15 июня в нашем инстаграм-аккаунте прошел прямой эфир с Ильей, руководителем фронтенд-разработки в Яндекс.Деньги. Выкладываем запись эфира и расшифровку.
Меня зовут Илья, я работаю в компании Яндекс.Деньги и руковожу фронтендом. До этого был бэкенд-разработчиком, писал на C#, около 5 лет назад перешел во фронтенд. Чуть больше года руковожу. Вот такой путь развития. Еще активно участвую в Burning Lead – это сообщество для ведущих разработчиков, тимлидов, людей, которые так или иначе пересекаются с задачами управления; надеюсь, ребята из сообщества слушают стрим.
Про Node.js и его использование
Сначала скажу, как она у нас появилась и почему мы ею пользуемся. Исторически сложилось так, что у нас в Деньгах есть полноценный Java-бэкенд, в котором Java-разработчики работают с базами данных, с основной бизнес-логикой. Фронтендеры с бизнес-логикой не работают, мы подготавливаем для себя нужный формат данных и отправляем его на фронтенд, а там уже рисуем их на каком-либо фреймворке. Изначально у нас был Xscript-сервер, который ребята в Яндексе сделали еще в 2000-х годах – это наше legacy. Часть логики – серверный рендеринг – мы писали на XML, XSL/XML преобразования. Так продолжалось очень долго. Потом, когда мы осознали, что разработчиков на XSL/XML стало тяжело искать, мы стали выбирать новый сервер, в который можно было бы писать на бэкенде и потом использовать на фронтенде. Оказалось, что есть целая платформа Node.js.
Тогда Node.js была очень молодой платформой, версия 0.10, наверно. Решено было использовать ее по нескольким причинам: язык Javascript набирал популярность, разработчиков было много; кроме того, серверную и клиентскую логику мог писать один разработчик без суперспецифичных знаний. О своем выборе мы не жалеем: платформа все еще активно развивается, оптимизируется, становится быстрее, получает полезные фичи, имеет активное сообщество.
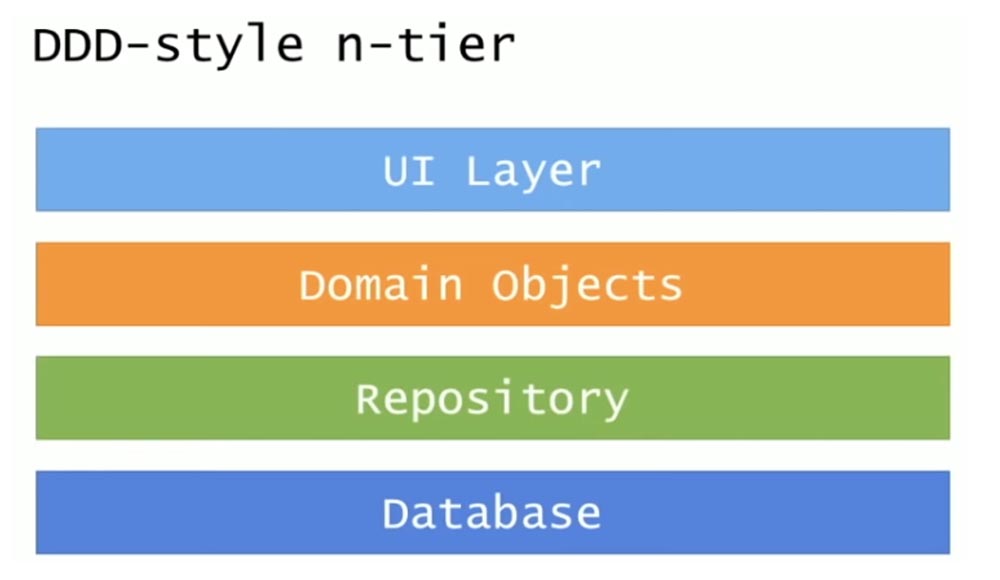
Поговорим про архитектуру фронтенда и о том, чего мы хотели бы достичь в архитектуре Яндекс.Денег в целом. Так как мы используем Node.js, у нас уже долгое время основой серверного фреймворка служит Express. Он хорошо справляется со своей задачей – обрабатывает запросы пользователя и дает ответы, больше от него ничего не нужно. Для него написано множество плагинов. Есть SSR для React-приложений, например; так как основной стек на клиенте – это React, SSR не проблема прикрутить. Есть много реализаций; можно даже не писать код: разворачиваешь из NPM, он сам все делает.
