
Всем привет! Меня зовут Артем, в тырнетах более известен под идиотским ником TTEMMA, но не суть. Я являюсь одним из основателей любительской группы переводчиков Russian Studio Video 7 и единственным ромхакером-программистом в данной команде.
Мы с командой первые, кто смог подарить фанатам Resident Evil переводы двух культовых игр на Nintendo GameCube – Resident Evil Remake и Resident Evil Zero, когда-нибудь я расскажу о том, как мы все это делали, но в данной теме я бы хотел рассказать о такой роскошной игре, как Xenoblade Chronicles на Nintendo Wii и о том, как происходил и далее происходит ромхак данной игры. В данной игре всё сделано в японском стиле, странно и в некоторых моментах просто задаёшься вопросом — «Зачем?», но потом вспоминаешь, на сколько японцы странные люди и эти вопросы отпадают. Ну что ж, начнём?
Предисловие
Xenoblade Chronicles эта та игра, из-за которой стоит, нет, даже нужно приобрести
Nintendo Wii. JRPG, большой открытый мир, куча вспомогательных квестов и захватывающий сюжет, который затянет прохождение игры не на недели, а на месяца. Все, кто знаком с
Nintendo Wii, знает, что консоль предназначена для слабеньких красочных семейных игр по типу
Super Mario и т.п, но то, что сотворили
Monolith Soft достойно похвалы, их
Xenoblade Chronicles обладает прекрасной и красивой графикой, не смотря на огромные технические ограничения консоли(посоревноваться в плане графики может только
Resident Evil Remake и
Resident Evil Zero).
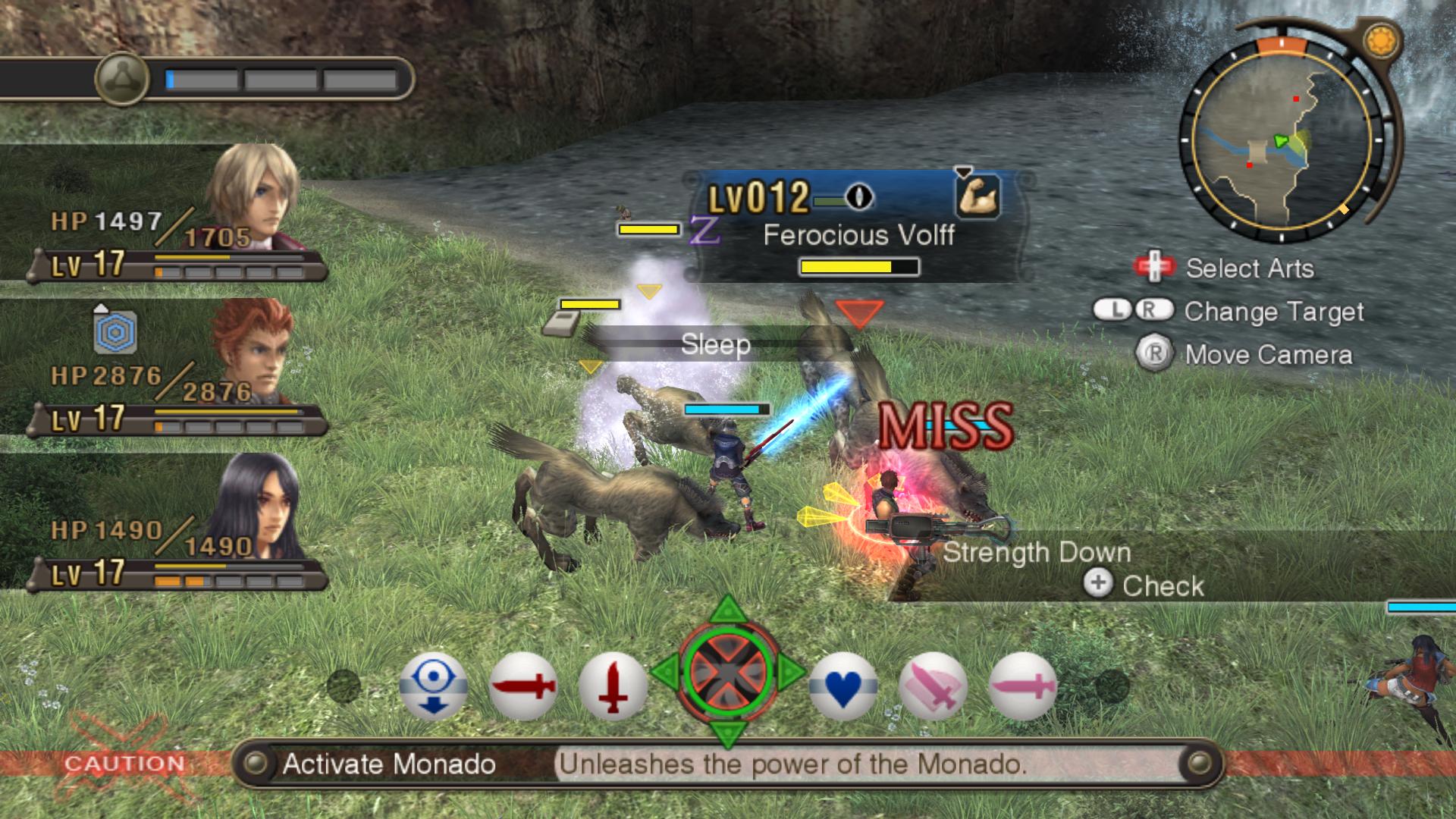
Посмотрев с командой на данную игру, мы решили, что она нуждается в переводе на наш великий и могучий. Но как известно, не разобравшись в технической составляющей игры, браться за перевод явно не стоит. И вот о технической составляющей мы сейчас и поговорим.
Технические нюансы
Немного расскажу о самой
Wii и о том, о чем речь в данной теме не пойдёт.
Что Nintendo GameCube, что Nintendo Wii работает на процессоре от IBM с архитектурой PowerPC. Данный процессор работает в Big-Endian режиме, это важно запомнить(как по мне, хакинг файлов Big-Endian намного удобнее, чем Little-Endian из-за порядка байтов).
