
Общая сводка. На фото выше представлена 3D модель разработанной мной платы при помощи САПР Altium Designer. Основные характеристики и функционал:
- 10\100 Mb Ethernet
- RTC
- MicroSD (FAT12, FAT16, FAT32) 4GB
- RS232 \ RS485
- CAN
- Buzzer
- 3 User LED
- GPIO
- 32 KB EEPROM
- 2MB FLASH
- I2C
- SPI
- UART
- SW \ JTAG
- USB serial (COM Port)
- Power: miniUSB 5V \ External 9..24V
Стоимость собранной платы ~ 5000 Р. За исходниками можно обращаться в личку или на почту, проект носит open source характер. То, что получилось в итоге, помимо основного функционала, можно считать неплохой отладочной платой для работы с микроконтроллером STM32.
А теперь к подробностям создания.
Hardware
Изучение данной задачи началось с поиска и оценки готовых решений. Основными требованиями были:
- преобразование поступающих CAN2.0B фреймов в TCP\IP пакеты и наоборот;
- невысокая стоимость, как следствие реализация устройства на базе микроконтроллера.
У коллег из Китая есть несколько промышленных решений, но не из дешевых, поэтому в наш офис на тест был доставлен представитель отечественного производства «Преобразователь интерфейсов ПИРС CAN-Ethernet». По описанным возможностям и характеристикам устройство удовлетворяло скромное Т.З., оставалось лишь проверить работоспособность на деле, чем я и занялся, вооружившись Wireshark’ом и осциллографом. По неизвестной причине при отправке в девайс TCP пакетов на выходе устройства, там, где должны были появляться CAN фреймы, выплёвывались последовательности с физическими уровнями CAN (диф. пара), но логическим протоколом интерфейса UART (со стартовыми и стоповыми битами). Вскрыв корпус, открыв документацию микросхем и прозвонив дорожки платы, обнаружилось, что, действительно, пины RX и TX (UART) микроконтроллера соединены с трансивером CAN и с него выведены на внешний разъем. Таким образом, никакой аппаратной поддержки стандарта CAN2.0B ожидать не приходилось.
Вот, что я увидел на выводе CANL «ПИРС CAN-Ethernet» при отправке двух байт данных [0xF0] и [0x0A] по TCP\IP:

Порядок бит перевернут, но с этим можно бороться программно, а вот со стартовыми и стоповыми битами через каждый байт что-то сделать на уровне приложения уже сложнее т.к. они вставляются аппаратно.
А вот как должен был выглядеть «истинный» CAN2.0B фрейм с теми же двумя байтами данных:

Как видно из осциллограммы, помимо байт данных в фрейме присутствует немало служебных бит протокола плюс биты стаффинга, а что самое главное – идут они непрерывно без всяких стартовых и стоповых! (Для тех, кому интересно, под спойлером детальное описание данной посылки).

Первые 4 байта – идентификатор фрейма. Подробнее о формате CAN можно узнать из [1]
Таким образом, решить проблему несоответствия CAN и UART фреймов программным способом мне не представлялось возможным и, окинув разочарованным взглядом промежуточные результаты исследований, было принято решение разработки собственного прототипа требуемого устройства.
В связи с тем, что теперь под контроль можно было взять более широкий спектр технических характеристик устройства, добавились следующие требования:
3. Возможность питания от 12-24 В в транспортных системах;
4. Наличие внешней памяти для хранения логов;
5. Размеры платы не более 86х80мм.
6. Рабочий диапазон температур -40..85 °С
В качестве мозга нового устройства была выбрана небезызвестная платформа STM32F407VET6 [2], обладающая аппаратной поддержкой всех необходимых интерфейсов и неплохим запасом RAM и FLASH памяти. Пошерстив интернет, в качестве PHY Ethernet был выбран трансивер DP83848IVV [3], имеющий хорошую, на мой взгляд, документацию и достаточно примеров схем с подключением и трассировкой. В качестве внешней энергонезависимой памяти для хранения логов я выбрал SPI FLASH 2 MB и SPI EEPROM для хранения разнообразных настроек. Кроме того была добавлена защита питания от перенапряжения, переполюсовки. Через N вечеров и M выходных были составлены принципиальная схема и трассировка печатной платы устройства первой версии. Т.к. места на плате было достаточно, а незадействованные ножки МК оставлять не хотелось, помимо основного функционала на плату были добавлены:
- средства для отладки SW, JTAG;
- переключатель 8-DIP Switch;
- micro-USB (USB Serial);
- RS-232;
- UART;
- I2C;
- GPIO
Идея была в том, чтобы при необходимости плата была готова к расширению функционала за счет монтажа дополнительных компонентов. Тем более на стоимость производства запасные посадочные места не влияют. На одной стороне, к сожалению, из-за этого уместить все не удалось, так что плата получилась двусторонняя 86х80мм, мин. ширина дорожки 0.25мм, мин диаметр отверстия 0.6мм.

