Это статья о первых программных синтезаторах, которые были когда-то созданы на самых обычных персональных компьютерах. Я даю несколько практических примеров по реализации простых методов звукового синтеза в историческом контексте.
Перейти к первой части
Однобитный синтез
Моим первым персональным компьютером был клон ZX Spectrum 48K. В данной модели отсутствовал «музыкальный сопроцессор» и звуковые возможности ограничивались встроенным динамиком, которым можно было управлять с помощью вывода нулей или единиц в специальный однобитный порт. В руководстве к ZX-Бейсику существовала единственная команда для работы со звуком — BEEP, для которой требовалось задать высоту ноты и длительность. Этого хватало для простых одноголосных мелодий в духе популярных когда-то электронных музыкальных открыток.
Впрочем, как я быстро уловил, качество компьютерного звука, выдаваемого через динамик, сильно зависело от таланта программиста. Особенно это было заметно по играм: во многих из них звучание было примитивным, но существовали и удивительно хорошо звучащие музыкальные вещи. Самые качественные произведения воспроизводились во время статичных заставок. Громкость динамика при этом ощущалась ниже обычного (настолько, что иной раз приходилось ухо прикладывать к клавиатуре, чтобы уловить нюансы композиции). Зачастую, слышны были свист и искажения, как при плохой записи. Но, при всем этом, явственно можно было различить несколько одновременно звучащих голосов, присутствовали смена тембров, работа с амплитудной огибающей, пространственные эффекты, звучание ударных. К ZX Spectrum я еще вернусь после некоторого отступления.
Пример однобитного синтеза для ZX Spectrum, автор Tim Follin
Однобитная музыка является старейшей среди прочей компьютерной музыки. Еще в начале 50-х годов на первых компьютерах в Австралии и Англии проводились эксперименты с воспроизведением мелодий. Разумеется, в те времена создатели компьютеров не думали о каких-то задачах из области музыки. Динамик предназначался исключительно для целей отладки и диагностики работы вычислительной машины. Тем не менее, в свободное от работы время и потратив на это массу сил, хакеры начала 50-х заставили свои компьютеры проигрывать простейшие мелодии. В арсенале тогдашних компьютерных музыкантов было только два уровня сигнала, подаваемого на динамик.
Появление динамика на одном из первых микрокомпьютеров, Apple II, было связано с желанием Стива Возняка портировать на свой компьютер игру Breakout. В оригинальном игровом автомате от Atari имелись звуки, поэтому Возняк и добавил динамик в Apple II. Серьезной проблемой для программиста при работе с динамиком являлась необходимость совмещать вывод звука с другими задачами. Для корректного формирования меандра приходилось тщательно выверять такты процессора. В этом отношении несколько проще дела обстояли в IBM PC, поскольку на нем задача генерирования меандра могла быть возложена на отдельную микросхему таймера. Но даже эта микросхема не слишком помогала в использовании широтно-импульсной модуляции (ШИМ, PWM) — способа для вывода многоразрядных звуковых данных на динамик.
Вывод многоразрядного звука на динамик с помощью ШИМ заключается в передаче аудиоданных с использованием прямоугольного сигнала-несущей, ширина импульса которой модулируется (управляется) значениями уровня амплитуды. При получении очередного значения амплитуды компьютер тратит дополнительное время на генерирование несущей с жестко заданным периодом, который зависит от желаемой разрядности звука. В случае ШИМ за наличие всего двух уровней квантования сигнала приходится расплачиваться значительно возросшим разрешением во временной области при передаче данных. Неудивительно поэтому, что наиболее эффективно ШИМ использовалась не на микрокомпьютерах, а на PC. Причины связаны как с быстродействием, так и с объемом памяти, ведь с помощью ШИМ чаще всего воспроизводили оцифрованную музыку. Особенно симпатично такая музыка звучала в заставках PC-игр второй половины 80-х от французской компании Loriciel.
Чтобы завершить тему PC, упомяну об одном распространенном подходе к имитации полифонического звучания для динамика. В большинстве случаев на стадии игрового процесса было слишком накладно выводить многоразрядный звук с помощью ШИМ. Вместо этого проигрываемые голоса попросту чередовались с заданным временным интервалом. Чем короче период чередования, тем более качественное «полифоническое» звучание можно получить, но это потребует и большей активности со стороны процессора. Любопытно, что такого рода прием давно известен в классической музыке под названием скрытого многоголосия и использовался, например, в баховских сюитах для виолончели соло. Ощущение полифонии слушателем при скрытом многоголосии является, в большей степени, психоакустическим эффектом. Феномен схожего рода возникает в однобитной музыке и во время исполнения звуков ударных. Все остальные голоса при этом просто замолкают, ведь реальное микширование каналов не используется, но мозг слушателя автоматически достраивает несуществующее в данный момент звучание.