Благо, Nintendo сильно позаботились о разработчиках игр и в своих SDK предоставили просто огромное количество форматов для любой цели, именно о них речь в данной теме и не пойдёт. Может быть я потом и расскажу о них подробно, но моя лень вряд ли позволит. Выделить из форматов Nintendo я хочу лишь один – BRFNA (Binary Revolution Font), о нём и пойдёт дальше речь.
Шрифт
Шрифт в
Xenoblade Chronicles(далее XC) хранится в стандартном, но редко используемом в играх формате с расширением BRFNA.
Существует лишь два стандартных для Wii формата шрифта:
- BRFNT(более популярный)
- BRFNA(редко используемый)
Я не буду углубляться в их структуру, а лишь расскажу о различиях:
- В BRFNA был добавлен новый блок, хранящий в себе информацию о кодировке(ansi, kanji, european и т.д.)
- В BRFNA текстуры с символами сжаты неизвестным мне форматов, в то время как в BRFNT они лежат в открытом виде и спокойно редактируются.
BRFNA успел доставить много проблем, во первых – неизвестный тип сжатия, во вторых – слегка странное разделение по кодировкам. Спас нас из этой ситуации, как ни странно, официальный конвертер шрифтов из 3DS SDK от
Nintendo. Но и с ним появились проблемы, пришлось изучать используемые кодировки в самом
XC, писать отдельные конфигурационные файлы для конвертера текстур и поиграться с настройками самого конвертера, чтобы шрифт был идентичен оригиналу. И о благо, после нескольких дней мучений я смог вывести русские буквы с использованием русских кодов символов из UTF8.
Правда, игра долго упиралась из-за размера нового шрифта и крашилась в самом начале загрузки игры. Сначала были подозрения, что мои кривые руки делают что-то не так, но после того, как я убрал умляуты из шрифта, то игра спокойно запустилась. Но убирать умляуты я категорически не хотел, поэтому подошёл с другой стороны, я просто изменил формат текстур c IA4(4 бита на цвет, 4 бита на прозрачность) на просто I4(4 бита на цвет, без прозрачности) и вуаля, XC взлетела как миленькая.
Почему я решил изменить именно формат текстур? Потому что могу! Ну а если честно, то это никак не ухудшило качество символов. Вывод символов в данной игре работает таким образом, что он выводит лишь альфа канал, никак не используя при этом основной канал, а вот если использовать формат шрифта без прозрачности, то ему и использовать, кроме как основной канал, нечего. Безобразие, подумал я и решил обойтись без прозрачности, чтобы не захламлять место.
