StarCraft: Brood War. Как много это значит для меня. И для многих из вас. Настолько много, что я засомневался, давать ли ссылку на вики.
Как-то раз мне в личку постучался Halt и предложил выучить Rust. Как и любые нормальные люди, мы решили начать с hello world написания динамической библиотеки под Windows, которая могла бы загружаться в адресное пространство игры StarCraft и управлять юнитами.
В статье будет описан процесс поиска решений, использования технологий, приемов, которые позволят вам почерпнуть новое в языке Rust и его экосистеме или вдохновиться для реализации бота на своем любимом языке.
Эту статью стоит читать непременно под
BWAPI
Этой игре уже 20 лет. И она до сих пор популярна, чемпионаты собирают целые залы людей в США даже в 2017 году, где состоялась битва грандмастеров Jaedong vs Bisu. Помимо живых игроков, в битвах участвуют и бездушные машины! И это возможно благодаря BWAPI. Больше полезных ссылок.
Итак, команда фанатов несколько лет назад отреверсила внутреннести Starcraft и написала на C++ API, которое позволяет писать ботов, внедряться в процесс игры и господствовать над жалкими людишками.
Как это часто бывает, прежде чем построить дом, надо добыть руду, выковать инструменты... написать бота, необходимо реализовать API. Что же может предложить со своей стороны Rust?
FFI
Взаимодействовать с другими языками из Rust довольно просто. Для этого существует FFI. Позвольте мне предоставить краткую выдержку из документации.
Пусть у нас есть библиотека snappy, у которой есть заголовочный файл snappy-c.h, из которого мы будем копировать объявления функций.
Создадим проект с помощью cargo.
$ cargo new --bin snappy
Created binary (application) `snappy` project
$ cd snappy
snappy$ tree
.
├── Cargo.toml
└── src
└── main.rs
1 directory, 2 files
Cargo создал стандартную файловую структуру для проекта.
В Cargo.toml укажем зависимость к libc:
[dependencies]
libc = "0.2"
src/main.rs файл будет выглядеть так:
extern crate libc; // Для определения C типов, в нашем случае для size_t
use libc::size_t;
#[link(name = "snappy")] // Указываем имя библиотеки для линковки функции
extern {
// Пишем руками объявление функции, которую хотим импортировать
// В C объявление выглядит:
// size_t snappy_max_compressed_length(size_t source_length);
fn snappy_max_compressed_length(source_length: size_t) -> size_t;
}
fn main() {
let x = unsafe { snappy_max_compressed_length(100) };
println!("max compressed length of a 100 byte buffer: {}", x);
}
Собираем и запускаем:
snappy$ cargo build
...
snappy$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/snappy`
max compressed length of a 100 byte buffer: 148
Можно вызвать только cargo run, который перед запуском вызывает cargo build. Либо собрать проект и вызвать бинарник напрямую:
snappy$ ./target/debug/snappy
max compressed length of a 100 byte buffer: 148
Код скомпилируется при условии, что библиотека snappy установлена(для Ubuntu надо поставить пакет libsnappy-dev).
snappy$ ldd target/debug/snappy
...
libsnappy.so.1 => /usr/lib/x86_64-linux-gnu/libsnappy.so.1 (0x00007f8de07cf000)
Как можно увидеть, наш бинарник слинкован с разделяемой библиотекой libsnappy. И вызов snappy_max_compressed_length является вызовом функции из этой библиотеки.
rust-bindgen
Было бы хорошо, если бы мы могли в автоматическом режиме сгенерировать FFI. К счастью, в арсенале растоманов есть такая утилита под названием rust-bindgen. Она умеет генерировать FFI байндинги к C (и некоторым C++) библиотекам.
