Недавно мне попалось к просмотру это видео, стало интересно как это возможно и выяснил что автор видео разогнал частоту I2S до телевизионного диапазона, а затем с помощью DMA генерировал AM сигнал. Мне захотелось повторить это, но или прошивка криво собирается, или ESP модуль оказался неподходящий. Запустить передачу телесигнала не получалось.
Затем я вспомнил что STM32 умеет выводить свой тактовый сигнал на один из пинов.
Введение
Современные микроконтроллеры могут работать на частотах в сотни МГц, они попадают в диапазон работы FM приемников и аналоговых телевизоров. Практически все они имеют возможность вывода своей тактовой частоты на один из пинов. В микроконтроллерах STM32 эта функция называется Master Clock Output.
Если выбрать источником тактирования PLL, частоту на выходе можно менять в широких пределах. Так-же выход MCO можно включить и выключить простым переключением режима пина в регистре GPIO. Это побудило меня к экспериментам над возможностями формирования радиосигналов с помощью микроконтроллера.
В наличии была отладочная плата с микроконтроллером STM32F407. Его максимальная частота ядра равна 168МГц, а максимальная частота переключения GPIO равна 84мгц.
Для начала нужно было понять на какую частоту настраивать MCO чтобы его мог поймать телевизор. Поиск привел меня на страницу с таблицей частот всех тв каналов. Наибольшую частоту ядра без превышения максимальной частоты переключения GPIO можно достичь выбрав 3 канал.
Частота ядра при этом будет равна 154.5МГц, а тактовый выход необходимо поделить на 2, чтобы получить искомые 77.25МГц.
Начало экспериментов
Чтобы долго не изучать мануалы, для генерации инициализационного кода был использован cubeMX. В нем настроил PLL на частоту 154.5МГц, вывод MCO1 сделал с источником от PLL предделителем на 2. К выводу PA8 подсоединил кусок провода.
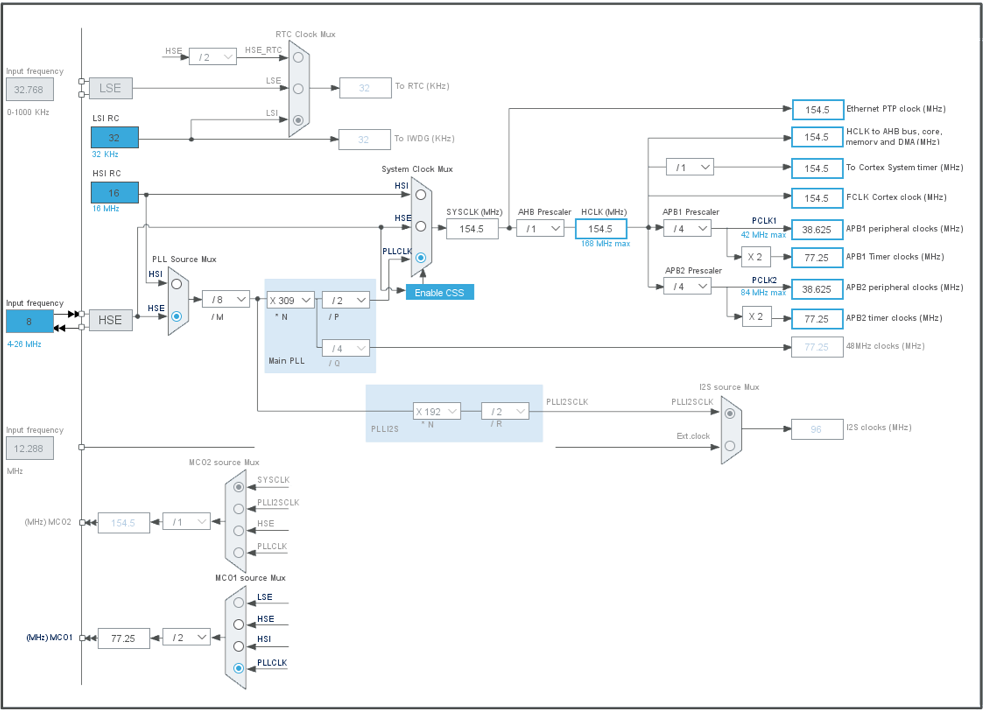
Скомпилировал проект, залил прошивку в плату и экран на телевизоре стал темным. Это означает что телевизор понимает импровизированную несущую как сигнал.
