Как датасайентисты, мы обязаны уметь анализировать и интерпретировать данные. И мы были очень обеспокоены результатами анализа данных, касающихся covid-19. Наибольшему риску подвержены самые уязвимые категории – пожилые люди и люди с достатком ниже среднего, но для контроля распространения и влияния заболевания все мы должны изменить свое поведение. Тщательно и регулярно мойте руки, избегайте скоплений людей, отменяйте мероприятия и не касайтесь своего лица. В этом сообщении мы объясним причину нашего беспокойства, и расскажем, почему вам также следует беспокоиться. Краткое изложение ключевой информации можно найти в публикации Итана Алли (Ethan Alley) Corona in Brief (автор — президент некоммерческой организации, разрабатывающей технологии для уменьшения риска пандемий).
Содержание:
- Нам нужна работоспособная медицинская система
- Это не что-то типа гриппа
- Подход «Не паникуйте, сохраняйте спокойствие» не помогает
- Это касается не только Вас
- Мы должны сделать кривую более пологой
- Реакция общества имеет значение
- Мы в США плохо проинформированы
- Заключение
1. Нам нужна работоспособная медицинская система
Всего 2 года назад одна из нас (Рэйчел) заразилась инфекцией, которая поражает мозг и убивает ¼ зараженных, а также приводит к когнитивным нарушениям у каждого третьего заразившегося. Многие переболевшие получают постоянные нарушения слуха и зрения. Рэйчел была в бреду к тому моменту, когда добралась до больницы. Ей повезло получить своевременную медицинскую помощь, диагностику и лечение. Непосредственно перед этим событием она чувствовала себя замечательно, и ее жизнь наверняка была спасена благодаря быстрому доступу к отделению скорой помощи.
Теперь давайте поговорим о covid-19 и о том, что в ближайшие недели и месяцы может случиться с людьми в ситуации, подобной ситуации с Рэйчел. Количество выявленных случаев заражения covid-19 удваивается каждые 3-6 дней. Если принять этот срок равным трем дням, за три недели число зараженных возрастет в 100 раз (на самом деле все не так просто, но не будем отвлекаться на технические детали). Каждый десятый инфицированный нуждается в длительной (много недель) госпитализации, и большинству таких пациентов требуется подача кислорода. Хотя распространение вируса только начинается, в некоторых регионах больницы уже переполнены, и люди лишены возможности получить требуемое лечение (в различных состояниях, а не только в случае заражения covid-19). Например, в Италии, где всего неделю назад власти говорили, что все хорошо, сейчас 16 млн. человек находятся на карантине (upd: спустя 6 часов после публикации была закрыта вся страна). Чтобы помочь справиться с наплывом пациентов, устанавливают палатки вроде этой:
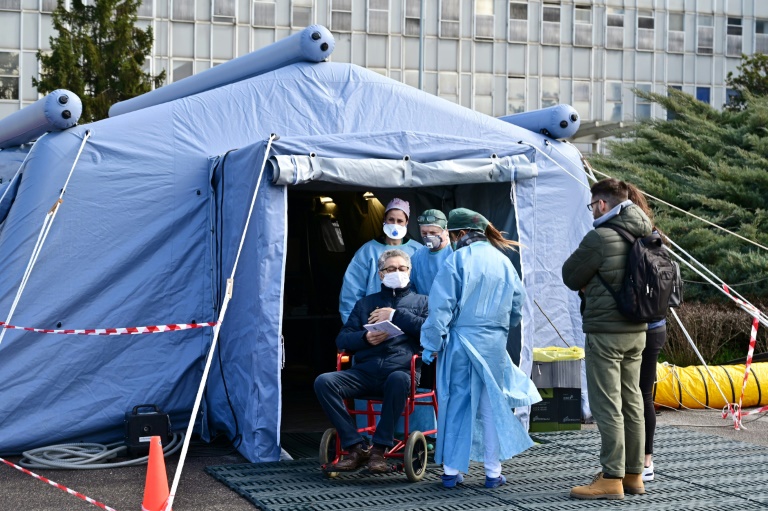
Доктор Antonio Pesenti, глава регионального центра по борьбе с кризисом в наиболее сильно пострадавшем районе Италии, говорит: «Нам приходится организовывать отделения интенсивной терапии в коридорах, операционных и комнатах для реабилитации… Одна из наилучших систем здравоохранения в мире, в Ломбардии, находится в шаге от краха».
