На самом деле, это легкий технический лонгрид, надеемся, после прочтения у вас появится дополнительный интерес сделать какую-нибудь игру, или хотя бы вы узнаете, как это работает.

О спикере: Александр Хаёров (@allexx) руководит отделом разработки в компании Ingram Micro Cloud. Ребята в команде Александра считают себя не просто отличными инженерами, а называют себя великой командой voxel джедаями, мастерами оптимизации, гуру 3D и повелителями больших данных! [примечание: по аналогии с названиями должностей в LinkedIn и Medium]
Эта классная команда, готовясь к выступлению на Highload++ 2017, решила развлечь аудиторию и сделать что-то новое и интересное для стенда. Поэтому они запилили игру, о создании которой и пойдет дальше речь.
Хозяйке на заметку: со стороны организаторов, мы очень приветствуем усилия по подготовке к участию в конференции. Они многократно окупаются, привлекая участников, и, как выясняется, идут на пользу команде.
Итак, поехали!
Часто, разбирая почту, я просматриваю заголовки информационных лент, где мелькают самые разные новости. Однажды я увидел заголовок «Кто такие инди-разработчики». Почему-то он меня зацепил, и я решил почитать эту статью. Я открыл ее — там было очень много цифр, букв и статистики.
Справка: Инди-разработчики — это люди, которые творят игры без специального бюджета и без финансовой поддержки издателей компьютерных игр.
Как правило, инди-разработчики не обременены рамками сценария и шаблонами, поэтому у них получаются довольно интересные игры, фильмы и прочее.
В этой статье я узнал несколько забавных фактов:
- 97% мифических инди-разработчиков — это мужчины;
- 60% из них — нет, не одиночки, но делают игры в одиночку;
- В среднем, чтобы сделать инди-игру, требуется от 1 до 3 месяцев.

Так получилось, что мы тоже начали делать игру.
Почему мы начали делать игру
Мне всегда нравились игры от сервиса Reddit. Думаю, и вы не один месяц своей жизни провели на этом ресурсе.
A social experiment by Reddit
Каждый год Reddit проводит социальный эксперимент, как они это называют. Хотя на самом деле это различные игры для сообщества. В 2017 году социальный эксперимент проходил, как всегда, в начале апреля (на день дурака).

Суть игры была многообещающей. Разработчики Reddit создали картину из 1 000 х 1 000 пикселей. Каждому зарегистрированному пользователю на Reddit, а их несколько миллионов, предлагалось закрасить 1 пиксель этой канвы одним цветом из достаточно широкой палитры.
Мероприятие продолжалось 72 часа, и каждый участник раз в 5 минут мог нарисовать лишь одну точку на экране. Люди создавали разные картинки, боролись между собой, перекрашивая пиксели. Некоторые страны и сообщества объединялись и делали совместную работу.
В конечном итоге получилось интересное панно, из которого кто-то потом сделал пазл, кто-то связал носки с таким орнаментом и т.д.
Мне очень понравилась сама идея, что можно вовлекать людей в массовые онлайн игры, пускай и с простым гейм-плеем. Это, наверное, было главным вдохновением для нас создать именно онлайн-игру. Вообще я считаю, что игры полны веселья и уверен, что вы иногда играете в разные игры и это приносит вам удовольствие.
Но для технаря самое интересное находилось внутри, поскольку игра привлекла огромное количество людей — в ней участвовало более миллиона зарегистрированных уникальных пользователей — до 90 тысяч человек одновременно закрашивало пиксели ежесекундно!
Профессионально я занимаюсь разработкой web-сервисов и различных M2M-сервисов, когда сервер общается с серверами. Это на самом деле очень важно и ответственно, но порой немножко скучно. Поэтому новый девелоперский опыт всегда интересен. Я им с вами сейчас как раз поделюсь.
Забегая вперед, скажу, что мы действительно узнали очень много нового и интересного про игры, не имея при этом никакого опыта изначально.
The Game
Features
Мы с ребятами собрались и набросали скелет идеи, о чем можно сделать игру. Сначала мы решили идти с козырей и написать классные Features.
- Однозначно хотелось сделать мультиплеер.
Мы решили, что игра будет
сетевая, да еще и массовая, а не в формате разделения экрана.
Хотя сделать 2D без опыта было бы, вероятно, проще, команда захотела объема.
- Решили взять хайповую технологию — пусть это будет Виртуальная Реальность.
Мы понимали, что без переоценённой, передутой технологии невозможно сделать успешную игру.
Так у нас образовался Features set, но без определенного геймплея.
Concessions
Но, подумав примерно недельку, мы решили, что нужно как-то ограничить свои хотелки и пошли на небольшие компромиссы.
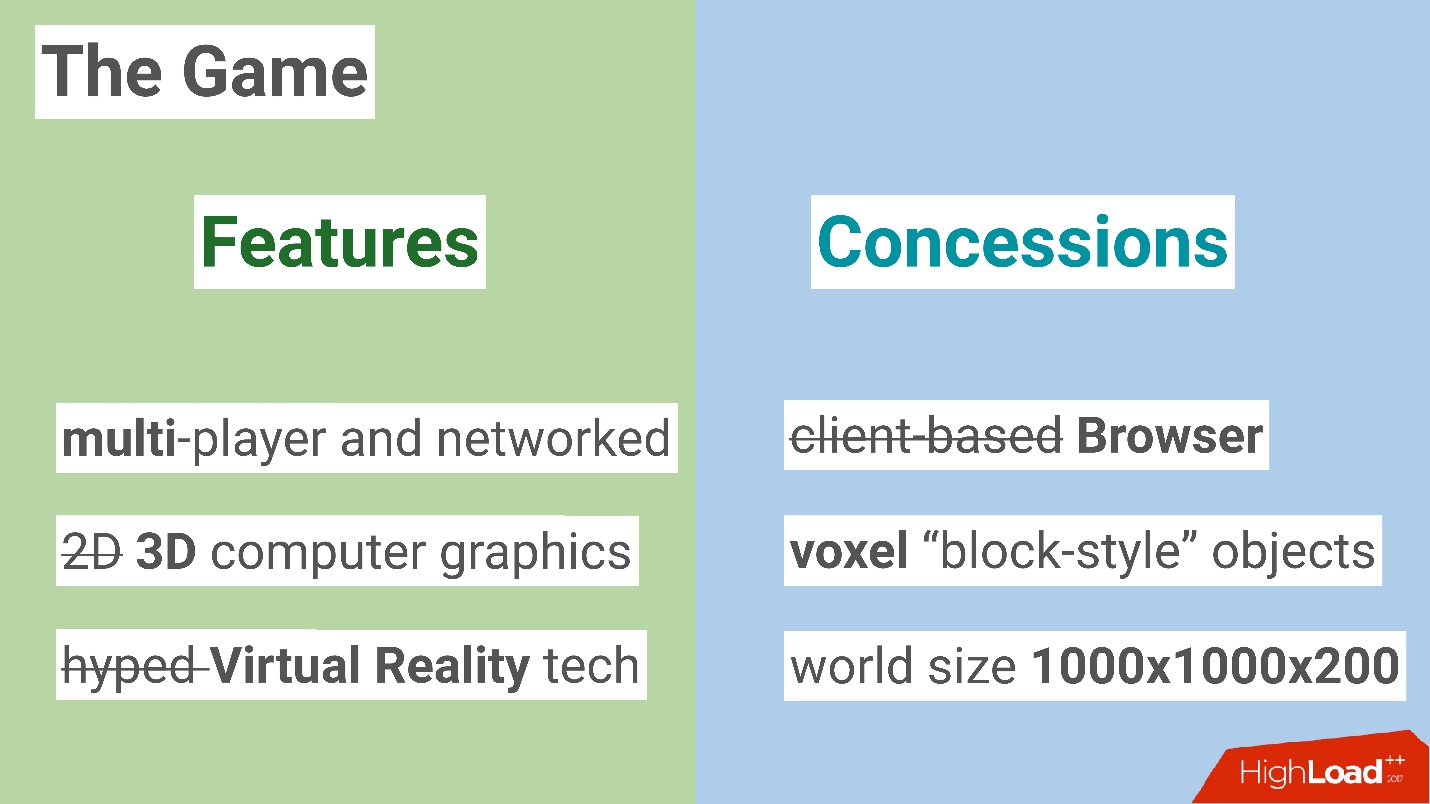
- Нам на самом деле не хотелось писать отдельного клиента, и мы решили, что игра будет браузерная, тем более что мы слышали, что современные браузеры стали очень мощными и позволяют делать 3D-графику.
- Вторым важным фактором было то, что мы, являясь инженерами, конечно же стремимся к прекрасному, но к графике имеем посредственное отношение. Поэтому идея использовать маленькие воксели или блоки для того, чтобы создавать весь мир и конструкцию, нам показалась некоей панацеей.
- Наконец, мы решили, что мир у нас не будет бесконечным (хотя я уверен, что вселенная бесконечна) и ограничились размерами 1000×1000×200 вокселей, тем самым немножко упростив для себя техническую особенность игры.
