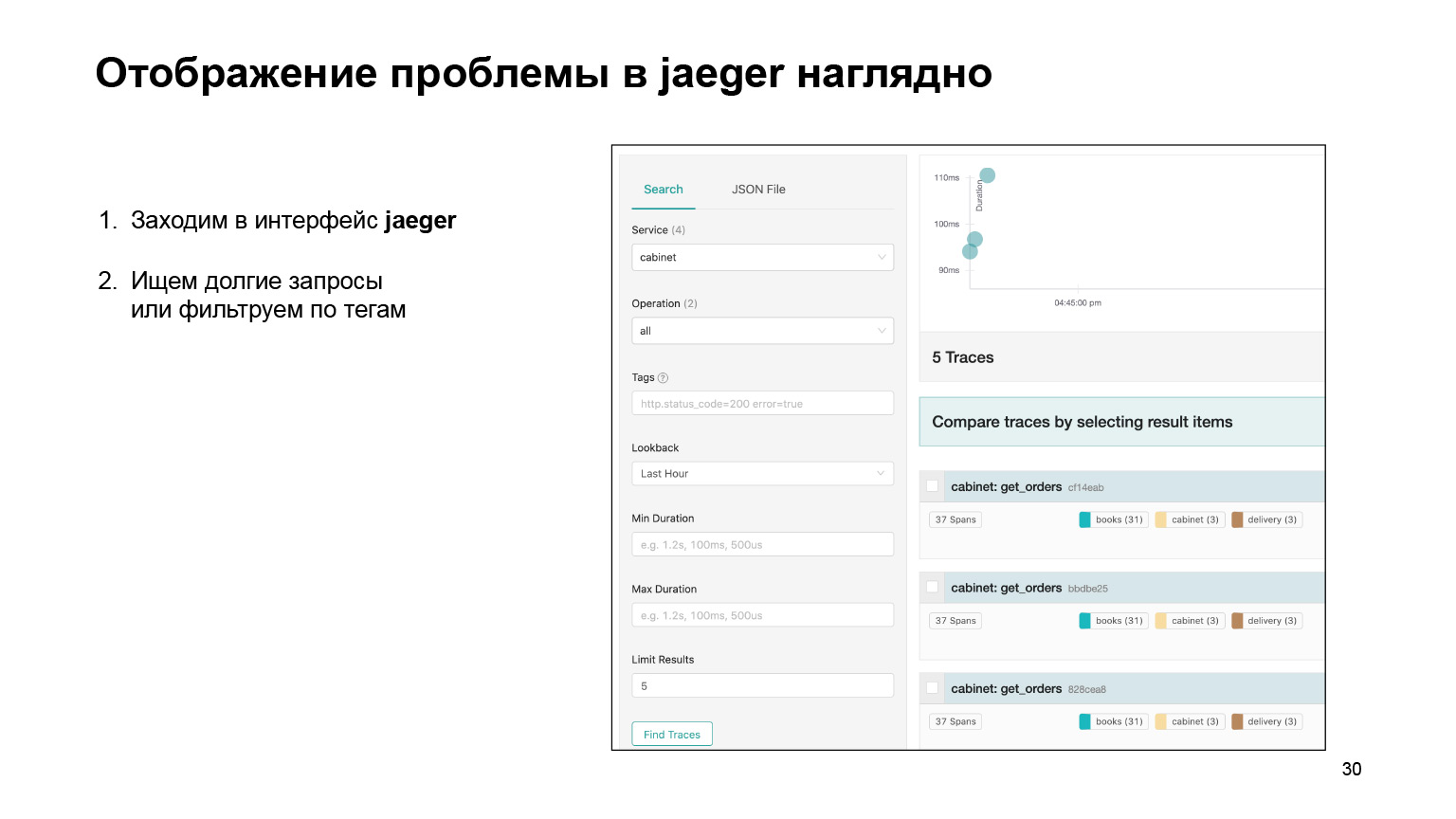
Посмотрим, как вообще можно было найти проблему в интерфейсе и там же ее локализовать. Мы заходим в интерфейс Jaeger. Вот так выглядят наши запросы. Мы можем поискать запросы именно кабинета или другого сервиса. Сразу фильтруем долгие запросы. Нас интересуют именно долгие, их по логам довольно сложно найти. Получаем их список.
