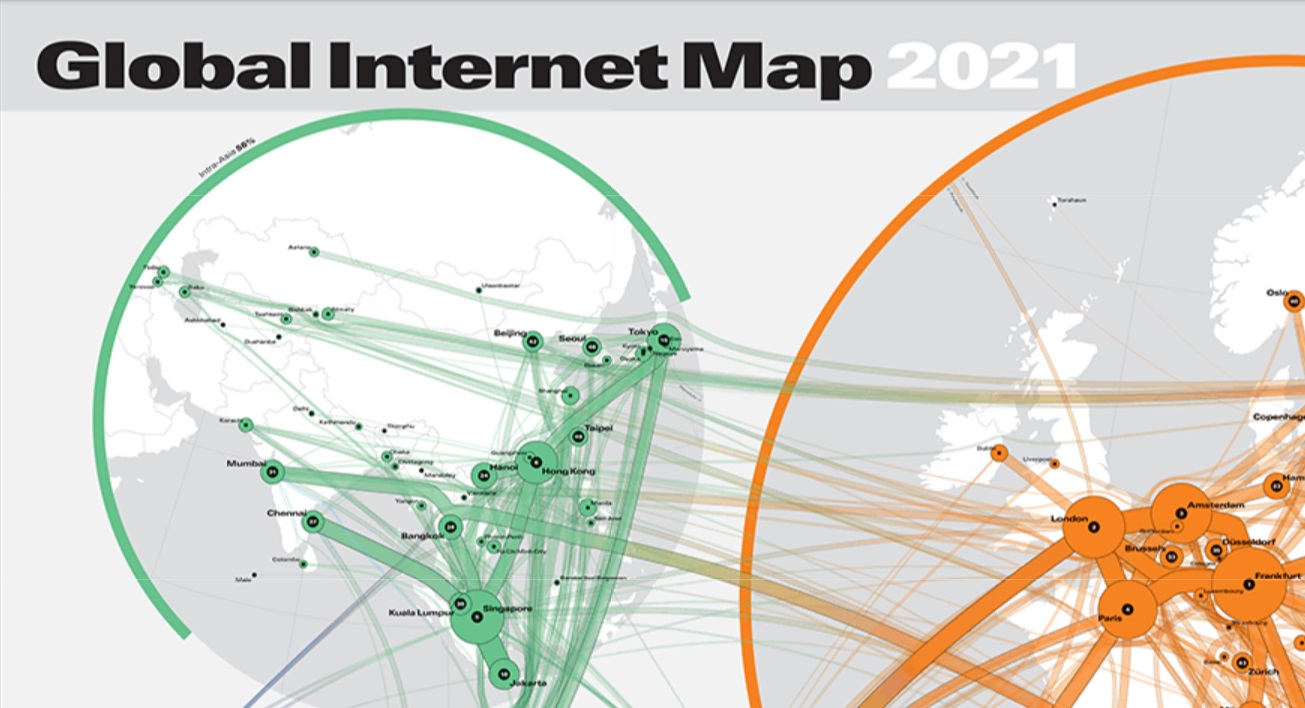
Компания TeleGeography проанализировала показатели глобального обмена интернет-трафиком. Результаты исследования представлены в виде интерактивной Глобальной карты интернета 2021 (Global Internet Map). По данным исследования, в 2020 году мы стали потреблять больше интернет-трафика. Средний показатель по миру увеличился с примерно 120 до 170 Тбит/с, в пике — 300 Тбит/с.
В целом, трафик рос на протяжении последних нескольких лет, причем не на малую цифру — 30% ежегодно. Но в 2020 году он побил все рекорды и составил 47%. Рост вполне объясним: из-за глобальной пандемии люди месяцами были заперты дома. В ход пошли стриминговые платформы, платформы для облачного гейминга, сайты доставки и YouTube-каналы с видео котиков. Так что, пожалуй, в этих процентах есть доля каждого из нас.
Выросла и общая емкость глобальной сети в период с 2019 по 2020 гг. — с 450 до более 600 Тбит/c (на 35%). Больше всего обменивалась интернет-трафиком Европа. Больше всего нагрузки досталось точкам обмена трафиком (IX) в Германии, Франкфурт, (DE-CIX FRA) и в Нидерландах, Амстердами (AMS-IX). Пиковый трафик у них составил около 7 Тбит/с. Существующим IX было непросто, ведь в 2019 году появилось меньше всего новых точек обмена трафиком.
Как подтвердили аналитики TeleGeography, глобальная пропускная способность и интернет-трафик выросли в 2020 году в основном за счет повсеместного распространения удаленной работы и обучения. «Больше людей, чем когда-либо прежде, стало полагаться на интернет», — отметили в компании.
TeleGeography также проанализировала деятельность шести мировых провайдеров облачных услуг, включая AWS, Google Cloud Platform, Microsoft Azure и т.д., и составила карту стоимости телекоммуникационных услуг в разных странах. Если верить отчету, в России цены на интернет выше, чем в Европе, но намного ниже, чем в Южной Америке. Цена $0,32 за Мбит/c примерно сравнима с ценами США: $0,35 — в Лос-Анджелесе, $0,34 — в Нью-Йорке.
К слову, в декабре прошлого года на сетях MKS-IX — крупнейшей российской точки обмена интернет-трафиком — зафиксирован новый пиковый рекорд в 4,6 Тбит/с. Предыдущее пиковое значение (3,7 Тбит/с) было отмечено 17 марта прошлого года. Впрочем, пока сети справляются с этими нагрузками.
Поводить мышкой по интерактивной карте можно по ссылке. А если вы любитель эффектных постеров (и у вас есть лишние $250), можно еще и заказать печатную версию Global Internet Map.
Примерно год назад я начал готовиться к переезду и собирать прототип умного дома. В качестве системы управления я выбрал наиболее популярное на текущий момент и активно развивающееся решение - Home Assistant. По мере обрастания умного дома датчиками встал вопрос об охранной системе, которая в случае чего поднимет тревогу и сообщит мне (соседям) о незваных гостях. В системе от частных охранных предприятий пока не вижу необходимости, поэтому решил сделать всё сам.
Как это работает: на входной двери размещён датчик открытия, который по протоколу Zigbee сообщает серверу умного дома, что кто-то зашёл в квартиру. Срабатывает сигнализация в "тихом режиме" (событие "triggered" во встроенной интеграции; это никак не проявляется, но идёт обратный отсчёт до запуска сирены). Если за указанное в настройках время не снять блокировку (через ввод кода или NFC-меткой), запустится сирена и световая индикация.
Из чего собрано:
ESP32 WROOM DevKit v1 (в теории можно заменить любой ESP, изменив конфиг под неё)
RFID/NFC модуль PN532
Соединительные провода (6 штук)
Напечатанный на 3D-принтере корпус
Xiaomi Gateway 2 (который с локальным управлением) я планирую использовать как динамик и световую индикацию
Датчик открытия двери от Aqara
Опционально можно добавить люстру, LED-ленты, умные колонки и любые другие устройства на ваш вкус, цвет и возможности автоматизаций Home Assistant.
ESP32 WROOM DevKit v1 (30 контактов)RFID/NFC модуль PN532. Китайцы скопировали версию от Elechouse.
Корпус мне намечал друг, у которого есть 3D-принтер. Хаб и датчики от Xiaomi вынесем за скобки. Остальные элементы покупались на Aliexpress и суммарно обошлись мне в 600 рублей.
Подключение и настройка ESP
Для начала переключим NFC-модуль в режим работы через интерфейс SPI. Ставим первый переключатель в нижнее положение (ближе к цифре 1), а второй - в верхнее (ближе к буквам). Припаиваем гребёнку на 8 контактов и готовим соединительные провода.
Включенный режим I2C и подключенные соединительные провода
Насколько я понял из распиновки, возможно несколько вариантов подключения NFC-модуля к ESP-32: мне было удобнее подключить всё на одну сторону. Если будете использовать другие контакты, внимательно проверяйте конфиг - возможно, он немного изменится.
Распиновка для 30-контактной ESP-32
Подключаем модуль следующим образом (слева ESP, справа PN532):
GPIO18 - SKC
GPIO19 - MSO
GPIO23 - MOSI
GPIO5 - SS
3V3 - VCC
GND - GND
PN532 подключенная к ESP-32
На следующем этапе нам нужно установить аддон ESPHome и настроить нашу ESP-32. Подробно расписывать базовые моменты не буду, рекомендую следовать данному видео:
Обратите внимание на блоки spi и pn532_spi, где мы указывает контакты подключения. В блоке switch я задействовал светодиод на плате (им можно мигать, например, при поднесении валидной метки), а в блоке binary_sensor создал сущность для Home Assistant (при поднесении карты с указанным uid сенсор переходит в статус true; uid карты можно найти в логах вашей ESP в аддоне ESPHome). Как показали опыты, можно читать RFID-метки, банковские карты и тройку. NFC в моём телефоне нет, но скорее всего и он будет работать.
Компилируем прошивку и выгружаем её на ESP. Проверяем, что всё работает, открыв логи и поднеся к считывателю RFID-метку. Её uid должен отобразиться в логе:
[17:42:35][D][pn532:149]: Found new tag '79-EB-08-B4'
Со стороны ESP всё готово, теперь нужно настроить автоматизации в Home Assistan
Подключение сигнализации в Home Assistant
Для работы в сигнализацией в Home Assistant есть встроенная интеграция и карточка Lovelace. Начнём с интеграции - чтобы её включить, нужно добавить в configuration.yaml следующий блок:
alarm_control_panel:
- platform: manual
code: !secret alarm_pin
code_arm_required: false
# Задержка перед постановкой на охрану
arming_time: 5
# Задержка перед запуском сигнализации
delay_time: 10
# Время сигнализации
trigger_time: 600
Код для разблокировки я вынес в отдельный файл secrets.yaml. Почитать, как он устроен, можно тут.