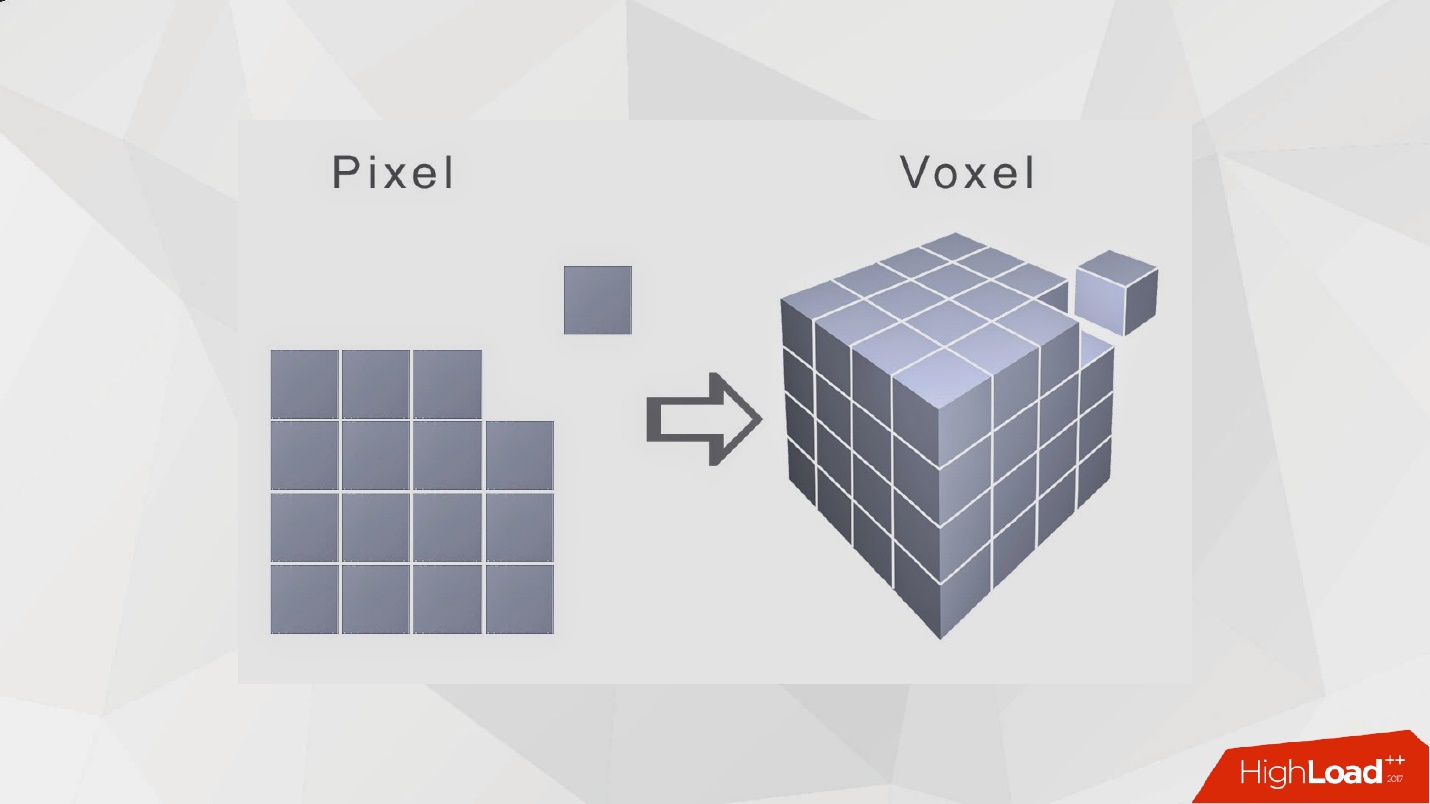
Справка: Воксель (Voxel) — это практически пиксель, но в 3-мерном мире. Например, в игре Minecraft мир представлен вокселями.
На этом мы разошлись на некоторое время и в дальнейшем решили разговаривать только по делу, в частности, обсудить геймплей и правила.
Gameplay и правила
Кажется, что геймплей — это очень простая вещь! Мы прекрасно знаем, как играть в StarCraft, Doom или Quack. Но когда вы создаете свою игру, у вас возникает огромное количество идей. Эти мысли разлетаются в разные стороны и очень сложно (особенно в команде) договориться о том, как игра будет выглядеть и что в ней будет происходить.
Этот процесс у нас не был линейным, мы не смогли сразу все определить. Финальная версия наших правил выглядит достаточно просто:
- Нужно найти спот — некое здание — именно поэтому игра называется Urban (Город).
- На споте есть флаг, который нужно захватить, за это начисляются баллы.
- Участник, набравший больше всех баллов, получает приз.
- Игроки могут свободно перемещаться по общему миру и перезахватывать флаги (вариация «capture the flag»).

На этом мы определились со всеми менеджерскими функциями и решили заняться архитектурой.
Архитектура
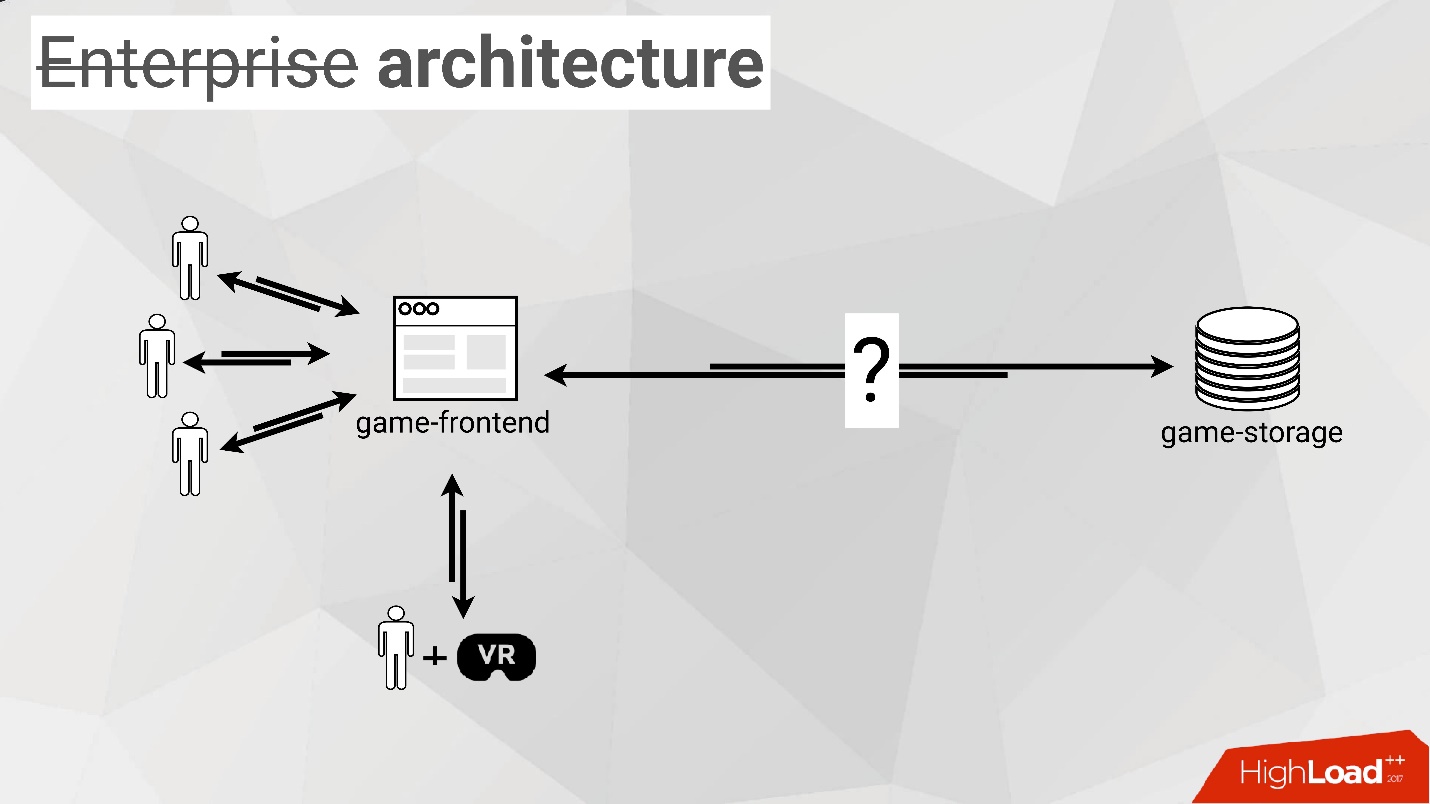
Так как мы создаем enterprise-продукты, то решили начать с enterprise-архитектуры нашей игры. Мы подумали, что в ней обязательно должны быть:
- Игроки.
- Специальный стенд для того, чтобы поиграть в шлеме виртуальной реальности.
- Браузер, поскольку мы решили, что это будет браузерная игра. Люди будут туда приходить и получать оттуда данные.
- Какая-нибудь «хранилка» — ведь у нас многопользовательская игра по сети, нам нужно где-то хранить данные о разных игроках.
Это была изначальная, достаточно наивная схема архитектуры.
Проблема репликаций в распределенных системах
Как «хранилка» должна общаться с браузером, где работает игра? Тут начинаются интересные моменты, и я бы хотел вас отвести в более знакомую область.
Вообще проблема репликаций в распределенных системах достаточно хорошо изучена. Репликации ежедневно используются в нашей отрасли. Но любая игра, особенно сетевая, представляет собой нетиповую ситуацию репликаций, когда нужно обеспечить репликацию только для того, чтобы игра случилась. Если у вас в распределенной системе нет репликации и связности, согласованности между игроками, то игру можно завершать, потому что в нее невозможно играть.