Дальше было определение насколько быстро можно включать/выключать тактовый сигнал чтобы создать подобие амплитудной модуляции. В бесконечном цикле включая и выключая тактирование с плавным уменьшением задержек удалось получить сначала горизонтальные, а затем и вертикальные полосы на кинескопе.


Но как вывести на него изображение?
Использование DMA
Если осуществлять управление с помощью ядра, практически всё его время будет использовано только для переключения тактового сигнала и любое прерывание будет сбивать тайминги. Поэтому единственным способом управления осталось использовние DMA с буфером.
Чтобы не тратить ресурсы ядра на запуск DMA каждый кадр, последнее можно настроить на работу в кольцевом режиме. Для того чтобы данные переносились со строго заданной скоростью, запуск передачи нужно осуществлять по событию от таймера.
В cubeMX это выглядит так:
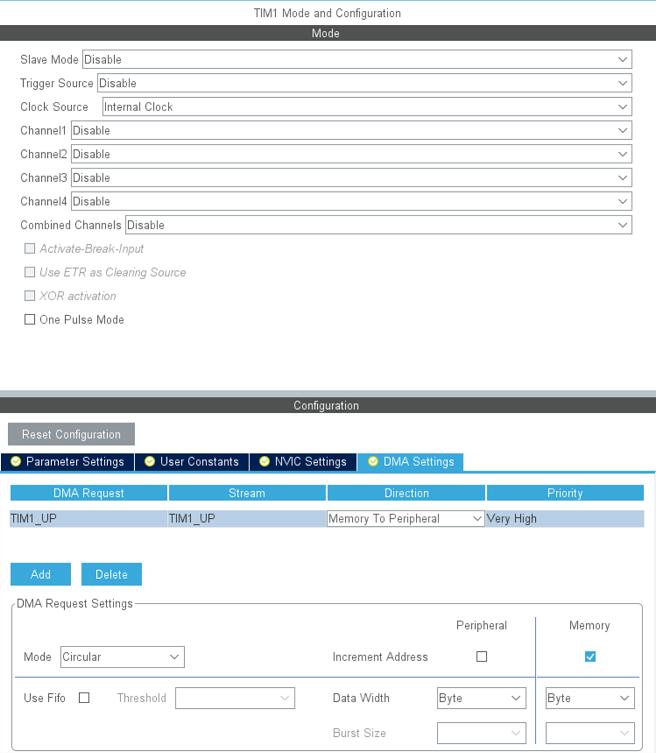
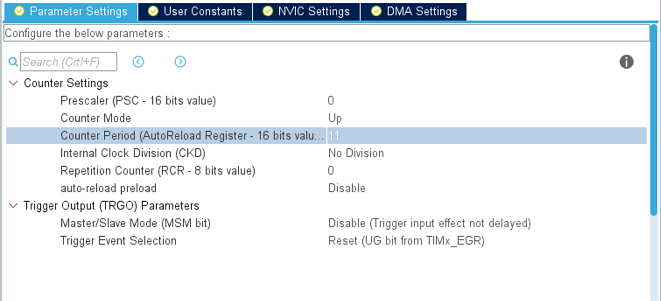
В ходе эксперимента выяснилось что к регистрам GPIO возможен и побайтовый доступ как самим ядром, так и через DMA, что позволило тратить всего 1 байт на пиксель:
#define GPIOA_MODER_8_11 (((uint8_t*)(&(GPIOA->MODER)))[2])
#define MCO_ON() (GPIOA_MODER_8_11) = 2
#define MCO_OFF() (GPIOA_MODER_8_11) = 0В начальной поставке библиотеки HAL, адресом назначения DMA является регистр таймера ARR. Пришлось написать функцию, позволяющую задать произвольный адрес назначения. Этим адресом является биты [16:23] регистра GPIOA->MODER.
