
В современных условиях бизнес активно применяет процессный подход к организации работы. Но до сих пор существует проблема понимания – что такое управление бизнес-процессами и как правильно использовать BPM.
Определение по версии EABPM (Европейская ассоциация BPM) этого термина звучит следующим образом:
Управление бизнес-процессами (BPM) представляет собой системный подход для отражения, проектирования, выполнения, документирования, измерения, мониторинга и контроля как автоматизированных, так и неавтоматизированных процессов, для достижения целей и бизнес-стратегий компании. BPM охватывает осознанное, всеобъемлющее и все более технологичное определение, совершенствование, инновации и поддержание сквозных процессов. Благодаря этому системному и сознательному управлению процессами компании добиваются лучших результатов быстрее и гибче.
Я считаю, что это определение вносит больше путаницы, чем настоящего понимания BPM, особенно для людей, не изучавших глубоко эту тему.
В своей работе я постоянно пользуюсь графическими нотациями управления бизнес-процессов и BPMN. Считаю этот инструмент очень удобным, он помогает мне не только в разработке решений для бизнеса, но и в их обосновании. Ведь, как я уже много раз повторял, одна картинка стоит тысячи слов. Человек мыслит образами, и представить какой-то вид деятельности при помощи картинки (схемы) ему намного проще.
Также напомню, что эту тему я поднимаю уже не первый раз. Я много говорил о бизнес-процессах в таких статьях, как «Что такое бизнес-процесс и описание бизнес процесса» или «Краткое описание BPMN с примером».
Но вопросы остаются, их часто задают мне и читатели статей, и мои клиенты. Кроме того, очень много путаницы в понимание сути вносят маркетинговые статьи и термины, связанные с этой сферой деятельности. Как разработчики программных систем, так и бизнес-консультанты, постоянно использующие в работе эти инструменты, успели внести в сферу управления бизнес-процессов очень много исключительно маркетинговых понятий. С одной стороны, этот процесс неизбежен в любой коммерческой сфере. С другой — BPM и без того не самая простая для неспециалиста методология. А маркетинг вносит дополнительную путаницу.
А потому я решил дать свое развернутое определение тому, что такое управление бизнес-процессами. И надеюсь, что сумею помочь разобраться в основных вопросах, связанных с применением BPM.
Как появилось BPM
Любой новый бизнес можно сравнить с ребенком. Каждая компания, создаваемая с нуля, проходит период становления и обучения. Необходимо организовать взаимодействие сотрудников и подразделений, создать механизмы передачи знаний и т.д. И не важно, насколько большой будет эта компания – в малом бизнесе все эти вопросы также важны, как и в крупной организации с большим числом филиалов.
При этом человечество не стоит на месте. И как в сфере обучения детей, так и в сфере организации бизнеса появляются новые инструменты, более гибкие, удобные, понятные интуитивно, что особенно важно для людей, делающих первые шаги в любой сфере.
Если мы обратимся к старым записям и попробуем изучить особенности организации труда что на советских предприятиях, что в западных компаниях, например, Форда, мы увидим преимущественно сухие, сложные для восприятия текстовые инструкции, относящиеся преимущественно к функциональному подходу:
- Описание рабочего места;
- Должностная инструкция сотрудника;
- Требования техники безопасности и т.д.
Все это, как многие помнят, крайне сложно воспринимается, и значительная часть подобных инструкций пылились на полках, зачастую, никем, кроме создателя, не прочитанные. А опыт и требования передавались от опытного сотрудника новичку.
А что делать, если появляется необходимость быстро изменить работу целой организации? А если еще при этом внедряется автоматизация? Ответом на эти запросы и стало появление BPM.
О том, что такое бизнес-процесс, я уже писал («Что такое бизнес-процесс и описание бизнес процесса»), а потому повторять основные положения и определение самого бизнес-процесса не буду. А на понятии управление бизнес процессами давайте остановимся подробнее.