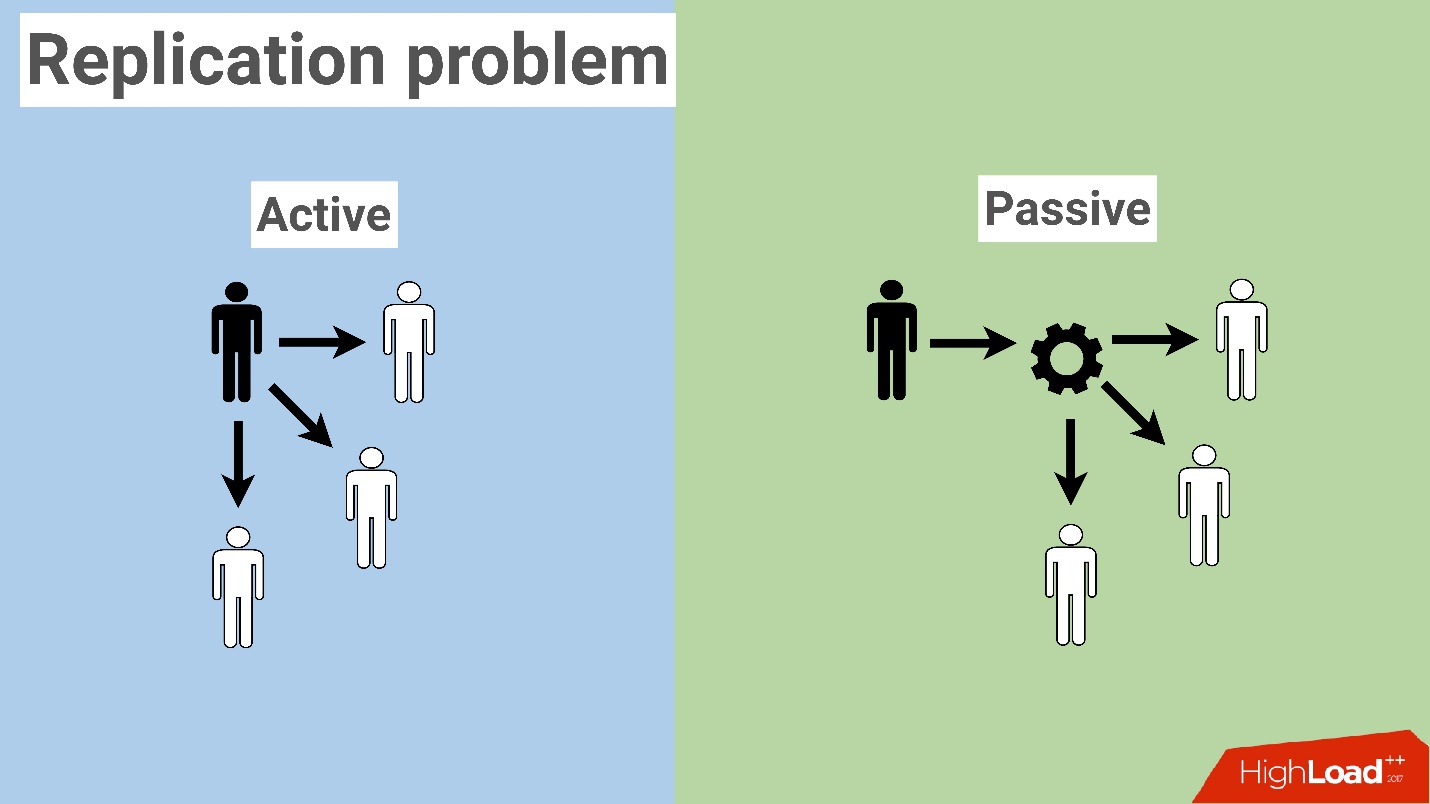
Выделяются два вида репликаций:
- Активная репликация, когда данные берутся непосредственно от одного клиента и передаются всем остальным игрокам, например, рассылается информация о том, что игрок захватил флаг. На других клиентах происходит точно такая же анимация, те же самые события и т.п.
- Пассивная репликация, в таком случае игрок отправляет информацию на некий сервер, и уже этот сервер обеспечивает пересылку данных всем остальным игрокам.
Попробуем разобраться, в чем здесь соль, что лучше, хуже, и вообще есть ли разница между активной и пассивной репликацией.
Плюсы и минусы активной репликации:
+ В активной репликации все
просто и интуитивно понятно: берем данные, отправляем всем другим игрокам, получаем от всех других игроков информацию.
+ Второй важный момент — эта система достаточно эффективна. Действительно, не нужно никакое дополнительное устройство в виде сервера, которое будет принимать, обрабатывать и передавать другим игрокам данные.
- Но есть огромный минус — системы, построенные на активной репликации, очень хрупкие. Достаточно появления сетевых проблем, например, потерь, задержек или затруднений с клиентами, получается полностью несогласованная система. Синхронизация ломается, а наша задача — иметь одинаковый общий мир.
На самом деле выйти из ситуации со сломанной синхронизацией достаточно непросто. Для этого существуют различные протоколы, например, Paxos, но все они незаметно усложняют простую схему активной репликации, требуют времени и вычислительных ресурсов.
Для примера могу сказать, что классическая игра StarCraft построена на активной репликации. Это один из явных примеров использования простой, но достаточно хрупкой модели. Именно поэтому, когда появляются определенные проблемы в синхронизации, игру, как правило, приходится завершать и начинать заново.
Плюсы и минусы пассивной репликации:
+ В отличие от активной, пассивная репликация очень
стойкая к десинхронизации. Если что-то пойдет не так, есть специальное устройство — сервер, который может привести систему в норму.
+ Вторым моментом, и зачастую очень недооцененным и важным, является безопасность игр. Недавно появилась игра VKpixel Battle — прямой аналог игры Place от Reddit, в которой тоже можно было разрисовывать доску. Эту игру взломали в течение нескольких часов ( источник ). В пассивной модели безопасность игры заметно легче обеспечить по той причине, что опять-таки есть сервер, где можно много всего контролировать.
- Но не бывает одних плюсов без минусов. С появлением сервера — устройства, которое принимает и отправляет данные, возникает классическая точка отказа. Если не применять специальные средства, например, шардирование, разделение на ноды, то можно потерять всю игру путем выхода из строя сервера.
Мы недолго думали, и, как и разработчики всех современных игр, выбрали пассивный способ репликации. На самом деле сейчас подавляющее большинство игр (порядка 99%) используют пассивную репликацию. Поэтому на нашей мощной enterprise-архитектуре появился еще один компонент — game-бэкенд, который берет на себя задачу синхронизации.

Data Structure
Поговорим немножко о системе хранения. Дело в том, что к выбору хранилища мы относились, скажем так, без должного внимания, как это принято в некоторых кругах.
Для того, чтобы понять, в чем хранить данные, нужно знать, как их представлять. Наверное, это наиболее важный вопрос, который определяет те или иные критерии. Рассмотрим структуру данных, которая возможна в нашей игре.
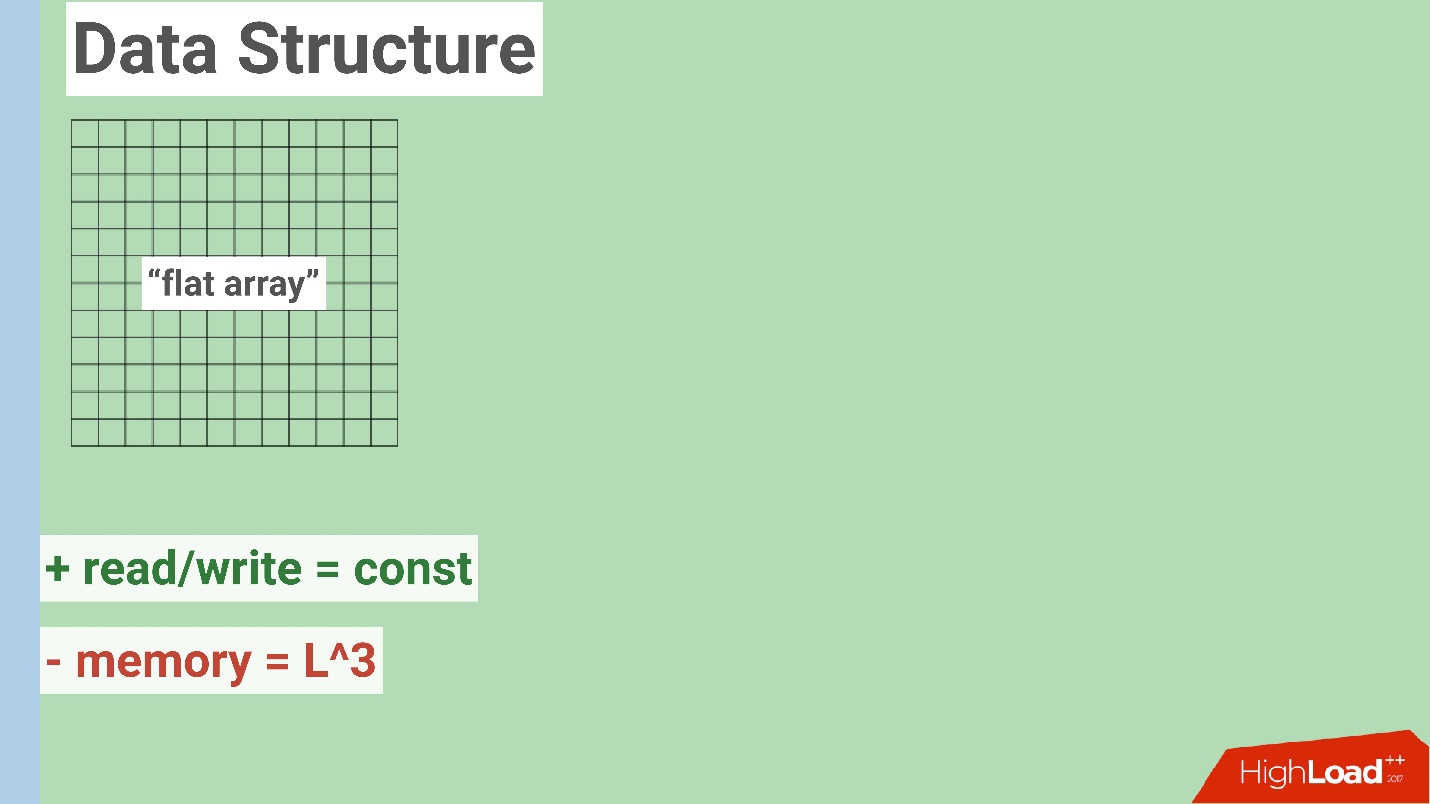
В ней очень много вокселей и ограниченный мир. Можно взять всю информацию о кубиках (вокселях) и хранить в обычном линейном большом массиве. Это очень простой и понятный способ. Его основным преимуществом является константная запись и чтение в ячейку. Мы можем спокойно получить информацию о вокселе, и это потребует какое-то константное время.