Так-как DMA имеет 16 битный счетчик элементов, размер буфера ограничен в 64кб. Но можно настроить DMA на работу с двойным буфером, что позволяет увеличить количество элементов в 2 раза.
// Изначальная функция, которая принимает в качестве аргумента лишь источник данных, а назначением является регистр TIM->ARR (регистр предзагрузки)
// HAL_StatusTypeDef HAL_TIM_Base_Start_DMA(TIM_HandleTypeDef *htim, uint32_t *pData, uint16_t Length);
// Добавлен аргумент - адрес назначения данных
HAL_StatusTypeDef HAL_TIM_Base_Start_DMA(TIM_HandleTypeDef *htim, uint32_t *pData, uint32_t *pDest, uint16_t Length);
// Запуск в режиме двойного буфера
HAL_StatusTypeDef HAL_TIM_Base_Start_DMA_DoubleBuffer(TIM_HandleTypeDef *htim, uint32_t *pData, uint32_t *pData2, uint32_t *pDest, uint16_t Length);
Формирование кадра
В стандарте PAL/SECAM видеосигнал имеет частоту кадров равную 25гц и 625 строк на кадр. В случае отказа от черезстрочной развертки остается 312 строк изображения с частотой полей 50гц. При максимальном размере буфера в 128кб получится: 131072/312 = 420 «пикселей» на строку.
Значит фреймбуфер получится размером 312x410.
Чтобы телевизор понял где находится начало кадра и начало каждой строки, необходимо формировать синхроимпульсы. Поскольку в эфире сигнал передается с негативной полярностью, эти импульсы будут соответствовать максимальной амплитуде сигнала. Поскольку управление сигнала возможно лишь дискретно, для создания уровня черного используется ШИМ.
Перед запуском передачи происходит заполнение фреймбуфера синхроимпульсами, а уровень черного обеспечивается заполнением ШИМ в 25%.
// заполнение синхроимпульсами
void init_fb()
{
// кадровый синхроимпульс находится в начале буфера,
// чтобы прерывание конца передачи DMA (Vsync) приходилось
// на начало обратного хода луча
for (int i=0;i<24;i++)
for (int j=0;j<(WIDTH);j++)
frameBuf[i][j] = 2;
// строчный синхроимпульс
for (int i=0;i<312;i++)
for (int j=(WIDTH - 30);j<(WIDTH);j++)
frameBuf[i][j] = 2;
}
// приведение буфера кадра к уровню черного
void clear_fb()
{
for (int i=24;i<312;i++)
{
// смещение начала строки
int offset = (i * WIDTH);
// ядро cortex-m4 позволяет работать с невыровненными данными,
// 32 битный доступ позволяет ускорить работу
uint32_t* data_ptr = (uint32_t*)(&((uint8_t*)(frameBuf))[offset]);
// диагональные линии менее заметны на экране чем вертикальные
uint32_t pattern = 0x02020202;
pattern &= ~( 2 << (((i)%4)*8) );
for (int j=0;j<(390);j+=4)
{
*(data_ptr++) = pattern;
}
}
}
На этом этапе записью значений в frameBuf можно формировать изображение на экране телевизора.
