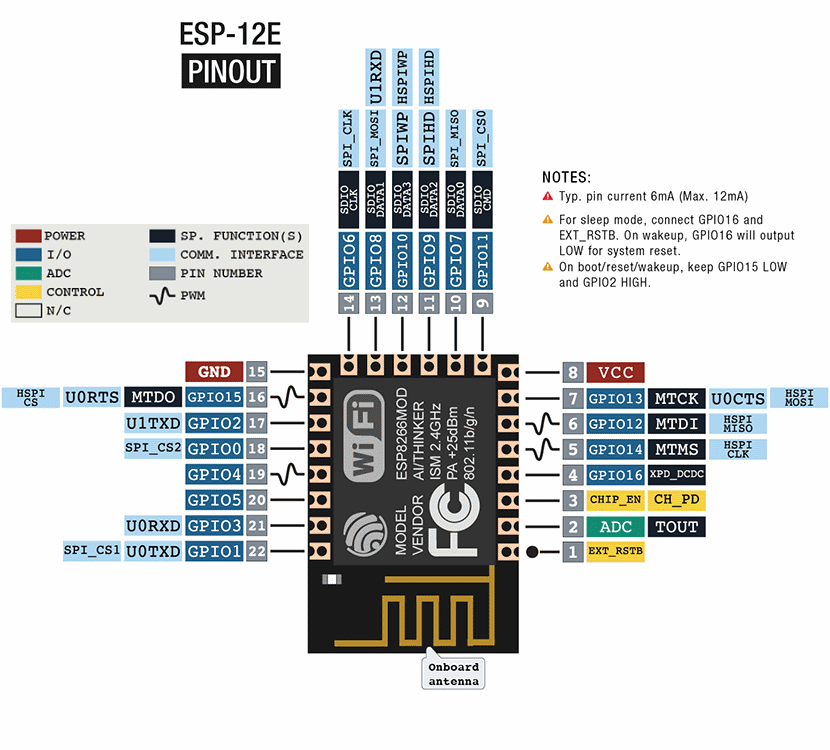
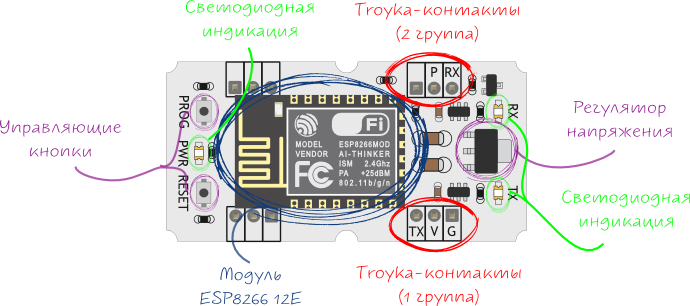
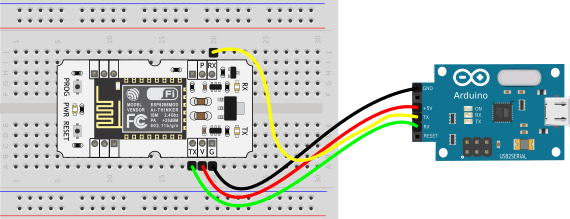
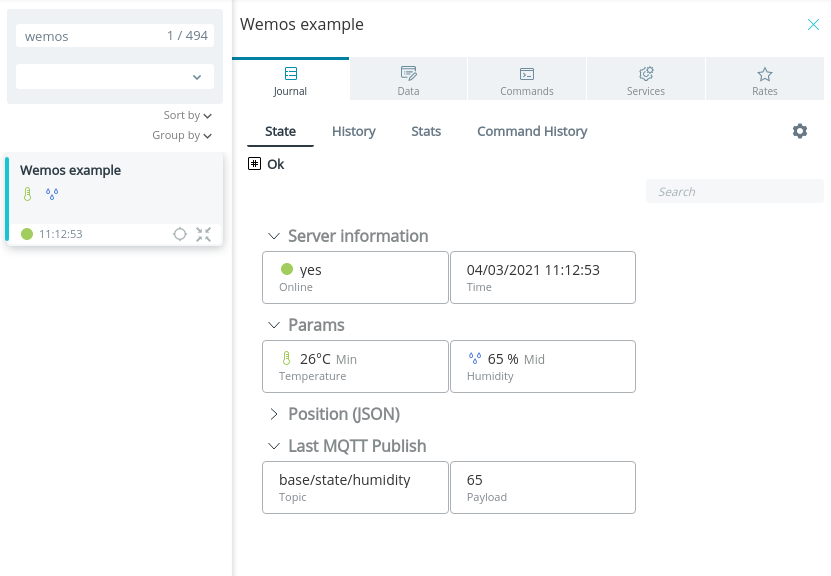
Асинхронное программирование — мощный инструмент. Но экосистема Rust продолжает активно развиваться, и пока язык далёк от идеала. В частности, по этой причине многие считают, что асинхронное программирование в Rust — это боль. Однако некоторые не только критикуют, но и предлагают. Среди таких людей автор данной статьи.