Установка:
$ cargo install bindgen
Как выглядит использование rust-bindgen? Мы берем заголовочные файлы C/C++, натравливаем на них утилиту bindgen, на выходе получаем сгенерированный Rust код с определениями сишных структур и функций. Вот как выглядит генерация FFI для snappy:
$ bindgen /usr/include/snappy-c.h | grep -C 1 snappy_max_compressed_length
extern "C" {
pub fn snappy_max_compressed_length(source_length: usize) -> usize;
}
Оказалось, что bindgen пасует перед заголовками BWAPI, генерируя тонны неюзабельных простынок кода (из-за виртуальных функций-членов, std::string в публичном API и т.д.). Все дело в том, что BWAPI написан на C++. C++ вообще сложно использовать даже из C++ проектов. Однажды собранную библиотеку лучше влинковывать тем же линковщиком (одинаковых версий), заголовочные файлы лучше парсить тем же компилятором (одинаковых версий). Потому что существует множество факторов, которые могут повлиять на исход. Например, манглинг, который в GNU GCC до сих пор не могут реализовать без ошибок. Эти факторы настолько значимы, что их не смогли побороть даже в gtest, а в документации указали, что лучше бы вам собирать gtest как часть проекта тем же компилятором и тем же линковщиком.
BWAPI-C
C — это лингва франка программирования. Если rust-bindgen хорошо работает для языка C, почему бы не реализовать BWAPI для C, а потом использовать его API? Хорошая идея!
Да, хорошая идея, пока ты не заглянул в кишки BWAPI и не увидел кол-во классов и методов, которые необходимо реализовать =( Особенно все эти расположения структур в памяти, ассемблеры, патчинг памяти и прочие ужасы, на которые у нас нет времени. Надо по максимуму заиспользовать уже существующее решение.
Но надо как-то бороться с манглингом, C++ кодом, наследованиями и виртуальными функциями-членами.
В C++ есть два мощнейших инструмента, которыми мы воспользуемся для решения нашей задачи, это непрозрачные указатели и extern "C".
extern "C" {} дает возможность C++ коду замаскироваться под C. Это позволяет генерировать чистые имена функций без манглинга.
Непрозрачные указатели дают нам возможность стереть тип и создавать указатель в "какой-то тип", чью реализацию мы не предоставляем. Так как это лишь объявление какого-то типа, а не его реализация, то использовать этот тип по значению невозможно, можно использовать лишь по указателю.
Допустим, у нас есть такой C++ код:
namespace cpp {
struct Foo {
int bar;
virtual int get_bar() {
return this->bar;
}
};
} // namespace cpp
Мы можем превратить в такой C заголовок:
extern "C" {
typedef struct Foo_ Foo; // Непрозрачный указатель на Foo
// объявляем cpp::Foo::get_bar
int Foo_get_bar(Foo* self);
}
И C++ часть, которая будет связующим звеном между C заголовком и C++ реализацией:
int Foo_get_bar(Foo* self) {
// кастуем непрозрачный указатель к конкретному cpp::Foo и вызываем метод ::get_bar
return reinterpret_cast<cpp::Foo*>(self)->get_bar();
}
Не все методы классов пришлось обрабатывать таким образом. В BWAPI есть классы, операции над которыми можно реализовать самому, используя значения полей этих структур, например typedef struct Position { int x; int y; } Position; и методы вроде Position::get_distance.
Были и те, над которыми пришлось постараться особенным образом. Например, AIModule должен быть указателем на C++ класс с определенным набором виртуальных функций-членов. Тем не менее, вот заголовок и реализация.
Итак, спустя несколько месяцев кропотливой работы, 554 метода и десяток классов, на свет родилась кроссплатформенная библиотека BWAPI-C, которая позволяет писать ботов на C. Побочным продуктом стала возможность кросскомпиляции и возможность реализовать API на любом другом языке, который поддерживает FFI и соглашение о вызове cdecl.
Если вы пишите библиотеку, пожалуйста, пишите API на C.
Пишем бота на C
Эта часть описывает общие принципы устройства модулей Starcraft.
Существуют 2 типа ботов: модуль и клиент. Мы рассмотрим пример написания модуля.
Модуль — это загружаемая библиотека, общий принцип загрузки можно посмотреть здесь. Модуль должен экспортировать 2 функции: newAIModule и gameInit.
