Всем привет.
Эта публикация является продолжением предыдущего рассказа про смарт-часы Huawei Watch с OS Android Wear. Те часы использовались 1.5 года, и в целом, эта система оставила приятные впечатления. Но жизненный цикл таких продуктов весьма короткий, да и как известно, гики оплачивают прогресс чтобы все остальные могли потом пользоваться отлаженной технологией. Так что настала пора поменять часы на более новую модель, заодно сравнить что стало лучше или хуже за пару лет прогресса.

Фото (с) Samsung
Под катом отзывы о предыдущей модели, и сравнение с новой.
Часть 1. Huawei Watch — опыт использования
Стоит сказать пару слов об использовании смарт-часов вообще — для чего оно нужно? Разумеется, сценарии использования у всех могут быть разные, но можно с уверенностью сказать что в 95% случаев часы используются как «второй экран» к смартфону. И в принципе это реально удобно: если например пришло сообщение по SMS или E-mail, можно просто поднять руку и сразу посмотреть на экране текст сообщения. Или утром не вставая с кровати, можно бысто пролистать входящую почту, посмотреть погоду на сегодня или остановить звонок будильника. Это удобно, и к такому комфорту быстро привыкаешь, все-таки часы в отличие от смартфона, почти всегда на руке.
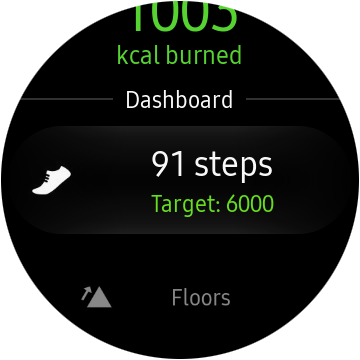
Второй полезной функцией оказался шагомер, при сидячей работе полезно знать сколько шагов пройдено за день, чтобы поддерживать уровень в 10000 шагов, так же в тур.поездках бывает интересно посмотреть общую дистанцию в конце дня. Иногда пригождалась возможность поставить таймер голосовым управлением прямо с часов, например если готовить что-нибудь на кухне, и руки заняты. В целом и все, никакие сторонние приложения в общем-то не пригодились. В Android Wear 2.0 была даже добавлена возможность загружать приложения прямо с часов, которая тоже ни разу не пригодилась… реально, что еще на часах делать, не в игры же играть.
Для тех кто не читал предыдущую часть, напомню что в свое время были куплены часы Huawei Watch, цена которых на момент покупки составляла 380Евро. Это конечно не Tag Heuer, но тем не менее, цена часов была примерно на 30% выше среднерыночной среди других моделей с Android Wear. И надо сказать, их дизайн вполне неплох, часы имеют металлический корпус, кожаный ремешок и сапфировое стекло:

Но не все оказалось идеально, и во время эксплуатации выявился ряд недостатков.
— Первый, и очевидный — батарея. Можно конечно настроить чтобы экран был выключен по умолчанию, но часы, не показываюшие время, это весьма бесмысленно (вскидывать руку или нажимать каждый раз кнопку тоже не очень удобно). В общем, с включенным экраном часы работали 2 дня, затем с обновлением с 1.5 до 2.0 и/или с деградацией батареи, это время сократилось до 1 дня. Это в принципе не так уж критично, если бы часы удобно заряжались. Но к сожалению, за 1.5 года контакты зарядки часов пришли в полную негодность.
Прошу прощения за не очень художественное фото под спойлером, но что есть, то есть. В итоге, часы заряжались 1 раз из 10, и их нужно было долго и аккуратно ставить на зарядную площадку, чтобы появился нормальный контакт. Не знаю из чего делали эти контакты, но явно не из золота. Наверно инженеры Huawei и не подозревали, что часы будут
носить (сарказм), и от влаги и пота контакты могут окислиться (или наоборот, так и было задумано?).
— OLED экран постепенно выгорает. В принципе, это не приводит к его неработоспособности, но на однотонном фоне это становится заметно:

Хорошо видно серую область в нижней части экрана, где выводились цифровые часы. Но в реальном использовании это не видно, если бы не батарея (которая кстати не является съемной), еще несколько лет экран бы вполне проработал.
— Часы носились аккуратно, не ронялись. Но тем не менее черный металлический корпус получил непонятно где пару царапин до металла, белые царапины на черном фоне выглядят неопрятно. Видимо, покрытие не такое уж надежное, что учитывая цену, конечно не радует. Кожаный ремешок за 1.5 года тоже полностью истрепался, так что было опасение что часы просто потеряются (новый фирменный стоит тоже недешево, хотя аналоги есть и на китайском ebay).
Как следствие вышеперечисленного, можно заметить, что остаточная стоимость весьма недешевых часов увы, стремится к нулю. Практически неработающий зарядник, выгоревший частично экран, батарея, держащая заряд всего один день, и протертый до дыр ремешок — продать такое невозможно, думается, даже смартфон 1.5 годовой давности имел бы гораздо лучшее состояние и цену, не говоря об обычных «классических» часах. Увы, в плане апгрейда, смарт-часы «игрушка» практически одноразовая.
Все это подробно описывается для того, чтобы те, кто выбирает смарт-часы, могли сделать некоторые выводы. Например, стало ясно что зарядка часов желательно должна быть беспроводной, иначе надежность такого решения оставляет желать лучшего.
OS Tizen и Samsung Galaxy Watch
Hardware
Samsung Galaxy Watch — это новый продукт, посмотрим какие функции предлагают сегодня современные производители смарт-часов.
— 1.3" или 1.2" экран с разрешением 360х360 и стеклом Gorilla Glass
— батарея 472 или 270мАч, в зависимости от модели
— 4Гбайт флеш-памяти, из которой пользователю доступно примерно 2.5Гб (можно хранить например музыку)
— Соединение по Bluetooth или WiFi
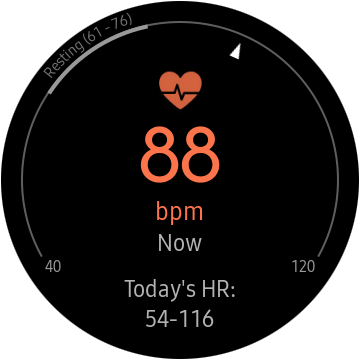
— Различные сенсоры (акселерометр, барометр, датчик пульса)
— Наличие GPS
— Наличие NFC (поддержка Samsung Pay, теоретически часами можно платить в магазине)
— Опциональная поддержка LTE, позволяющая быть онлайн даже при отсутствии смартфона (можно например слушать музыку онлайн во время пробежки)
— Наличие датчика освещенности (кстати, его отсутствие раздражало в Huawei Watch — та яркость дисплея, которая достаточна для солнечного света, слепит ночью в темноте)
— Беспроводная зарядка.
Цена часов на сайте samsung.com составляет 349$ за обычную и 399$ за версию с LTE. Версии с 1.2" экраном на 20$ дешевле.
Software
Одним из ключевых элементов дизайна Samsung является широкое кольцо вокруг экрана (bezel), которое используется для прокрутки. Решение на мой взгляд спорное — и обычный свайп пальцем на современных экранах работает вполне хорошо, так что никакой пользы кольцо не добавляет, зато занимает много места.
Основным на экране являются (кто бы мог подумать:) часы, выбор циферблатов (watch faces) можно видеть в программе Galaxy Wear, с помощью которой можно менять настройки часов.
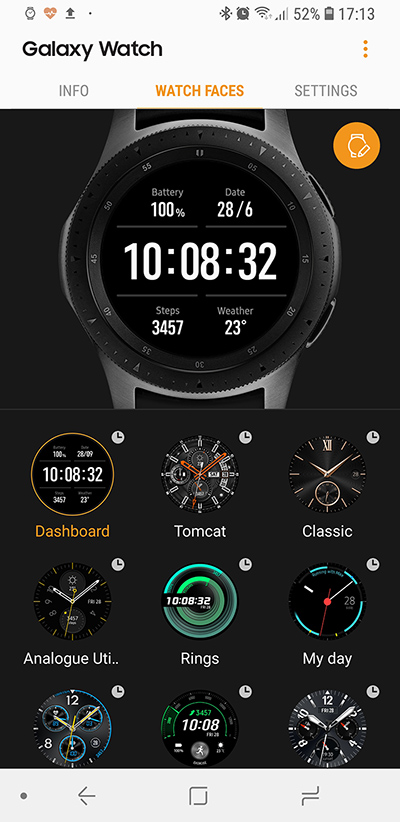
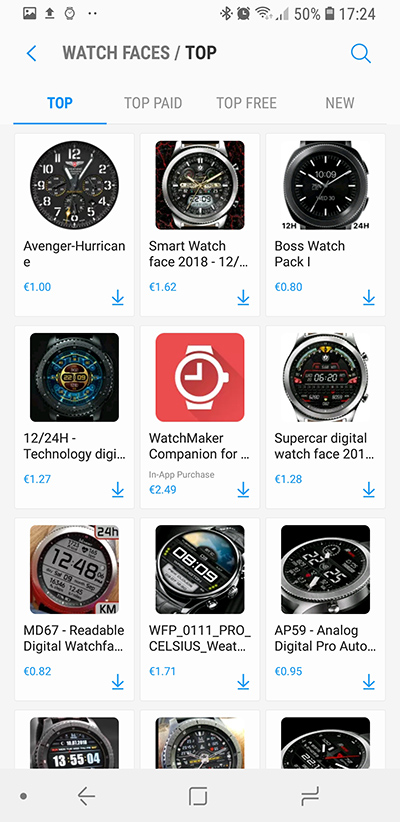
Нельзя сказать, что выбор так уж велик, но при желании можно перейти в магазин приложений Samsung, в котором есть сторонние циферблаты, в том числе и платные.
Поворот безеля или свайп пальцем с главного экрана влево показывает последние напоминания (почта, SMS, уведомления приложений), поворот или свайп вправо показывает различные «виджеты» — барометр, измеритель пульса, календарь, фитнес-трекер и пр.
Скриншоты с часов:


«Виджет» в понимании Samsung — это нечто вроде простого приложения с быстрым доступом. Вернуться на главное окно можно верхней кнопкой, которая везде работает как кнопка Back.
Нижняя кнопка открывает список установленных приложений, занимающий несколько экранов:

Многие приложения вполне простые — таймеры, будильники, напоминалки и пр. Некоторые программы могут быть полезны, например удаленное управление для GoPro или Philips Hue. Учитывая наличие GPS, иногда могут быть полезными карты, однако бесплатных версий не нашлось. Странно, но у Samsung никаких приложений для отображения карт нет вообще, а все сторонние приложения платные.
Есть даже игры, примерный вид которых понятен из скриншота.

По-моему сложно придумать занятие глупее игры на часах, но раз их делают, кто-то возможно их даже покупает…
По современной моде, часы имеют множество фитнесс-функций. Учет калорий, сердцебиения, различные виды тренировок, ведение лога выпитой воды или кофе, и так далее.

Встроенное приложение для бега вполне функциональное, и умеет показывать темп и скорость, пульс, записывать маршрут, имеет функции авто-остановки, сохранения результов.



Часы могут играть музыку, в том числе через Bluetooth-наушники, что может пригодиться спортсменам во время тренировки — не нужно брать с собой телефон. В магазине приложений есть и клиент Spotify, так что владельцы LTE версии смогут слушать музыку онлайн.
Часы имеют динамик и микрофон, с их помощью можно ответить на звонок, или например, посмотреть ролик с youtube со звуком (хотя и с сомнительным удовольствием — на мелком и круглом экране).