Здесь я расскажу о некоторых ранее предложенных идеях и свяжу их с новыми предложениями. Я проведу некий мысленный эксперимент и постараюсь ответить на вопрос «Что мы могли бы сделать с асинхронным программированием в Rust, если бы нам дали полный карт-бланш?».
Непродуманное внесение изменений в Rust может разрушить его. Поэтому всё нужно делать аккуратно, учитывая плюсы и минусы. Допускаю, что некоторые предложения могут вызвать негативную реакцию. Я отношусь к этому с пониманием и прошу читателя подойти к изучению этого материала максимально непредвзято.
Потоки vs Асинхронность
Писать асинхронный код зачастую сложнее, чем просто использовать потоки. Но с потоками мы не можем получить выигрыш в производительности, так как они слишком прожорливые. В процессе переключения между разными потоками и обмена данными между ними возникает много накладных расходов. Даже поток, который сидит и ничего не делает, использует ценные системные ресурсы. Чаще всего, асинхронный код работает гораздо быстрее. Но не всегда:
Например, этот echo server написан с использованием потоков. Он работает быстрее своей асинхронной версии — для случая, когда количество одновременных подключений не превышает 100.
На мой взгляд, лучший аргумент в пользу асинхронности таков:
- она позволяет эффективно моделировать сложный процесс управления потоком исполнения.
Например, приостановку или отмену операции на лету будет сложно реализовать, не сделав эту операцию асинхронной. Или в случае, когда несколько потоков (одно соединение на один поток) конкурируют за ограниченный ресурс, приходится использовать примитивы синхронизации. Применяя концепцию асинхронности, мы можем добиться более высокой производительности, работая с несколькими соединениями в одном потоке.
Главная проблема с асинхронностью в Rust
Поначалу кому-то может показаться, что писать асинхронный код на Rust легко. Но его мнение изменится после первых трудностей, которые связаны с подводными камнями, не описанными в документации. Энтузиасты
пытаются сами вести учёт и предлагать решения. Копать нужно сразу в нескольких местах, но на мой взгляд, самая большая проблема с асинхронностью в Rust связана с нарушением принципа наименьшего удивления.
Если назначение элемента или сочетания неясно, то его поведение должно быть наиболее ожидаемым. Код должен вести себя так, как ожидает программист.
В этой статье я буду много раз приводить пример с неким Аланом, который начал изучать Rust и сталкивается с первыми сложностями.