Первая версия PCB-дизайна
Позже были заказаны и собраны два тестовых образца с полным набором периферии для исследований. В целях экономии плата была изготовлена без маски поэтому имеет такой нехарактерный цвет.

При помощи STM32CubeMX я набросал тестовую прошивку с проверкой работоспособности основных периферийный модулей устройства и, в первом приближении, заработало все, кроме запуска МК от внешнего кварца 8 МГц. Оказалось, из-за моей ошибки в составлении спецификации, были напаяны не те нагрузочные конденсаторы. Но это не помешало STM32F407 работать от внутреннего RC-генератора. Когда же я смог пропинговать свое устройство, радости было не сдержать т.к. с трассировкой PHY Ethernet я провозился, наверное, дольше всего. Затем в браузере я увидел свою тестовую http страницу и с тестированием успокоился.
Производство первых образцов плат заказывали в Зеленограде. И, несмотря на то, что стоимость «с» маской и «без» отличалась почти в два раза, не рекомендую так делать даже на стадии прототипа, потому что, как правило, как раз на этом этапе всплывают ошибки трассировки и приходится что-нибудь перепаивать. А паяться на «голых» дорожках крайне неприятно, денег сэкономите, а вот нервов – вряд ли. Да и гадать потом коротнулось ли где-то или трассировка неверная – такое себе удовольствие. Я, в силу неопытности, перепаивая кварцевый резонатор и нагрузочные конденсаторы, один образец таки убил.
К тому времени, на работе, в закромах нашлась железка способная решить поставленную задачу конвертации в текущем проекте, но, помимо крупных габаритов и стоимости, сев писать для нее прошивку, я столкнулся с проблемами связанными с объемом RAM и урезанным функционалом TCP\IP стека МК LPC2368. Так что желание сделать свое устройство только усиливалось.
Внимательно изучив недостатки первой версии, я, долго не думая, приступил ко второй. И снова захотелось добавить «задел на будущее», вместив в прежний форм-фактор следующие компоненты:
- поддержка RTC с батарейкой;
- RS-485;
- micro-SD;
- пищалка buzzer;
- возможность питания от USB;
- SPI на внешний разъем;
- питание 5V и 3.3V на внешний разъем.
Кроме прочего была добавлена защита питания по току и TVS диоды на пользовательские разъемы.
В итоге получился этакий dev-board с возможностью подключения внешних модулей. На этот раз плату заказал в Китае. Сборка производилась у нас.


Вторая версия платы
Ко второй версии я разобрался с 3D моделированием в Altium Designer, что очень помогло в избежании ошибок взаимного расположения компонентов по двум сторонам (оказалось, в интернете уже полно готовых моделек SMD компонентов [4]). Тем самым, все ошибки первой версии были исправлены, нововведения показали свою работоспособность, что очень меня порадовало.
Firmware
Описание кода выходит за рамки данной части, однако пару слов о программной составляющей сказать хочется. В своем устройстве я решил использовать связку FreeRTOS + LwIP стек. Статей про них в достаточном количестве, например, [5] и [6], поэтому прикрутить их к своему проекту не должно составить трудностей. Вкратце, LwIP – TCP\IP стек для встраиваемых систем, характеризующийся малым потреблением RAM и удобным API (есть даже BCD socket оболочка). Я использовал netconn API. Средствами FreeRTOS, вся работа TCP\IP стека помещается в поток отдельный от приложения. Помимо основной работы (соединение внешнего TCP-сервера с CAN шиной) в самостоятельном потоке крутится отдельный веб-сервер для доступа к настройкам устройства. Такой веб-интерфейс предназначен для мониторинга и конфигурации настроек устройства – установки разных режимов работы, скоростей передачи, адресов и т.д. Пока не знаю получится ли сделать и обновление прошивки через него.
Заключение
Это был мой первый (и надеюсь, что не последний) хардверный проект такой сложности и, несмотря на допущенные ошибки, вторую версию платы, думаю, можно считать успешной. На каждой итерации было множество сомнений, но, тем не менее, лишний раз убеждаюсь, что если не пробовать — получаться ничего точно не будет.
Используемые источники
1. Wikipedia/Controller_Area_Network
2. STM32F407VET6 datasheet
3. DP83848 datasheet
4. 3D Models
5. Введение в FreeRTOS
6. Введение в LwIP





