В этой статье рассматривается создание достаточного простого автотеста. Статья будет полезна начинающим автоматизаторам.
Материал изложен максимально доступно, однако, будет значительно проще понять о чем здесь идет речь, если Вы будете иметь хотя бы минимальные представления о языке Java: классы, методы, etc.
Нам понадобятся:
- установленная среда разработки Intellij IDEA (является самой популярной IDE, для большинства случаев достаточно бесплатной версии Community Edition);
- установленные Java (jdk/openjdk) и Maven, прописанные в системные окружения ОС;
- браузер Chrome и chromedriver — программа для передачи команд браузеру.
Создание проекта
Запустим Intellij IDEA, пройдем первые несколько пунктов, касающихся отправки статистики, импорта проектов, выбора цветовой схемы и т.д. — просто выберем параметры по умолчанию.
В появившемся в конце окне выберем пункт «Create New Project», а в нем тип проекта Maven. Окно будет иметь вид:
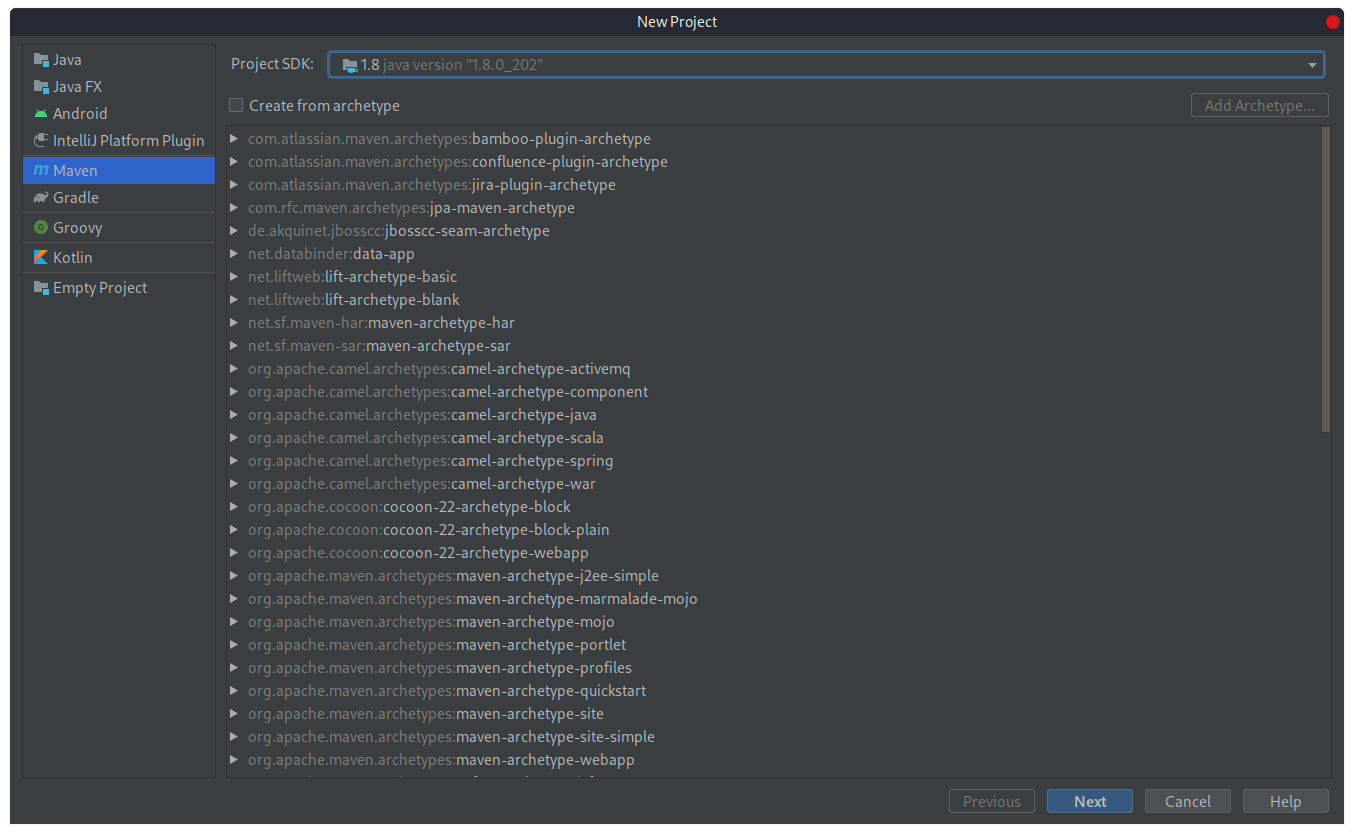
- Maven — это инструмент сборки Java проектов;
- Project SDK — версия Java, которая установлена на компьютере;
- Create from archetype — это возможность создавать проект с определенным архетипом (на данном этапе данный чекбокс отмечать не нужно).
Нажмем «Next». Откроется следующее окно:
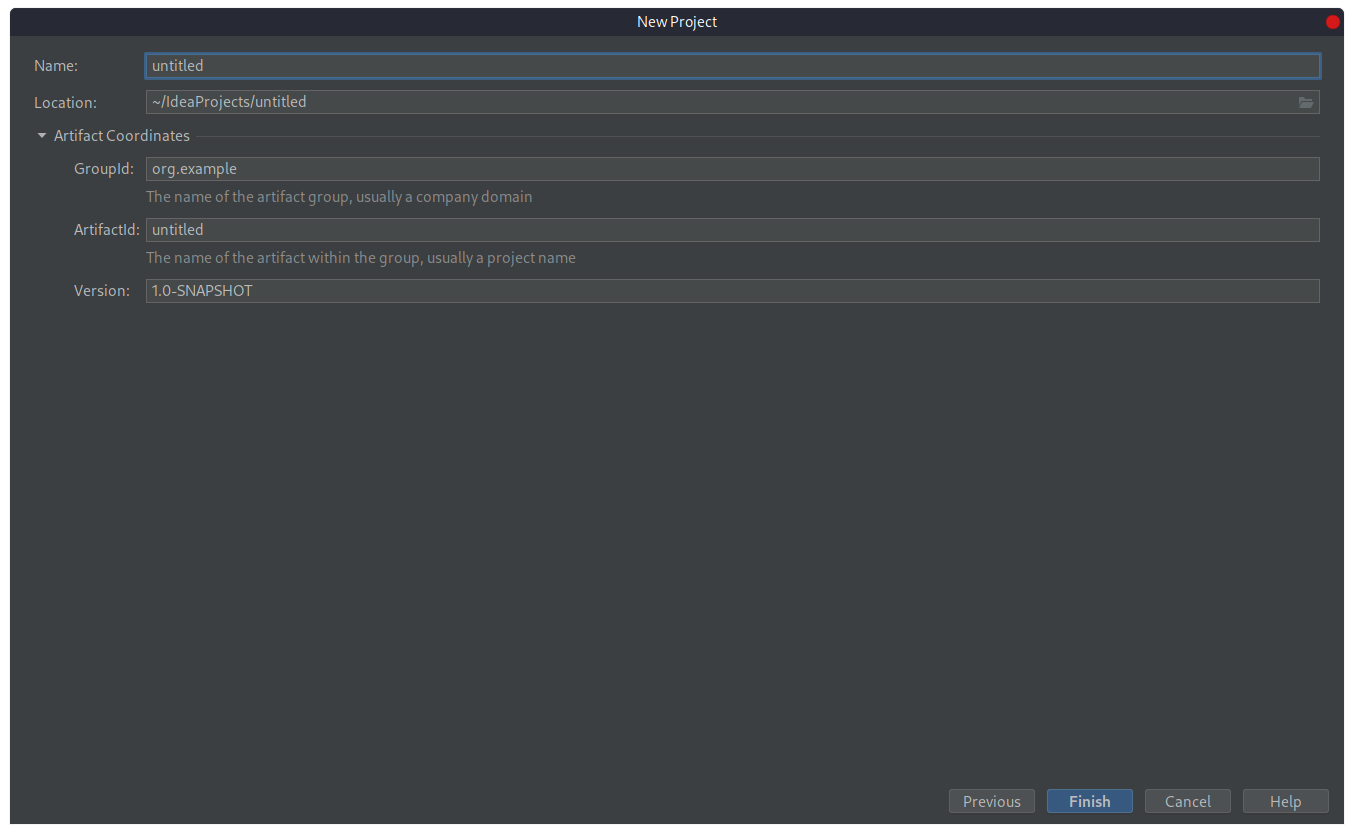
Groupid и Artifactid — идентификаторы проекта в Maven. Существуют определенные правила заполнения этих пунктов:
- Groupid — название организации или подразделения занимающихся разработкой проекта. В этом пункте действует тоже правило как и в именовании пакетов Java: доменное имя организации записанное задом наперед. Если у Вас нет своего доменного имени, то можно использовать свой э-мейл, например com.email.email;
- Artifactid — название проекта;
- Version — версия проекта.