Поскольку мы тестируем нашу СКУД, arming_time (время до включения режима охраны, за которое вы успеете выйти из квартиры и закрыть дверь) и delay_time (время после срабатывания датчика двери, через которое запустится сирена) зададим как 5 и 10 секунд соответственно. Сохраняем, перезагружаем Home Assistant.
Далее создаём карточку сигнализации в Lovelace, добавив код в нужное вам место ui-lovelace.yaml
В entity указываем название объекта, который создался после подключения alarm_control_panel. В states можно указать, какие кнопки будут в карточке: я оставил только "Охрана (не дома)".
Автоматизация
Чтобы связать NFC-метки с нашим умным домом, потребуется создать 5 автоматизаций:
Срабатывание сигнализации (запускается, когда мы заходим в квартиру)
Включение режима охраны (прикладываем метку и уходим из дома)
Отключение режима охраны (прикладываем метку, когда пришли домой)
Включение сирены
Отключение сирены
Срабатывание сигнализации
В качестве триггера используется датчик открытия двери. Когда дверь открывается при условии, что включен режим охраны, запускается наша автоматизация. В блоке с действиями я задал мигание шлюзом Xiaomi и диодом на ESP-32. Вы можете использовать любые другие действия.
Триггер - чтение метки с заданным на этапе настройки ESP uid. Пока мы выходим из квартиры, шлюз мигает оранжевым светом. После того, как включился режим охраны, загорается диод на ESP, а шлюз включает статичный красный свет на 3 секунды и гаснет.
В этой автоматизации в качестве триггера снова используется RFID-метка. Условием является включенный или включающийся режим охраны. Последний предусмотрен на случай, если собрались уходить из дома, приложили карточку и вспомнили про включенный утюг. При валидной метке коротко включается диод на ESP и зелёная подсветка на шлюзе.
- id: '3-0003'
alias: 'Отключение режима охраны'
trigger:
platform: state
entity_id: binary_sensor.nfc_card
to: 'on'
condition:
condition: or
conditions:
- condition: state
entity_id: alarm_control_panel.ha_alarm
state: armed_away
- condition: state
entity_id: alarm_control_panel.ha_alarm
state: pending
action:
- service: alarm_control_panel.alarm_disarm
data:
entity_id: alarm_control_panel.ha_alarm
code: !secret alarm_pin
- delay:
milliseconds: 100
- service: switch.turn_off
entity_id: switch.esp_led
- service: light.turn_on
data:
entity_id: light.gateway_light_44237c82f751
color_name: green
brightness: 255
- delay:
seconds: 3
- service: light.turn_off
entity_id: light.gateway_light_44237c82f751
Включение сирены
Пока что я не особо заморачивался с индикацией, поэтому в автоматизации только сирена из встроенных звуков шлюза. В будущем планирую дополнительно выводить звук на умную колонку и мигать люстрой.
От "отключения режима охраны" отличается лишь условием по статусу alarm_control_panel.ha_alarm (здесь triggered) и отключением сирены или другой индикации.
Наверное, очевидно, что две платы без какого-либо корпуса выглядят не очень красиво и безопасно. Я попросил другая спроектировать и напечатать под них корпус. Цвет выбрали белый, чтобы подходил под будущий интерьер. Уже после печати я понял, что белый корпус не гасит свет диодов на ESP, поэтому их можно использовать в автоматизациях. Даже синий диод в условиях коридора должен быть виден.
Основа, на которую ложатся платы, и прищепка (слева) для того, чтобы закрепить PN532К ESP подключается кабель питания, поэтому она не должна болтаться внутри корпуса.
Ух, наконец-то закончил. Спасибо, что дочитали до конца. Надеюсь, что этот гайд помог вам!
Если возникнут какие-то вопросы, задавайте в комментариях. Постараюсь ответить.
Huawei объявила о запуске проекта по разработке и внедрению технологий искусственного интеллекта для обслуживания свиноводческих ферм. Эту информацию подтвердил президент подразделения Huawei по компьютерному зрению Дуан Айгуо.
Технологии Huawei будут включать адаптированную для отрасли систему распознавания лиц, которая позволит наблюдать за состоянием животных и отслеживать их перемещение. ИИ будет анализировать рыло, уши и глаза свиньи. Технология также позволит поддерживать необходимый вес, соблюдать диету и режим физической активности животных.
«Свиноводство – еще один пример наших попыток оживить некоторые традиционные отрасли с помощью информационных технологий», – объяснил Айгуо такое решение компании.
Другой причиной стало то, что Huawei пытается адаптироваться к американским санкциям, которые запрещают компании доступ к жизненно важным компонентам и системам.
Китай в настоящее время имеет самую крупную в мире свиноводческую отрасль. В стране выращивается половина всех животных в мире. Другие китайские технологические гиганты, включая JD.com и Alibaba, уже работают со свиноводческими фермами в Китае.
Одновременно Huawei начала сотрудничать с угледобывающей промышленностью. Основатель компании и исполнительный директор Жэнь Чжэнфэй объявил о создании лаборатории инноваций в горнодобывающей промышленности в провинции Шаньси на севере Китая. Ее целью станет разработка технологии для угольных шахт, которая позволит сократить число рабочих, а также повысить безопасность и эффективность выработки. Huawei обещает, что эти технологии позволят шахтерам «носить костюмы и галстуки» на работе.
Наконец, компания расширяется в области производства потребительских товаров, таких как телевизоры, компьютеры и планшеты. На российский рынок Huawei в этом году собирается выпустить свои новые продукты, включая настольные компьютеры, мониторы и умные очки.
Кроме того, компания ведет переговоры о продаже своих премиальных линеек смартфонов P и Mate. По данным Reuters, шанхайские инвестиционные компании могут сформировать консорциум с дилерами Huawei для поглощения брендов, аналогично тому, как это происходило при продаже Honor.
Параллельно компания пытается отстоять позиции в США. Huawei подала иск в американский суд, оспаривая ее признание угрозой национальной безопасности. Правда, шансов на отмену этого решения немного. Администрация президента США Джо Байдена уже объявила, что не видит причин снимать действующие ограничения с Huawei.
По информации CNEWS и портала Роскомсвобода, 19 февраля 2021 года на портал правовой информации был опубликован приказ Министерства просвещения Российской Федерации от 18.11.2020 № 649 «Об утверждении Порядка формирования и ведения государственного информационного ресурса о лицах, проявивших выдающиеся способности».
Согласно этому документу, ранее созданный реестр всех одаренных российских детей будет значительно переработан и расширен. Теперь туда будут обязательно вноситься все контактные данные несовершеннолетних гражан РФ и их представителей, включая ФИО, даты рождения, адреса проживания, номера телефонов, адреса электронной почты и СНИЛС.
Доступ к реестру будет контролировать образовательный фонд «Талант и успех». Эта организация будет полноправным оператором информационного ресурса об одаренных российских детях, а также отвечать за сохранность их персональных данных.
Полный перечень данных, которые будут вноситься в реестр одаренных детей.
ФИО, дата рождения, место обучения;
результат участия в различных мероприятиях;
информация об имеющихся у лиц до 18 лет результатах интеллектуальной деятельности, подтверждённых патентами или свидетельствами, и (или) публикациях в научном международном и (или) всероссийском издании;
информация об имеющихся у лиц достижениях в педагогической, научной (научно-исследовательской), научно-просветительской, инженерно-технической, изобретательской, творческой и (или) физкультурно-спортивной деятельности, проводимой образовательной, научной или иной организацией, либо о научном (научно-методическом, научно-техническом, научно-творческом) результате интеллектуальной деятельности, подтвержденном патентом, свидетельством, либо о публикации в научном (учебно-научном, учебно-методическом) международном, всероссийском, ведомственном, региональном издании, в издании образовательной, научной или иной организации (при наличии);
страховой номер индивидуального лицевого счета в системе индивидуального (персонифицированного) учета;
контактные данные лица и его законного представителя (номер телефона, почтовый адрес, адрес электронной почты);
данные о наставниках (личных тренерах), осуществлявших их подготовку: фамилия, имя, отчество (при наличии), место работы, должность и реквизиты документа, удостоверяющего личность, – для победителей международных олимпиад по общеобразовательным предметам – членов сборных команд РФ.
Ранее Минобрнауки поясняло, что этот реестр должен содействовать выявлению, развитию, поддержке и сопровождению одаренных детей.
Эксперт Роскомсвободы пояснил, что доступ к этим данным несовершеннолетних детей будет иметь множество федеральных органов и различных организаций, включая образовательные и псевдообразовательные, которые ранее получали эту информацию путем личного посещения школ и изучения успехов школьников на различных соревнованиях и олимпиадах.
Кадр из х/ф «Гостья из будущего», эпизод на стадионе.
Для всех, кто хочет пообщаться на митапах о разработке или пройти наши практикумы, мы подготовили короткий дайджест всех ближайших событий. В феврале и марте приглашаем – онлайн и офлайн – на митапы и практикумы по Web-, Frontend-, Backend-разработке и тестированию, а также на онлайн-конференцию по управлению проектами. За самые интересные вопросы к спикерам митапов мы подарим полезные призы.
Всем привет! Наша команда продолжает регулярные митапы для опытных разработчиков, а также интенсивы и практикумы для тех, кто начинает изучение новых областей и стремится получить поддержку ментора или опыт командной работы. Ранее мы рассказывали о наших интенсивах, а теперь представляем новые мероприятия – подключайтесь!
Митап для тех, кто начинает свой путь в разработке, интересуется новостями Frontend и хочет пообщаться с экспертами в этой области напрямую. Наши спикеры поделятся личным опытом работы с MobX и лайфхаками, с помощью которых можно успешно пройти собеседование на роль frontend-разработчика, а еще расскажут, как создавать динамические диаграммы для Vue на основе SVG.
2)Web
27 февраля в 11:00 МСК офлайн-митапHot Webспециально для Краснодара
Эксперты поделятся опытом интеграции платежных систем, расскажут об особенностях разработки графических приложений на Python с использованием фреймворка Kivy и нюансах интеграции ML на проде с Django.
Эксперты SimbirSoft расскажут о специфике работы в области QA, о том, как на проекте использовать и правильно читать метрики, а также рассмотрят вопросы ручного и автоматизированного тестирования.
