В предыдущих частях туторов мы рассматривали то, как создаются текстуры. Точнее, то, как всё выглядит под капотом (как выразился
Yoooriii в комментариях к 4-ой части). Расставили на свои места термины — пиксели и тексели. Разобрали немного развертку и сетку моделей, PBR и материалы. И, наконец, подвели черту под профессией «художник по текстурам». Казалось бы, можно остановиться и начать уже работу.
Часть 1. Пиксель здесь.
Часть 2. Маски и текстуры здесь.
Часть 3. PBR и Материалы здесь.
Часть 4. Модели, нормали и развертка здесь.
Часть 5. Система материалов — вы ее читаете.
Вводный блок.
В этой части у нас не будет практики, так как 5ая часть получилась достаточно большого объема. Всю информацию о том, как можно создавать материалы и настраивать их в Unreal Engine 4 можно найти в туторах Flakky и многих других. Наша задача сейчас разобрать теорию максимально подробно (И если какой-то информации будет недоставать, пожалуйста, сообщите мне об этом).
В 2017-ом году на Unreal Dev Day Montreal выступил технический художник Harrison Moore. Он рассказывал о том, какой подход для текстурирования он и его команда применяли для того, чтобы в игре Paragon были очень красивые материалы. Ниже приведена ссылка на его лекцию.
Дело в том, что мы создаем VR проект, где качество текстур имеет огромное значение. Например, создавая текстуры для крупных объектов (стены, пол, большие шкафы, коробки и прочее), мы наталкивались на то, что стандартный метод давал очень пикселизованные текстуры, а фаски, которые создавались при помощи жестких граней и карты нормалей (мы это разбирали в 4 части) при приближении объектов близко к глазам, смотрелись настолько пиксельно и убого, что нам приходилось увеличивать размер текстур, чтобы это исправить. В конечном счете, чтобы добиться хотя бы приближенного к желаемому результата, мы стали клепать 8к текстуры. Получалось, что на основные большие объекты создавать текстуры 8к очень накладно, но визуально это было удовлетворительно (максимум).

По началу все шло гладко. Текстуры клепались, качество нормальное, но собрав сцену из объектов с такими текстурами, мы поняли, что это не работает. Объем текстур был очень большим — для того, чтобы наш проект заработал у конечного пользователя, требовалось, чтобы видеокарта имела объем оперативной памяти не менее 3 гигабайт. Да и размер одной такой текстуры составлял 67 млн текселей. Даже не смотря на то, что это уже полностью просчитанные и запеченные текстуры, требовались не малые вычислительные способности видеокарты, чтобы прогнать все тексели и отобразить их на экране. А мы же понимаем, что для полноценной реализации PBR нам требуется не 1 текстура (и не 1 канал), а минимум 9 каналов.
В итоге, у нас получались сцены, в которых объем текстур имел огромные размеры, требовал дичайших расчетов и проваливал FPS с нужных нам 90 кадров до 45. Стало понятно, почему почти во всех играх используются только текстуры BaseColor, а другие практически не подключают. Например, игра Torn для VR:

Большая часть (я бы сказал, 90%) объектов сделана просто — материал состоял исключительно из BaseColor. Ни карт нормалей, ни металлика ни шероховатости. К сожалению, скриншоты игры, доступные в сети, не позволяют показать минус данного подхода, и наоборот, очень часто скриншоты показывают, что там есть все карты, и картинка очень красивая. Но не будем об этой игре.
По началу я проигнорировал лекцию, видео которой я вставил выше. Точнее, просмотрел и подумал, что вроде бы неплохой подход, однако менять pipeline создания объектов и текстур в нашей команде мы не стали, так как для этого потребуется достаточно большой кусок времени, чтобы освоить, чтобы внедрить, чтобы наработать навыки. И всё же, столкнувшись с проблемой качества материала, я решил пересмотреть под к текстурированию.
Мы начали разбирать, что же такое предлагал Harrison Moore.
Предпосылки к становлению понятия «художник поверхностей».
И так. Ребята из Epic Games разработали интересный подход для текстурирования (Точнее, рассказали о нем). Они взяли подход к созданию текстур в Substance Painter (или любой другой программе по текстурированию) и перенесли само запекание текстур из программы в движок напрямую (если быть точнее, то этот процесс можно назвать процедурной генерацией материалов). То есть, теперь расчеты для запекания текстур уже проводятся в самом движке, а текстуры не создаются, а компилируются заранее. Результат компиляции (шейдер) хранится в формате, который понимает движок, и, когда отображается модель с этим шейдером, то результат накладывается на модель.