Нажмем «Finish»: IDE автоматически откроет файл pom.xml:
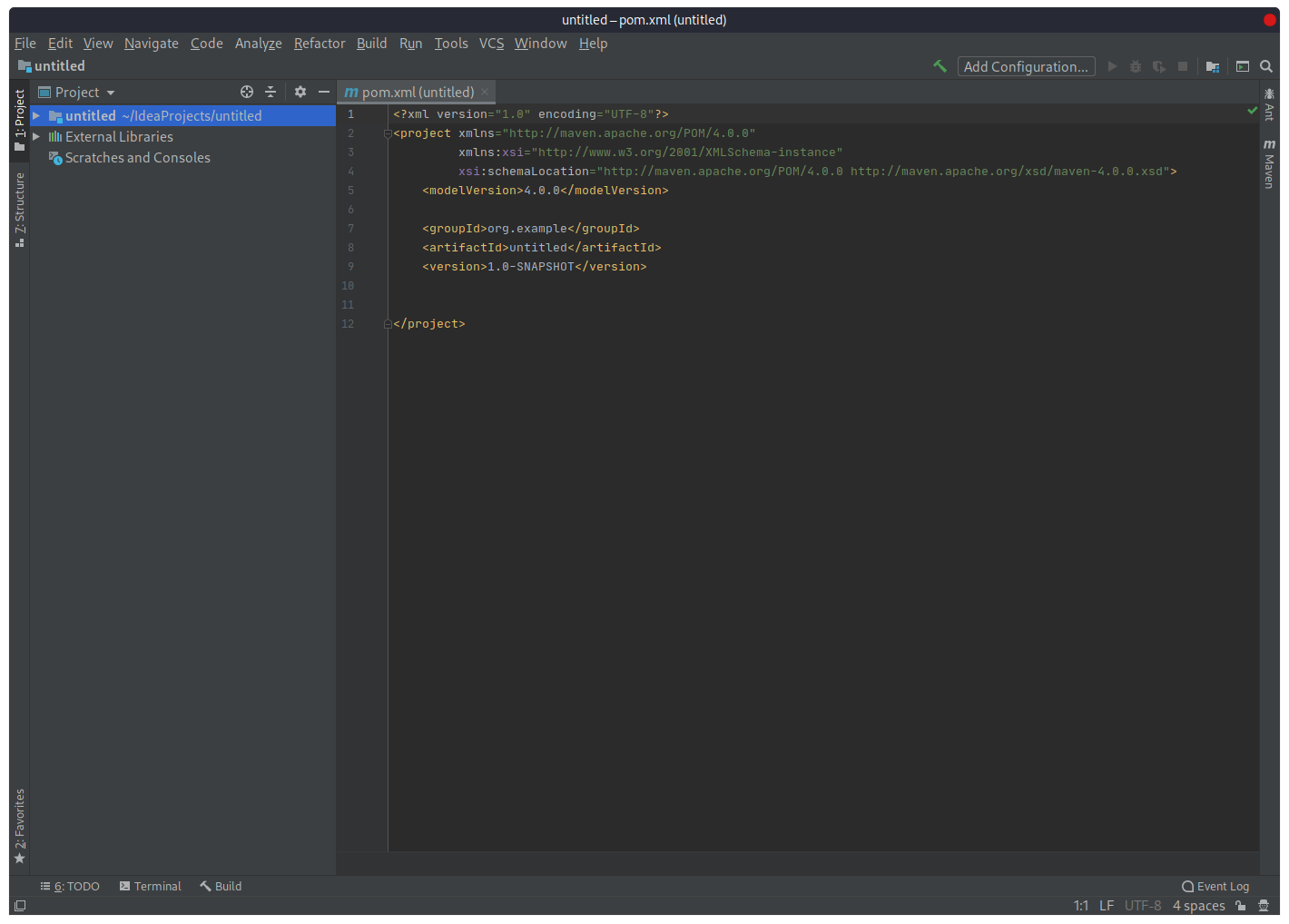
В нем уже появилась информация о проекте, внесенная на предыдущем шаге: Groupid, Artefiactid, Version. Pom.xml — это файл который описывает проект. Pom-файл хранит список всех библиотек (зависимостей), которые используются в проекте.
Для этого автотеста необходимо добавить две библиотеки: Selenium Java и Junit. Перейдем на центральный репозиторий Maven mvnrepository.com, вобьем в строку поиска Selenium Java и зайдем в раздел библиотеки:
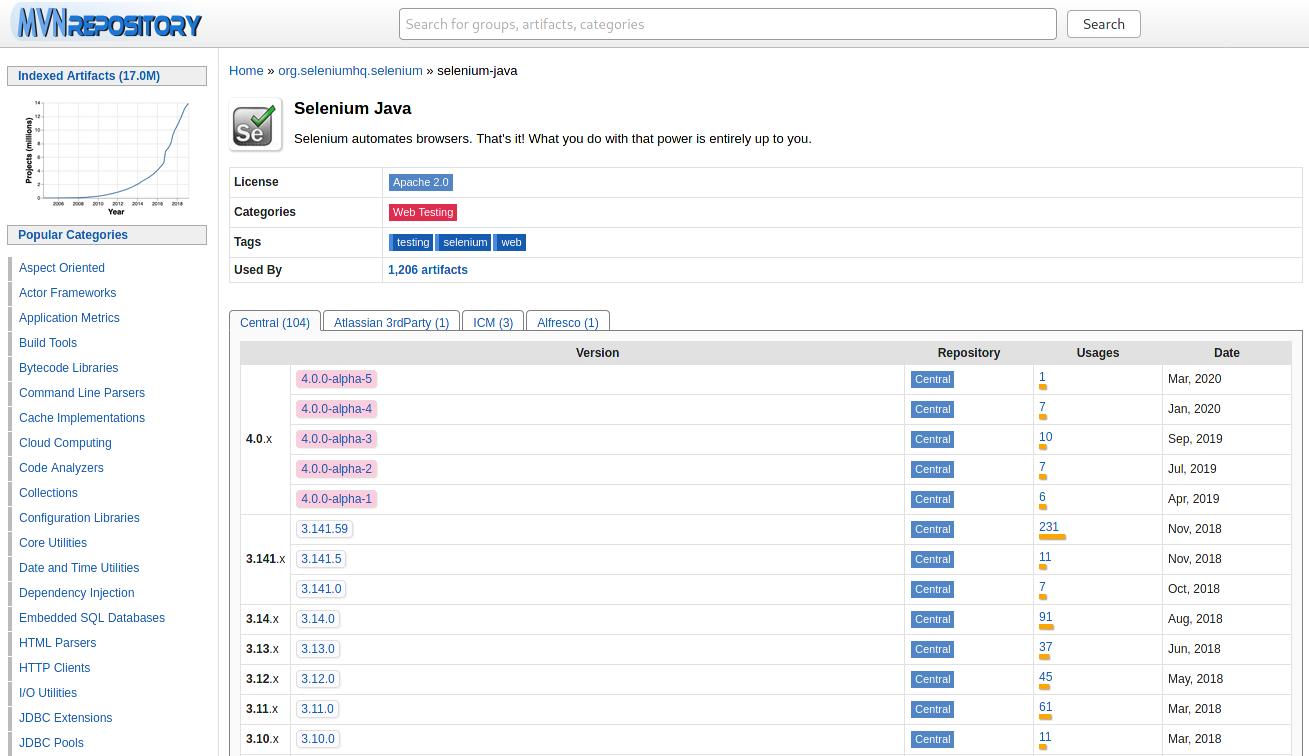
Выберем нужную версию (в примере будет использована версия 3.14.0). Откроется страница:
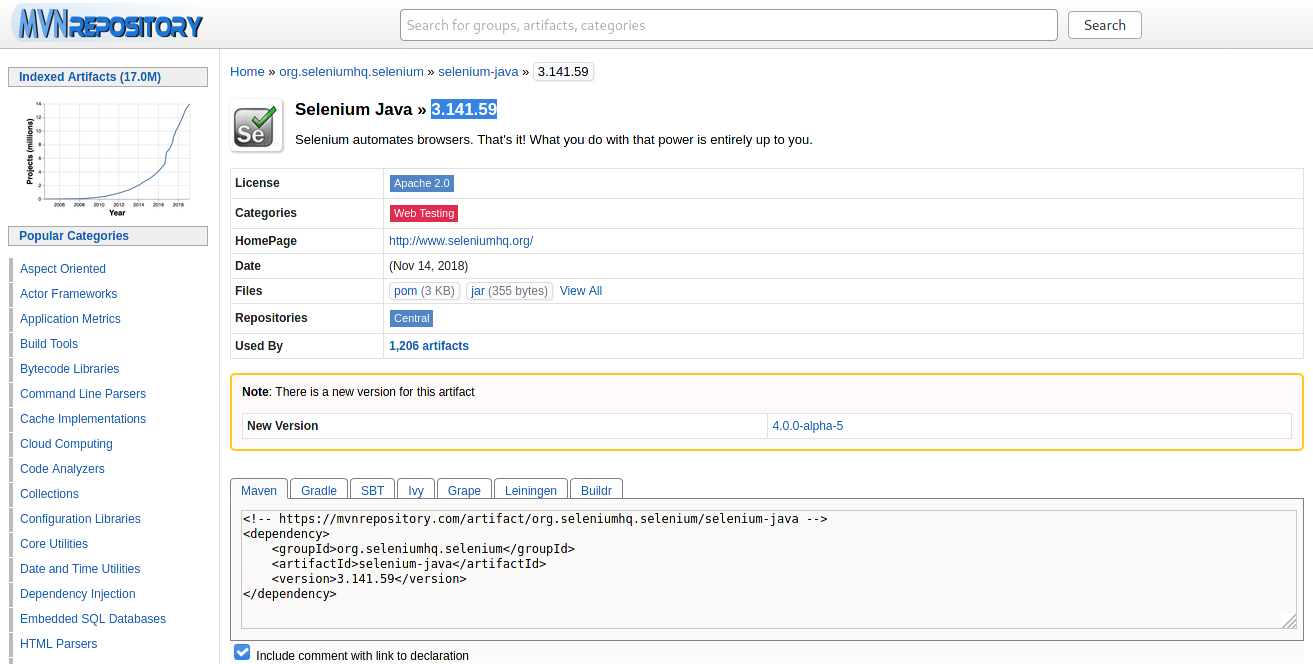
Копируем содержимое блока «Maven» и вставим в файл pom.xml в блок
<dependencies> </dependencies>
Таким образом библиотека будет включена в проект и ее можно будет использовать. Аналогично сделаем с библиотекой Junit (будем использовать версию 4.12).