Встроенный почтовый клиент, в принципе, вполне позволяет прочитать заголовки и текст:

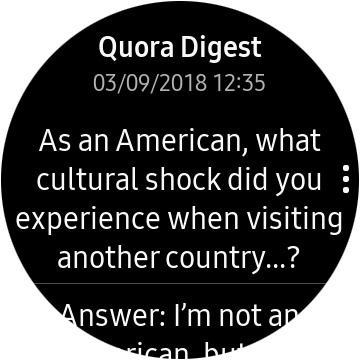
На письмо можно ответить предустановленными фразами (их заранее целесообразно отредактировать).

При большом желании можно набрать текст, но это будет медленно и печально:

Также есть голосовой ввод с микрофона, который более-менее понимает английский (насчет русского не уверен). Кстати, так же, как у Amazon, Google или Apple, у Samsung есть свой «интеллектуальный помощник» Bixby, способный понимать текст. Впрочем, «интеллектуальность» весьма условная, например, простые фразы типа «какая сегодня погода» распознаются нормально, а вот команда после сохранения скриншота «пошли последнее изображение с часов на смартфон» хоть и была грамматически распознана, но поставила систему в тупик (в программе «Галерея» на часах есть функция отправки изображения на смартфон, которой и хотелось воспользоваться).
Недостатки
Если говорить о часах Galaxy Watch, то они вполне крупные, даже для мужской руки. Даже на рекламных картинках от Samsung они кажутся слишком большими.

Впрочем, это плата за большое число функций и батарею большей емкости.
Если говорить о софте, то главный недостаток Tizen OS — то, что это не Android. Суть в том, что Android Wear гораздо больше интегрирован со смартфоном Android. Все приходящие на смартфон уведомления тут же отображаются на часах, если запустить воспроизведение youtube на смартфоне, на часах появляются кнопки «стоп/пауза», и пр. С Tizen OS почти все это тоже вроде как есть, но в меньшей степени. Например, почта отображается нормально, а вот остановить будильник с часов не получается, при срабатывании будильника на смартфоне, на часах не отображается ничего. Разумеется, в часах нет gmail-клиента (есть свой от самсунг, умеющий впрочем читать почту gmail) и нет google maps, нет приложения youtube (хотя видео можно смотреть через браузер), и так далее.
Так что, если с «хардварной» точки зрения к часам претензий нет, то вот с «софтовой» — для тех, кто хочет абсолютно полной и прозрачной синхронизации с Android-смартфоном, лучше смотреть в сторону часов с такой же ОС. Впрочем, каких-то критичных моментов (кроме будильника и отсутствия встроенных карт) пока найдено не было.
Еще один минус (хотя это скорее придирка) — тенденция к тому, что каждая крупная компания хочет иметь свою платежную систему, свой магазин приложений, свой аккаунт с аутентификацией, а пользователь в свою очередь должен поддерживать всю эту тучу аккаунтов. Было бы проще, если бы появилась какая-то единая платежная система, где было бы достаточно одного аккаунта и одной регистрации, но увы, вряд ли это возможно.
Заключение
В целом можно заметить, что смарт-часы пока хоть и экзотика, но этот рынок определенно показывает неплохой рост. До идеала еще далеко, но технологии совершенствуются, и это радует. Что касается функционала Tizen OS, то опасения о недостаточности функций оказались напрасными, за небольшими исключениями, все необходимые функции есть и работают ничуть не хуже.
Интересно и то, что большие возможности современных часов предоставляют новые функции, которые раньше были недоступны, например, поддержка LTE дает возможность владельцу оставаться онлайн даже без наличия смартфона, или совершать оплату с помощью системы Samsung Pay.
Let's block ads! (Why?)