Участников ждут 19 онлайн-консультаций от ведущих QA-специалистов, 17 часов полезного контента, около 100 часов самостоятельной работы для выполнения практических заданий с поддержкой ментора и проектная работа в команде.
Эксперты расскажут о возможностях роста в профессии, поделятся своими историями и ответят на вопросы.
5) Управление проектами
20 марта специально для владельцев IT-продуктов мы проведем онлайн-конференцию «Технореволюция 2.0». В программе три потока: разработка, онбординг, управление. Эксперты SimbirSoft, ABBYY, Skillbox, «Спортмастер», «ВкусВилл», «Магнит» и многих других компаний поделятся своими кейсами из практики и опытом управления разработкой.
Спасибо за внимание! Надеемся, что этот дайджест был вам полезен.
Наша команда постоянно делится опытом, и мы уже выбираем темы для новых митапов и практикумов, которые состоятся весной. Если вы хотите быть в курсе, приглашаем подписаться на нас ВКонтакте или в Telegram.
В International Data Corporation (IDC) сообщили, что в прошедшем году иностранные компании из финансовой и розничной сферы начали активнее закупать облачные мощности у российских поставщиков. Аналитики объясняют это тем, что российская облачная инфраструктура стала более конкурентоспособной как по цене, так и по функционалу.
Кроме того, многим компаниям теперь необходимо хранить персональные данные российских клиентов на территории страны.
IDC предварительно оценивает рынок публичных облачных услуг России по итогам 2020 года в $1,2 млрд. По оценкам iKS-Consulting, его размер составляет $1,4 млрд.
Крупнейшими облачными провайдерами стали «Ростелеком» (20,8% выручки рынка), МТС (11,2%), «Крок» (8,3%), Selectel (8,2%) и SberCloud (6,2%).
В IT-провайдере Selectel отмечают, что рост интереса наблюдается со стороны крупного и среднего бизнеса, международных брендов одежды, автопроизводителей и производителей потребительской электроники.
«Яндекс.Облако» заработало на иностранных компаниях 80 млн рублей или 8% от общей выручки.
Как отметил руководитель платформы Mail.ru Cloud Solutions Илья Летунов, зарубежные компании ищут те платформы, которые помогают ускорить запуск цифровых сервисов и новых каналов продаж.
В IT-компании «Крок» говорят, что за 2020 года число ее зарубежных клиентов увеличилось примерно в 1,5 раза, преимущественно за счет IT-компаний из Европы и Малой Азии. Чаще всего это были компании из сфер программной разработки, гейминга, логистики, а также крупные предприятия, которые открывают в России региональные офисы.
Представители рынка считают, что интерес зарубежных компаний продолжит расти и в 2021 году.
Между тем доходы крупнейших мировых облачных провайдеров в период пандемии выросли на 33% и составили $33 млрд. Amazon заработал $11,6 млрд. В тройке лидеров также оказались Microsoft Azure и Google.
20 февраля 2021 года российский разработчик Григорий Клюшников (бывший программист VK и Telegram) опубликовал в открытом доступе клиент Clubhouse для Android. Он сделал приложение менее чем за два дня.
Проект доступен GitHub по названием Houseclub. В настоящее время программист оперативно дорабатывает приложение по отзывам пользователей. Через несколько часов после релиза он выпустил исправленную версию 1.0.1, которая работает на Android 11 и 1.0.2, где исправлены были проблемы с PubNub.
Приложение Clubhouse для Android поддерживает дизайн и основные функции оригинального клиента под iOS. В нем можно авторизироваться, присоединяться к комнатам, общаться с другими пользователями, «поднимать руку», просматривать профили пользователей и подписываться на них. Пока что не работают уведомления и недоступна модерация комнат.
Разработчик (на Хабре grishkaa) советует зарегистрироваться в соцсети через iOS-приложение, так как в его клиенте регистрация работает не очень стабильно.
Программист пояснил, что он создал этот проект фактически за полтора дня. Он уточнил, что в техническом плане инфраструктура Clubhouse — это 3 SaaS-сервиса, «смотанные по-быстрому синей изолентой», а именно:
для хранения статики (аватарок) задействована AWS.
В проекте Houseclub используется API Clubhouse, реверс-инжиниринг которого был сделан в рамках проекта clubhouse-py.
Сервис аудиоконференций Clubhouse появился в марте 2020 года. Он приобрел особую популярность в январе-феврале 2021 года. В частности, благодаря тому, что к нему подключились Марк Цукерберг и Илон Маск. Приложение сервиса ранее было доступно только в App Store, для окончательной регистрации в Clubhouse нужно получить инвайт от полноправного пользователя сервиса.
26 февраля в 19ч00 в БЦ «Лефорт» в Москве стартует первый офлайновый митап Делимобиля, посвящённый технологической реализации внутренностей.
Для кого
Для backend и разработчиков мобильных приложений. Если вам знакомы эти слова и буквосочетания, то эта встреча точно для вас: HighLoad, IoT, UX/UI, Figma, Kotlin, API, SWIFT, RnD.
Для чего
Обсудим, как делать приложение для людей и машин. Поделимся инсайтами, поговорим про челленджи и, может, даже расскажем, как заработать много денег.
Формат
Встреча пройдет в неформальной обстановке.
О трендах и будущем в сфере расскажут
Дмитрий Рязанов - директор по продукту; Дмитрий Андриянов и Артем Никифоров - ведущие бэкендеры; Алена Матросова - менеджер продукта; Андрей Урпин - главный по Linux; Паньшин Павел, Антон Лосев – главные по базам.
О чем будем говорить
О продуктах Делимобиля
Об экспансии: как Делимобиль запускался в Беларуси
Об организации взаимодействия с IoT
О практическом применении стримов
Об эволюции инфраструктуры: от одного сервера до high load
О DWH, анализ данных
Нетворкинг
Участие в мероприятии бесплатное, регистрация и получение инвайта обязательны - https://t.me/delimeetup_IT
В дальнейшем компания планирует проводить такие встречи с IT-специалистами на постоянной основе.
Разработчик Григорий Клюшников (@grishkaa) выложил на GitHub свой проект Houseclub — неофициальное Android-приложение для Clubhouse. Сейчас Clubhouse официально доступен только на iOS, в будущем ожидается и официальное приложение для Android, но, как пояснил Григорий, он «устал ждать».
Пока что в Houseclub есть лишь базовая функциональность (вроде участия в голосовых комнатах), но позже может появиться и остальная (например, создание новой комнаты). Григорий подчёркивает, что сейчас это скорее прототип, чем полноценный продукт.
Юридический статус проекта и возможная реакция Clubhouse пока что непонятны: одобрят в компании начинание или, наоборот, примутся блокировать пользователей стороннего приложения, покажет только время.
Поэтому размещать проект в Google Play его создатель не намерен. Установить приложение можно, скачав на GitHub из раздела Releases готовый APK-файл (ну или самостоятельно собрав исходники в Android Studio).
По словам Григория, Clubhouse устроен довольно просто («склеивает скотчем» три сторонних сервиса), поэтому и стороннюю реализацию создать оказалось несложно. Также ему помогли уже существовавшие чужие наработки реверс-инжиниринга Clubhouse.
С 2011-го по 2016-й Клюшников был разработчиком Android-приложения ВКонтакте. С этим проектом изначально произошла похожая история: официального приложения не было, и Григорий (на тот момент — студент) сделал собственное. Тогда закончилось тем, что Павел Дуров нанял его, чтобы он продолжил работу уже в официальном статусе.
Разумеется, у нового проекта появилась своя комната в Clubhouse, на момент публикации задать вопрос Грише можно там. Но он активен на Хабре, так что, вероятно, и здесь в комментариях ответит.
Ядерная энергия, безусловно, совершила технологическую революцию. Но почему мирный атом не используют повсеместно? Я расскажу вам, по какой причине свернули проект ядерного самолёта и атомобиля, и чем закончилась попытка добывать нефть с помощью ядерных взрывов.
Ледоколы
В 1959 году суперзвездой мировых новостей стал Ленин — первый в мире атомный ледокол вышел на испытания в море. Судно с ядерной силовой установкой на борту и сейчас выглядит впечатляюще, а в 1959 люди были потрясены: вертолётная площадка, кинозал, музыкальный салон, — настоящий плавучий город. Атомный ледокол сконструировали для обслуживания Северного морского пути и экспедиционного плавания в Арктике. В сутки он расходовал примерно сорок пять грамм радиоактивного топлива.
Советский атомный ледокол «Ленин»
Раньше ледоколы были дизель-электрические или даже паровые, например «Красин», стоящий на вечной стоянке в Санкт-Петербурге. Стране нужен был более мощный корабль. И не просто более мощный, но и способный ходить несколько месяцев без дозаправки топливом, поскольку заправляться на Северном морском пути, по сути, было негде.
Военные эксперты опасались, что в открытом море на ядерном реакторе произойдет авария. Но за тридцать лет службы никаких форс-мажорных ситуаций не случилось. Самый сложный ремонт ледокол «Ленин» перенес в 1967 году. Это была целая операция по замене атомной установки, для проведения которой пришлось взрывать днище. Саму же идею — строить суда на ядерном топливе — признали крайне удачной. Так в СССР появился единственный в мире атомный ледокольный флот.
Затем в советское время стали интенсивно строиться серии ледоколов. И эта флотилия ледоколов работала до Карских ворот и дальше. Последний атомный ледокол «50 лет Победы» был уже построен при Новейшей России. Сейчас он единственный, который находится в строю.
«50 лет Победы» — не просто самый большой ледокол в мире, он ещё и круизный лайнер. Коммерческие туры помогли уцелеть атомному флоту в 90-е годы прошлого века. Сейчас этот ледокол прокладывает путь для других судов и катает туристов. Стоимость билета на Северный полюс начинается от двух миллионов рублей. Цена зависит от класса каюты.