Что касается архитектуры – мы порядка 4-5 лет живем на Express, и из-за этого возникают некоторые проблемы. У нас довольно много разработчиков – в отделе сейчас человек 50 – и нам нужно писать понятный для всех код; разработчики могут менять интересы, переходить из команды в команду, и нам нужно, чтобы код был примерно одинаковым, чтобы разработчик в новой команде не тратил по месяцу на акклиматизацию к новому коду. Express – довольно низкоуровневый фреймворк, и с ним живется довольно тяжело: каждая команда использует свое видение того, как писать обработчики запросов или бизнес-логику, ходить в бэкенд. Первая попытка наладить архитектуру сервера была совершена, когда мы сделали ProcessFlow. Я на эту тему выступал с докладами – рассказывал, как на основе IDEF0 можно построить систему, которая позволит организовать бизнес-логику, задать правила ее написания, сделать поддержку, визуализацию связей между сущностями. Попытка была вполне успешной: в некоторых местах у нас были серьезные проблемы с пониманием кода, и ProcessFlow помогла их решить. Она работает и сейчас, и вполне нас устраивает.
Сейчас у нас идет переезд на NestJS. Это довольно современный серверный фреймворк, позволяет писать контроллеры в парадигме Model-View-Controller, организовывать бизнес-логику; его философия пришла из Angular. Его сильная сторона – это правила, они уже на уровне фреймворка определяют написание контроллеров и бизнес-логики. Бесконтрольная среда бывает губительна, когда вас много и все пишут по-разному; лучше иметь свод правил, к которому всегда можно обратиться – такой путь мы выбираем. Про NestJS активно рассказывает мой коллега Андрей Мелехов, ведущий подкаст devSchacht; он сейчас описывает процесс переезда на NestJS, обсуждает проблемы.
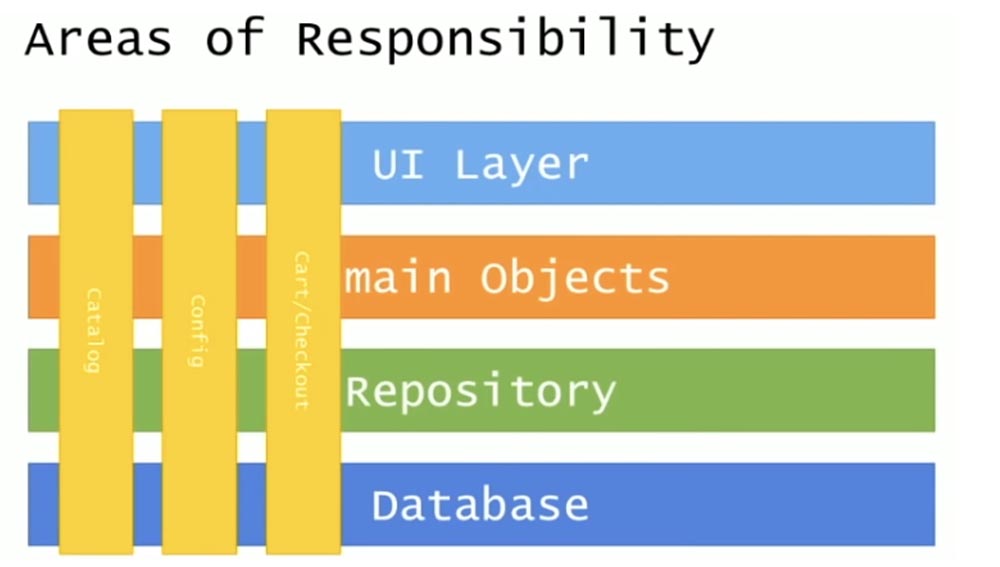
Мы стремимся к тому, чтобы перевести все приложения на NestJS. Еще мы продумываем более строгие архитектурные правила, чтобы сильнее снизить энтропию между разными приложениями в компании, и проводим дробление приложений по микросервисному подходу. Раньше у нас был монолит, и все было неплохо до того, как наша команда выросла и разработчики начали мешать друг другу – по релизам, по функциональности – и, кроме того, монолит долго собирался. Мы решили разделяться на микросервисы. Сейчас мы видим, что микросервисы во фронтенде – это тяжело: на страничке нужно отобразить несколько доменных областей, при том, что каждый микросервис должен обслуживать только одну область. Мы видим, что микросервисы превращаются в мини-монолиты, и теперь мы смотрим в сторону микро-фронтенда, который позволит адекватно организовать фронтенд без пересечения предметных областей.
