Добрый день, DEFCON! Я рад присутствовать здесь. Меня зовут Джен Бренсфильд, я главный инженер по безопасности компании Tenacity и очень люблю свою работу, поэтому, когда наступает уик-энд, я просто не могу дождаться утра понедельника! Сегодня я расскажу Вам о том, как вооружить свою кошку, это весёлая история, со своими победами, поражениями и целой кучей слайдов.

Итак, зачем мне понадобилось вооружать своего питомца?
Известно, что 15% мирового Интернет-трафика посвящено кошкам. Кроме того, я часто выступаю с презентациями по поводу систем безопасности перед техническими и не техническими специалистами. Я заметил, что технические подробности утомляют людей, они начинают скучать, закатывать глаза и думать о посторонних вещах. Чтобы привлечь их внимание, я стал разбавлять свои презентации слайдами с картинками кошек и рассказывать о них разные смешные истории. Например, я начинаю презентацию такой картинкой:

Я как раз заканчивал одну из своих презентаций, когда ко мне подошёл человек и сказал: «Я хочу подарить Вам этот кошачий ошейник, здесь есть GPS, модуль сотовой связи и можно отследить местонахождение кошки в любое время, и если Вы волнуетесь за неё, то можно отправить SMS, и Вам придёт ответ с её GPS координатами».
Я не был бы собой, если бы мне в голову не пришла мысль: «Стоит добавить в этот ошейник маленькую WiFi-ищейку, и мы получим настоящую Боевую Киску»!
Что касается служебных собак, то на другой конференции хакеров, AT Outerz0ne, я встретил Lady Merlin, которая выгуливала своего пса в шлейке — жилетке с большими карманами по бокам, из-за чего он выглядел как настоящая служебная собака. Я сказал, что это круто, в кармане, наверное, лежит Pineapple, хакерский роутер, перехватывающий весь свободный трафик? Она ответила, что нет, это всё-равно, что использовать ноутбук, который скачет у Вас на коленях, мешая работать, но Pineapple это хорошая идея!
На следующих слайдах показано, как используют служебных собак в армии, на первом изображена просто рабочая собака, а на двух других собаки, которые находят приключения на свою задницу, когда их выбрасывают из самолёта в воду или заставляют прыгать на руках парашютиста-десантника. Вы видите, что у десантника на лице кислородная маска? Собака тоже в маске, потому что прыжок осуществляется с высоты 30 тысяч футов.



На этом слайде показан настоящий морской котик. Это правда, ВМФ США использует морских животных для защиты гаваней и розыска плавучих мин. И если Вы попытаетесь незаметно проплыть в порт, чтобы взорвать его, рядом с Вами тут же вынырнет дельфин Флиппер с экшн-камерой GoPro на плавнике.

В 60-х годах под эгидой ЦРУ действительно проводились исследования возможности шпионского использования домашних кошек, как показано на следующем слайде. Это «кошка-прослушка», в ухо которой вживлён микрофон, вдоль позвоночника расположена антенна, а на груди расположен передатчик с источником питания. Такое мог придумать только человек, курящий нечто очень забористое.

Я не шучу, они получили финансирование под этот проект и провели испытания первого экземпляра акустической кошки. Они принесли её в помещение, где сидело несколько парней, читавших вслух, чтобы кошка могла их слушать. Но она убежала и пропала, и это стало первой и последней попыткой использования акустической кошки. Они прекратили испытания не потому, что это было плохой идеей, а потому, что с этими вертлявыми кошками очень трудно работать. Однако они нашли очень интересную вещь, к которой я вернусь позже.
Сейчас я расскажу о требованиях, которые предъявлялись к моей Боевой Киске.