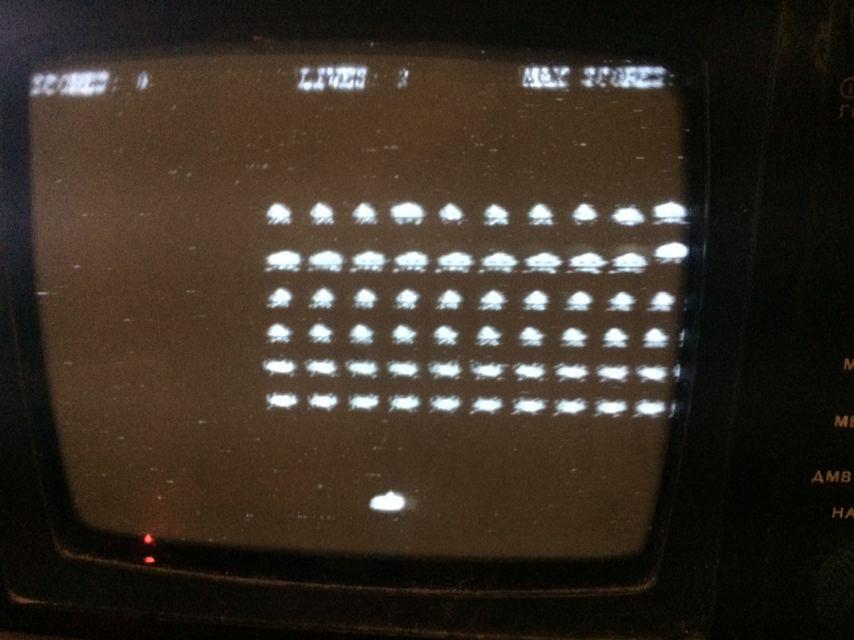
Графическая библиотека была портирована из демо проекта от другой платы discovery. С ее помощью можно генерировать различные графические примитивы и символы. Так-же был портирован когда-то мной написанный клон игры Space Invaders и 3D шары из проекта от ESP8266.
Результат получился следующий:
По фотографиям экрана видны диагональные полосы, полученные в результате формирования «уровня черного».
Эксперименты с созданием промежуточных уровней сигнала
Что если управлять тактовым выходом не просто включая и выключая его, а менять значение регистра OSPEEDR? Этим регистром управляется крутизна фронта переключения вывода. Было интересно, возможно ли меняя его значение создать на экране телевизора больше чем 2 градации яркости.
Написал код, который в бесконечном цикле перебирает 5 вариантов:
MCO выключен через MODER
OSPEEDR = 0
OSPEEDR = 1
OSPEEDR = 2
OSPEEDR = 3
На экране появилось 4 полосы с разной яркостью. Состояние с минимальной крутизной фронтов и выключенным совсем MCO никак не отличается для телевизора.

Использование регистра OSPEED вместо MODER позволило увеличить четкость изображения.
Так-же пытался использовать I2S, но безуспешно.
Выше примерно скорости 20 Мбит/с при дальнейшем увеличении частоты тактирования интерфейса, появляется нестабильность в работе. А на «стабильных» частотах если принимать гармоники сигнала, изображение едва отличимо от шума. SPI1 может работать на частотах выше, но качество сигнала тоже остается плохим.
Видео демонстрации работы прилагаю, код на гитхабе
github.com/rus084/F4Discovery-tv-transmitter
Как насчет частотной модуляции?
В STM32 в регистре RCC_CR есть биты HSITRIM, отвечающие за подстройку частоты HSI генератора.
Если настроить PLL со входом от HSI и выходной частотой, попадающей в FM диапазон, можно получить радиосигнал, который будет приниматься FM приемником. Модуляция осуществляется изменением значения битов HSITRIM.
Доказательство работоспособности показано в этом видео. Исходники тоже прилагаются.
github.com/rus084/F4Discovery-fm-transmitter
p.s. Да, код ужасный, но как proof of concept сгодится



















 Первая селфи-фотография «Тяньвэнь-1» на расстоянии более 24 млн км от Земли.
Первая селфи-фотография «Тяньвэнь-1» на расстоянии более 24 млн км от Земли.