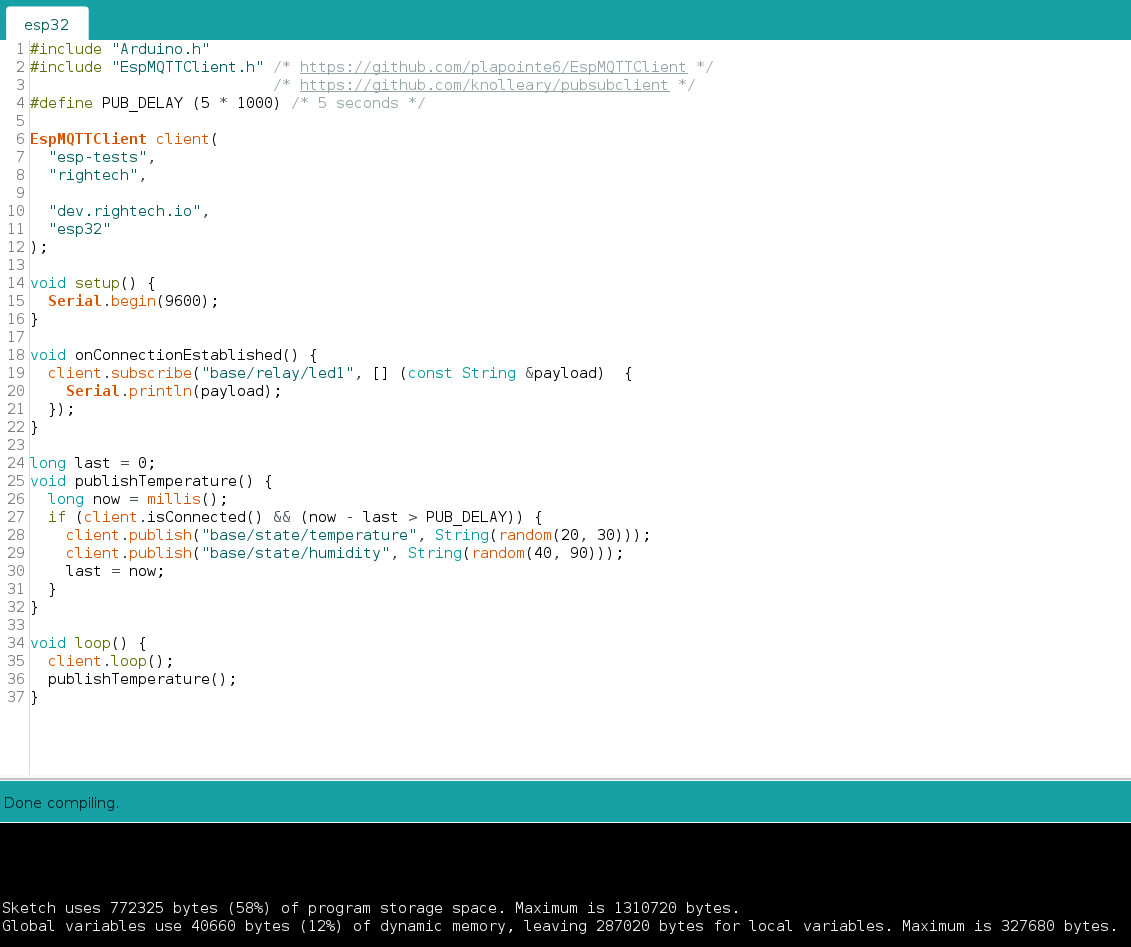
Итак, Алан прочитал книгу по Rust и доки Tokio. Он хочет написать свой чат-сервер. Алан выбирает простой линейный протокол и для шифрования строк использует префиксный код. Его функция парсинга строк выглядит так:
async fn parse_line(socket: &TcpStream) -> Result<String, Error> {
let len = socket.read_u32().await?;
let mut line = vec![0; len];
socket.read_exact(&mut line).await?;
let line = str::from_utf8(line)?;
Ok(line)
}
Этот код очень похож на обычный, не асинхронный, код Rust, за исключением ключевого слова
async и вызова .
await. Хотя Алан никогда раньше не писал на Rust, он уверен, что знает, как работает эта функция. Как мы увидим позже, он ошибается. При локальном тестировании его чат-сервер работает без ошибок, поэтому Алан отправляет ссылку Барбаре. К сожалению, после небольшой переписки в чате сервер вылетает с ошибкой «
invalid UTF-8». Теперь Алан не понимает, в чём дело: он проверяет код и не находит ошибок.
Так в чем проблема? Оказывается, под капотом, в стеке вызовов, используется макрос select!
Макрос futures::select запускает несколько футур (асинхронных вычислений) одновременно и передаёт управление пользователю, как только любая из футур завершится.
loop {
select! {
line_in = parse_line(&socket) => {
if let Some(line_in) = line_in {
broadcast_line(line_in);
} else {
// соединение закрыто, выходим из цикла
break;
}
}
line_out = channel.recv() => {
write_line(&socket, line_out).await;
}
}
}
Предположим, что сообщение пришло в чат (через
channel) именно в то время, когда
parse_line всё ещё занят обработкой данных. Но select! прерывает операцию parse_line, не дав ей завершить парсинг. На следующей итерации цикла parse_line вызывается снова и начинает парсить с середины фрейма, что приводит к чтению тарабарщины.