В действительности очень много современных игр, в том числе и Minecraft, стартовали именно с такой модели, и она себя показала достаточно успешной.
Минусом здесь является большое потребление памяти. Дело в том, что наш мир растет в трех измерениях, поэтому количество памяти, необходимое для хранения этих данных возрастает нелинейно.
Эту проблему можно решить, например, с помощью октодеревьев. Не будем вдаваться в то, что это такое, предлагаю для понимания просто посмотреть на картинку.
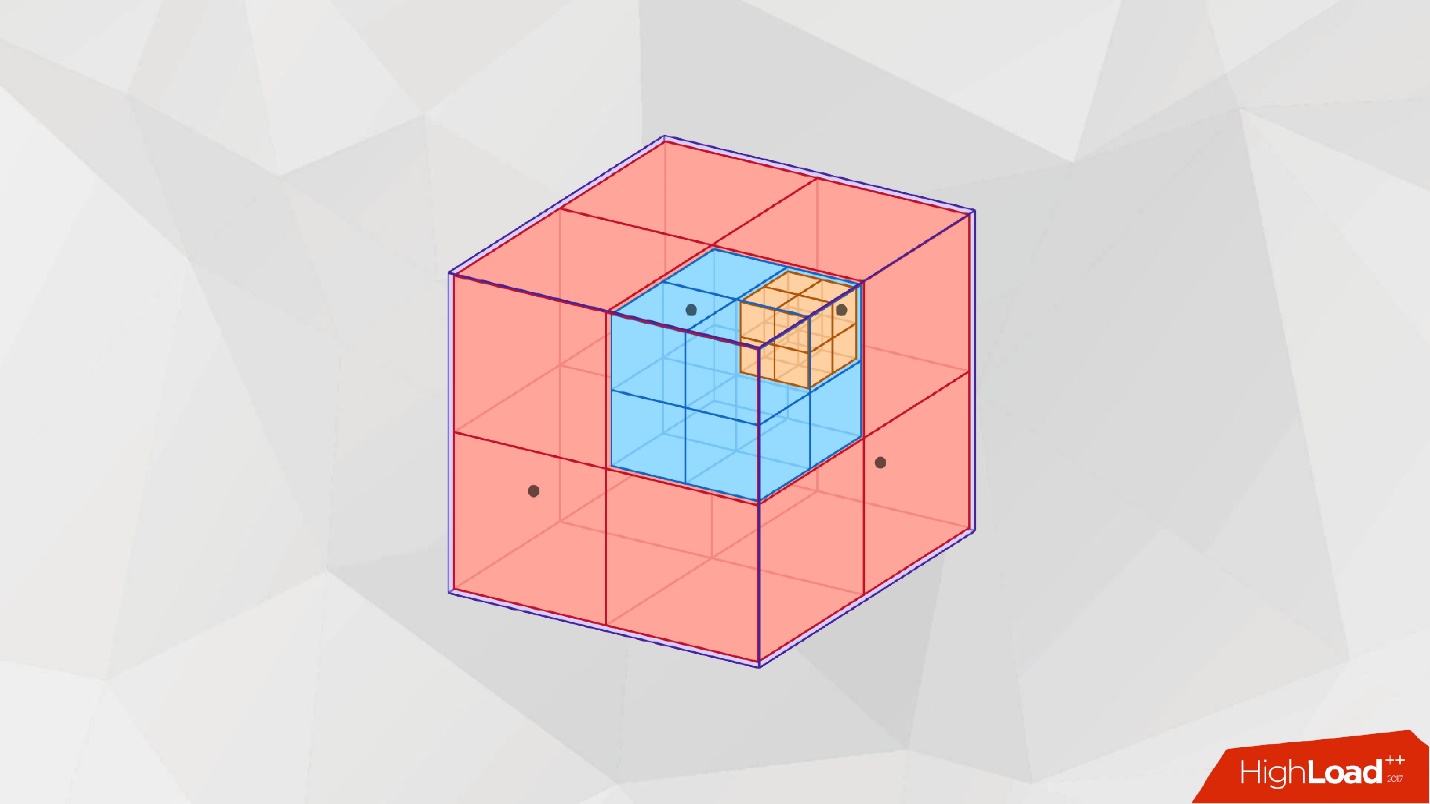
Если 3-мерный мир представить в виде большого куба, то его можно разделить на 8 частей — окты. Каждую из них можно также делить на 8 секций. Этот механизм позволяет сильно сэкономить на хранении структуры за счет областей, в которых отсутствуют данные.
Здесь есть явный плюс — это более выгодная с точки зрения хранения структура. Минус изначально не так очевиден, но быстро вылезает на практике. Дело в том, что нужно использовать различные кэши. Как правило, все, кто использует октодеревья, жалуются, что это заметно медленнее работает, чем обычные массивы.
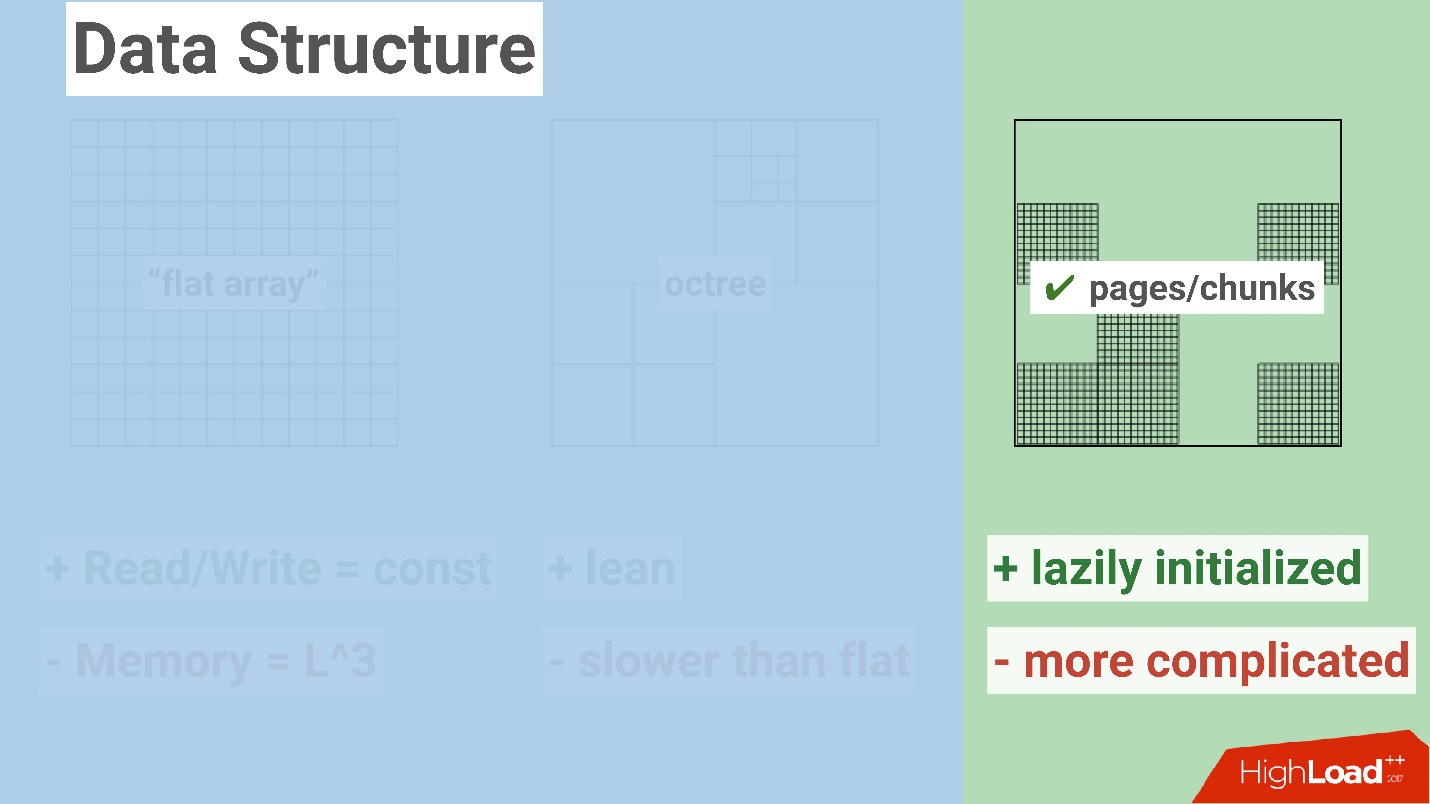
Наконец, есть третий вариант, я бы его назвал компромиссным — можно взять обычный линейный массив и разделить его на некоторые равномерные области (чанки). Это дает определенные преимущества. Например, в отличие от обычного массива, можно подгружать отдельные блоки. Нам не нужно загружать целый мир одного пользователя. Мы можем загружать только ближайшие от него блоки.
