Разработка многопользовательских игр сложна по множеству причин: их хостинг может оказаться дорогим, структура — неочевидной, а реализация — трудной. В этом туториале я постараюсь помочь вам преодолеть последний барьер.
Статья предназначена для разработчиков, умеющих создавать игры и знакомых с JavaScript, но никогда раньше не писавших мультиплеерные онлайн-игры. Завершив этот туториал, вы освоите реализацию базовых сетевых компонентов в своей игре и сможете развить её во что-то большее! Вот, что мы будем создавать:
Поиграть в готовую игру можно
здесь! При нажатии клавиш W или «вверх» корабль приближается к курсору, при щелчке мыши — стреляет.
(Если никого нет онлайн, то чтобы проверить, как работает мультиплеер, откройте два окна браузера на одном компьютере, или одно из них на телефоне, ). Если вы хотите запустить игру локально, то полный исходный код выложен на
GitHub.
При создании игры я использовал графические ресурсы из
Kenney's Pirate Pack и игровой фреймворк
Phaser. В этом туториале вам отведена роль сетевого программиста. Начальной точкой будет полностью функциональная однопользовательская версия игры, а нашей задачей будет написание сервера на Node.js с использованием
Socket.io для сетевой части. Чтобы не перегружать туториал, я сосредоточусь на частях, относящихся к мультиплееру, и пропущу концепции, относящиеся к Phaser и Node.js.
Вам не нужно настраивать ничего локально, потому что мы будем создавать эту игру полностью в браузере на сайте Glitch.com! Glitch — это потрясающий инструмент для создания веб-приложений, в том числе бэкенда, баз данных и всего остального. Он отлично подходит для прототипирования, обучения и совместной работы, и я очень рад буду познакомить вас с его возможностями в этом туториале.
Давайте приступим.
1. Подготовка
Я выложил заготовку проекта на
Glitch.com.
Подсказки по интерфейсу: превью приложения можно запустить, нажав на кнопку Show (вверху слева).
В вертикальной боковой панели слева содержатся все файлы приложения. Для редактирования этого приложения необходимо создать его «ремикс». Так мы создадим её копию в своей учётной записи (или «форк» в жаргоне git). Нажмите на кнопку
Remix this.
На этом этапе вы редактируете приложение под анонимной учётной записью. Чтобы сохранить работу, можно выполнить вход (справа вверху).
Сейчас, прежде чем двигаться дальше, вам важно познакомиться с игрой, в которую мы будем добавлять многопользовательский режим. Посмотрите на index.html. В нём есть три важные функции, о которых нужно знать: preload (строка 99), create (строка 115) и GameLoop (строка 142), а также объект игрока (строка 35).
Если вы предпочитаете обучаться практикуясь, то убедитесь, что разобрались в работе игры, выполнив следующие задания:
- Увеличьте размер мира (строка 29) — заметьте, что есть отдельный размер мира для внутриигрового мира и размер окна для самого холста страницы.
- Сделайте так, чтобы двигаться вперёд можно было и при помощи «пробела»(строка 53).
- Измените тип корабля игрока (строка 129).
- Замедлите движение снарядов (строка 155).
Установка Socket.io
Socket.io — это библиотека для управления коммуникациями в реальном времени внутри браузера с помощью
WebSockets (вместо использования протоколов наподобие UDP, которые применяются при создании классических многопользовательских игр). Кроме того, у библиотеки есть резервные способы обеспечения работы, даже когда WebSockets не поддерживаются. То есть она занимается протоколами обмена сообщениями и позволяет использовать удобную систему сообщений на основе событий.