С gameInit все просто, эта функция вызывается для передачи указателя на текущую игру. Этот указатель очень важен, так как в дебрях BWAPI живет глобальная статическая переменная, которая используется в некоторых участках кода. Опишем gameInit:
DLLEXPORT void gameInit(void* game) {
BWAPIC_setGame(game);
}
newAIModule чуть посложнее. Он должен возвращать указатель на C++ класс, у которого существует виртуальная таблица методов с именами onXXXXX, которые вызываются на определенные игровые события. Определим структуру модуля:
typedef struct ExampleAIModule
{
const AIModule_vtable* vtable_;
const char* name;
} ExampleAIModule;
Первым полем обязательно должен быть указатель на таблицу методов (магия, все дела). Итак, функция newAIModule:
DLLEXPORT void* newAIModule() {
ExampleAIModule* const module = (ExampleAIModule*) malloc( sizeof(ExampleAIModule) );
module->name = "ExampleAIModule";
module->vtable_ = &module_vtable;
return createAIModuleWrapper( (AIModule*) module );
}
createAIModuleWrapper — это еще одна магия, которая превращает С указатель в указатель на С++ класс с виртуальными методами функциями-членами.
module_vtable — это статическая переменная на таблицу методов, значения методов заполнены указателями на глобальные функции:
static AIModule_vtable module_vtable = {
onStart,
onEnd,
onFrame,
onSendText,
onReceiveText,
onPlayerLeft,
onNukeDetect,
onUnitDiscover,
onUnitEvade,
onUnitShow,
onUnitHide,
onUnitCreate,
onUnitDestroy,
onUnitMorph,
onUnitRenegade,
onSaveGame,
onUnitComplete
};
void onEnd(AIModule* module, bool isWinner) { }
void onFrame(AIModule* module) {}
void onSendText(AIModule* module, const char* text) {}
void onReceiveText(AIModule* module, Player* player, const char* text) {}
void onPlayerLeft(AIModule* module, Player* player) {}
void onNukeDetect(AIModule* module, Position target) {}
void onUnitDiscover(AIModule* module, Unit* unit) {}
void onUnitEvade(AIModule* module, Unit* unit) {}
void onUnitShow(AIModule* module, Unit* unit) {}
void onUnitHide(AIModule* module, Unit* unit) {}
void onUnitCreate(AIModule* module, Unit* unit) {}
void onUnitDestroy(AIModule* module, Unit* unit) {}
void onUnitMorph(AIModule* module, Unit* unit) {}
void onUnitRenegade(AIModule* module, Unit* unit) {}
void onSaveGame(AIModule* module, const char* gameName) {}
void onUnitComplete(AIModule* module, Unit* unit) {}
По названию функций и их сигнатур понятно, при каких условиях и с какими аргументами они вызываются. Для примера я все функции сделал пустыми, кроме
void onStart(AIModule* module) {
ExampleAIModule* self = (ExampleAIModule*) module;
Game* game = BWAPIC_getGame();
Game_sendText(game, "Hello from bwapi-c!");
Game_sendText(game, "My name is %s", self->name);
}
Данная функция вызывается при старте игры. В качестве аргумента передается указатель на текущий модуль. BWAPIC_getGame возвращает глобальный указатель на игру, который мы установили с помощью вызова BWAPIC_setGame. Итак, покажем пример кросскомпиляции и работы модуля:
bwapi-c/example$ tree
.
├── BWAPIC.dll
└── Dll.c
0 directories, 2 files
bwapi-c/example$ i686-w64-mingw32-gcc -mabi=ms -shared -o Dll.dll Dll.c -I../include -L. -lBWAPIC
bwapi-c/example$ cp Dll.dll ~/Starcraft/bwapi-data/
bwapi-c/example$ cd ~/Starcraft/bwapi-data/
Starcraft$ wine bwheadless.exe -e StarCraft.exe -l bwapi-data/BWAPI.dll --headful
...
...
...
Тыкаем в кнопочки и запускаем игру. Подробнее про запуск можно прочитать на сайте BWAPI и в BWAPI-C.