Итоговый pom-файл:
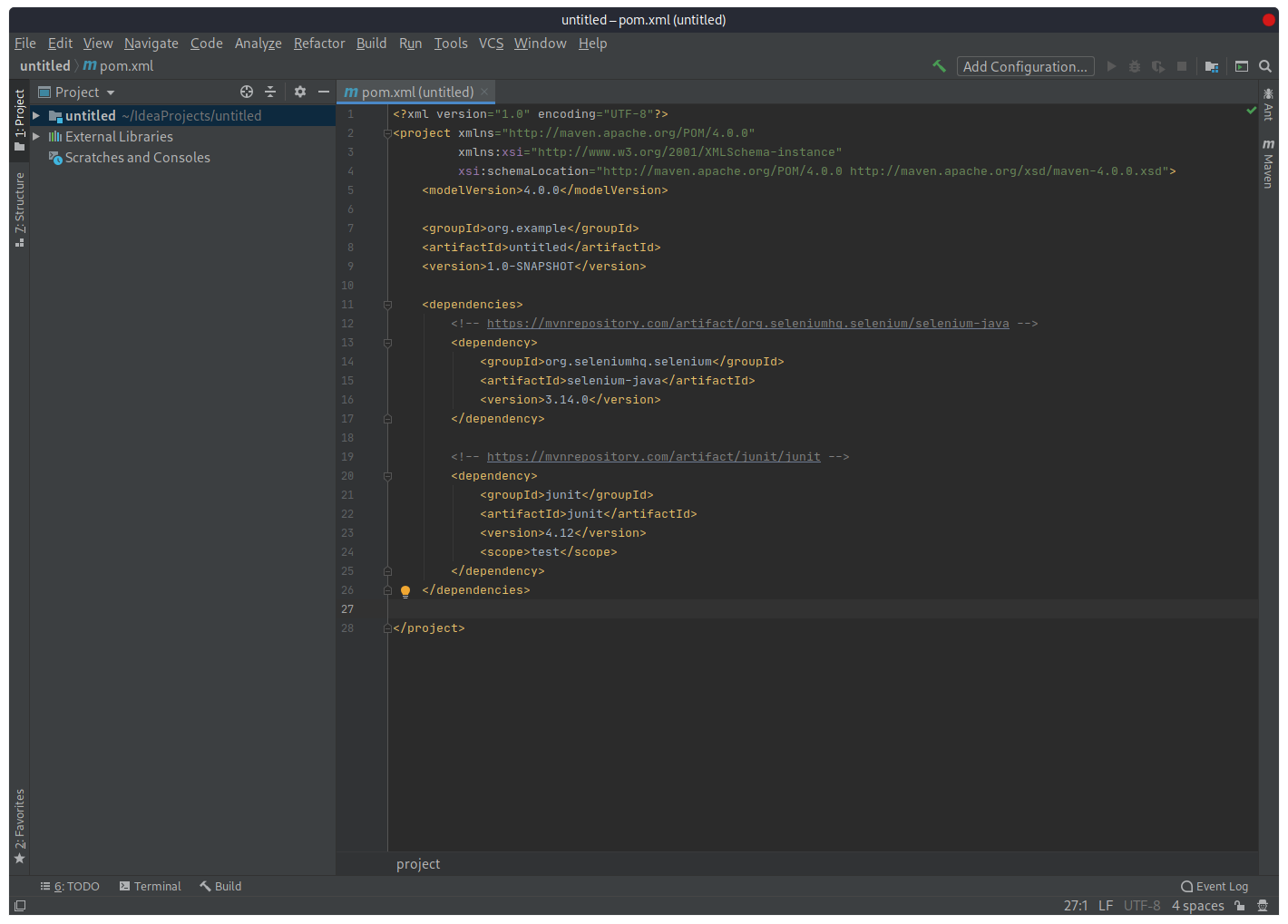
Создание пакета и класса
Раскроем структуру проекта. Директория src содержит в себе две директории: «main» и «test». Для тестов используется, соответственно, директория «test». Откроем директорию «test», кликом правой клавиши мыши по директории «java» выберем пункт «New», а затем пункт «Package». В открывшемся диалоговом окне необходимо ввести название пакета. Имя базового пакета должно носить тоже имя, что и Groupid — «org.example».
Следующий шаг — создание класса Java, в котором пишется код автотеста. Кликом правой клавиши мыши по названию пакета выберем пункт «New», а затем пункт «Java Class».
В открывшемся диалоговом окне необходимо ввести имя Java класса, например, LoginTest (название класса в Java всегда должно начинаться с большой буквы). В IDE откроется окно тестового класса:
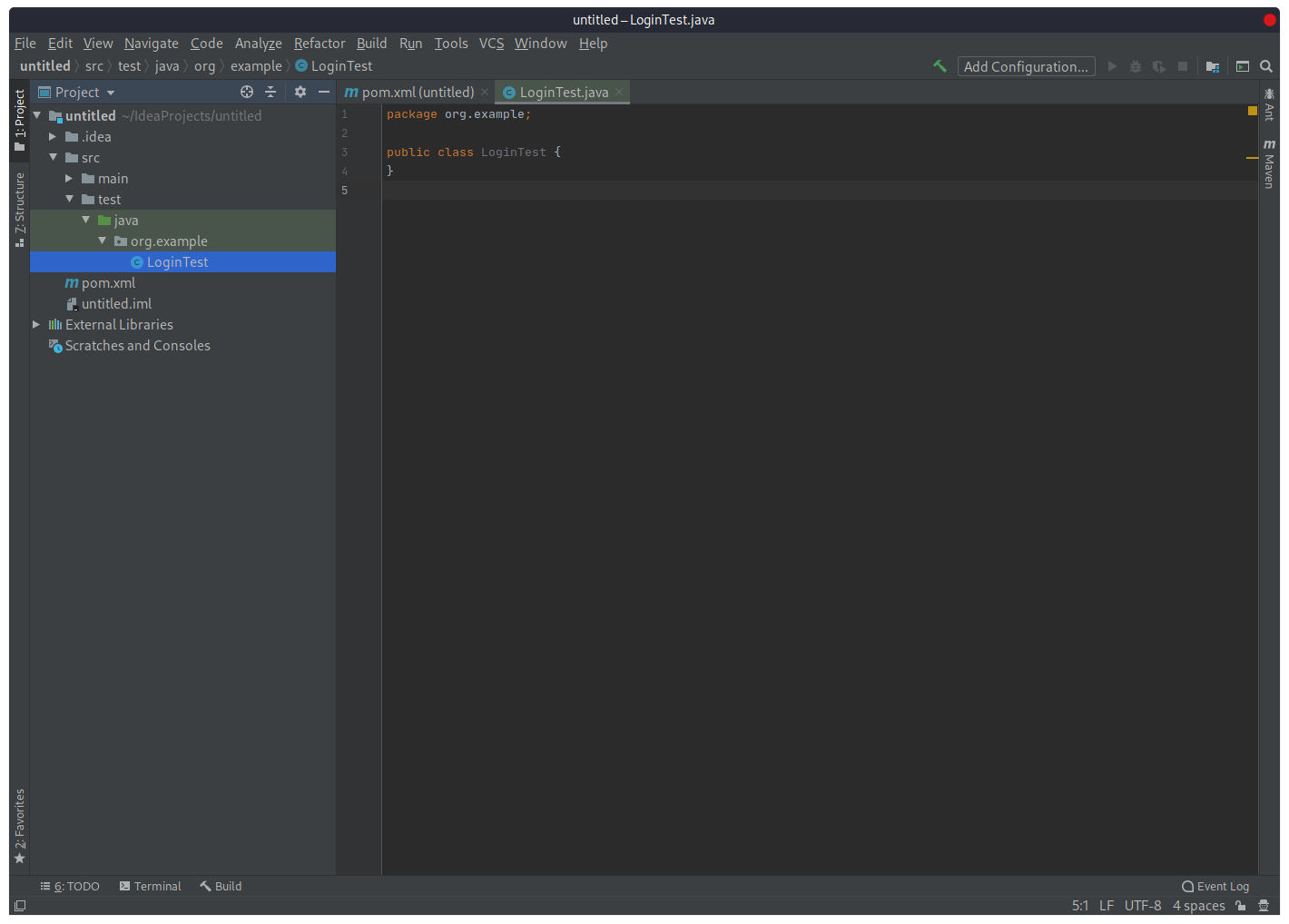
Настройка IDE
Прежде чем начать, необходимо настроить IDE. Кликом правой клавиши мыши по названию проекта выберем пункт «Open Module Settings». В открывшемся окне во вкладке «Sources» поле «Language level» по умолчанию имеет значение 5. Необходимо изменить значение поля на 8 (для использования всех возможностей, присутствующих в этой версии Java) и сохранить изменения:
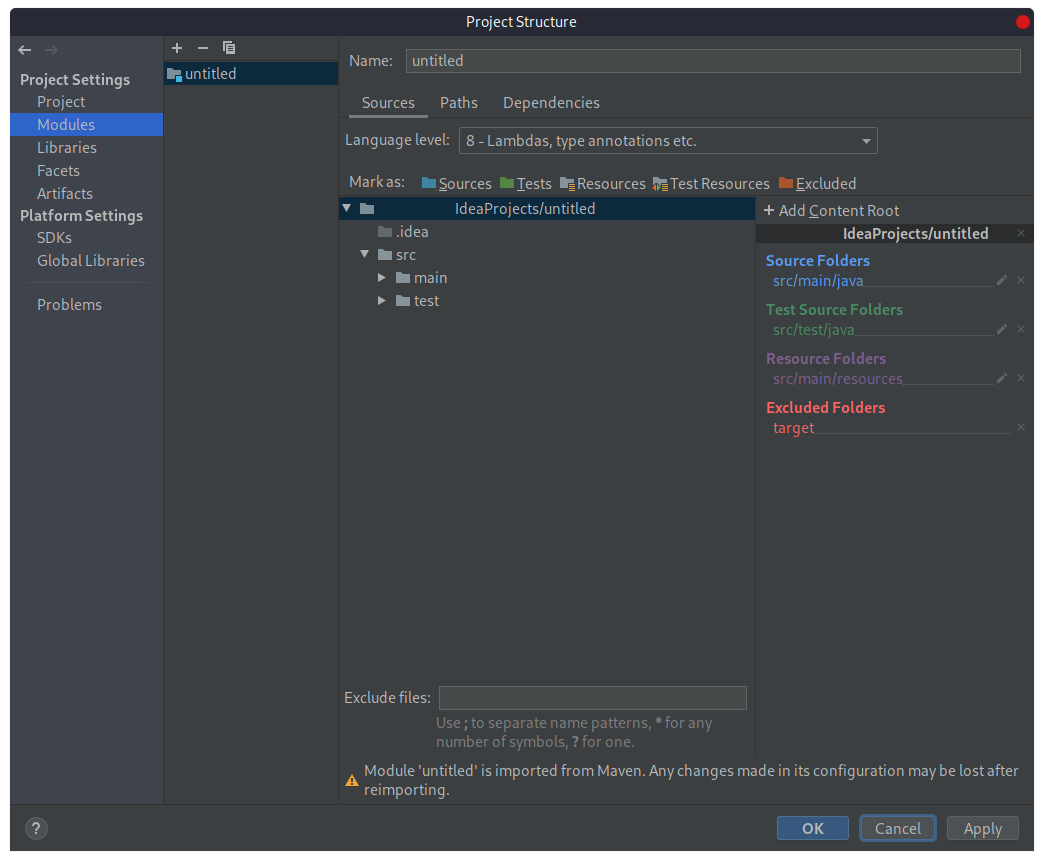
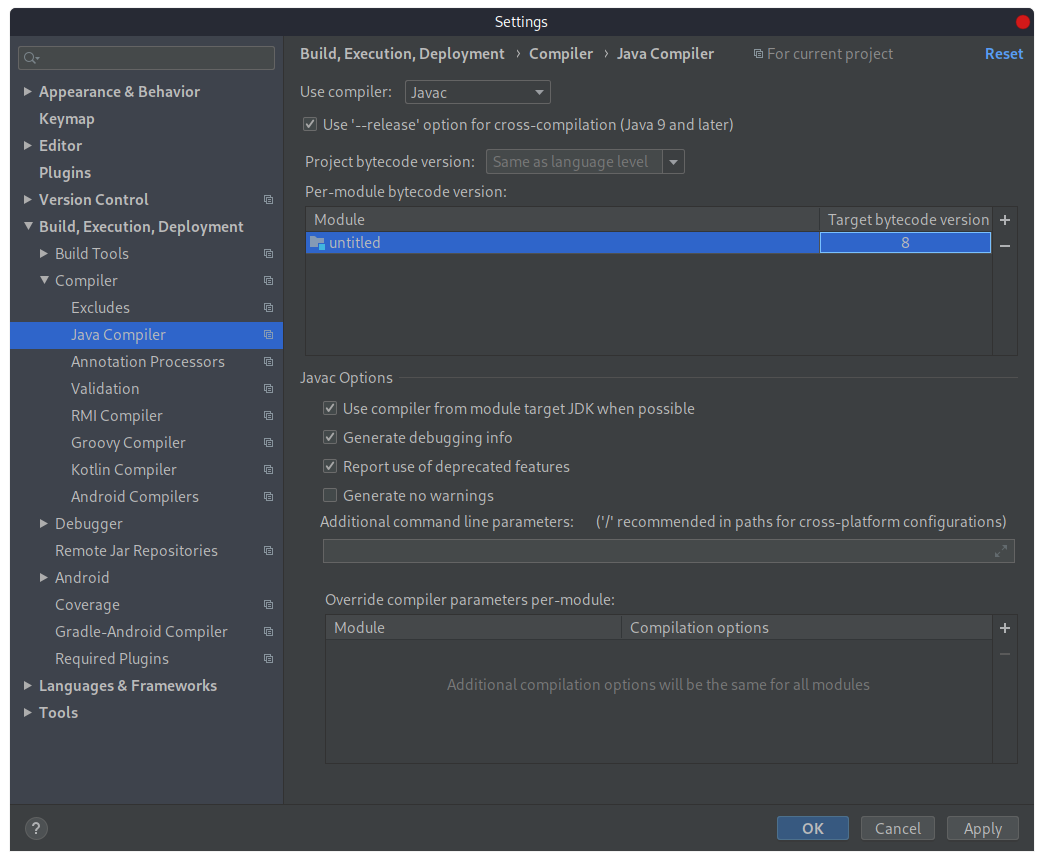
Далее необходимо изменить версию компилятора Java: нажмем меню «File», а затем выберем пункт Settings.
В открывшемся перейдем «Build, Execution, Deployment» -> «Compiler» -> «Java Compiler». По умолчанию установлена версия 1.5. Изменим версию на 8 и сохраним изменения:
Test Suite
Описание:
- Пользователь открывает страницу аутентификации;
- Пользователь производит ввод валидных логина и пароля;
- Пользователь удостоверяется в успешной аутентификации — об этом свидетельствует имя пользователя в верхнем правом углу окна;