В этом и заключается проблема: любая асинхронная функция Rust может перестать работать в любое время, так как её могут просто прервать. И это ситуация не является чем-то из ряда вон выходящим. Каким местом должен думать начинающий Rust-разработчик, чтобы понять причину такого поведения?
Да никаким. Нужно просто изменить это поведение — внести изменения в сам язык.
Изменение #1: Используем футуры с гарантированным завершением
Если поведение языка не соответствует ожиданиям и интуитивным представлениям, нужно подсказать ученику правильное направление, а не молчать. А по-хорошему, необходимо свести к минимуму вот такие неприятные сюрпризы в процессе обучения, особенно на раннем этапе.
Давайте начнём с исправления проблемы неожиданной отмены (или прерывания) асинхронных операций. Сделаем так, чтобы они выполнялись полностью (впервые эта идея была предложена здесь). Используя футуры с гарантированным завершением, мы добавляем в асинхронный Rust немного блокировок, но оставляем ключевые слова async и await. Создание порождённых задач (с помощью spawn) добавляет параллелизма, а асинхронные каналы (тип Channel) обеспечивают взаимодействие между потоками и обмен задачами. Поэтому передадим в select! каналы или «канальные типы» (например, JoinHandle).
Вот как изменится код из первых двух примеров:
async fn handle_connection(socket: TcpStream, channel: Channel) {
let reader = Arc::new(socket);
let writer = reader.clone();
let read_task = task::spawn(async move {
while let Some(line_in) in parse_line(&reader).await {
broadcast_line(line_in);
}
});
loop {
//
select! {
res = read_task.join() => {
// соединение закрыто, выходим из цикла
break;
}
line_out = channel.recv() => {
write_line(&writer, line_out).await;
}
}
}
}
Теперь все асинхронные операции должны выполняться полностью, select! принимает только канальные типы, вызов
parse_line () перемещается внутрь порождённой задачи. Эти небольшие изменения в коде могли бы предотвратить проблему, с которой столкнулся Алан. Если Алан попытается вызвать parse_line () внутри select!, он получит ошибку компилятора с рекомендацией создать задачу, чтобы внутри неё вызывать эту функцию.
При использовании канальных типов внутри select! можно не переживать, что какие-то ветки не выполнятся. Каналы могут хранить значения атомарно. От того, что какие-то ветки не проработают, данные не потеряются.
Отмена асинхронной операции
Что произойдет, если при записи возникнет ошибка? В приведённом выше коде
read_task продолжит работать. Но вместо этого Алан хочет, чтобы ошибка приводила к корректному закрытию соединения и всех задач. К сожалению, здесь мы уже начинаем сталкиваться с проблемами проектирования языка.
Если бы мы могли прервать любую асинхронную операцию в любой момент, всё бы решалось принудительным завершением футуры. Но теперь-то мы ввели футуры с гарантированным завершением! Возвращаться назад мы не будем, придётся внести в Rust новые изменения.
Возможность отменить операцию на лету — одна из главных причин использования асинхронного подхода. Попробуем использовать метод cancel ():
async fn handle_connection(socket: TcpStream, channel: Channel) {
let reader = Arc::new(socket);
let writer = reader.clone();
let read_task = task::spawn(async move {
while let Some(line_in) in parse_line(&reader).await? {
broadcast_line(line_in)?;
}
Ok(())
});
loop {
//
select! {
_ = read_task.join() => {
// соединение закрыто либо будет прервано из-за ошибки,
// выходим из цикла
break;
}
line_out = channel.recv() => {
if write_line(&writer, line_out).await.is_err() {
read_task.cancel();
read_task.join();
}
}
}
}
}
Но что тут может сделать один cancel ()? Он не может немедленно прервать задачу, потому что мы используем футуры с гарантированным завершением. А мы хотим, чтобы отменённая задача прекратила работу и завершилась как можно скорее. К сожалению, вместо этого она просто вернёт ошибку «interrupted». Дальнейшие попытки использования ресурсов в этой задаче также приведут к ошибкам.
В итоге задача зависает на неопределённое время, продолжая выдавать сообщения об ошибках. Правда, в какой-то момент она всё-таки завершается.