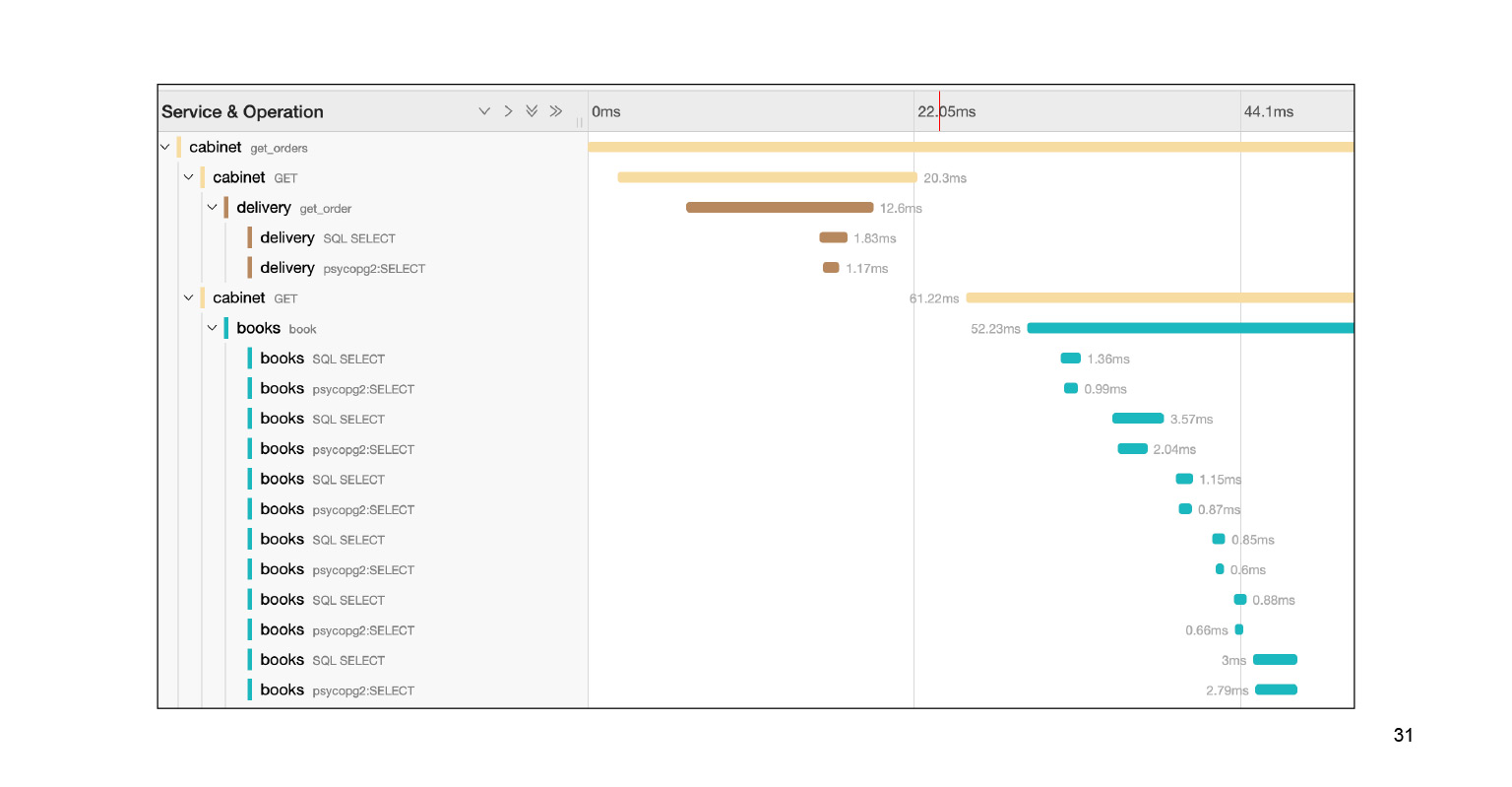
Проваливаемся в этот запрос, и видим большую портянку SQL-подзапросов. Мы прямо наглядно видим, как они исполнялись по времени, какой блок кода за что отвечал. Очень круто. Причем в контексте нашей проблемы это не весь лог. Там есть еще большая портянка на два-три слайда вниз. Мы довольно быстро локализовали проблему в Jaeger. В чем после решения проблемы нам может помочь контекст, который предоставляет Jaeger?