- Пользователь осуществляет выход из аккаунта путем нажатия на имя пользователя в верхнем правом углу окна с последующим нажатием на кнопку «Выйти…».
Тест считается успешно пройденным в случае, когда пользователю удалось выполнить все вышеперечисленные пункты.
Для примера будет использоваться аккаунт Яндекс (учетная запись заранее создана вручную).
Первый метод
В классе LoginTest будет описана логика теста. Создадим в этом классе метод «setup()», в котором будут описаны предварительные настройки. Итак, для запуска браузера необходимо создать объект драйвера:
WebDriver driver = new ChromeDriver();
Перед созданием объекта WebDriver следует установить зависимость, определяющую путь к chomedriver (в ОС семейства Windows дополнительно необходимо указывать расширение .exe):
System.setProperty("webdriver.chrome.driver", "/usr/bin/chromedriver");
Чтобы ход теста отображался в полностью открытом окне, необходимо сказать об этом драйверу:
driver.manage().window().maximaze();
Случается, что элементы на страницах доступны не сразу, и необходимо дождаться появления элемента. Для этого существуют ожидания. Они бывают двух видов: явные и неявные. В примере будет использовано неявное ожидание Implicitly Wait, которое задается вначале теста и будет работать при каждом вызове метода поиска элемента:
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
Таким образом, если элемент не найден, то драйвер будет ждать его появления в течении заданного времени (10 секунд) и шагом в 500 мс. Как только элемент будет найден, драйвер продолжит работу, однако, в противном случае тест упадем по истечению времени.
Для передачи драйверу адреса страницы используется команда:
driver.get("https://passport.yandex.ru/auth")
Выносим настройки
Для удобства вынесем название страницы в отдельный файл (а чуть позже и некоторые другие параметры).