Как это работает?
В движок загружают текстуры какой-либо фактуры (материала) размерами по 1к. То есть, стандартный набор — Base Color, ORM, Normal Map. Таких фактур загружают 10-20 штук. Например, 4 разновидности металла, 5 разновидностей кожи, несколько вариантов пластика, дерево и так далее. Все это объединяют в шейдерные функции, чтобы потом можно было легко подключать их. 1 фактура = 1 функция.


После этого создают маски для нужного нам объекта. Вот здесь Substance Painter снова становится необходим — с помощью него создаются маски на объект. То есть, нужно указать, в каких местах объекта какие фактуры должны отображаться, чтобы потом отрисовывать нужную фактуру в нужном месте на объекте:
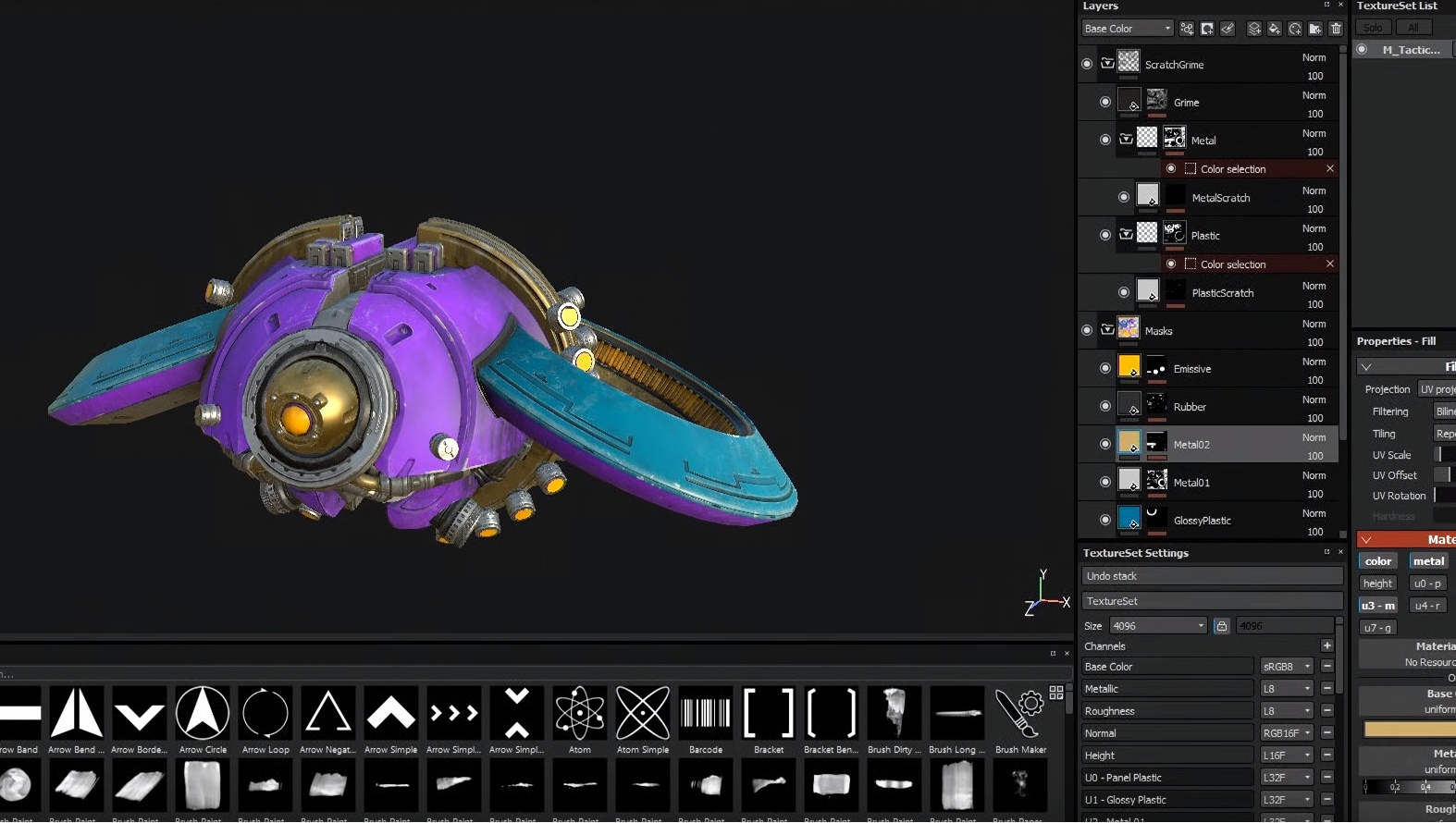
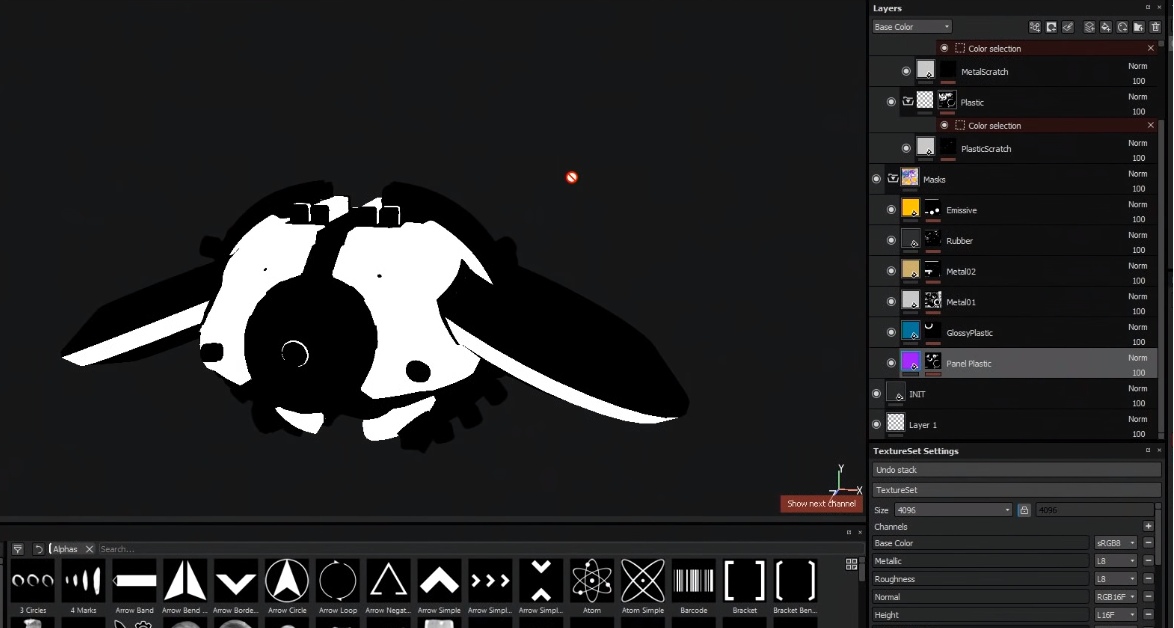
Выше на скриншоте видно, как летающий робот покрашен в яркие цвета. Коротко — это сделано специально, чтобы видеть, какие где какие маски располагаются. Второй скриншот показывает одну из масок.
Эти маски выгружаются в движок. Так же создают карту нормалей для каждого объекта отдельно, чтобы сгладить фаски, отобразить какие-то мелкие технические элементы с помощью нее и так же загружают в движок.
Далее создается новый шейдер (материал), в который добавляются созданные маски. Добавляются нужные шейдерные функции с нужными фактурами (например, ржавый металл, пластик и свежий металл) и далее прописывается код (практически ничего писать не нужно, все таки Epic Games все сделали все возможное, чтобы нам было удобно работать), в котором мы указываем, как смешивать правильно маски, какие фактуры отображать под какими масками, как отображать фактуру грязи и прочее-прочее.
После того, как все собрано, компилируется шейдер и выводится результат.
Ну, казалось бы, чего такого — ведь то же самое можно сделать в Painter и получить уже готовый результат. Однако это не так. И всему виной тайлинг.
Немного о тайлинге.
Тайлинг (Tiling) (дословно — плиточный, плитка, ) — Это повторение текстуры, как будто плитки, если она меньше размером, чем зона для текстурирования (UV). Это необходимо для того, чтобы заполнить пробелы, которые образуются в UV-пространстве, если текстура меньше размером. Видеокарта просто начинает ее дублировать столько раз, сколько нужно, чтобы закрыть брешь. Тайлинг работает интересным способом — видеокарта рассчитывает каждый тексель текстуры (например, размером 1к). И когда дело доходит до той части, которая продублирована — никаких расчетов уже не производится, так как они уже есть. Видеокарта просто копирует и вставляет данные. Копи-паст. И это практически ничего не стоит для производительности. Это настолько не требовательно к ресурсам, что не влияет ни на что, даже если вы сделаете тайлинг 10000*10000 повторений, (а это с нашим примером порядка 10 миллиардов текселей повторить, на минуточку о цифрах), ваш проект ни на секунду ни затормозит.
Продолжаем.
То есть, мы можем взять теперь фактуру. Показать в нужном месте на объекте и зайтайлить (продублировать) ее ровно столько, сколько нужно для достижения нужного качества. За счет тайлинга размер текселей очень сильно уменьшается, что увеличивает качество самой фактуры.
Минусом такого подхода является математика — теперь, чтобы отобразить текстуры на объекте, шейдеру необходимо просчитать различные операции по многу раз, чтобы отобразить конечный результат, и вместо стандартных 3-х текстур движку необходимо учитывать маски, смешивание нормалей, цветов и так далее.
На самом деле проигрыш в расчетах нивелируется:
- Вы можете и будете использовать фактурные функции повторно. Раз за разом на других объектах. То есть, расчеты будут суммарно те же, но количество самих текстурных карт будет меньше в разы. Вам уже не нужно для каждого объекта создавать новые текстуры, только определить зоны для фактур и использовать одни и те же фактуры.
- Вы можете создавать меньше размером маски — например, 128 на 128 пикселей. Что уменьшает расчеты в сотни раз.
- Вы можете тайлить текстуры сколько вам будет угодно, добиваясь результата, которого не получится добиться стандартным методом текстурирования.
- Добавляя другие расчеты и маски, вы можете играть с отдельными каналами, например, сделать тайлинг канала шероховатости меньше, чем карты цвета, тем самым нарушив визуальное повторение рисунка и создав ощущение уникальности всей поверхности.
- Вы можете накладывать текстурные функции таким образом, чтобы они смещались относительно координат объекта в мировом пространстве — таким образом можно поставить 2 одинаковых объекта с одинаковыми шейдерами, но они оба будут выглядеть уникально.
Стоит понимать, что этот подход не ко всем платформам. Например, мобильные игры уже сложно собирать таким образом из-за сложности в расчетах.
Самый простой пример минусов стандартного подхода к текстурированию и новой Системы Слоев Материалов (Material Layer System — так назвали данный подход ребята из Epic Games) — игра Final Fantasy 15. Для того, чтобы улучшить качество картинки, они выпустили пак с 8к текстурами. А что такое — 4к текстуры? Это 16 млн просчетов текселя на 1 канал. А если их 9 для стандарта PBR?
И вот тут мощь Системы Слоев Материалов начинает проступать максимально. Чтобы собрать с помощью фактур одежду на персонаже — достаточно использовать 3-4 фактуры (может больше). В сумме это будет меньше, чем стандартные текстуры высокого разрешения, производительность примерно на одном уровне, а качество можно контролировать с помощью тайлинга и выставлять намного выше.
Material Layer System.
Ребята из Epic Games пошли дальше и представили бета-версию «Системы Слоев Материалов» (Material Layer System), которая не создала шумихи и оказалась достаточно забагованной.
Пример ее работы можно посмотреть на этом видео:
Исходя из того, что система оказалась пока что не пригодной к работе, мы с ней ознакомились, обрадовались, что когда-нибудь ее доделают, а пока отказались от работы с ней и перешли на создание шейдеров вручную, указывая каждую маску в шейдере напрямую.
В итоге, мы начали пробовать и экспериментировать.
Как мы избавились от карт нормалей.
Сначала работа с фактурами шла не совсем гладко — нужного эффекта с текстурами мы достигали, но все еще нас сильно тормозила карта нормалей, так как ее необходимо было генерировать для каждого объекта, чтобы создавать ощущение красивых фасок. Не смотря на качество фактур, создаваемых нами, при приближении к объекту камеры фаски оставляли желать лучшего даже при 8к текстурах (напомню, что мы разрабатывали проект под VR). Но 8к текстуры — это очень большой объем текселей. Настолько большой, что 2 полных комплекта текстур просаживали FPS до 45 кадров (для VR надо 90).
