
NVIDIA на днях продемонстрировала графические процессоры с архитектурой Ampere. Они предназначены для дата-центров, способны выполнять научные расчеты и обрабатывать большие данные.
Презентация прошла необычным образом. Директор компании Дженсен Хуанг вынул cистему DGX A100 из духовки у себя на кухне.
«Это наш самый лучший графический процессор для дата-центров, и он вобрал почти десять лет нашего опыта», — отметил Хуанг позднее уже на пресс-конференции.
У GА100 свыше 54 млрд транзисторов. GPU GA100 содержит 8192 ядра CUDA и 512 тензорных ядер третьего поколения, а также шесть модулей памяти HBM2 с шиной памяти разрядностью в 6144 бита. Выпускается по 7-нм технологии компанией TSMC.
A100 GPU при этом — не графический процессор, а графический ускоритель. Он включает пять модулей HBM2 (40 ГБ) с шиной памяти разрядностью в 5120 бит. 3456 ядер CUDA предназначены для вычислений с плавающей запятой двойной точности (FP64), 6912 ядер — для одинарной (FP32). Тензорных ядер третьего поколения с поддержкой вычислений TF32 — 432.
В новой станции DGX A100 AI восемь таких процессоров объединят в один. Общая производительность системы составит 5 петафлопс. Она будет иметь 320 ГБ видеопамяти с пропускной способностью 12,4 Тбит/с.
В GPU включили TensorFloat-32 — новый режим для обработки математических матриц, также называемый тензорными операциями, который используется в основе AI и некоторых приложений HPC. Комбинация TF32 со структурированной разреженностью позволяет повысить производительность процессоров по сравнению с GPU Volta в 20 раз.
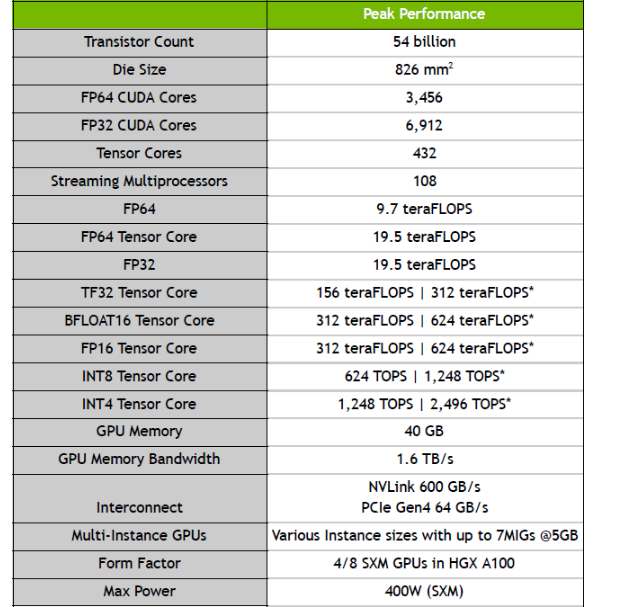
Пиковая производительность ускорителя составляет 19,5 TFLOPS (FP32) или 9,7 TFLOPS (FP64).
GA100 поддерживает интерфейс NVLink третьего поколения. Это дает возможность обмениваться данными с аналогичными GPU со скоростью 600 Гбайт/с. Каждый графический процессор поддерживает 12 каналов NVLink 3.0. С помощью технологии виртуализации MIG можно разделять ресурсы одного графического процессора на семь независимых сегментов.
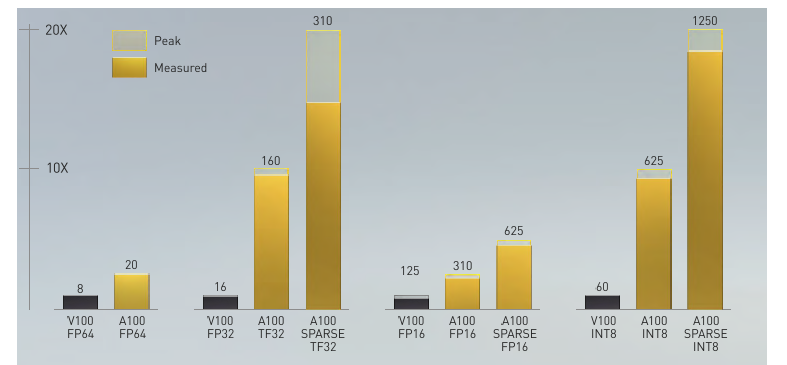
Разработка будет выполнять задачи обучения искусственного интеллекта. Как отметили в NVIDIA, сейчас клиенты использует решение стоимостью $11 млн, которое занимает 25 серверных стоек в дата-центре и потребляет 630 киловатт электроэнергии. Однако на базе Ampere для тех же мощностей понадобится в 11 раз меньше оборудования, стоимость которого составит около $1 млн, всего одна серверная стойка и 28 киловатт электроэнергии. В компании подчеркнули, что использование новой системы ускорит процесс обучения ИИ в 20 раз.
Серийное производство DGX A100 уже стартовало. В числе заказчиков оказалась Аргоннская национальная лаборатория США, которая планирует задействовать систему в исследованиях коронавируса.
Начальная цена вычислительной станции составляет $199 000.
Nvidia показала также кластер из 140 DGX A100 под названием DGX SuperPod. Он имеет производительность 700 петафлопс. Благодаря соединению с серверными адаптерами Mellanox HDR 200Gbps InfiniBand interconnects компании удалось получить собственный суперкомпьютер. Его можно задействовать в исследованиях генома и разработке говорящих ИИ.
При этом никаких официальных данных о сроках доступности игровых видеокарт с архитектурой Ampere нет.
См. также:
Комментариев нет:
Отправить комментарий