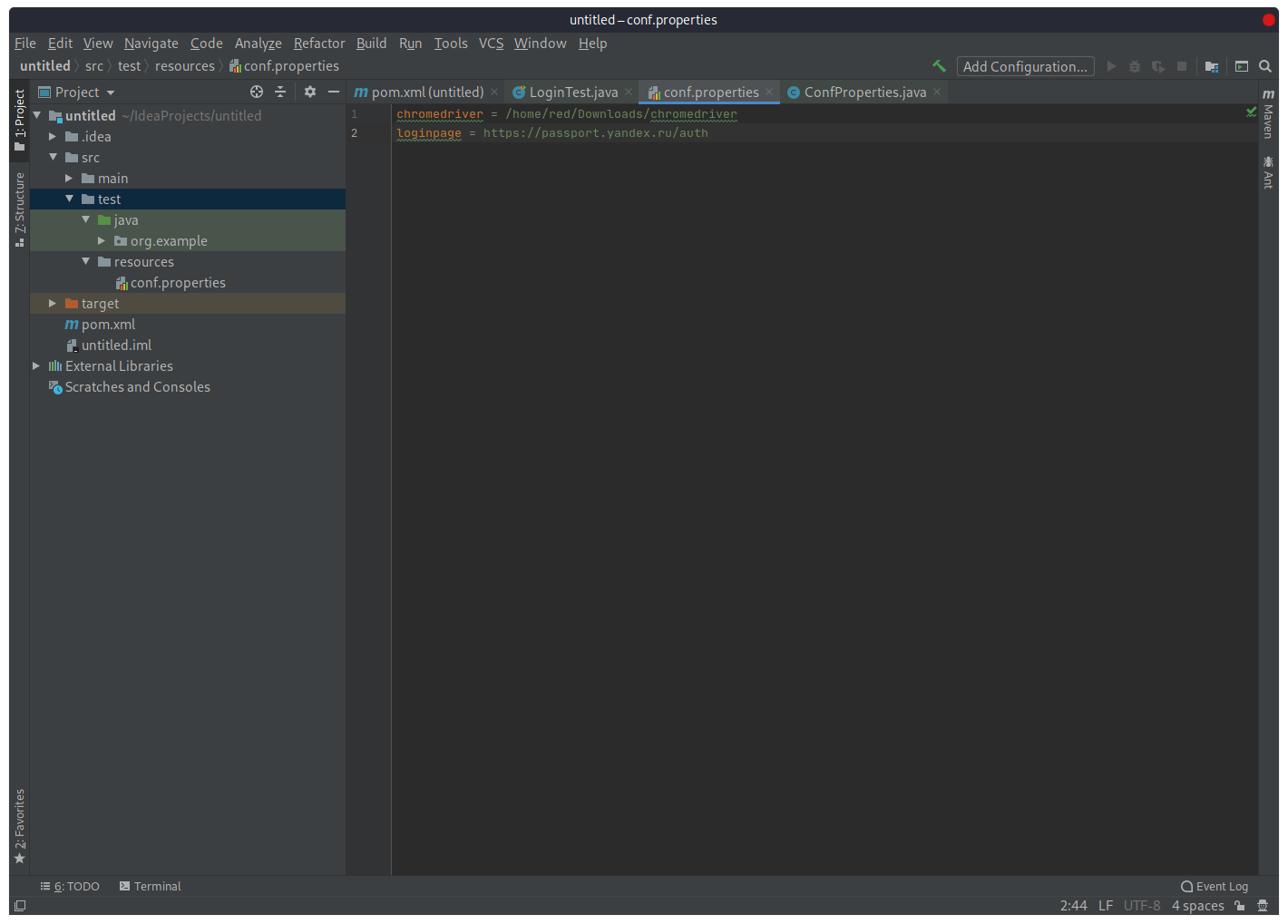
Создадим в каталоге «test» еще один каталог с названием «resources», а в нем обычный файл «conf.properties», в который поместим переменную:
loginpage = https://passport.yandex.ru/auth
а также внесем сюда путь до драйвера
chromedriver = /usr/bin/chromedriver
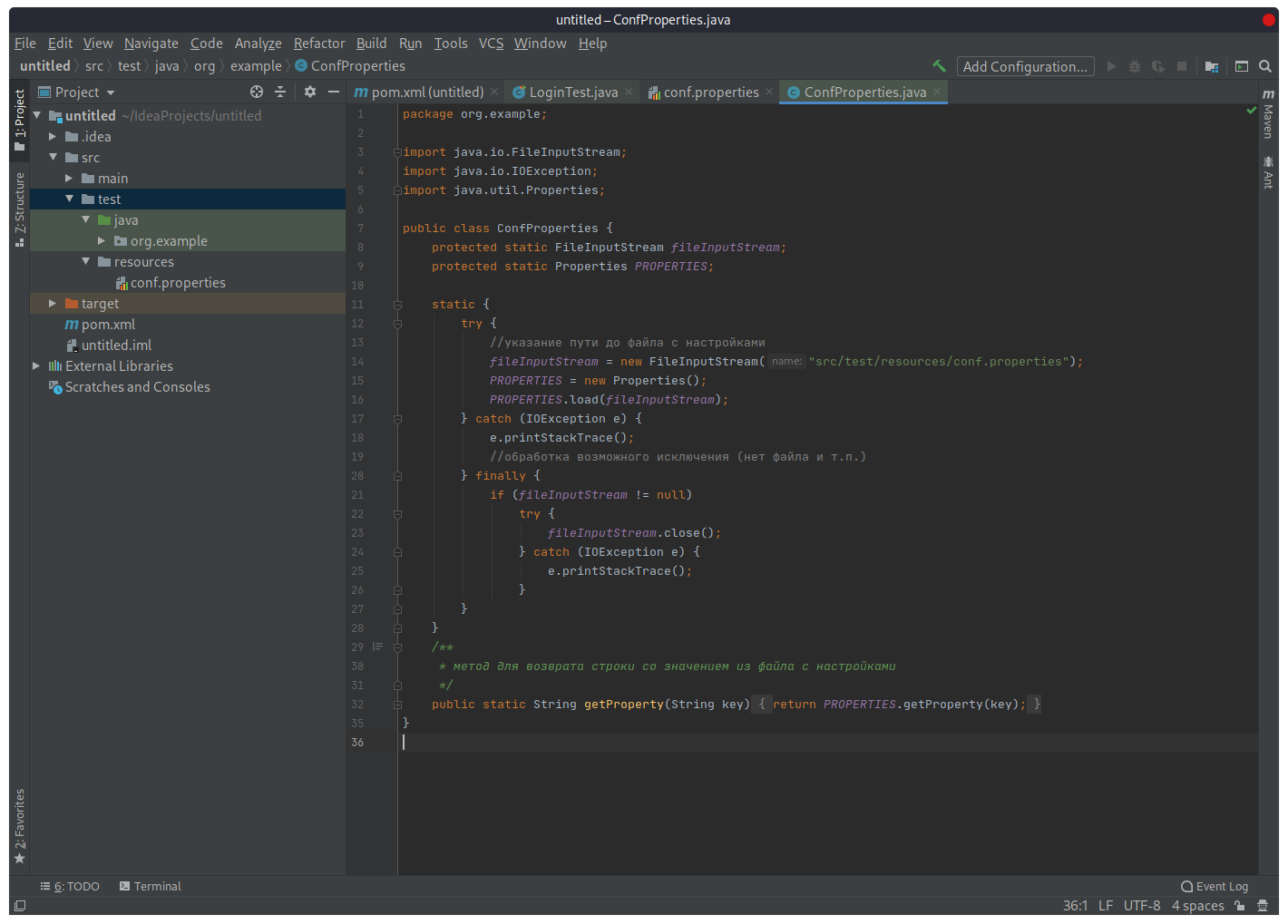
В пакете «org.example» создадим еще один класс «ConfProperties», который будет читать записанные в файл «conf.properties» значения:
package org.example;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Properties;
public class ConfProperties {
protected static FileInputStream fileInputStream;
protected static Properties PROPERTIES;
static {
try {
//указание пути до файла с настройками
fileInputStream = new FileInputStream("src/test/resources/conf.properties");
PROPERTIES = new Properties();
PROPERTIES.load(fileInputStream);
} catch (IOException e) {
e.printStackTrace();
//обработка возможного исключения (нет файла и т.п.)
} finally {
if (fileInputStream != null)
try {
fileInputStream.close();
} catch (IOException e) {
e.printStackTrace(); } } }
/**
* метод для возврата строки со значением из файла с настройками
*/
public static String getProperty(String key) {
return PROPERTIES.getProperty(key); } }
Обзор первого метода
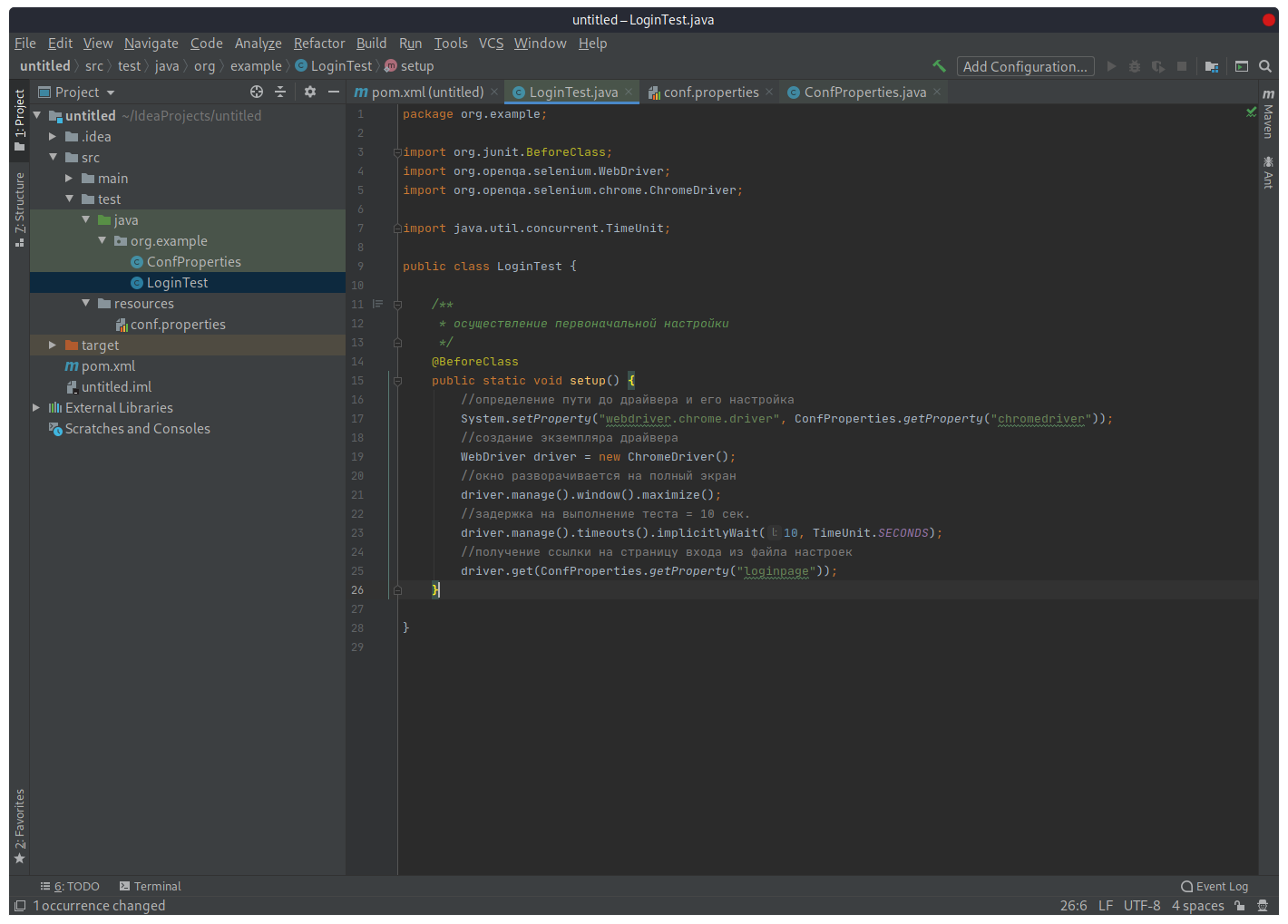
Метод «setup()» пометим аннотацией Junit «@BeforeClass», которая указывает на то, что метод будет выполняться один раз до выполнения всех тестов в классе. Тестовые методы в Junit помечаются аннотацией Test.