Но есть определенный минус — это конечно же усложняет всю модель обычного массива, потому что нужно хранить ссылки на чанки, оперировать чанками, добавлять логику во фронтенд игры и т.п.
Мы решили, что для нашей игры последний вариант оптимален и выбрали его. После этого выбор хранилища для нас прошел незаметно: мы решили — пускай это будет MongoDB. Я бы сейчас не хотел разводить холивар на эту тему — уверен, что на многих других прекрасных базах данных это тоже можно реализовать. Однако мы имели небольшой опыт работы с этой базой и поэтому решили на ней остановиться для экспериментов.
Протокол взаимодействия между фронтендом и бэкендом
У нас есть некая структура, есть клиенты, наверное, появится какой-нибудь браузер, в котором это все будет отображаться. Но как передавать данные между хранилищем и игрой? Пора подумать о протоколе.
Как мы уже знаем, наш мир представлен в виде параллелепипеда с основанием 1000×1000 и высотой 200. Можно проигнорировать высоту и всегда использовать максимальную высоту в выгрузке. Это сильно упрощает создание игры.
В свою очередь каждый квадрат в соответствии с нашим стандартом мы разбили на чанки 32×32 вокселя внутри.
Как я уже сказал, мы решили использовать MongoDB. В ней воксели хранятся достаточно просто, для этого мы используем обычные документы. Внутри документ выглядит примерно, как нас слайде ниже:
- служебное поле id,
- координаты,
- название цвета игрока,
- некое служебное название,
- дата, когда этот блок появился.

Теперь у нас возникают, как минимум, две задачи. Например, мы направляем игрока. Он рождается в мире в некой точке.
- Определяем ближайшие чанки, которые игрок может видеть, и формируем радиус. На самом деле это не совсем корректное название. Мы формируем понимание расстояния и смотрим, какое количество чанков это затрагивает. Далее делаем запрос get к базе данных, в котором говорим текущую координату игрока и этот радиус.
- Создаем set — блок или кубик на карте. Здесь достаточно просто отправить координаты кубика, который хотим установить.
Это прямые запросы в наше хранилище.
В обратную сторону можно наблюдать запросы об обновлении прочих кубиков.
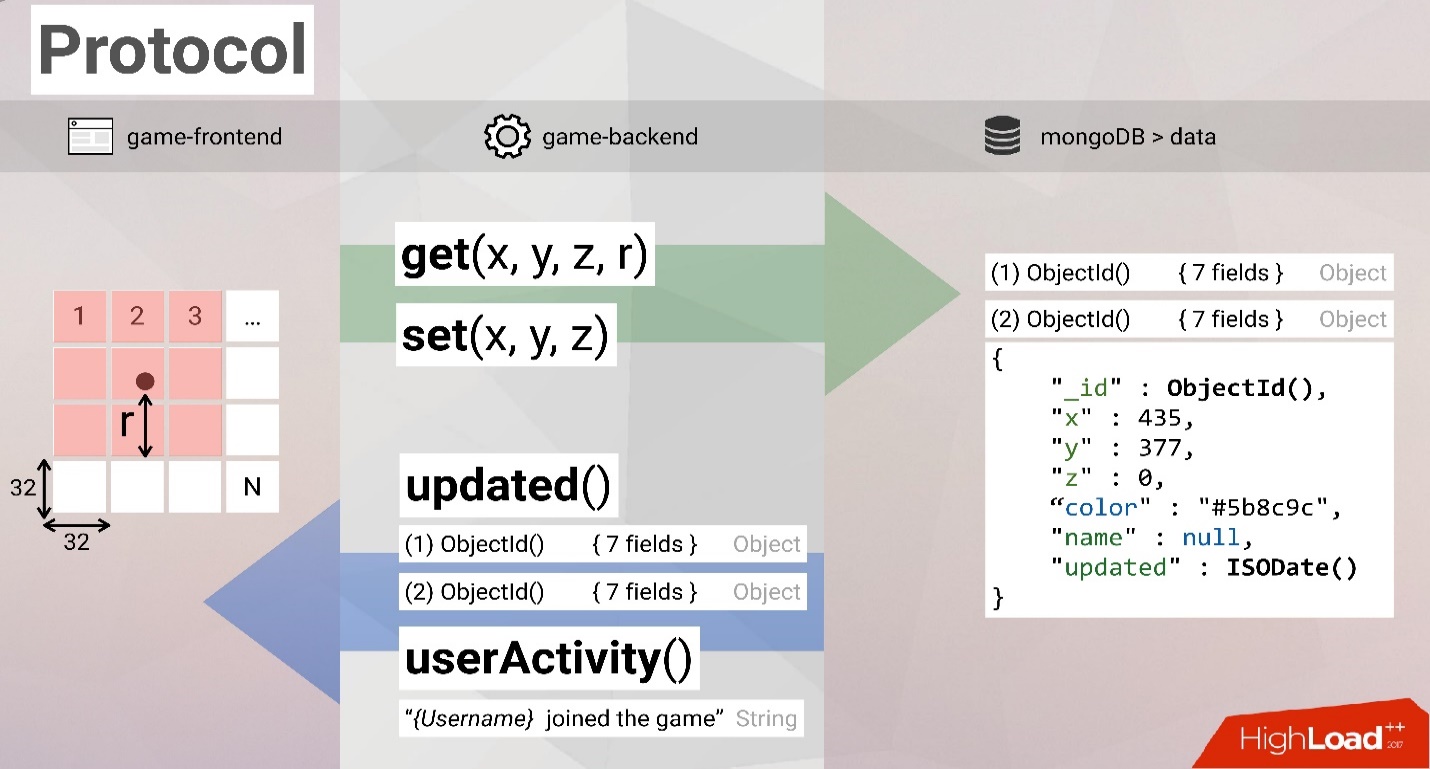
В данном случае речь идет о том, что, находясь в мире и получив некое его изначальное состояние, мы хотим наблюдать новые кубики, которые создают другие пользователи. Для этого мы подписываемся на события и получаем сообщения типа updated о всех кубиках, которые появляются в игре.
Наконец, мы хотели добавить немножко интерактивности в игру, и поэтому добавили специальное сообщение об активности пользователей — когда кто-нибудь зашел в игру, или вышел, или перехватил флаг, который позволяет получать очки.
Так у нас сформировался протокол взаимодействия.
У нас был небольшой выбор того, как мы можем общаться между бэкендом и фронтендом: HTTP, WebSocket, HTTP2. Мы решили остановиться на WebSocket по понятным причинам — для того, чтобы интуитивно уменьшить потенциальные задержки, которые были возможны.
Также мы подумали, что было бы неплохо получать результаты игры — например, смотреть, кто вошел в игру, какие у него очки. Для этого мы сделали отдельную «вьюшку», которую прикрутили к фронтенду и решили использовать для нее HTTP, чтобы не делать для нее авторизацию и не усложнять этот процесс.
Так у нас сформировался определенный стек в архитектуре. Ключевой точкой взаимодействия в нем стал WebSocket.
Game-backend
Бэкенд, как минимум, можно назвать сердцем нашей системы.

- Так как мы имеем определенный опыт в web-разработке, мы решили не использовать новых, для нас неизвестных технологий. Мы остановились на Python 3.6 и aiohttp. То есть у нас получился полностью асинхронный сервер.
- К нему мы добавили измененный loop — это uvloop, который позволяет еще быстрее работать.
- Так как мы используем MongoDB, нам нужен был какой-то асинхронный клиент. Для этого мы использовали motor, который прекрасно позволяет общаться с MongoDB в асинхронном режиме.
- Наконец, для того, чтобы выставить наш сервер наружу, мы использовали gunicorn, который разрабатывает на Python.
Так у нас получился вполне традиционный стек, который позволяет
обмениваться данными по нашему обозначенному протоколу.
Game-frontend
Это изюминка нашей игры — то, как игра начинает жить и существовать.