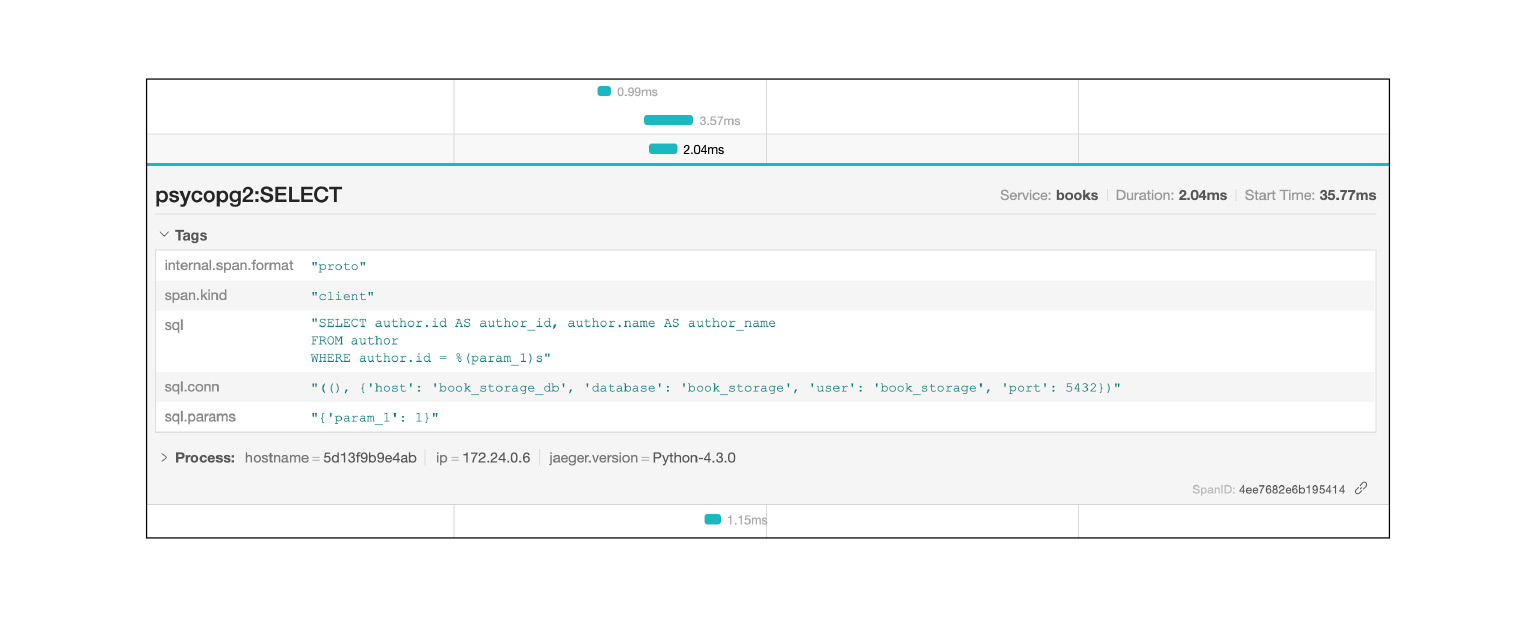
Jaeger логирует, например, SQL-запросы: вы можете посмотреть, какие запросы повторяются. Очень быстро и круто.