Об управлении бизнес-процессами простыми словами
Управление бизнес-процессами заключается в том, что вы регламентируете, описываете и изменяете бизнес-процессы. Именно изменяете, а не улучшаете, ведь вы можете как улучшить так и ухудшить бизнес процесс. В отличие; от станка или автомобиля, непосредственно управлять при помощи директив или нажатия кнопки коллективом невозможно. Но мы можем задать последовательность действий, которую будет выполнять коллектив при решении той или иной задачи. Именно это и называется BPM.
Определение от меня:
Управление бизнес-процессами (BPM) – это управление действиями (автоматизированными и неавтоматизирвоанными) в коллективе посредством бизнес-процессов.
Чтобы управлять любыми бизнес процессами необходимо:
- Описать сами бизнес-процессы.
- Внедрить в работу; коллектива; описанный бизнес процесс
- Назначить людей, ответственных за бизнес-процессы, так называемых, стек-холдеров или владельцев бизнес-процессов.
Важно понимать, что бизнес-процесс может выполняться как человеком, так и быть частично автоматизированным. Аналогично и стек-холдером может быть и человек, и программа (автоматическое выполнение операций и автоматизированный контроль).
При этом необходимо управлять крайне разнородной средой. Разные бизнес-процессы требуют различного подхода и действий сотрудников, различных инструментов автоматизации. И все это нужно уметь описывать по-отдельности, после чего объединять в общую систему.
Необходимо исходить из понимания: процессный подход — это управление целым через управление частями.
И чтобы исключить путаницу в терминологии, поясню:
- BPM – это методология. т.е. набор основных принципов и подходов к построению нотаций и самой организации работы при помощи бизнес-процессов.
- BPMN – нотация(язык), в которой строятся нотации, в том числе, исполняемые;
- BPMS – ;IT система исполнения, построенная по определенным правилам, заданных в методологии;
Если проводить аналогию с наукой, то BPM — это прежде всего подход, своего рода мировозрение. BPMN — это методы и алгоритмы решения конкретных задач. Например, доказательства для теорем или набор методов для создания проекта обеспечения электричеством объекта (производства, многоквартирного дома). А, в свою очередь, BPMS- это уже готовые прикладные решения, которые можно “включить” и они уже будут работать. Для математики это — готовые решения задач, имеющих практическое значение. Для физики — непосредственное реализации той самой электропроводки и подключение объектов. Для сферы айти — готовый программный код.
Исполняемые и неисполняемые бизнес процессы
Я уже писал в прошлых статьях о том, что нотации бизнес-процессов могут быть исполняемые и неисполняемые. Первые предназначены для автоматизации, вторые – для изучения работы компании и повышения эффективности взаимодействия в коллективе.
Т.е. мы используем принципы и методы BPM для создания нотаций. При этом пользуемся правилами написания BPMS. Для того, чтобы создать нотацию неисполняемую, в принципе, можно воспользоваться даже листом ватмана и карандашом. Главное, четко соблюдать все правила.
Для исполняемой нотации требуется определенная IT-среда — BPMS. При этом даже неисполняемые я рекомендую выполнять в BPMN, так как здесь сама среда помогает выявлять возможные ошибки, противоречия, что повышает грамотность и точность описания бизнес-процесса.
Отличия процессного и функционального подходов
Еще один важный факт, который поможет понять, что же такое на самом деле «управление бизнес-процессом». Мы уже выяснили, что управление – это создание определенной последовательности действий сотрудников. Т.е. в результате каждая автоматизированная система работает определенным образом. А человек – обязан по инструкции также выполнять заданные по инструкции действия.
При этом также необходимо знать:
Для стратегического планирования и оценки работы компании “в целом” лучше использовать функциональное моделирование и нотации (например IDF0). Об этом я подробно писал в статье “Знакомство с нотацией IDEF0 и пример использования”. Здесь вы сможете исходить из желаемого результата и выстраивать последовательность функций “черных ящиков”, необходимых для его достижения.