2. Это не что-то типа гриппа
Смертность при гриппе составляет примерно 0,1%. Марк Липсич (Marc Lipsitch), директор Center for Communicable Disease Dynamics в Гарварде, дает оценку для covid-19 на уровне 1-2%. Новейшее эпидемиологическое моделирование дает уровень смертности 1,6% для Китая в феврале, то есть в 16 раз выше, чем при гриппе1 (это может быть весьма консервативной оценкой, поскольку смертность резко возрастает, когда система здравоохранения перестает справляться). Лучшие на сегодняшний день оценки говорят, что covid-19 в этом году убьет в 10 раз больше людей, чем грипп (а модель Елены Гриваль (Elena Grewal), бывшего датасайенс-директора в Airbnb, в худшем случае дает оценку в 100 раз больше, чем грипп). И все это не принимая по внимание важное влияние системы здравоохранения, о чем было сказано выше. Можно понять, почему некоторые люди убеждают себя, будто не происходит ничего нового и это болезнь типа гриппа. Весьма некомфортно осознавать, что на самом деле они с таким вообще не сталкивались.
Наш мозг не приспособлен к интуитивному восприятию экспоненциального роста числа зараженных. Поэтому будем проводить анализ как ученые, не опираясь на интуицию.

Каждый зараженный гриппом в среднем заражает 1,3 других людей. Этот показатель называется R0. Если R0 меньше 1, инфекция прекращает распространяться, а если больше 1, происходит ее дальнейшее распространение. Для covid-19 за пределами Китая R0 сейчас составляет 2-3. Разница может показаться незначительной, но после 20 «итераций» заражения в случае R0=1,3 количество зараженных составит 146 человек, а для R0=2,5 – 36 млн.! Это упрощенные расчеты, но они служат разумной иллюстрацией относительной разницы между covid-19 и гриппом.
Обратите внимание, что R0 не является фундаментальной характеристикой заболевания. Этот показатель в значительной степени зависит от реакции [на заболевание] и может меняться со временем2. Например, в Китае R0 для covid-19 быстро уменьшается и сейчас достигает 1! Вы спросите, как такое возможно? Путем применения мер, масштаб которых тяжело представить в странах типа США – например, полная изоляция многих гигантских городов и разработка диагностических процедур, позволяющих выполнять проверку миллиона человек в неделю.
В соцсетях (включая популярные аккаунты, такие как аккаунт Илона Маска) часто можно видеть непонимание разницы между логистическим и экспоненциальным ростом. Логистический рост на практике соответствует S-образной форме кривой распространения эпидемии. Разумеется, экспоненциальный рост тоже не может продолжаться бесконечно, поскольку количество зараженных всегда ограничено численностью населения Земли. Вследствие этого уровень заболеваемости должен уменьшаться, приводя в итоге к S-образной кривой (сигмоиде) для зависимости скорости роста от времени. Тем не менее, уменьшение достигается определенными путями, а не магическим образом. Основные способы:
- массовая и эффективная реакция общества;
- доля заболевших настолько велика, что остается слишком мало незаболевших для дальнейшего распространения инфекции.
Таким образом, неразумно ссылаться на логистическую кривую роста как на способ «контроля» пандемии.
Другим сложным аспектом для интуитивного понимания влияния covid-19 на местное общество является очень значительная задержка между заражением и госпитализацией – обычно около 11 дней. Может показаться, что это не очень долго, но такой срок означает, что к моменту заполнения всех койко-мест в больницах число зараженных будет в 5-10 раз превышать количество госпитализированных.
Заметим, что есть некоторые ранние признаки влияния климата на распространение инфекции. В публикации Temperature and latitude analysis to predict potential spread and seasonality for COVID-19 говорят о том, что пока что болезнь распространяется в умеренном климате (к несчастью для нас, температура в Сан-Франциско, где мы живем, как раз находится в нужном диапазоне; сюда же попадают густонаселенные регионы Европы, включая Лондон).