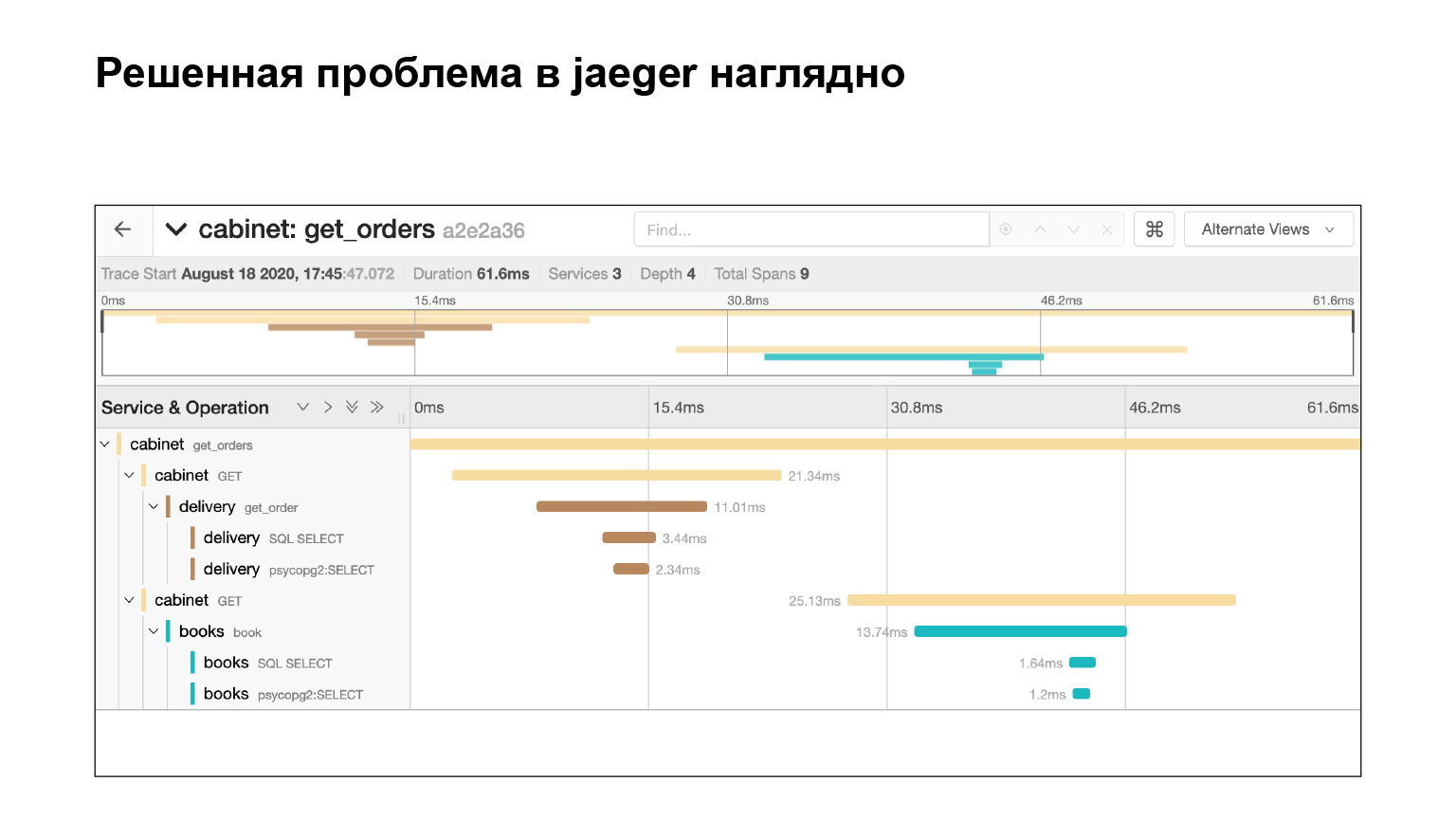
Проблему мы решили и сразу видим в Jaeger, что все хорошо. Мы проверяем по тому же запросу, что у нас теперь нет подзапросов. Почему? Предположим, мы проверим тот же запрос, узнаем тайминг — посмотрим в Elastic, сколько запрос выполнялся. Тогда мы увидим время. Но это не гарантирует, что подзапросов не было. А здесь мы это видим, круто.