Про клиентскую часть
Она состоит из двух больших стеков. Первый – это легаси-стек с использованием методологии BEM Naming (определенные названия CSS-стилей, позволяющие избегать пересечений), на основе которой в Яндексе создали фреймворк. Мы использовали его довольно долго, так как мы используем технологический стек Яндекса. Он классный, и в нем работа с компонентами организована примерно так же, как в современных фреймворках: в виде отдельно лежащих блоков, которые удобно поддерживать. Однако он уже устарел, поскольку основан на GQL и не отвечает современным требованиям по UI; на нем очень сложно делать анимации и приложения на клиенте. Мы постепенно переходим на React уже несколько лет (переход продвигается тогда, когда меняется дизайн или функциональность: то есть, все переписывания бизнес-процессов происходят на новой технологии). Он показался нам довольно мейнстримовым — то есть, разработчиков на нем много. React — основной фреймворк на клиенте, в качестве стейт-менеджера используется Redux; с ним же мы используем Redux-Thunk для асинхронных действий и запросов к бэкенду. В нескольких проектах использовали hooks.
Почему не Angular?
Когда мы выбирали стек, Angular был приблизительно версии 1.5. Он показался нам сомнительным, и мы выбрали другое решение. К последним версиям Angular я не имею претензий, но отказываться от React мы не хотим.
Как я стал тимлидом, почему я выбрал этот путь, какие плюсы и минусы
На самом деле, в каждой компании будут собственные требования к тимлиду или руководителю отдела, но, как мне кажется, есть и определенный план того, что нужно знать и делать, чтобы развиваться в направлении менеджмента. Есть такой подкаст – PodlodkaPodcast, они публиковали такой план (роадмап). Крутая штука; там написано, что следует читать для развития нужных softskills — на них нужно делать упор. Конечно, у хорошего тимлида должны быть и отличные hardskills: он – не просто формальный лидер команды (допустим, 5 человек), он должен доказать свое лидерство, он должен учить свою команду, его люди должны желать научиться программировать так же, как может он. Но важны и softskill: коммуникативные навыки для общения в пределах команды и вне их, для отстаивания мнения команды, для поиска компромиссов. В работе тимлида очень много коммуникаций. Кроме того, нужно уметь проявлять эмпатию: при общении с разработчиками важно устанавливать понимание на уровне чувств, понимать настроение каждого собеседника, определять, чего он хочет. Напрямую это не говорится, но очень хорошо, когда тимлид владеет этим. Здорово, когда к hardskills также прилагается умение наставничества: за таким тимлидом потянутся люди, он будет в состоянии четко формулировать и ставить задачи.
У меня все произошло приблизительно по этому плану. Я учился коммуникации, помогал ребятам – даже в тех случаях, когда я сам изначально не понимаю, в чем проблема, полезно вместе сесть и разобраться с проблемой. Ко мне стали чаще обращаться люди; руководство это заметило, и меня повысили до старшего разработчика, а через год – до ведущего. В нашей компании это – тот разработчик, который непосредственно отвечает за развитие и рост команды. Я готовил много различных воркшопов по тестам, нагрузочному тестированию. В общем, я смотрел, какие темы в отделе в данный момент «больные», и старался сделать что-то полезное для команды, чтобы улучшить положение – с помощью воркшопов, выступлений, просто личной помощи; и, когда наш руководитель ушел, он порекомендовал меня на его место.
