История о том, как я неожиданно купил синтезатор, починил его, разобрался с тем, как он устроен, и написал эмулятор.
Эта история началась во время проведения фестиваля Chaos Constructions на последних выходных августа 2019 года. Просматривая вечером Авито в поисках интересных артефактов ушедшей эпохи, я наткнулся на недорогой синтезатор Форманта П432. Выглядел он вполне привычно для цифровых синтезаторов: в нижней части клавиатура из 41 клавиши (3,5 октавы), в верхней ‒ кнопки выбора тембра, включения эффекта хор и унисон, а также регуляторы настройки эффекта вибрато. Слева от клавиатуры установлен джойстик, позволяющий сместить строй вверх и вниз, а также плавно подключить вибрато.
Самое интересное для меня заключалось в том, что этот синтезатор был именно цифровым и генерировал звуки по методу wavetable, т. е. в момент нажатия клавиши он генерировал звук на основе табличных данных, сохраненных в микросхемах ПЗУ. После беглого ознакомления со схемами в интернете стало понятно, что управление синтезатором построено на широко известном микропроцессоре КР580ВМ80 (i8080), а звуки хранятся в 8 микросхемах ПЗУ общим объемом 8*2 = 16 Кб.
Синтезатор был куплен и неспешно отправился из города продавца в местный офис транспортной компании, а я продолжил изучать схемы. Продавец написал в объявлении, что инструмент имеет дефект, проявляющийся в виде хрипов при нажатии больше одной клавиши. «Тем интереснее, — подумал я. — Нужно будет найти и устранить».
Но основным мотивом к покупке было желание разобраться с внутренним устройством и извлечь семплы звуков из ПЗУ синтезатора.
DISCLAIMER: Названия составных частей узлов и сигналов синтезатора (кроме указанных в “кавычках” и БОЛЬШИМИ буквами) придуманы мной и могут отличаться от задуманных разработчиками. Описание работы узлов сделано на основе моих (ограниченных) знаний, материалов из сети интернет и советов опытных людей.
Ремонт
Когда П432 [2] добрался до меня в целости и сохранности, первое, что я сделал, это разобрал его. Внутри меня ожидало не очень приятное зрелище из пучков проводов и нескольких печатных плат.
Плата, на которой распаяны кнопки и регуляторы лицевой панели, а также индикация режимов работы.
Содержит микропроцессор КР580ВМ80 и другие микросхемы комплекта 580, ПЗУ 2 Кбайт на РФ2, две микросхемы статического ОЗУ суммарным объемом 256 байт (К541РУ2). Также на плате установлены дешифраторы, выделяющие части адресного пространства под взаимодействие с клавиатурой, с кнопками управления и регистрами, на выходе которых формируются управляющие сигналы для узла генераторов.
Установлен над узлом процессора и состоит из отдельного ПЗУ с подпрограммами обмена миди сообщениями, мелкой логики и двух больших микросхем: контроллера прерываний ВН59 и последовательно интерфейса ВВ51. К контактам TX/RX ВН51 подключена стандартная схема реализации midi токовой петли с развязкой на оптроне.
В виде изолированной платы, имеющей только аналоговый вход, выход и питание. Реализован на микросхемах КА528БР2 – аналоговых линиях задержки. Узел очень шумный, но придает звуку интересную окраску.
Основной модуль синтезатора. Содержит 8 микросхем ПЗУ по 2 Кбайт каждая, цифровую логику (регистры, сумматоры), два ЦАП, аналоговый фильтр с изменяемыми параметрами и термостабилизацией. Узел также содержит генератор тактовых импульсов, с которым синхронизирована работа регистров узла процессора. Дочерней платой на этом узле установлена плата ГУН (генератора, управляемого напряжением), являющаяся заводской доработкой более поздних ревизий синтезатора.
Линейный блок питания, выдающий +5В для питания логики и +12/-15В для операционных усилителей. +5В стабилизированы КР142ЕН5, в качестве радиатора которой выступает металлический корпус синтезатора, а +12/-15В ‒ простейшими параметрическими стабилизаторами на стабилитронах и транзисторах. Дополнительное напряжение питания -5В для КР580ВМ50 формируется стабилитроном из -15В прямо на плате узла процессора. Аналоговая и цифровая земля разведены отдельно и соединяются только в этом блоке.
Герконовая, не чувствительная к скорости нажатия, как и на многих отечественных синтезаторах того времени.

Вынос узла МИДИ на отдельную плату со своим ПЗУ обусловлен наличием еще одного синтезатора в линейке П432 – Форманта П432-МИНИ, не имеющего миди интерфейса и эффекта ХОР. Узел процессора у МИНИ немного отличается прошивкой, а узел генераторов такой же, как на П432.
Итак, при первом включении я обратил внимание на две проблемы: очень слабый уровень сигнала на линейном выходе и уже упомянутый призвук при нажатии более одной клавиши одновременно. Надо заметить, что П432 ‒ это полифонический синтезатор, и он может воспроизводить одновременно 4 голоса (частоты) одного тембра. А с включением эффекта УНИСОН количество одновременно звучащих голосов увеличивается до 8-ми, по два для каждой клавиши.
Причина тихого звука была найдена почти сразу, виноват был сгоревший выходной ОУ К544УД1А.
После его замены инструмент стал звучать громко даже при подключении к выходу пассивных наушников.
А вот со странными звуками ситуация была очень непонятной, потому что даже при нажатии отдельных клавиш звуки тембров были не похожи на демонстрации П432 с youtube.
На поиск проблемы ушло довольно много времени, но в итоге она была локализована на уровне основного ЦАП. Старший бит цифрового входа имел недостаточный уровень для признания его логической 1, поэтому выходной аналоговый сигнал искажался. Виновник этой истории был найден и устранен, после чего проблема решилась. Все тембры стали звучать чисто и без проблем при нескольких нажатиях.
Тут бы и истории конец, но времени на ремонт уже было потрачено много, поэтому я решил, что не стоит на этом останавливаться и надо разобраться:
- как устроен процесс синтеза звука
- что хранится в ПЗУ узла генератора
- как работает фильтр и его характеристики
- где хранится конфигурация для каждого тембра и параметры огибающих
Итогом этой работы должна была стать программная эмуляция П432 с использованием данных оригинальных ПЗУ.
Устройство узла генераторов
Форма сигнала на выходе основного ЦАП узла генераторов формируется по принципу прямого цифрового синтеза (DDS) [1]. Полученный аналоговый сигнал пропускается через фильтр нижних частот, затем при необходимости смешивается с выходом узла хора, усиливается выходным усилителем и подается на линейный выход. Фильтр в П432 выполнен по схеме, ранее использованной в синтезаторе «Поливокс» [3].