Давайте внедрим Jaeger. Кода нужно не очень много. Вы добавляете зависимости для opentracing, для Flask. Теперь о том, какой код мы делаем.
Первый блок кода — это настройка клиента Jaeger.
Затем мы настраиваем интеграцию с Flask, Django или с любым другим фреймворком, на который есть интеграция.
install_all_patches — самая последняя строчка кода и самая интересная. Мы патчим большинство внешних интеграция, взаимодействуя с MySQL, Postgres, библиотекой requests. Мы все это патчим и именно поэтому в интерфейсе Jaeger сразу видим все запросы с SQL и то, в какой из сервисов ходил наш искомый сервис. Очень круто. И вам не пришлось много писать. Мы просто написали install_all_patches. Магия!
Что мы получили? Теперь не нужно собирать события по логам. Как я сказал, логи — это разрозненные события. В Jaeger это одно большое событие, структуру которого вы видите. Jaeger позволяет отловить узкие места в приложении. Вы просто делаете поиск по долгим запросам, и можете проанализировать, что идет не так.
Проблема 3. Ошибки
Последняя проблема — ошибки. Да, я лукавлю. Я не помогу вам избавиться от ошибок в приложении, но я расскажу, что с ними можно делать дальше.

Контекст. Вы можете сказать: «Даня, мы логируем ошибки, у нас есть алерты на пятисотки, мы настроили. Чего ты хочешь? Логировали, логируем и будем логировать и отлаживать.