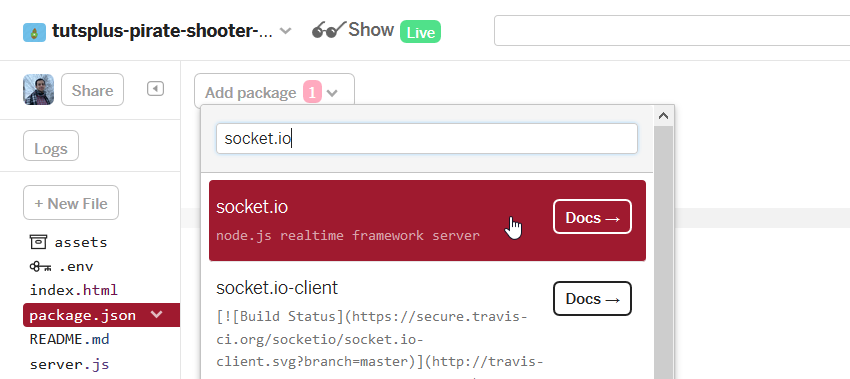
Первое, что нам нужно сделать — установить модуль Socket.io. В Glitch это можно сделать, перейдя в файл package.json, а затем или введя необходимый модуль в зависимостях, или нажав Add package и введя «socket.io».
Теперь как раз подходящее время, чтобы разобраться с логами сервера. Нажмите на кнопку
Logs слева, чтобы открыть лог сервера. Вы должны увидеть, что он устанавливает Socket.io со всеми её зависимостями. Именно здесь нужно искать все ошибки и выводимые данные серверного кода.
Теперь перейдём в
server.js. Именно здесь находится наш серверный код. Пока здесь есть только некий базовый boilerplate-код для обслуживания нашего HTML. Добавим в верхнюю часть файла строку, чтобы включить Socket.io:
var io = require('socket.io')(http); // вставьте это после определения http
Теперь нам также нужно включить Socket.io в клиенте, так что давайте вернёмся к
index.html и добавим внутрь тега
<head> такие строки:
<!-- Загрузка сетевой библиотеки Socket.io -->
<script src="/socket.io/socket.io.js"></script>
Примечание: Socket.io автоматически обрабатывает подгрузку клиентской библиотеки по этому пути, поэтому эта строка работает, даже если в ваших папках нет каталога /socket.io/.
Теперь Socket.io включена в проект и готова к работе!
2. Распознавание и спаунинг игроков
Нашим первым реальным шагом будет принятие соединений на сервере и создание новых игроков в клиенте.
Принятие соединений на сервере
Добавьте этот код в нижнюю часть
server.js:
// Приказываем Socket.io начать принимать соединения
io.on('connection', function(socket){
console.log("New client has connected with id:",socket.id);
})
Так мы просим Socket.io слушать все события
connection, которые автоматически происходят при подключении клиента. Библиотека создаёт новый объект
socket для каждого клиента, где
socket.id — это уникальный идентификатор этого клиента.
Чтобы проверить, что это работает, вернитесь в клиент (index.html) и добавьте куда-нибудь в функцию create эту строку:
var socket = io(); // Это запустит событие 'connection' на сервере
Если запустить игру и посмотреть на лог сервера (нажмите на кнопку
Logs), то вы увидите, что сервер зарегистрировал это событие соединения!
Теперь при подключении нового игрока мы ожидаем, что он передаст нам информацию о своём состоянии. В нашем случае нам необходимо знать по крайней мере x, y и angle, чтобы правильно создать его в нужной точке.
Событие connection было встроенным событием, запускаемым Socket.io. Мы можем слушать любые самостоятельно задаваемые события. Я назову своё событие new-player, и буду ожидать, что клиент отправит его, как только он подключится с информацией о своём положении. Это будет выглядеть так:
// Приказываем Socket.io начать принимать соединения
io.on('connection', function(socket){
console.log("New client has connected with id:",socket.id);
socket.on('new-player',function(state_data){ // Слушаем событие new-player в этом клиенте
console.log("New player has state:",state_data);
})
})
Если запустить этот код, то пока в логе сервера вы ничего не увидите, потому что мы пока не сказали клиенту сгенерировать это событие
new-player. Но давайте на минуту притворимся, что мы уже это сделали, и продолжим работу на сервере. Что должно произойти после получения местоположения нового присоединившегося игрока?
Мы можем отправить сообщение всем остальным подключённым игрокам, чтобы они знали, что появился новый игрок. В Socket.io есть для этого удобная функция:
socket.broadcast.emit('create-player',state_data);
При вызове
socket.emit сообщение просто передаётся этому одному клиенту. При вызове
socket.broadcast.emit оно отправляется каждому клиенту, подключенному к серверу, за исключением того, на чьём сокете была вызвана эта функция.