Для управления последовательностью действий и оптимизации того. что происходит внутри каждого этапа работы, а также улучшению взаимодействия между разными “черными ящиками”, необходим процессный подход BPM. Здесь вы изучаете уже сами действия, отслеживаете скорость и трудоемкость достижения результатов, оптимизируете и стандартизируете их.
Если вы вносите какие-то изменения в бизнес-процесс, то вы всегда отталкиваетесь не от целого, а от части. Т.е. вы меняете алгоритм работы программы и/или корректируете должностную инструкцию сотруднику, выполняющую определенные функции. В результате меняется один из элементов бизнес-процесса, и, как следствие, бизнес-процесс в целом.
Необходимо понимать:
Создание описания бизнес процесса начинается «в целом», после чего каждый процесс делится на подпроцессы и детализируется до определенного предела.
Изменение бизнес-процесса наоборот, начинается с «нижних» уровней – максимальной детализации. И от частностей – к целому – вносятся все необходимые правки.
Если при функциональном подходе очень важны объекты на входе и выходе. В самой функции «черном ящике» происходит определенная обработка объектов для получения необходимого результата. И здесь основная ориентация идет на то, «что именно мы хотим получить», т.е. подход к управлению бизнесом, скорее стратегический.
При процессном подходе мы получаем ответ на вопрос «как это лучше выполнить», т.е. концентрируемся на тактическом, оперативном управлении. А потому здесь при изменении отдельных элементов между «входом и «выходом» меняется весь процесс.
Также важно при детализации определить оптимальный уровень: не слишком «в общем», но и не детализировать крупный процесс вплоть до действий каждого сотрудника. Я в свое время видел описание бизнес-процессов, размещенное на двухметровом ватмане. Но чем сложнее и детальнее будет прописан процесс, тем сложнее он будет восприниматься «в целом» и, как следствие, его будет сложнее понимать и совершенствовать.
По этим причинам при работе с бизнес-процессами используется многоуровневая декомпозиция, т.е. детализация каждого «черного ящика» выделяется в отдельный процесс. И по этой же причине процессный подход не используется для стратегического планирования, для этого, повторюсь, применяют функциональное моделирование.
Описание работы с BPM
Для лучшего понимания того, что такое BPM (управление бизнес-процессами), я приведу пример последовательности действий бизнес-аналитика в рамках этой методологии:
Опрос людей (сотрудников компании). Понимание того, каким образом производится работа в каждом конкретном случае.
Документирование бизнес-процесса на основе полученных данных. На этом этапе аналитик получает описание бизнес-процесса «как есть».
Изучение полученного бизнес-процесса с точки зрения слабых мест и возможности оптимизации:
На основе готовой оптимизированной (по мере необходимости) схемы создаются документы: должностные инструкции, руководства пользователя, а также при необходимости реализуются автоматизированные решения.
После внедрения на основе нотации осуществляется контроль бизнес-процесса, выявляются возможные несоответствия, изучаются их причины.
В случае необходимости в схему вносятся изменения на основании выявленных недочетов или изменений в работе компании, связанных с внешними факторами.
Далее – снова проработка изменений в инструкциях и программных системах. И новый этап внедрения в эксплуатацию.
Жизненный цикл процесса в BPM
Как видно из описанной выше последовательности, каждый бизнес-процесс проходит определенный цикл от создания до внедрения. Далее какой-то период времени он работает “как есть”. После чего практика показывает определенные недостатки и недочеты, аналитик изучает отчетность и со своей стороны находит какие-то “слабые места”. Процесс подвергается модернизации.
Этот цикл может повторяться бесконечное число раз. Любой бизнес, любая организация — не застывший монолит, а развивающийся организм в постоянно изменяющемся окружении. Меняются особенности законодательства, приходят и уходят с рынка конкуренты, появляются новые инструменты автоматизации и т.д.
Главное правило бизнес-аналитика: при оптимизации процесса нужно уметь вовремя остановиться. И здесь необходимо четко анализировать — трудоемкость (стоимость) изменений и повышение эффективности (выгоды) в результате.