Результат работы модуля:
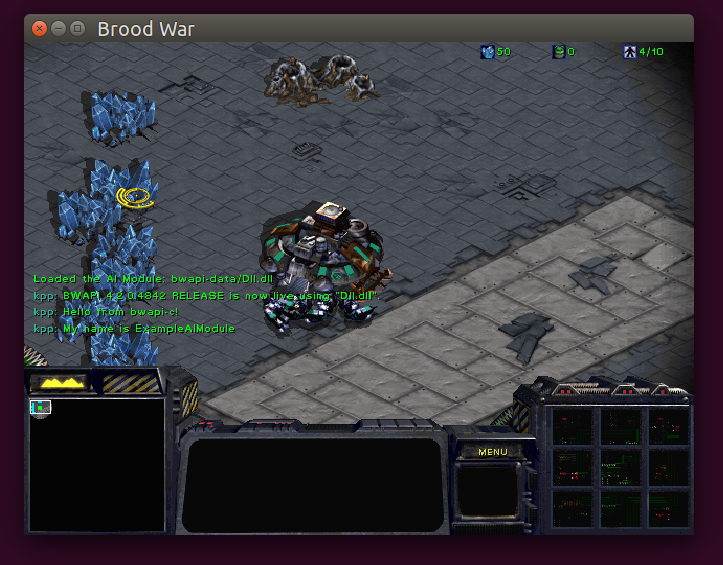
Чуть более сложный пример модуля, который показывает работу с итераторами, управлением юнитов, поиском минералов, выводом статистики можно найти в bwapi-c/example/Dll.c.
bwapi-sys
В экосистеме Раста принято определенным образом называть пакеты, которые линкуются к нативным библиотекам. Любой пакет foo-sys занимается двумя важными функциями:
- Линкуется к нативной библиотеке libfoo
- Предоставляет объявления к функциям из библиотеки libfoo. Но только лишь объявления, высокоуровневые абстракции в *-sys крейтах не предоставляются.
Чтобы *-sys пакет умел успешно линковаться, в него встраивают поиск нативной библиотеки и/или сборку библиотеки из исходников.
Чтобы *-sys пакет предоставил объявления, надо или написать их руками, или сгенерировать с помощью bindgen. Снова bindgen. Попытка номер два =)
Генерация байндингов с помощью bwapi-c становится до неприличия простой:
bindgen BWAPI.h -o lib.rs \
--opaque-type ".+_" \
--blacklist-type "std.*|__.+|.+_$|Game_v(Send|Print|Draw).*|va_list|.+_t$" \
--no-layout-tests \
--no-derive-debug \
--raw-line "#![allow(improper_ctypes, non_snake_case)]" \
-- -I../submodules/bwapi-c/include
sed -i -r -- 's/.+\s+(.+)_;/pub struct \1;/' lib.rs
Где BWAPI.h — файл с инклудами всех сишных заголовков из BWAPI-C.
Например, для уже известных функций bindgen сгенерировал такие объявления:
extern "C" {
/// BWAPIC_setGame must be called from gameInit to initialize BWAPI::BroodwarPtr
pub fn BWAPIC_setGame(game: *mut Game);
}
extern "C" {
pub fn BWAPIC_getGame() -> *mut Game;
}
Существуют 2 стратегии: хранение сгенерированного кода в репозитории и генерация кода на лету при сборке. И тот и другой подход имеет свои преимущества и недостатки.
Приветствуем bwapi-sys, еще одну маленькую ступень к нашей цели.
Помните, я говорил про кроссплатформенность? К проекту присоединился nlinker и реализовал хитрую стратегию. Если целевой таргет — Windows, то скачиваем уже собранную BWAPIC из гитхаба. А для остальных таргетов собираем BWAPI-C из исходников для OpenBW (расскажу чуть позже).
bwapi-rs
Теперь, когда у нас есть байндинги, мы можем описывать высокоуровневые абстракции. У нас есть 2 типа, с которыми надо работать: чистые значения и непрозрачные указатели.