Обнаружив такое странное поведение, Алан мог бы попытаться выяснить, что именно происходит, пока задача висит. Для этого можно добавить в код оператор println! или использовать другие способы отладки.
Явные и неявные вызовы .await
Без ведома Алана, его чат-сервер избегает большинства системных вызовов с помощью io_uring (это интерфейс взаимодействия с ядром Linux, позволяющий асинхронно отправлять и получать данные). Асинхронный Rust может прозрачно использовать
io_uring API благодаря футурам с гарантированным завершением. Когда Алан сбрасывает значение
TcpStream в конце
handle_connection (), сокет должен асинхронно закрыться. Реализация
AsyncDrop для
TcpStream выглядит так:
impl AsyncDrop for TcpStream {
async fn drop(&mut self) {
self.uring.close(self.fd).await; // тут await вызывается НЕЯВНО!
}
}
И как быть, когда .await вызывается неявно? Этот вопрос остаётся открытым. Сегодня для асинхронного ожидания завершения футуры требуется вызов .await. В этом случае трейт AsyncDrop добавляет ещё один подводный камень, когда управление выходит за пределы области видимости асинхронного контекста. Такое поведение нарушает принцип наименьшего удивления. Зачем нужны неявные вызовы .await, если наряду с ними используются явные?
Напрашивается решение проблемы в лоб:
- все вызовы .await сделать явными.
my_tcp_stream.read(&mut buf).await?;
async_drop(my_tcp_stream).await;
А если, например, пользователь забудет сделать вызов
async_drop(my_tcp_stream).await — что произойдет? Заметьте, что в приведённом выше фрагменте кода есть ошибка: оператор
? пропустит вызов async_drop, если чтение выполнится некорректно. Компилятор Rust может выдать предупреждение, указывающее на проблему, но как решить её?
Изменение #2: Отказываемся от .await
А что, если вместо требования явно вызывать async_drop (...)
.await, мы вообще удалим ключевое слово await? Тогда его не придётся писать после вызова каждой асинхронной функции (например, socket.read_u32 ().await). Однако, тогда при вызове асинхронных функций (с ключевым словом async) все вызовы .await становятся неявными.
Такой ход мыслей может показаться непоследовательным. И это так. Но все наши предложения и гипотезы нужно проверять. Неявный .await имеет ограниченное применение и зависит от контекста, поскольку встречается только в асинхронных операциях. Алану достаточно взглянуть на определение функции (на ключевое слово async), чтобы понять, что он находится в асинхронном контексте. Более того: легче станет не только Алану, но и анализаторам кода.
Отказ от явных вызовов .await имеет ещё одно преимущество: код становится больше похож на Rust без асинхронности. И тогда единственным заметным отличием становится необходимость аннотировать определённые функции ключевым словом async. В этом случае и проблема «ленивых футур» (которые запускаются только по необходимости) тоже отпадает сама собой, поэтому Алан не сможет «случайно» написать такой код и удивиться, почему «two» печатается первым.
async fn my_fn_one() {
println!("one");
}
async fn my_fn_two() {
println!("two");
}
async fn mixup() {
let one = my_fn_one();
let two = my_fn_two();
join!(two, one);
}
Один из RFC-запросов в своё время действительно вызвал некую дискуссию по теме неявных вызовов .await. В то время наиболее убедительным аргументом против было то, что неявные вызовы .await увеличивают количество непредвиденных ситуаций, в которых асинхронная операция может быть прервана. Но в случае с футурами с гарантированным завершением этот аргумент теряет силу.
Как бы то ни было, отказ от явных вызовов .await — это очень серьёзное изменение, и к нему нужно подходить осторожно. Соответствующие исследования должны выявить, насколько плюсы перевешивают минусы.
Изменение #3: Отказываемся от Arc и используем scoped tasks
Теперь Алан может разработать свой чат-сервер с помощью асинхронного Rust, не заглядывая под капот и не сталкиваясь с неожиданным поведением. Компилятор рекомендует ему использовать канальные типы и добавить async к своим функциям, и эти рекомендации действительно работают. Он показывает свой код Барбаре и спрашивает, нужно ли использовать Arc для сокета (
let reader
= Arc::new(socket);).