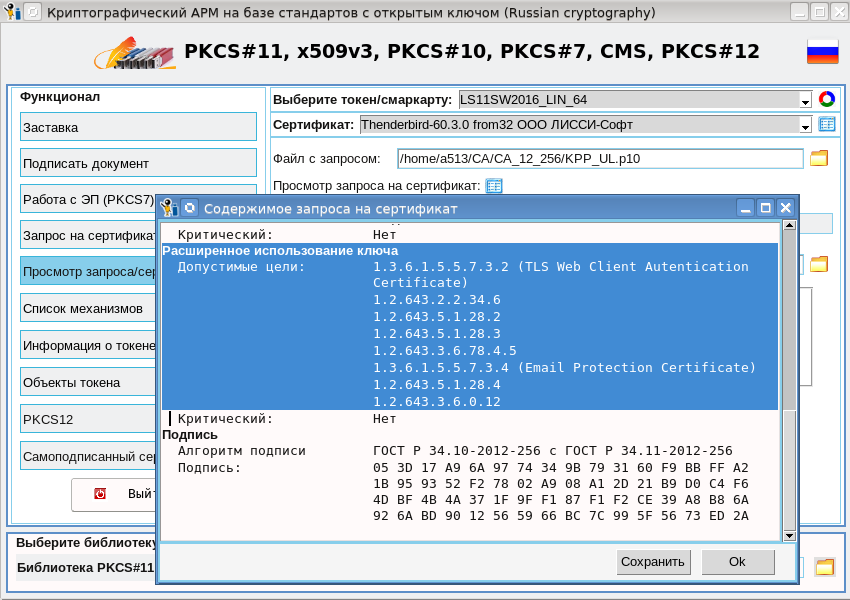
 И вот, когда я уже практически добавил в криптографический АРМ на базе токенов PKCS#11 cryptoarmpkcs генерацию
И вот, когда я уже практически добавил в криптографический АРМ на базе токенов PKCS#11 cryptoarmpkcs