Пример однобитного синтеза для ZX Spectrum, авторы Jonathan Smith и Keith Tinman
Вернемся, наконец, к ZX Spectrum. Однобитная музыка второй половины 80-х для этого микрокомпьютера отличалась особенным своеобразием. У ZX Spectrum, разумеется, не было возможностей PC для эффективной поддержки подходов к выводу звука, о которых говорилось выше. Но при этом, популярность Speccy стимулировала интерес разработчиков к поиску нетривиальных приемов воспроизведения звука с помощью динамика.
Простейший однобитный синтез к середине 80-х был хорошо известен разработчикам ZX Spectrum. Основа его в том, что при генерировании прямоугольного сигнала (последовательно отправляя нули и единицы в порт динамика) есть возможность управлять двумя параметрами: частотой сигнала и шириной импульса. В результате, модулируя по некоторому закону частоту, можно получить разновидность FM-синтеза, о котором говорилось в одном из предыдущих разделов. Кроме того, достижимы и эффекты на основе ШИМ. Здесь важно отличать подход ШИМ для вывода многоразрядного звука, где частота несущей может составлять мегагерцы, от ШИМ, влияющей на тембр, в духе звучания знаменитых звуковых микросхем SID (Commodore C64) и 2A03 (NES). Управляя данными параметрами можно получить достаточно широкую палитру интересных тембров. Единственный недостаток — все это работает в режиме одного голоса.
Одним из первых на ZX Spectrum многоканальный однобитный синтез начал применять Тим Фоллин (Tim Follin). Юный музыкант и программист из Англии (на момент создания своих знаменитых однобитных синтезаторов ему было 15-16 лет) в первых своих композициях для игр использовал 2-3 канала, но уже к 1987 году его музыка насчитывала более 5 каналов с использованием нескольких тембров, амплитудных огибающих, пространственных эффектов и ударных.
Вместо меандра, у которого ширина импульса равна половине периода, Фоллин использовал форму волны c весьма узкой шириной импульса. В результате получался характерный «игольчатый» тембр, отдаленно напоминающий звучание язычковых инструментов, таких, как губная гармоника. При этом, в заданных узких пределах ширину импульса можно было регулировать, что отражалось на громкости, и, дополнительно, на тембре. Микширование нескольких виртуальных каналов Фоллин реализовал с помощью последовательного вывода значений в порт в духе скрытого многоголосия, но на значительно более высокой частоте, чем в случае PC.
На этой основе композитор создавал более сложные элементы, такие как амплитудные огибающие, эффекты флэнжер и эхо. Уникальность композиций Фоллина обусловлена тем, что их автор являлся в то время не только талантливым музыкантом с отличным вкусом, но и неплохим программистом, который самостоятельно реализовывал свои однобитные синтезаторы.
К слову сказать, на некоторых микрокомпьютерах 80-х, включающих в себя звуковые микросхемы, тоже использовались некоторые элементы программного синтеза. Для получения большего разнообразия тембров находчивые музыканты использовали ряд трюков, связанных с модуляцией параметров звуковых чипов. Например, на Commodore C64 сложные тембры компоновались из нескольких базовых форм волны путем их быстрого переключения, а на Atari ST имитация звучания ШИМ в духе чипа SID была реализована путем управления одним из аппаратных каналов микросхемы AY-3-8910 с помощью прерывания таймера.
Где сегодня используется однобитный звук? Судя по всему, тема синтеза для динамика оказалась неисчерпаемой, поскольку энтузиасты ZX Spectrum и поныне продолжают совершенствовать свои движки с количеством каналов, которое уже перевалило за десяток. На смену ШИМ в качестве метода для вывода многоразрядных данных пришла плотностно-импульсная модуляция, которая применяется в высококачественных аудиосистемах. В академической сфере об эстетике однобитной музыки пишут научные статьи и даже используют однобитные генераторы в концертах камерной музыки.
Практика
Давайте рассмотрим устройство музыкальной программы Тима Фоллина, опубликованной в августовском номере журнала Your Sinclair за 1987 год. В заметке, озаглавленной Star Tip 2, говорится лишь, что в приведенном коде используется 3 канала звучания.

Заметка Star Tip 2 из журнала Your Sinclair
К счастью, результат дизассемблирования HEX-дампа, напечатанного в журнале, можно найти в интернете. Видно, что программа состоит из небольшого плеера, за которым следует некоторое число фреймов музыкальных данных.
Как же устроен синтез из Star Tip 2? Каждый голос определяется периодом и шириной импульса. Вместо реального микширования голоса выводятся на динамик последовательно. Имеется 16 возможных значений ширины импульса. Данный параметр задается разом для всех 3 выводимых голосов и соответствует ощущаемой в данный момент их общей громкости. Остальная часть кода для исполнения фрейма связана с организацией «амплитудной» огибающей, которая динамически управляет общим для голосов параметром ширины импульса.
Синтез организован таким образом, что после последовательной обработки счетчиков голосов и возможного вывода данных на динамик используется еще некоторое число тактов для организации работы огибающих. Более того, после завершения проигрывания очередного фрейма, некоторое количество тактов затрачивается на чтение параметров следующего фрейма. Все эти задержки не оказывают такого разрушительного влияния на звук, как это можно было бы ожидать.
При моделировании кода Star Tip 2 на Питоне возникает проблема с частотой дискретизации. 44100 Гц не хватает для организации вывода голосов с учетом необходимого контроля ширины узких импульсов. Наилучшим вариантом было бы выполнение кода плеера на частоте процессора Z80 (3.5 МГц) с дальнейшим понижением частоты результата до 44100 Гц. Передискретизацию, или, если говорить конкретнее, понижение частоты дискретизации (прореживание или децимацию) необходимо производить аккуратно, с предварительным удалением частот, лежащих вне целевого диапазона, а не просто отбрасывая лишние сэмплы. Простым вариантом реализации фильтра для децимации является использование скользящего среднего (см. функцию decimate). Обратите внимание, что в приведенном далее коде я использую коэффициент децимации равный лишь 32 для ускорения работы программы. Константы T1 и T2 были выбраны на слух и с учетом известной длины мелодии.

Фрагмент композиции Star Tip 2, в увеличенном масштабе представлена «игольчатая» форма сигнала
def decimate(samples, m):
x_pos = 0
x_delay = [0] * m
y = 0
for i, x in enumerate(samples):
y += x - x_delay[x_pos]
x_delay[x_pos] = x
x_pos = (x_pos + 1) % len(x_delay)
samples[i] = y / m
return samples[::m]
# Коэффициент децимации
M = 32
# Уровни громкости динамика
ON = 0.5
OFF = 0
# Задержки при отправке данных в порт динамика
T1 = 6
T2 = 54
def out(samples, x, t):
samples += [x] * t
# Синтез 3 голосов на основе параметров фрейма
def engine(samples, dur, t1, t2, vol, periods):
counters = periods[:]
t1_counter = t1
t2_counter = t2
update_counter = t1
width = 1
is_slide_up = True
for d in range(dur):
for i in range(3):
counters[i] -= 1
if counters[i] == 0:
out(samples, ON, width * T1)
out(samples, OFF, (16 - width) * T1)
counters[i] = periods[i]
# Далее происходит обработка огибающей в двух режимах: нарастание и спад
update_counter -= 1
if update_counter == 0:
update_counter = 10
if is_slide_up:
t1_counter -= 1
if t1_counter == 0:
t1_counter = t1
width += 1
if width == 15:
width = 14
is_slide_up = False
else:
t2_counter -= 1
if t2_counter == 0:
t2_counter = t2
if width - 1 != vol:
width -= 1
out(samples, samples[-1], T2)
# Чтение и проигрывание фреймов
def play(samples, frames):
dur = 0
vol = 0
t1 = 0
t2 = 0
i = 0
while frames[i] != 0:
if frames[i] == 0xff:
dur = frames[i + 2] << 8 | frames[i + 1]
t1, t2, vol = frames[i + 3:i + 6]
i += 6
else:
engine(samples, dur, t1, t2, vol, frames[i: i + 3])
i += 3
samples = [0]
with open("startip2.txt") as f:
frames = [int(x, 16) for x in f.read().split()]
play(samples, frames)
write_wave("startip2.wav", decimate(samples, M))
Исходный код
Фреймы
Звучание
Необычное звучание на 26 секунде в wav-файле создается с помощью эффекта флэнжер, путем введения очень короткой задержки между идентичными голосами.
Алгоритмы передискретизации широко используются в реализациях современных программных синтезаторов. В частности, использование подобных алгоритмов является еще одним, помимо уже известного нам FM-синтеза с обратной связью, способом борьбы с явлением наложения частот при воспроизведении волновых форм. Кроме того, как показывает данный пример, без подобных алгоритмов трудно обойтись при моделировании звучания старинных звуковых чипов (AY-3-8910, SID и т.д.).
Sonix
В 1985 году на свет появился персональный компьютер Commodore Amiga 1000, у которого для работы со звуком использовался специальный чип Paula. Возможности Paula разительно отличались от типичных звуковых микросхем, которые использовались в домашних компьютерах того времени. В распоряжении пользователя на Amiga находились 4 аппаратных аудиоканала с разрядностью по 8 бит каждый и настраиваемой для каждого канала частотой дискретизации до 28.8 кГц. Схожими характеристиками обладал популярный в среде музыкантов сэмплер E-MU Emulator. С точки зрения программиста особенно удобной была организация в данном компьютере вывода многоканального звука практически без участия центрального процессора.
Хотя Amiga и позиционировалась в качестве компьютера для творческих людей, она, все же, потерпела поражение в схватке с Atari ST за внимание со стороны профессиональных музыкантов. В Atari ST была встроенная поддержка MIDI-интерфейса, а у Amiga ее не было. Более того, на первых Amiga существовали определенные проблемы с использованием последовательного порта для соединения по MIDI. В результате Amiga стала отличной системой для компьютерных музыкантов-любителей, которые сами написали для себя нужные программы — музыкальные трекеры с их своеобразной нотацией нотных событий и сэмплами в качестве инструментов.
Программные синтезаторы для Amiga были редкостью, что объяснимо, в том числе, нехваткой быстродействия процессора. Тем не менее, программный синтез на Amiga существовал, например, в виде FM-синтезаторов (FMsynth). Самой же первой реализацией программного синтеза для Amiga стало приложение MusiCraft, которое использовалась компанией Commodore для демонстрации возможностей нового компьютера. В 1986 году MusiCraft был продан компании Aegis и, после некоторых доработок, вышел на рынок под именем Sonix.
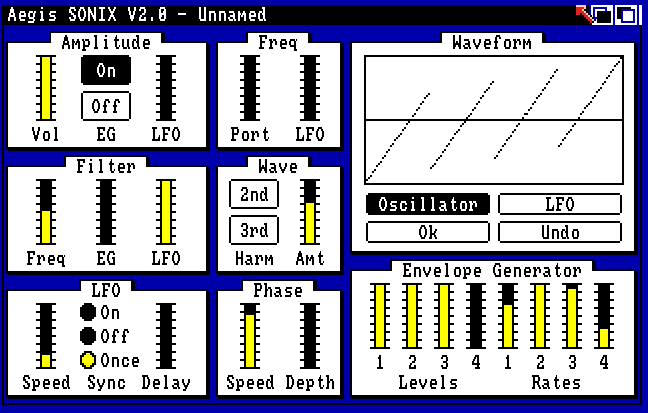
Окно параметров Sonix
Sonix представляет собой модель аналогового синтезатора, работающую в реальном времени с полифонией до 4 голосов. Возможности этого старинного программного синтезатора не так уж сильно отличаются от современных VSTi-плагинов: есть осциллятор с выбором формы волны, фильтр с настраиваемой частотой среза (но без резонанса), ADSR-огибающая, LFO (генератор сигнала низкой частоты). Форму волны для осциллятора и LFO можно изобразить с помощью мыши. В Sonix использовано остроумное решение для имитации звучания резонанса: по нажатию на экранную кнопку изображение формы волны попросту заменяется несколькими ее повторениями в пределах того же периода, что приводит к характерному звучанию. Также в наличии имеется эффект флэнжер с настраиваемыми параметрами. Хотя возможности Sonix кажутся по нынешним временем весьма скромными, синтезатор отличает достаточно широкая палитра звучаний. Единственное, несколько странным на сегодняшний взгляд кажется решение разработчиков использовать классический нотный стан для написания музыки в Sonix.
Практика
Теперь давайте попробуем создать, в духе Sonix, модель осциллятора и фильтра аналогового синтезатора. В качестве осциллятора будет использоваться генератор пилообразного сигнала. Для избавления от явно слышимых проявлений эффекта наложения частот воспользуемся FM-синтезом с обратной связью. Любопытно отметить, что с помощью регулирования уровня обратной связи можно сразу получить некоторый эффект НЧ-фильтра, но это будет работать только для конкретного осциллятора, а не для любого входного сигнала.
Как и в случае Sonix, реализовываться будет фильтр нижних частот без управления резонансом. Обратите внимание на реализацию НЧ-фильтра 1 порядка (см. определение класса Lp1 в коде ниже). Хотя такой фильтр не отличается высокой крутизной среза частот, он требует лишь всего одного умножения и может использоваться, например, для сглаживания значений управляющих параметров. Кроме того, данный фильтр может применяться и в качестве строительного блока для построения более сложных фильтров в каскадной форме. В частности, знаменитый фильтр Муга содержит 4 последовательно соединенных НЧ-фильтра 1 порядка. Такая каскадная схема реализована и в данном примере.
Дополнительный осциллятор lfo1 (генератор синусоиды) используется в автоматизации управления частотой среза фильтра. Для демонстрации я взял знаменитую нотную последовательность из композиции On the Run группы Пинк Флойд.
# Реализация генератора пилообразного сигнала
# с помощью FM-синтеза с обратной связью,
# используется ранее определенный класс Sine
class Saw:
def __init__(self):
self.o = Sine()
self.fb = 0
def next(self, freq, cutoff=2):
o = self.o.next(freq, cutoff * self.fb)
# Используется усреднение для уменьшения эффекта наложения частот
self.fb = (o + self.fb) * 0.5
return self.fb
# НЧ-фильтр 1 порядка
class Lp1:
def __init__(self):
self.y = 0
# Частота среза cutoff в пределах 0..1
def next(self, x, cutoff):
self.y += cutoff * (x - self.y)
return self.y
# E3, G3, A3, G3, D4, C4, D4, E4, 165 BPM
ON_THE_RUN = [82.41, 98, 110, 98, 146.83, 130.81, 146.83, 164.81]
osc1 = Saw()
lfo1 = Sine()
flt1 = Lp1()
flt2 = Lp1()
flt3 = Lp1()
flt4 = Lp1()
samples = []
for bars in range(16):
for freq in ON_THE_RUN:
for t in range(int(sec(0.09))):
x = osc1.next(freq)
cutoff = 0.5 + lfo1.next(0.2) * 0.4
x = flt1.next(x, cutoff)
x = flt2.next(x, cutoff)
x = flt3.next(x, cutoff)
x = flt4.next(x, cutoff)
samples.append(0.5 * x)
write_wave("on_the_run.wav", samples)
Исходный код
Звучание
Моделирование фильтров аналоговых синтезаторов — обширная тема, по которой можно рекомендовать хорошую современную книгу The Art of VA Filter Design. Автор этой книги, Вадим Завалишин, в конце 90-х создал программный синтезатор Sync Modular и, далее, стал одним из ключевых разработчиков знаменитого синтезатора NI Reaktor. Технология Core, разработанная Завалишиным, имеет отношение к тем самым блокам и проводам, пример работы с которыми был приведен в одном из предыдущих разделов. В случае Core графы транслируются в эффективный машинный код каждый раз, когда меняется их структура и происходит это прямо в процессе работы с синтезатором.
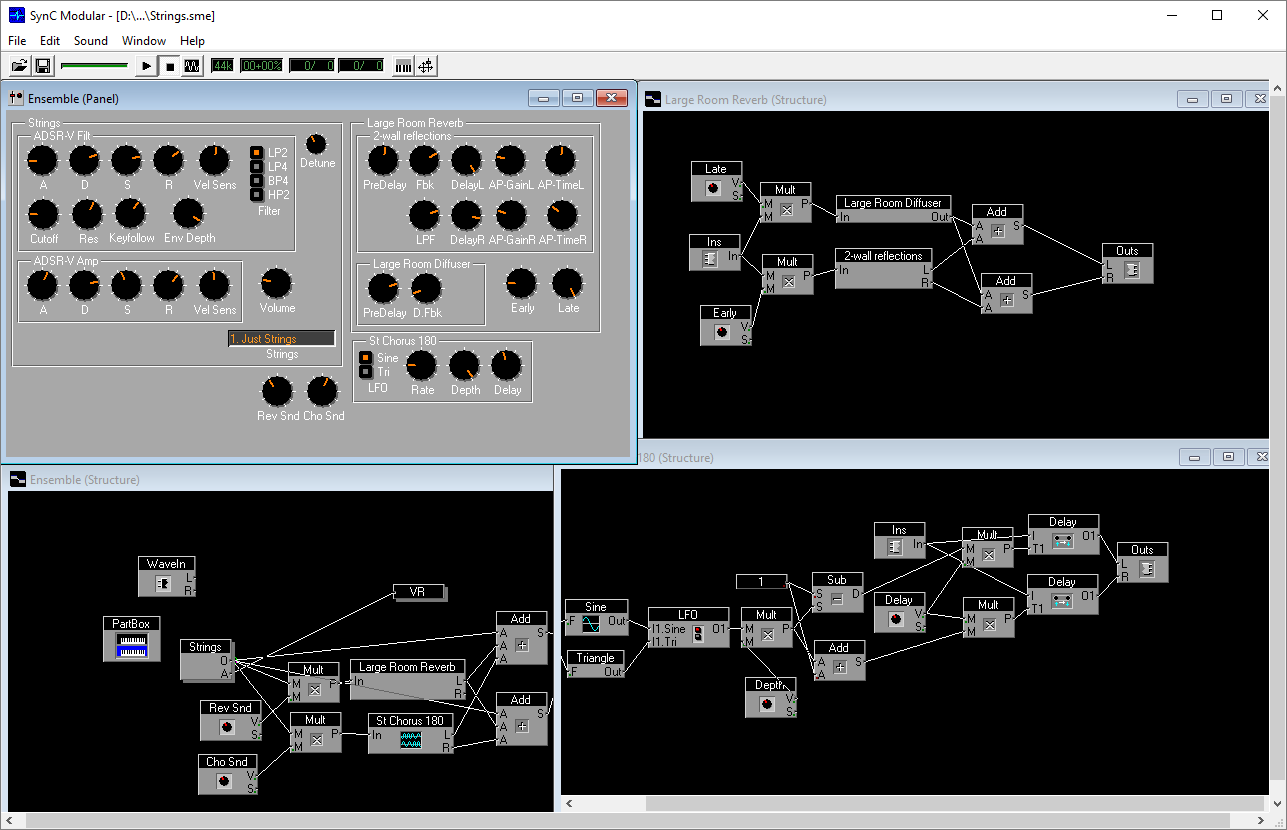
Интерфейс Sync Modular
Music Kit
1988 год. На сцене концертного зала играет необычный дуэт, состоящий из профессионального скрипача и компьютера, который генерирует в реальном времени звучание струнных c помощью синтеза на основе физического моделирования. Именно таким образом Стив Джобс решил завершить презентацию своего нового детища — персонального компьютера NeXT. Джобс сделал все от него зависящее, чтобы звуковые возможности нового компьютера не имели равных среди конкурентов. Сложный звуковой синтез на NeXT производился с использованием основного 32-битного процессора, математического сопроцессора, а также специально выделенного для задач, связанных со звуком, DSP-процессора. Вывод аудио в NeXT осуществлялся в режиме стерео, 44100 Гц, 16 бит.
Джобс понимал, что для того, чтобы задействовать в полном объеме мощную аппаратную часть, ему понадобится команда профессионалов компьютерного звука. По этой причине он обратился Джулиусу Смиту (Julius Smith), одному из лучших специалистов в области музыкальной цифровой обработки сигналов из Стэнфордского университета.
Смит и еще один выходец из Стэнфорда, Дэвид Яффе (David Jaffe), создали систему Music Kit для NeXT. Эта система объединяла MIDI-подход для работы с нотными событиями с подходом описания звуковых модулей и связей между ними из MUSIC N. Music Kit брала на себя управление DSP-процессором, занималась распределением ресурсов и предоставляла разработчику высокоуровневый интерфейс в виде набора объектов, которые могли быть использованы в создании конечных GUI-приложений, связанных со звуком.
В рамках Music Kit были реализованы различные виды синтеза звука. Вариант, прозвучавший на презентации 1988 года, основан на алгоритме Карплуса-Стронга (Karplus-Strong). Это удивительно простой алгоритм, придуманный еще в конце 70-х, который позволяет моделировать звучание затухающих колебаний струны. В первоначальной версии данный алгоритм использует циклический буфер (линию задержки), длина которого соответствует периоду колебаний моделируемой струны. Для создания начальных условий для затухающих колебаний в буфер помещаются случайные значения. Далее последовательное чтение из буфера сопровождается усреднением очередной пары соседних отсчетов, то есть фильтрацией, которая может быть реализована без операций умножения. Подход Карплуса-Стронга Смит развил до синтеза на основе цифровых волноводов (digital waveguide), который сейчас является общим подходом к физическому моделированию различных акустических инструментов. Данная технология применялась компаниями Yamaha и Korg в своих синтезаторах на основе физического моделирования.
Приложения для Music Kit, как и сам компьютер NeXT, были известны, в основном, в университетской среде. Среди разработок можно выделить несколько визуальных сред музыкального программирования (SynthEdit, SynthBuilder), а также синтезатор поющего голоса (SPASM). Кроме того, с помощью Music Kit были созданы физические модели самых различных акустических инструментов.
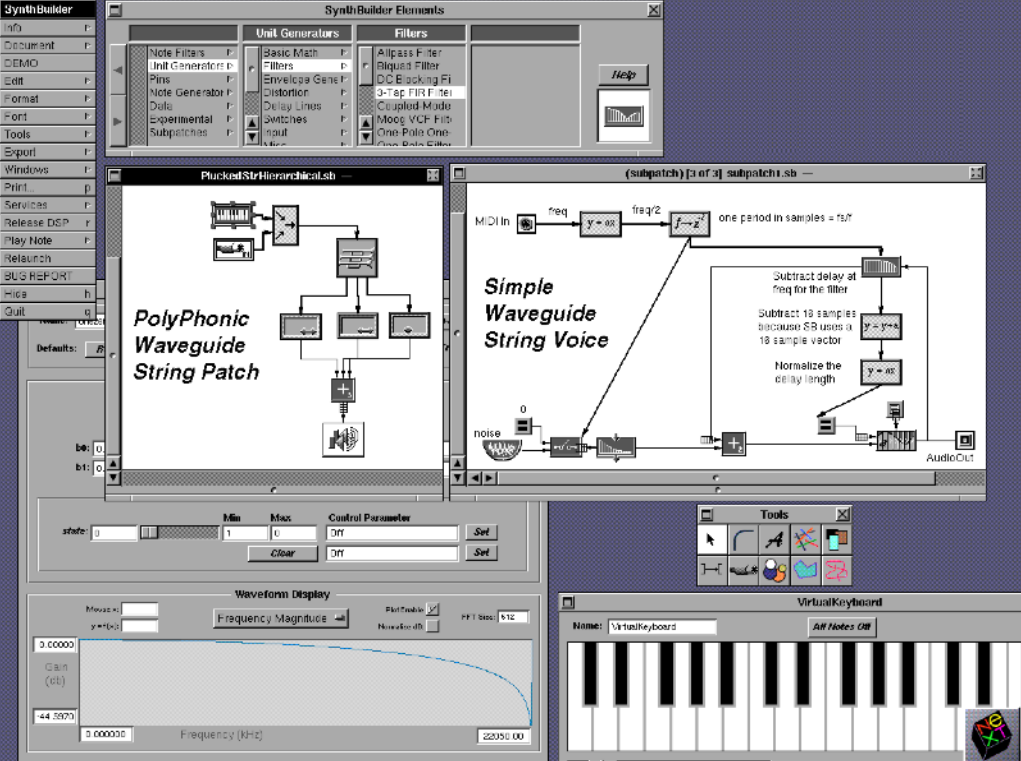
Среда SynthBuilder на базе Music Kit
С начала 90-х система Music Kit развивалась в стенах Стэнфордского университета, а Стив Джобс принял заслуживающее особого уважения решение открыть ее код. Появилась версия Music Kit для PC, но, к сожалению, распространения она так и не получила.
Практика
В данном примере мы рассмотрим реализацию простой модели акустической бас-гитары методом Карплуса-Стронга. Модель будет состоять из следующих элементов: генератор шума, линия задержки, НЧ-фильтр. Ключевым элементом является линия задержки, которая имитирует колебания струны. В момент очередного «удара по струне» в буфер линии задержки попадают значения из генератора шума и количество этих значений зависит от силы «удара». Случайные значения создают эффект более естественного звучания, когда каждый удар по струне несколько отличается от предыдущего. Длина буфера линии задержки соответствует периоду колебания и чтение очередного сэмпла результата происходит по индексу, который перемещается в пределах размера буфера. Для создания эффекта колебаний струны, при которых высокие гармоники затухают быстрее, чем низкие, используется НЧ-фильтр, который применяется к значению по текущему индексу в буфере линии задержки.
В оригинальном варианте алгоритма НЧ-фильтр представляет собой простое усреднение значений двух сэмплов, которое можно реализовать без операции умножения, но при такой реализации проявляется нежелательный эффект: высокие ноты затухают слишком быстро, а низкие, соответственно, слишком медленно. В представленном ниже коде используется НЧ-фильтр 1 порядка, реализованный в предыдущем разделе. Этот фильтр, с помощью соответствующего параметра, позволяет установить для конкретной ноты нужное значение частоты среза.