Основным требованием было не нанести кошке вред. Я не люблю кошек, но я не хочу им вредить.
Следующим условием была комфортность «одежды», то есть кошке должно было быть удобно как одевать, так и носить свою шлейку – жилетку. Нам не нужны были мигающие огни и прочее, что превращало бы нашу кошку в лёгко обнаруживаемую добычу.
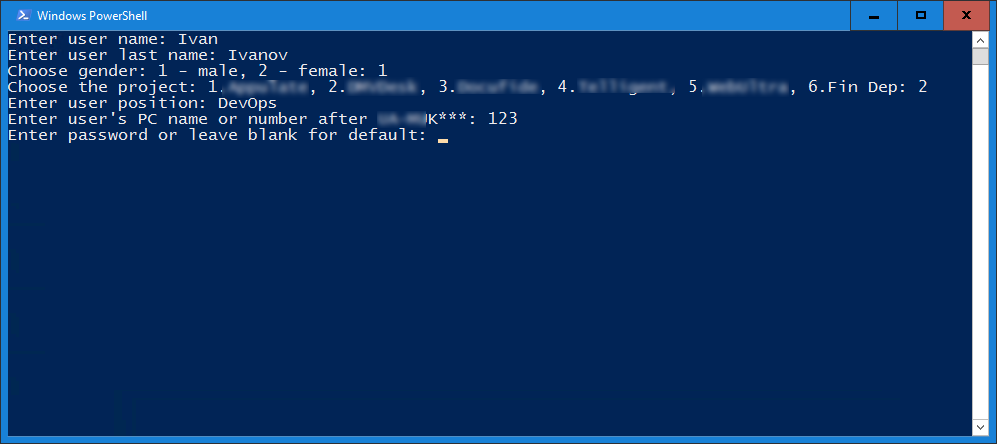
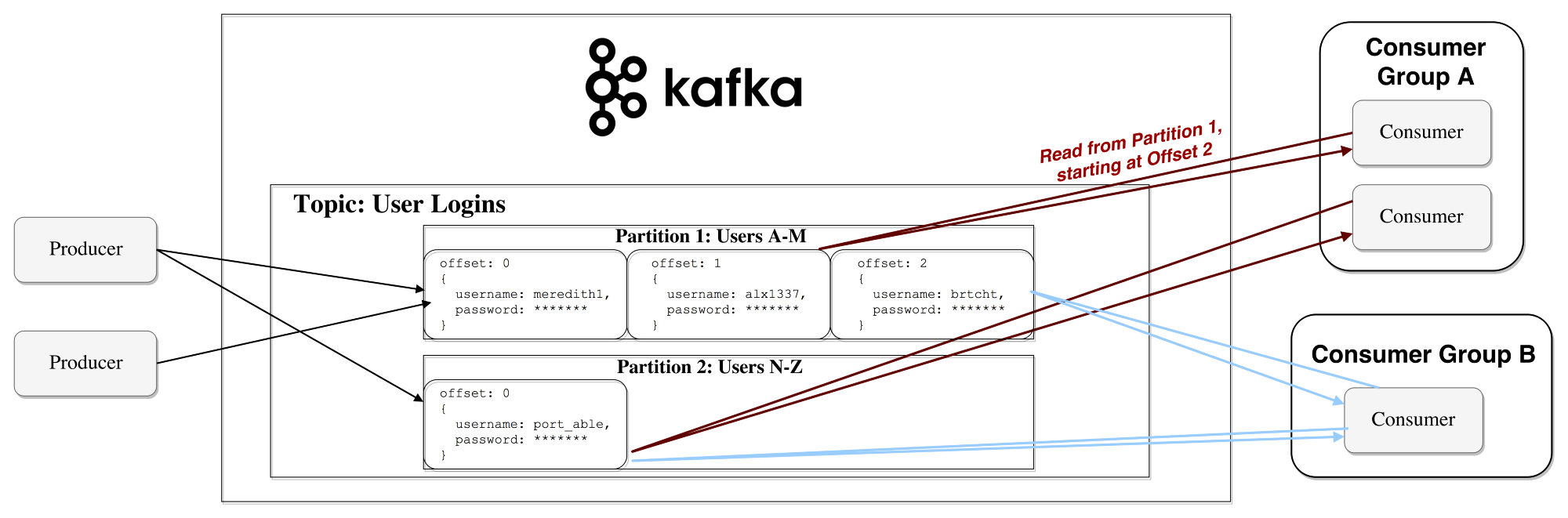
GPS должен был записывать точки маршрута с соответствующими штампами даты и времени, для того, чтобы после возвращения кошки можно было отследить, где она побывала. «Ищейка-сканер» Wi-Fi должен был синхронизировать время с GPS модулем и собирать Wi-Fi SSID и прочие сигналы, имеющие отношение к Wi-Fi, для последующего анализа.
Смысл был в том, чтобы одеть на кошку ошейник или шлейку и выпустить гулять по окрестностям. Ошейник или шлейка должны содержать в себе GPS приёмник и Wi-Fi сканер-ищейку, чтобы отмечать на карте беспроводные точки доступа Wi-Fi, как это делается в боевых условиях.
Мы также использовали дополнительные средства слежения, такие как камера Mr Lee Cat Cam, которая крепится на ошейник, трекер для домашних животных Pet Tracker и гарнитуру Garmin. Для обеспечения совместной работы всех устройств можно было использовать портативный компьютер GumStix небольшого форм-фактора Stix длиной около 11 см, но довольно дорогой, микропроцессор Cotton Candy такого же форм-фактора и миниатюрный телеприёмник Rock Chip 3066 с двухядерным процессором A9, который можно подсоединить к телевизору для приёма потокового HD видео.


Так что я взял банку пива и сел поразмышлять над всем этим. Мне нужен был малый форм-фактор, GPS, Wi-Fi и сотовая связь. Как бы могло выглядеть подобное устройство? Возможно, как смартфон, который постоянно лежит в моём кармане. Но нужно было приложение, которое работало бы на Android, то есть требовалось написать соответствующий код для Android и Wi-Fi.
Может быть, такое приложение уже существует? Я нашёл, скачал и установил из магазина мобильных приложений для «Андроид» крутое приложение под названием WIGLE WiFi, а затем выбрал кота-добровольца для своих испытаний. Это кот моего друга Ривзи по имени Скитзи.

Это чертовски крупный кот с длиной туловища 55 см, обхватом груди 50 см и обхватом шеи 30 см. Теперь нам нужен был Cat Coat, или «плащ для кота», возможно, такого вида:

Если набрать в Google фразу «кошачье пальто», Вы увидите целую кучу фотографий девушек в пальто с изображением кошечек, так что этот вариант не подходит, поэтому я стал «гуглить» фразу «собачье пальто» и нашёл то, что мне могло подойти.

План был такой: я кладу свою технику в пальто, пальто одеваю на кота, кот отправляется на прогулку, и я восстанавливаю записанные данные, когда он возвращается домой.
Последовательность действий изображена на слайдах.


Здесь он выглядит немного испуганным.

Затем мы выпустили кота…

И это окончилось неудачей! Пролезая сквозь забор, кот потерял свой плащ, видимо, он висел на нём слишком свободно.