3. Подход «Не паникуйте, сохраняйте спокойствие» не помогает
В соцсетях людям, указывающим на причины для беспокойства, часто советуют «не паниковать» или «сохранять спокойствие». Это, как минимум, бесполезно. Никто не утверждает, что паника является приемлемой реакцией. Но есть причины, по которым «сохранение спокойствия» является распространенной реакцией в определенных кругах (но не среди эпидемиологов, чьей работой является отслеживание таких вещей). Возможно, «сохранение спокойствия» помогает людям комфортнее воспринимать собственное бездействие, или же позволяет чувствовать свое превосходство над теми, кто, по их мнение, бегают вокруг как курица без головы.
Но «сохранение спокойствия» легко может помешать подготовиться и адекватно среагировать. В Китае были изолированы десятки миллионов граждан и построены две больницы к тому моменту, как статистика заболевания достигла уровня, наблюдаемого сейчас в США. Италия ждала слишком долго, и лишь сегодня (8 марта) было сообщено о 1492 новых случаях и 133 новых смертях, несмотря на пребывание 16 млн. человек на карантине. Основываясь на наиболее достоверной доступной нам информации, всего 2-3 недели назад по статистике заболеваемости Италия была на том же уровне, что США и Великобритания сейчас.
Обратите внимание, что на данном этапе у нас мало знаний о covid-19. На самом деле мы не знаем, какая у него скорость распространения или летальность, как долго он сохраняется на поверхностях, может ли он выживать и распространяться в теплых условиях. Все, что у нас есть, это предположения, основанные на собранной воедино наиболее достоверной информации. И помните, что основная часть информации приходит из Китая на китайском языке. Сейчас наилучшим источником для понимания китайского опыта является отчет Report of the WHO-China Joint Mission on Coronavirus Disease 2019, основанный на совместном работе 25 экспертов из Китая, Германии, Японии, Кореи, Нигерии, России, Сингапура, США и ВОЗ.
В условиях такой неуверенности насчет того, что глобальной пандемии не будет и все, возможно, обойдется без краха системы здравоохранения, бездействие не кажется правильной реакцией. Это было бы чрезвычайно рискованным и неоптимальным при любом смоделированном сценарии. Также выглядит маловероятным, что такие страны, как Италия и Китай, фактически остановили значительные сегменты своей экономики без веской причины. И еще бездействие не согласуется с фактическим влиянием, которое мы наблюдаем в зараженных регионах, где медицинская система не в состоянии справиться с ситуацией (например, в Италии используют 462 палатки для предварительной сортировки пациентов, и там по-прежнему требуется вывоз находящихся в реанимации пациентов из зараженных областей.
Вместо этого обдуманная и разумная реакция состоит в выполнении шагов, которые рекомендуются экспертами для предотвращения распространения инфекции:
- Избегайте больших мероприятий и толп людей
- Отменяйте мероприятия
- По возможности работайте из дома
- Мойте руки по приходу домой, а также когда выходите на улицу и проводите время вне дома
- Старайтесь не прикасаться к лицу, особенно когда вы вне дома (это непросто!)
- Дезинфицируйте поверхности и упаковки (возможно, вирус сохраняет активность на поверхностях до 9 дней, хотя это точно неизвестно).
4. Это касается не только Вас
Если вы моложе 50 лет и у вас нет таких факторов риска, как ослабленная иммунная система, сердечно-сосудистые заболевания, история курения в прошлом или хронические заболевания, вы можете с достаточной степенью быть уверенным, что COVID19 вряд ли вас убьет. Но Ваша реакция на происходящее по-прежнему крайне важна. У вас все еще есть такой же шанс заразиться, как у всех, и в случае заражения, так же много шансов заразить других. В среднем каждый инфицированный заражает более двух человек, и они становятся заразными до того, как проявляются симптомы. Если у вас есть родители, о которых вы волнуетесь, или бабушка с дедушкой, и вы планируете провести с ними время, а после обнаружите, что несете ответственность за их заражение вирусом COVID19, это будет тяжким бременем.
Даже если вы не контактируете с людьми старше 50 лет, скорее всего, у вас больше коллег и знакомых с хроническими заболеваниями, чем вы думаете. Исследования показывают, что немногие люди раскрывают свое состояние здоровья на работе, если могут этого избежать, опасаясь дискриминации. Мы оба [Рэйчел и я] в категориии высокого риска, но многие люди, с которыми мы регулярно общаемся, возможно, не знали об этом.