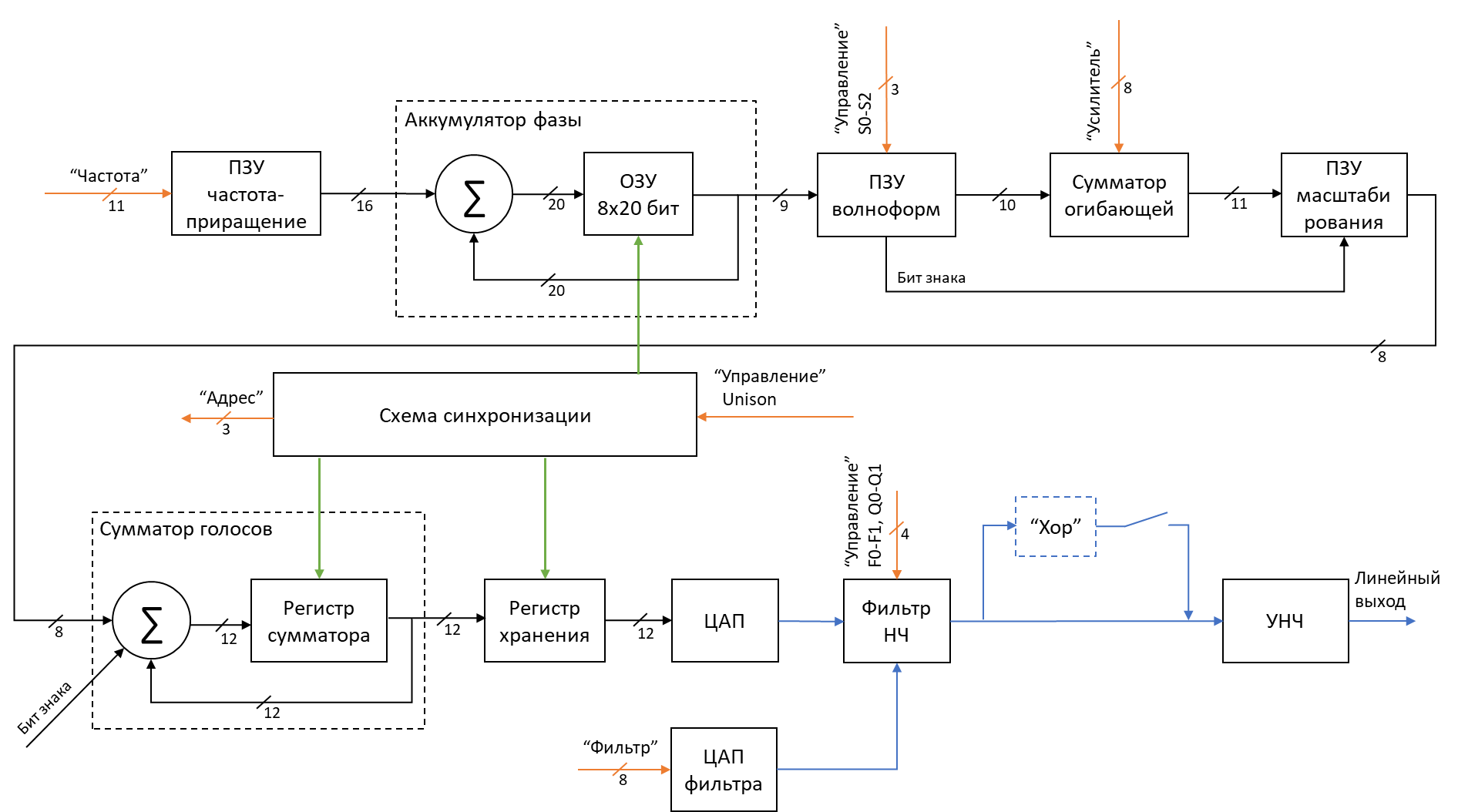
На схеме представлен узел генераторов и его основные функциональные блоки. Оранжевыми стрелками обозначены входы и выходы внешних цифровых сигналов, черными – цифровые сигналы внутри модуля, синими ‒ аналоговые сигналы.
Сначала рассмотрим входы и выходы:
- Вход «Частота» (12 бит) — для каждого голоса, включая унисон, от узла процессора приходят значения, соответствующие нажатой клавише или миди ноте.
- Вход «Усилитель» (8 бит) —значения огибающей для амплитуды сигнала.
- Вход «Фильтр» (8 бит) — значения огибающей частоты среза фильтра.
- Вход «Управление» — (8 бит) – 3 младших бита отвечают за выбор волноформы, 2 бита за смещение фильтра, еще 2 за уровень добротности фильтра Q (резонанс) и последний бит определяет, включен или нет эффект УНИСОН.
- Выход «Адрес» (3 бит) — отвечает за синхронизацию с узлом процессора.
Теперь посмотрим, как работают основные блоки узла.
Схема синхронизации с помощью мультивибраторов, счетчика и логических элементов формирует импульсы управления различными модулями узла генераторов и выдает на выход «Адрес» номер текущего голоса. При активном режиме УНИСОН «Адрес» принимает значения [0,1,2,3,4,5,6,7] а при неактивном: [0,2,4,6]. Частоту задающего генератора можно менять в небольших пределах ручкой подстройки на передней панели и джойстиком слева от клавиатуры.
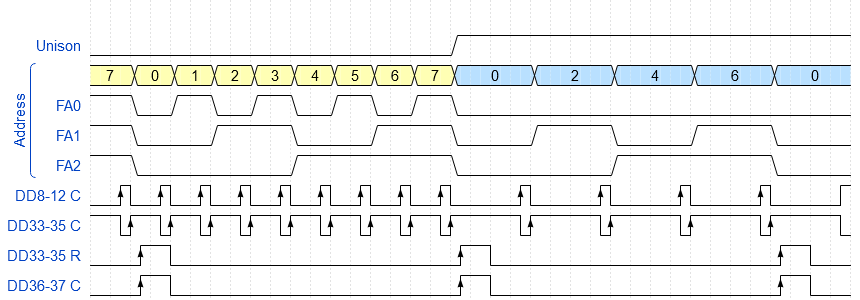 Временная диаграмма тактовых импульсов. Пояснения: Unison – лог. 0 активный уровень, FA0-2 – выход «Адрес», DD8-12 – Регистр аккумулятора фазы, DD33-35 – регистр сумматора голосов, DD36-37 – регистр ЦАП.
Временная диаграмма тактовых импульсов. Пояснения: Unison – лог. 0 активный уровень, FA0-2 – выход «Адрес», DD8-12 – Регистр аккумулятора фазы, DD33-35 – регистр сумматора голосов, DD36-37 – регистр ЦАП.