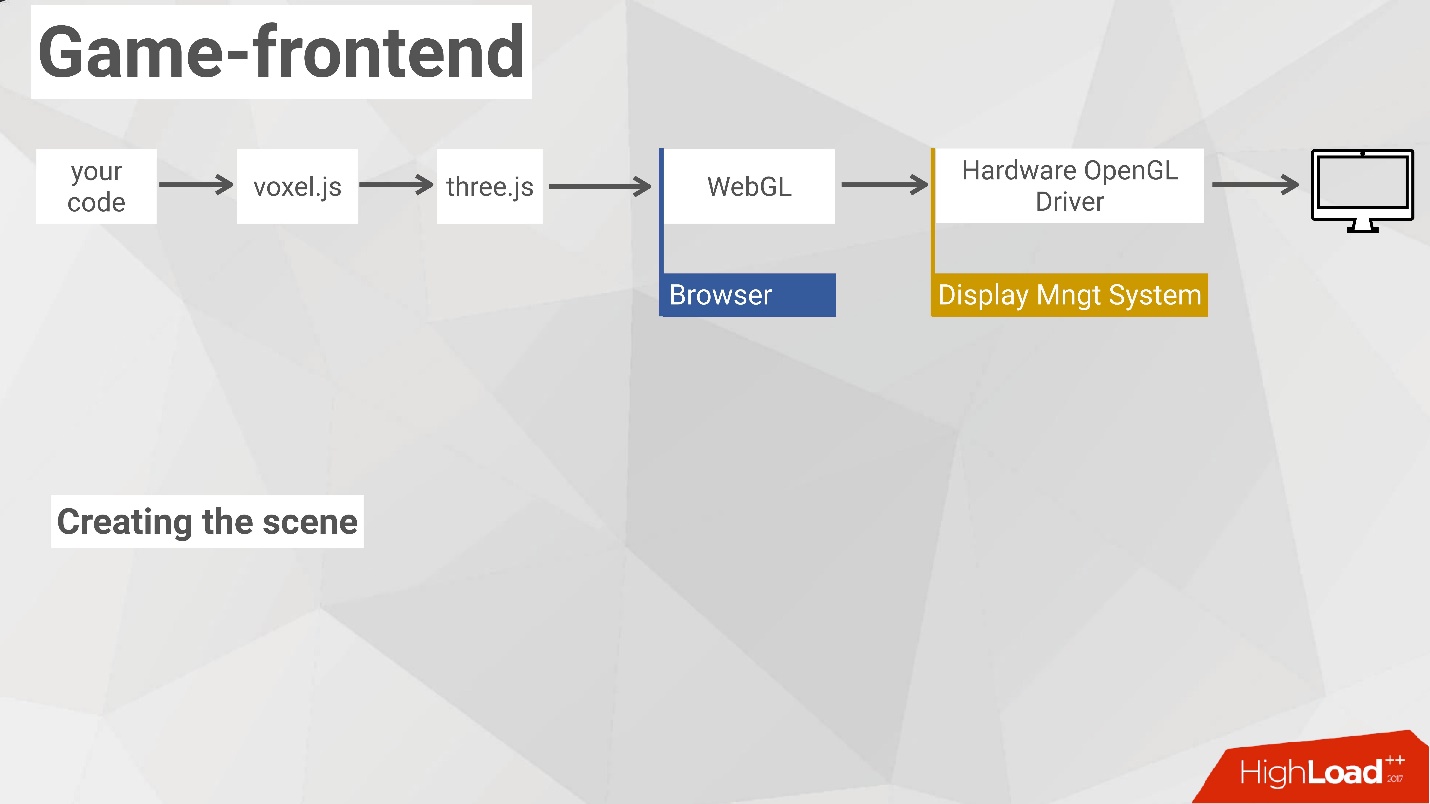
В первую очередь у нас встал вопрос — каким образом мы можем написать игровой движок, как вообще делать игры и как это все работает. После недолгого изучения материала мы поняли, что существует библиотека WebGL, которая позволяет очень многое. Она работает с библиотекой OpenGL, которая уже в свою очередь работает с оборудованием, с драйверами, с видеокартой и т.п.
Поэтому первая мысль была — использовать обычный нативный JavaScript, посмотреть, какой API предоставляет WebGL и начать делать игру. Эту идею мы достаточно быстро отмели, потому что по опыту в web-разработке понимали, что разрабатывать самому web-сервер — очень странная и долгая затея. Тем более у нас не было так много времени.
После недолгих поисков мы нашли JS-библиотеку, которая называется Voxel.js. На самом деле она стала для нас Граалем, потому что представляет очень много инструментов.

Библиотека существует уже более 3 лет, и, как заявляет автор, фактически является tool-kit для создания современных браузерных игр, причем воксельных. В ней присутствует все, что необходимо.
- Понятие мира, в котором есть оси и координаты;
- Работа с блоками (вокселями), которые понимают концепцию чанков;
- Инструменты для создания видеоигр:
- ограничивающие многогранники для того, чтобы понимать столкновения, нахождение рядом, работу с объектами и т.п.;
- ray casting — метод, который позволяет из 3D-объектов создавать на мониторах вид 2D;
- текстуры.
- Самое главное, есть понятие игрока и его управление. Фактически мы получили уже почти готовую игру!
- Все необходимые события — цикл создания мира, цикл установки блока и т.д. На все из них можно подписаться и производить свои действия.
Как выглядит весь стек
- Мы пишем свой код, используя библиотеку Voxel.js — это наша специальная логика.
- В свою очередь Voxel.js общается с библиотекой, которая называется three.js. На ней я немножко остановлюсь, потому что она является краеугольным и важным камнем во всей этой схеме.
- Далее three.js уже общается с WebGL, которая фактически встроена в браузер (использует его API).
- WebGL работает уже с настоящим оборудованием — с OpenGL драйвером, который рисует картинку на мониторе.
На самом деле сцену с использованием three.js, и в частности с Voxel.js, который это использует, произвести на свет не так уж и просто. Хотя кажется, здесь нет ничего сложного ровным счетом.
Посмотрим на код, но не будем заранее пугаться.
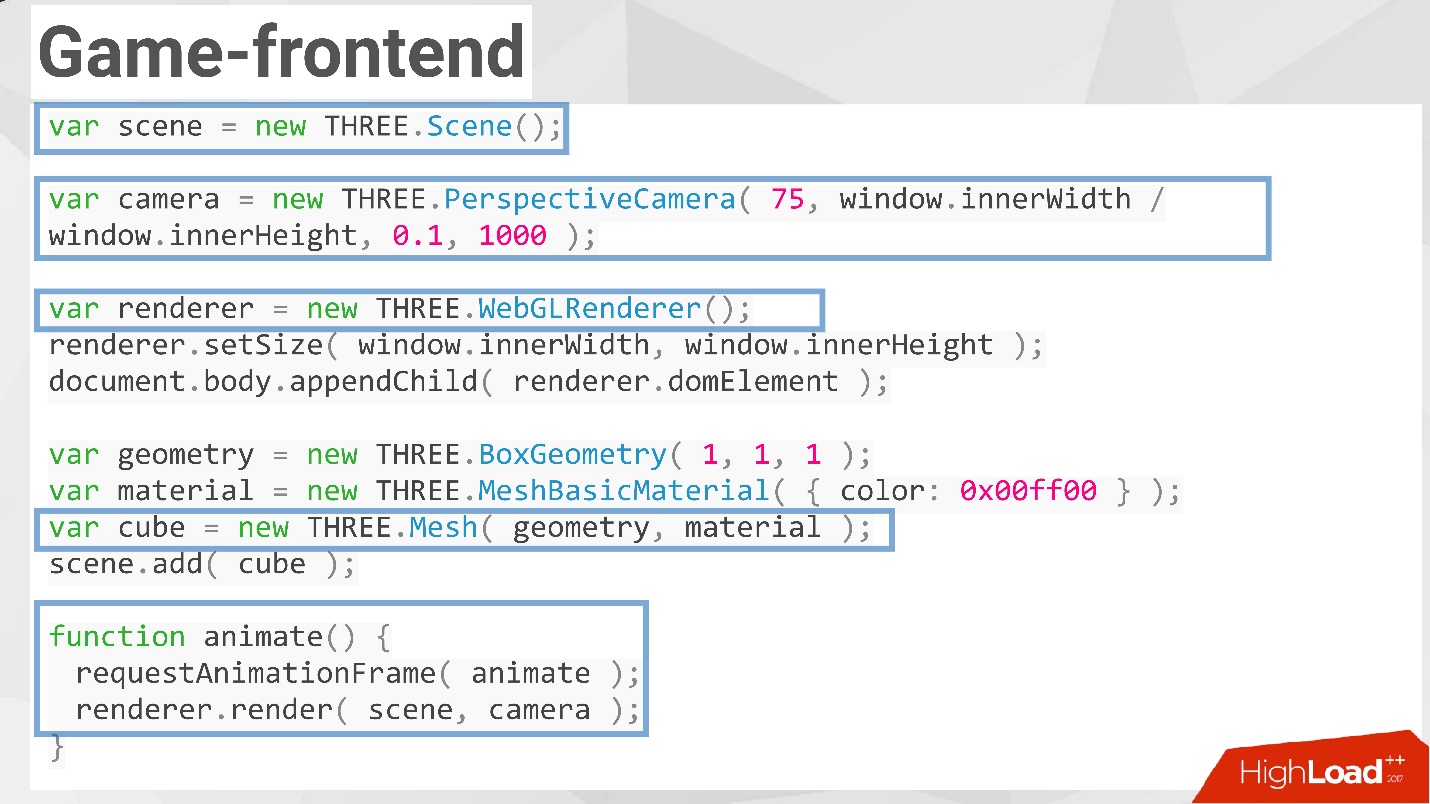
Чтобы создать классную 3D-картинку в браузере, нужны на самом деле всего 3-4 вещи:
- В первую очередь нужна сцена, как и в обычном мире.
- На этой сцене должна быть камера — мы создаем объект camera, в котором обозначаем размеры и максимальное/минимальное расстояние, которое мы видим.