Плюсы и минусы BPM
К числу преимуществ использования BPM относятся:
Возможность максимально детализировать действия людей и систем, необходимые для получения результата.
Графические нотации – наглядны, что позволяет понять особенности процессов в компании и увидеть их слабые места.
Нотации прекрасно подходят в качестве инструкции исполнителю, который получит четкую и однозначную последовательность действий. При этом она будет оформлена графически – наиболее удобным для восприятия человеком образом.
При использовании процессного подхода результат выполнения процесса будет стандартизирован и соответствовать ожидаемому.; Это позволит снизить влияние человеческого фактора на уровень сервиса или выполнения любых других видов работы.
Методология BPM – прекрасно проработана и стандартизирована благодаря BPMN. При этом инструменты (нотации BPMN) интуитивно понятны даже для людей, не изучавших управление бизнес-процессами вообще. С другой стороны, наличие стандартов и правил позволяет избегать ошибок при разработке и создавать в системе BPMS исполняемые нотации (готовые элементы автоматизации бизнеса).
Минусы BPM, как это часто бывает, находятся там же, где и преимущества:
Высокая степень детализации процессов мешает восприятию работы бизнеса для стратегического планирования.
На людях, которые разрабатывают процессную модель, лежит очень большая ответственность. Любая ошибка может привести к печальным результатам. Например, при разработке функциональной модели есть данные на входе, результат на выходе, инструменты, которые предоставляет компания исполнителю, и сам исполнитель. Пока исполнитель на выходе выдает ожидаемый результат, в рамках функции он может действовать по собственному усмотрению, выбирая оптимальный метод достижения цели. При процессном подходе исполнитель лишается «свободы маневра». У него появляется четко заданная последовательность действий с учетом всех возможных условий. И он не имеет права действовать иначе, даже если результат окажется отличным от ожидаемого.
Бизнес-процесс статичен и практически не подлежит корректировкам «изнутри». Исполнитель получает четкую последовательность действий и уже не может проявить инициативу. В результате, любую ошибку исполнители будут повторять из раза в раз, пока она не будет исправлена в самом бизнес-процессе.
Каким компаниям подходит BPM
Процессный подход идеально подойдет государственным компаниям. Здесь важно повышать уровень сервиса и качество работы, при этом также важна стандартизация обслуживания. В государственной компании клиенты не ждут каких-то бонусов или особых инициатив. Но услуга должна быть выполнена от и до на соответствующем уровне.
В коммерческих компаниях процессный подход хорош для стандартизации работы, он позволит «подтянуть» уровень обслуживания до определенных стандартов. С одной стороны – это большой плюс. С другой – одновременно и минус, так как инициативные и талантливые сотрудники при всем желании никак не смогут себя проявить и принести больше пользы и прибыли. Процессный подход – это именно стабильность и определенная статичность. А потому при его использовании нужно четко понимать, где вас такой вариант работы устраивает, а где лучше предоставить людям больше свободы.
Для того чтобы бизнес процесс был на пользу а не во вред, рекомендуется собирать от участников бизнес процесса замечания и ошибки. Не нужно считать что BPM это истина в последней инстанции.
Подробнее о том, как именно управлять бизнесом при помощи бизнес-процессов я рассказывал уже в прошлых статьях, и буду говорить еще не один раз. Здесь я постарался максимально просто пояснить различия между терминами BPM, BPMS, BPMN и описать само понятие «управление бизнес-процессами». Без этих базовых знаний разобраться в процессном подходе невозможно.
Вопросы и ответы
В чем отличие функционального моделирования от процессного?
При функциональном подходе мы рассматриваем действия людей и автоматизированных систем как “черный ящик”. И подходим к моделированию с точки зрения — этапов достижения поставленной цели, а также необходимых для этого ресурсов. При процессном моделировании мы изучаем последовательность действий сотрудников и систем на каждом этапе для их оптимизации и повышении эффективности.