Функция io.emit отправляет сообщение каждому подключенному к серверу клиенту без всяких исключений. В нашей схеме нам это не нужно, потому что если мы получим от сервера сообщение с запросом создания своего собственного корабля, то у нас получится дубликат спрайта, потому что мы уже создали собственный корабль при запуске игры. Вот удобная подсказка по различным видам функций работы с сообщениями, которые мы будем использовать в этому туториале.
Серверный код теперь должен выглядеть вот так:
// Приказываем Socket.io начать принимать соединения
io.on('connection', function(socket){
console.log("New client has connected with id:",socket.id);
socket.on('new-player',function(state_data){ // Слушаем событие new-player в этом клиенте
console.log("New player has state:",state_data);
socket.broadcast.emit('create-player',state_data);
})
})
То есть каждый раз, когда игрок подключается, мы ожидаем, что он отправит нам сообщение с данными о своём местоположении, а мы отправляем эти данные всем остальным игрокам, чтобы они могли создать его спрайт.
Спаунинг в клиенте
Теперь, чтобы завершить этот цикл, нам нужно выполнять в клиенте два действия:
- Сгенерировать сообщение с данными нашего местоположения после соединения.
- Слушать события
create-player и создавать игрока в этой точке.
Для выполнения первого действия после создания игрока в функции
create (примерно в строке 135), мы можем сгенерировать сообщение, содержащее данные о местоположении, которые нам нужно отправить:
socket.emit('new-player',{x:player.sprite.x,y:player.sprite.y,angle:player.sprite.rotation})
Нам не нужно беспокоиться о сериализации отправляемых данных. Можно передавать их в любом типе объекта, а Socket.io сама обработает его за нас.
Прежде чем двигаться дальше, протестируем работу кода. Мы должны увидеть в логах сервера подобное сообщение:
New player has state: { x: 728.8180247836519, y: 261.9979387913289, angle: 0 }
Теперь мы знаем, что наш сервер получает оповещение о подключении нового игрока и правильно считывает данные о его местоположении!
Далее мы хотим слушать запросы на создание нового игрока. Мы можем разместить этот код сразу после генерирования сообщения, он должен выглядеть так:
socket.on('create-player',function(state){
// CreateShip - это функция создания и возврата спрайта, которую я определил ранее
CreateShip(1,state.x,state.y,state.angle)
})
Теперь
протестируйте код. Откройте два окна с игрой и убедитесь, что он работает.
Вы должны увидеть, что после открытия двух клиентов у первого клиента два созданных корабля, а у второго — всего один.
Задача: сможете разобраться, почему так получилось? Или как вы можете это исправить? Пошагово пройдите по написанной нами логике клиента/сервера и попробуйте отладить её.
Надеюсь, вы попробовали разобраться самостоятельно! Происходит следующее: когда первый игрок подключается, сервер отправляет событие
create-player всем остальным игрокам, но пока ещё нет игроков, которые могут его получить. После подключения второго игрока сервер снова отправляет свои сообщения, и первый игрок получает его и корректно создаёт спрайт, в то время как второй игрок пропустил сообщение первого игрока.
То есть проблема заключается в том, что второй игрок подключается к игре позже и ему нужно знать состояние игры. Мы должны сообщить всем новым подключающимся игрокам, что игроки уже существуют (а также о других событиях, произошедших в мире), чтобы они смогли сориентироваться. Прежде чем мы перейдём к решению этой задачи, у меня есть краткое предупреждение.
Предупреждение о синхронизации состояния игры
Существует два подхода к реализации синхронизации всех игроков. Первый заключается в отправке по сети минимального количества информации о произошедших изменениях. То есть при каждом подключении нового игрока мы будем отправлять всем другим игрокам только информацию об этом новом игроке (а этому новому игроку отправлять список всех остальных игроков в мире), а после его отключения мы сообщаем всем игрокам, что отключился этот конкретный игрок.