Российский атомный ледокол «50 лет Победы»
Атомные автомобили
В середине прошлого века мир охватила ядерная эйфория. Казалось, человечество нашло неограниченный источник энергии. Пытались создать даже автомобили на атомной тяге. Nucleon — первый и самый известный проект такого типа.
По расчетам инженеров, машина с фантастическим дизайном могла проехать восемь тысяч километров. Конструкторы автоконцерна продумали всё — от бампера до последнего винтика. Но партнеры — компания по производству реакторов для подводных лодок — не смогли создать автомобильный вариант атомного двигателя. Амбициозный проект остался в виде макета.
Nucleon — первый проект атомобиля
Саму идею — поставить ядерный реактор на колеса — специалисты оценивают скептически. Они считают, что это крайне опасно, потому что в случае поломки реактора придется эвакуировать всё население в радиусе тридцати-сорока километров.
«Век без дозаправки!», — с таким громким лозунгом несколько лет назад американская компания представила проект автомобиля на ториевом реакторе. Причём по конструкции он напоминает старый Nucleon: кабина тоже убрана подальше от атомного двигателя. Хотя торий не такой опасный и радиоактивный, как плутоний или уран (для создания ядерной бомбы он не годится), тем не менее без защиты для пассажиров и водителя в таком автомобиле не обойтись.
Проект Кадиллака на ториевом двигателе
Советский атомолёт
После Второй мировой войны супердержавы по разные стороны океана разрабатывали проект ядерного самолёта. Идея создать бомбардировщик с практически неограниченным радиусом полета была очень заманчивой. В СССР испытательную лабораторию сделали на базе ТУ-95.
Советский атомолет Ту-95 ЛАЛ
В США экспериментальный реактор установили на модифицированную версию стратегического бомбардировщика B-36. Атомная установка и система защиты экипажа составляли блок массой шестнадцать тонн, то есть полезной нагрузки было очень мало. Для какого-либо запаса бомб места практически не было.
Атомный стратегический бомбардировщик В-36
Испытания показали, что самолёт оставляет за собой радиоактивный след. Проект свернули, а опытный образец разобрали со всеми мерами предосторожности. В Советском Союзе от идеи создать атомолет тоже отказались. Сегодня военные самолеты могут пролететь больше десяти тысяч километров с помощью дозаправки в воздухе.
Бредовая идея канадских ученых
В Канаде в 50-х годах всерьёз обсуждали возможность добывать нефть с помощью ядерных взрывов. Запасы «черного золота» там огромные, но почти все они заключены в нефтеносных песках, поэтому традиционные способы добычи неэффективны. По расчетам специалистов, энергия ядерного взрыва должна была освободить нефть, после чего её легко можно было бы выкачивать.
В Канаде собирались добывать нефть с помощью ядерных взрывов
Для испытания подобрали место в провинции Альберта. Но такие новости вызвали панику среди местных жителей. Серия подземных ядерных взрывов в СССР и США показала, что подобные опыты опасны для окружающей среды. Так что одобренный правительством проект резко свернули.
Заключение
Давняя мечта фантастов и ученых — создать эффективный термоядерный реактор. Топливо для него (дейтерий или водород) можно добывать из морской воды. Ядра этих элементов при слиянии выделяют огромное количество тепла. Сама реакция абсолютно безопасна, но пока создать установку, которая производит больше энергии, чем потребляет, не удалось.
Экспериментальные реакторы строят в США, Великобритании, Китае и во Франции. Вполне возможно, что в XXI веке вместо ядерной гонки начнется термоядерная.
Профессиональную сферу DWH (Data Warehouse, или, по-нашему, хранилище данных) отличает высокая технологичность, а также огромное многообразие используемых решений. Крупные компании строят хранилища с самыми разными инструментами и технологиями, отличаются архитектуры, процессы. Но необходимость идти в ногу со временем постоянно вносит свои коррективы.
Tinkoff.ru не исключение. Мы постоянно совершенствуем свои процессы и стремимся развивать не только внешние, но и внутренние продукты. И на примере хранилища данных я хочу рассказать о том, как эволюционировали наши процессы по обеспечению качества. В этой статье я расскажу о том, как ранее был устроен наш рабочий процесс, с какими проблемами мы столкнулись и какие события стали переломными в эволюции нашего процесса QA.
Но сначала я дам некоторую вводную по основным определениям, которые используются в статье:
Хранилище данных (или Data Warehouse, DWH) — это предметно-ориентированная база данных, позволяющая хранить данные для построения бизнес-отчетности и принятия управленческих решений на основе анализа данных в хранилище.
Задача на доработку хранилища (или пакет) — отдельная директория в системе контроля версий (VCS), содержащая набор файлов, использующихся для изменения метаинформации и физических данных хранилища.
А вот теперь можно приступить к основной части рассказа. Итак, поехали.
Откуда выросли проблемы
Рисунок 1. Прошлое: ручной труд облагораживает
В самом начале было слово был поиск оптимальных инструментов для организации работы хранилища, отладка процессов внутри управления хранилища данных, а также поиск основных направлений развития.
В рамках flow выделялись три основные функциональные роли:
системный аналитик;
ETL-разработчик;
QA-инженер.
Что получается на выходе каждого этапа flow — показано на рисунке 2.
Давайте выделим перечень проблем, существовавших на тот момент в реализации процесса:
Ручной сбор пакета разработчиками.
Ручное ревью пакета.
Ручной перенос задач на тест.
Необходимость в синхронизации продуктового и тестового контуров.
Проверки данных без использования автоматизации.
Рисунок 2. Функциональные роли в DWH (SyA — системный аналитик, DEV — разработчик, QA — инженер по тестированию)
Детальнее остановимся на каждой из проблем.
Ручной сбор пакета
ETL-процесс — это процесс извлечения данных из различных источников (БД, файлы), их дальнейшей очистки и преобразования (фильтрация, агрегация, дедупликация, вычисление дополнительных атрибутов и т. д.) с дальнейшей загрузкой полученного результата в хранилище.
Две основные составляющие, с которыми мы работаем (рисунок 3):
метаинформация;
физические данные.
Рисунок 3. Составляющие ETL-процесса
Разработчик при получении задачи на доработку хранилища:
С помощью конструктора SAS DIS изменяет логику ETL-процесса.
При необходимости пишет SQL (а иногда и python) скрипты для изменения физических данных.
Пишет инструкцию для переноса задачи на тестовый и продуктовый контуры. Кроме того, если сценарий наката задачи специфический и отличается от типовых задач, то он пишет еще и кастомизированный сценарий наката.
Собирает все доработки в отдельную директорию (рисунок 4) для дальнейшей передачи задачи QA-инженеру.
Вот именно эта директория в VCS и является объектом дальнейшего изучения со стороны QA.
Рисунок 4. Пример содержимого пакета
Недостатки. Сбор руками неудобен, появляется человеческий фактор: можно что-то упустить при формировании пакета, больше времени разработчика тратится на задачи, не связанные с самой разработкой.
Ручное ревью пакета
Итак, пакет готов: разработчик выполнил все требуемые по ТЗ доработки, сформировал пакет с нужными файлами и готов передать задачу в тестирование. Но стоит ли делать это сразу после завершения работ?
Нет, поскольку выявление проблем на более поздних этапах в разы увеличивает стоимость исправления этих самых проблем. Поэтому как можно больше проверок нужно выполнить на ранних этапах процесса.
И тут помогает ревью. Опытный коллега-разработчик отсматривает пакет на предмет корректности содержимого, структуры и соблюдения общих подходов к разработке, руководствуясь стандартом проектирования — документом, отражающим множество самых разных аспектов разработки и проектирования ETL-процессов.
И вроде все прекрасно, но есть нюансы:
Ревью занимает много времени, поскольку выполняется вручную.
Невозможно отследить глазами выполнение абсолютно всех требований.
Ручной перенос задач на тест
На рисунке 5 показано, как выполнялся перенос пакетов на тестовый контур. QA запасался терпением, изучал инструкцию, написанную разработчиком, и руками переносил всю необходимую информацию на тестовый контур. Далее он запускал нужные скрипты из пакета, выполнял прочие действия и, наконец, запускал ETL-процессы.
Рисунок 5. Перенос задачи на тестовый контур
Очевидно, что некоторые недостатки в текущем подходе присутствуют:
Длительность подготовки тестового окружения.
Человеческий фактор и, как следствие, ошибки.
Высокий порог вхождения — нужны глубокие знания, чтобы понимать процесс релиза.
Рутинность и однообразность процесса.
Блокирование метаинформации при выполнении шагов, взаимодействующих с метой, во время наката задачи.
Очень много проблем с откатами и перенакатами задач.
Откаты и перенакаты не всегда можно было выполнить — тогда ждали синхронизации.
Первые три пункта из списка выше, на мой взгляд, очевидны, на них я останавливаться не буду. А вот оставшиеся стоит разобрать подробнее. Начну с блокировки метаинформации.
В рамках экосистемы, завязанной на SAS, инструментом для работы с метаинформацией стал SAS Data Integration Studio (SAS DIS). Объекты хранилища (описание баз, ETL-процессов, таблиц и т. д.) разрабатываются в SAS DIS и хранятся на SAS-сервере в виде метаданных. Физически таблицы находятся в базах Greenplum и SAS. Подробнее про технологии, которые используются в нашем хранилище, можно почитать здесь и здесь, а также просто воспользовавшись поиском по нашему блогу на «Хабре» поискать по ключевому слову "DWH".
Но у каждого инструмента есть тот или иной недостаток. У SAS DIS это блокировки метаинформации. SAS DIS устроен таким образом, что при выполнении одновременно нескольких переносов задач на тестовый контур все операции над метаинформацией (импорт, правка, удаление и т. д.) формируют очередь. И, что самое главное, при выполнении каждой такой операции любые другие манипуляции над метаинформацией, даже простой просмотр, будут недоступны для всех пользователей. То есть при получении большой очереди операций работать с метаинформацией долгое время будет просто невозможно.