Мы поймали кота, снова одели на него плащ, затянули поплотнее и повторили попытку. И вот сидим и ждём, и ждём, и ждём… мы прождали его 18 часов, а когда открыли дверь, то увидели, что кот вернулся голым, без своей боевой попоны.

Нас постигла неудача! Мы отследили последнюю известную отметку GPS, но попоны там не было. Из этого эксперимента мы извлекли такие уроки:
- с котами очень трудно работать;
- всегда тестируйте свою работу, прежде чем посылать дорогостоящее оборудование на улицу,
при совершении дорогих покупок на Amazon мы можем получить Prime-аккаунт;
- беспокойство о том, чтобы коту было удобно в одежде, приводит к потере одежды,
нужно использовать устройство с такими же возможностями, но гораздо меньшего размера.
Тогда я поговорил со своим другом Биллом, который увлекался всякими инженерными штуками, и он посоветовал использовать микрокомпьютер Arduino, который обладал такими чертами:
- маленький форм-фактор;
- небольшое потребление электроэнергии;
- делает именно то, что вам нужно, ни больше, ни меньше;
- совместим со множеством чипов и позволяет использовать различные решения.
Я стал разбираться, что собой представляет этот «Ардуино»:
- это открытая электронная платформа, основанная на простом в использовании «железе» и «софте», которая интересна для тех, кто занимается интерактивными проектами;
- здесь имеется много слотов расширения для подключения датчиков, сами платы Arduino можно устанавливать друг на друга;
- используется при создании роботов, машинок с дистанционным управлением, систем домашней безопасности и т.д.
Билли использовал чип «Ардунино» для проверки продуктов холодильнике, для роботизированной «руки» и для своих видео-игр. Он имеет действительно крохотный форм-фактор, это открытый ресурс и стоит очень дёшево.

К недостаткам «Ардуино» относится бедная документация, сомнительное качество и то, что требуется целая вечность, чтобы в нём разобраться.
Это всё хорошо, но я никогда не работал с «Ардуино», фирменным ПО и наборами маленьких чипов, я не являюсь профессиональным кодером и не умею паять. Но Билл сказал: «Не беспокойся, это легко»!
Мой план действия состоял из таких пунктов:
- узнать как можно больше об Arduino и изучить основные понятия;
- выбрать наиболее подходящий форм-фактор для вооружения нашего кота;
- вставить всю электронику в ошейник, а потом придумать что-нибудь для служебной собаки...
Я прочитал книжку, которая шла в комплекте с Arduino Unо, и ещё много руководств по инжинирингу и электронике, достал кучу светодиодов, чтобы испытать их работу с Arduino, хотя не собирался использовать никаких лампочек. Самым потрясающим было то, что я обнаружил программные библиотеки для Wi-Fi, GPS и SD-карты.
На сайте Джереми Блюма jeremyblum.com я нашёл много видео о конструировании всяких устройств на основе «Ардуино».
После всего этого я посчитал, что стал экспертом в этом деле. Итак, у меня была плата расширения Wi-Fi Arduino и плата расширения GPS Itead Studio.