Когда я стал тимлидом, проблемы только начались. Можно подумать, что на этом месте всё должно быть хорошо: разработчики работают, лид командует, и всё — но это не так. Когда я был разработчиком, я делал понятную задачу и радовался своему достижению – но у руководителя, как оказалось, задачи часто сильно размыты. Нужно «улучшить что-нибудь». Например, надо ускорить время код-ревью: человек заходит, просматривает код и нажимает кнопку, что тут можно улучшать? Второй важный момент, который на тебя давит, состоит в том, что руководитель не решает прикладных задач своими руками. И тут происходит «синдром самозванца»: может казаться, что ты просто тратишь время, пока разработчики пишут код, и ты иногда чувствуешь себя бесполезным. Нужно понимать и знать свою ценность: коммуникации – это тоже важная задача. Хороший руководитель помогает снять ненужные коммуникационные барьеры в ходе проекта; разработчики могут не коммуницировать, потому что им это некомфортно, но руководитель – обязан.
Из плюсов можно назвать масштабность работы. Когда был разработчиком, я мыслил в рамках отдельного проекта. Проект мог быть большим, конечно, но в роли тимлида я мыслю в рамках всей компании: я должен сделать весь свой отдел лучше, чтобы вся компания стала лучше. От этого масштаба мне приятнее работать над проектами.
О процессах управления людьми в нашем отделе
Процесс разработки подразумевает общение разработчиков между собой, и у нас есть несколько точек пересечения. Задача на разработку поступает в одну из команд; обычно команда — это Java-разработчики, фронтенд-разработчики, менеджер, продукт, обязательно тестировщики. Такая единица, сидит где-то отдельно. Существование других команд для нее особенного значения не имеет само по себе – но нам необходимо, чтоб все команды писал приблизительно единообразный код. Для этого нужно общаться, и здесь есть несколько подходов. Во-первых, это происходящие время от времени встречи всего отдела; сейчас мы все собираемся в zoom, но это, конечно, не то. На встречах мы делимся новостями, ребята рассказывают, что они делают у себя в командах: какие у них проекты, какие будут в дальнейшем, что и как они делают. Это помогает строить представление о том, что происходит во фронтенде: он большой, просто так его рассмотреть не выйдет. Еще мы организуем tech talks, разные по масштабам: на всю компанию или на наш отдел, и там представляются технические приемы: например, на одном из них рассказывали, как используются hooks в React, как они влияют на форму, как выглядит код для них, какие плюсы и минусы. Такие доклады интересно слушать, и они помогают распространять по компании знания.Непосредственно в разработке есть процессы, которые позволяют нам общаться так, чтобы писать код, который потом не встретит непонимания на кодревью из-за используемых приемов, компонентов и библиотек – то есть, мы стараемся нивелировать плохие последствия от изолированного принятия решений. Этот процесс, который мы называем Logic Review, позволяет нам узнавать мнения экспертов, ведущих разработчиков, старших разработчиков после того, как мы понимаем, как делать определенную задачу – то есть, сверить наше видение реализации проекта с видением тех, кто определяет дальнейшее развитие всего отдела. Он позволяет нам обмениваться знаниями, технологиями, и контролировать однородность и архитектуру стека. Конечно, успеть везде и избежать всех проблем на кодревью невозможно, но такая сверка перед началом разработки позволяет уменьшить их количество.
Можно ли обмануть Review 360?
Напомню, что Review 360 – это когда все (разработчики, тестировщики, менеджеры), с кем работал человек, которого нужно оценить, опрашиваются «по кругу» с помощью опросника. Я об этом процессе рассказывал на Burning Lead. Если команда небольшая, как у нас обычно – человек 5-10 – то этот процесс, собственно, не нужен: тимлид может сам пообщаться с каждым членом команды. Собственно, он и должен общаться с каждым разработчиком раз в 1-2 недели, чтобы понимать, чего хочет разработчик, какое у него настроение, доволен ли он задачами, как он работает, как проходит его рост. Но, когда команда большая – например, у меня сейчас больше 50 фронтендеров – то на такое личное общение уже не будет хватать времени. У тимлида есть и другие обязанности и проекты, он обязан развивать отдел, он не может тратить все рабочее время только на общение, которое впоследствии нужно будет еще и проанализировать. Поэтому приходится использовать менее точные подходы – например, Review 360.