И, конечно же, речь идет не только о людях в Вашем непосредственном окружении. Это очень важный этический вопрос. Каждый человек, который делает все возможное для борьбы с распространением вируса, помогает всему сообществу в целом снизить уровень заражения. Как писала Зейнеп Туфекчи (Zeynep Tufekci) в журнале Scientific Amercian: «Подготовка к почти неизбежному глобальному распространению этого вируса… является одной из самых просоциальных, альтруистических вещей, которые вы можете сделать». Она продолжает:
Нам следует подготовиться, не потому, что мы лично чувствуем себя в опасности, а чтобы помочь уменьшить риск для всех. Мы должны подготовиться не потому, что мы сталкиваемся со сценарием конца света вне нашего контроля, а потому что мы можем изменить каждый аспект этого риска, с которым мы столкнулись как общество. Все верно, Вы должны готовиться, потому что ваши соседи нуждаются в Вашей подготовке — особенно ваши пожилые соседи, соседи, которые работают в больницах, соседи с хроническими заболеваниями и ваши соседи, у которых может не быть средств или времени на подготовку.
Это коснулось лично нас. Самый обширный и самый важный курс, который мы когда-либо создавали на fast.ai, который представляет собой кульминацию нашей многолетней работы, должен был начаться в Университете Сан-Франциско через неделю. В прошлую среду (4 марта) мы приняли решение перенести все это в онлайн. Мы были одними из первых крупных курсов, которые перешли в онлайн режим. Почему мы это сделали? Поскольку в начале прошлой недели мы осознали, что, если мы проведем этот курс, мы будем косвенно поощрять сотни людей собираться в замкнутом пространстве несколько раз в течение нескольких недель. Худшее, что можно сделать, это собирать группы людей в замкнутом пространстве, и нашим моральным долгом было избежать этого. Решение было тяжелым, ведь наша работа с учащимися каждый год была для нас наибольшим удовольствием и наиболее продуктивным периодом. И были студенты, которые собирались прилететь из-за границы, которых мы не хотели подводить3.
Но мы знали, что поступаем правильно, потому что в противном случае поспособствовали бы распространению заболевания в нашем сообществе4.
5. Мы должны сделать кривую более пологой
Это крайне важно, поскольку, если мы можем снизить скорость распространения инфекции в обществе, это позволит больницам справляться и с потоком инфицированных, и с их обычными пациентами. Иллюстрация ниже наглядно это показывает:
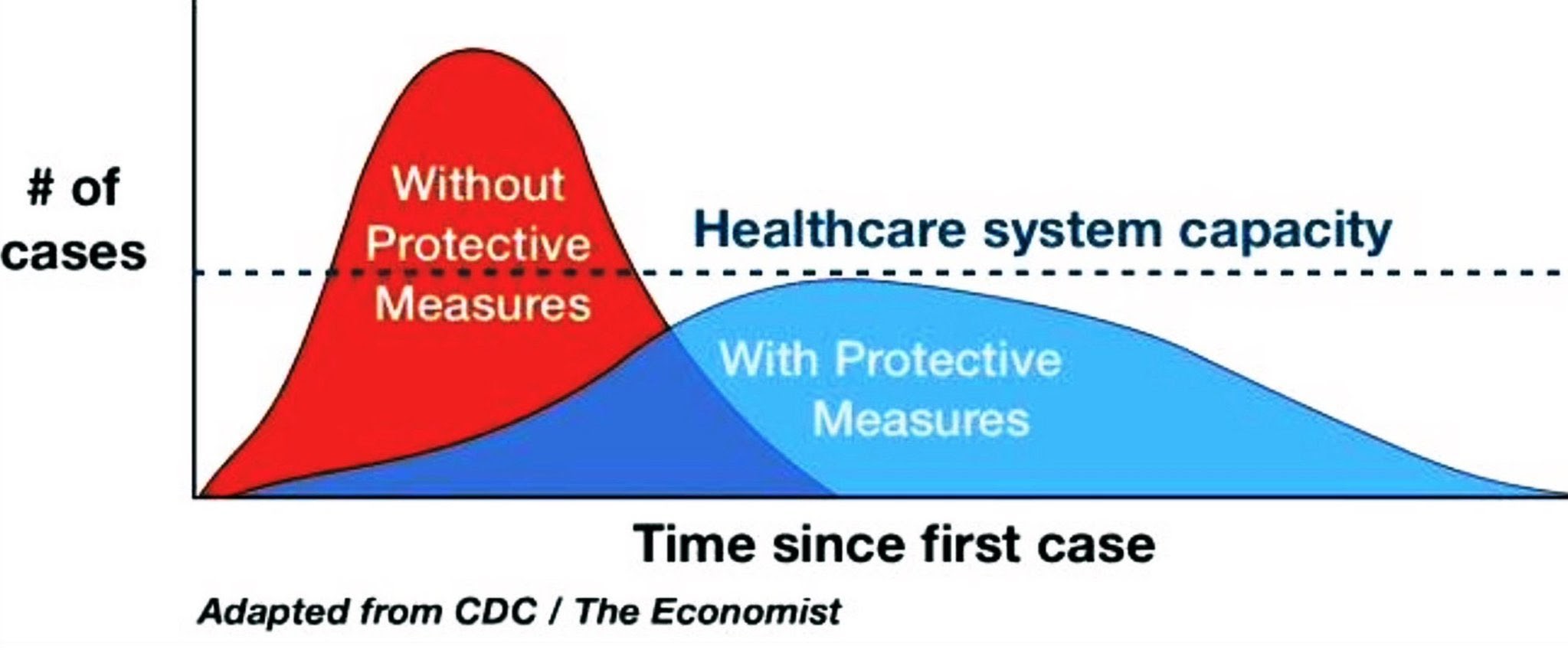
Фарзад Мосташари (Farzad Mostashari), бывший национальный координатор Health IT, поясняет: «Новые случаи среди не путешествовавших и не имевших контактов с зараженными выявляются каждый день, и мы знаем, что это лишь вершина айсберга из-за задержек с проверкой. Это означает взрывной рост количества зараженных в следующие две недели… Попытка сдерживания при экспоненциальном распространении в обществе — это все равно, что сосредоточиться на тушении искр, когда горит весь дом. Когда это происходит, нам нужно переключиться на ослабление — принять защитные меры для замедления распространения и снижения пикового воздействия на здравоохранение». Если мы будем поддерживать скорость распространения на достаточно низком уровне, больницы смогут справиться с нагрузкой, и пациенты получат требуемое лечение. Иначе нуждающиеся в госпитализации госпитализированы не будут.
Согласно расчетам Лизы Шпект (Liz Specht):
В США имеется примерно 2,8 больничных коек на 1000 человек. При численности населения 330 млн. это дает примерно 1 млн. коек, 65% из которых постоянно заняты. Таким образом, всего доступно 330 тыс. коек (возможно, немного меньше из-за сезонного гриппа и пр.). Давайте поверим опыту Италии и будем считать, что примерно 10% случаев достаточно серьезны, чтобы потребовалась госпитализация. И помним, что часто госпитализация длится неделями – другими словами, койки с больными COVID19 будут освобождаться очень медленно. По таким оценкам все больничные койки будут заняты к 8 мая. И при этом мы не учитываем приспособленность данных койко-мест к содержанию пациентов с вирусными заболеваниями. Если мы ошибаемся насчет доли тяжелых случаев в 2 раза, это сдвигает время насыщения больниц всего на 6 дней в том или ином направлении. Все это не предполагает роста потребности в местах из-за других причин, что выглядит сомнительным предположением. С ростом нагрузки на систему здравоохранения и появлением дефицита рецептурных препаратов люди с хроническими заболеваниями могут оказаться в ситуации, требующей ухода и госпитализации.
6. Реакция общества имеет значение
Как уже обсуждалось, в этих цифрах нет уверенности – Китай уже продемонстрировал, что экстремальные меры позволяют снизить распространение заболевания. Другим прекрасным примером является Вьетнам, где, среди прочего, общенациональная рекламная кампания (включая навязчивую песню!) быстро мобилизовала население и обеспечила требуемые изменения в поведении.