На этом моменте работы со шрифтом были окончены и вычеркнуты из списка задач.
PKB\PKH – контейнеры файлов
Что-то начал я свой рассказ совсем не с того. Чтобы добраться до многих основных файлов, придётся их как-то извлечь из контейнера PKB.
PKB представляет из себя просто контейнер, без каких либо указателей, размеров и имен файлов. Всё, что можно заметить, так это кучу файлов, выравненных по 2048 байт.
Самое же интересное хранится в PKH файлах, но и чтобы добраться до них придётся постараться. Все PKH файлы находятся в отдельном для каждого языка U8 архиве с именем static.arc.
STATIC.ARC английского языка
PKH же представляет из себя весьма странную разметку для PKB, хранящую в себе размер, указатель и индекс файла. Из индекса сама игра как-то получает полное имя файла, но я с этим разбираться не стал, т.к. это слишком муторно и бессмысленно.
Я не смог разобрать структуру данного контейнера до конца, но для извлечения и запаковки файлов изученного хватило.
PKH можно поделить на 2 блока: Header и Entry, что я и сделал.
public class pkhModuleEntry
{
public uint ID;
public uint unk;
public ushort sizeFile;
public uint offsetFile;
public pkhModuleEntry()
{
ID = unk = offsetFile = sizeFile = 0;
}
}
public class pkhModule
{
uint Magic;
uint version;
uint tableOffset;
uint pkhSize;
uint countFiles;
pkhModuleEntry[] entry;
string[] extensions;
...
}
Entry у нас начинается с указателя tableOffset. Только вот проблема в том, что entry разделено ещё на несколько блоков, загрузка всей информации о файлах происходит таким образом:
for (int i = 0; i < countFiles; i++)
{
entry[i] = new pkhModuleEntry();
entry[i].ID = mainPkhSfa.ReadUInt32();
entry[i].unk = mainPkhSfa.ReadUInt32();
}
for (int i = 0; i < countFiles; i++)
entry[i].sizeFile = mainPkhSfa.ReadUInt16();
for (int i = 0; i < countFiles; i++)
entry[i].offsetFile = mainPkhSfa.ReadUInt32();
По коду выше можно понять, что вся информация о файлах разделена на 3 блока:
- Индексы файлов и неизвестные значение
- Размеры файлов
- Указатели на файлы
Можно заметить, что указатель на определённый файл хранится в uint32, то есть в 4-байтной переменной, а вот размер, почему-то, в 2-байтной. Объясню данный изъян, как я говорил выше, в PKB файлы выравнены по 2048 байт и это сделано не спроста. Размер файла указывается не в байтах, а в количестве данных блоков. К примеру, размер файла указан 0xC, следовательно размер в PKB будет 0xC * 0x800 = 0x6000.
Изучив данную структуру был быстро наклёпан распаковщик\запаковщик и я приступил к изучение контейнеров, хранящих в себе текст.
Контейнеры с текстом
Как и всегда, японцы понаделали странностей в своей игре. После долгих изучений игровых контейнеров было выделено 3 фронта с игровым текстом:
- Контейнер BDAT – хранит в себе какие-то данные и строки, приоритетно системные (меню, торговля, настройки).
- Контейнер SB – хранит в себе скрипты и строки с разговорами с жителями.
- Контейнер REV – хранит в себе данные и строки, используемые в кат-сценах.
К защите своих строки японцы подошли отлично, но нам данный факт совсем уж не понравился.
В каждом контейнере шифруются только строки, это не стало бы проблемой, если использовался бы только один алгоритм шифрования. Но увы, японцы решили для каждого контейнера разработать свой алгоритм шифрования, что и создало для нас много проблем.
В данной теме я расскажу лишь о контейнере BDAT и его алгоритме шифрования, о шифровании в контейнере SB пока что промолчу, а об шифровании в контейнере REV сказать ничего не могу, т.к. пока что он находится в процессе хакинга.