Можно ли его обмануть – я думаю, имеется ввиду то, могут ли разработчики договориться между собой и поставить себе высокие оценки? Наверно, могут, но с менеджером и product owner так не договоришься: эти люди преследуют несколько другие интересы, и это будет легко вычислено. То есть – можно, но ненадолго. Со временем станет понятно, что разработчик не делает свои задачи. Если product owner говорит, что разработчик не справляется, а другие разработчики ставят ему высшие оценки, то мы ясно понимаем, что существует проблема: либо product owner на него точит зуб, либо другие разработчики чего-то не замечают (или они договорились).
В целом, я думаю, что 360 Review – довольно объективная вещь, и мы их проводим с определенным промежутком времени. Опыта по ним накопили еще не слишком много, но мы постепенно двигаемся вперед и совершенствуем методы подсчета статистики и наборы вопросов.
Расскажите про менеджер зависимости, composer и Laravel
Я знаю, что Laravel – хороший PHP-фреймворк, и у нас на нем пишут, но сам с этими технологиями почти не работал.
У вас есть разделение на верстальщиков и JS-разработчиков, или разработчик делает все?
У нас подразумевается, что фронтендер – это человек, который пишет на JS вызовы к бэкенду, передает на фронтенд и реализует его. Мы не пишем сложную бизнес-логику и взаимодействия с базами данных. Но можно сказать, что фронтендер – это фуллстек, потому что он пишет и на клиенте, и на сервере.
Что нужно знать джуниор-фронтенд-разработчику для работы в компании?
К сожалению, сейчас у нас нет открытых вакансий для джунов, но они бывают. Мы требуем знания теории языка Javascript. Это может показаться абсурдным, потому что теория JS в повседневных задачах вроде бы не нужна; однако мы знаем, что человек, изучивший теорию, умеет работать с информацией и воспринимать её. Кроме того, у него есть мотивация: он сел и разобрался с тем, как язык работает; когда он сталкивается с проблемой или сложным местом, он знает, как искать нужную для решения информацию (даже гуглить надо уметь).
Расскажите про архитектуру клиентской части. Есть ли у вас библиотека компонентов, и как она шарится? Сколько независимых приложений, все ли они в одном стеке?
Про архитектуру я уже немного рассказывал. Библиотека компонентов у нас есть, их несколько. Есть та, которую мы получаем от Яндекса, чтобы визуальный стиль был одинаковым. Есть дизайн-система, которая говорит, какие сетки, цвета, типографику (и т.д.) мы используем на фронтенде – то есть, эта система полностью диктует расположение и цветовую схему. Наконец, библиотека общих между приложениями компонентов, которые мы используем. Приложений у нас больше 20 (26?), и во всех она используется; иногда мы довольно сильно ползем по версиям – получаются разные версии в разных приложениях, из-за чего может страдать визуальная часть. Это одна из больших проблем устройства микросервисов с общей библиотекой, но мы стараемся.
Какой размер вашей команды?
У меня две роли в компании: я руковожу отделом порядка 50 человек и одновременно являюсь product owner нашей платформенной команды, там 8 человек.
React Native или Flutter?
У нас были эксперименты с React Native, Flutter тогда был очень новым; мы решили, что выберем React Native.
Яндекс хочет свой фрейм запускать?
Нет, BEM – это очень старый фреймворк, он устарел, мы вместо него используем React. Никто не хочет запускать новый фреймворк.
Вопрос: на бэкенде только JS, или есть какие-то legacy-части?
Я рассказывал, что у нас есть сервер с Xscript с XML/XSL. Это как раз и есть наше legacy, мы его активно выпиливаем и хотим как можно скорее прекратить его использовать. В основном – в 96% случаев – у нас используется JS.