Цифровая часть платы генераторов для каждого из 4(8) голосов синхронно с изменением значения на выходе «Адрес» производит следующие операции. С узла процессора на вход «Частота» поступает значения частоты сигнала. Линейное значение частоты преобразуется в приращение фазы дешифратором на ПЗУ. Приращения суммируются в аккумуляторе фазы (20 бит), состоящем из сумматора и ОЗУ на 8 слов. Старшие 9 бит суммы подаются на адресные входы ПЗУ волноформ. Конкретная область ПЗУ выбирается тремя младшими битами входа «Управление». 10 бит с выхода ПЗУ суммируются со значением на входе «Усилитель» и подаются на входы ПЗУ масштабирования, которое формирует биполярный код для ЦАП. Выход попадает в накопительный буфер, построенный на сумматорах и регистрах, который последовательно суммирует значения кодов всех 4(8) голосов. В конце каждого цикла итоговый код защелкивается регистром хранения и попадает на 12-бит ЦАП. Частота выдачи кода на ЦАП является частотой дискретизации сигнала и составляет для П432 – около 33 килогерц. Согласно Найквисту, максимальная частота звука, доступная генератору П432, примерно равна 16,5 кГц.
Если для выбранного тембра требуется динамическое изменение параметров фильтра нижних частот, то на вход «Фильтр» выдаются значения огибающей, которые проходя через 10-бит ЦАП формируют управляющее напряжение для ОУ фильтра. ФНЧ выполнен по бесконденсаторной схеме фильтра переменных состояний и включает схему температурной стабилизации, блок изменения добротности Q и начального смещения.
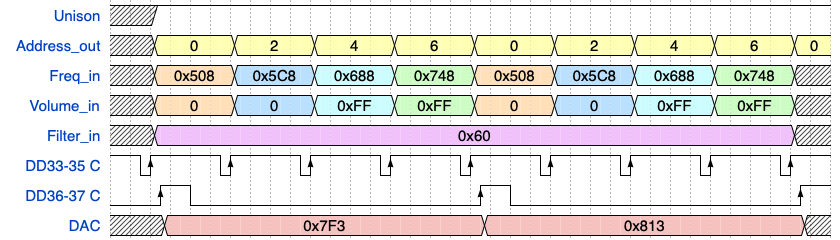
На этой временной диаграмме отображено два периода дискретизации платы генераторов. УНИСОН выключен. На вход «Частота» (Freq_in) синхронно со сменой адреса поступают номера частот четырех разных клавиш. Но нажаты только последние две из них (Volume_in=0xFF). При этом на вход «Фильтр» выдается постоянное значение (Filter_in=0x60). Финальный код поступает на вход ЦАП (DAC) после защелкивания в регистрах хранения (DD36-37).
Внимание: отображен только один период.

Более детальное описание узла генераторов
Ниже приведены подробности и схемы электрические принципиальные для желающих подробнее разобраться в устройстве синтезатора. Схемы были найдены в интернете, хотя к моему синтезатору прилагалось руководство по эксплуатации [4] и полный комплект бумажных схем [5]. Архивом с содержимым всех ПЗУ поделились добрые люди на одном форуме, но как потом оказалось, в одном из файлов была ошибка, поэтому пришлось выпаять отдельные ПЗУ и сверить их с прошивками в архиве.
Надо отметить, что за время производства П432 заводом-изготовителем было выпущено несколько ревизий плат синтезатора с целью улучшения технических характеристик, которые могут отличаться от представленных ниже схем первой ревизии.
- ПЗУ преобразования частота-приращение — DD1-2, выполненное на двух 573РФ2, содержит таблицу соответствия линейного значения частоты экспоненциальному приращению фазы. В графическом виде ее содержимое выглядит так
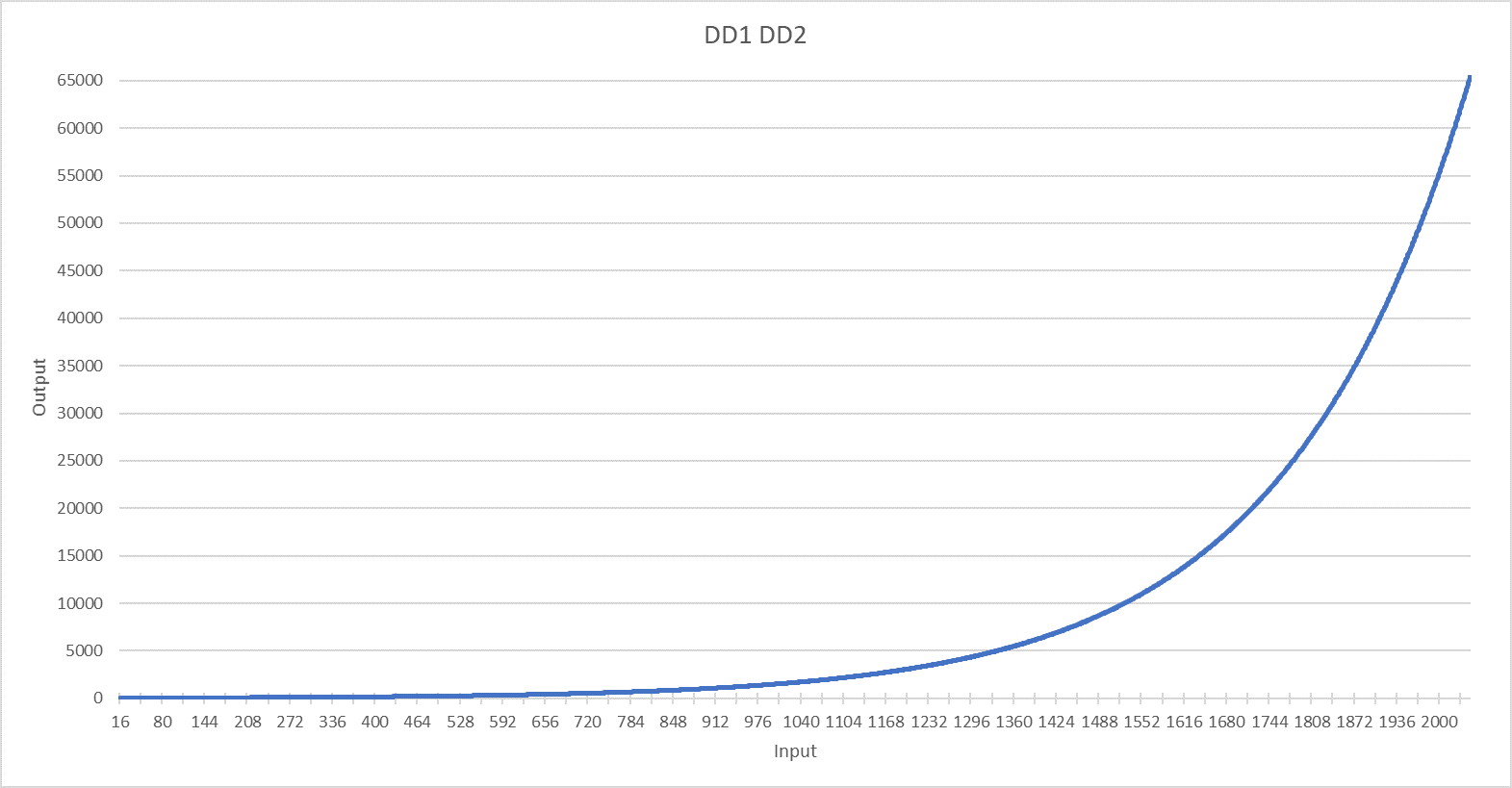
Синхронно с изменением значения на выходе «Адрес» узел процессора выдает 11-бит значения частоты соответствующего голоса на вход «Частота», которое преобразуется в 16 бит приращения.