- После этого нам нужно устройство, которое будет рендерить — создавать для камеры на сцене то, что мы хотим видеть. Для этого мы создаем render. В данном случае как раз используется WebGL технологии, и наша видеокарта будет трудиться для того, чтобы создать мир.
В принципе, у нас есть все для того, чтобы игра работала. Единственное, не хватает каких-то объектов.
4. Для того, чтобы создать объект, нам нужны:
- Геометрия (geometry) — это то, как объект будет выглядеть в пространстве. Например, если это куб, то у него должны быть вершины и грани.
- Материал (material) — для того, чтобы раскрасить объект. Самый простой вариант — использовать цветную заливку.
Соединив геометрию и материал, мы получим так называемый mesh (или некую сетку объекта).
Дальше вызывается простая функция animate. Как setInterval в браузере, она каждый раз отрисовывает новый фрейм и получается анимация. Фактически этот механизм используется в обычных 3D играх и доступен в браузере.
Виртуальная реальность
Я бы хотел поговорить немножко о VR. Как я уже говорил, нам хотелось использовать хайповую передутую технологию для того, чтобы привлечь внимание. Мы решили использовать VR. Это был случайный, спонтанный выбор, но изучив тему, мы поняли, что VR — это не очень новая и не очень хайповая технология. Эта картинка датирована началом XX века — это VR, но XX века!

Нужно всего лишь использовать этот шлем, чтобы рассматривать настоящие 3D-объекты — единственное, что в статике.

Oculus Rift
Мы решили использовать не статическую картинку, а все-таки создать графику с видео. Поэтому наш выбор пал на
Oculus Rift.

Опять-таки выбор был достаточно интуитивный и спонтанный. В нем нет ничего особенного, Oculus Rift представлен, как минимум, 3 базовыми устройствами:
- шлем;
- специальное устройство для того, чтобы понимать трекинг, то есть движение головы, которое носит вспомогательный характер (слева);
- контроллер — источник команд, который может быть представлен разными
устройствами.
Никто из нас до этого с VR-технологиями и со шлемом Oculus не имел дела.

Плюсы:
+ Это действительно VR-картинка — она вполне настоящая и позволяет обманывать наш мозг и представлять, что мы находимся в 3D-мире.
+ Неплохое разрешение экрана и очень приличная скорость обновления картинки. Я лично не наблюдал каких-то заметных ухудшений своего самочувствия во время просмотра картинки, в отличие от первых старых шлемов виртуальной реальности.
+ Это действительно очень удобное устройство, хорошо сделанное, которое прекрасно лежит в руке и отлично носится на голове. Можно сказать, что это действительно потребительское устройство.
Минусы:
- Я представлял себе VR так, что можно просто надеть шлем, девайсы и будет классно! На самом деле это огромное количество проводов. Фактически к каждому устройству необходим кабель, а то и два.
- Второй важный для меня момент и легкое разочарование — я ожидал, что я возьму свой обычный лэптоп и смогу программировать, сидя на диване. Оказалось, что есть серьезные ограничения: можно использовать только Windows, Oculus и SDK не доступен для macOS/Linux. Возможно, это стратегия компании или особенность операционной системы — мне сказать достаточно сложно.
- Я не смог запустить даже простое видео или игру в VR, не подключая достаточно приличную видеокарту. Я не являюсь ярым геймером современных 3D-игр и поэтому мне пришлось искать ее для того, чтобы начать разработку.
Думаю, что если вас не стесняют эти минусы, то смело можно пробовать современные шлемы виртуальной реальности.
Как делать игры для VR
Для нас эта тема была абсолютно закрыта и непонятна. Мы думали, что нужна специальная магия, возможно, устройства или ученая степень. На самом деле нет.
A-Frame
Сейчас не так много инструментов, которые позволяют делать VR-игры еще и в браузере.
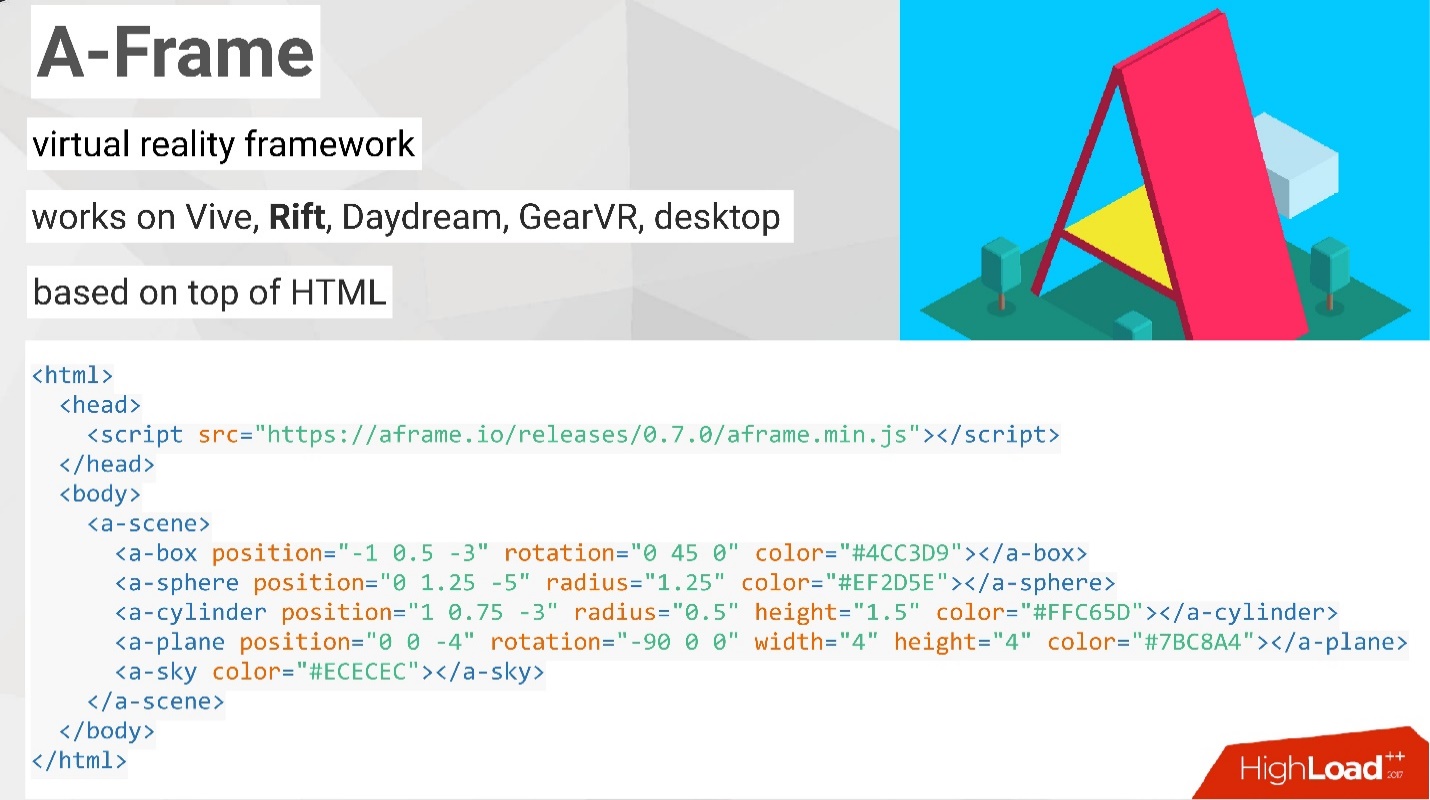
Наверное, первое, что можно найти в интернете, это фреймворк A-Frame. Он является лидером и вообще доминирующим фреймворком для создания дополненной и виртуальной реальности.
Что здорово, он работает с огромным количеством устройств, включая Oculus Rift, и даже с обычными мониторами. Это позволяет работать в режиме совместимости, когда нет шлема, что очень удобно для разработки.
Но, наверное, самое здоровское то, что если вы являетесь web-разработчиком, он будет вам очень близок, потому что использует парадигму и концепцию HTML. Вам не придется компилировать код, не нужны специальные программы — достаточно использовать свой браузер и обычный блокнот для того, чтобы написать первую 3D VR-сцену в браузере.
Код на картинке выше выглядит, как обычная html-страница. Вспомните мой предыдущий рассказ о сцене и рендере, здесь можно увидеть примерно то же самое.
Есть сцена, на которой созданы разные объекты. Рендер и камера заданы по умолчанию, но их можно переопределить. Если вы скопируете этот блок кода, то в своем браузере увидите соответствующую картинку. На ней с помощью мышки или клавиатуры можно перемещаться и увидеть полностью 3D-объекты с тенями и т.п. Дальше можно здорово развиваться, расширяя эту идею.
Так мы начали делать версию для VR.
Вы спросите — а где здесь VR? VR здесь на самом деле находится в правом нижнем углу. На этой картинке этого нет. Там появляется очень маленький значок очков виртуальной реальности. При нажатии на эту кнопку, появляется VR-картинка. Это выглядит абсолютной магией, потому что вы не делаете ничего специально для того, чтобы появилась виртуальная реальность. Это делает за вас фреймворк.
Если посмотреть детальнее, то здесь нет ничего сложного. Для этого достаточно создать изображение для двух глаз и правильно его расположить. Это позволит генерировать правильную картинку.