Контейнер BDAT

Самый первый контейнер, который пал мне на хакинг — это BDAT. Бегло осмотрев, сложно было понять, что он в себе хранит текст. Но мы же не пальцем деланы, так что сразу полезли гуглить об этом формате. На забугорном форуме была найдена кое-какая информация о структуре данного контейнера и была предоставлены пруфы, что там хранится текст. Даже софт нашёлся, который его извлекает, но мои файлики он, почему-то, не скушал. Порыскав ещё по забугорным форумам я понял, что их версия игры содержит текст в открытом виде, а вот я в своих файлах этого не вижу. В голове сразу же потекли потоки информации и разные предположения и только один был верный — шифруются японцы, шифруются. Осталось лишь одно, разобраться как.
Проведя несколько манипуляций, у меня на руках был дамп памяти с расшифрованным BDAT и оригинальным, начался процесс анализа этих файлов. Проведя кучу времени на сравнение файлов, я не смог разобраться в шифровании. Никаких закономерностей я не видел и выход был один — дебажить!
К сожалению, Dolphin обладает хреновеньким дебаггером(либо я просто зажрался и привык к дебаггеру PCSX, где есть все возможные функции для дебагга). Мне надо было выяснить, в какой области памяти расшифровывается BDAT и поставить там брик на запись, но, Dolphin умеет ставить бряк только на команду по адресу, но на чтение\запись из опр. участка RAM не умеет, это стало проблемой. Начались поиски Dolphin с дополненными функциями для дебагга и таковой был найден — Dolphin DebugFast на основе 4 версии, в него добавлена лишь одна особенность — брик на чтение\запись в RAM, то что нужно, подумал я и приступил к дальнейшему хаку.
Найдя в памяти участок с нужными мне данными, я поставил брик и начал изучать, как же игра расшифровывает свои BDAT. Всё оказалось просто и в тоже время интересно. В BDAT есть 2 байтовый ключ, первый байт грузится в регистр R5, второй в R0 соответственно, так же есть булевая переменная, которая в начале расшифровка устанавливается в 1(true).
Если булевая переменная установлено в 1, то расшифровка происходит с помощью регистра R5, если же в 0, то расшифровка происходит с помощью регистра R0.
Шифрование же основано на простом XOR, порядок расшифровка таков:
- Зашифрованный байт = Зашифрованный байт ^ R(5 или 0)
- R(5 или 0) = (Зашифрованный байт + R(5 или 0)) & 0xFF
- Смена булевой переменной на противоположное значение
Код на C#:
public static void BDAT_DecryptPart(int offset, int size, ushort key, MemoryStream data)
{
data.Position = offset;
int endOffset = offset + size;
if (endOffset > data.Length)
endOffset = (int)data.Length;
bool reg = true;
byte _r0 = (byte)(0xFF - (key & 0xFF));
byte _r5 = (byte)(0xFF - (key >> 8 & 0xFF));
byte inByte = 0;
while (offset < endOffset)
{
inByte = data.GetBuffer()[offset];
if (reg)
{
data.GetBuffer()[offset] = (byte)(inByte ^ _r5);
_r5 = (byte)((_r5 + inByte) & 0xFF);
reg = false;
}
else
{
data.GetBuffer()[offset] = (byte)(inByte ^ _r0);
_r0 = (byte)((_r0 + inByte) & 0xFF);
reg = true;
}
offset += 1;
}
}
Шифрование разработано очень интересно, каждый следующий байт зависит от прошлого, да ещё с чередованием, гениально! Причём, что ресурсов для расшифровки почти на израсходуется, а понять суть алгоритма без дебагга не возможно.
Покончив с шифрованием, я стал разбираться со структурой самого BDAT. После расшифровки строковых данных, в начале файла были замечены какие-то названия, больше похожи на название каких-то блоков.
Примерчик
Зашифрованный блок с 0x2C — 0x66.

Но разбор этого блока я отложил, и решил разобраться с общей структурой. Путем непростого анализа, было выявлено, что Header у нас занимает всего 0x20 байт, его структуру я описал ниже.
Не буду углубляться, как я всё это определил, а просто расскажу, что каждый из этих байт значит.
class header
{
public uint magic;
public byte mode;
public byte unk;
public ushort offsetToNameBlock;
public ushort sizeTableStruct;
public ushort unkTableOffset;
public ushort unk2;
public ushort offsetToMainData;
public ushort countEntryMain;
public ushort unk3; public ushort unk4;
public ushort cryptKey;
public uint offsetToStringBlock;
public uint sizeStringBlock;
...