Если рассмотреть содержимое первых 16 слов DD1-2, то там записаны какие-то странные числа, которые похоже не используются при синтезе звука: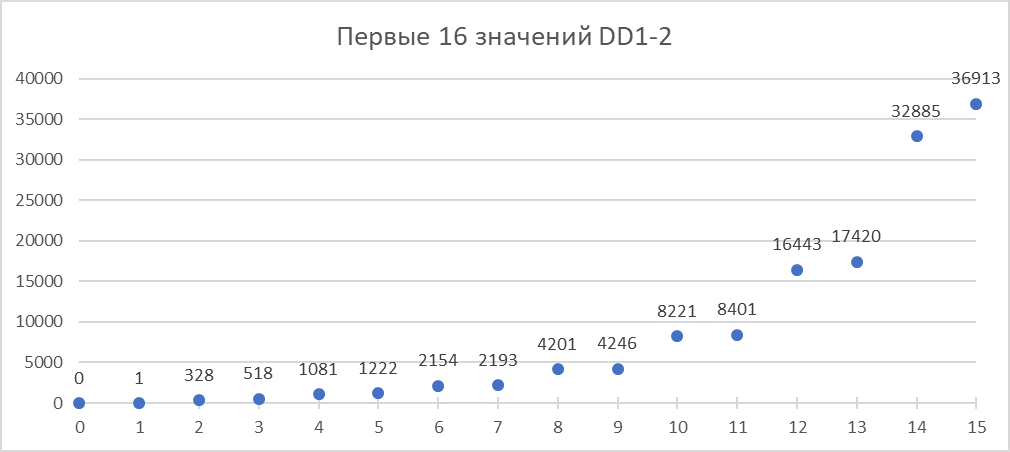
- Аккумулятор фазы — состоит из сумматоров DD3-7 (561ИМ1) и регистров DD8-12 (561ИР11). Сумматоры включены в цепочку общей разрядностью в 20 бит. Блок регистров позволяет хранить восемь 20-байтных значений фазы сигнала. Адресные входы чтения/записи регистров соединены с шиной «Адрес». Такое включение позволяет по приходу тактового импульса получать на выходе предыдущее значение и сохранять текущее со входа. Таким образом обеспечивается накопление фазы отдельно для каждого голоса синтезатора. Старшие 9 бит выхода регистров подаются на адресные входы ПЗУ волноформ.
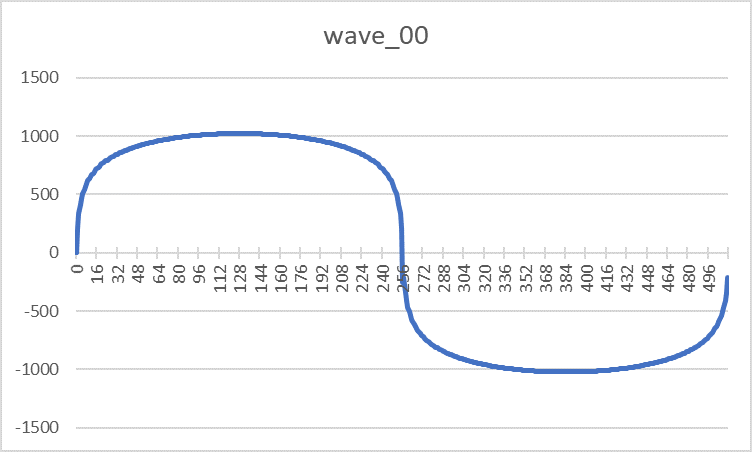
- ПЗУ волноформ — DD13-14, DD18-19 (573РФ2) содержит таблицы восьми форм сигналов, которые может синтезировать узел генераторов. Конкретная область памяти и пара ПЗУ выбирается битами S0-S2 сигнала «Управление». Под описание каждого сигнала отводится 512 слов разрядностью 11 бит. Самый старший 10 бит имеет служебное назначение, указывая на полярность сигнала: 1-положительная, 0-отрицательная. Внешний вид волноформ приведен с учетом разворота отрицательных значений:
Wave_00
 Wave_01
Wave_01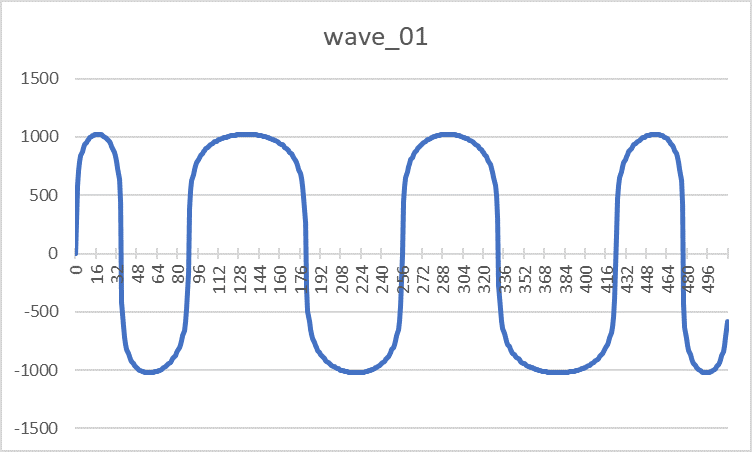 Wave_02
Wave_02 Wave_03
Wave_03 Wave_04
Wave_04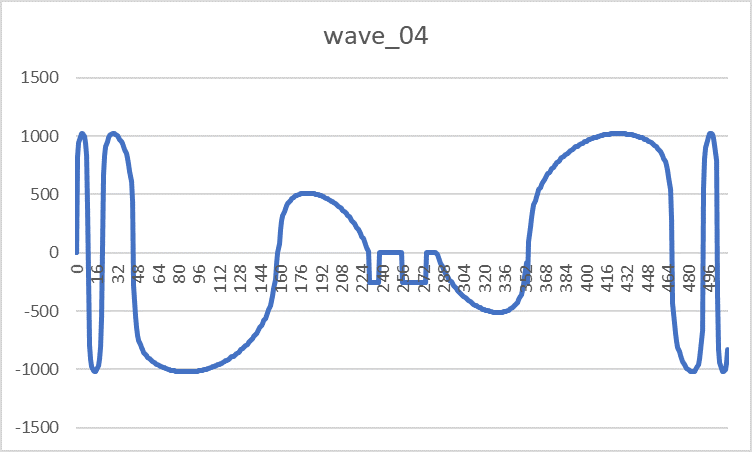 Wave_05
Wave_05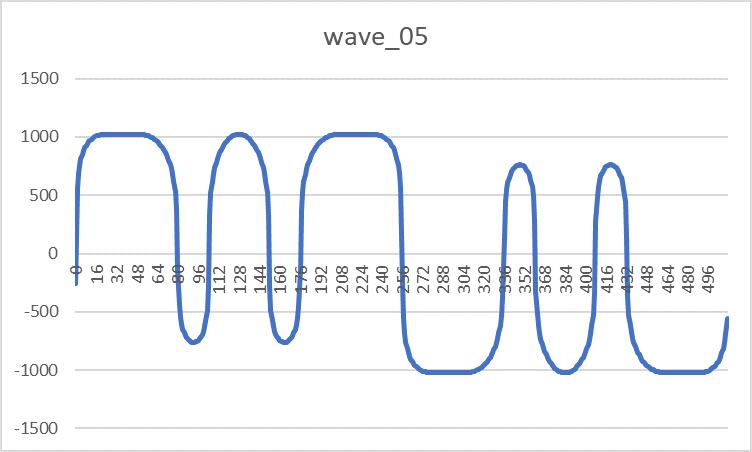 Wave_06