Эти расчеты не гипотетические – все было проверено во время пандемии гриппа в 1918 г. В США два города совершенно по-разному среагировали: в Филадельфии прошел гигантский парад с участием 200 тыс. человек для сбора денег на войну. Но в Сент-Луисе были минимизированы социальные контакты для уменьшения распространения вируса, а также отменены все массовые мероприятия. Так выглядело количество смертей в каждом из городов по данным Proceedings of the National Academy of Sciences:
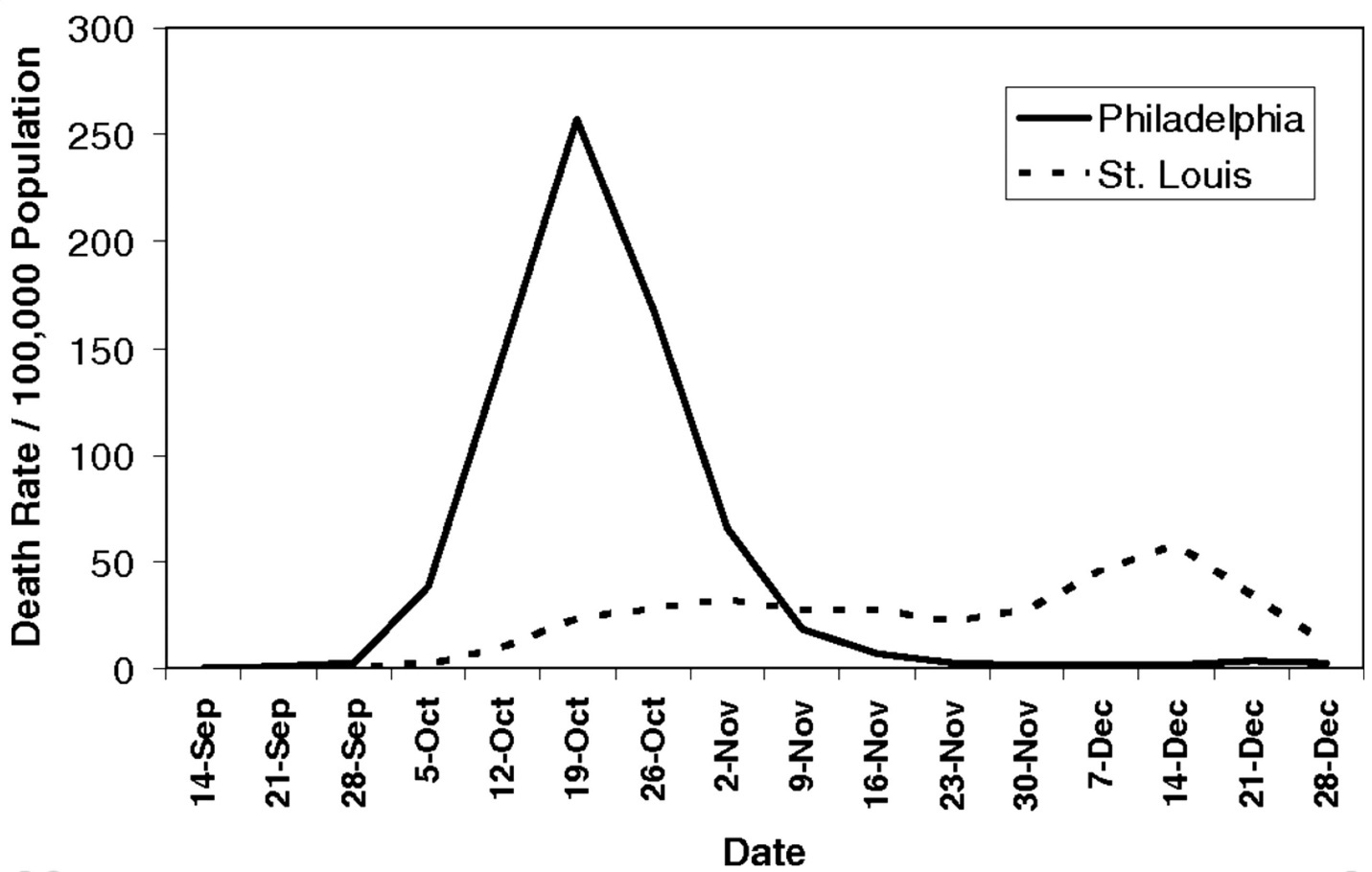
Ситуация в Филадельфии стала крайне тяжелой, не хватало гробов и моргов, чтобы справиться с огромным количеством умерших.