Redux-Thunk или Redux-Saga?
Мы использует Thunk. К Saga был подход; может быть, у нас тогда просто не было ребят, которые достаточно хорошо в ней разбираются, но преимуществ над Thunk мы не увидели. Сейчас уже есть подход с hooks, но пока Thunk очень активно используется.
Вы внутри компании или команды ставите задачи по Smart?
Когда мы делаем проекты, цели ставятся по Smart. То есть, мы должны четко представлять, что мы будем делать и к чему прийти. Новичкам тоже задачи ставятся по Smart. Но я не могу сказать, чтобы уже в процессе разработки всегда были четко прописанные задачи: часто, когда ребята в команде создают задачи, они могут быть совершенно по-разному описаны, но для новичков всегда всё описывается так, чтобы было ясно, как идти и к чему. То есть, не все 100% задач ставятся по Smart, но мы активно используем эту методологию.
Насчет микросервисов – сейчас выкатили Module Federation Pack 5, можно ли в эту сторону посмотреть?
Да, но это уже, наверно, не микросервис, а микрофронтенд? Нужно будет анализировать, что можно вытащить из этого; просто в лоб микросервисные задачи на фронтенде не очень хорошо решаются.
В чем разница в управлении 5, 10 и 50 людьми?
Во внимании, уделяемом разработчикам. Когда разработчиков 5-10, я могу с каждым из них пообщаться, выслушать проблемы, понять, чего они хотят и как развиваются. Когда их 50, это невозможно; конечно, это ухудшает ощущения от роли руководителя, потому что кажется, что я отделен от разработчиков, но сделать с этим ничего нельзя. Это основная разница. Кроме того, 5-10 человек – это одна команда, которая вместе работает, но 50 человек не могут быть одной командой; такое количество разработчиков нужно разбивать по отдельным управляемым группам, иначе не получится держать фокус.
Будет ли массовый переход на NestJS?
Сложно сказать. Может, завтра появится новый фронтенд-фреймворк, превосходящий NestJS, и мы все будем на него переходить. Я думаю, что сейчас NestJS хорошо проработан, но нужно исходить из задачи. Для многих задач, которые мы решаем на Node, не нужен такой серьезный фреймворк – например, для лямбда-функций, которые кто-то будет вызывать; но, когда на фронтенде есть развесистая логика, кажется, что подошел бы лучше Nest. Он сейчас хорошо проработан, есть и бэкенд-фреймворк (хотя он был довольно сырым, когда мы смотрели его). Nest развивается и, может быть, станет более популярным, но я не думаю, что будет массовый переход на него, как на Express.
Чем отличаются собеседования на джуна и миддла? Что оценивается во втором случае?
Когда мы собеседуем джуна, мы проверяем мотивацию человека, базовые знания JS, смотрим на коммуникативность и желание развиваться. С миддлом все интереснее: ведь миддлы – это люди, которые пишут основную часть кода наших проектов; у них мало встреч, они большую часть времени именно разрабатывают. Мы должны хорошо проверить его hardskills (задачами), узнать, как он рассуждает, поговорить про архитектуру, спросить, как он организует проекты, рассмотреть его стиль написания кода. У самого миддла уже есть сформированные ожидания относительно компании – то есть, с нашей стороны нужно донести, чего мы ждем от него и что можем предложить.
Есть ли какая-то боль в твоей команде, которую хотелось бы решить? С чем это связано, и какое может быть решение?
Мне бы хотелось сместить фокус на работу с людьми, чтобы в отделе уделялось больше внимания разработчикам. Мой фокус сейчас расплывается, потому что людей слишком много; моя задача – как-то так выстроить общение (необязательно только с моим участием), чтобы проблемы, которые есть у ребят, и их желание развиваться – не терялись, и доводились до логического завершения. Все нужно чинить и делать лучше. Может быть, можно сделать группы, в которых ребята, отвечающие за эти группы, будут общаться с разработчиками – чаще, чем могу себе позволить я – и решать их вопросы, либо эскалировать до меня, если нужно. Я думаю, так можно исправить потерю в коммуникациях: ведь, когда руководителю не хватает фокуса на разработчика – даже из-за того, что разработчиков попросту много – это влияет на его рост. Каждому разработчику нужно внимание – так, как будто мы с ним сидим за соседними столами и работаем вместе. Я уже решаю эту проблему, но она не решена.