Wave_06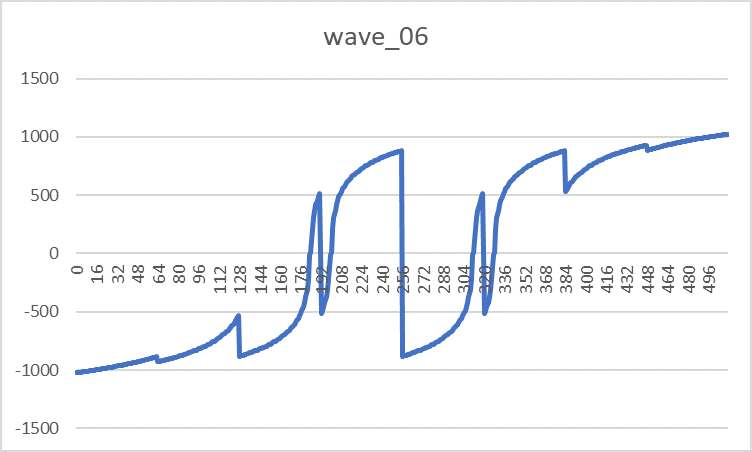 Wave_07
Wave_07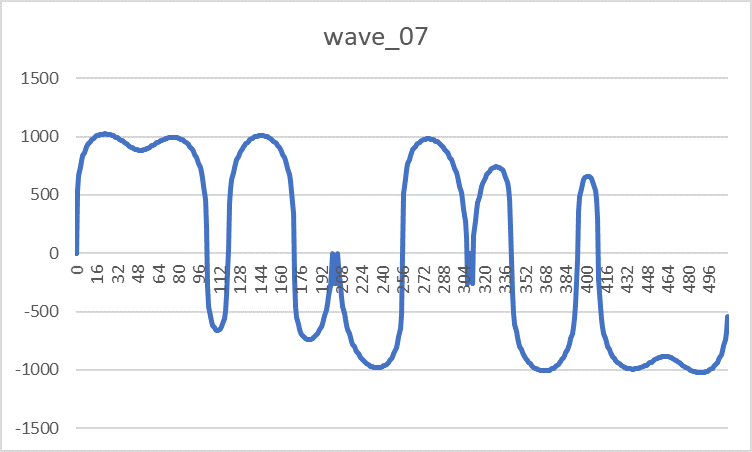
- Сумматор огибающей — на вход «Усилитель» поступает 8 бит огибающей (сдвинутой влево на 2 бита), которые суммируются на элементах DD23-25 (561ИМ1) с 10 младшими битами выхода ПЗУ волноформ. Огибающая имеет 4 фазы: Атака (Attack), Спад (Decay), Поддержка (Sustain), Затухание (Release), которые формируются узлом процессора отдельно для каждого из 4-х основных голосов в зависимости от времени нажатия/отпускания клавиши.
Пример огибающей для тембра 00: отчетливо видно быструю атаку до значения 255, затем спад до уровня поддержки 239, далее плавное уменьшение уровня, оканчивающиеся резким затуханием до 0 при отпускании клавиши. По горизонтальной оси ‒ время в секундах, по вертикальной ‒ значение входа «Усилитель».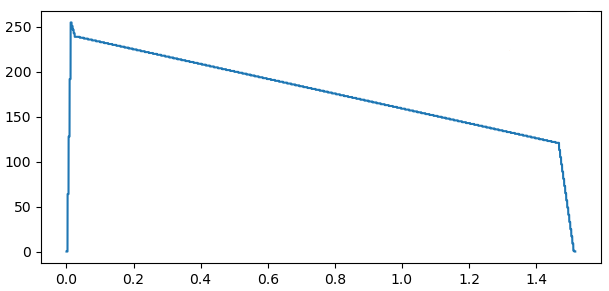
Значения в ПЗУ синтезатора подобраны таким образом, что при 0 на входе «Усилитель» на выходе ЦАП тоже будет нулевой уровень сигнала, при том, что на всех промежуточных микросхемах постоянно меняются значения переменных и генерируются разные сигналы.
- ПЗУ масштабирования, состоящее из DD27-28 (573РФ2), содержит кривые для получения кода биполярного сигнала в соответствии со значением старшего бита волноформы. В графическом виде содержимое ПЗУ выглядит так.
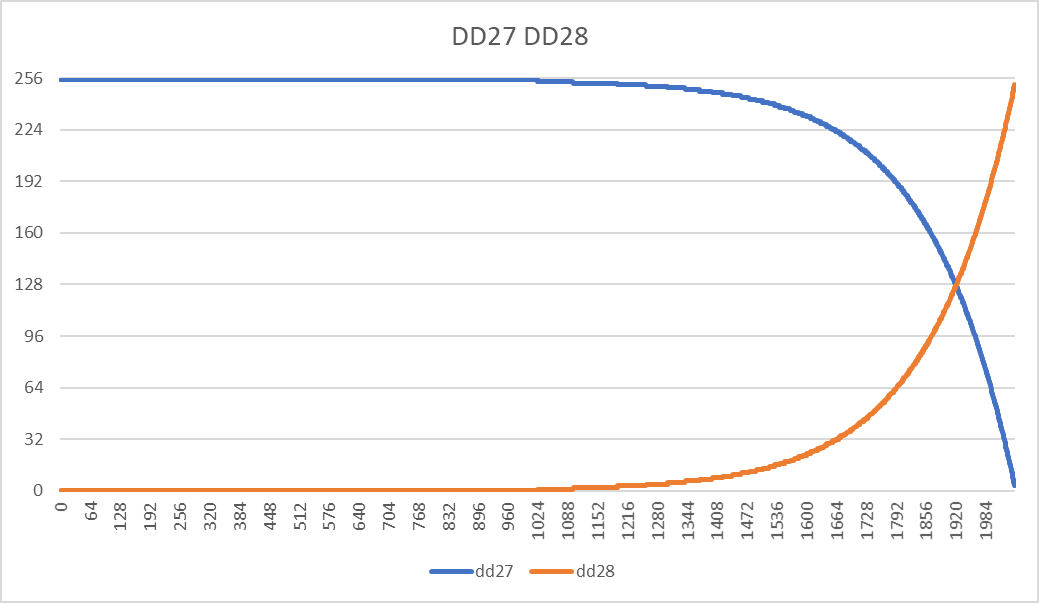
Если 10-й бит равен 1, то используется значение с выхода DD28 + 256, а если 0, то DD27 + 1.