С чистыми значениями все проще. Возьмем за пример цвета. Нам надо добиться удобного использования из Rust кода, чтобы можно было использовать цвета удобным и естественным образом:
game.draw_line(CoordinateType::Screen, (10, 20), (30, 40), Color::Red);
^^^
Значит для удобного использования надо будет определить идиоматическое для языка Rust перечисление с константами из C++ и определить методы конвертирования в bwapi_sys::Color с помощью типажа std::convert::From:
// FFI version
#[repr(C)]
#[derive(Copy, Clone)]
pub struct Color {
pub color: ::std::os::raw::c_int,
}
// Idiomatic version
#[derive(PartialEq, PartialOrd, Copy, Clone)]
pub enum Color {
Black = 0,
Brown = 19,
...
Хотя для удобства можно воспользоваться крейтом enum-primitive-derive.
С непрозрачными указателями ничуть не сложнее. Для этого воспользуемся паттерном Newtype:
pub struct Player(*mut sys::Player);
То есть Player — это некая структура с приватным полем — сырым непрозрачным указателем из C. И вот как можно описать метод Player::color:
impl Player {
// так объявлен метод Player::getColor в bwapi-sys
//extern "C" {
// pub fn Player_getColor(self_: *mut Player) -> Color;
//}
pub fn color(&self) -> Color {
// bwapi_sys::Player_getColor - обертка функции из BWAPI-C
// self.0 - сырой указатель
let color = unsafe { bwapi_sys::Player_getColor(self.0) };
color.into() // каст bwapi_sys::Color -> Color
}
}
Теперь мы можем написать своего первого бота на Rust!
Пишем бота на Rust
В качестве proof of concept бот будет похож на одну известную страну: весь его функционал будет заключаться в найме рабочих и сборе минералов.


Начнем с обязательных функций gameInit и newAIModule:
#[no_mangle]
pub unsafe extern "C" fn gameInit(game: *mut void) {
bwapi_sys::BWAPIC_setGame(game as *mut bwapi_sys::Game);
}
#[no_mangle]
pub unsafe extern "C" fn newAIModule() -> *mut void {
let module = ExampleAIModule { name: String::from("ExampleAIModule") };
let result = wrap_handler(Box::new(module));
result
}
#[no_mangle] выполняет ту же функцию, что и extern "C" в C++. Внутри wrap_handler происходит всякая магия с подстановкой таблицы виртуальных функций и маскировкой под C++ класс.
Описание структуры модуля еще проще и красивее, чем в C:
struct ExampleAIModule {
name: String,
}
Добавим пару методов для отрисовки статистики и раздачи приказов:
impl ExampleAIModule {
fn draw_stat(&mut self) {
let game = Game::get();
let message = format!("Frame {}", game.frame_count());
game.draw_text(CoordinateType::Screen, (10, 10), &message);
}
fn give_orders(&mut self) {
let player = Game::get().self_player();
for unit in player.units() {
match unit.get_type() {
UnitType::Terran_SCV |
UnitType::Zerg_Drone |
UnitType::Protoss_Probe => {
if !unit.is_idle() {
continue;
}
if unit.is_carrying_gas() || unit.is_carrying_minerals() {
unit.return_cargo(false);
continue;
}
if let Some(mineral) = Game::get()
.minerals()
.min_by_key(|m| unit.distance_to(m))
{
// WE REQUIRE MORE MINERALS
unit.right_click(&mineral, false);
}
}
UnitType::Terran_Command_Center => {
unit.train(UnitType::Terran_SCV);
}
UnitType::Protoss_Nexus => {
unit.train(UnitType::Protoss_Probe);
}
UnitType::Zerg_Hatchery |
UnitType::Zerg_Lair |
UnitType::Zerg_Hive => {
unit.train(UnitType::Zerg_Drone);
}
_ => {}
};
}
}
}
Чтобы тип ExampleAIModule превратился в настоящий модуль, необходимо научить его отзываться на события onXXXX, для чего надо реализовать типаж EventHandler, который является аналогом виртуальной таблицы AIModule_vtable из C:
impl EventHandler for ExampleAIModule {
fn on_start(&mut self) {
Game::get().send_text(&format!("Hello from Rust! My name is {}", self.name));
}
fn on_end(&mut self, _is_winner: bool) {}
fn on_frame(&mut self) {
self.draw_stat();
self.give_orders();
}
fn on_send_text(&mut self, _text: &str) {}
fn on_receive_text(&mut self, _player: &mut Player, _text: &str) {}
fn on_player_left(&mut self, _player: &mut Player) {}
fn on_nuke_detect(&mut self, _target: Position) {}
fn on_unit_discover(&mut self, _unit: &mut Unit) {}
fn on_unit_evade(&mut self, _unit: &mut Unit) {}
fn on_unit_show(&mut self, _unit: &mut Unit) {}
fn on_unit_hide(&mut self, _unit: &mut Unit) {}
fn on_unit_create(&mut self, _unit: &mut Unit) {}
fn on_unit_destroy(&mut self, _unit: &mut Unit) {}
fn on_unit_morph(&mut self, _unit: &mut Unit) {}
fn on_unit_renegade(&mut self, _unit: &mut Unit) {}
fn on_save_game(&mut self, _game_name: &str) {}
fn on_unit_complete(&mut self, _unit: &mut Unit) {}
}
Сборка и запуск модуля так же просты, как и для C:
bwapi-rs$ cargo build --example dll --target=i686-pc-windows-gnu
bwapi-rs$ cp ./target/i686-pc-windows-gnu/debug/examples/dll.dll ~/Starcraft/bwapi-data/Dll.dll
bwapi-rs$ cd ~/Starcraft/bwapi-data/
Starcraft$ wine bwheadless.exe -e StarCraft.exe -l bwapi-data/BWAPI.dll --headful
...
...
...
И видео работы:
OpenBW
Эти ребята пошли еще дальше. Они решили написать open-source версию игры SC:BW! И у них неплохо получается. Одной из их целей была реализация HD картинки, но SC: Remastered их опередили =( На данный момент можно использовать их API для написания ботов (да, тоже на C++). Но самой умопомрачительной фичей является возможность просматривать реплеи прямо в браузере.
Заключение
При реализации осталась нерешенная проблема: мы не контролируем уникальность ссылок, а одновременное существование &mut и & при изменении объекта приведет к неопределенному поведению. Беда. Но для решения этой задачи придется качественно перелопатить C++ API и правильно проставить const квалификаторы.
Мне очень понравилось работать над этим проектом, я 하루종일 смотрел реплеи и глубоко погрузился в атмосферу. Эта игра оставила 믿어지지 않을 정도인 наследие. Ни одну игру нельзя 비교할 수 없다 по популярности с SC:BW, а ее влияние на 대한민국 정치에게 оказалось немыслимым. Прогеймеры в Корее 아마도 так же популярны, как и 드라마 주연 배우들 корейских дорам, транслирующихся в прайм-тайм. 또한, 한국에서 프로게이머라면 군대의 특별한 육군에 입대할 수 있다.
Да здравствует StarCraft!
Ссылки
bwapi-rs — https://github.com/RnDome/bwapi-rs
bwapi-sys — https://github.com/RnDome/bwapi-sys
bwapi-c — https://github.com/RnDome/bwapi-c
bwapi — https://github.com/bwapi/bwapi/
openbw — http://openbw.com/
Let's block ads! (Why?)










 Впервые о E-метре стало известно в 40-х годах прошлого века. Его создал изобретатель и мануальный терапевт из США Волней Мэтисон. Изначально прибор назывался Mathison Model B Electropsychometer — «электропсихометр Мэтисона модель Б. Мэтисон». Сам Мэтисон был психоаналитиком, приверженцем школы Фрейда.
Впервые о E-метре стало известно в 40-х годах прошлого века. Его создал изобретатель и мануальный терапевт из США Волней Мэтисон. Изначально прибор назывался Mathison Model B Electropsychometer — «электропсихометр Мэтисона модель Б. Мэтисон». Сам Мэтисон был психоаналитиком, приверженцем школы Фрейда.