Мне нужно было придать плате Wi-Fi функцию сборщика данных с записью на SD-карту, а плате GPS – функцию трекера, также с возможностью записи данных на карту, и объединить их в одно целое.
С платой Wi-Fi всё прошло идеально: установка была лёгкой, драйвера, скачанные с сайта Arduino, работали, после небольшой возни с параметрами и переменными всё получилось, как надо.
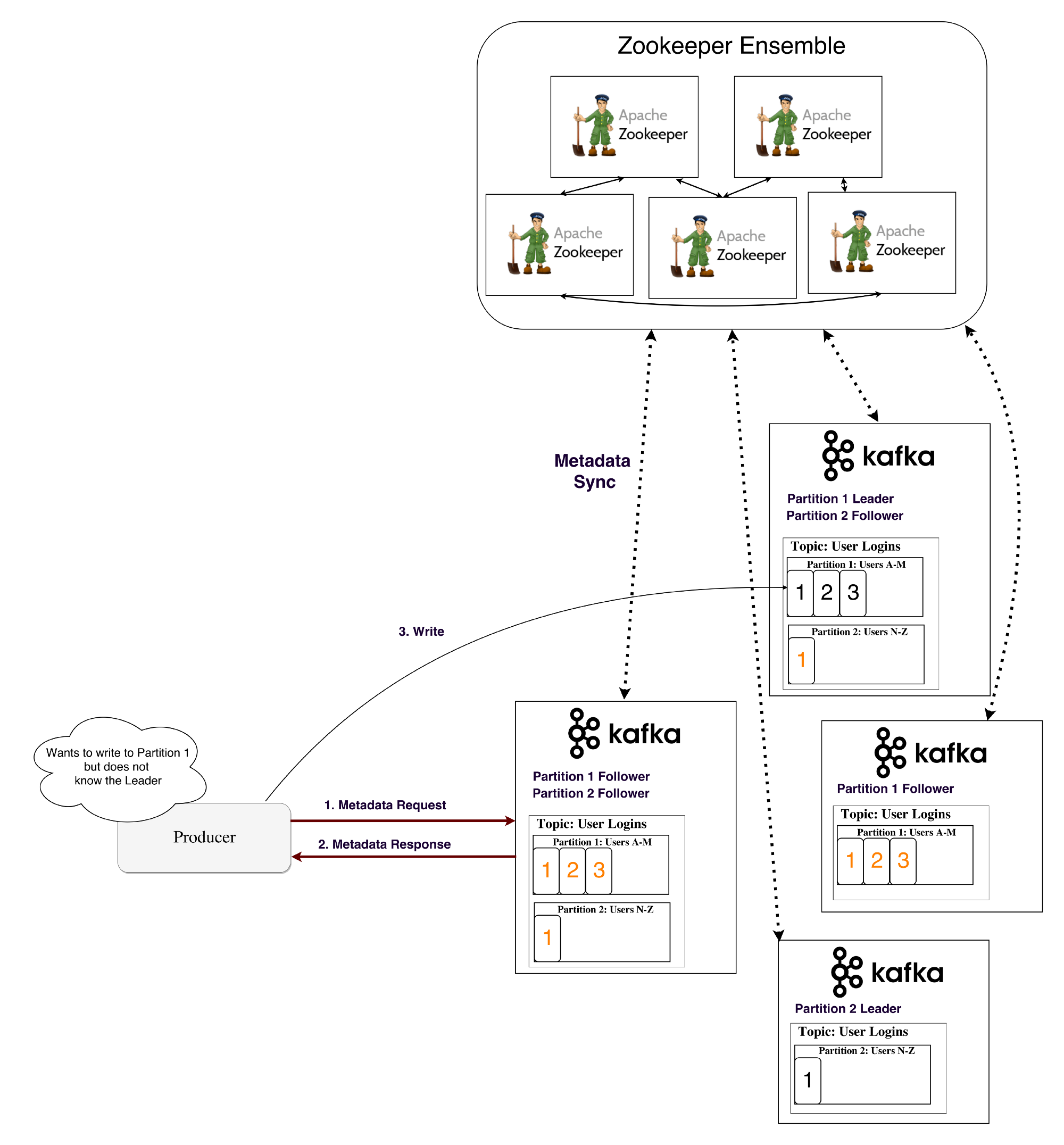
А вот с GPS было не так легко. Существует строка NMEA, National Maritime Electronics Association, в которой прописаны стандарты параметров работы GPS – приём, передача, координаты и прочее. Процесс загрузки модуля может производиться с любого места на земле – Вы просто подсоединяете этот модуль к источнику питания, и он начинает «слушать» космос. Устройство засекает 3 спутника, определяет позицию, и это занимает от 2 до 15 минут в зависимости от местных условий.
Плата расширения GPS также имела бедную документацию и в коробке с набором не было никакой инструкции. Мне потребовалась неделя, чтобы понять, почему модуль не работает, и в конце концов я выяснил, что ему нужна скорость передачи данных 34840 бод, которую я до сих пор нигде не могу найти.
В общем, я собрал все компоненты вместе… и потерпел неудачу.

Оказалось, что используется больше 80% памяти Arduino, количество библиотек и переменных слишком велико, и 32 КБ памяти Arduino Uno совершенно не достаточно — чип просто не может работать с такой нагрузкой.
Поэтому я купил микропроцессор Arduino Mega 2560 с 256 КБ памяти, опять соединил всё вместе, запустил, и оно заработало!

Arduino Mega 2560 имел:
- больше памяти, что было намного лучше;
- больше портов, что было намного лучше;
- больший размер, что было намного хуже.
В поисках альтернативы я облазил весь Интернет и нашёл чип Arduino Mega Mini от компании JK Devices, который был меньше стандартного Mega.

Я продолжил поиски платформ маленького размера и нашёл микропроцессор под названием Spark Core, который представлял собой комбинацию двух модулей на одной печатной плате – спереди располагался модуль Wi-Fi, а сзади – чип Arduino.

К нему я докупил GPS чип марки GP-635T и плату для карты памяти SparkFun MicroSD Breakout.

Поскольку мне сказали, что доставки Arduino Mega Mini придётся ждать несколько недель, а все остальные платформы были или слишком велики, или имели слишком маленький объём памяти, я остановил свой выбор на продукции Spark. Платформа Spark Core имела такие технические характеристики:
- процессор ARM 32-бит М3;
- память объёмом 128 КБ, больше, чем мне нужно;
- совместимость с SPI и I2С, то есть протоколы для взаимодействия микроконтроллера, внешних компонентов и сети интернет;
- Wi-Fi чип TI CC3000;
- совместимость с Arduino отсутствовала.
Последний пункт означал, что хотя контроллер использует чип Arduino и к нему можно подсоединить внешние компоненты, нельзя обеспечить их взаимодействие, просто написав соответствующий код, то есть Spark и платформа Arduino всё-таки совсем разные вещи. Это меня не огорчило, и я снова приступил к созданию своего продукта.
Всё начинается с языка программирования Scratch, но я выяснил, что в нём нет библиотек, необходимых для работы моего устройства. Несмотря на это, он был очень крутым, поэтому в поисках решения я обратился к группе разработчиков Peekay123, и вот что из этого получилось:
- кто-то разместил библиотеки для SD карт на форуме, и они мне подошли!
- кто-то разместил на форуме библиотеки для GPS, они работали и были совместимы с моим GPS модулем!
Однако с библиотеками для Wi-Fi было сложнее, потому что Spark Core был создан по принципу «интернет вещей», а Wi-Fi представлял собой фоновую службу, которую нельзя было с ним связать.
Но я хотел их связать! Для чипа Adafruit СС3000 существовали библиотеки, которые можно было скачать с сайта Adafruit, чтобы использовать его для сбора данных Wi-Fi, я скачал их, установил, и это сработало!
Итак, у меня был GPS, работающий на Spark, SD-карта, совместимая со Spark, набор SSID, работающий на Spark, и теперь мне нужно было соединить всю эту мелочь вместе. Для этого понадобилась пайка!