- Сумматор голосов на DD30-32 (561ИМ1) и регистрах DD33-DD35 (561ИР9) смешивает значения кодов всех голосов перед выдачей на ЦАП. После обработки кода последнего голоса полученное значение передается дальше на регистр хранения, а регистр сумматора сбрасывается к нулю.
Пример: Как уже было упомянуто выше, если «Усилитель»=0, а максимально возможное значение амплитуды на выходе ПЗУ волноформ (1<<10)-1=1023, то на выходе ПЗУ масштабирования мы получим либо 0+256, либо 255+1 в зависимости от 10 бита волноформы, что дает в сумме 256*8=2048 и соответствует 0 на выходе ЦАП.
- Регистр хранения на элементах DD36-37 (555ТМ9) принимает и сохраняет на выходе значение кода в течение интервала дискретизации. Частота дискретизации узла генераторов примерно равна 33000Гц.
- ЦАП DA38 (534ПА1) – преобразует 12-битное значение в аналоговый биполярный сигнал, код 2048 соответствует аналоговому 0.
- Фильтр нижних частот – построен по схеме, разработанной Владимиром Кузьминым для синтезатора «Поливокс», однако в П432 добавлен узел термостабилизации тока управления ОУ фильтра. Причем взят он из того же Поливокса, где использовался для стабилизации частоты генераторов. На сайте автора можно найти инструкцию по настройке этого узла [6].
Про сам фильтр уже довольно много написано, поэтому обойдемся без подробностей.
Управление фильтром построено на 10-битном ЦАП (572ПА1), на вход которого подается 8-бит сигнал «Фильтр», представляющий собой огибающую фильтра, причем в зависимости от тембра она может быть и постоянной величиной, и вообще равняться нулю. Также на параметры фильтра влияет значение 4-х бит сигнала «Управление»: F0-F1 задают смещение выходного напряжения ЦАП, а Q0-Q1 отвечают за добротность (уровень резонанса) фильтра. - После фильтра установлен коммутатор, позволяющий включить подмешивание к основному сигналу его копии, обработанной эффектом ХОР. В ранних модификациях П432 этот же коммутатор использовался для отключения выхода звука в моменты, когда ни одна клавиша не нажата. Но в более поздних ревизиях от этого отказались, начали резать дорожки, кидать провода и добавлять в схему новые элементы.
- Усилитель – поднимает уровень выходного сигнала до 250мВ.
Конфигурация и узел процессора
Итак, с генераторами мы разобрались. Теперь осталось понять, откуда берутся все сигналы управления и где хранятся параметры их описывающие.
Сначала я планировал снять дампы всех управляющих сигналов логическим анализатором и придумать алгоритм для их описания. Например, огибающие усилителя и фильтра можно описать кусочно-линейной функцией, что требует ограниченного числа параметров.
С входом «Частота» тоже было достаточно записать для каждого тембра значения частоты какой-то одной клавиши, а все остальные рассчитывать исходя из нее.
Согласно руководству по эксплуатации П432 имеет клавиатуру в 41 клавишу объемом в 3 и 5/12 октавы с диапазоном C1-E4 в научной нотации или С1-e1 в нотации Гельмгольца. Однако на практике (для тембра 00), если исходить из соответствия А4 = 440Гц, оказалось, что звук такой частоты издает клавиша А во второй слева октаве, а это уже дает диапазон C3-E6. Как выяснилось позже, в зависимости от активного тембра диапазон воспроизводимых частот может меняться, сдвигаясь на 1 или 2 октавы.
Значения байта с входа «Управление» я также записал логическим анализатором для всех возможных тембров и свел в табличку.
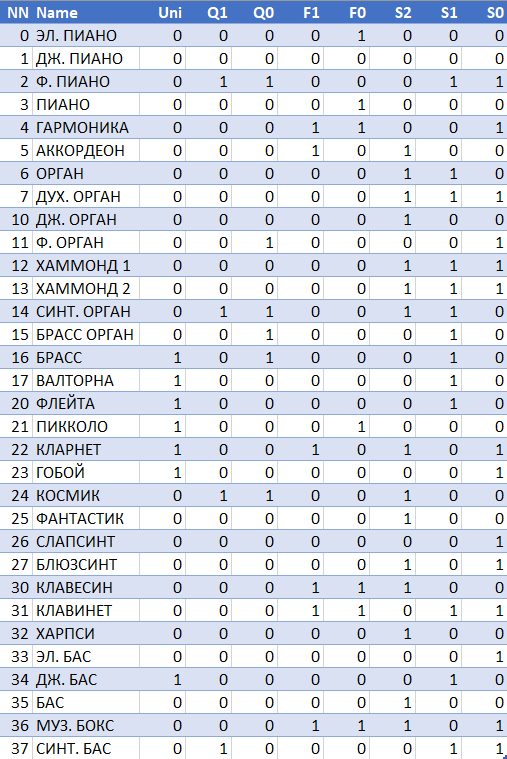
Было очевидно, что все эти конфигурационные параметры должны храниться в одной из ПЗУ синтезатора, и после небольших поисков они нашлись во второй половине прошивки DD16 узла процессора. Напомню, что объем ПЗУ 573РФ2 составляет 2048 байт.

1024 байта области конфигурации легко делились на 32 тембра, выделяя 32 байта под настройки каждого тембра. Довольно много времени я потратил на поиски корреляции между настройками тембров и реальными фазами огибающей, частотой звука и прочим. Пришлось просмотреть много дампов логического анализатора.
Как видно из таблицы, все значения можно разделить на четыре группы: описание огибающей входа «Усилитель», огибающей входа «Фильтр», байт входа «Управление» и байты, отвечающие за частоты основного голоса и УНИСОНа на входе «Частота».
Рассмотрим их поподробнее на примере огибающей Усилителя, с которой я разобрался в первую очередь. Огибающая Фильтра формируется аналогично за исключением нескольких тембров, для которых пришлось использовать хардкод, потому что по-другому получить правильную огибающую не удалось.