Второй подход заключается в передаче всего состояния игры. В этом случае мы просто при каждом подключении или отключении отправляем всем полный список всех игроков.
Первый подход лучше тем, что он минимизирует объём передаваемых по сети информации, но реализовать его бывает очень сложно, и он имеет вероятность рассинхронизации игроков. Второй гарантирует, что игроки всегда будут синхронизированы, но в каждом сообщении придётся отправлять больше данных.
В нашем случае, вместо того, чтобы пытаться отправлять сообщения при подключении игрока для его создания и при отключении для его удаления, а также при перемещении для обновления его позиции, мы можем объединить всё это в одно общее событие update. Это событие обновления всегда будет отправлять позиции каждого игрока всем клиентам. Именно этим и должен заниматься сервер. Задача клиента — поддерживать соответствие мира получаемому состоянию.
Для реализации такой схемы я сделаю следующее:
- Буду хранить словарь игроков, ключом которого будет их ID, а значением — данные об их местоположении.
- Добавлять игрока в этот словарь при его подключении и отправлять событие update.
- Удалять игрока из этого словаря при его отключении и отправлять событие update.
Можете попробовать реализовать эту систему самостоятельно, потому что эти действия довольно просты (здесь может пригодиться
моя подсказка по функциям). Вот, как может выглядеть полная реализация:
// Приказываем Socket.io начать принимать соединения
// 1 - Сохраняем словарь всех игроков как ключ/значение
var players = {};
io.on('connection', function(socket){
console.log("New client has connected with id:",socket.id);
socket.on('new-player',function(state_data){ // Слушаем событие new-player в этом клиенте
console.log("New player has state:",state_data);
// 2 - Добавляем в словарь нового игрока
players[socket.id] = state_data;
// Отправляем событие обновления
io.emit('update-players',players);
})
socket.on('disconnect',function(){
// 3- Удаляем игрока из словаря при отключении
delete players[socket.id];
// Отправляем событие обновления
})
})
Сторона клиента чуть сложнее. С одной стороны, теперь нам стоит заботиться только о событии
update-players, но с другой стороны, нам следует учитывать создание новых кораблей, если сервер отправляет больше кораблей, чем мы знаем, или удаление, если их слишком много.
Вот как я обрабатываю это событие в клиенте:
// Слушаем подключение других игроков
// ПРИМЕЧАНИЕ: где-то в другом месте у вас должно быть определено other_players = {}
socket.on('update-players',function(players_data){
var players_found = {};
// Обходим в цикле все полученные данные игроков
for(var id in players_data){
// Если игрок ещё не создан
if(other_players[id] == undefined && id != socket.id){ // Проверяем, чтобы не создать самого себя
var data = players_data[id];
var p = CreateShip(1,data.x,data.y,data.angle);
other_players[id] = p;
console.log("Created new player at (" + data.x + ", " + data.y + ")");
}
players_found[id] = true;
// Обновляем позиции других игроков
if(id != socket.id){
other_players[id].x = players_data[id].x; // Обновляем целевую, а не текущую позицию, чтобы можно было её интерполировать
other_players[id].y = players_data[id].y;
other_players[id].rotation = players_data[id].angle;
}
}
// Проверяем отсутствие игрока и удаляем его
for(var id in other_players){
if(!players_found[id]){
other_players[id].destroy();
delete other_players[id];
}
}
})
На стороне клиента я храню корабли в словаре
other_players, который я просто определил в верхней части скрипта (здесь она не показана). Поскольку сервер отправляет данные игроков всем игрокам, я должен добавить проверку, чтобы клиент не создавал лишний спрайт для себя. (Если у вас появились проблемы со структурированием, то вот
полный код, который должен быть в index.html на текущий момент).
Теперь протестируем код. Вы должны иметь возможность создать несколько клиентов и увидеть правильное количество кораблей, созданных в правильных позициях!
3. Синхронизация позиций кораблей
Здесь начинается очень интересная часть. Мы хотим синхронизировать позиции кораблей на всех клиентах. В этом проявится простота той структуры, которую мы создали на текущий момент. У нас уже есть событие обновления, которое может синхронизировать местоположения всех кораблей. Нам достаточно сделать следующее:
- Заставить клиент генерировать сообщение каждый раз, когда он перемещается в новую позицию.