Какие понятия входят в BPMN?
В первую очередь, это непосредственно система BPMN, а также описание нотаций BPMS. О них я писал в этой статье, и подробно — в предыдущих статьях (см. рекомендуемые ссылки в конце публикации). Кроме того, не так давно появились новые понятия — DMN и CMMN. На них я сейчас подробно останавливаться не буду. Постараюсь описать новые понятия и их особенности в будущих публикациях.
Зачем нужно в построении нотаций столько сложностей и разные подходы?
Управление бизнес-процессами и сама методология BPM необходимы в том числе для директивного управления большими коллективами. Именно для этого необходимы нотации, описания бизнес-процессов и широкий перечень инструментов.
С чего начать работу с BPM?
Изучите язык нотаций BPMN и попробуйте использовать его в своей работе. Главное, не бойтесь начинать. Вы поймете, что простые нотации на практике строить намного проще, чем кажется. И шаг за шагом сможете изучить методологию, опираясь на простые и понятные графические инструменты BPM.
Можно ли использовать BPM для неавтоматизированных систем?
Можно. Это подход предназначен, в первую очередь, не для автоматизации (в IT сфере есть свои инструменты), а для организации работы компании или любого коллектива. Здесь могут учитываться участки работы с применением автоматизированных систем. А могут рассматриваться исключительно процессы в коллективе, причем, любом — от строительных бригад или производства до творческих коллективов в театре или филармонии. Главное, четко описать — как происходит интересующий вас процесс, а также, как вы его хотите изменить.
Для лучшего понимания тематики рекомендую статьи:
Также в настоящее время я готовлю к публикации книгу и онлайн курс, в которой подробно опишу собственное видение процессного подхода к бизнесу, а также мой собственный практический опыт работы в сфере функционального и процессного моделирования. Все желающие могут подписаться на уведомление о выходе новой книги по
ссылке.
Let's block ads! (Why?)