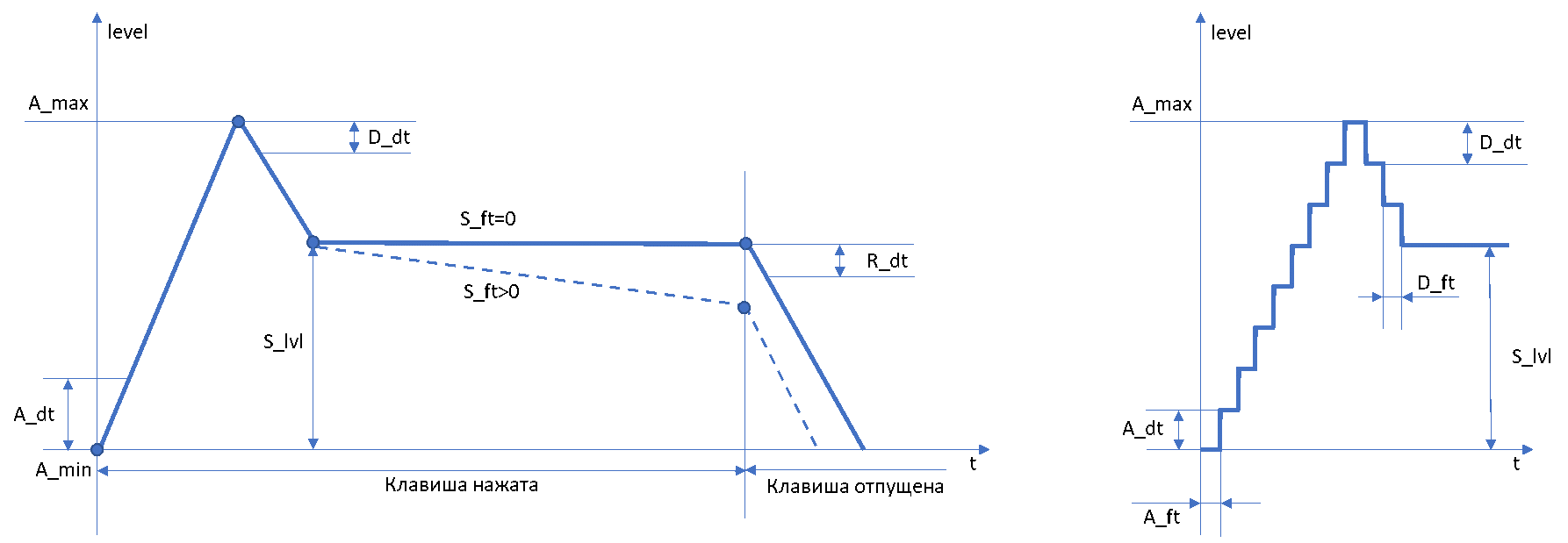
Параметры с суффиксом *_dt задают дельту изменения уровня сигнала соответствующей фазы, например, для тембра 00: A_min=0, A_dt=48 а A_max=255. Это значит, что начальное значение Атаки 0 нужно инкрементировать на 48, пока оно не достигнет 255. Для фазы Спад значение D_dt нужно декрементировать из A_max до уровня S_lvl, если S_ft>0, то уровень Поддержки должен уменьшаться с каждым интервалом S_ft на 1, моделируя плавно затухающий звук. Параметр R_dt указывает на дельту фазы Затухания: текущий уровень огибающей необходимо уменьшать на R_dt каждый временной интервал до достижения уровня 0. Реальное dt равно 1, если значение параметра *_dt<=1 и значению *_dt в других случаях.
Параметры *_ft определяют время, в течение которого значение должно оставаться неизменным, своего рода интервал дискретизации для огибающих. Эмпирически было установлено, что нулевое значение этого параметра соответствует ~ 100 периодам дискретизации ЦАП или ~ 3 мс. При значениях больше нуля время нужно рассчитывать по формуле int(256 / *_ft) * 100, т.е. *_ft является множителем для базового интервала в 100 периодов ЦАП.
Иллюстрация, на которой отображены все параметры огибающей. В правой части она продублирована с явной дискретизацией для лучшего понимаю сути параметров *_ft/*_dt.
Байт «Управление» в области конфигурации совпал с тем, что я получил эмпирически с помощью логического анализатора.
Байты частоты определяют значения входа «Частота». Как уже упоминалось выше, синтезатор может воспроизводить одновременно 4 голоса (полифония), каждому из которых, при включении УНИСОН, может быть добавлен в унисон еще один генератор с небольшой расстройкой или смещенный относительно основного на 1-2 октавы.
Частоты кодируются двумя байтами: FREQ_1, FREQ_2 для основной и FREQ_u1, FREQ_u2 для унисона. Экспериментально была выведена формула расчета значения частоты для ноты A второй октавы клавиатуры П432.
freq_offset = {4:0xd0, 5:0x90, 6:0x50}
freq = (config['FREQ_1'] << 8) + freq_offset[config['FREQ_1']] + config['FREQ_2']
Пример для тембра 00, где: FREQ_1=6, FREQ_2=8, получаем: 6 * 0x100 + 0x50 + 8 = 0х658, что согласуется с данными логического анализатора для всех тембров. Для унисона расчет аналогичен.
Стоит отметить, что для тембра 00 значение 0x658 соответствует частоте 440Гц или ноте A4.
Опытным путем было установлено, что интервал «Частоты» для соседних (включая черные) клавиш составляет 16(0x10) единиц. Следовательно, если мы знаем значение для 22-ой слева клавиши (А второй октавы) — 0x658, то можем легко получить значение для самой левой (№1): 0x508 и самой правой (№41): 0x788.
Исходя из этого можно рассчитать диапазон клавиатуры и воспроизводимых частот для разных тембров. Колонка «Частота» будет корректна только для простых волноформ.
Создание эмуляции П432 на Python
Я подумал, что было бы неплохо разделить хранение конфигурации и генерирование звука, поэтому были созданы два основных класса:
- P432data, отвечающий за подгрузку значений из образов ПЗУ и приведение конфигурации тембров в удобный для использования вид;
- P432, содержащий методы для создания форм огибающих и собственно генерации цифровых семплов.
А вот методы P432 рассмотрим поподробнее.
Основной это, конечно, gen_samples с параметром, означающим количество семплов, которое он должен вернуть. В этом методе максимально близко к прототипу воссоздана обработка сигналов от поступления значения на вход «Частота» до выхода на ЦАП. В принципе ориентируясь на схему П432, можно довольно быстро найти питоновские аналоги модулей узла генераторов. Единственное, что пришлось явно добавить, это приведение переменных к заданной размерности: 20 бит для аккумулятора фазы, 11 бит для сумматора огибающей и 12 бит для сумматора голосов. Это ограничение необходимо для того, чтобы нормально работала логика переполнения этих переменных.
Методы создания огибающих усилителя getADS и фильтра getFADS формируют списки со значениями амплитуды огибающей, из которого gen_samples берет значения в момент нажатия клавиш. К ним в компанию есть пара методов getR и getFR, формирующих фазу Затухание огибающей. Они принимают на вход параметр level — текущее значение уровня огибающий, начиная с которого он будет уменьшаться до 0.