Как строите процесс по управлению таким количеством человек? Сколько лидов? Тяжело ставить цели?
Непросто. Очень много коммуникаций. Вместо официальных лидов у нас в каждой команде роль лидера выполняет самый опытный разработчик, который непосредственно работает и общается с людьми, проводит ревью, декомпозирует и нарезает задачи. С каждым таким лидом мы коммуницируем, пересекаемся на ревью. Есть еще более крупные направления (B2B, B2C), и у каждого направления есть человек, который за него отвечает. Он выстраивает работу в своем направлении, в том числе работу с людьми. Я стараюсь общаться как со старшими разработчиками, так и с ведущими разработчиками направления, как можно чаще; еще у нас есть общие встречи старших разработчиков, где мы обсуждаем новости, проблемы команд и процессов, думаем, что делать. Я думаю, старшие разработчики должны ощущать себя некоторой командой, с которой можно свернуть любые горы – сделать процессы такими, как нужно, вместо того, чтобы смиряться с неудобствами.
Проводите 1 на 1? Как часто? Лайфхаки?
Собственно, у нас в компании ревью как раз называется «1 на 1». Сейчас я провожу со всеми старшими разработчиками ревью раз в месяц (это реже, чем рекомендуется – лучше проводить раз в пару недель). Зачастую нам есть, что обсуждать. Лайфхаков особых нет – в литературе достаточно подробно расписано про 1 на 1. Важно давать разработчику говорить – он должен говорить примерно 80% времени; в этом суть: задача руководителя – создать на ревью дружественную и безопасную атмосферу, чтобы разработчик мог ему рассказать все, что его беспокоит. Это довольно тяжело и не всегда получается, но круто, если 1 на 1 есть, и на них есть, что обсуждать. Их лучше проводить в неформальной обстановке – например, можно в парке. Создание комфортной атмосферы может быть разным – это не только переговорка в офисе.
Какие вакансии у вас открыты?
В каком направлении? У нас довольно много в разных направлениях. По фронтенду мы ищем нескольких миддл-разработчиков (по-моему, 2), можно и senior.
Какие сложные задачи возникают у руководителя?
Сложно говорить о сложности задач, когда ты их решаешь. Допустим, отказ от легаси – это сложная задача. Есть бизнес, который хочет развиваться; есть ты, руководитель, который хочет, чтобы легаси не стало. Нужно находить общий язык с бизнесом и добиваться внесения в бизнес-план задач по отказу от легаси, что нетривиально. Это требует хороших коммуникативных навыков, хорошего фокуса – нужно постоянно держать на пульсе руку; задача бизнеса – зарабатывать деньги, он не любит отказываться от работающих легаси-систем.
Сложная задача – придумывать задачи по улучшению работы в отделе. Нужно анализировать, с какими проблемами сталкиваются разработчики, не забывать улучшать dev-experience. Выявлять проблемы – это тоже нетривиально.
Рассматриваете фронтов на удаленке?
Мы предпочитаем работать в офисе, поэтому удаленку не рассматриваем. Естественно, сейчас вся работа как раз на удаленке – новых сотрудников мы подключаем тоже к удаленке, но с условием перемещения в офис после окончания эпидемии.
Что делать, если тимлид слабоват и явно не должен оставаться на позиции?
Нужно использовать механизм подачи обратной связи. Это мощный и классный механизм, но, конечно, нужно делать это аккуратно, чтобы человек не обиделся. Нужно уметь проявлять эмпатию, понимать чувства человека, давать в правильном направлении обратную связь. Он может либо принять, либо не принять ее; если он стал тимлидом, он должен уметь работать над собой и принимать обратную связь. Важно не просто дуться на него из-за того, что он «не дотягивает», а сказать ему конструктивно, что, на ваш взгляд, делается плохо, и узнать его мнение. Я сам не мастер подачи обратной связи, мне еще предстоит этому научиться, но я знаю главное правило: говорить про действие, а не про личность. Если рассказать лиду, какие вещи в команде проседают – может быть, все починится.