Кто из Вас умеет паять, поднимите руки! Вы видите – всего пару человек в зале! Изучение искусства пайки стало моим последним занятием. При этом я усвоил несколько важных правил, например, что паяльник нужно держать не за жало, а за рукоятку. Второе правило заключалось в том, что не нужно класть руки где попало, чтобы не получить ожог паяльником. Правило три гласило, что в интернете всё выглядит легко, но в действительности это далеко не так.
Итак, сначала я разместил на монтажной плате GPS-модуль и кард-ридер для SD-карты и связал всё это с контроллером Spark. Выглядело неплохо, и я решил проверить, как оно работает.

Домашние испытания прошли великолепно! Я взял устройство с собой и прогулялся вокруг дома – всё работало идеально! Оно показало, что вот моя сеть, вот здесь Wi-Fi моего соседа и так далее. Но когда я взял его с собой в автомобиль и немного проехался, то потерпел фиаско. В чём же была причина?
В том, что Spark был ярким представителем «Интернета вещей», а это означает, что он не должен никогда отсоединяться от Интернета! В данном случае от домашней сети Интернет. Я общался с ребятами на форумах по поводу того, что происходит с устройством при езде в автомобиле. Выяснилось, что чип Spark должен быть подключён к известной ему точке доступа, чтобы начать работать. Получалось, что пока он подключён к моей домашней сети Wi-Fi, всё работает без ошибок, но стоит отъехать на полмили, устройство перестаёт работать.
Я мог просканировать уникальный 32-х значный код SSID, который используется для идентификации моей беспроводной локальной сети. Чтобы Spark мог к ней подключится, он использует именно этот код. Происходило вот что: когда контроллер терял сигнал домашней сети WI-FI и пробовал подключиться снова, то искал сеть именно с этим SSID, но не находил её. Значит, мне нужно было просто успеть удалить этот код из памяти чипа, чтобы после потери сигнала одной сети он смог подключаться к другим сетям. После того, как я это проделал, проблем с WiFi больше не возникало.
Следующим этапом было испытание GPS. Я проехался немного и получил данные о точках W-Fi, всё отлично работало, я проехал ещё полмили и проверил координаты GPS. Я был на шоссе, а по карте выходило, что я нахожусь в озере. Вернувшись домой, я выяснил, что имеющиеся GPS библиотеки не могли правильно конвертировать данные спутников в координаты на карте. Получалось, что у меня нет библиотек GPS.
Тогда я раздобыл TinyGPS++, набор библиотек, которые извлекают данные NMEA, полученные GPS модулем, такие, как позиция, высота, скорость, дата, время, курс и т.д., и передают их чипу Arduino. Это было то, что мне нужно, но оно не работало со Spark. Я поговорил с Биллом, и он посоветовал использовать библиотеки для порта Ардуино.
Я снова погрузился в область космических наук. Это как с ракетой, когда Вы заправляете её топливом, ставите на стартовую позицию, нажимаете красную кнопку, и она взрывается. Или ракета сначала взлетает, а потом взрывается. Или всё-таки уходит в космос, и тогда Вы говорите: «Да, вот это и есть космическая наука»! Несколько хуже, когда внутри ракеты сидит обезьянка. В общем, я выяснил, что нужно поменять местами Arduino и Sparks, чтобы всё заработало. Для этого мне пришлось заняться кодировкой библиотек для портов Sparks, что ничуть не легче космических наук. Так что следующей специальностью, которой я овладел, была специальность кодера. Зато у меня наконец-то всё заработало как надо.
Следующей проблемой стало энергопотребление. Нужно было подумать, как улучшить его характеристики. Я решил использовать миниатюрный аккумулятор Elite 3,7 В ёмкостью 500 мАч, который мой друг Рикки использовал для своих авиамоделей, и приступил к тестированию его работы.

Выяснилось, что вариант экономии энергопотребление путём периодического отключения и включения питания всего устройства мне не подходит. Тогда я сделал так, чтобы можно было вводить в режим глубокого сна главный чип, при этом модуль GPS продолжал работать. «Засечки» данных каждые 30 секунд разряжали аккумулятор за 4 часа, сбор данных каждые 10 минут увеличивал время работы до 8 часов.
Наконец настало время делать ошейник. Выяснилось, что отпаивать детали в два раза веселей, то есть сложней, чем припаивать, и я спалил при этом много всякой полезной мелочи. Интернет снова мне не помог, зато ролики на YouTube несколько улучшили понимание процесса. Я спросил своего друга Джо, что мне делать, и он посоветовал обратиться к специалистам NovaLabs из Рестона, штат Вирджиния. Это был Тэд, сумасшедший учёный и по совместительству злой гений, который помог мне изучить EAGLE, и Брайан, мастер пайки, который объяснил мне, что правильному железу нужна правильная пайка. Они существенно облегчили мне жизнь.
Дальше я приступил к разработке конструкции кошачьего ошейника. Его можно было сделать несколькими способами. Джо предложил сшить вместе несколько лент и вставить между ними моё оборудование. Я пошёл к Майку и взял у него такую красивую леопардовую тесьму, которая идеально подходила нашему коту.

Теперь мне нужно было сшить их вместе. Кто из Вас знает, как это делается? Это искусство наших бабушек, так что мне понадобилась бабушка. Это бабушка моей жены, её зовут Нэнси, и она очень рада с Вами познакомиться.