- Научить сервер слушать это сообщение о перемещении и обновлять элемент с данными игрока в словаре
players.
- Генерировать событие обновления для всех клиентов.
И этого должно быть достаточно! Теперь ваша очередь попробовать реализовать это самостоятельно.
Если вы совершенно запутаетесь и вам нужна будет подсказка, то посмотрите на готовый проект.
Примечание о минимизации передаваемых по сети данных
Наиболее прямолинейный способ реализации — обновлять позиции всех игроков каждый раз при получении события перемещения от
любого игрока. Замечательно, если игроки всегда получают последнюю информацию сразу же после её появления, но количество передаваемых по сети сообщений легко может вырасти до сотен на кадр. Представьте, что у вас есть 10 игроков, каждый из которых отправлять в каждом кадре сообщение о перемещении. Сервер должен передавать их обратно всем 10 игрокам. Это уже 100 сообщений на кадр!
Лучше будет сделать так: подождать, пока сервер не получит все сообщения от всех игроков, а потом отправить всем игрокам большое обновление, содержащее всю информацию. Таким образом мы ужмём количество передаваемых сообщений до количества присутствующих в игре пользователей (вместо квадрата этого числа). Проблема здесь в том, что все пользователи буду ощущать ту же задержку, что и игрок с самым медленным подключением.
Ещё один способ решения заключается в отправке сервером обновлений с постоянной частотой, вне зависимости от количества полученных от игрока сообщений. Распространённым стандартом является обновление сервера примерно 30 раз в секунду.
Однако при выборе структуры своего сервера вам следует оценивать количество передаваемых в каждом кадре сообщений ещё на ранних этапах разработки игры.
4. Синхронизация снарядов
Мы почти закончили! Последняя серьёзная часть заключается в синхронизации по сети снарядов. Мы можем реализовать её так же, как синхронизировали игроков:
- Каждый клиент отправляет позиции всех своих снарядов в каждом кадре.
- Сервер перенаправляет их каждому игроку.
Но тут есть проблема.
Защита от читерства
Если вы будете перенаправлять всё, что клиент передаёт как истинные позиции снарядов, то игрок сможет с лёгкостью жульничать, модифицировав свой клиент и передавая вам фальшивые данные, например, снаряды, телепортирующиеся к позициям кораблей. Вы можете сами легко это проверить, скачав веб-страницу, изменив код на JavaScript и открыв её снова. И это проблема не только для браузерных игр. В общем случае мы никогда не может доверять данным, поступающим от пользователя.
Чтобы частично справиться с этой проблемой, мы попробуем использовать другую схему:
- Клиент генерирует сообщение о выстреленном снаряде с его позицией и направлением.
- Сервер симулирует движение снарядов.
- Сервер обновляет данные каждого клиента, передавая позицию всех снарядов.
- Клиенты рендерят снаряды в позициях, полученных от сервера.
Таким образом, клиент несёт ответственность за позицию создания снаряда, но не за его скорость и не за его дальнейшее движение. Клиент может менять позиции снарядов для самого себя, но это не изменит то, что видят другие клиенты.
Для реализации такой схемы мы добавим генерирование сообщения при выстреле. Я больше не буду создавать сам спрайт, потому что его существование и местоположение целиком будут определяться сервером. Теперь наш новый выстрел снарядом в index.html будет выглядеть так:
// Выстрел снарядом
if(game.input.activePointer.leftButton.isDown && !this.shot){
var speed_x = Math.cos(this.sprite.rotation + Math.PI/2) * 20;
var speed_y = Math.sin(this.sprite.rotation + Math.PI/2) * 20;
/* Сервер теперь симулирует снаряды, а клиенты всего лишь рендерят позиции снарядов, поэтому это нам больше не нужно
var bullet = {};
bullet.speed_x = speed_x;
bullet.speed_y = speed_y;
bullet.sprite = game.add.sprite(this.sprite.x + bullet.speed_x,this.sprite.y + bullet.speed_y,'bullet');
bullet_array.push(bullet);
*/
this.shot = true;
// Сообщаем серверу, что мы выстрелили снарядом
socket.emit('shoot-bullet',{x:this.sprite.x,y:this.sprite.y,angle:this.sprite.rotation,speed_x:speed_x,speed_y:speed_y})
}
Также теперь мы можем закомментировать весь фрагмент кода, обновляющий снаряды в клиенте:
/* Мы обновляем снаряды на сервере, поэтому в клиенте нам это больше не нужно
// Обновление снарядов
for(var i=0;i<bullet_array.length;i++){
var bullet = bullet_array[i];
bullet.sprite.x += bullet.speed_x;
bullet.sprite.y += bullet.speed_y;
// Удаляем снаряд, если он слишком далеко от экрана
if(bullet.sprite.x < -10 || bullet.sprite.x > WORLD_SIZE.w || bullet.sprite.y < -10 || bullet.sprite.y > WORLD_SIZE.h){
bullet.sprite.destroy();
bullet_array.splice(i,1);
i--;
}
}
*/
Наконец, нам нужно заставить клиент слушать обновления снарядов. Я решил реализовать это так же, как и с игроками, то есть сервер просто отправляет массив всех позиций снарядов в событии под названием
bullets-update, а клиент для поддержания синхронизации создаёт или уничтожает снаряды. Вот, как это выглядит:
// Слушаем события обновления снарядов
socket.on('bullets-update',function(server_bullet_array){
// Если в клиенте недостаточно снарядов, создаём их
for(var i=0;i<server_bullet_array.length;i++){
if(bullet_array[i] == undefined){
bullet_array[i] = game.add.sprite(server_bullet_array[i].x,server_bullet_array[i].y,'bullet');
} else {
// В противном случае просто их обновляем!
bullet_array[i].x = server_bullet_array[i].x;
bullet_array[i].y = server_bullet_array[i].y;
}
}
// Если их слишком много, удаляем лишние
for(var i=server_bullet_array.length;i<bullet_array.length;i++){
bullet_array[i].destroy();
bullet_array.splice(i,1);
i--;
}
})
И это всё, что должно быть в клиенте. Я буду предполагать, что вы уже знаете, куда вставлять эти фрагменты кода и как всё это соединить, но если у вас возникли проблемы, то можете всегда вглянуть на
готовый результат.
Теперь в server.js нам нужно отслеживать и симулировать снаряды. Сначала мы создадим массив для отслеживания снарядов, аналогично массиву для игроков:
var bullet_array = []; // Отслеживает все снаряды для обновления их на сервере
Далее мы слушаем событие выстрела снаряда:
// Слушаем события shoot-bullet и добавляем их в наш массив снарядов
socket.on('shoot-bullet',function(data){
if(players[socket.id] == undefined) return;
var new_bullet = data;
data.owner_id = socket.id; // Добавляем к снаряду id игрока
bullet_array.push(new_bullet);
});
Теперь мы симулируем снаряды 60 раз в секунду:
// Обновляем снаряды 60 раз в секунду и отправляем обновления
function ServerGameLoop(){
for(var i=0;i<bullet_array.length;i++){
var bullet = bullet_array[i];
bullet.x += bullet.speed_x;
bullet.y += bullet.speed_y;
// Удаляем, если снаряд слишком далеко от экрана
if(bullet.x < -10 || bullet.x > 1000 || bullet.y < -10 || bullet.y > 1000){
bullet_array.splice(i,1);
i--;
}
}
}
setInterval(ServerGameLoop, 16);
И последний шаг — это отправка события обновления где-нибудь внутри этой функции (но совершенно точно вне цикла for):
// Сообщаем всем, где находятся все снаряды, передавая целый массив
io.emit("bullets-update",bullet_array);
Теперь мы наконец можем протестировать игру! Если всё получилось правильно, то вы должны увидеть, что снаряды правильно синхронизируются на всех клиентах. То, что мы реализовали это на сервере, заставило нас проделать больше работы, зато дало нам гораздо больше контроля. Например, когда мы получаем событие выстрела снарядом, мы можем проверить, находится ли скорость снаряда в пределах определённого интервала, и если это не так, то будем знать, что этот игрок жульничает.