А что дальше?
30 июня в 20:00 в нашем
инстаграм-аккаунте будет выступать Влада Рау — Senior Digital Analyst в лондонском офисе McKinsey Digital Labs. Сейчас Влада занимается product/data engineering. До своего переезда в Лондон она дважды стажировалась в Google в Дублине, а также училась в ВШМ СПбГУ и IE Business School в Мадриде.
Задать ей вопрос можно в комментариях к этому посту.
Что было ранее
- Илона Папава, Senior Software Engineer в Facebook — как попасть на стажировку, получить оффер и все о работе в компании
- Борис Янгель, ML-инженер Яндекса — как не пополнить ряды стремных специалистов, если ты Data Scientist
- Александр Калошин, СEO LastBackend — как запустить стартап, выйти на рынок Китая и получить 15 млн инвестиций.
- Наталья Теплухина, Vue.js core team member, GoogleDevExpret — как пройти собеседование в GitLab, попасть в команду разработчиков Vue и стать Staff-engineer.
- Ашот Оганесян, технический директор и основатель DeviceLock — кто ворует и зарабатывает на ваших персональных данных.


Let's block ads! (Why?)






 Магнитная лента распространилась по миру уже после окончания войны, когда американские солдаты вывезли конфискованное оборудование из Германии. Один из них затем разработал новое устройство воспроизведения.
Магнитная лента распространилась по миру уже после окончания войны, когда американские солдаты вывезли конфискованное оборудование из Германии. Один из них затем разработал новое устройство воспроизведения.






 В JavaScript возможно применять оператор получения остатка от деления к числами с плавающей точкой. Работает это так:
В JavaScript возможно применять оператор получения остатка от деления к числами с плавающей точкой. Работает это так:
 В следующем примере условие оказывается истинным.
В следующем примере условие оказывается истинным.
 Этот код на JavaScript три раза выводит 3.
Этот код на JavaScript три раза выводит 3.
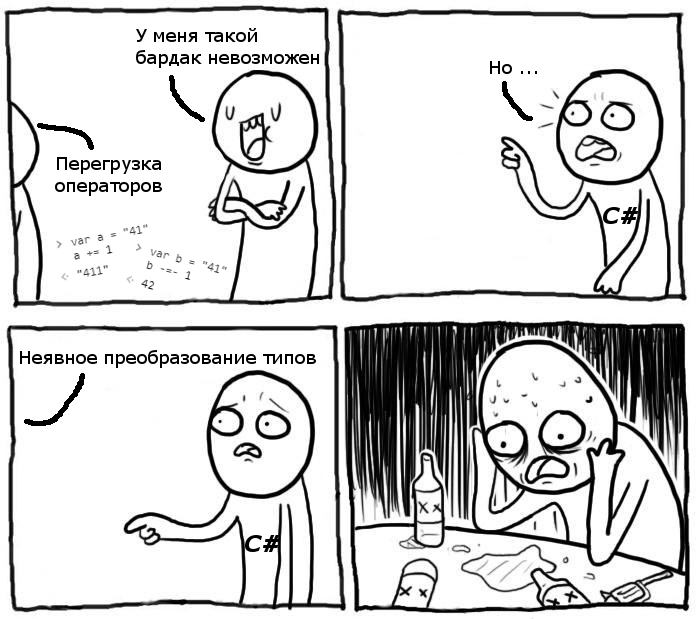
 Операторы в JavaScript иногда не отличаются коммутативностью.
Операторы в JavaScript иногда не отличаются коммутативностью.
 В JavaScript можно выполнять математические операции совместно над строками и числами.
В JavaScript можно выполнять математические операции совместно над строками и числами.
 В JavaScript строку «banana» можно получить следующим способом:
В JavaScript строку «banana» можно получить следующим способом: