Не так уж и давно стало популярным использовать видеокарты для вычислений. В один прекрасный день, несколько лет назад и я взглянул на новую, тогда, технологию CUDA. В руках была хорошая карточка по тем временам GTX8800, да и задачки для распараллеливания тоже были.
Кто работал с GPU, знает про объединение запросов, конфликт банков и как с этим бороться, а если не работал, то можно найти несколько полезных статей по основам программирования на CUDA
[1]. Карта GTX8800, в некотором смысле, была хороша тем, что была одной из первых и поддерживала только первые версии CUDA, поэтому на ней было четко заметно, когда есть конфликты банков или запросы в глобальную память не объединяются, потому что время в этом случае увеличивалось в разы. Все это помогало лучше понять все правила работы с картой и писать нормальный код.
В новые модели добавляют все больше и больше функциональности, что облегчает и ускорят разработку. Появились атомарные операции, кеш, динамический параллелизм и т.д.
В посте я расскажу про пространственно-временную фильтрацию изображений и реализацию для compute capability = 1.0, и как можно ускорить получившийся результат за счет новых возможностей.
Временная фильтрация может пригодиться при наблюдении за спутниками или в прочих ситуациях фильтрации, когда требуется точное подавление фона.

Сократил насколько смог, но самое главное оставил. Итак, на вход поступает последовательность кадров. Каждый кадр можно представить в виде суммы шума матрицы, фона и полезного сигнала.

Используя несколько предыдущих кадров можно обелить вновь пришедший кадр и выделить сигнал в случае его наличия. Для этого необходимо спрогнозировать фон на этом кадре, получить его оценку, по реализации в предыдущих кадрах. Пусть число кадров в истории N, тогда оценку фона можно представить как сумму кадров с некоторыми весами.

Критерием качества будет разность кадра и предсказанного фона, которую необходимо минимизировать.

Решение имеет вид:

Выборочная корреляционная матрица вычисляется как:

а вектор правой части имеет вид:

где k,l- изменяются от 1 до N.
Однако этот метод не учитывает сдвига кадров. Если представить коэффициенты

в виде явной функции сдвига

относительно некоторого опорного кадра, то можно сформулировать критерий качества и выписать решение. Здесь должно быть много формул, но в результате
зависит только от сдвигов.
Сдвиги вычисляются относительно некоторого опорного кадра

по следующим формулам:

Зная сдвиги кадров относительно опорного кадра, вычисляем вектор коэффициентов a(t) по следующей формуле:

Где α- вектор коэффициентов полинома степени n, γ — достаточно малая величина, E — единичная матрица.

Рассмотрим реализацию второго способа фильтрации. На GPU выгодно перенести функцию обеления кадров и функцию нахождения сдвигов кадра. Функция вычисления коэффициентов для обеления по известным сдвигам занимает мало времени и слишком малоразмерная задача.
Сразу оговорюсь, что это один из первых проектов который я писал, поэтому код не претендует на совершенство, однако, я постараюсь указать на недостатки и пути их исправления, часть из них мы исправим и посмотрим на результат.
Сначала в память видеокарты необходимо перекинуть последовательность кадров. Для этого нужно выделить массив с указателями на память GPU и потом его тоже скопировать в память GPU.
float **h_array_list, **d_array_list;
h_array_list = ( float** )malloc( num_arrays * sizeof( float* ));
cudaMalloc((void**)&d_array_list, num_arrays * sizeof( float * ));
for ( int i = 0; i < num_arrays; i++ )
cudaMalloc((void**)&h_array_list[i], data_size);
cudaMemcpy( d_array_list, h_array_list, num_arrays * sizeof(float*), cudaMemcpyHostToDevice );
При такой организации есть небольшой недостаток. Если читать из кадра следующим образом
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
int aBegin = nx * BLOCK_SIZE * by + BLOCK_SIZE * bx;
float a = inFrame[ j ][ aBegin + nx * ty + tx]
то в ранних версиях compute capability при таком чтении запросы в глобальную память не объединялись.
Это сейчас есть кеш и указатели на кадры оседают в нем и быстро читаются. Для удовлетворения правил объединения запросов необходимо или загрузить предварительно эти указатели в разделяемую память (на что тоже потребуется время) или же сделать, например, вот так:
float **h_array_list, **d_array_list;
h_array_list = ( float** )malloc( 16 * num_arrays * sizeof( float* ) );
cudaMalloc((void**)&d_array_list, 16 * num_arrays * sizeof(float *));
for ( int i = 0; i < num_arrays; i++ )
{
cudaMalloc((void**)&h_array_list[i*16], data_size);
for( int j = 1; j < 16; j++ )
h_array_list[ i*16 + j ] = h_array_list[ i*16 ];
}
cudaMemcpy( d_array_list, h_array_list, 16*num_arrays * sizeof(float*), cudaMemcpyHostToDevice );
В этом случае запрос на чтение будет объединен и мы ощутим заметный прирост скорости.
Функция обеления кадров для GPU выглядит примерно так:
__global__ void kernelWhite( float * out, float ** inFrame, float *at, int nx, int mem )
{
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
int aBegin = nx * BLOCK_SIZE * by + BLOCK_SIZE * bx;
__shared__ float frame1 [BLOCK_SIZE][BLOCK_SIZE];
__shared__ float a [32];
int i = ty * BLOCK_SIZE + tx;
// загрузка вектора коэффициентов
if( i < mem )
a[ i ] = at[ i ];
__syncthreads ();
frame1 [ty][tx] = 0;
// в цикле читаем кадры и находим обеленный кадр
for( int j = 0; j < mem; j++ )
{
frame1 [ty][tx] += a[ j ]*inFrame[ j*16 + tx ][ aBegin + nx * ty + tx];
}
// записываем результат
out [ aBegin + nx * ty + tx ] = inFrame[ mem*16 + tx ][ aBegin + nx * ty + tx] - frame1 [ty][tx];
}
В целом здесь все просто, мы создаем разделяемую память для результата обеления кадра, подгружаем наш вектор коэффициентов, синхронизуем потоки и дальше в цикле обеляем наш кадр с этими коэффициентами. Также здесь можно выбрать не квадратный блок потоков, а линейный, что в целом будет даже правильнее, так как сократит число вычислений в индексации.
Для функции поиска сдвигов использовался стандартный оптимизированный алгоритм для поиска суммы массива[2]. В этой функции необходимо сначала найти коэффициенты rij, gij, hij а затем посчитать по приведенным выше формулам суммы.
__global__ void kernelShift ( float *inFrameR, float *inFrame, float *outData, int nx )
__global__ void kernelShift ( float *inFrameR, float *inFrame, float *outData, int nx )
{
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
int aBegin = nx * BLOCK_SIZE * by + BLOCK_SIZE * bx;
// массивы для хранения данных в разделяемой памяти
__shared__ float rij [BLOCK_SIZE*BLOCK_SIZE];
__shared__ float gij [BLOCK_SIZE*BLOCK_SIZE];
__shared__ float hij [BLOCK_SIZE*BLOCK_SIZE];
__shared__ float tmp [BLOCK_SIZE*BLOCK_SIZE];
__shared__ float p [BLOCK_SIZE*BLOCK_SIZE];
__shared__ float q [BLOCK_SIZE*BLOCK_SIZE];
__shared__ float frame1 [BLOCK_SIZE][BLOCK_SIZE];
// загрузка кадра в shared memeory
frame1 [ty][tx] = inFrameR [ aBegin + nx * ty + tx];
// синхронизация
__syncthreads ();
int i = ty * BLOCK_SIZE + tx;
// находим коэффициенты gij, hij, rij в подматрице 14х14.
if( tx > 0 && > 0 && tx < BLOCK_SIZEm1 && ty < BLOCK_SIZEm1 )
{
gij[ i ] = ( frame1[ty + 1][tx] - frame1[ty - 1][tx] )/2.0;
hij[ i ] = ( frame1[ty][tx + 1] - frame1[ty][tx - 1] )/2.0;
rij[ i ] = ( frame1[ty][tx] + frame1[ty][tx + 1] + frame1[ty][tx - 1] + frame1[ty + 1][tx] + frame1[ty - 1][tx] )/5.0;
}
else
{
gij[ i ] = 0;
hij[ i ] = 0;
rij[ i ] = 0;
}
// синхронизация
__syncthreads ();
// загрузка кадра в shared memeory
frame1 [ty][tx] = inFrame [ aBegin + nx * ty + tx] - rij[i];
// вычисление p, q
p [i] = gij [i]*frame1 [ty][tx];
q [i] = hij [i]*frame1 [ty][tx];
// вычисление u
tmp [i] = hij [i]*hij [i];
// вычисление v
rij[i] = hij [i]*gij [i];
// вычисление w
hij [i] = gij [i]*gij [i];
__syncthreads ();
for ( int s = BLOCK_SIZEhalfqrt; s > 32; s >>= 1 )
{
if ( i < s )
{
p [i] += p [i + s];
q [i] += q [i + s];
tmp [i] += tmp [i + s];
rij [i] += rij [i + s];
hij [i] += hij [i + s];
}
__syncthreads ();
}
if ( i < 32 )
{
p [i] += p [i + 32];
p [i] += p [i + 16];
p [i] += p [i + 8];
p [i] += p [i + 4];
p [i] += p [i + 2];
p [i] += p [i + 1];
q [i] += q [i + 32];
q [i] += q [i + 16];
q [i] += q [i + 8];
q [i] += q [i + 4];
q [i] += q [i + 2];
q [i] += q [i + 1];
tmp [i] += tmp [i + 32];
tmp [i] += tmp [i + 16];
tmp [i] += tmp [i + 8];
tmp [i] += tmp [i + 4];
tmp [i] += tmp [i + 2];
tmp [i] += tmp [i + 1];
rij [i] += rij [i + 32];
rij [i] += rij [i + 16];
rij [i] += rij [i + 8];
rij [i] += rij [i + 4];
rij [i] += rij [i + 2];
rij [i] += rij [i + 1];
hij [i] += hij [i + 32];
hij [i] += hij [i + 16];
hij [i] += hij [i + 8];
hij [i] += hij [i + 4];
hij [i] += hij [i + 2];
hij [i] += hij [i + 1];
}
if ( i == 0 )
{
outData [ by*gridDim.x + bx ] = p[0];
outData [ by*gridDim.x + bx + gridDim.x*gridDim.y] = q[0];
outData [ by*gridDim.x + bx + 2*gridDim.x*gridDim.y] = tmp [0];
outData [ by*gridDim.x + bx + 3*gridDim.x*gridDim.y] = rij [0];
outData [ by*gridDim.x + bx + 4*gridDim.x*gridDim.y] = hij [0];
}
};
В самом конце еще необходимо сложить результаты для всех блоков. Так как число блоков не очень большое, то результат выгоднее получать уже на процессоре. Так как для каждого кадра сдвиг вычисляется независимо, то можно придумать реализацию, когда одно ядро считает сдвиг для всех кадров, добавив в таблицу потоков еще одно измерение для индексации кадров памяти фильтра. Однако это будет выгодно, если кадры небольшого размера.
// окончательное суммирование оставшихся коэффициентов.
int numbCoeff = regInfo->nx / threads.x*regInfo->nx / threads.y;
cudaMemcpy( coeffhost, coeffdev, numbCoeff*5* sizeof ( float ), cudaMemcpyDeviceToHost );
float q = 0, p = 0;
float u = 0, v = 0, w = 0;
for( int i = 0; i < numbCoeff; i++ )
{
p += coeffhost[ i ];
q += coeffhost[ i + numbCoeff];
u += coeffhost[ i + 2*numbCoeff];
v += coeffhost[ i + 3*numbCoeff];
w += coeffhost[ i + 4*numbCoeff];
}
dx = ( q * w - p * v )/( u * w - v * v );
dy = ( p * u - q * v )/( u * w - v * v );
Какие здесь основные минусы.
1. Окончательный результат мы получаем на процессоре.
2. Коэффициенты для опорного кадра rij, gij, hij вычисляются многократно для каждого кадра.
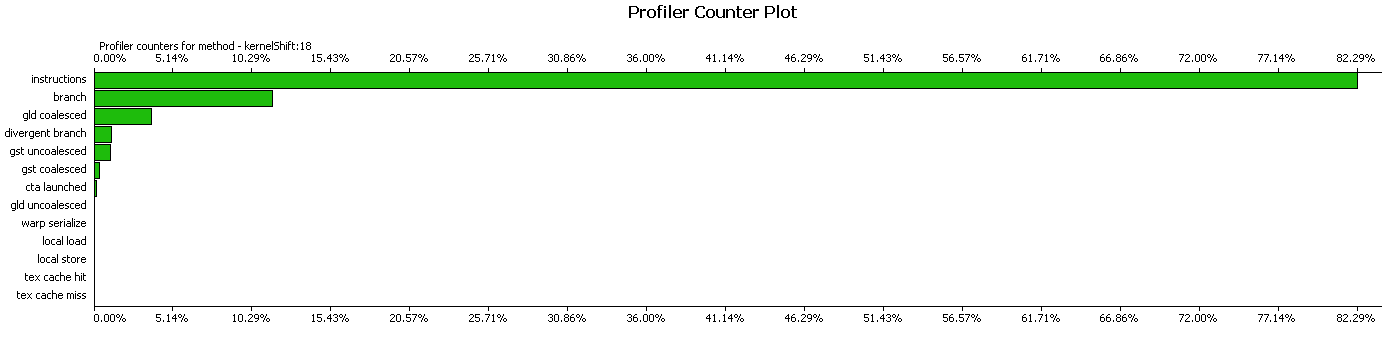
Посмотрим на результат в профайлере и оценим, хорошо ли работает данная реализация. Профайлер говорит нам о том, что запросы на чтение объединены, и инструкции занимаю большую часть времени.
Ядро поиска смещений:
Ядро для обеления кадров:
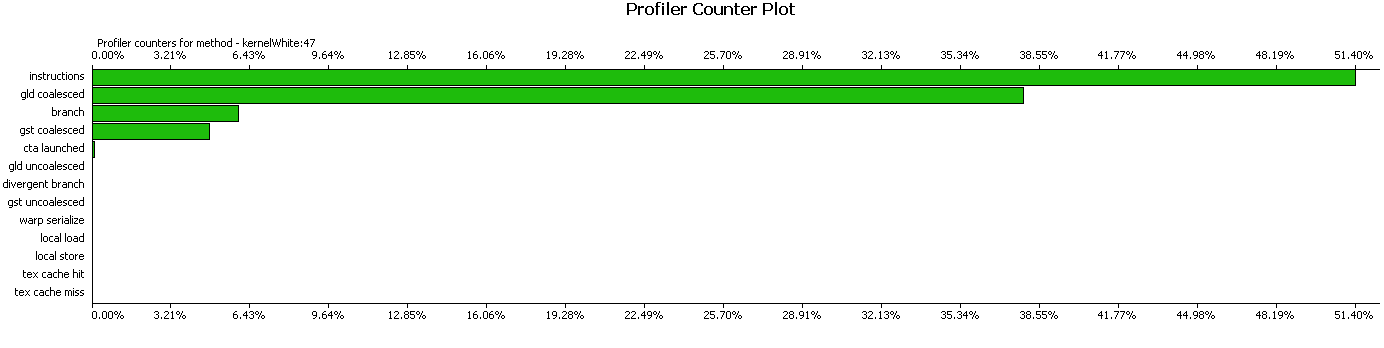
Так как старая GTX8800 была на другом компьютере и уже куда-то делась, то результаты привожу для GTX Titan.
Для кадров размером 512х512 получились следующие результаты времени работы. Ядро для вычисления коэффициентов сдвига занимает 60 мкс. Если добавить к нему копирование коэффициентов и окончательное суммирование, то получится 130 мкс. При памяти 20 кадров время работы составляет соответственно уже 2.6 мс. Функция обеления кадров занимает 156 мкс. Есть еще функция вычисления коэффициентов на процессоре, это еще 50 мкс. В сумме получается 2,806 мс.
Соответственно на CPU вычисление сдвигов занимает 40 мс, обеление кадра 30 мс и вычисление коэффициентов еще 50 мкс. В сумме получается 70 мс, что в 25 раз медленнее, чем на GPU (на самом деле это не так, но об этом позже).
Реализация довольно простая и совместима с СС = 1.0. Давайте теперь посмотрим, что можно исправить. Последнее действие в поиске сдвигов можно изменить и реализовать через атомарные операции, что будет работать в несколько раз быстрее.
Модифицированный код теперь выглядит вот так:
// замена в функции для поиск сдвигов
if ( i == 0 )
{
atomicAdd( &outData[0], p[0] );
atomicAdd( &outData[1], q[0] );
atomicAdd( &outData[2], tmp[0] );
atomicAdd( &outData[3], rij[0] );
atomicAdd( &outData[4], hij[0] );
}
// на CPU досчитываем коэффициенты
float p = coeffhost[ 0 ];
float q = coeffhost[ 1 ];
float u = coeffhost[ 2 ];
float v = coeffhost[ 3 ];
float w = coeffhost[ 4 ];
dx = ( q * w - p * v )/( u * w - v * v );
dy = ( p * u - q * v )/( u * w - v * v );
При этом ядро занимает примерно столько же времени, 66 мкс.
От многократного пересчета rij, gij, hij можно избавиться, написав отдельное ядро для их вычисления, но тогда придется их загружать каждый раз, а это в три раза больше памяти, так как вместо загрузки одного опорного кадра придется загружать три кадра с коэффициентами. Оптимальным решением было бы сделать одно ядро для вычисления сразу всех сдвигов, сделав цикл по кадрам внутри ядра.
Допустим, что у нас более общая задача и так не получилось бы сделать, а необходимо было бы запускать ядра многократно. В этот момент можно подумать, что все прекрасно, ядра написаны в целом оптимально, а ускорение получилось до 25 раз, но если взглянуть на профайлер, то мы увидим следующую картину:
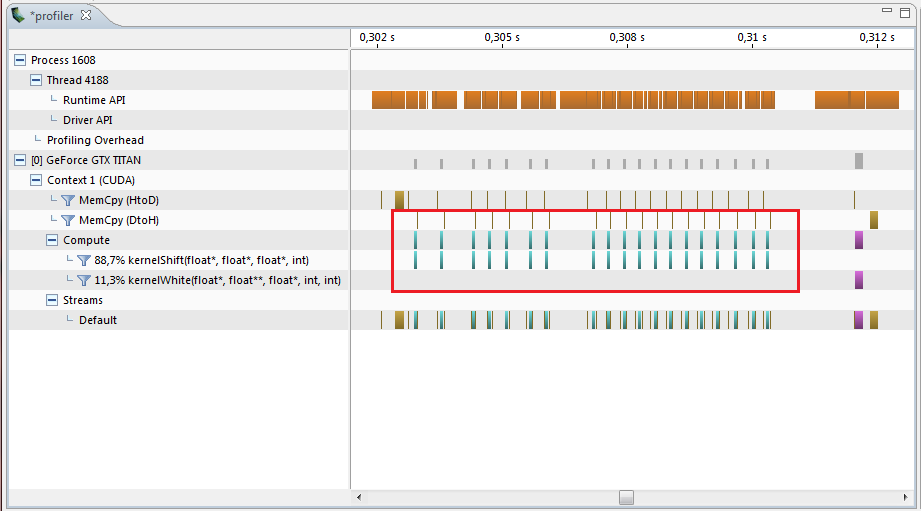
Наши функции на GPU работаю только маленький промежуток времени, остальное это задержки, копирование памяти и другие промежуточные операции. В сумме набегает 11.5 мс для вычисления сдвигов для всех кадров. В итоге ускорение получилось всего в 6 раз относительно CPU. Уберем все промежуточные вычисления и запустим ядра друг за другом в цикле:
for( int j = 0; j < regressInfo->memory - 1; j++ )
kernelShift<<< SKblocks, SKthreads >>> ( … );
После оптимизации профайлер показывает совершенно другую картинку.

Куда приятнее получилось, правда?.. Теперь часть с вычисление сдвигов занимает 1.40 мс вместо 11.5 мс. Здесь остался небольшой интервал между ядрами равный 4 мкс, который выдает профайлер. А давайте теперь попробуем запустить ядра в разных потоках.
// stream
for( int it = 0; it < 4; it++ )
cudaStreamCreate( &streamTX[it] );
……
for( int j = 0; j < regressInfo->memory - 1; j++ )
kernelShift<<< SKblocks, SKthreads, 0, streamTX[j%4] >>> (…);
Теперь профайлер показывает такой результат и здесь интервал составляет 1.22 мс.
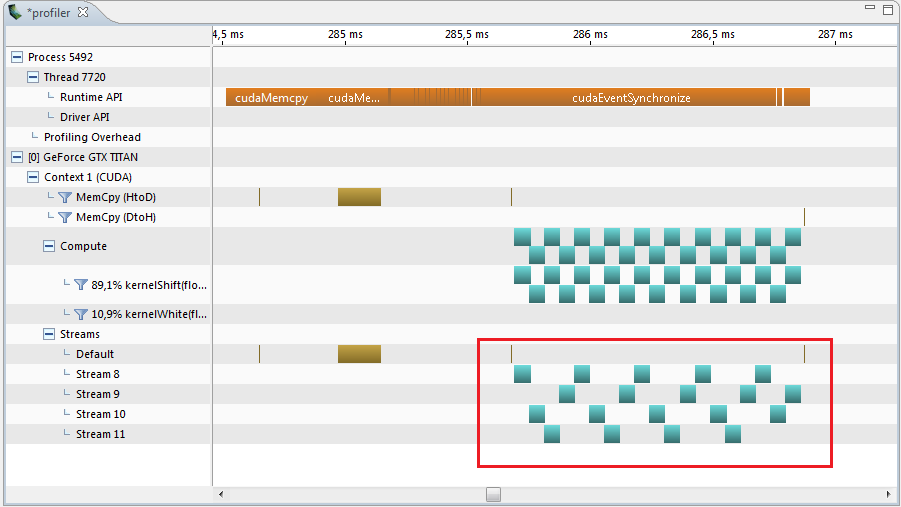
А это даже меньше на 0.12 мс чем 0.066*20 = 1.320.
Загрузка процессора при этом составляет 84%.
В результате общее время получается 1.22мс + 50 мкс + 156 мкс = 1.426 мс, а это в 50 раз быстрее, чем на CPU.
Конечно, написать одно ядро для вычисления сдвигов было бы правильнее, но это другой путь оптимизации, а мы рассмотрели более общий путь, недооценивать который нельзя. Можно написать хорошую реализацию на GPU, но забыть про оптимизацию взаимодействия с GPU. Чем меньше времени занимает работы ядра, тем больше будут влиять промежутки между вызовами, в которых есть какие либо действия на CPU.
Для примера были взяты снимки звездного неба, к ним добавлен движущийся тусклый объект, небольшие колебания и собственный шум.
До обработки:

После обработки:

До обработки:

После обработки:

В дополнение к алгоритму можно и даже нужно добавить функцию удаления объекта с предыдущих кадров, так как он может сильно портить результат фильтрации, оставляя следы после себя.
К сожалению, реальную запись достать не получилось, но если получится сделать и читателям будет интересно, то напишу о результатах.
1. Работа с памятью в CUDA.
2. Алгоритм вычисления суммы на CUDA.
This entry passed through the Full-Text RSS service — if this is your content and you're reading it on someone else's site, please read the FAQ at http://ift.tt/jcXqJW.