генерацию 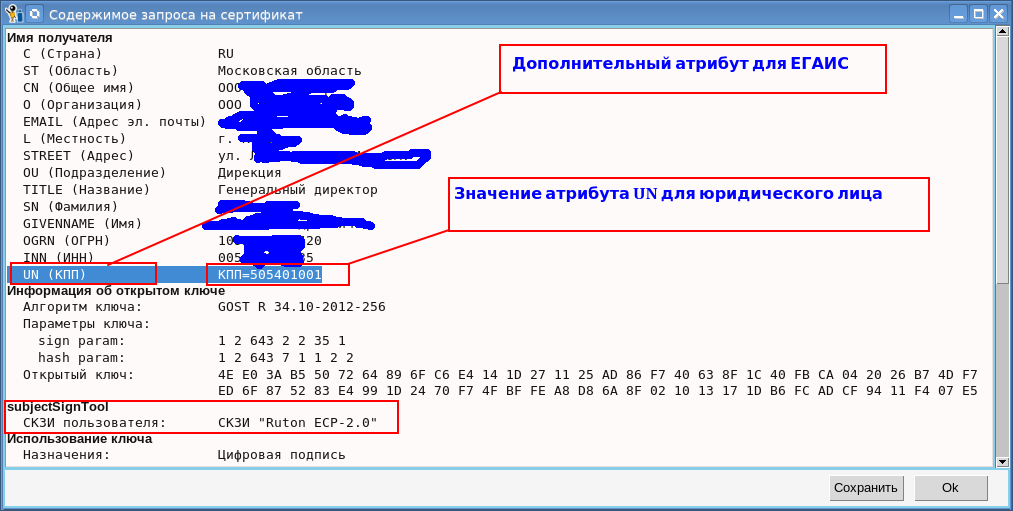
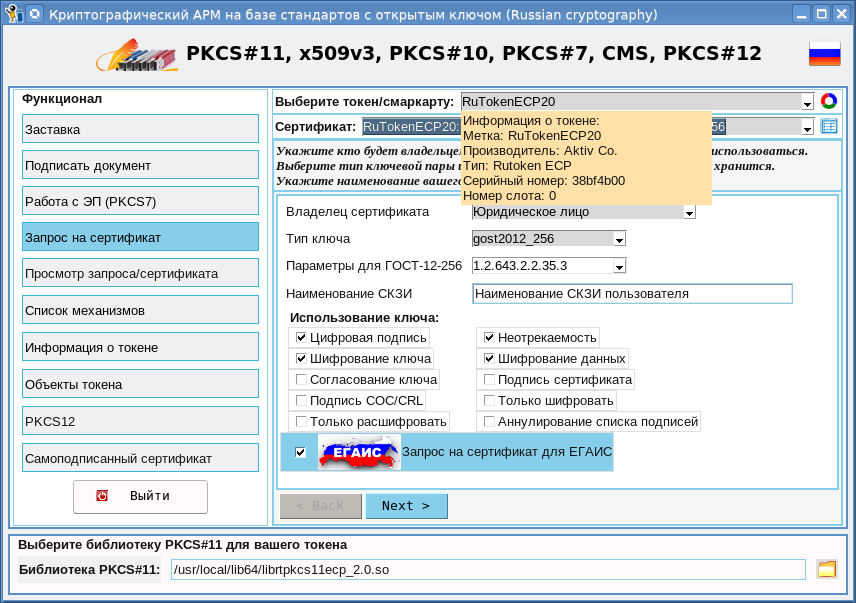
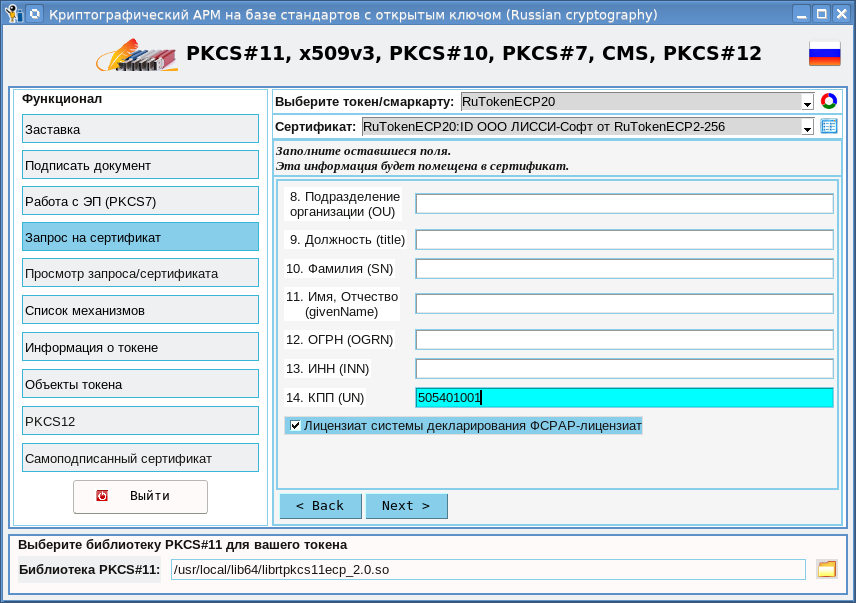
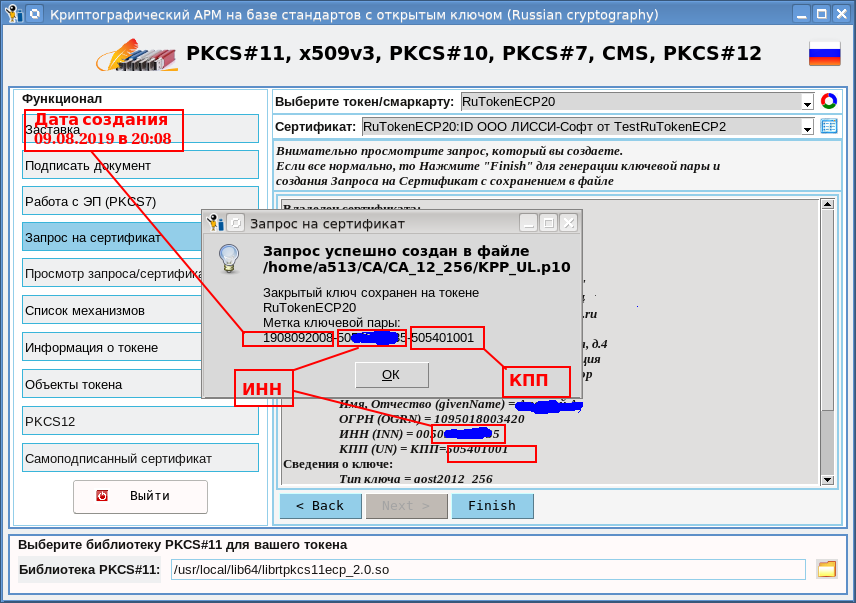

















 Мы в 1cloud.ru предлагаем услугу «
Мы в 1cloud.ru предлагаем услугу «