Откаты задач и дальнейшие их перенакаты после исправления ошибок требовали повторения ручных действий, но не всегда можно было вернуть тестовый контур в корректное предыдущее состоянии. В этом случае требовалось восстановление данных на тестовом контуре, что достигалось путем его синхронизации с продуктовым контуром. Это тоже требовало времени.
Недостатки: долго, много ручных действий, вынужденные простои.
Необходимость в синхронизации продуктового и тестового контуров
Синхронизация — это актуализация данных на тестовом контуре путем передачи с продуктового контура актуальной метаинформации и самих данных для тестирования.
Синхронизация нужна была достаточно часто, не реже раза в месяц, поскольку за месяц из-за различных проблем (сбои и ошибки при накатах задач, удаление необходимых для отката задачи бэкапов и т. д.) данные и метаинформация на тестовом контуре переставали быть актуальными.
Кроме того, QA-инженеры перезатирали данные друг друга, и зачастую восстановление исходного состояния без синхронизации было невозможно. Это происходило из-за того, что часть объектов могла использоваться как источники в одних и как целевые таблицы в других пакетах. Тогда при изменениях метаинформации или физических данных происходил конфликт. Изолировать данные и метаинформацию при условии выполнения модульного и интеграционного тестирования на одном контуре не представлялось возможным.
Синхронизация проводилась достаточно долго, начиналась в пятницу вечером и завершалась в понедельник — при хорошем стечении обстоятельств. Плюс ко всему в процессе возникало много проблем.
Нужно было что-то делать, и появилось решение: создавать изолированные окружения для модульного тестирования каждого отдельно взятого пакета.
А теперь поговорим о том, какие проверки и каким образом выполнялись на этом этапе нашей эволюции.
Проверки данных без использования автоматизации
Все проверки качества данных в пакете с доработками хранилища на тестовом контуре носили ручной характер. QA-инженеры проверяли:
корректность данных на отсутствие NULL и дублей в ключевых полях;
соответствие DDL-таблицы на тестовом контуре описанию данной таблицы в модели данных;
наполнение каждого из столбцов таблицы;
соответствие данных в таблице эталонному прототипу;
регресс, сравнение с предыдущей версией таблицы, если объект менялся в рамках текущей доработки.
Кроме того, после выполнения всех вышеуказанных проверок запускались все зависимые объекты хранилища (кроме отчетов, то есть только ETL-процессы), чтобы проверить, не поломала ли доработка ранее работавший функционал. Таких ETL-процессов могло быть очень много плюс при прогрузке можно было бы испортить тестовые данные коллеге и т. д.
Итак, общие минусы ручных проверок:
долгое выполнение;
снижение мотивации сотрудников;
низкая производительность.
Также были минусы интеграционного тестирования:
зависимость от окружения;
возможные конфликты объектов из разных задач;
человеческий фактор.
Вот с такими проблемами мы сталкивались ранее, и их решение стало важной задачей для нашего дальнейшего развития. Какие же первые шаги были предприняты для решения описанных выше проблем?
Вот с чего началась наша эра
Рисунок 6. Переломные моменты — знаковые события в QA
Множество ручных действий, проблемы с тестовым контуром и синхронизациями, долгое тестирование — вот те проблемы, с которыми мы ежедневно сталкивались.
Какие же события стали переломными в этой ежедневной борьбе?
Авторелиз
Автонакат
Ручные переносы пакетов на тестовый контур заставляли дергаться глаза даже самых матерых QA-инженеров. С этим нужно было что-то делать, и команда python-разработки нашего управления создала его — авторелиз!
Это была специальная утилита, позволяющая переносить задачи на соответствующие контуры (dev/test/prod), причем интерфейс взаимодействия с ней был очень простой:
SSH-подключение к серверу;
запуск в терминале команды с указанием номера задачи, нужного контура.
Это позволило автоматизировать процесс переноса задач, но проблемы с зависанием меты при нескольких параллельных переносах задач на тестовый контур остались актуальными.
Демоны
Демоны — наши внутренние сервисы для улучшения и автоматизации процессов.
Первые демоны:
Валькирия — очищает изолированные тестовые окружения по тем задачам, что уже протестированы. То есть попросту удаляет все таблицы с данными на тестовом контуре по задачам со статусом testing done. Запускается демон ежедневно в 22:00, и уже на основе результатов работы этого демона Харон будет очищать буфер.
Харон — удаляет из общего буфера таблицы, которые не используются в задачах, ежедневно в 23:00. Это позволяет экономить место на тестовом контуре и не тратить рабочее время на очистку контура вручную.
Гермес — ищет подходящие бэкапы с продуктового контура, которые нужны для построения изолированных тестовых окружений. Об этом чуть подробнее расскажу в следующем разделе.
Создание авторелиза и демонов позволило сильно упростить процесс подготовки тестовых окружений, а также очистки тестового контура после завершения тестирования.
При описании демонов использовались такие понятия, как буфер, изолированное тестовое окружение. Давайте разберемся, что это такое, и познакомимся с нашей разработкой — vial.
Модульное тестирование
Vial
Итак, у нас уже появился авторелиз, а значит, задача переноса на тестовый контур решена. А что с проблемами тестирования? Их было много: частые синхронизации, проведение всех тестов на одном контуре (частые поломки окружения) и ручное выполнение тестовых проверок. Решение последней проблемы обсудим позже, а сейчас остановимся на первых двух.
Чтобы в процессе тестирования отдельные задачи не конфликтовали между собой и тестовое окружение дольше оставалось актуальным, был придуман механизм пробирок, или vial-контуров.
Что же это такое — давайте разберем более подробно.
Vial (или «пробирка») — изолированное окружение на тестовом контуре, включающее в себя физические данные только дорабатываемых и создаваемых по задаче объектов. При этом остальные объекты хранилища никак не затрагиваются, и любые работы с данными в пробирке не влияют на остальное хранилище.
Рисунок 7. Как соотносятся vial и test
С точки зрения хранения данных схема стала такой, как показано на рисунке 7: в базе данных тестового контура создаются отдельные схемы с префиксом preXXXXX (pre — префикс проекта, XXXXX — номер задачи в Jira) и в этих схемах хранятся все необходимые для модульного тестирования данные.
При построении пробирки с продуктового контура берутся бэкапы таблиц источников (Source на рисунке 8) для каждого дорабатываемого в данной задаче ETL-процесса. Причем бэкапы берутся консистентными.
Рисунок 8. Как формируется vial
А для целевых таблиц ETL-процессов (Target на рисунке 8) берется целых два бэкапа:
За одну и ту же дату, что и таблицы источники, — today.
За предыдущую дату — yesterday.
Зачем берутся два бэкапа?
Для ответа на этот вопрос разберем, как формируются данные на проде.
ETL-процессы хранилища ежедневно запускаются для прогрузки свежих данных из источников в целевые таблицы. Что при этом происходит:
Перед запуском ETL-процесса в источниках накапливаются свежие данные.
В целевой таблице ETL-процесса, Target(yesterday) на рисунке 9, находятся данные с актуальностью на вчера (или на дату прошлого запуска ETL-процесса, если процесс может запускаться несколько раз за сутки).
Далее ETL-процесс запускается и данные в целевой таблице приобретают актуальность на ту же дату, что и данные в источниках, — Target(today).
Все ETL-процессы хранилища делятся на две категории: работающие на полных данных (то есть при каждом запуске они перезагружают все данные в целевой таблице) и работающие на инкременте (при каждом запуске ETL-процесс подтягивает только новые и измененные записи из источников). При таком подходе, независимо от способа загрузки данных, используя самые последние версии источников и предпоследнюю версию таргета, ETL-процесс корректно выгрузит данные в таргет.
С принципом работы ETL-процессов на проде ознакомились, теперь перейдем к созданию виала.
Рисунок 9. Механизм обновления хранилища на проде
Данные с прода копируются в огромную специальную схему на тестовом контуре. Это буфер, в котором в специальных таблицах прописана связь каждого бэкапа с определенной задачей, где он используется. Именно отсюда демоны удаляют те бэкапы, что становятся ненужными после завершения тестирования.
Рисунок 10. Принцип формирования vial
На виале при тестировании новой версии этого ETL-процесса мы будем прогружать данные из тех же самых источников — рисунок 10. Но для этого сначала нужно скопировать данные из Target(yesterday)-бэкапа в целевую таблицу на виале.
Теперь наш ETL-процесс готов для прогрузки.
Если кроме изменения метаинформации в задаче есть правка физических данных, то выполняются соответствующие скрипты. Новая метаинформация деплоится на тестовый сервер, и ETL-процесс запускается.
По аналогии с продом процесс отработал на новых данных и сформировалась новая версия целевой таблицы. И вот именно она будет сравниваться с Target(today)-бэкапом на корректность проведенных доработок.
Данная проверка важна, поскольку позволяет отловить:
Неоднозначность в данных — по одному и тому же ключу при каждом запуске ETL-процесса приходят случайные значения атрибутов. Это происходит из-за того, что в источнике ключу соответствует сразу несколько значений, а в самом ETL-процессе не настроен однозначный критерий отбора нужного значения.
Ошибочные зануления или, наоборот, заполнения атрибутов.
Любые изменения в физических данных, которые не ожидались по ТЗ в конкретной задаче.
Таким образом, для выполнения регресса у нас есть все необходимые данные: целевые таблицы и старого, и нового процесса, прогруженных на одинаковых входных данных. Регресс считаем корректным, если таблицы на виале и таблицы на проде отличаются только выполненными по ТЗ доработками (рисунок 11).
Рисунок 11. Регресс
Итоговая общая концепция vial-контура изображена на рисунке 12.
Рисунок 12. Общая концепция vial
И что же нам дал vial?
Во-первых, отпала необходимость в синхронизациях. Данные и метаинформация легко стягиваются с продуктового контура точечно для каждой задачи, и это не требует огромных затрат, да и при порче данных достаточно стало перенакатить задачу на виал — и всё! Никаких долгих, муторных ручных откатов.
Во-вторых, разнесение по разным контурам модульного и интеграционного тестирования позволило меньше бояться за надежность интеграционного тестирования, так как окружение реже ломается и QA не портят данные друг другу.