package org.example;
import org.junit.BeforeClass;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.concurrent.TimeUnit;
public class LoginTest {
/**
* осуществление первоначальной настройки
*/
@BeforeClass
public static void setup() {
//определение пути до драйвера и его настройка
System.setProperty("webdriver.chrome.driver", ConfProperties.getProperty("chromedriver"));
//создание экземпляра драйвера
WebDriver driver = new ChromeDriver();
//окно разворачивается на полный экран
driver.manage().window().maximize();
//задержка на выполнение теста = 10 сек.
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
//получение ссылки на страницу входа из файла настроек
driver.get(ConfProperties.getProperty("loginpage")); } }
Page Object
При использовании Page Object элементы страниц, а также методы непосредственного взаимодействия с ними, выносятся в отдельный класс.
Создадим в пакете «org.example» класс LoginPage, который будет содержать локацию элементов страницы логина и методы для взаимодействия с этими элементами.
Откроем страницу авторизации в сервисах Яндекс (https://passport.yandex.ru/auth) в браузере Chrome. Для определения локаторов элементов страницы, с которыми будет взаимодействовать автотест, воспользуемся инструментами разработчика. Кликом правой кнопки мыши вызовем меню «Просмотреть код». В появившейся панели нажмем на значок курсора (левый верхний угол панели разработчика) и наведем курсор на интересующий нас элемент — поле ввода логина.
В результате мы увидим этот элемент среди множества других. Теперь мы можем скопировать его локацию. Для этого кликаем правой кнопкой мыши по выделенному в панели разработчика элементу, выбираем меню «Copy» -> «Copy XPath».
//*[@id="root"]/div/div/div[2]/div/div/div[3]/div[2]/div/div/div[1]/form/div[1]/div[1]/label
Для локации элементов в Page Object используется аннотация @FindBy.
Напишем следующий код:
@FindBy(xpath = "//*[@id="root"]/div/div/div[2]/div/div/div[3]/div[2]/div/div/div[1]/form/div[1]/div[1]/label")
private WebElement loginField;
Таким образом мы нашли элемент на страницу и назвали его loginField (элемент доступен только внутри класса LoginPage, т.к. является приватным).
Однако, такой длинный и страшный xpath использовать не рекомендуется (рекомендую к прочтению статью «Не так страшен xpath как его незнание». Если присмотреться, то можно увидеть, что поле ввода логина имеет уникальный id:
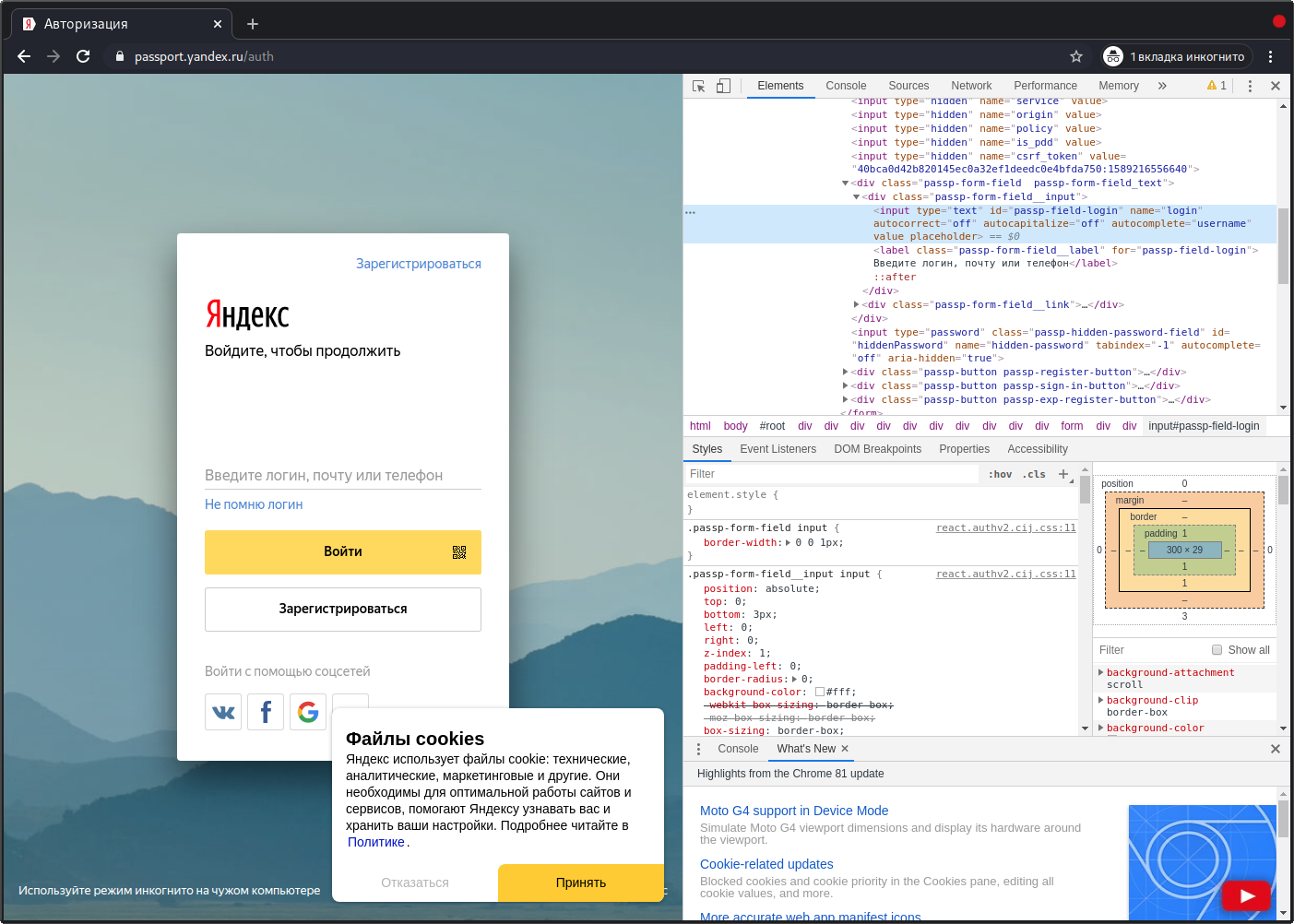
Воспользуемся этим и изменим поиск элемента по xpath:
@FindBy(xpath = "//*[contains(@id, 'passp-field-login')]")
Теперь вероятность того, что поле ввода пароля будет определено верно даже в случае изменения местоположения элемента на странице, возросла.
Аналогично изучим следующие элементы и получим их локаторы.
Кнопка «Войти»:
@FindBy(xpath = "//*[contains(text(), 'Войти')]")
private WebElement loginBtn;
Поле ввода пароля:
@FindBy(xpath = "//*[contains(@id, 'passp-field-passwd')]")
private WebElement passwdField;
А теперь напишем методы для взаимодействия с элементами.