Ричар Бессер (Richard Besser), который был исполнительным директором ЦКЗ (Centers for Disease Control and Prevention) во время пандемии H1N1 в 2009, говорит, что в США «риск заражения и способность защитить себя и свою семью зависят, среди прочих факторов, от дохода, доступа к медицинской помощи и иммиграционного статуса». Он утверждает:
Пожилые люди и люди с ограниченными возможностыми подвергаются особому риску, когда их повседневная жизнь и система поддержки нарушаются. Те, у кого нет легкого доступа к медицинской помощи, в том числе сельские жители и коренное население, могут столкнуться с потребностью преодолевать огромными расстояниями в случае необходимости. Люди, живущие в стесненных условиях — будь то социальное жилье, дома престарелых, тюрьмы, приюты (или даже бездомные на улицах) — могут поражаться волнами, как мы уже видели в штате Вашингтон. И уязвимые сферы экономики с низкой заработной платой, с неоплачиваемыми работниками и нестабильным графиком работы, будут выставлены на всеобщее обозрение во время этого кризиса. Спросите 60 процентов рабочей силы в США, которые получают почасовую оплату, насколько легко отказаться от работы при необходимости.
Бюро трудовой статистики США показывает, что менее трети лиц с самым низким доходом имеют доступ к оплачиваемому отпуску по болезни:

7. Мы в США плохо проинформированы
Одна из больших проблем в США – в том, что проводится очень мало тестов на коронавирус, а результаты испытаний не распространяются должным образом, и мы толком не знаем, что на самом деле происходит. Скотт Готлиб (Scott Gottlieb), бывший уполномоченный Управления по контролю за продуктами и лекарствами (FDA), объяснил, что в Сиэтле проводилось более качественное тестирование, и поэтому там мы наблюдаем инфекцию: «Причина, по которой мы рано узнали о вспышке COVID-19 в Сиэтле, заключалась в работе санитарно-эпидемиологического надзора [sentinel surveillance] независимых ученых. Такой надзор никогда не проводился в подобном масштабе в других городах. Таким образом, другие горячие точки США могут быть еще не полностью обнаружены”. По сообщению The Atlantic, вице-президент Майк Пенс (Mike Pence) пообещал, что на этой неделе будет доступно «примерно 1.5 миллиона тестов», но на данный момент в США было протестировано менее 2000 человек. Опираясь на результаты The COVID Tracking Project, Робинсон Мейер (Robinson Meyer) и Алексис Мадригал (Alexis Madrigal) из The Atlantic утверждают:
Собранные нами показания свидетельствуют о том, что реакция США на вирус COVID-19 и вызываемое им заболевание была чрезвычайно инертной, особенно по сравнению с другими развитыми странами. Восемь дней назад Центр по контролю и профилактике заболеваний (CDC) подтвердил, что в США вирус распространяется среди людей, а именно, что он заражал американцев, которые не ездили за границу и не общались с теми, кто ездил. В Южной Корее более 66 650 человек прошли тестирование в течение недели после первого случая заражения, и очень быстро стало возможным тестировать 10 000 человек в день.
Отчасти проблема в том, что это стало политическим вопросом. Президент Дональд Трамп дал понять, что он хочет, чтобы число людей, инфицированных в США, оставалось низким. Это пример того, как оптимизация показателей мешает получению хороших результатов на практике (подробнее об этой проблеме изложено в статье об этике Data Science – The Problem with Metrics is a Fundamental Problem for AI). Глава Google AI Джефф Дин (Jeff Dean) выразил в Твиттере свои опасения по поводу политизированной дезинформации:
Когда я работал во Всемирной Организации Здравоохранения (ВОЗ), я был причастен к Глобальной Программе по СПИДу (ныне UNAIDS), созданной для того, чтобы помочь миру справиться с пандемией ВИЧ / СПИДа. Там работали добросовестные врачи и ученые, сосредоточенные на оказании помощи в преодолении этого кризиса. Во время кризиса важна четкая и достоверная информация, которая поможет принять обоснованное решение о том, как реагировать (на всех уровнях: страны, штата, местных органов власти, компании, НКО, школы, семьи и отдельного человека). Имея доступ к верной информации и советам лучших медицинских и научных экспертов, мы справимся с проблемами, будь то ВИЧ / СПИДом или COVID-19. Но в случае дезинформации, движимой политическими интересами, есть огромный риск серьезно усугубить положение, если не действовать быстро и решительно перед лицом растущей пандемии, а наоборот, активно способствовать более быстрому распространению болезни. Очень больно смотреть, как все это происходит прямо сейчас.