5. Столкновение со снарядами
Это последняя базовая механика, которую мы реализуем. Надеюсь, вы уже привыкли к процедуре планирования своей реализации, сначала целиком завершая реализацию клиента, а затем переходя к серверу (или наоборот). Такой способ гораздо менее подвержен ошибкам, чем перескакивание при реализации туда и обратно.
Проверка коллизий — критически важная игровая механика, поэтому мы хотим, чтобы она была защищена от читерства. Мы реализуем её на сервере аналогично тому, что проделали со снарядами. Нам нужно следующее:
- Проверить, достаточно ли близко снаряд к какому-нибудь игроку на сервере.
- Сгенерировать событие для всех клиентов, когда в какого-то игрока попадает снаряд.
- Научить клиент слушать событие попадания и заставлять корабль мигать при попадании.
Можете попробовать реализовать эту часть самостоятельно. Чтобы заставить корабль игрока мерцать при попадании, просто задайте его альфа-каналу значение 0:
player.sprite.alpha = 0;
И он будет плавно возвращаться к полной непрозрачности (это выполняется в обновлении игрока). Для других игроков действие будет похожим, но вам придётся возвращать его альфа-канал к единице в функции обновления чем-то подобным:
for(var id in other_players){
if(other_players[id].alpha < 1){
other_players[id].alpha += (1 - other_players[id].alpha) * 0.16;
} else {
other_players[id].alpha = 1;
}
}
Единственная сложная часть может заключаться в проверке того, чтобы в игрока не попадали собственные снаряды (в противном случае он каждый раз будет получать урон при стрельбе).
Заметьте, что в этой схеме даже если клиент пытается сжульничать и отказывается от принятия передаваемого ему сервером сообщения о попадании, это изменит только то, что он видит на собственном экране. Все другие игроки всё равно увидят, что в игрока попали.
6. Сглаживание движения
Если вы выполнили все шаги до этого момента, то могу вас поздравить. Вы только что создали работающую многопользовательскую игру! Отправьте ссылку другу и посмотрите, как волшебство онлайн-мультиплеера может объединять игроков!
Игра полностью функциональна, но наша работа на этом не заканчивается. Есть пара проблем, способных негативно сказаться на игровом процессе, и мы должны с ними справиться:
- Если не у всех есть быстрое подключение, то движение других игроков выглядит очень дёрганым.
- Снаряды кажутся тормозными, потому что выстреливаются не сразу. Прежде чем появиться на экране клиента, они ждут обратного сообщения от сервера.
Мы можем решить первую проблему интерполированием наших данных позиций кораблей в клиенте. Поэтому если мы недостаточно быстро получаем обновления, то можем плавно перемещать корабль к тому месту, где он должен быть, а не просто телепортировать его туда.
Снаряды требуют более сложного решения. Мы хотим, чтобы для защиты от читерства сервер обрабатывал снаряды, но также нам нужна мгновенная реакция: выстрел и летящий снаряд. Лучший способ решения — это гибридный подход. И сервер, и клиент могут симулировать снаряды, а сервер по-прежнему будет отправлять обновления позиций снарядов. Если они рассинхронизуются, то мы предполагаем, что прав сервер, и переопределяем позицию снаряда в клиенте.
Мы не будем реализовывать эту систему снарядов в этом туториале, но вам неплохо знать о существовании такого метода.