Тогда мы ознакомились с методом создания фасок, о котором я рассказывал кратко в 4-ой части. Создание фасок на моделях объектов позволило практически полностью избавиться от карт нормалей. Да, у нас увеличился полигонаж моделей, но не более 20-40%, при этом качество фасок взлетело до небес.
Такой подход позволил нам избавиться и от другой проблемы — швов на гранях. Создавая на модели фаски, более не требовалось резать модель по жестким граням. Жестких граней в принципе более не было на моделях, поэтому острова стали большими, они стали включать в себя большие пространства, и теперь, когда мы накладываем фактуры на модели — на моделях практически нет швов.
Это не значит, что теперь на всех объектах у нас нет отдельной карты нормалей. Просто большинство из стандартных объектов может обойтись одними фасками в моделях без дополнительной карты нормалей.
В конечном счете, постепенно уменьшая маски, увеличивая и усложняя шейдеры мы начали создавать сложные материалы, которые позволяют нам текстурировать очень красивые поверхности:

Выше пол состоит из 2х фактур — железные полоски — 32х32 пикселя и гексагоны — 32х32 пикселя. У материала очень сложная формула — очень большое количество операций для расчетов — порядка 295 инструкций. Для обычного материала такой шейдер потребовал бы большие вычислительные мощности, но мы используем всего 32х32 = 1024 текселя на канал. 9 каналов = 10к текселей, которые необходимо учесть при расчетах данного материала + маска 128х128. Очень большое количество операций нивелируется маленьким количеством текселей для обработки. В итоге, у нас получилась красивая картинка очень быстрым и легким шейдером.
За счет масок, грамотного управления тайлингом и каналами можно создавать очень сложные шейдеры, которые будут генерировать красивые материалы и при этом практически не кушать ресурсов.
Для примера — на текущий момент мы используем около 10-15 фактур на весь проект (плюс несколько уникальных полностью затекстуренных объектов по стандартному методу). Один и тот же металл есть практически на каждом объекте. Он видоизменяется в шейдерах — мы добавляем к материалу разные цвета, мы сдвигаем карты шероховатости фактур, накладываем по маске царапины, а их смещением управляют координаты объекта (если речь идет о статических объектах), что приводит к уникальным объектам со своими сколами, трещинами, грязью.
При увеличении разрешения экрана нам достаточно просто отрегулировать тайлинг, чтобы кол-во текселей совпадало с кол-вом пикселей экрана. При стандартном методе текстурирования придется перелопачивать все текстуры, поднимать старые проекты в Painter и пересохранять их. А еще нужно убедиться, что текстура не поедет. А потом это все необходимо будет реимпортировать в движок и убедиться, что там все будет нормально, что шейдеры будут достаточно быстро просчитывать текстуры большего объема, чем прежде.
Мыслить фактурами.
Когда я общался с 3D-художниками на тему фактур, мне не раз говорили, что большинство объектов невозможно собрать с помощью фактур, что для этого требуется отдельная текстура с уникальными рисунками и прочим составляющим. Например, вот эта беседка:

Сложность представления этого объекта в фактурном плане состоит в том, что у него есть уникальные моменты:

Паттерн ремня сверху ткани можно сделать отдельной фактурой и просто наложить поверх фактуры ткани. Или вшить ремень в фактуру ткани, и тогда у нас получится уникальная фактура ткани с ремнем:

При использовании такой фактуры пришивка ремней к ткани будет постоянно на одном и том же участке повторяться, но это не будет бросаться в глаза.
Мокрые пятна делаются маской и накладывается грязь или что-то еше. И это уже выглядит уникально.
Бахрома так же выделяется фактурой, причем ее размер будет очень маленьким, так как она повторяется. Отобразить ее на модели можно через маску.
Уникальный узор на металлическом крючке можно наложить либо декалью либо отдельным слоем карты нормали небольшого размера, который зайтайлить под положение развертки и проявить через маску.
Складки на рулоне ткани можно реализовать с помощью геометрии или наложить маски с затенениями. В текущем поколении железа добавление небольшого кол-ва вертексов не вызовет никакой нагрузки, а лодами всегда можно будет спрятать их при отдалении.
Деревянные объекты можно сделать фаской, и тем самым, убрать полностью из расчетов карту нормалей. И так далее. Самое главное здесь то, что всё это очень быстро поддается корректировке без сторонних программ и трат времени.
И самое важное, все эти фактуры можно использовать в любом другом шейдере, подкорректировав цвета и пятна.
Исключения.