Метод ввода логина:
public void inputLogin(String login) {
loginField.sendKeys(login); }
Метод ввода пароля:
public void inputPasswd(String passwd) {
passwdField.sendKeys(passwd); }
Метод нажатия кнопки входа:
public void clickLoginBtn() {
loginBtn.click(); }
Для того, чтобы аннотация @FindBy заработала, необходимо использовать класс PageFactory. Для этого создадим конструктор и передадим ему в качестве параметра объект Webdriver:
public WebDriver driver;
public LoginPage(WebDriver driver) {
PageFactory.initElements(driver, this);
this.driver = driver; }
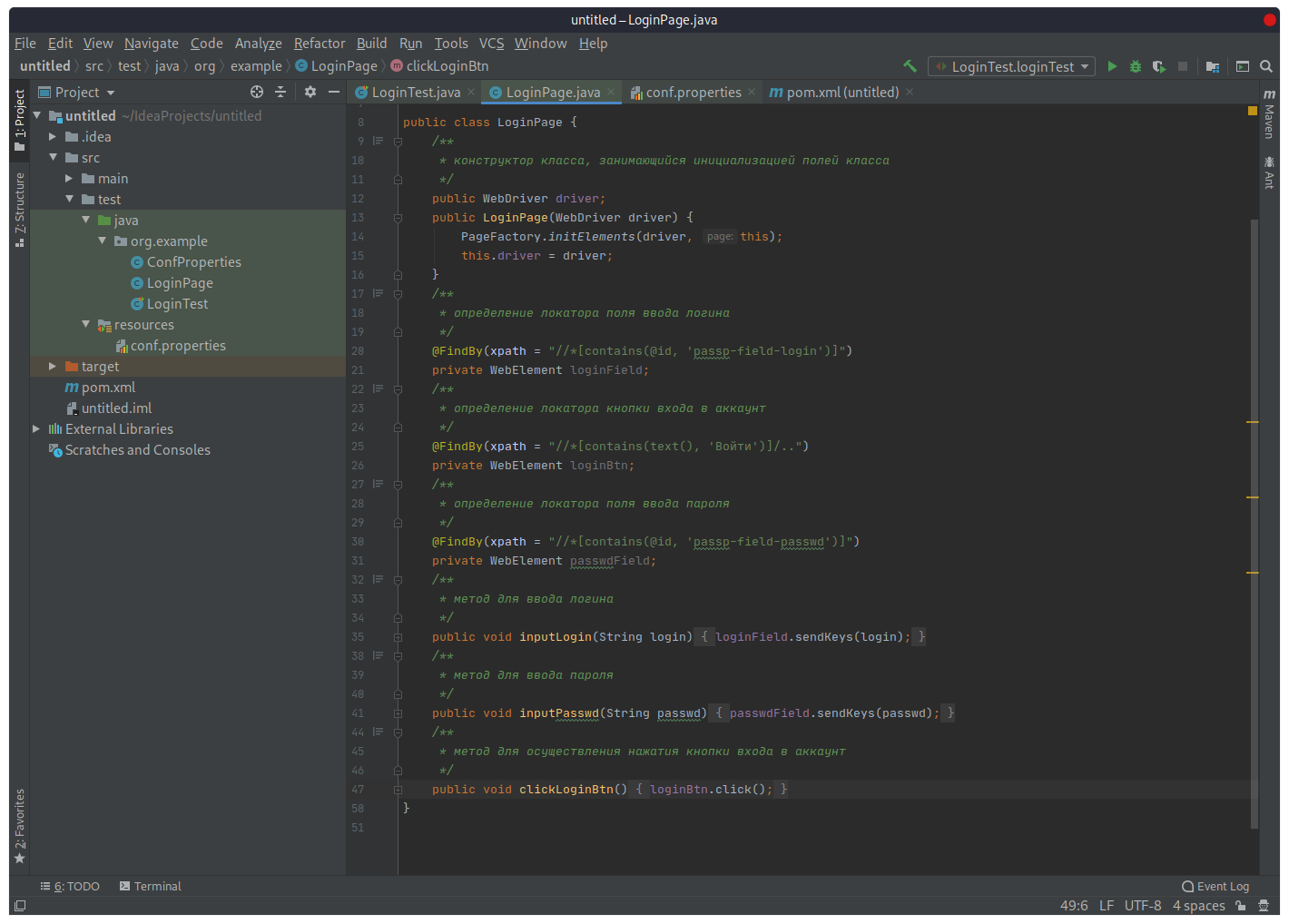
package org.example;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.support.FindBy;
import org.openqa.selenium.support.PageFactory;
public class LoginPage {
/**
* конструктор класса, занимающийся инициализацией полей класса
*/
public WebDriver driver;
public LoginPage(WebDriver driver) {
PageFactory.initElements(driver, this);
this.driver = driver; }
/**
* определение локатора поля ввода логина
*/
@FindBy(xpath = "//*[contains(@id, 'passp-field-login')]")
private WebElement loginField;
/**
* определение локатора кнопки входа в аккаунт
*/
@FindBy(xpath = "//*[contains(text(), 'Войти')]/..")
private WebElement loginBtn;
/**
* определение локатора поля ввода пароля
*/
@FindBy(xpath = "//*[contains(@id, 'passp-field-passwd')]")
private WebElement passwdField;
/**
* метод для ввода логина
*/
public void inputLogin(String login) {
loginField.sendKeys(login); }
/**
* метод для ввода пароля
*/
public void inputPasswd(String passwd) {
passwdField.sendKeys(passwd); }
/**
* метод для осуществления нажатия кнопки входа в аккаунт
*/
public void clickLoginBtn() {
loginBtn.click(); } }
После авторизации мы попадаем на страницу пользователя. Т.к. это уже другая страница, в соответствии с идеологией Page Object нам понадобится отдельный класс для ее описания. Создадим класс ProfilePage, в котором определим локаторы для имени пользователя (как показателя успешного входа в учетную запись), а также кнопки выхода из аккаунта. Помимо этого, напишем методы, которые будут получать имя пользователя и нажимать на кнопку выхода.
Итого, страница ввода логина будет иметь следующий вид:
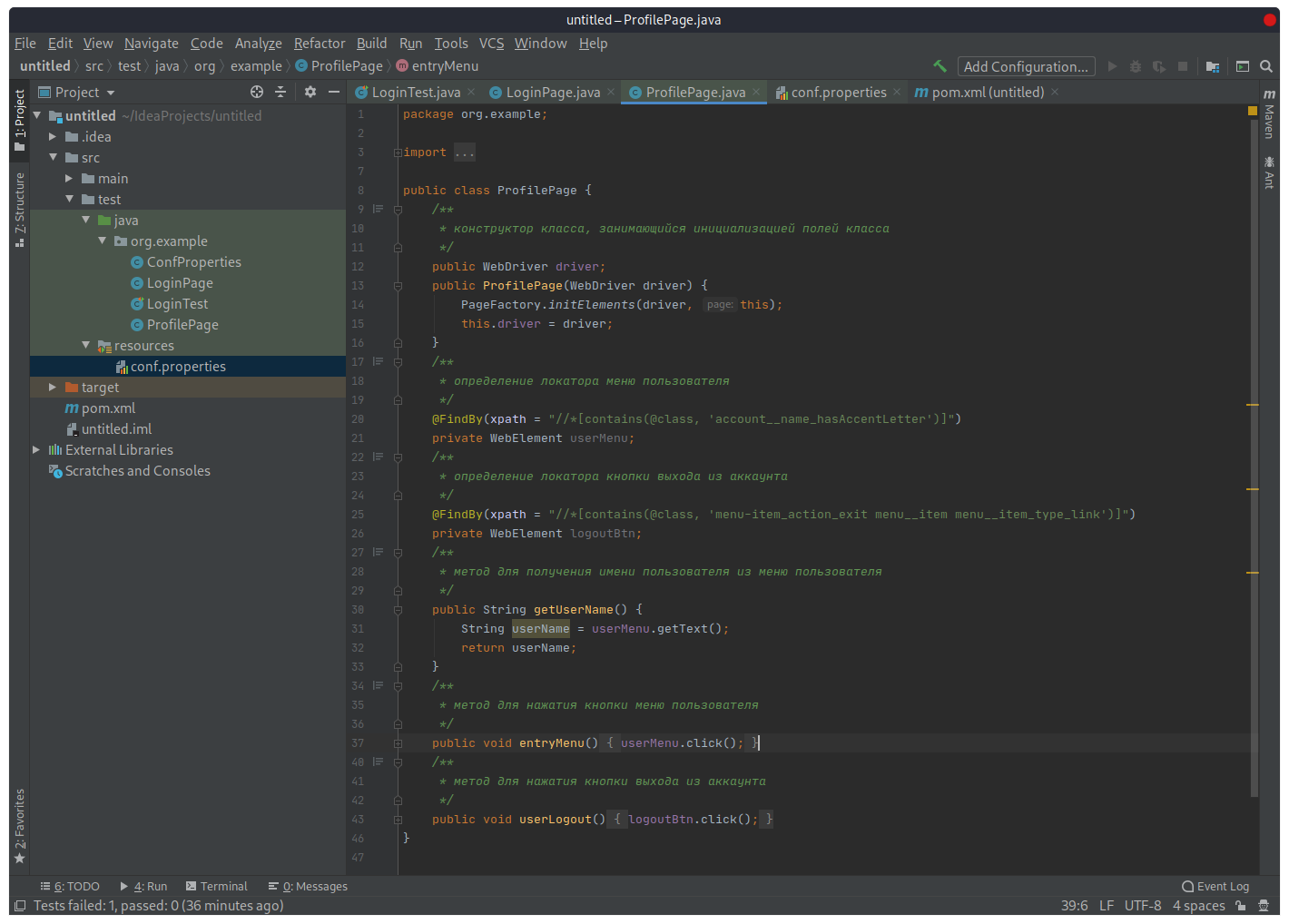
package org.example;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.support.FindBy;
import org.openqa.selenium.support.PageFactory;
public class ProfilePage {
/**
* конструктор класса, занимающийся инициализацией полей класса
*/
public WebDriver driver;
public ProfilePage(WebDriver driver) {
PageFactory.initElements(driver, this);
this.driver = driver; }
/**
* определение локатора меню пользователя
*/
@FindBy(xpath = "//*[contains(@class, 'account__name_hasAccentLetter')]")
private WebElement userMenu;
/**
* определение локатора кнопки выхода из аккаунта
*/
@FindBy(xpath = "//*[contains(@class, 'menu-item_action_exit menu__item menu__item_type_link')]")
private WebElement logoutBtn;
/**
* метод для получения имени пользователя из меню пользователя
*/
public String getUserName() {
String userName = userMenu.getText();
return userName; }
/**
* метод для нажатия кнопки меню пользователя
*/
public void entryMenu() {
userMenu.click(); }
/**
* метод для нажатия кнопки выхода из аккаунта
*/
public void userLogout() {
logoutBtn.click(); } }
Интересный момент: в метод getUserName() пришлось добавить еще одно ожидание, т.к. страница «тяжелая» и загружалась довольно медленно. В итоге тест падал, потому что метод не мог получить имя пользователя. Метод getUserName() с ожиданием:
public String getUserName() {
WebDriverWait wait = new WebDriverWait(driver, 10);
wait.until(ExpectedConditions.visibilityOfElementLocated(By.xpath("//*[contains(@class, 'account__name_hasAccentLetter')]")));
String userName = userMenu.getText();
return userName; }
Вернемся к классу LoginTest и добавим в него созданные ранее классы-страницы путем объявления статических переменных с соответствующими именами:
public static LoginPage loginPage;
public static ProfilePage profilePage;