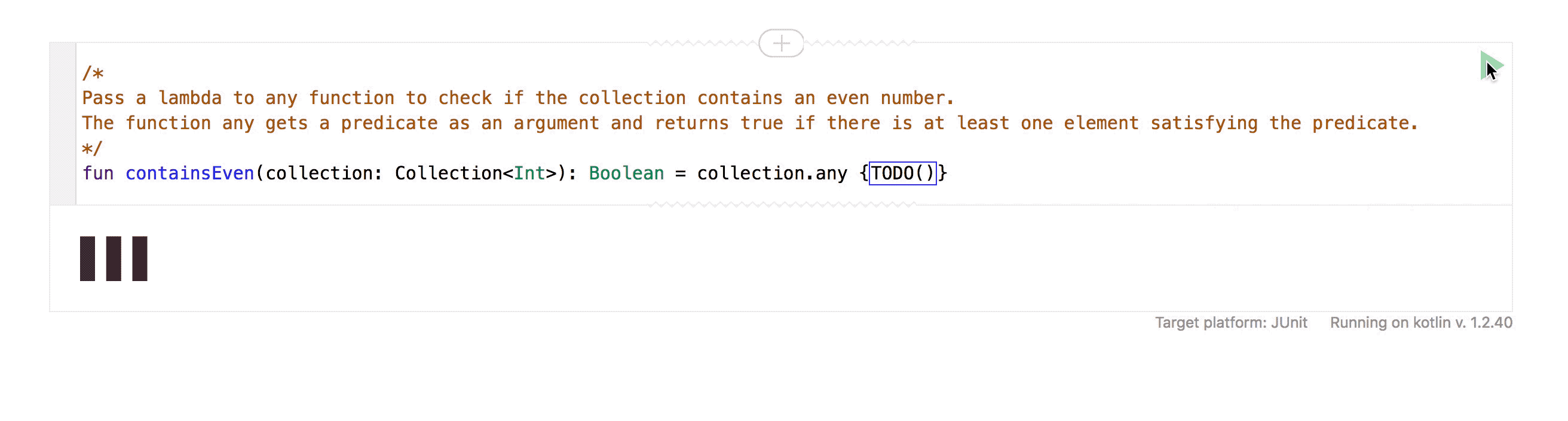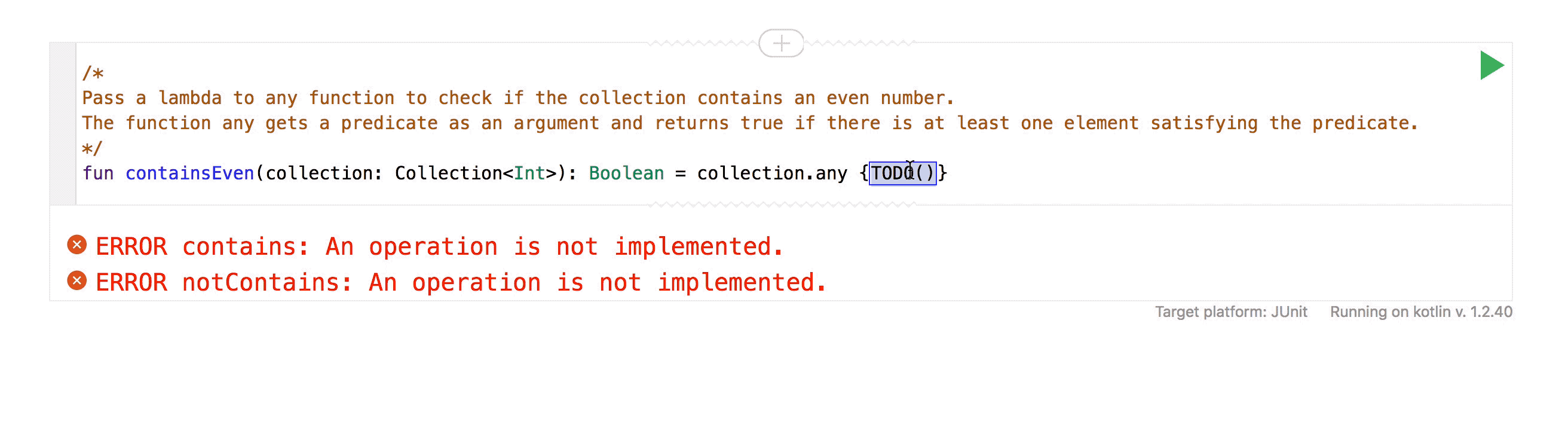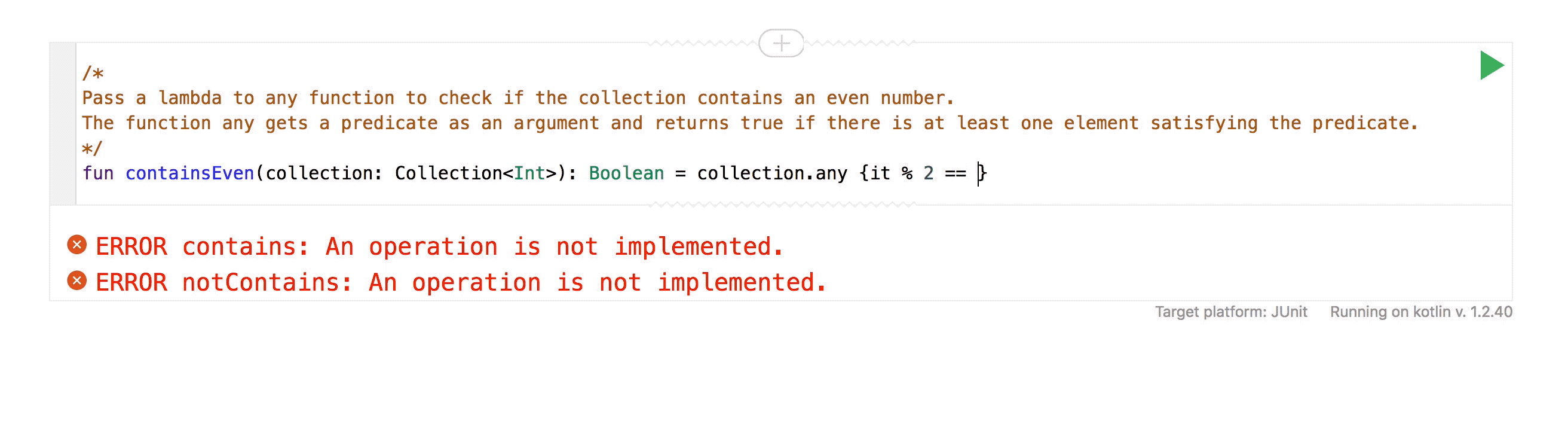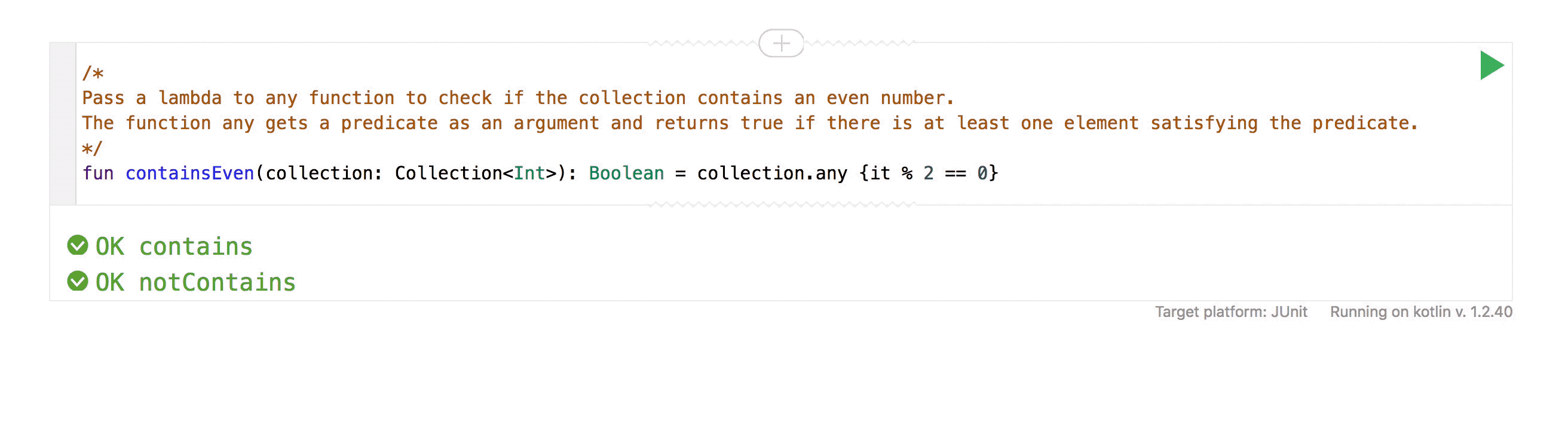

 Каждый день поступает все больше заказов, и их нужно как-то распределять по исполнителям. Вроде ничего сложного: пришёл заказ – отдай его клинеру. Но не всё так просто, как кажется. У наших клинеров нет фиксированного графика работы, они могут работать, когда захотят, отказываться практически от любых заказов (и это клинеры, увы, делают довольно часто). Поэтому распределение заказов – одна из самых сложных задач, над которой мы работаем.
Каждый день поступает все больше заказов, и их нужно как-то распределять по исполнителям. Вроде ничего сложного: пришёл заказ – отдай его клинеру. Но не всё так просто, как кажется. У наших клинеров нет фиксированного графика работы, они могут работать, когда захотят, отказываться практически от любых заказов (и это клинеры, увы, делают довольно часто). Поэтому распределение заказов – одна из самых сложных задач, над которой мы работаем.

















 /
/