Выполнять простые интерполяции позиций кораблей очень просто. Вместо задания позиции непосредственно в событии update, где мы впервые получаем новые данные позиций, мы просто сохраняем целевую позицию:
// Обновляем позиции у игроков
if(id != socket.id){
other_players[id].target_x = players_data[id].x; // Присваиваем целевую, а не настоящую позицию, чтобы можно было интерполировать
other_players[id].target_y = players_data[id].y;
other_players[id].target_rotation = players_data[id].angle;
}
Затем в функции update (тоже на стороне клиента) мы обходим в цикле всех остальных игроков и толкаем их по направлению к их цели:
// Интерполируем всех игроков к позиции, в которой они должны быть
for(var id in other_players){
var p = other_players[id];
if(p.target_x != undefined){
p.x += (p.target_x - p.x) * 0.16;
p.y += (p.target_y - p.y) * 0.16;
// Интерполируем угол, избегая проблему с положительными/отрицательными значениями
var angle = p.target_rotation;
var dir = (angle - p.rotation) / (Math.PI * 2);
dir -= Math.round(dir);
dir = dir * Math.PI * 2;
p.rotation += dir * 0.16;
}
}
Таким образом, сервер отправляет нам обновления по 30 раз в секунду, но мы всё равно можем играть с частотой 60 fps и игра по-прежнему выглядит плавной!
Заключение
Мы рассмотрели множество вопросов. Перечислим их: мы узнали, как передавать сообщения между клиентом и сервером, как синхронизировать состояние игры, транслируя его с сервера на всех игроков. Это самый простейший способ реализации многопользовательской онлайн-игры.
Также мы узнали, как защитить игру от читерства, симулируя её важные части на сервере и сообщая клиентам о результатах. Чем меньше вы доверяете клиенту, тем безопаснее будет игра.
Наконец, мы узнали, как преодолеть задержки с помощью интерполяции в клиенте. Компенсация задержек — это серьёзная тема и она очень важна (некоторые игры при достаточно большой задержке становятся просто неиграбельными). Интерполяция в процессе ожидания следующего обновления с сервера — это всего лишь один из способов уменьшения проблемы. Ещё один заключается в прогнозировании следующих нескольких кадров заранее, и их коррекция при получении настоящих данных с сервера, но, разумеется, такой подход может быть очень сложным.
Совершенно другой способ снижения влияния задержек — сделать так, чтобы дизайн системы обходил эту проблему. Преимущество медленных поворотов кораблей заключается и в том, что это уникальная механика движения, и в том, что это способ предотвращения резких изменений перемещения. Поэтому даже при медленном подключении они всё равно не разрушат игровой процесс. Очень важно учитывать задержку при разработке базовых элементов игры. Иногда наилучшие решения заключаются вовсе не в технических трюках.
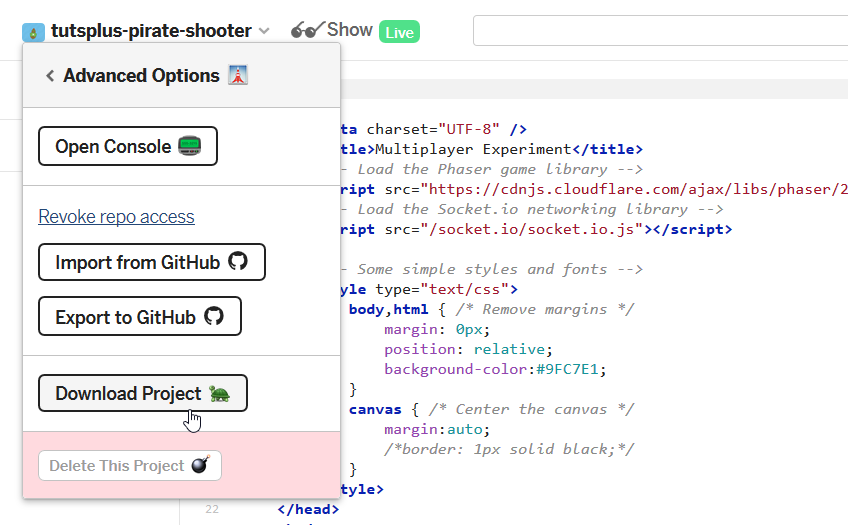
Вы можете воспользоваться ещё одной полезной функцией Glitch, которая заключается в возможности скачивания или экспорта собственного проекта через расширенные параметры (Advanced Options) в левом верхнем углу:
Let's block ads! (Why?)





 27 июля 2018 года компания Opera Ltd., разработчик одноимённого браузера,
27 июля 2018 года компания Opera Ltd., разработчик одноимённого браузера,