По логам вы не знаете важность ошибки. Что такое важность? Вот у вас есть одна крутая ошибка, и ошибка подключения к базе. База просто флапнула. Хочется сразу видеть, что эта ошибка не так важна, и если нет времени, не обращать на нее внимания, а фиксить более важную.
Частота появления ошибок — это контекст, который может нам помочь в ее отладке. Как отслеживать появление ошибок? Преподолжим, у нас месяц назад была ошибка, и вот она снова появилась. Хочется сразу найти решение и поправить ее или сопоставить ее появление с одним из релизов.
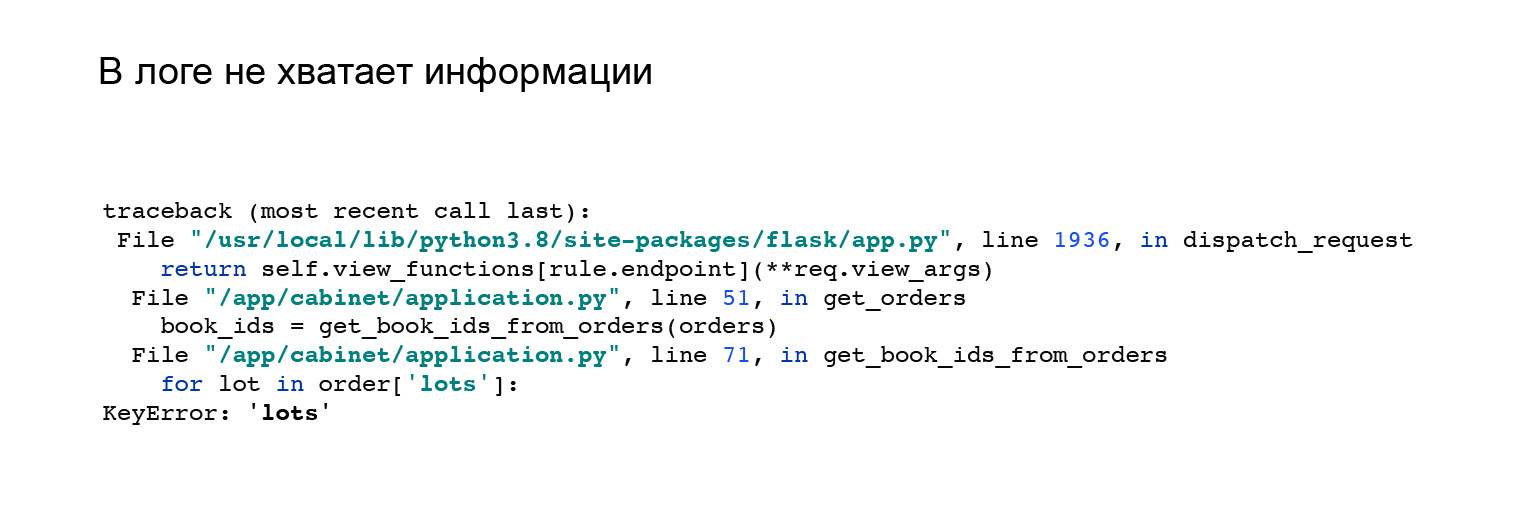
Вот наглядный пример. Когда я впиливал интеграцию с Jaeger, то немного поменял свою API. У меня изменился формат ответа приложения. Я получил вот такую ошибку. Но в ней непонятно, почему у меня нет ключа, lots в объекте order, и нет ничего, что мне бы помогло. Мол, смотри ошибку здесь, воспроизведи и самостоятельно отлови.

Давайте внедрим sentry. Это баг-трекер, который поможет нам в решении подобных проблем и поиске контекста ошибки. Возьмем стандартную библиотеку, поддерживаемую разработчиками sentry. В четыре строчки кода мы ее добавляем в наше приложение. Всё.
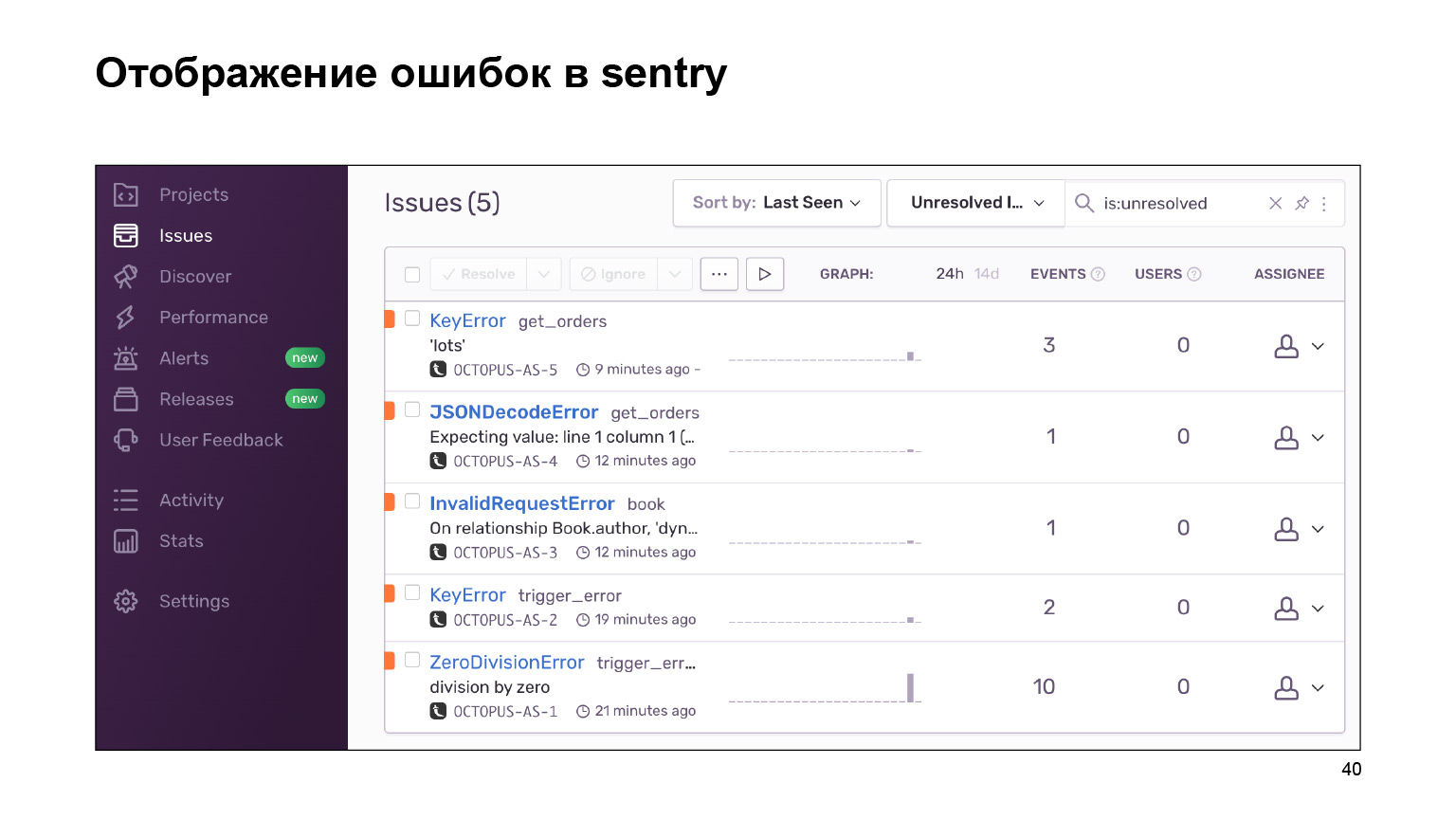