Сюда же вынесем переменную для драйвера
public static WebDriver driver;
В аннотации @BeforeClass создаем экземпляры классов созданных ранее страниц и присвоим ссылки на них. Создание экземпляра происходит с помощью оператора new. В качестве параметра указываем созданный перед этим объект driver, который передается конструкторам класса, созданным ранее:
loginPage = new LoginPage(driver);
profilePage = new ProfilePage(driver);
А создание экземпляра драйвера приведем к следующему виду (т.к. он объявлен в качестве переменной):
driver = new ChromeDriver();
Тест
Теперь можно перейти непосредственно к написанию логики теста. Создадим метод loginTest() и пометим его соответствующей аннотацией:
@Test
public void loginTest() {
//значение login/password берутся из файла настроек по аналогии с chromedriver
//и loginpage
//вводим логин
loginPage.inputLogin(ConfProperties.getProperty("login"));
//нажимаем кнопку входа
loginPage.clickLoginBtn();
//вводим пароль
loginPage.inputPasswd(ConfProperties.getProperty("password"));
//нажимаем кнопку входа
loginPage.clickLoginBtn();
//получаем отображаемый логин
String user = profilePage.getUserName();
//и сравниваем его с логином из файла настроек
Assert.assertEquals(ConfProperties.getProperty("login"), user); }
Осталось лишь корректно все завершить. Создадим финальный метод и пометим его аннотацией @AfterClass (методы помеченные этой аннотацией выполняются один раз, после завершения всех тестовых методов класса).
В этом методе осуществляется вход в меню пользователя и нажатие кнопки «Выйти», чтобы разлогиниться.
@AfterClass
public static void tearDown() {
profilePage.entryMenu();
profilePage.userLogout();
driver.quit(); }
Последняя строка нужна для закрытия окна браузера.
Обзор теста
Итого, имеем:
package org.example;
import org.junit.AfterClass;
import org.junit.Assert;
import org.junit.BeforeClass;
import org.junit.Test;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.concurrent.TimeUnit;
public class LoginTest {
public static LoginPage loginPage;
public static ProfilePage profilePage;
public static WebDriver driver;
/**
* осуществление первоначальной настройки
*/
@BeforeClass
public static void setup() {
//определение пути до драйвера и его настройка
System.setProperty("webdriver.chrome.driver", ConfProperties.getProperty("chromedriver"));
//создание экземпляра драйвера
driver = new ChromeDriver();
loginPage = new LoginPage(driver);
profilePage = new ProfilePage(driver);
//окно разворачивается на полный экран
driver.manage().window().maximize();
//задержка на выполнение теста = 10 сек.
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
//получение ссылки на страницу входа из файла настроек
driver.get(ConfProperties.getProperty("loginpage")); }
/**
* тестовый метод для осуществления аутентификации
*/
@Test
public void loginTest() {
//получение доступа к методам класса LoginPage для взаимодействия с элементами страницы
//значение login/password берутся из файла настроек по аналогии с chromedriver
//и loginpage
//вводим логин
loginPage.inputLogin(ConfProperties.getProperty("login"));
//нажимаем кнопку входа
loginPage.clickLoginBtn();
//вводим пароль
loginPage.inputPasswd(ConfProperties.getProperty("password"));
//нажимаем кнопку входа
loginPage.clickLoginBtn();
//получаем отображаемый логин
String user = profilePage.getUserName();
//и сравниваем его с логином из файла настроек
Assert.assertEquals(ConfProperties.getProperty("login"), user); }
/**
* осуществление выхода из аккаунта с последующим закрытием окна браузера
*/
@AfterClass
public static void tearDown() {
profilePage.entryMenu();
profilePage.userLogout();
driver.quit(); } }
Запуск автотеста
Для запуска автотестов в Intellij Idea имеется несколько способов:
- Alt+Shift+F10;
- Клик правой клавишей мышки по имени тестового класса, после чего в открывшемся меню выбрать Run;
В результате выполнения автотеста, в консоли Idea я вижу, что тестовый метод loginTest() пройден успешно:
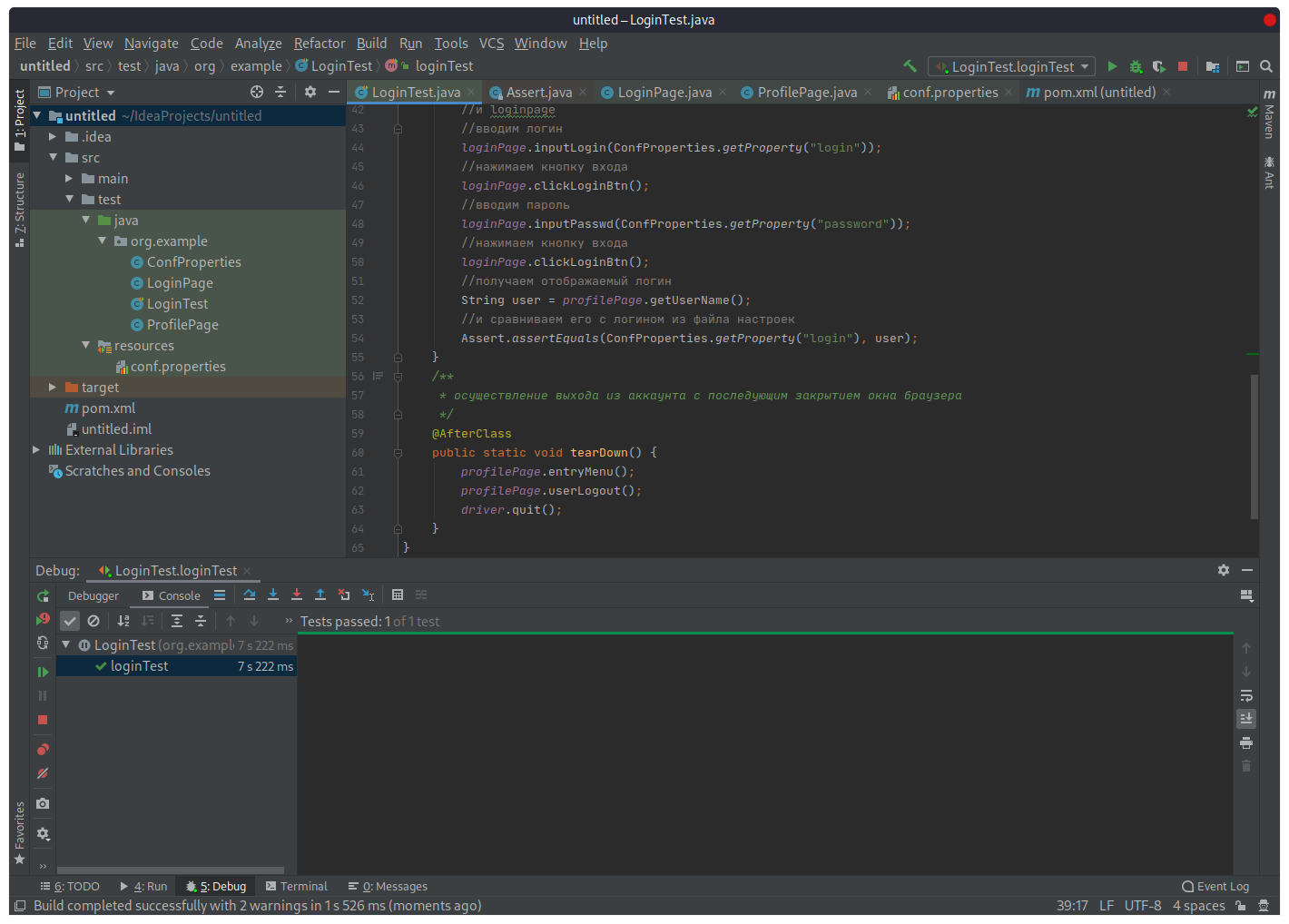
Let's block ads! (Why?)