# "Щипок" струны (используется класс Lp1 из предыдущего раздела),
# amp: амплитуда ноты,
# freq: частота ноты,
# dur: длительность ноты
def pluck(samples, amp, freq, dur):
flt = Lp1()
delay_buf = [0] * int(SR / freq)
delay_pos = 0
for i in range(int(len(delay_buf) * amp)):
delay_buf[i] = random.random()
for t in range(int(sec(dur))):
delay_buf[delay_pos] = flt.next(delay_buf[delay_pos], 220 / len(delay_buf))
samples.append(amp * delay_buf[delay_pos])
delay_pos = (delay_pos + 1) % len(delay_buf)
# Пауза в звучании длительностью dur,
# Обратите внимание, что здесь повторяется последнее значение
# из буфера сэмплов, это позволяет избежать сильных скачков амплитуды
def rest(samples, dur):
for t in range(int(sec(dur))):
samples.append(samples[-1])
samples = []
for i in range(4):
pluck(samples, 0.7, 58, 0.27)
pluck(samples, 0.4, 62, 0.27)
pluck(samples, 0.4, 66, 0.27)
pluck(samples, 0.6, 69, 0.27)
pluck(samples, 0.5, 138, 0.01)
rest(samples, 0.13)
pluck(samples, 0.7, 123, 0.13)
rest(samples, 0.27)
pluck(samples, 0.7, 139, 0.47)
rest(samples, 0.07)
pluck(samples, 0.7, 78, 0.27)
pluck(samples, 0.4, 82, 0.27)
pluck(samples, 0.4, 87, 0.27)
pluck(samples, 0.6, 92, 0.27)
pluck(samples, 0.5, 184, 0.01)
rest(samples, 0.13)
pluck(samples, 0.7, 139, 0.13)
rest(samples, 0.27)
pluck(samples, 0.7, 165, 0.47)
rest(samples, 0.07)
write_wave("chameleon.wav", samples)
Исходный код
Звучание
Остается добавить, что в качестве демонстрации звучания я выбрал басовый рифф из композиции Chameleon Херби Хэнкока.
Заключение
В 90-е годы программные синтезаторы для PC и Mac пережили бурное развитие. Среди наиболее необычных программ можно упомянуть MetaSynth, с помощью которой, в духе советского синтезатора «АНС» Е.А. Мурзина, можно было генерировать звук на основе изображения. Одним из пользователей MetaSynth был известный электронный музыкант Эфекс Твин (Aphex Twin). В 1999 году компания Steinberg выпустила вторую версию своего формата аудиоплагинов VST, в котором поддерживались входные MIDI-данные. Так появились столь популярные сегодня VST-синтезаторы.
В последние годы основные исследования по части синтеза звука сосредоточены на детальном моделировании элементов аналоговых синтезаторов. Синтез на основе физического моделирования акустических инструментов и более экзотические подходы к созданию тембров оказались не слишком востребованы музыкантами. Как мне думается, в настоящий момент у большинства музыкантов просто нет художественных задач, требующих использования сложных и абстрактных схем синтеза звука.
Однако, сложный звуковой дизайн все еще востребован в кино. Одним из исторических и вдохновляющих меня примеров компьютерного звукового дизайна является композиция Deep Note, созданная Джеймсом Мурером (James A. Moorer) из Стэнфордского университета. Эта короткая композиция звучала в американских кинотеатрах каждый раз, когда на экране появлялся логотип технологии THX. Создание DeepNote потребовало от ее автора знаний в области музыкального программирования. Такого рода композицию, где практически не используются типовые музыкальные элементы, сложно сочинить в современных редакторах, рассчитанных на устоявшийся процесс работы пользователя. Еще одним примером из области кино является система визуального музыкального программирования Kyma, которая и в наше время используется в озвучивании голливудских фильмов.
Оптимизм вызывает также недавний (2010 год) выход серьезного учебника Энди Фарнелла (Andy Farnell) Designing Sound. Эта книга полностью посвящена компьютерному звуковому синтезу с примерами на визуальном аудиоязыке Pure Data.
Наконец, сложные схемы алгоритмического звукового дизайна могут применяться в компьютерных играх. В частности, это касается моделирования природных явлений или звуков различных механизмов, шума двигателя. Соответствующие методы синтеза звука уже некоторое время используются в играх и в будущем, следует надеяться, будут использоваться более широко.
Let's block ads! (Why?)