Большая часть, я бы сказал, 95% всех объектов в игре покрываются этим методом. В целом, даже хендпейнтинг попадает под фактуры и может быть реализован через него. Однако не все объекты на данном технологическом этапе можно реализовать. Например, сложные персонажи, у которых есть особые элементы. И даже их, если хорошенько подумать, можно покрыть фактурами — важно их своевременно увидеть, обрезать и затайлить.
Мне предложили продемонстрировать диван (картинка ниже), как элемент, который нельзя затекстурить фактурно.

Однако, если внимательно присмотреться, то у дивана есть 3 фактуры (кожа сверху, обивка, дерево для ножек) и 2 сложности — это складки и швы.Складки можно имитировать 2-мя способами:
1. Дополнительные вертексы.
2. Дополнительная небольшая карта нормалей, которая будет эмитировать волны складок (более привлекательный метод).
Тоже касается и швов — их можно выделить маской и просветить фактуру для швов или, опять же, дополнительной картой нормали.
Все обрывы, все переходы можно имитировать фактурами и масками, создавая тот же результат, но с меньшим кол-вом текстур (нам достаточно использовать фактуры стандартной для нашего проекта ткани и просто изменять ее цвет в шейдере напрямую).
Тут можно задать вопрос — а что делать с выцветаниями вокруг подушек? Маски решают такие проблемы на ура =)
Далее мы можем использовать эти же фактуры для кресел. Для других диванов, для стульев с такой же тканью на сидушке. И все это мы можем многообразить, перемножив цвета фактур на нужные нам. И нам не потребуется более с нуля создавать текстуры — достаточно собрать маски и правильно наложить слои фактур. Таким образом, мы уменьшим объем загружаемых текстур, но сохраним качество и даже поднимем его. Однако, стоит отметить, что это наш пайплайн, и сбор материалов может отличаться от студии к студии, платформ и в целом проектов.
Художник по поверхностям.
И вот мы плавно подошли к художнику по поверхностям. Основная задача художника по поверхностям научиться видеть, что можно делать фактурами, что вертексами, а что — стандартным методом текстурирования. Понимать, какие маски использовать и где, чтобы добиваться нужного результата.
Так же нужно понимать, что не все можно сделать фасками — бывает так, что некоторые объекты должны иметь карту нормалей с хай-поли модели, чтобы передать все тонкости изгибов поверхностей. Например, сложные изгибы тканей одежды на персонаже, или тонкости деталей на оружии. Саму ткань, опять же, уже текстурировать с помощью фактур и масок.
Распознавание фактур, как мне кажется, достаточно сложная задача, потому что наш мозг нацелен на уникальные текстуры, так как просто привык с ними работать. Тем более, что это стандарт игровой индустрии, который является основой всего. А ведь, когда-то стандартом была простая текстура цвета без дополнительных параметров.
Важно научиться пользоваться Substance Designer — это та программа, которая позволит вам создавать собственные маски и фактуры очень высокого качества.
А еще ребята из Epic Games выложили замечательную статью "Jobs in Unreal Engine — Surface Artist", где рассматриваются требования к тому, чтобы стать полноценным художником по поверхностям. Очень рекомендую ознакомиться с ними, чтобы понимать, куда расти и к чему стремиться.
Вместо заключения:
Мое имя Денис Кузнецов, и я представляю компанию Qbercat Studio, мы так же разрабатываем игру Movies Tycoon (на данный момент об игре информацию мы не выкладываем, однако у нас есть группа в контакте, в которой мы планируем выпускать дневники разработчиков и промо-материалы. Поэтому не удивляйтесь, что группа пуста) и практически все наши материалы созданы исключительно фактурным методом. В нашей студии три 3D-художника и 1 художник по поверхностям. На 1-го художника по поверхностям в среднем хватает 3-5 3D-художников. Все зависит от сложности шейдеров, конечного результата, платформы и самого проекта.
Отдельное спасибо Snake из discord-чата "Unreal Engine — RuCommunity", с которым мы в жаркой полемике рождали выводы.
Спасибо Flakky за то, что внес правки по тексту.
Помните, если вы видите в статье какие-то неточности или неверную информацию — я всегда буду рад вашим замечаниям. Эти туторы созданы не для рекламы, а для того, чтобы все желающие могли максимально быстро включиться в работу, поняв саму суть текстурирования и его видов.
Спасибо вам за внимание =)
Let's block ads! (Why?)