Не похоже, что найдутся политическая силы, заинтересованные в прозрачности ситуации вокруг COVID-19. Министр здравоохранения и социальных служб [Health and Human Services Secretary] Алекс Азар (Alex Azar), по словам Wired, «начал обсуждать тесты, которые медицинские работники используют, чтобы определить, заражен ли кто-то из них новым коронавирусом. Но нехватка таких тестов означает нехватку информации о распространении и серьезности эпидемиологического заболевания в США, усугубляемую непрозрачностью со стороны правительства. Азар упоминал, что новые тесты сейчас проходят контроль качества». Но далее, согласно Wired:
Затем Трамп прервал Азара. «Я считаю, главное, что любой человек, нуждающийся в тестировании, проходит его. Тесты есть, и они хороши. Любого нуждающегося в проверке проверяют», — сказал Трамп. Это неправда. В четверг вице-президент Пенс (Pence) заявил журналистам, что в США не хватает тестов на COVID-19 для удовлетворения спроса.
Другие страны реагируют гораздо оперативнее, чем США. Многие страны Юго-Восточной Азии хорошо сдерживают распространение вируса. Например, Тайвань, где R0 сейчас снизился до 0.3, или Сингапур, который вообще послужил примером того, как государство должно реагировать на COVID-19. Это речь не только об Азии; во Франции, например, запрещены любые мероприятия с 1000 и более участников, и в настоящее время школы закрыты в трех районах.
8. Заключение
COVID-19 – это важная социальная проблема, и мы все не только можем, но и должны приложить все усилия, чтобы уменьшить распространение болезни. Для этого:
- Избегайте больших мероприятий и толп людей (social distancing)
- Отменяйте культурные и прочие массовые мероприятия
- По возможности работайте из дома
- Мойте руки по приходу домой, а также когда выходите на улицу и проводите время вне дома
- Старайтесь не прикасаться к лицу, особенно когда вы вне дома
Примечание: из-за необходимости опубликовать это сообщение как можно раньше мы были чуть менее чем обычно скрупулезны в том, что касается цитирования источников информации, на которые мы опираемся. Пожалуйста, дайте нам знать, если мы что-то упустили.
Спасибо Сильвену Гуггеру (Sylvain Gugger) и Алексису Галлахеру (Alexis Gallagher) за обратную связь в виде ценных комментариев.
Примечания:
1 Эпидемиологи — это люди, которые изучают распространение болезней. Оказывается, что оценить такие вещи, как смертность и R0, на самом деле довольно сложно, поэтому есть целая область, которая специализируется на этом. Остерегайтесь людей, которые используют простые соотношения и статистику, чтобы рассказать вам, как ведет себя covid-19. Вместо этого посмотрите на моделирование, выполненное эпидемиологами.
2 Технически это неверно. Строго говоря, R0 относится к уровню распространения инфекции при отсутствии реакции. Но так как на самом деле это не то, что нас волнует, мы позволим себе быть немного неаккуратными в определениях.
3 После этого решения мы усердно работали над тем, чтобы найти способ запустить виртуальный курс, который, как мы надеемся, будет даже лучше, чем очная версия. Мы смогли открыть его для всех в мире, и каждый день будем работать с виртуальными учебными и проектными группами.
4 Мы также внесли много других небольших изменений в наш образ жизни, в том числе занимались спортом дома, вместо того чтобы ходить в спортзал, заменили все наши встречи на видео-конференции и пропускали ночные мероприятия, которых мы с нетерпением ждали.
Над переводом работали А.Огурцов, Ю.Кашницкий и Т.Габрусева.
Let's block ads! (Why?)