}
- Magic — константа и всегда равна BDAT(ansi)
- Mode — 1: нет шифрования, 3: имеется шифрование
- unk — как понятно, неизвестно, но данный байт всегда равен нулю
- offsetToNameBlock — указатель на зашифрованный блок с именами блоков
- sizeTableStruct — размер одного блока со всеми данными
- unkTableOffset — указатель на таблицу, которую до конца я разобрать не смог
- unk2 — неизвестно, но всегда равен 0x3D
- offsetToMainData — указатель на блок, содержащий все данные
- countEntryMain — количество блоков по указателю offsetToMainData (размер блока MainData можно просчитать таким образом: sizeTableStruct * countEntryMain)
- unk3 — неизвестно, всегда 0x01
- unk4 — неизвестно, всегда 0x02
- cryptKey — 2-х байтный ключ для расшифровки
- offsetToStringBlock — указатель на блок с текстом
- sizeStringBlock — размер блока с текстом(равен 0, если текста нет)
После Header до offsetToNameBlock идут неизвестные данные, как выяснилось это информация о блоках в MainData и имеет данную структуру:
class typeStruct
{
public byte unk;
public byte type;
public ushort idx;
...
}
- unk — неизвестно
- type — тип данных
- idx — указатель в MainData(точный указатель просчитывается таким образом: offsetToMainData + (IndexStructure * sizeTableStruct) + idx
И остался последний блок — offsetToNameBlock, он имеет такую структуру:
class nameBlock
{
public string bdatName;
public nameBlockEntry[] nameEntry;
public nameBlock(StreamFunctionAdd sfa, int countName)
{
bdatName = sfa.ReadAnsiStringStopByte();
sfa.SeekValue(2);
nameEntry = new nameBlockEntry[countName];
for (int i = 0; i < countName; i++)
{
nameEntry[i] = new nameBlockEntry(sfa);
}
}
}
class nameBlockEntry
{
public ushort offsetToStructType;
public ushort unk;
public string name;
public typeStruct type;
public nameBlockEntry(StreamFunctionAdd sfa)
{
offsetToStructType = sfa.ReadUInt16();
unk = sfa.ReadUInt16();
name = sfa.ReadAnsiStringStopByte();
type = new typeStruct(sfa, offsetToStructType);
sfa.SeekValue(2);
}
}
Хочу выделить только переменную countName, которой нет нигде в Header, но просчитывается она путем отнимания указателя на NameBlock 0x20 и делением данного числа на 4. Объясню почему: Header кончается по адресу 0x20, NameBlock начинается далеко после Header, а как мы знаем, сразу после Header идёт информация о структурах блоков в MainData, которая занимает 4 байта на структуру. И вот чтобы узнать кол-во таких структур, нужно узнать размер только информации о структурах и поделить на их размер, то есть 4.
Кажется, на первый взгляд, сложным строением, но попробую объяснить по другому:
Есть блок, где хранятся все данные — MainData. Данный блок поделён на несколько блоков, количество которых описано переменной countEntryMain, а размер одного такого блока описан переменной sizeTableStruct. А вот какие данные хранятся в одном таком блоке уже описывается с помощью класса typeStruct, количество которых может быть от 1 до нескольких. Для каждой typeStruct есть название, которое храниться в nameBlockEntry.
Вот и всё, BDAT разобран был наклёпан софт для извлечения\замены текста, который успешно пашет.
Пример извлечённых строк из BDAT
Заключение
В данной теме я попытался озвучить о том, как я пытался хакать одну из легендарных игр на
Wii и довести до Вас, как японцы продолжают делать всё для того, чтобы в их файлах никто не рыскал.
Возможно будет и продолжение разбора форматов в данной игре, но это не точно. Если понравилась моя статья, то я расскажу о том, как мы переводили Resident Evil Remake и Resident Evil Zero.
Спасибо за уделённое время!
P.S. Это моя первая статья в подобной тематике, прошу не кидаться тапками, а лучше сразу указать на ошибки. Может что-то нужное не раскрыл до конца или не объяснил, прошу указать на это, чтобы больше таких ошибок не повторилось.
Комментарии (0)