Казалось бы, вот оно — счастье, живи и радуйся! Live-контур-то зачем было придумывать?
Оказывается, не для всех ETL-процессов такая схема регрессионного тестирования подходит. Дело в том, что во многих ETL-процессах источники обновляются гораздо чаще, чем раз в сутки, это так называемые реплики. И в случае с репликами, пока мы перенесем задачу на vial-источники, успеют обновиться и данные в целевой таблице, пробирки будут существенно отличаться от бэкапа, отработавшего еще на прошлой версии источников.
И вот тут на помощь приходит live.
Live
Задача данного контура — прогнать на тех же самых данных, что использовались при создании пробирки на vial, старую версию ETL-процесса. Рассинхрон данных в источниках исключается, и, таким образом, расхождения при сравнении старой и новой целевой таблицы ETL-процесса будут только в случае ошибочной логики или, например, всплывшей неоднозначности — один и тот же SQL-запрос при нескольких запусках возвращает разный результат.
Live позволяет быстрее локализовать источник расхождений и неоднозначность, являясь лучшим другом QA-инженера.
Итак, подытожим. У нас был единственный тестовый контур (test), на котором выполнялось и модульное, и интеграционное тестирование. Причем при выполнении модульного тестирования объекты не были изолированы (да, так получилось) и мы много страдали.
Проблема была решена созданием отдельных изолированных тестовых окружений на vial, а также контура для проведения регресса — live. Таким образом, test перестал использоваться для модульного тестирования.
А что же с ним стало?
Test
Test стал использоваться исключительно в качестве тестового контура для проверки интеграции.
На интеграционный контур мы сначала переносили задачи полностью, чтобы выполнить интеграционное тестирование: запустить все зависимые ETL-процессы и проверить, что они успешно отработали, а затем стали переносить только метаинформацию.
Поскольку все зависимости мы отслеживали с помощью инстанса (дерево взаимосвязей всех ETL-процессов хранилища), для интеграционного тестирования мы поддерживали мету теста в актуальном состоянии. Сами же интеграционные тесты были автоматизированы. Другого инструмента отслеживания зависимостей не было, поэтому отказаться от теста мы не могли.
Авточекер
Авточекер был первым шагом в автоматизации тестирования хранилища. Ряд проверок для интеграционного тестирования был описан в виде функций на python. Далее в сценарий переноса задачи на интеграционный контур была добавлена опция запуска специального шага сценария, на котором и выполнялись эти функции.
Все результаты проверок выводились в командную строку. Сообщения об ошибках подсвечивались красным. В общем, это была теплая ламповая консоль и при этом автоматизация плюс экономия нашего времени.
Время подводить предварительные итоги.
Проблемы на данном этапе
Итак, на текущем этапе мы запустили авторелиз и изолированные тестовые окружения, а также авточекер. Благодаря им была решена проблема ручного переноса задач, а также сделан первый шаг в автоматизации тестирования.
Но по-прежнему остались проблемы:
Ручной сбор пакета разработчиками.
Необходимость в синхронизации продуктового и тестового контуров.
Ручное ревью пакета.
Недоступность операций над метаинформацией при возникновении очереди (изначально выделена не была, но по ходу статьи упоминалась).
Для тестирования интеграции используется отдельный тестовый контур — test.
Решить эти проблемы нам помогли наши внутренние разработки: Портал автоматизации и Авторевью, тестовый фреймворк для автоматизации тестирования. Но об этом я расскажу уже в следующей статье.
Наш проект Quarkly по-прежнему в открытой бете, мы готовимся к релизу и в хорошем темпе добавляем функционал, который заложен в Roadmap. При этом апдейты апдейтами, а более активно щупать свою аудиторию, да что там щупать – сформировать комьюнити, которое не против таких виртуальных тактильных манипуляций – это большая и важная задача. С ней пока не всё гладко.
– Вот наш проект, он вот для этого и потенциально решает вот такую задачу.
– А есть юзкейсы? Дайте посмотреть.
– Ок, зайдем позже.
Полагаю, знакомая история для многих, кто запускал свои проекты. Тем ценнее, когда use case появляется сам из ниоткуда. Вот вы в бете и объективно понимаете, что нужно сделать, чтобы с помощью вашего продукта люди начали системно решать свои задачи, а они берут и уже сейчас что-то делают не по фану, а даже для прохода в финал крупного хакатона.
Эта история началась с того, что Саша написал нам в чатик в телеграме и задал несколько вопросов по работе с Quarkly.
В личной переписке Саша рассказал, что они в паре со знакомой дизайнером участвуют в хакатоне Цифровой прорыв 2020 и делают проект для прохода через сито регионального этапа в финал. Да, дело было аж в ноябре 2020, а полноценно пообщаться и наконец написать об этом пост дошли руки лишь сейчас. Но лучше поздно, чем никогда, как говорится.
Ниже с разрешения Саши публикую наше интервью.
Расскажи про первое знакомство с Quarkly. Насколько я понимаю, это случилось в сентябре в Ростове на конференции, где у нас был свой стенд?
Мы в фокусе и расфокусе
Притаились снизу
Верно, про Quarkly узнал на RndTechConf. Проект заинтересовал, но посмотреть руки дошли не сразу, скажу честно. Уже позже, когда знакомая позвала участвовать в хакатоне, я прикинул, что главное там пройти региональный этап и попасть в финал. Решает тут скорость.
Для этого нужно было либо быстро придумать, что можно сделать в одно лицо, либо в команде сотворить магию. Вместе со своей знакомой – она, кстати, дизайнер – мы никогда прежде не работали. Предложил ей рискнуть и посмотреть в сторону Quarkly. Это показалось удачным для экономии времени – она делает дизайн, я – всё остальное, заодно сразу в бою можно познакомиться с инструментом.
Про совместную работу как раз интересно. Насколько реально удобно было, не мешали друг другу? И удалось ли сэкономить время, как думаешь, если объективно?
Сначала у меня было дикое непонимание, как здесь реализовывать какую-то простую логику (как настоящий аладушек, прочел гайд лишь после хакатона, на хакатоне же делал по наитию). Поэтому поначалу задачей-минимум было использовать Quarkly для показа нашей рабочей концепции хотя бы из-за простоты развертывания. В этом плане точно удалось сэкономить, ибо схема «дизайн ––> реализация дизайна ––> залив» изменилась на «дизайн ––> накидываю сверху код, если требуется ––> залив изменений».
Ещё отмечу, что концепция наша менялась миллион раз уже во время хакатона, без Quarkly мы бы вряд ли могли себе такое позволить.
Как я знаю, в финал вы прошли?
Да, мы залетели по итогу в последний вагон: проходило всего 5 команд, и мы оказались пятыми. В финале уже не использовали Quarkly.
Не потому, что что-то не понравилось, а скорее из-за того, что на финал у нас была одна понятная концепция, да и основной упор был на бота в телеграме. Буст в скорости выхода какого-то веба нам уже не требовался.
Раз уж мы собираем кейсы, такой вопрос: каким ты видишь идеальное применение Quarkly сейчас? И что нужно в первую очередь добавить, чтобы он реально занял нишу на рынке?
При совместной работе мы всё время находились на разных страницах, в таком режиме нам было максимально удобно и понятно. Чтобы быстро собрать какой-то визуал и показать его – Quarkly полезен. А вот работать на одной странице одновременно сложно. Нет понимания, что в моменте на странице кто-то ещё есть. Непонятно, в какую область он смотрит.
Примечание: добавление подсветки совместных действий на одной странице уже есть в планах.
В работе условной дизайн-студии на несколько человек Quarkly может стать основным инструментом, как думаешь? В чем могут быть трудности?
Трудности для дизайнера, который делает что-то из серии margin-left: 2000px. Со стороны разработчика, пожалуй, непонятность со стором и с созданием каких-то общих утилит.
А так, да, я думаю, что спокойно студия может использовать как основной инструмент.
А ведь наверняка было что-то помимо невозможности увидеть совместные действия, что доставило сложности? Про непрочитанную доку упустим, я скорее о том, что вроде понятно, но для удобства хотелось бы иначе?
Сейчас особенно полезно об этом написать, бета-версия и всё такое.
Хотелось бы убрать костыль перехода между страницами через кнопки, которые на самом деле были ссылками.
Ради интереса или для каких-то проектов планируешь использовать Quarkly в ближайшее время?
Ради интереса – точно да. Информация про апдейты и фиксы периодически мелькает в телеге, поэтому не потеряемся.
Представитель Nvidia пояснил изданию TechPowerUp, что ограничения хешрейта графических процессоров GeForce RTX 3060 при майнинге Ethereum происходит не только с помощью драйвера.
Директор по связям с общественностью подразделения GeForce Брайан Дель Риццо уточнил, что между драйвером, графическим чипом RTX 3060 и прошивкой карты (vBIOS) существует дополнительная система проверки и обмена данными (secure handshake), которая предотвращает удаление или изменение заложенного производителем ограничителя скорости хэширования видеокарты
Фактически, Nvidia пытается сделать такой способ понижения хешрейта майнинга, который бы не зависел от версии драйвера карты.
Эксперты TechPowerUp предполагают, что Nvidia может перезапустить некоторые свои существующие на рынке модели видеокарт под другим идентификаторами. Они также будут иметь встроенный антимайнинговый алгоритм защиты, который обычный пользователь не сможет убрать самостоятельно. С 2018 года, начиная с графических процессоров Turing (GeForce 20, GeForce 16, Quadro и в Tesla T4), vBIOS поставляется партнерам в зашифрованном виде. Невозможно его скачать, изменить и загрузить обратно на карту.
Издание Tom's Hardware считает, что такая блокировка не помешает разработчикам майнинговых компаний, которые пишут свои собственные прошивки и драйверы. А если эти разблокированные vBIOS появятся в общем доступе, то все действия производителя будут зря.