Четыре основных голоса имеют одну и ту же форму огибающей Усилителя и Фильтра, но если для Усилителя огибающая своя для каждого голоса и запускается при нажатии клавиши, то для фильтра она общая для всех голосов, запускается от первого нажатия, перезапускается при последующих и длится до последнего отпускания. Смотри выше
Согласно руководству по эксплуатации, П432 выдает по MIDI номера нот с 36 по 77 (в реальности 76) для клавиш клавиатуры с 1 по 41 соответственно. Чтобы не изобретать велосипед, я решил использовать в эмуляторе диапазон 36-76 в качестве номеров нажатой клавиши, поэтому понадобился метод midi2freq, преобразующий номер клавиши в значения «Частоты» с учетом выбранного тембра.
Последней парой методов были key_press(midi_note) и key_release(midi_note), которые формировали словарь соответствия голоса частоте основного тона, фазе и текущей позиции огибающей.
Последний из основных метод это setprog(prog, clean=True), предназначенный для выбора активного тембра. Setprog подгружает конфигурацию нужного тембра и, если флаг clean не сброшен, очищает внутренние переменные. Если clean в значении False, то внутренние переменные не обнуляются, что позволяет переключаться между тембрами во время генерирования звука практически без щелчков и других неприятных звуков.
Для записи сгенерированных семплов в WAV файл был создал служебный метод write_wav на основе модуля wave. Для каждого семпла выполняется масштабирование для увеличения амплитуды и приведения его к signed 16bit виду.
Этих методов достаточно, чтобы получить wav файл с записью нескольких секунд любого из тембров синтезатора.
# создали экземпляр класса
p432=P432()
# выбрали тембр
p432.setprog(0)
# отключили унисон и фильтр (для чистоты эксперимента)
p432.unison=False
p432.filter_en = False
# нажали клавишу A второй октавы
p432.key_press(57)
# сгенерировали 3 секунды семплов
samples=p432.gen_samples(33000*3)
# отпустили клавишу
p432.key_release(57)
# сохранили в файл
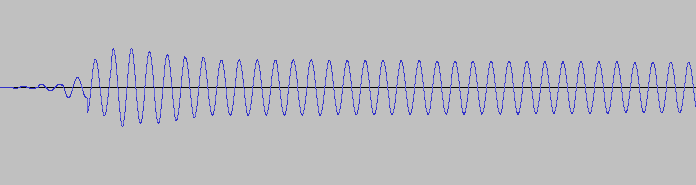
p432.write_wav('test_00.wav',samples)Волноформа тембра 00 представляет собой синусоиду, поэтому на выходе мы получим синусоиду с наложенной огибающей. Послушать.
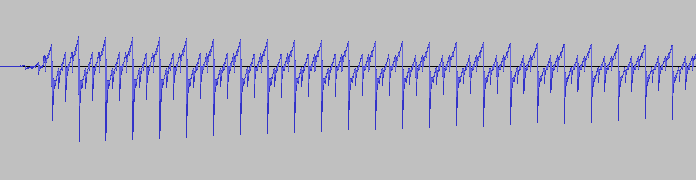
Немного интереснее будет выглядеть запись тембра 14 с включенным унисоном и фильтром. Послушать.
Графический интерфейс
Консольный генератор звуков — это хорошо, но хочется и на клавиатуре сыграть. Поэтому я решил сделать простой GUI на Tkinter.
Интерфейс делался под влиянием реального П432 с добавлением легенды по клавишам, кнопки выбора MIDI входа и возможности отключения фильтра.
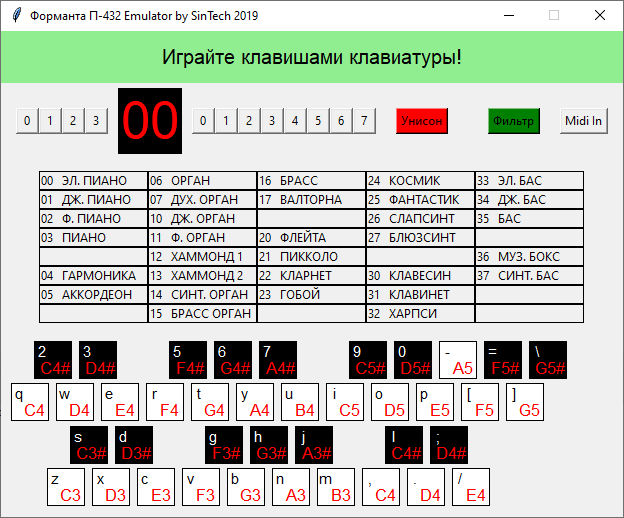
Кнопка “Midi In” появится, если у вас установлен модуль “python-rtmidi”. После ее нажатия и выбора Midi-input устройства, программа активирует callback функцию, перехватывающую события Note-On, Note-Off и Program Change на всех 16 midi каналах. Через Program Change можно менять номер активного тембра эмулятора.
Для перехвата нажатий клавиш клавиатуры используется метод Tkinter bind(''), bind(''), а затем в callback функции, номер клавиши сверяется со списком разрешенных, преобразуется в midi ноту и вызываются методы p432.key_press(), p432.key_release(). Перехват активируется при запуске программы и деактивируется при завершении.
Для вывода потокового звука используется модуль pyaudio в non-blocking режиме. После отрисовки интерфейса он запускается в отдельном Threading потоке, а tkinter продолжает работать в основном. В callback функцию, pyaudio передает количество семплов, которое надо сгенерировать, а в ответ он получает семплы от gen_samples и флаг статуса. Для уменьшения latency между событием note-on (нажатием клавиши) и появлением звука выбран достаточно маленький буфер: 200 семплов. Его задает параметр “frames_per_buffer” метода “open” pyaudio.
Скомпилированную pyinstall версию P432_emulator для Windows можно скачать в releases.
Заключение
В этой статье почти не раскрыты подробности работы аналогового фильтра в узле генераторов (и его цифровой реализации в эмуляторе), узла процессора, эффекта ХОР и MIDI-интерфейса. Акцент был сделан на устройстве цифровой части узла генераторов, способе хранения параметров тембров и использовании их при создании эмулятора.
Если тема вызовет интерес, то я запланирую вторую статью с разбором оставшегося.
Также, если вам кажется, что в описании работы узлов П432 есть ошибки или неточности, пожалуйста, пишите в комментарии.
Исходный код проекта, прошивки ПЗУ, схемы и руководство по эксплуатации доступны на github.
Список литературы
- Ридико Л. DDS: прямой цифровой синтез частоты.
- Музей Советских Синтезаторов, Форманта П432. www.ruskeys.net/base/form432.php
- Wikipedia. Поливокс.
- Инструмент электромузыкальный клавишный “Форманта П432”. Руководство по эксплуатации.
- Схемы электрические принципиальные изделия “Форманта П432”.
- Настройка температурной стабильности Поливокса.