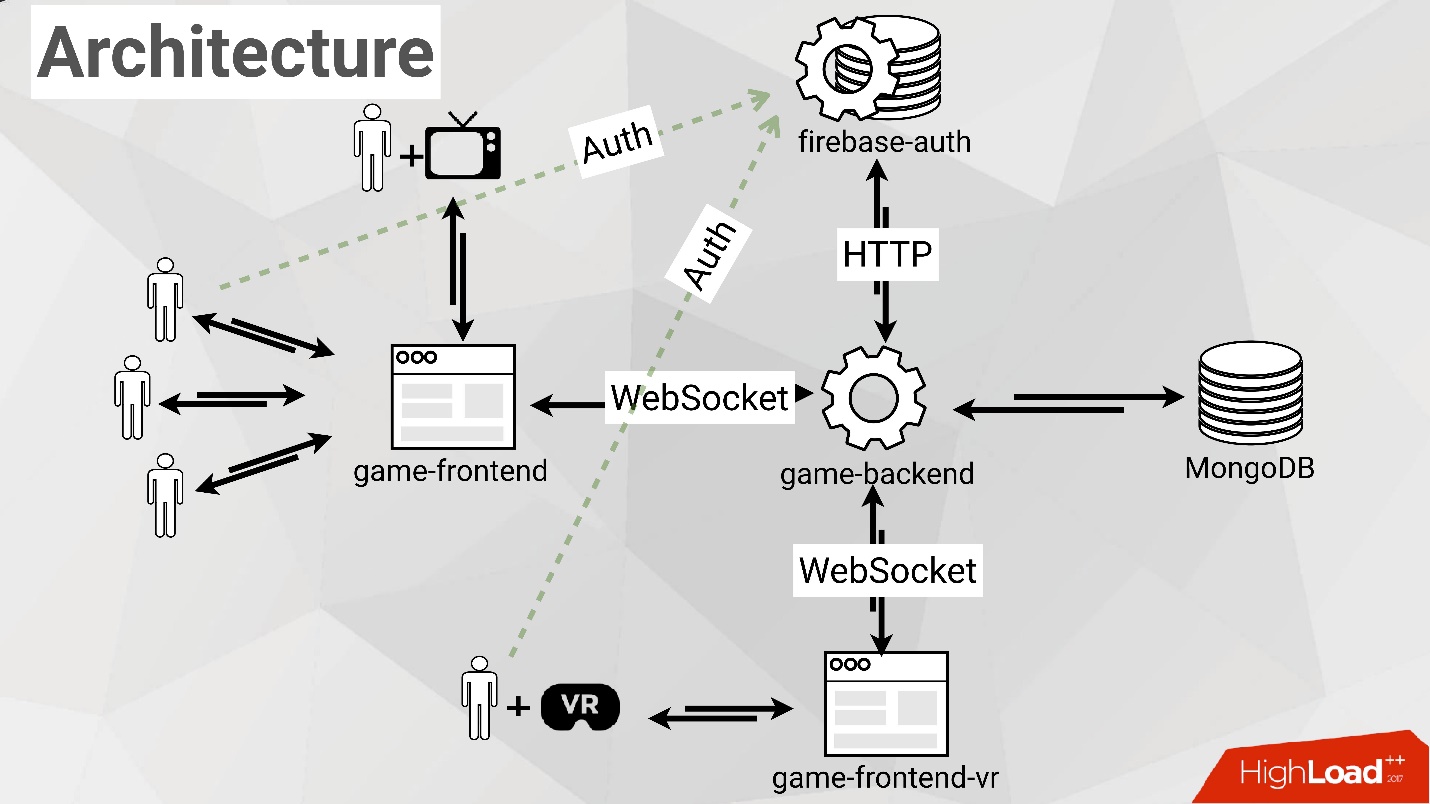
Возвращаясь к нашей enterprise-архитектуре, мы пришли к тому, что у нас будет два клиента:
- Один для обычной игры с использованием Voxel.js.
- Другой — с использованием библиотеки A-Frame.
Наконец, мы решили добавить авторизацию в игру, чтобы люди могли знать свои
имена, имена своих друзей. Для этого мы используем Firebase, чтобы не изобретать аутентификацию и авторизацию самостоятельно.
Оптимизация
Напоследок хотел бы рассказать немного об оптимизации.

Пока мы делали игру, приключалось очень много разных историй, три из которых мне бы хотелось отметить. Это довольно любопытные вещи, которые могут очень сильно упростить жизнь разработчика.
1. Pre-process voxel models
Как я уже говорил, для того чтобы создать мир, мы использовали воксели и программу для рисования вокселей наподобие PowerPoint. Конечно же, те объекты, которые мы создавали, состояли из огромного количества полных кубиков.
Когда этот мир загружался, наша картинка требовала много данных и достаточно медленно работала, поскольку содержала очень много вокселей. Первое, что нам пришло на ум: «Почему бы не сделать объекты полыми, то есть внутри не создавать эти самые кубики? Ведь пользователь их все равно не увидит!»
Мы написали очень простой алгоритм, который позволяет исключать из нашего мира, который мы создали в отдельном редакторе, воксели, которые находятся внутри. Это просто колоссально снизило количество передаваемых данных — примерно на 78% уменьшило количество вокселей в мире.
2. User Mesher
Вторым важным моментом является рекомендация использовать mesher. Дело в том, что, создавая игру с воксельной графикой, мы конечно же в голове у себя представляем отдельные кубики. Но в действительности мир, как и в Minecraft в том числе, устроен немножко по-другому.
Мы используем обычные полигональные модели, и поэтому имеет большой смысл все отдельные воксели соединять вместе в сеть (или Mesh). Для этого используется специальный инструмент mesher. Он колоссально увеличивает производительность, потому что уменьшает количество вершин, граней, ребер. Для того, чтобы просчитать, например, падение света или какую-то физику, нужно меньше вычислительных ресурсов, поскольку будет меньше полигонов.
Кстати, в некоторых фреймворках mesher включен по умолчанию. Так c Voxel.js мы получили достаточно приличный FPC изначально. В A-Frame такого нет, и мы использовали mesher уже дополнительно.
3. Enable compression for WebSocket (RFC 7692)
Наконец, оптимизация из мира web-разработки. WebSocket — отличная технология, но по умолчанию она не производит никаких манипуляций с теми сообщениями, которые передаются с ее помощью.
Мы передавали достаточно большое количество текста (в данном случае JSON) между клиентом и сервером. Эти данные были очень похожи друг на друга. Поэтому у нас возникла идея — почему бы нам их не сжать?
Единственной загвоздкой было наличие WebSocket, а не классического HTTP. Открытием для нас, возможно, это будет также приятным открытием для вас, стало существование специального RFC, который описывает, как можно делать компрессию внутри WebSocket.
Там есть несколько технологий, основанных на использовании специальных плагинов. Фактически включение такой технологии на сервере в нашем случае позволило заметно понизить трафик — буквально с 5 MB передаваемых данных до 1,8 MB.
Приятно, что современные браузеры — такие, как Chrome, Firefox, Safari — поддерживают компрессию со стороны клиента. Вам достаточно правильно включить компрессию на сервере и реализовать ее, и все будет прекрасно работать.
Единственно важным моментом является то, что во всех отладочных инструментах браузера информация по компрессии не отображается, а показывается информация уже раскрытых данных. Поэтому не стоит переживать — компрессия, скорее всего, у вас работает, а данные, которые показаны, уже активны после всех процедур.
В заключении хочу сказать — обязательно пробуйте что-то новое и получайте от этого удовольствие! Заходите к нам и посмотрите, как выглядит наша игра, в статье специально нет ни одного скриншота.
Для любопытных ребят, которым хочется посмотреть кодовую базу, мы сделали ее открытой. Вы можете понаблюдать, как мы разрабатывали игру, что она из себя представляет и даже запустить без проблем свой экземпляр игры, включая сервер и две версии — для VR и просто для браузера.
Кстати, к РИТ++ 2018 ребята готовят ремейк логической игры Pipes — называется CloudPipes.
Что еще раз подтверждает тезис, участие в конференциях, особенно наших, — это весело!
Расписание фестиваля с докладами, митапами, викториной и «Что? Где? Когда?» готово, а у вас еще есть шанс приобрести билет.
Также на забывайте про Highload++ Siberia, которая тоже всего через месяц.
Let's block ads! (Why?)
















 Фактически перед нами ценник. Представьте, что мы продаём арбузы. Мы выпускаем ценник прямо под конкретный плод с конкретным весом, наклеиваем на арбуз и пишем: «Стоит 1 ETH». После этого нам нужно, чтобы ценник либо принял 1 ETH, либо «сгнил» через сутки: возможно, на следующий день мы захотим продать арбуз за 2 эфира.
Фактически перед нами ценник. Представьте, что мы продаём арбузы. Мы выпускаем ценник прямо под конкретный плод с конкретным весом, наклеиваем на арбуз и пишем: «Стоит 1 ETH». После этого нам нужно, чтобы ценник либо принял 1 ETH, либо «сгнил» через сутки: возможно, на следующий день мы захотим продать арбуз за 2 эфира. Эта схема в блокчейне используется для того, чтобы пообещать что-то сделать и потом доказать, что дело сделано.
Эта схема в блокчейне используется для того, чтобы пообещать что-то сделать и потом доказать, что дело сделано. Этот контракт — адрес, с которого можно вывести средства, предоставив N из M подписей.
Этот контракт — адрес, с которого можно вывести средства, предоставив N из M подписей.