18 февраля 2021 года Nvidia объявила, что запускает на рынок решения на базе специализированного GPU под названием CMP HX (Crypto-mining processor) для профессионального майнинга. Видеокарты серии GeForce компания хочет оставить геймерам. Компания ограничит хешрейт графических процессоров GeForce RTX 3060, чтобы они были менее желательны для майнеров. Это произойдет путем снижения производительности графического процессора в майнинге при использовании алгоритмов DaggerHashimoto и Ethash-подобных на 50%. На этот шаг компания пошла, чтобы улучшить ситуацию на рынке с дефицитом видеокарт.
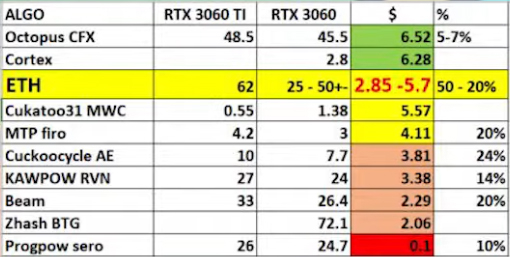
Блогер, который получил карту до релиза, подтвердил, что ограничение производительности в RTX 3060 работает только для одного майнингового алгоритма Ethash, при его применении карта выдает мегахэшей в секунду на 50 % меньше, чем обычно.
Сравнительная таблица производительности RTX 3060 на различных майнинговых алгоритмах.
Инженеры Калифорнийского университета в Сан-Диего создали четвероногого мягкого робота, для работы которого не требуется электроника. Робот управляется и перемещается при наличии постоянного источника сжатого воздуха.
Большинство нынешних мягких роботов питает сжатый воздух, а управляются они электроникой. Но для этого нужны сложные компоненты, такие как печатные платы, клапаны и насосы. Обычно они громоздкие и дорогие.
Новый робот управляется легкой и недорогой системой пневматических контуров, состоящих из трубок и мягких клапанов, установленных на нем самом. Аппарат может ходить по команде или в ответ на сигналы, которые он воспринимает из окружающей среды.
Вычислительная мощность робота примерно имитирует нервные реакции позвоночника млекопитающих.
Чтобы имитировать функции генераторов, инженеры построили систему клапанов, которые действуют как осцилляторы, управляя порядком, в котором сжатый воздух входит в мускулы четырех конечностей робота с пневматическим приводом.
Кроме того, исследователи создали инновационный компонент, который координирует походку робота, задерживая нагнетание воздуха в его ноги. Походка робота имитирует передвижение черепахи.
Аппарат также оснащен простыми механическими датчиками — маленькими мягкими пузырьками, наполненными жидкостью, расположенными на концах стрел, выступающих из его тела. Когда пузырьки опускаются, жидкость переворачивает клапан, заставляя робота менять направление.
Каждая из четырех ног робота имеет три степени свободы, приводимые в движение тремя мускулами. Стойки наклонены вниз под углом 45 градусов и состоят из трех параллельно соединенных пневматических цилиндрических камер с сильфонами. Когда камера находится под давлением, конечность изгибается в противоположном направлении. В результате три камеры каждой конечности обеспечивают многоосевой изгиб, необходимый для ходьбы. Исследователи соединили камеры на каждой ноге по диагонали друг от друга, что упростило задачу контроля.
Мягкий клапан переключает направление вращения конечностей против часовой стрелки и по часовой стрелке. Этот клапан действует как двухполюсный двухпозиционный переключатель с защелкой.
Авторы разработки отмечают, что ее можно применять как в сфере развлечений для разработки недорогих роботов, так и в тех средах, где не может работать электроника. К примеру, роботов можно поместить внутрь аппарата МРТ или в шахту. Разработку можно задействовать в работе более высокоорганизованных роботов, которые будут перемещаться благодаря пневматике, а выполнять команды — под управлением электроники.
В будущем исследователи хотят улучшить походку робота, чтобы он мог перемещаться по естественной местности и неровным поверхностям. Это потребует более сложной сети датчиков и, как следствие, разработки более сложной пневматической системы.
Ранее инженеры Калифорнийского университета показали робота-кальмара, который может автономно плавать, выпуская струи воды. Робот снабжен собственным источником энергии. Его можно задействовать для подводных исследований. Аппарат уже оснащен специальными датчиками для этой работы.
Привет, в этой статье будут рассматриваться легальные способы получить преимущество перед противником с помощью таких простых средств, как NodeJS, Electron и React, при этом обходя бан стороной. На эксперименты меня вдохновила другая статья Визуализация времени возрождения Рошана и желание автоматизировать часть рутины. Стоит заметить что сейчас будут рассматриваться инструменты не модифицирующие каким либо нечестным способом игру - все API открыты, данные получены честным путём, никакого вмешательства в процесс игры не происходит. Под катом будет несколько картинок и немного кода.
Пример использования в демо режиме игры
Весь исходный код расположен на Github, с ним можно ознакомится, лайкнуть, форкнуть, предложить изменения. Писал его левой пяткой правой ноги, прямо во время игры, поэтому просьба не ругаться сильно за стилистику.
Если честно, то я ничего нового не придумал, уже всё до меня придумали и даже есть готовые приложения, которые примерно тоже самое умеют.
Дальнейшими знаниями можно пользоваться, как во имя добра - делать инструменты для студий аналитики, киберспорта, стримов Twitch, тренировок команд и т.д., так и во имя зла - написания читов, выбор за вами.
Disclaimer: Автор не несёт ответственности за применение вами знаний полученных в данной статье или ущерб в результате их использования. Вся информация здесь изложена только в познавательных целях. Особенно для компаний разрабатывающих MOBA, чтобы помочь им бороться с читерами. И, естественно, автор статьи ботовод, читер и всегда им был.
В итоге созданные инструменты умеют:
Отслеживать игровое время
Воспроизводить звуки до начала важных событий
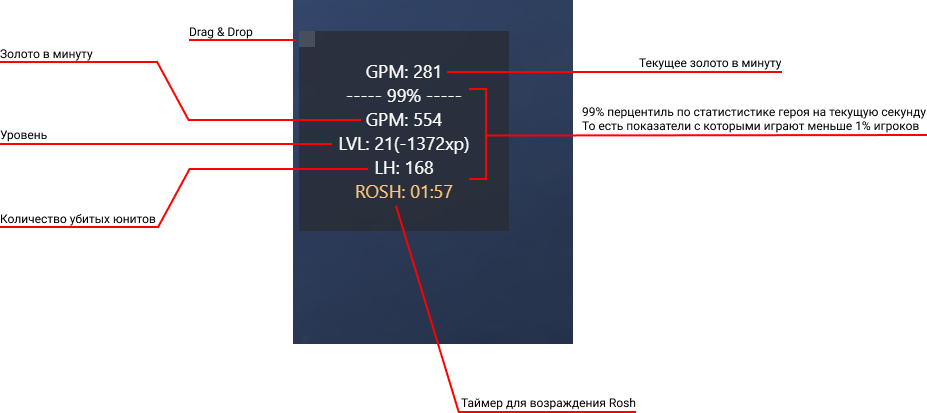
Отображают текущие показатели золота (GPM)
Отображают статистику по герою из открытого источника OpenDota.com
Отслеживать время возрождения рошана
Собирать данные о любимых героях противника
Какие ещё можно сделать улучшения:
Отображать историю средних показателей противника
Добавить ретроспективный анализ игры по её окончанию
Добавить больше звуковых/визуальных уведомлений
Дать возможность отслеживать "ультимейты"
Добавить больше визуальных данных во время просмотра киберспортивных игр
Добавить подробнейшие руководства прямо во время игры
и т.д...
С чего всё начиналось
У Dota 2 неожиданно есть GSI (Game State Integration), который придумали для интеграции сторонних приложений / оверлеев (наложение картинки поверх игры) и синхронизации этих самых оверлеев с игрой в реальном времени. Это говорит о том, что можно получать состояние игры и дальше что - то с ним делать. Для интеграции с NodeJS есть готовое решение в виде библиотеки. Для работы GSI сервера, в первую очередь, нужно создать файл конфигурации в "Steam\steamapps\common\dota 2 beta\game\dota\cfg", в этом файле прописываются настройки, например, такие:
После перезапуска игры, подтягиваются новые настройки и запускается сервер GSI, который будет отправлять данные по HTTP на localhost:3001, на котором и поднимается NodeJS сервер:
var server = app.listen(3001, () => {
console.log("Dota 2 GSI listening on port " + server.address().port);
});
Собственно, после запускается код слушателя, который как раз и позаимствован из сторонней библиотеки NodeJS
Сервер получения данных об игровом мире готов.
Данные, которые не дают преимущества
Во время рейтингового матча в Dota 2, GSI отдаёт обрезанные данные, из полезного доступно
Прошедшее количество секунд с начала игры
ID Героя
Игровое время в секундах
Личный GPM
Пример данных (в игре запущена карта с демо режимом)
Если просматривать реплей или чужую игру, то доступно гораздо больше информации - вся она описана тут. Что-ж, самая важная информация нам уже доступна - GPM, игровое время, Id героя.
После получения информации мы должны с ней что - то поделать, например, отрисовать или предупредить о наступившем моменте в игре.
UI, Оповещения, Electron
Для UI решено было использовать Electron и внутри этого электрона запускать React. Идея заключается в том, чтобы рисовать Electron приложение поверх игры (оверлей). Исходник оверлея можно найти тут, немного задержимся на нём - есть пару особенностей.
Для начала нужно настроить окно, в котором будет всё отображаться:
const win = new BrowserWindow({
width: 210,
height: 200,
// Окно должно без рамки
frame: false,
// Окно может быть прозрачным
transparent: true,
webPreferences: {
// Фикс багов связанных с импортами React
nodeIntegration: true,
},
});
// Окно должно всегда быть поверх остальных
win.setAlwaysOnTop(true, "screen-saver");
Сначала у меня не получалось поверх доты что - то вывести, пока не наткнулся на настройку в файле machine_convars.vcfg (Dota 2) под названием "dota_mouse_window_lock", которую нужно выставить в "0", а в самой игре (либо в тех же файлах конфигурации) настроить режим отображения в окне без рамки.