Она была рада нам помочь и за 1 доллар сшила два ошейника – внешний и внутренний, который должен был защитить электронику от повреждений и влаги. Spark имел несколько вспыхивающих светодиодов, которые я не хотел прицеплять на кота, поэтому я их удалил.
Пришло время опять обратиться за помощью к нашему коту-добровольцу. Этот поганец задолжал мне потерянный сотовый! Сначала нужно было провести испытания с пустым ошейником, чтобы проверить, не потеряет ли его кот, как это произошло со шлейкой.

В новой амуниции кот выглядел вот так – сверху Вы видите кольцо, к которому был прицеплен груз в виде патрона. Он должен ориентировать положение ошейника на шее кота таким образом, чтобы находящийся внутри GPS-приёмник был всегда направлен вверх.

Итак, мы вставили электронику в ошейник, одели его на кота и отправили его гулять. Когда он вернулся домой, я снял ошейник и ничего не обнаружил! Я проверил электронику – всё работало! Мы снова одели ошейник на кота и отправили его на улицу. Он залез в кусты и завис там на 20 минут, вылизывая себя. Я сказал Ривзу об этом, он подошёл к кустам, принялся их трясти, и кот оттуда выскочил.
Мы решили изменить технологию работы таким образом:
- вынести ошейник на улицу и подождать соединения с GPS в течение 5-10 минут;
- принести кота к ошейнику и одеть ошейник на кота;
- отправить кота гулять в ошейнике.
Наконец-то нас ждала УДАЧА!

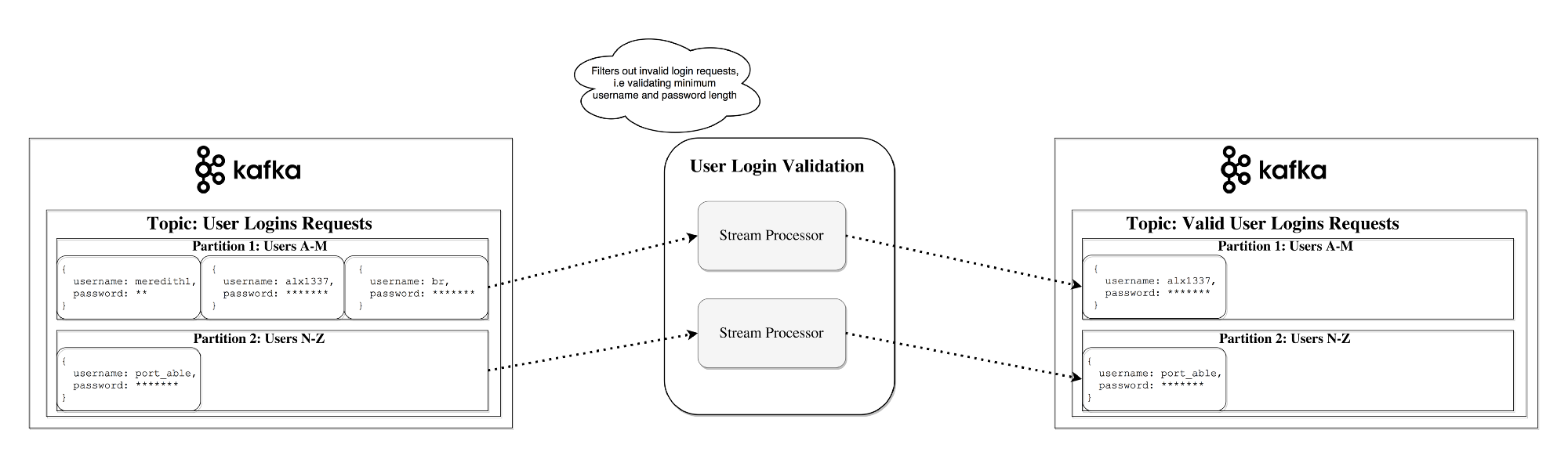
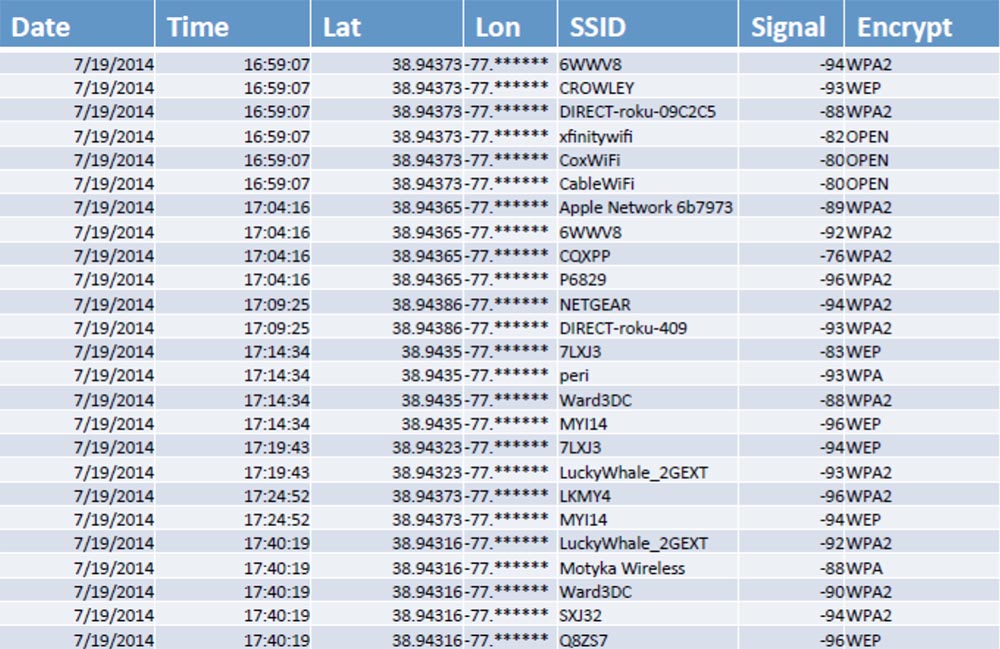
Данные, извлечённые из ошейника, выглядели так:

Здесь были дата, время, широта, долгота, название точек доступа Wi-Fi SSID, сигнал и его расшифровка.
Я сделал видео его перемещений по полученным координатам, и получилось, что всё это время проклятый кот даже не покидал переднего двора, причём первым местом, где он отметился, была машина.

Мы нашли ещё одну кошку, которую звали Коко, и испытали ошейник на ней. Полученные данные были намного разнообразней, а зона её перемещений намного шире.
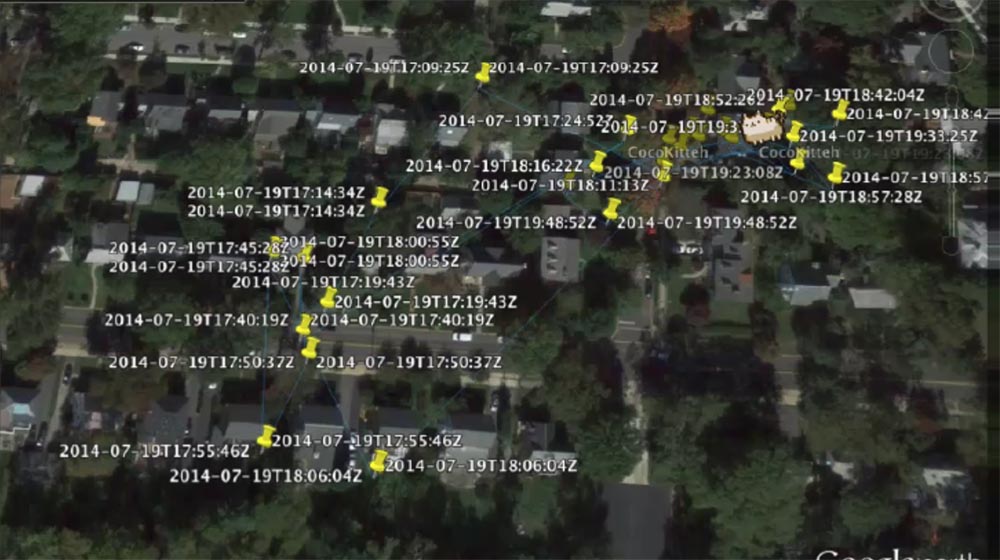
Во время своего путешествия она наверняка охотилась на мышей. В общем, наше устройство работало отлично, результаты исследований возвращались куда нужно.
Вот так мне удалось создать свою Боевую Киску!
Осталось решить вопрос, как можно усовершенствовать служебную собаку.

Итак, служебных собак в Интернете троллят больше, чем кого-то ещё. Для них можно использовать продукт компании Smoocon под названием WiFi Pineapple и дистанционный выключатель телевизоров TV В Gone на основе контроллеров Adafruit / Radiosnack. Устройство TV В Gone используют для того, чтобы одновременно отключать все телеприёмники в публичных местах. Всё это можно разместить в шлейке-жилетке, или собачьем рюкзаке. Для того, чтобы всё это работало, нужна программа Karma для обработки ответов на запросы в режиме Answers Probes, DNS Spoof, который направляет всё в Pineapple, и модуль RandomRoll.

На следующем слайде показано, как выглядит TV В Gone, разобранный на части. Для его потребовались мои таланты пайщика, в результате я получил компактный модуль, который модифицировал, выпаяв светодиоды.



Теперь всё это нужно было пропатчить, не приведи господь кому-нибудь заниматься подобным! С этим мне помогла Cept Irina & Friends из JoAnn’s Fabrics, расположенной в Стерлинге, штат Вирджиния. Так нам удалось создать комплект оборудования под названием «Denial of Service Dog», то есть «cобака для отказа сервиса» с модулем Wi-Fi.
У меня есть видео, где показано, как это работает. Вы видите, что снаружи шлейки расположен блок со светодиодом, и когда я нажимал выносную кнопку, он начинал мигать зелёным светом, показывая, что телепередача идёт, а затем автоматически выключался. Сейчас я покажу, как подключение выглядело на экране смартфона, когда я сидел в автомобиле. Сначала я нахожу точку доступа к Wi-Fi сети, присваиваю ей имя DEFCON и пытаюсь подсоединиться, при этом Karma сообщает, что «вот она я», после чего соединение устанавливается, и я выхожу в Интернет. Всё работало отлично, и теперь нам нужна была собака-доброволец.
Мы выбрали доберман-пинчера, которого звали Доберман Доберман, и он минут 10 носился по двору, радуясь, что видит так много новых людей. Затем мы напялили на него шлейку, и он оставался в таком положении 10 минут.