Что мы получили на выходе? Вот такой дашборд с ошибками, которые можно сгруппировать по проектам и за которыми можно следить. Огромная портянка логов с ошибками группируется в одинаковые, похожие. По ним приводится статистика. И вы также можете работать с этими ошибками с помощью интерфейса.
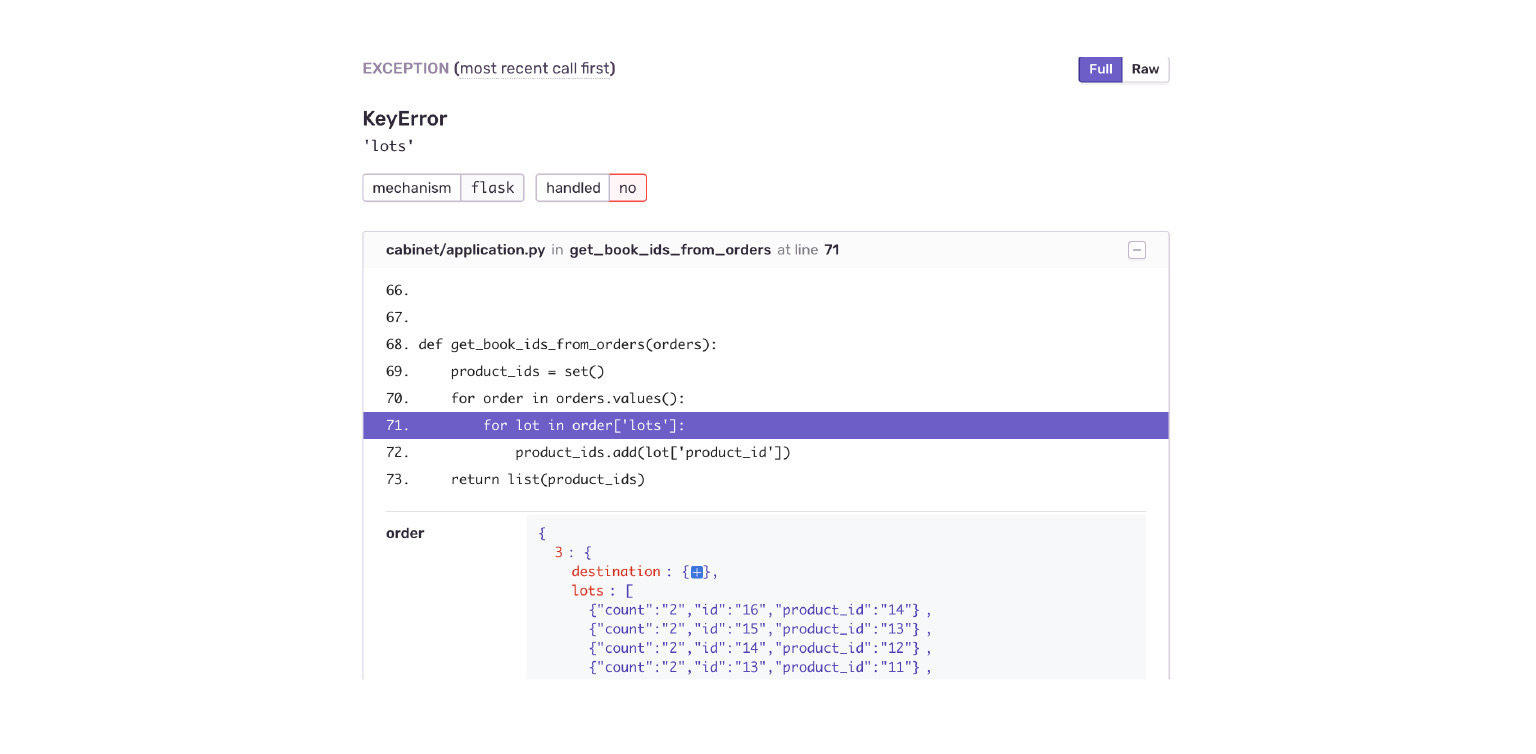
Посмотрим на нашем примере. Проваливаемся в ошибку KeyError. Сразу видим контекст ошибки, что было в объекте order, чего там не было. Я сразу по ошибке вижу, что мне приложение Delivery отдало новую структуру данных. Кабинет просто к этому не готов.

Что дает sentry, помимо того, что я перечислил? Формализуем.
Это хранилище ошибок, в котором можно искать их. Для этого есть удобные инструменты. Есть группировка ошибок — по проектам, по похожести. Sentry дает интеграции с разными трекерами. То есть вы можете следить за вашими ошибками, работать с ними. Вы можете просто добавлять задачу в ваш контекст, и все. Это помогает в разработке.
Статистика по ошибкам. Опять же, легко сопоставить с выкаткой релиза. В этом вам поможет sentry. Похожие события, которые произошли рядом с ошибкой, тоже могут вам помочь в поиске и понимании того, что к ней привело.

Давайте подведем итог. Мы с вами написали приложение, простое, но отвечающее потребностям. Оно помогает вам в разработке и поддержке, в его жизненном цикле. Что мы сделали? Мы собрали логи в одно хранилище. Это дало нам возможность не искать их по разным местам. Плюс у нас появился поиск по логам и сторонние фичи, наши tools.