UI написан с использованием React, поэтому решено его было загружать прямо с dev сервера разработки (да, я ленивый):
В UI был выбран мой любимый стек: TS, CRA (Styled только для одного/двух классов использовался - рисовать то особо нечего). После того, как GSI Dota2 отправил данные на express сервер, их нужно передать на фронт. Пишется простая GET ручка для отдачи данных. Затем на фронте пишется хук, который раз в секунду запрашивает эти данные и дальше они попадают сразу во все остальные хуки. То есть в приложении каждую секунду запускаются все хуки - это важный факт, ведь иногда понадобится хранить время запуска хука, чтобы случайно его не запустить несколько раз (если этого не делать, то у вас произойдёт в лучшем случае два оповещения подряд, в худшем случае взрыв из оповещений). Логика получения данных:
import { State } from "../state/state";
import { useState } from "react";
import { useInterval } from "./useInterval";
const SERVER_URL = "http://localhost:3001/time";
const UPDATE_FREQUENTLY = Number(process.env.REACT_APP_SERVER_UPDATE_FREQUENTLY);
export function useServerState(): State {
const [state, setState] = useState<State>({});
useInterval(async () => {
try {
const data = await (await fetch(SERVER_URL)).json();
setState(data);
} catch {}
}, UPDATE_FREQUENTLY);
return state;
}
Теперь, когда есть все данные на фронте, можно написать хук для звуковых оповещений, что пора бы пойти (за 30 секунд до начала оповещает) забрать руны богатства, появляющиеся на каждой минуте кратной пяти (5, 10, 15, 20 минута):
export function useBountyRunes(state: State) {
const clockTime = clockTimeSelector(state);
const [play] = useSound(bountiesMp3, { volume: 0.25 });
const [lastIntervalPlay, setLastIntervalPlay] = useState<number>(-1);
useEffect(() => {
// Проверка, что время пришло корректное
if (!clockTime || isNegative(clockTime)) {
return;
}
// Проверка кратности минуты на 4,5 и проверка от двойного оповещения
if (isNeedToPlay(clockTime, lastIntervalPlay)) {
// Проигрываем звук
play();
// Записываем когда последний раз было оповещение
setLastIntervalPlay(getInterval(clockTime + ALARM_BEFORE));
}
}, [clockTime, lastIntervalPlay, play]);
}
Запись о последнем воспроизведении (setLastIntervalPlay) нужна чтобы не повторить оповещение случайно дважды.
И вот уже в игре одно преимущество, может быть оно несущественное, но как мне кажется неплохо управляет вниманием команды. Что - ж можно пойти дальше и сделать такую же кнопку возрождения рошана, как из прошлой статьи:
Хук useRoshanSpawn для кнопки
export function useRoshanSpawn(state: State) {
const currentGameTime = gameTimeSelector(state) || 0;
const [play] = useSound(roshanRespawnMp3, { volume: 0.25 });
const [roshanStopwatch, setRoshanStopwatch] = useState<RoshanStopwatch>({
isActive: false,
time: 0,
isPlayedSound: false,
});
// Фиксация смерти роши
function handleDead() {
setRoshanStopwatch({
time: currentGameTime,
isActive: true,
isPlayedSound: false,
});
}
// Сброс таймера
function handleReset() {
setRoshanStopwatch({
time: 0,
isActive: false,
isPlayedSound: false,
});
}
// Проверяем роша жив, жив/мёртв, и сколько времени прошло с момента смерти
const isDead = roshanIsDead(roshanStopwatch, currentGameTime);
const isDeadOrLive = schrodingerRoshan(roshanStopwatch, currentGameTime);
const timeToSpawn = roshanTimeDeadSelector(roshanStopwatch, currentGameTime);
useEffect(() => {
// Оповещаем звуком за 30 секунд до возможного возрождения
if (needToPlaySound(roshanStopwatch, currentGameTime)) {
play();
setRoshanStopwatch({
...roshanStopwatch,
isPlayedSound: true,
});
}
}, [roshanStopwatch, currentGameTime, setRoshanStopwatch]);
return { handleDead, handleReset, isDead, isDeadOrLive, timeToSpawn };
}
С рошаном всё немного запутаннее, чем с рунами - он может возрождаться в интервале от 9 до 12 минут. То есть у него есть состояния:
Точно мёртв (прошло до 9 минут с момента смерти)
Он жив или мёртв (прошло от 9 до 12 минут с момента смерти)
Он точно жив (прошло свыше 12 минут с момента смерти или это начало игры)
Поэтому у таймера есть три визуальных состояния:
Кнопка - для запуска таймера
Таймер тикает и сообщает о том что роша точно мёртв
Таймер тикает и сообщает о том что роша возможно жив, а возможно мёртв
И одно звуковое оповещение: Рошан будет в состоянии Шредингера через 30 секунд (то есть, и жив, и мёртв одновременно - пока не проверишь, не узнаешь). Также есть возможность сбросить таймер, ведь если мы проверили и узнали, что он жив - то таймер больше не нужен, а нужна кнопка о том чтобы сообщить о новой смерти рошана. Из минусов - иногда забываешь запускать таймер, было бы здорово в будущем это тоже автоматизировать.
Обогащаем данные
Ещё есть информация о том, на каком герое мы играем, поэтому пускай клиент запрашивает бенчмарки с сайта OpenDota.com и отображаем их, чтобы было понятно, на сколько мы отстаём от ритма игры. Я взял перцентиль 99%, то есть мне интересно, с какими показателями отыгрывается 1% лучших игр на том или ином герое.
export function useBenchmarks(state: State): State {
const [localState, setLocalState] = useState<Benchmarks>();
const updateBenchmarksForHero = useCallback(
async function (id: number) {
try {
// Запросили данные по герою
const response = await fetch(`${BENCHMARKS_URL}?hero_id=${id}`);
const benchmarks = (await response.json()) as Benchmarks;
// Сохранили бенчмарк
setLocalState(benchmarks);
} catch (error) {
setLocalState({
error,
});
}
},
[setLocalState]
);
useEffect(() => {
const heroId = heroIdSelector(state);
const benchmarksHeroId = localState?.hero_id;
// Запрашиваем бенчмарк, при появлении информации о герое
if (heroId && heroId !== benchmarksHeroId && !localState?.error) {
updateBenchmarksForHero(heroId);
}
}, [state, localState, updateBenchmarksForHero]);
// Возвращаем данные о бенчмарке
return { ...state, benchmarks: localState };
}
Узнаём предпочтения игрока
Было бы здорово получать информацию о том, на каких героях вероятнее всего будет играть противник, чтобы забанить, отобрать, законтрить их у него. Для этого нужно считывать память файл игры: "server_log.txt" и дальше распарсить его регуляркой, найти там ID ваших оппонентов, затем запросить историю игр в OpenDota или Dotabuff. У этого способа есть минусы - если оппоненты сделал свой игровой профиль скрытым в Dota 2, то никакой информации о нём вы не получите. Есть ещё один момент, который я забыл учесть - данные могут быть устаревшими, но в коде это легко исправляется добавлением фильтра по времени.
Attention: код по ссылке может совершить BSoD ваших глаз.
import fs from "fs";
const DEFAULT_FILE =
"C:\\Program Files (x86)\\Steam\\steamapps\\common\\dota 2 beta\\game\\dota\\server_log.txt";
// Парсим все ID в строке
const getDotaIdsFromLine = (line) => {
let playersRegex = /\d:(\[U:\d:(\d+)])/g;
let playersMatch;
let dotaIds = [];
while ((playersMatch = playersRegex.exec(line))) {
dotaIds.push(playersMatch[2]);
}
return dotaIds;
};
const getState = () => {
return new Promise((res) => {
// ищем последнюю строку со словом Lobby
fs.readFile(DEFAULT_FILE, (err, data) => {
const rowString = data.toString();
const startIndex = rowString.lastIndexOf("Lobby");
const finishIndex = rowString.indexOf("\n", startIndex);
const lobbyString = rowString.slice(startIndex, finishIndex);
res(getDotaIdsFromLine(lobbyString));
});
});
};
export const getSteamIDs = () => {
return getState();
};
После, будет здорово это тоже вывести, поэтому решено было сделать отдельное React приложение на localhost:3002. Без дизайна выглядит оно совсем по страшному, но это уже был просто спортивный интерес и вообще я им не пользуюсь. В нём есть информация о прошлых десяти играх. Кнопочка "Ban this id", чтобы убирать друзей, с которыми играешь, из этой статистики и ссылка на Dotabuff профиль, если вдруг хочется подробностей.
Это приложение тоже можно было бы красиво оформить в виде Electron оверлея и запускать его на стадии выбора героев, но кажется я слишком много играю в игры и мало уделяю времени действительно полезным вещам :-)
Что ещё пробовалось:
Пробовался DLL Injection из прошлой статьи и чтение памяти с помощью Rust, но там был большой изъян в том, что все найденные указатели на структуры данных жили до обновления игры, поэтому эта идея была заброшена.
Попытка создать сервис подбора героев на основе ML обучения по выгрузке игр из OpenDota.com или с тех же серверов Valve (провал - хотя мне кажется я просто не сумел правильно приготовить ML часть)
Парсинг Dota 2 реплеев - там не сложно, используется Protobuff и все структуры легко находятся на гитхабе. Вот только что дальше с этим огромным объёмом данных делать?
Вывод: интегрироваться с Dota2 не вызывает труда, можно делать быстрый анализ прямо во время игры, при просмотре киберспортивных игр можно сделать огромное количество красивого оверлея для Twitch стрима, также можно развивать эту тему в сторону ретроспективного анализа из реплеев, что скорее всего будет полезно профессионалам.
Надеюсь вам было интересно почитать про то, как я собрал на коленке читы (на самом деле хороший вопрос - читы это или нет?), да ещё и на JS, если есть орфографические или лексические ошибки, то пишите пожалуйста в ЛС, спасибо за внимание.



")




 для того, чтобы закрепить PN532")

















")