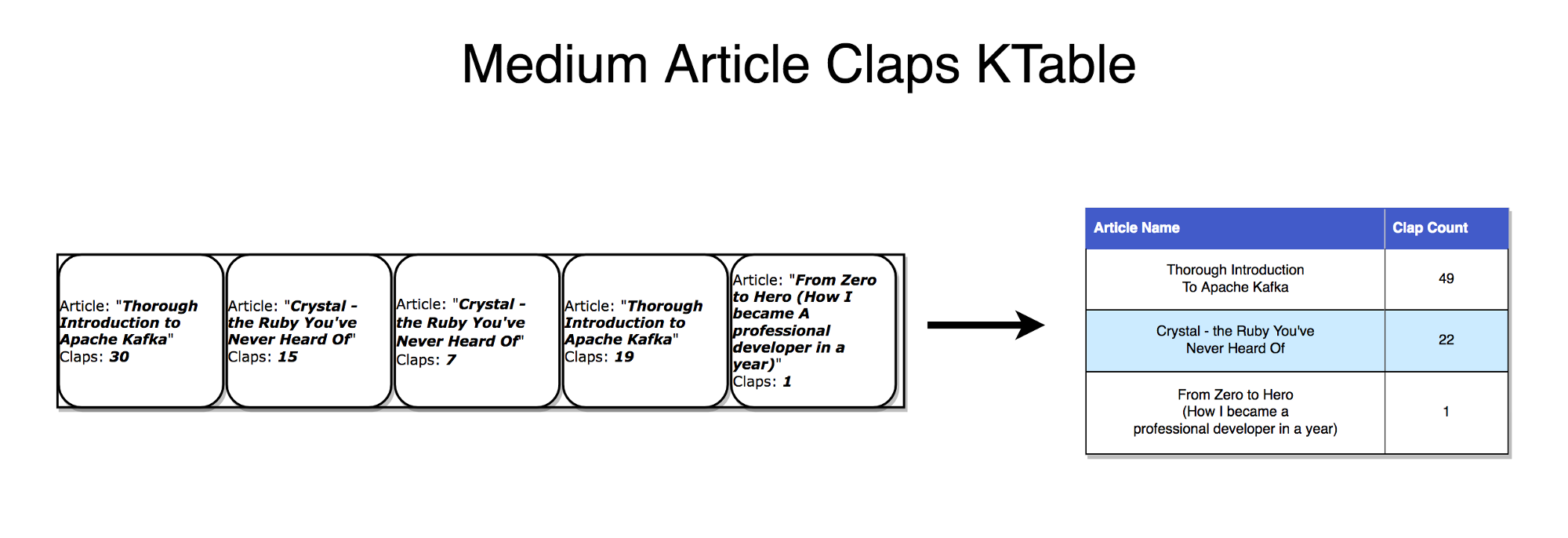
Вот как его рюкзак выглядел сбоку и сверху.

Поднявшись на лапы, пёс принялся отряхиваться, что стало серьёзным испытанием для электронной начинки, и я в очередной раз похвалил себя за то, что научился хорошо паять.
После этого мы отправились в ресторан. Нас пустили туда с собакой без проблем, потому что мы сказали, что у нас служебная собака (в США служебными называют собак, которые помогают людям с ограниченными возможностями). Я нажал кнопку записи GoPro, но от волнения перепутал и нажал не ту, что надо, там всего было 2 кнопки. Мы сели за столик, к нам подошёл официант и спросил: «Почему на его жилетке написано cобака для отказа сервиса»? Мы ответили: «Знаете, сегодня целый день к нам все подходят с этим вопросом, мы не отвечаем, они разворачиваются и уходят»!

Телевизоры в ресторане были выключены, поэтому мы не смогли проверить работу нашего устройства и решили пойти в спортивный бар. Там телевизор был включён, но я не рискнул опробовать на нём наш TV В Gone, потому что люди смотрели чемпионат World Cup, полуфинальный матч с Аргентиной, и отключать трансляцию было опасно для здоровья.
Так что если Вы заходите в ресторан, где на стене висит 50 дюймовый телевизор, учтите, что он всегда дистанционно управляются каким-нибудь парнем на заднем плане, а если Вы посещаете ресторан с одним или двумя небольшими телевизорами, то обычно они вообще не работают.
Наконец, мы зашли в супермаркет, и там у нашего пса просто разбежались глаза, так что его постоянно приходилось хватать за ручку на спине и одёргивать. Мы спросили продавца, можно ли ходить по магазину со служебной собакой, и он сказал, что можно, лишь бы она нигде не нагадила. Впрочем, это и произошло.
Мы прошли в секцию, где продавали телевизоры, и там нас ждала удача. Как только я нажал кнопку, изображение на телевизорах пропало.
В результате испытаний мы выяснили следующее:
- несколько несчастных жертв случайно подключились к Karma и их устройства выдали сообщение «ошибка регистрации»;
- только один человек спросил, почему на шлейке пса написано «cобака для отказа сервиса»,
большинство людей, видя нашего пса, говорили: «Хорошая собачка»!
Выученные мной уроки заключались в следующем:
- технически подкованный любитель без опыта прошивки устройств может создать функциональный ошейник для Боевой Киски за сравнительно короткое время;
- в 2014 году всё ещё существуют незащищенные точки доступа Wi-Fi;
- множество устройств всё ещё представляют собой пробные варианты;
- до сих пор не существует патча от человеческой глупости;
- с кошками и собаками действительно трудно работать!
Я хочу поблагодарить всех, кто принимал участие в моём проекте и сказать, что очень горд присутствовать здесь, среди Вас, ведь вместе мы способны делать великие дела!
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас оформив заказ или порекомендовав знакомым,
30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас:Вся правда о VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 ТВ от $249 в Нидерландах и США! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Let's block ads! (Why?)