Интегрировали трассировку. Теперь мы наглядно можем следить за потоком данных в нашем приложении.
И добавили удобный инструмент для работы с ошибками. Они в нашем приложении будут, как бы мы ни старались. Но мы будем фиксить их быстрее и качественнее.
Что еще можно добавить? Само приложение готово, оно есть по ссылке, вы можете посмотреть, как оно сделано. Там поднимаются все интеграции. Например, интеграции с Elastic или трассировки. Заходите, смотрите.
Еще одна крутая штука, которую я не успел осветить, — requests_id. Почти ничем не отличается от trace_id, который используется в трассировках. Но за requests_id отвечаем мы, это самая главная его фича. Менеджер может прийти к нам сразу с requests_id, нам не потребуется его искать. Мы сразу начнем решать нашу проблему. Очень круто.
И не забывайте, что инструменты, которые мы внедряли, имеют overhead. Это проблемы, которые нужно рассматривать для каждого приложения. Нельзя бездумно внедрить все наши интеграции, облегчить себе жизнь, а потом думать, что делать с тормозящим приложением.
Проверяйте. Если на вас это не сказывается, круто. Вы получили только плюсы и не решаете проблемы с тормозами. Не забывайте об этом. Всем спасибо, что слушали.
Подписаться на:
Комментарии (Atom)