Барбара вместо этого предлагает ему посмотреть в сторону scoped tasks. Это асинхронный эквивалент scoped threads. Задачи такого типа способны заимствовать данные, принадлежащие своему «родителю».
async fn handle_connection(socket: TcpStream, channel: Channel) {
task::scope(async |scope| {
let read_task = scope.spawn(async || {
while let Some(line_in) in parse_line(&socket)? {
broadcast_line(line_in)?;
}
Ok(())
});
loop {
//
select! {
_ = read_task.join() => {
// соединение закрыто либо будет прервано из-за ошибки,
// выходим из цикла
break;
}
line_out = channel.recv() => {
if write_line(&writer, line_out).is_err() {
break;
}
}
}
}
});
}
Такое решение должно гарантировать выполнение асинхронных операций полностью. Но у него есть недостаток: для использования scoped tasks придётся сделать метод Future::poll небезопасным, поскольку теперь мы не сможем опрашивать футуру до её завершения. Разработчикам языка придётся добавить в язык небезопасную реализацию типажа Future. Придётся реализовать такие трейты, как AsyncRead и AsyncIterator. Но я считаю, что это достижимая цель.
Гарантия завершения асинхронных операций также позволит передавать указатели из scoped task в ядро Linux при использовании io_uring или при интеграции с футурами C++.
Изменение #4: Отказываемся от FuturesUnordered
Сегодня в асинхронных Rust приложениях можно обеспечить параллелизм, порождая новую задачу, используя select! или FuturesUnordered. До сих пор мы много говорили про первые два варианта. Я и дальше предлагаю не говорить про FuturesUnordered, так как это частый источник ошибок. При использовании FuturesUnordered легко создавать задачи, ожидая, что они будут работать в фоновом режиме, а затем
удивиться, что они не показывают никакого прогресса.
«Имитировать» FuturesUnordered можно с помощью тех же scoped tasks и TaskSet. Это гораздо надёжнее.
let greeting = «Hello».to_string();
task::scope(async |scope| {
let mut task_set = scope.task_set();
for i in 0..10 {
task_set.spawn(async {
println!(»{} from task {}», greeting, i);
i
});
}
async for res in task_set {
println!(«task completed {:?}», res);
}
});
Каждая порождённая задача выполняется параллельно, заимствуя данные из порождающей задачи, а TaskSet предоставляет API, аналогичный FuturesUnordered. Такие примитивы, как buffered stream, также могут быть реализованы за счёт scoped tasks.
Текущая модель асинхронного Rust не позволяет исследовать другие примитивы параллелизма. Это могло бы стать возможным, если бы мы сделали Rust с гарантированным завершением асинхронных операций (к которому мы пришли в этой статье).
Изменение #5: Добавляем опцию #[abort_safe]
В начале статьи я утверждал, что использование асинхронного программирования позволяет нам эффективно моделировать сложное управление потоком исполнения. Самый эффективный примитив, который у нас есть сегодня, — это select!.. Я ранее предложил в этой статье использовать его, правда только с канальными типами. Но тогда нужно порождать две задачи для каждого соединения — для одновременного чтения и записи. Порождённые задачи действительно помогают предотвратить ошибки при отмене (прерывании) операции. Но попробуем найти более эффективное решение и переписать операцию чтения для случая её неожиданного прерывания.
Например, mini-redis при парсинге фреймов сначала сохраняет полученные данные в буфере. При прерывании операции чтения данные не теряются, потому что они находятся в буфере. Следующий вызов чтения возобновится с того места, где мы остановились. Такую реализацию можно назвать «abort_safe».
Что, если вместо использования select! для канальных типов мы применим abort_safe операции. Такие операции, как приём данных из канала или чтение из буферизованного дескриптора ввода-вывода по умолчанию являются abort_safe. Нам повезло. Но вместо этого мы потребуем, чтобы разработчик явно указывал #[abort_safe] при реализации соответствующей функции. Это более выигрышная стратегия.
#[abort_safe]
#[abort_safe]
async fn read_line(&mut self) -> io::Result<Option<String>> {
loop {
// взять всю строку из буфера
if let Some(line) = self.parse_line()? {
return Ok(line);
}
// в буфере недостаточно данных для парсинга всей строки
if 0 == self.socket.read_buf(&mut self.buffer)? {
// удалённый сервер закрыл соединение.
if self.buffer.is_empty() {
return Ok(None);
} else {
return Err("connection reset by peer".into());
}
}
}
}
Вместо того, чтобы использовать операции abort_safe (с безопасным прерыванием), по умолчанию, мы сделаем это опцией (можно сравнить с opt-in в маркетинге). На такую опцию можно как бы добровольно «подписаться». Когда разработчик знакомится с таким кодом, аннотация сообщает ему, что те и вот эти функции должны быть abort_safe. Компилятор Rust может даже выдавать дополнительные проверки и предупреждения для функций, помеченных #[abort_safe].
Теперь Алан может использовать свою функцию read_line () с «select!», но без канальных типов.
loop {
select! {
line_in = connection.read_line()? => {
if let Some(line_in) = line_in {
broadcast_line(line_in);
} else {
// соединение закрыто, выходим из цикла
break;
}
}
line_out = channel.recv() => {
connection.write_line(line_out)?;
}
}
}
Учтите, что в коде можно использовать сочетание функций с опцией #[abort_safe] и без неё. Вызов abort_safe функции всегда возможен как из безопасного, так и из небезопасного контекста. Обратное неверно: компилятор Rust предотвратит вызов небезопасных функций безопасного контекста, и выведет соответствующее сообщение об ошибке.
async fn must_complete() { ... }
#[abort_safe]
async fn can_abort() {
// Invalid call => compiler error
must_complete();
}
async fn must_complete() { ... }
#[abort_safe]
async fn can_abort() {
// Valid call
spawn(async { must_complete() }).join();
}
Разработчик всегда может создать новую задачу, чтобы связать небезопасную функцию с безопасным контекстом.
Включение двух разновидностей асинхронных функций усложнит язык, но эта сложность появится на поздних этапах обучения. Нужно начинать изучение асинхронного Rust в небезопасном контексте (без учёта abort_safe). Из этого контекста обучающийся может вызывать асинхронные функции независимо от данной опции. Информация о ней будет доступна в последних, продвинутых, главах руководства по асинхронному Rust.
По крайней мере, вот так я себе это всё представляю.
Для перехода от текущей асинхронной модели с abort_safe операциями по умолчанию к модели с гарантированным завершением потребуется существенно доработать Rust. Допустим, все работы будут завершены к 2026 году. Обычные футуры будут изменены на футуры с гарантированным завершением. Вместо этого старые (обычные) футуры в версии 2026 года будут жить под именем AbortSafeFuture.
Именно добавление #[abort_safe] к асинхронным функциям приведёт к появлению AbortSafeFuture вместо старой Future. Любая асинхронная функция, написанная в версиях Rust до 2026 года, должна иметь возможность использовать AbortSafeFuture. Это сделает весь существующий асинхронный код совместимым с новой версией (напомним, что abort_safe функция, может быть вызвана из любого контекста).
Обновление старой кодовой базы языка потребует добавления #[abort_safe] ко всем асинхронным функциям. Это механический процесс, можно легко автоматизировать его. Чтобы добавить поддержку асинхронного Rust с гарантированным завершением в среду исполнения Tokio, её тоже придётся основательно переработать.
Я рассказал о нескольких изменениях, которые, как мне кажется, помогут упростить асинхронное программирование в Rust:
- Используем футуры с гарантированным завершением
- Отказываемся от .await
- Отказываемся от Arc и используем scoped tasks
- Отказываемся от FuturesUnordered и расширяем возможности параллелизма
- Добавляем опцию #[abort_safe]
Они также помогут усовершенствовать сам механизм выполнения асинхронных операций. Но прежде чем принимать какие-либо решения, нам нужно больше экспериментальных данных. Какой процент сегодняшнего асинхронного кода защищён от нежелательных прерываний?
Можем ли мы провести достаточно исследований, чтобы оценить потенциальную пользу от этих изменений? И наоборот: насколько тяжелее будет изучать и программировать на Rust, если появится два вида асинхронных функций (с опцией abort_safe и без неё)?
Надеюсь, что эта статья также вызовет дискуссию, и, возможно, вы предложите альтернативные решения. Пришло время пробовать самые смелые идеи.
VDS/VPS хостинг с быстрыми NVMе-дисками и посуточной оплатой. Загрузка своего ISO.